สารบัญ[ซ่อน][แสดง]
บริษัทต่างๆ กำลังรวบรวมข้อมูลมากกว่าที่เคย เนื่องจากพวกเขาพึ่งพาข้อมูลดังกล่าวมากขึ้นเรื่อยๆ เพื่อแจ้งการตัดสินใจทางธุรกิจที่สำคัญ ปรับปรุงการนำเสนอผลิตภัณฑ์ และให้บริการลูกค้าได้ดียิ่งขึ้น
ด้วยปริมาณข้อมูลที่สร้างขึ้นในอัตราเลขชี้กำลัง ระบบคลาวด์จึงมีข้อดีหลายประการสำหรับการประมวลผลข้อมูลและการวิเคราะห์ ซึ่งรวมถึงความสามารถในการปรับขนาด ความน่าเชื่อถือ และความพร้อมใช้งาน
ในระบบนิเวศระบบคลาวด์ ยังมีเครื่องมือและเทคโนโลยีมากมายสำหรับการประมวลผลและวิเคราะห์ข้อมูล โครงสร้างการจัดเก็บข้อมูลขนาดใหญ่สองประเภทที่ใช้บ่อยที่สุดคือคลังข้อมูลและ Data Lake
แม้ว่าการใช้ data lake จะไม่ค่อยน่าสนใจนัก เนื่องจากคุณไม่สามารถสืบค้นแบบจำลองและข้อมูลในขณะที่ยังคงมีความเกี่ยวข้องอยู่ การใช้คลังข้อมูลสำหรับการสตรีมการจัดเก็บข้อมูลนั้นสิ้นเปลือง

Wเราเลือกสถาปัตยกรรมคลาวด์ประเภทใด
เราควรพิจารณาแนวคิดใหม่ๆ สำหรับ data lakehouse หรือเราควรพอใจกับข้อจำกัดของคลังสินค้าหรือข้อจำกัดของทะเลสาบ
สถาปัตยกรรมการจัดเก็บข้อมูลแบบใหม่ที่เรียกว่า "data lakehouse" ผสมผสานความสามารถในการปรับตัวของ data lake เข้ากับการจัดการข้อมูลของคลังข้อมูล
การทำความเข้าใจวิธีการจัดเก็บบิ๊กดาต้าต่างๆ เป็นสิ่งจำเป็นสำหรับการสร้างไปป์ไลน์การจัดเก็บข้อมูลที่เชื่อถือได้สำหรับข่าวกรองธุรกิจ (BI) การวิเคราะห์ข้อมูล และ เรียนรู้เครื่อง ปริมาณงาน (ML) ขึ้นอยู่กับความต้องการของบริษัทของคุณ
ในโพสต์นี้ เราจะพิจารณาอย่างใกล้ชิดที่ Data Warehouse, Data Lake และ Data Lakehouse พร้อมประโยชน์ ข้อจำกัด ตลอดจนข้อดีและข้อเสีย เอาล่ะ.
คลังข้อมูลคืออะไร?
คลังข้อมูลคือที่เก็บข้อมูลส่วนกลางที่องค์กรใช้เพื่อเก็บข้อมูลปริมาณมหาศาลจากแหล่งต่างๆ คลังข้อมูลทำหน้าที่เป็นแหล่ง "ความจริงของข้อมูล" แหล่งเดียวขององค์กร และจำเป็นต่อการรายงานและการวิเคราะห์ธุรกิจ
โดยทั่วไป คลังข้อมูลจะรวมชุดข้อมูลเชิงสัมพันธ์จากหลายแหล่ง เช่น แอปพลิเคชัน ธุรกิจ และข้อมูลธุรกรรม เพื่อจัดเก็บข้อมูลในอดีต ก่อนที่จะโหลดเข้าสู่ระบบคลังสินค้า ข้อมูลจะถูกแปลงและทำความสะอาดในคลังข้อมูลเพื่อให้สามารถใช้เป็นแหล่งข้อมูลจริงแหล่งเดียวได้
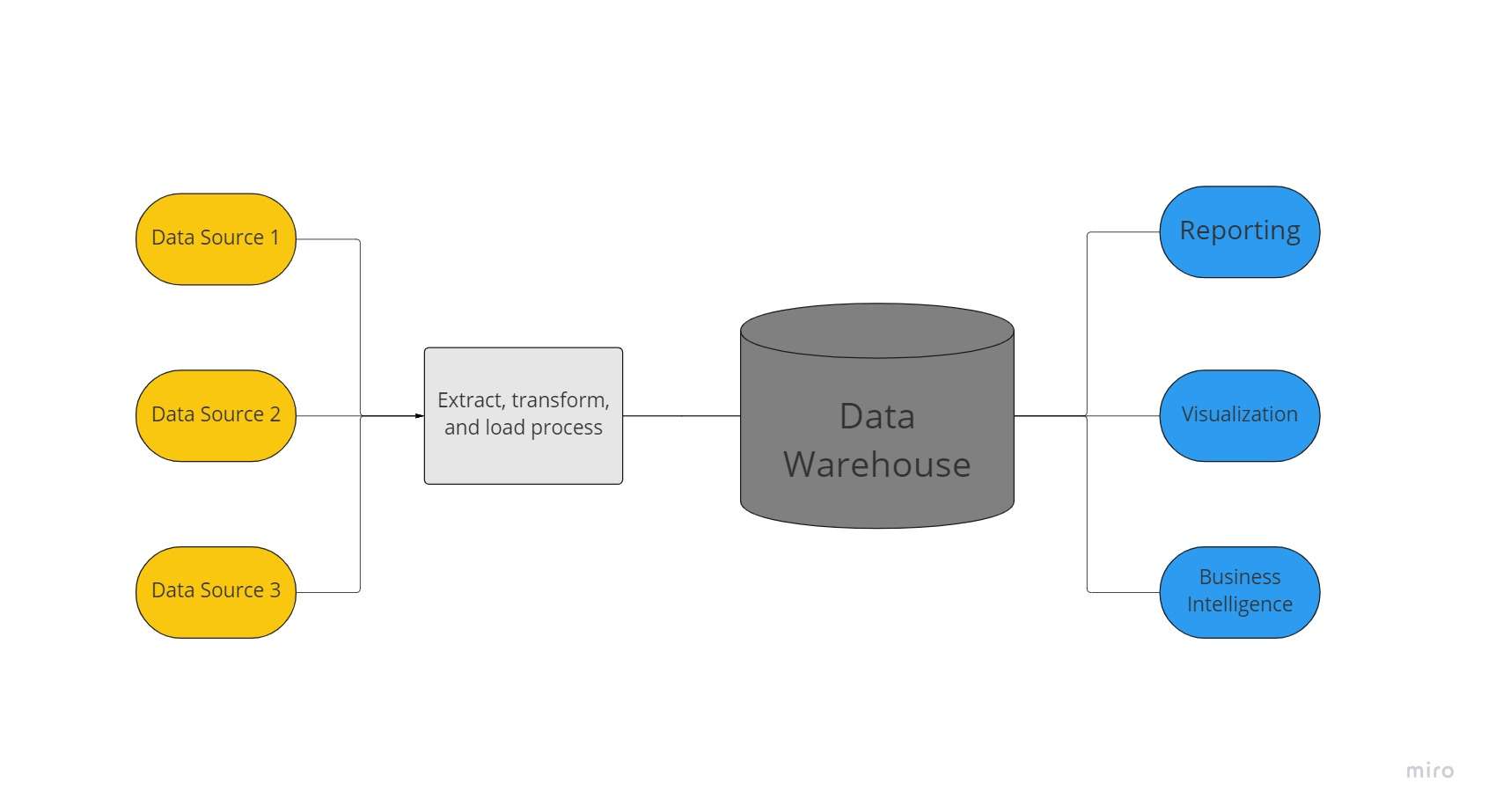
เนื่องจากความสามารถในการนำเสนอข้อมูลเชิงลึกทางธุรกิจอย่างรวดเร็วจากทุกพื้นที่ของบริษัท ธุรกิจจึงลงทุนในคลังข้อมูล ด้วยการใช้เครื่องมือ BI ไคลเอนต์ SQL และโซลูชันการวิเคราะห์อื่น ๆ ที่มีความซับซ้อนน้อยกว่า (เช่น วิทยาศาสตร์ที่ไม่ใช่ข้อมูล) นักวิเคราะห์ธุรกิจวิศวกรข้อมูล และผู้มีอำนาจตัดสินใจสามารถเข้าถึงข้อมูลจากคลังข้อมูลได้
การบำรุงรักษาคลังสินค้าที่มีปริมาณข้อมูลเพิ่มมากขึ้นเรื่อยๆ มีค่าใช้จ่ายสูง และคลังข้อมูลไม่สามารถจัดการข้อมูลดิบหรือข้อมูลที่ไม่มีโครงสร้างได้ นอกจากนี้ยังไม่ใช่ตัวเลือกในอุดมคติสำหรับเทคนิคการวิเคราะห์ข้อมูลที่ซับซ้อน เช่น การเรียนรู้ของเครื่องหรือการสร้างแบบจำลองการคาดการณ์
คลังข้อมูลจึงให้การตอบกลับแบบสอบถามเร็วขึ้นและข้อมูลคุณภาพสูงขึ้น Google Big Query, Amazon Redshift, Azure SQL Data warehouse และ Snowflake เป็นบริการคลาวด์ที่พร้อมใช้งานสำหรับคลังข้อมูล
ประโยชน์ของคลังข้อมูล
- เพิ่มประสิทธิภาพและความเร็วของธุรกิจอัจฉริยะและปริมาณงานการวิเคราะห์ข้อมูล: คลังข้อมูลช่วยลดเวลาที่จำเป็นสำหรับการเตรียมและวิเคราะห์ข้อมูล พวกเขาสามารถเชื่อมโยงไปยังเครื่องมือวิเคราะห์ข้อมูลและข่าวกรองธุรกิจได้อย่างง่ายดาย เนื่องจากข้อมูลจากคลังข้อมูลมีความน่าเชื่อถือและสม่ำเสมอ นอกจากนี้ คลังข้อมูลยังช่วยประหยัดเวลาที่จำเป็นสำหรับการเก็บรวบรวมข้อมูล และช่วยให้ทีมสามารถใช้ข้อมูลสำหรับรายงาน แดชบอร์ด และข้อกำหนดด้านการวิเคราะห์อื่นๆ
- เพิ่มความสม่ำเสมอ คุณภาพ และมาตรฐานของข้อมูล: องค์กรรวบรวมข้อมูลจากแหล่งต่างๆ รวมถึงข้อมูลผู้ใช้ ข้อมูลการขาย และธุรกรรม บริษัทสามารถไว้วางใจข้อมูลสำหรับความต้องการทางธุรกิจได้ เนื่องจากคลังข้อมูลรวบรวมข้อมูลองค์กรให้อยู่ในรูปแบบที่เป็นมาตรฐานเดียวกันและสามารถทำหน้าที่เป็นแหล่งข้อมูลความจริงแหล่งเดียวได้
- เสริมสร้างการตัดสินใจโดยทั่วไป: คลังข้อมูลช่วยอำนวยความสะดวกในการตัดสินใจได้ดีขึ้นด้วยการนำเสนอร้านค้าแบบรวมศูนย์สำหรับข้อมูลทั้งเก่าและใหม่ โดยการประมวลผลข้อมูลในคลังข้อมูลเพื่อให้ได้ข้อมูลเชิงลึกที่แม่นยำ ผู้มีอำนาจตัดสินใจสามารถประเมินความเสี่ยง เข้าใจความต้องการของลูกค้า และปรับปรุงสินค้าและบริการ
- ให้ข้อมูลทางธุรกิจที่ดีขึ้น: คลังข้อมูลเชื่อมช่องว่างระหว่างข้อมูลดิบขนาดมหึมา ซึ่งถูกรวบรวมเป็นประจำเป็นประจำ และข้อมูลที่ได้รับการดูแลซึ่งให้ข้อมูลเชิงลึก พวกเขาทำหน้าที่เป็นรากฐานสำหรับการจัดเก็บข้อมูลขององค์กร ทำให้สามารถตอบคำถามที่ซับซ้อนเกี่ยวกับข้อมูลของตน และใช้คำตอบเพื่อทำการตัดสินใจทางธุรกิจที่สามารถป้องกันได้
ข้อจำกัดของคลังข้อมูล
- ขาดความยืดหยุ่นของข้อมูล: ในขณะที่คลังข้อมูลเก่งในการจัดการข้อมูลที่มีโครงสร้าง แต่รูปแบบข้อมูลกึ่งโครงสร้างและไม่มีโครงสร้าง เช่น การวิเคราะห์บันทึก การสตรีม และข้อมูลโซเชียลมีเดียอาจเป็นสิ่งที่ท้าทายสำหรับพวกเขา ทำให้แนะนำคลังข้อมูลสำหรับกรณีการใช้งานที่เกี่ยวข้องกับการเรียนรู้ของเครื่องและ ปัญญาประดิษฐ์ ยาก.
- ค่าใช้จ่ายในการติดตั้งและบำรุงรักษา: คลังข้อมูลอาจมีราคาแพงในการติดตั้งและบำรุงรักษา นอกจากนี้คลังข้อมูลมักจะไม่คงที่ มันมีอายุมากและต้องบำรุงรักษาบ่อยซึ่งมีราคาแพง
ข้อดี
- ข้อมูลนั้นง่ายต่อการค้นหา เรียกค้น และสืบค้น
- ตราบใดที่ข้อมูลสะอาดอยู่แล้ว การเตรียมข้อมูล SQL ก็ทำได้ง่าย
จุดด้อย
- คุณถูกบังคับให้ใช้ผู้ให้บริการวิเคราะห์เพียงรายเดียว
- การวิเคราะห์และจัดเก็บข้อมูลที่ไม่มีโครงสร้างหรือไหลลื่นนั้นมีค่าใช้จ่ายค่อนข้างสูง
Data Lake คืออะไร?
ข้อมูลทุกประเภทได้รับการสัญญาและทำให้เป็นไปได้โดย data lake การมีข้อมูลในลักษณะที่สามารถเข้าถึงได้จากส่วนกลางและพร้อมสำหรับการอ่านจะเป็นประโยชน์อย่างยิ่ง
Data Lake คือพื้นที่จัดเก็บข้อมูลแบบรวมศูนย์และปรับเปลี่ยนได้อย่างมาก โดยที่ข้อมูลจำนวนมากที่มีการจัดระเบียบและไม่มีโครงสร้างจะถูกเก็บไว้ในรูปแบบที่ยังไม่ได้ประมวลผล ไม่มีการเปลี่ยนแปลง และไม่มีการจัดรูปแบบ
Data Lake ใช้สถาปัตยกรรมแบบเรียบและออบเจ็กต์ที่จัดเก็บไว้ในสถานะที่ยังไม่ได้ประมวลผลเพื่อจัดเก็บข้อมูล ต่างจากคลังข้อมูลซึ่งบันทึกข้อมูลเชิงสัมพันธ์ที่ก่อนหน้านี้ "ถูกล้าง"
Data Lake ต่างจากคลังข้อมูลซึ่งมีปัญหาในการจัดการข้อมูลในรูปแบบนี้ สามารถปรับ เชื่อถือได้ และราคาไม่แพง และช่วยให้องค์กรต่างๆ ได้รับข้อมูลเชิงลึกที่เพิ่มขึ้นจากข้อมูลที่ไม่มีโครงสร้าง
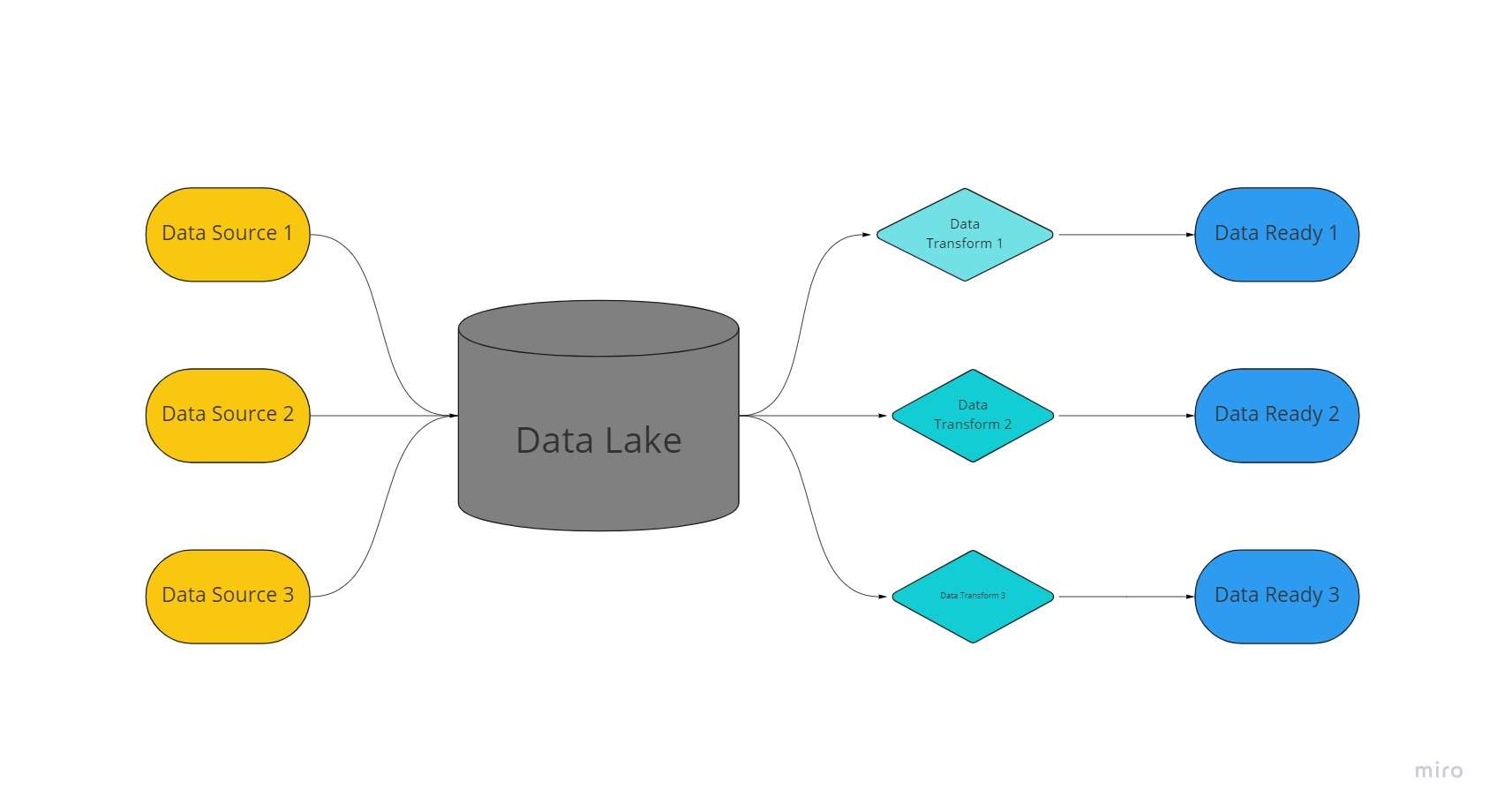
ใน Data Lake ข้อมูลจะถูกดึง โหลด และแปลง (ELT) เพื่อวัตถุประสงค์ในการวิเคราะห์ แทนที่จะสร้างสคีมาหรือข้อมูลในขณะที่รวบรวมข้อมูล
ใช้เทคโนโลยีสำหรับข้อมูลหลายประเภทจากอุปกรณ์ IoT โซเชียลมีเดียและการสตรีมข้อมูล Data Lake ช่วยให้การเรียนรู้ของเครื่องและการวิเคราะห์เชิงคาดการณ์
นอกจากนี้ นักวิทยาศาสตร์ข้อมูลที่สามารถประมวลผลข้อมูลดิบสามารถใช้ data lake ได้ ในทางกลับกัน คลังข้อมูลนั้นง่ายกว่าสำหรับธุรกิจ เหมาะสำหรับการจัดทำโปรไฟล์ผู้ใช้ การวิเคราะห์เชิงทำนาย, แมชชีนเลิร์นนิง และงานอื่นๆ
แม้ว่า Data Lake จะจัดการกับปัญหาหลายประการเกี่ยวกับคลังข้อมูล แต่คุณภาพของข้อมูลก็แย่และความเร็วในการสืบค้นไม่เพียงพอ นอกจากนี้ ยังใช้เครื่องมือเพิ่มเติมสำหรับผู้ใช้ทางธุรกิจในการดำเนินการค้นหา SQL Data Lake ที่มีโครงสร้างไม่ดีอาจประสบปัญหาเกี่ยวกับความซบเซาของข้อมูล
ประโยชน์ของ Data Lake
- รองรับกรณีการใช้งาน Machine Learning และ Data Science ที่หลากหลาย การใช้เครื่องที่แตกต่างกันและอัลกอริธึมการเรียนรู้เชิงลึกเพื่อจัดการข้อมูลใน Data Lake นั้นง่ายกว่า เนื่องจากข้อมูลจะถูกเก็บไว้ในลักษณะเปิดและดิบ
- ความเก่งกาจของ Data Lake ซึ่งช่วยให้คุณจัดเก็บข้อมูลในรูปแบบหรือสื่อใดๆ โดยไม่ต้องมีสคีมาที่กำหนดไว้ล่วงหน้า ถือเป็นข้อได้เปรียบอย่างมาก รองรับกรณีการใช้ข้อมูลในอนาคต และสามารถวิเคราะห์ข้อมูลเพิ่มเติมได้หากข้อมูลอยู่ในสถานะเดิม
- เพื่อหลีกเลี่ยงไม่ให้ต้องจัดเก็บข้อมูลทั้งสองประเภทในบริบทต่างๆ Data Lake สามารถมีทั้งข้อมูลที่มีโครงสร้างและไม่มีโครงสร้าง สำหรับการจัดเก็บข้อมูลองค์กรประเภทต่างๆ มีที่เดียว
- เมื่อเทียบกับคลังข้อมูลแบบเดิม Data Lake มีราคาถูกกว่าเนื่องจากสร้างขึ้นเพื่อเก็บไว้ในฮาร์ดแวร์สินค้าโภคภัณฑ์ราคาไม่แพง เช่น พื้นที่จัดเก็บอ็อบเจ็กต์ ซึ่งมักจะมุ่งให้ต้นทุนต่อกิกะไบต์ที่จัดเก็บต่ำลง
ข้อจำกัดของ Data Lake
- กรณีการใช้งานการวิเคราะห์ข้อมูลและข่าวกรองธุรกิจมีคะแนนต่ำ: Data Lake อาจไม่เป็นระเบียบหากไม่ได้รับการดูแลอย่างเพียงพอ ซึ่งทำให้ยากต่อการเชื่อมโยงไปยัง Business Intelligence และเครื่องมือวิเคราะห์ นอกจากนี้ เมื่อจำเป็นสำหรับกรณีการใช้งานการรายงานและการวิเคราะห์ การขาดความสอดคล้อง โครงสร้างข้อมูล และการสนับสนุนธุรกรรม ACID (อะตอมมิก ความสม่ำเสมอ การแยก และความทนทาน) อาจทำให้ประสิทธิภาพการสืบค้นต่ำลง
- ความไม่สอดคล้องกันของ Data Lake ทำให้ไม่สามารถบังคับใช้ความเชื่อถือได้และความปลอดภัยของข้อมูล ซึ่งส่งผลให้ขาดทั้งสองอย่าง การพัฒนามาตรฐานการรักษาความปลอดภัยและการกำกับดูแลข้อมูลที่เหมาะสมอาจเป็นเรื่องยาก เพื่อรองรับประเภทข้อมูลที่ละเอียดอ่อน เนื่องจาก Data Lake สามารถจัดการรูปแบบข้อมูลใดก็ได้
ข้อดี
- โซลูชันที่มีราคาไม่แพงสำหรับข้อมูลทุกประเภท
- สามารถจัดการข้อมูลที่มีทั้งการจัดระเบียบและกึ่งโครงสร้าง
- เหมาะอย่างยิ่งสำหรับการประมวลผลและการสตรีมข้อมูลที่ซับซ้อน
จุดด้อย
- ต้องการไปป์ไลน์ที่ซับซ้อนเพื่อสร้าง
- ให้เวลากับข้อมูลเพื่อให้สามารถสืบค้นได้
- ใช้เวลาในการรับประกันความเชื่อถือได้และคุณภาพของข้อมูล
Data Lakehouse คืออะไร?
สถาปัตยกรรมการจัดเก็บข้อมูลขนาดใหญ่แบบใหม่ที่เรียกว่า "data lakehouse" ผสมผสานแง่มุมที่ยิ่งใหญ่ที่สุดของ data lake และคลังข้อมูล ข้อมูลทั้งหมดของคุณ ไม่ว่าจะเป็นแบบมีโครงสร้าง กึ่งโครงสร้าง หรือไม่มีโครงสร้าง สามารถเก็บไว้ในที่เดียวด้วยการเรียนรู้ของเครื่องที่ดีที่สุด ระบบธุรกิจอัจฉริยะ และความสามารถในการสตรีมที่เป็นไปได้ด้วย Data Lakehouse
Data Lake ทุกประเภทมักเป็นจุดเริ่มต้นของ Data Lakehouse หลังจากนั้น ข้อมูลจะถูกแปลงเป็นรูปแบบเดลต้าเลค (เลเยอร์การจัดเก็บโอเพนซอร์สที่นำความน่าเชื่อถือมาสู่ดาต้าเลค)
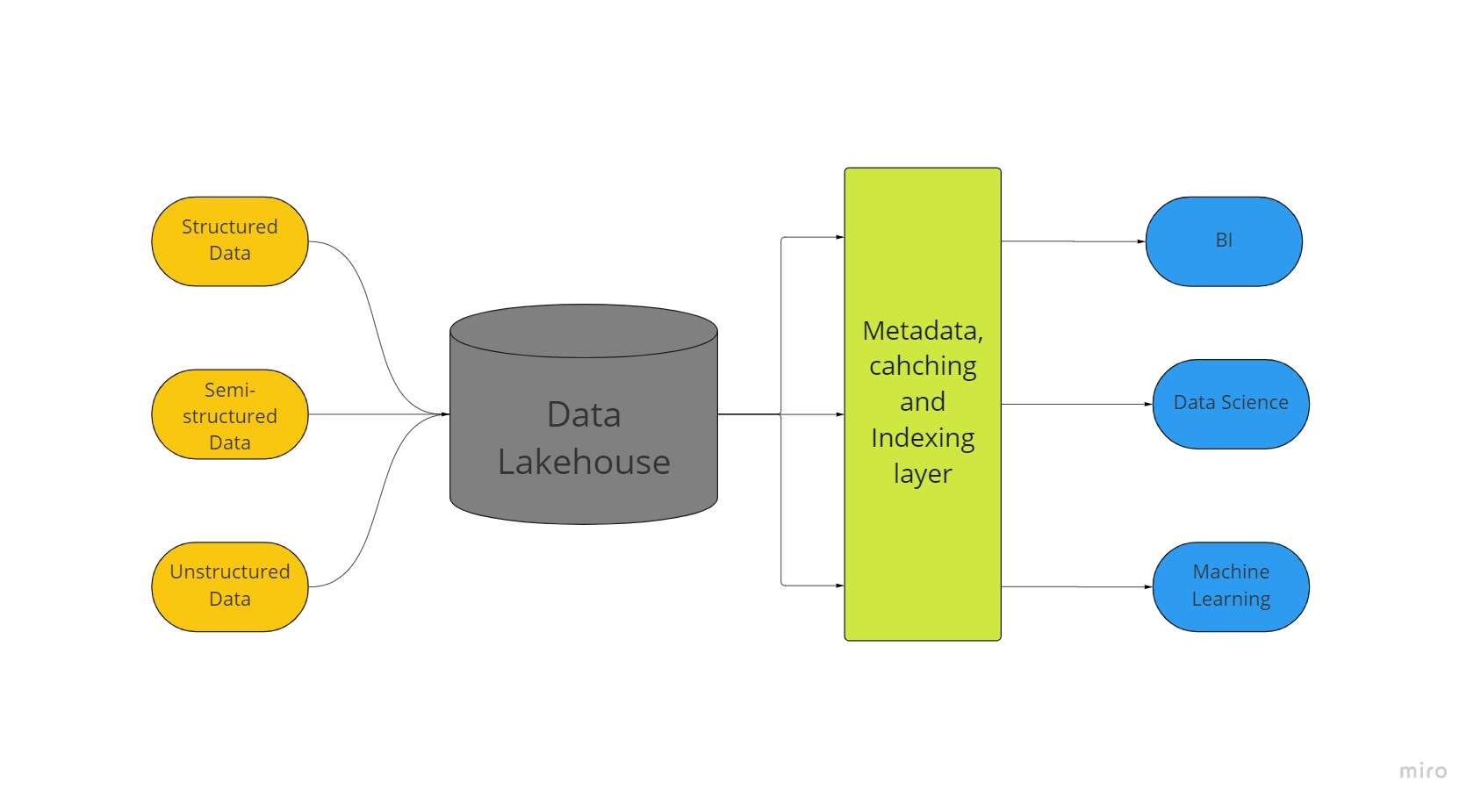
Data Lake ที่มีเดลต้าเลคเปิดใช้งานขั้นตอนการทำธุรกรรม ACID จากคลังข้อมูลทั่วไป โดยพื้นฐานแล้ว ระบบ Lakehouse ใช้ที่เก็บข้อมูลราคาไม่แพงเพื่อรักษาข้อมูลจำนวนมหาศาลในรูปแบบดั้งเดิม เหมือนกับ Data Lake
การเพิ่มชั้นข้อมูลเมตาที่ด้านบนของสโตร์ยังช่วยให้มีโครงสร้างข้อมูลและให้อำนาจเครื่องมือการจัดการข้อมูลเช่นเดียวกับที่พบในคลังข้อมูล
ซึ่งทำให้หลายทีมสามารถเข้าถึงข้อมูลของบริษัททั้งหมดผ่านระบบเดียวสำหรับความคิดริเริ่มที่หลากหลาย เช่น วิทยาศาสตร์ข้อมูล การเรียนรู้ของเครื่อง และระบบธุรกิจอัจฉริยะ
ประโยชน์ของ Data Lakehouse
- รองรับปริมาณงานที่หลากหลาย: เพื่ออำนวยความสะดวกในการวิเคราะห์ที่ซับซ้อน data lakehouses ให้ผู้ใช้เข้าถึงโดยตรงไปยังเครื่องมือข่าวกรองธุรกิจยอดนิยม (Tableau, PowerBI) นอกจากนี้ นักวิทยาศาสตร์ข้อมูลและวิศวกรการเรียนรู้ของเครื่องสามารถใช้ข้อมูลได้อย่างง่ายดาย เนื่องจาก data lakehouses ใช้รูปแบบข้อมูลแบบเปิด (เช่น Parquet) ร่วมกับ API และเฟรมเวิร์กการเรียนรู้ของเครื่อง เช่น Python/R
- ความคุ้มทุน: Data Lakehouses ใช้โซลูชันการจัดเก็บข้อมูลแบบออบเจ็กต์ราคาไม่แพงเพื่อใช้คุณลักษณะการจัดเก็บข้อมูลที่คุ้มค่าของ Data Lake ด้วยการนำเสนอโซลูชันเดียว Data Lakehouse ยังช่วยขจัดค่าใช้จ่ายและเวลาที่เกี่ยวข้องกับการจัดการระบบจัดเก็บข้อมูลต่างๆ
- การออกแบบ Data Lakehouse ช่วยให้มั่นใจได้ถึงสคีมาและความสมบูรณ์ของข้อมูล ทำให้ง่ายต่อการสร้างระบบความปลอดภัยของข้อมูลและการกำกับดูแลที่มีประสิทธิภาพ ความสะดวกในการ การกำหนดเวอร์ชันข้อมูลธรรมาภิบาล และความปลอดภัย
- Data Lakehouses นำเสนอแพลตฟอร์มการจัดเก็บข้อมูลอเนกประสงค์เพียงแพลตฟอร์มเดียวที่สามารถรองรับความต้องการข้อมูลของบริษัททั้งหมด ซึ่งช่วยลดความซ้ำซ้อนของข้อมูล ธุรกิจส่วนใหญ่เลือกโซลูชันไฮบริดเนื่องจากประโยชน์ของทั้งคลังข้อมูลและ Data Lake ในขณะเดียวกัน กลยุทธ์นี้อาจส่งผลให้เกิดการซ้ำซ้อนของข้อมูลที่มีต้นทุนสูง
- การสนับสนุนรูปแบบเปิด รูปแบบเปิดคือประเภทไฟล์ที่แอปพลิเคชันซอฟต์แวร์จำนวนมากสามารถใช้ได้และมีข้อกำหนดเฉพาะที่เปิดเผยต่อสาธารณะ ตามรายงาน Lakehouses สามารถจัดเก็บข้อมูลในรูปแบบไฟล์ทั่วไป เช่น Apache Parquet และ ORC (Optimized Row Columnar)
ข้อจำกัดของ Data Lakehouse
ข้อเสียเปรียบที่ใหญ่ที่สุดของ data lakehouse คือมันยังเป็นเทคโนโลยีที่อายุน้อยและกำลังพัฒนา ไม่แน่ใจว่าจะปฏิบัติตามคำมั่นสัญญาหรือไม่ ก่อนที่ data lakehouses จะแข่งขันกับระบบจัดเก็บข้อมูลขนาดใหญ่ที่จัดตั้งขึ้น อาจต้องใช้เวลาหลายปี
อย่างไรก็ตาม ด้วยอัตราที่นวัตกรรมสมัยใหม่เกิดขึ้น เป็นการยากที่จะบอกว่าระบบจัดเก็บข้อมูลอื่นจะไม่มาแทนที่ในที่สุด
ข้อดี
- แพลตฟอร์มเดียวมีข้อมูลทั้งหมด ซึ่งหมายความว่ามีชื่อโฮสต์ให้ดูแลน้อยลง
- ความเป็นปรมาณู ความสม่ำเสมอ การแยกตัว และความเหนียวจะไม่ได้รับผลกระทบ
- มีราคาไม่แพงมาก
- แพลตฟอร์มเดียวมีข้อมูลทั้งหมด ซึ่งหมายความว่ามีชื่อโฮสต์ให้ดูแลน้อยลง
- ง่ายต่อการจัดการและแก้ไขปัญหาได้อย่างรวดเร็ว
- ทำให้ง่ายต่อการสร้างไปป์ไลน์
จุดด้อย
- การตั้งค่าอาจใช้เวลาสักครู่
- ยังอายุน้อยเกินไปและอยู่ไกลเกินกว่าจะมีคุณสมบัติเป็นระบบจัดเก็บข้อมูลที่จัดตั้งขึ้น
คลังข้อมูลเทียบกับ Data Lake และ Data Lakehouse
คลังข้อมูลมีประวัติอันยาวนานในด้านข่าวกรององค์กร การรายงาน และแอปพลิเคชันการวิเคราะห์ และเป็นเทคโนโลยีการจัดเก็บข้อมูลขนาดใหญ่เครื่องแรก
ในทางกลับกัน คลังข้อมูลมีราคาแพงและมีปัญหาในการจัดการข้อมูลที่หลากหลายและไม่มีโครงสร้าง เช่น การสตรีมข้อมูล สำหรับเวิร์กโหลดของการเรียนรู้ของเครื่องและวิทยาศาสตร์ข้อมูล Data Lake ได้รับการพัฒนาเพื่อจัดการข้อมูลดิบในรูปแบบที่หลากหลายบนพื้นที่จัดเก็บข้อมูลราคาไม่แพง
แม้ว่า data lakes จะมีประสิทธิภาพกับข้อมูลที่ไม่มีโครงสร้าง แต่ก็ขาดความสามารถในการทำธุรกรรมของ ACID ของคลังข้อมูล ทำให้เป็นความท้าทายในการรับประกันความสอดคล้องของข้อมูลและความเชื่อถือได้
สถาปัตยกรรมการจัดเก็บข้อมูลใหม่ล่าสุดที่เรียกว่า "data lakehouse" ผสมผสานความเชื่อถือได้และความสอดคล้องของคลังข้อมูลเข้ากับความสามารถในการจ่ายและการปรับตัวของ data lakes
สรุป
โดยสรุป การสร้าง Data Lakehouse ตั้งแต่เริ่มต้นอาจเป็นเรื่องยาก นอกจากนี้ เกือบจะแน่นอนว่าคุณกำลังใช้แพลตฟอร์มที่ออกแบบมาเพื่อเปิดใช้งานสถาปัตยกรรมแบบ open data lakehouse
ดังนั้น โปรดใช้ความระมัดระวังในการตรวจสอบคุณสมบัติและการใช้งานต่างๆ ของแต่ละแพลตฟอร์มก่อนตัดสินใจซื้อ บริษัทต่างๆ ที่มองหาโซลูชันข้อมูลที่มีโครงสร้างครบถ้วนสมบูรณ์ โดยมุ่งเน้นที่กรณีการใช้งานระบบธุรกิจอัจฉริยะและการวิเคราะห์ข้อมูล สามารถพิจารณาคลังข้อมูลได้
อย่างไรก็ตาม องค์กรต่างๆ ที่มองหาโซลูชันบิ๊กดาต้าที่ปรับขนาดได้และราคาไม่แพง เพื่อเพิ่มประสิทธิภาพเวิร์กโหลดสำหรับวิทยาการข้อมูลและการเรียนรู้ของเครื่องบนข้อมูลที่ไม่มีโครงสร้างควรพิจารณา data lake
พิจารณาว่าธุรกิจของคุณต้องการข้อมูลมากกว่าที่คลังข้อมูลและเทคโนโลยี Data Lake สามารถให้ได้ หรือว่าคุณกำลังค้นหาโซลูชันเพื่อรวมการวิเคราะห์ที่ซับซ้อนและการดำเนินการเรียนรู้ของเครื่องเข้ากับข้อมูลของคุณ อา ดาต้าเลคเฮาส์ เป็นทางเลือกที่เหมาะสมในสถานการณ์





เขียนความเห็น