วิดีโอเกมยังคงสร้างความท้าทายให้กับผู้เล่นหลายพันล้านคนทั่วโลก คุณอาจยังไม่รู้ แต่อัลกอริธึมการเรียนรู้ของเครื่องก็เริ่มท้าทายเช่นกัน
ขณะนี้มีการวิจัยจำนวนมากในด้าน AI เพื่อดูว่าสามารถใช้วิธีการเรียนรู้ของเครื่องกับวิดีโอเกมได้หรือไม่ ความก้าวหน้าอย่างมากในด้านนี้แสดงให้เห็นว่า เรียนรู้เครื่อง ตัวแทนสามารถใช้เพื่อเลียนแบบหรือแทนที่ผู้เล่นที่เป็นมนุษย์
สิ่งนี้หมายความว่าอย่างไรสำหรับอนาคตของ วิดีโอเกม?
โครงการเหล่านี้ทำขึ้นเพื่อความสนุกสนานหรือมีเหตุผลที่ลึกซึ้งกว่านั้นว่าทำไมนักวิจัยจำนวนมากจึงมุ่งความสนใจไปที่เกม
บทความนี้จะกล่าวถึงประวัติของ AI ในวิดีโอเกมโดยสังเขป หลังจากนั้น เราจะให้ภาพรวมสั้นๆ เกี่ยวกับเทคนิคการเรียนรู้ของเครื่องที่เราสามารถใช้เรียนรู้วิธีเอาชนะเกมได้ จากนั้นเราจะดูการใช้งานที่ประสบความสำเร็จของ ตาข่ายประสาท เพื่อเรียนรู้และเชี่ยวชาญวิดีโอเกมเฉพาะ
ประวัติโดยย่อของ AI ในการเล่นเกม
ก่อนที่เราจะพูดถึงสาเหตุที่โครงข่ายประสาทกลายเป็นอัลกอริธึมในอุดมคติในการแก้ปัญหาวิดีโอเกม มาดูสั้น ๆ ว่านักวิทยาศาสตร์คอมพิวเตอร์ใช้วิดีโอเกมเพื่อพัฒนางานวิจัยด้าน AI ได้อย่างไร
คุณสามารถโต้แย้งได้ว่าตั้งแต่เริ่มก่อตั้ง วิดีโอเกมเป็นงานวิจัยที่น่าสนใจสำหรับนักวิจัยที่สนใจ AI
แม้ว่าจะไม่ได้มาจากวิดีโอเกม แต่หมากรุกก็เป็นจุดสนใจอย่างมากในช่วงแรกๆ ของ AI ในปี 1951 ดร. ดีทริช พรินซ์เขียนโปรแกรมเล่นหมากรุกโดยใช้คอมพิวเตอร์ดิจิตอล Ferranti Mark 1 นี่เป็นวิธีที่ย้อนกลับไปในยุคที่คอมพิวเตอร์ขนาดใหญ่เหล่านี้ต้องอ่านโปรแกรมจากเทปกระดาษ

ตัวโปรแกรมเองไม่ใช่ AI หมากรุกที่สมบูรณ์ เนื่องจากข้อจำกัดของคอมพิวเตอร์ Prinz สามารถสร้างโปรแกรมที่แก้ปัญหาหมากรุกแบบคู่ในสองเท่านั้น โดยเฉลี่ยแล้ว โปรแกรมใช้เวลา 15-20 นาทีในการคำนวณทุกการเคลื่อนไหวที่เป็นไปได้สำหรับผู้เล่นผิวขาวและผิวดำ
การพัฒนาหมากรุกและหมากฮอส AI ได้รับการปรับปรุงอย่างต่อเนื่องตลอดหลายทศวรรษที่ผ่านมา ความคืบหน้ามาถึงจุดสูงสุดในปี 1997 เมื่อ Deep Blue ของ IBM เอาชนะ Garry Kasparov ปรมาจารย์หมากรุกชาวรัสเซียในการแข่งขันหกเกม ทุกวันนี้ เครื่องมือหมากรุกที่คุณพบบนโทรศัพท์มือถือของคุณสามารถเอาชนะ Deep Blue ได้
ฝ่ายตรงข้าม AI เริ่มได้รับความนิยมในช่วงยุคทองของวิดีโอเกมอาร์เคด Space Invaders ในปี 1978 และ Pac-Man ในปี 1980 เป็นผู้บุกเบิกอุตสาหกรรมในการสร้าง AI ที่สามารถท้าทายผู้เล่นเกมอาร์เคดที่มากประสบการณ์ได้
โดยเฉพาะอย่างยิ่ง Pac-Man เป็นเกมยอดนิยมสำหรับนักวิจัย AI ที่จะทดลอง หลากหลาย การแข่งขัน สำหรับ Ms. Pac-Man ได้รับการจัดระเบียบเพื่อกำหนดว่าทีมใดสามารถคิด AI ที่ดีที่สุดเพื่อเอาชนะเกมได้
AI ของเกมและอัลกอริธึมฮิวริสติกยังคงพัฒนาต่อไปเนื่องจากความต้องการคู่ต่อสู้ที่ฉลาดขึ้นได้เกิดขึ้น ตัวอย่างเช่น Combat AI ได้รับความนิยมเพิ่มขึ้นเนื่องจากประเภทเช่นเกมยิงมุมมองบุคคลที่หนึ่งกลายเป็นกระแสหลักมากขึ้น
การเรียนรู้ของเครื่องในวิดีโอเกม
เนื่องจากเทคนิคแมชชีนเลิร์นนิงได้รับความนิยมอย่างรวดเร็ว โครงการวิจัยต่างๆ จึงพยายามใช้เทคนิคใหม่เหล่านี้ในการเล่นวิดีโอเกม
เกมเช่น Dota 2, StarCraft และ Doom สามารถทำหน้าที่เป็นปัญหาสำหรับสิ่งเหล่านี้ อัลกอริทึมการเรียนรู้ของเครื่อง เพื่อแก้ปัญหา อัลกอริธึมการเรียนรู้เชิงลึกโดยเฉพาะอย่างยิ่งสามารถบรรลุและเหนือกว่าประสิทธิภาพระดับมนุษย์ด้วยซ้ำ
พื้นที่ สภาพแวดล้อมการเรียนรู้อาเขต หรือ ALE ให้อินเทอร์เฟซแก่นักวิจัยสำหรับเกม Atari 2600 กว่าร้อยเกม แพลตฟอร์มโอเพ่นซอร์สช่วยให้นักวิจัยเปรียบเทียบประสิทธิภาพของเทคนิคการเรียนรู้ของเครื่องในวิดีโอเกม Atari แบบคลาสสิก Google ยังเผยแพร่ของตัวเอง กระดาษ ใช้เจ็ดเกมจาก ALE

ในขณะเดียวกันโครงการเช่น วิซดูม เปิดโอกาสให้นักวิจัย AI ฝึกอัลกอริธึมการเรียนรู้ของเครื่องเพื่อเล่นเกมยิงมุมมองบุคคลที่ 3 แบบ XNUMX มิติ

มันทำงานอย่างไร: แนวคิดหลักบางประการ
โครงข่ายประสาทเทียม
วิธีการส่วนใหญ่ในการแก้ปัญหาวิดีโอเกมด้วยการเรียนรู้ของเครื่องเกี่ยวข้องกับอัลกอริทึมประเภทหนึ่งที่เรียกว่าโครงข่ายประสาทเทียม
คุณสามารถคิดว่าโครงข่ายประสาทเป็นโปรแกรมที่พยายามเลียนแบบการทำงานของสมอง คล้ายกับที่สมองของเราประกอบด้วยเซลล์ประสาทที่ส่งสัญญาณ โครงข่ายประสาทก็มีเซลล์ประสาทเทียมด้วย
เซลล์ประสาทเทียมเหล่านี้ยังส่งสัญญาณถึงกัน โดยแต่ละสัญญาณเป็นตัวเลขจริง โครงข่ายประสาทประกอบด้วยหลายชั้นระหว่างชั้นอินพุตและเอาต์พุต เรียกว่าโครงข่ายประสาทลึก
เสริมการเรียนรู้
เทคนิคแมชชีนเลิร์นนิงทั่วไปที่เกี่ยวข้องกับการเรียนรู้วิดีโอเกมคือแนวคิดของการเรียนรู้แบบเสริมกำลัง
เทคนิคนี้เป็นขั้นตอนการฝึกอบรมตัวแทนโดยใช้รางวัลหรือการลงโทษ ด้วยวิธีการนี้ เอเจนต์ควรจะสามารถคิดหาทางแก้ไขปัญหาผ่านการลองผิดลองถูก
สมมติว่าเราต้องการให้ AI ค้นหาวิธีเล่นเกม Snake วัตถุประสงค์ของเกมนั้นเรียบง่าย: รับคะแนนให้ได้มากที่สุดโดยการบริโภคไอเท็มและหลีกเลี่ยงหางที่โตขึ้น
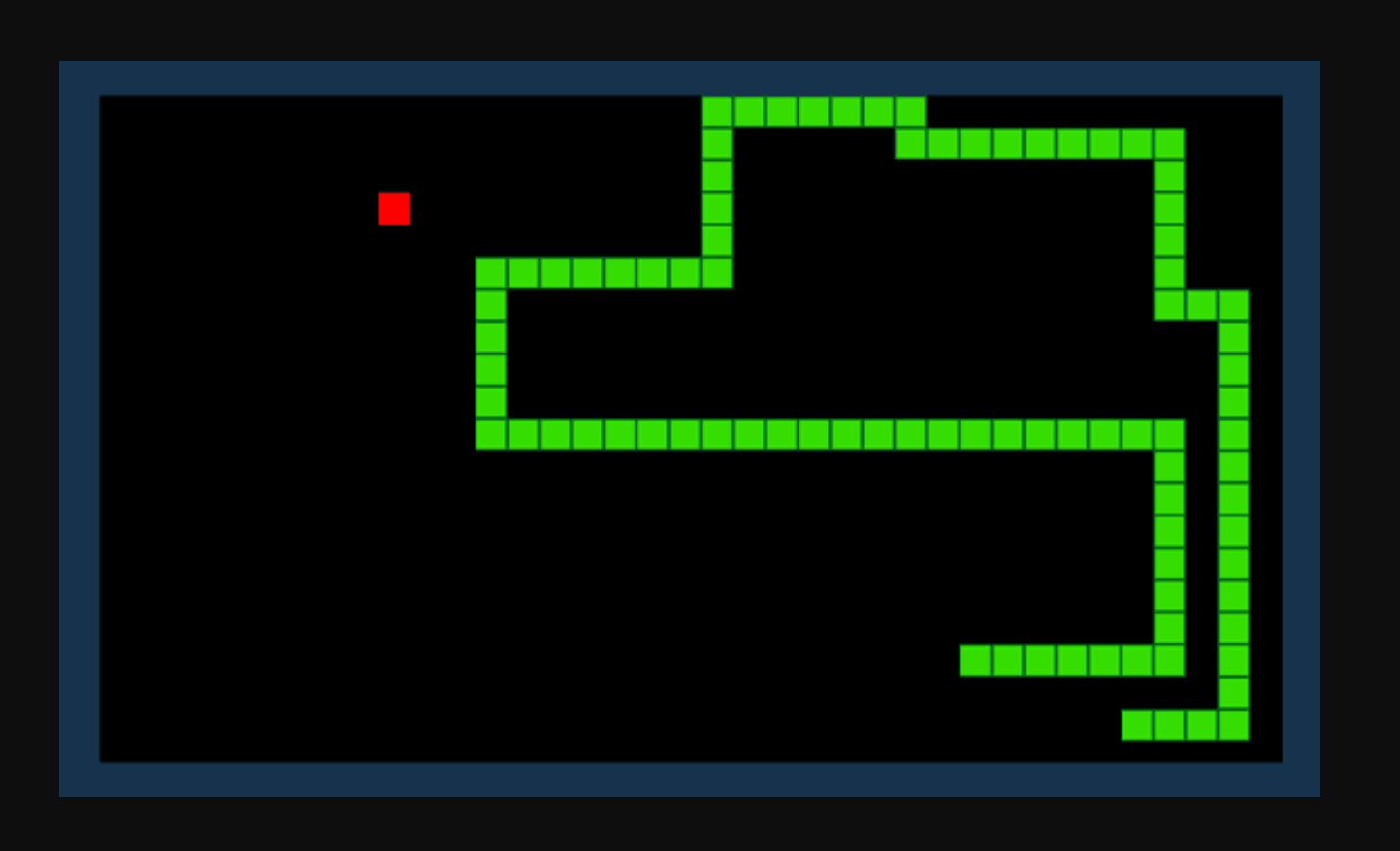
ด้วยการเรียนรู้การเสริมแรง เราสามารถกำหนดฟังก์ชั่นการให้รางวัล R ได้ ฟังก์ชั่นนี้จะเพิ่มคะแนนเมื่องูกินไอเท็มและหักคะแนนเมื่องูชนสิ่งกีดขวาง ด้วยสภาพแวดล้อมปัจจุบันและชุดของการกระทำที่เป็นไปได้ โมเดลการเรียนรู้แบบเสริมกำลังของเราจะพยายามคำนวณ 'นโยบาย' ที่เหมาะสมที่สุดที่จะเพิ่มฟังก์ชันการให้รางวัลของเรา
วิวัฒนาการทางระบบประสาท
นักวิจัยยังพบความสำเร็จในการใช้ ML กับวิดีโอเกมโดยใช้เทคนิคที่เรียกว่าวิวัฒนาการทางระบบประสาทโดยยึดธีมที่ได้รับแรงบันดาลใจจากธรรมชาติ
แทนที่จะใช้ การไล่ระดับสี ในการอัปเดตเซลล์ประสาทในเครือข่าย เราสามารถใช้อัลกอริธึมวิวัฒนาการเพื่อให้ได้ผลลัพธ์ที่ดีขึ้น
อัลกอริธึมวิวัฒนาการมักเริ่มต้นด้วยการสร้างประชากรเริ่มต้นของบุคคลแบบสุ่ม จากนั้นเราจะประเมินบุคคลเหล่านี้โดยใช้เกณฑ์บางอย่าง บุคคลที่ดีที่สุดจะถูกเลือกให้เป็น “พ่อแม่” และได้รับการอบรมร่วมกันเพื่อสร้างคนรุ่นใหม่ บุคคลเหล่านี้จะเข้ามาแทนที่บุคคลที่มีคุณสมบัติน้อยที่สุดในประชากร
อัลกอริธึมเหล่านี้มักจะแนะนำรูปแบบของการดำเนินการกลายพันธุ์ระหว่างครอสโอเวอร์หรือขั้นตอน "การผสมพันธุ์" เพื่อรักษาความหลากหลายทางพันธุกรรม
ตัวอย่างงานวิจัยเกี่ยวกับแมชชีนเลิร์นนิงในวิดีโอเกม
OpenAI Five

OpenAI Five เป็นโปรแกรมคอมพิวเตอร์โดย OpenAI ที่มีจุดมุ่งหมายเพื่อเล่น DOTA 2 เกมต่อสู้บนมือถือที่มีผู้เล่นหลายคน (MOBA) ยอดนิยม
โปรแกรมใช้ประโยชน์จากเทคนิคการเรียนรู้แบบเสริมกำลังที่มีอยู่ ซึ่งปรับขนาดเพื่อเรียนรู้จากเฟรมหลายล้านเฟรมต่อวินาที ด้วยระบบการฝึกอบรมแบบกระจาย OpenAI สามารถเล่นเกมได้ 180 ปีในแต่ละวัน
หลังจากระยะเวลาการฝึกอบรม OpenAI Five สามารถบรรลุประสิทธิภาพระดับผู้เชี่ยวชาญและแสดงให้เห็นถึงความร่วมมือกับผู้เล่นที่เป็นมนุษย์ ในปี 2019 OpenAI Five สามารถ ความพ่ายแพ้ ผู้เล่น 99.4% ในการแข่งขันสาธารณะ
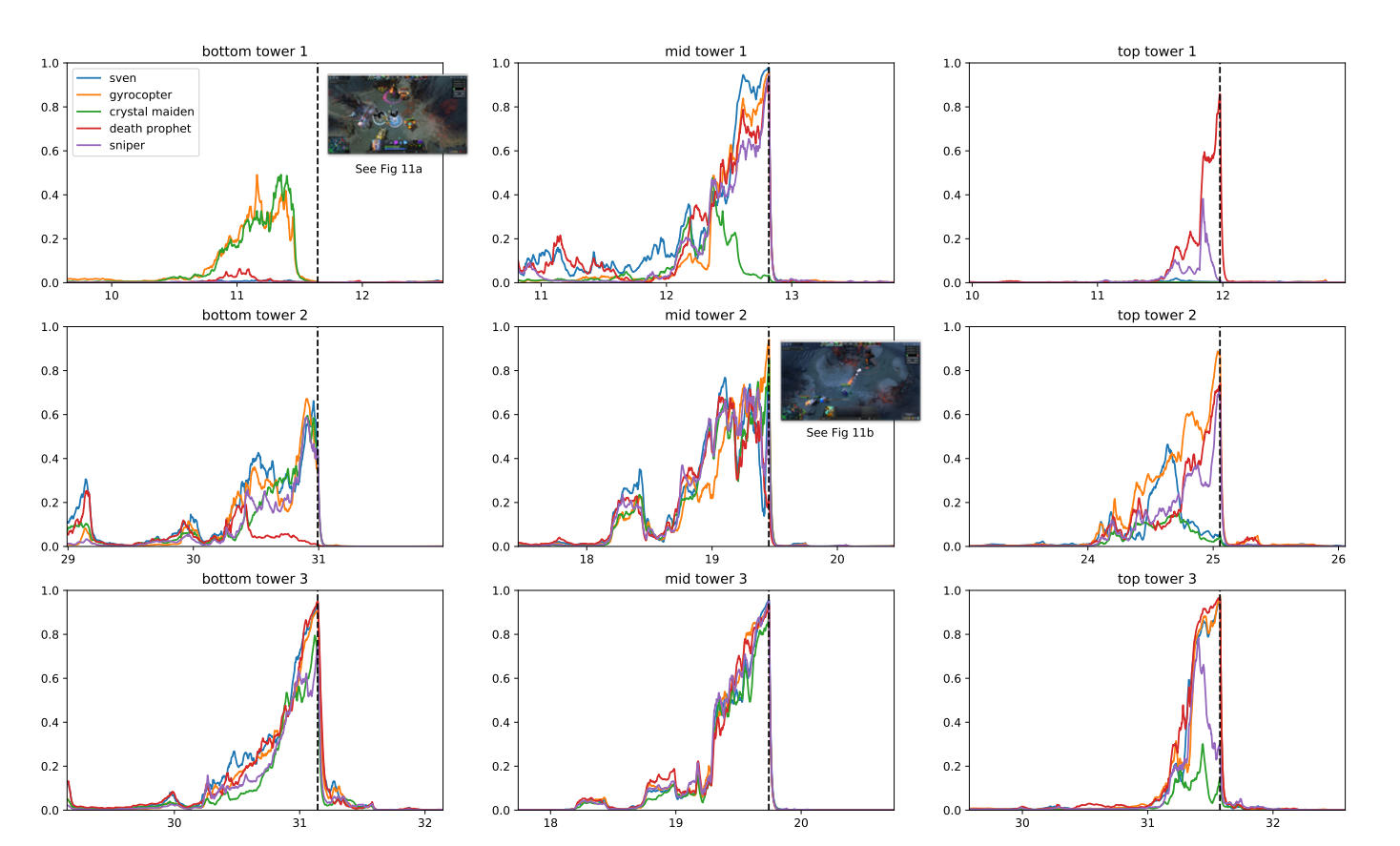
ทำไม OpenAI ถึงตัดสินใจเลือกเกมนี้ ตามที่นักวิจัย DOTA 2 มีกลไกที่ซับซ้อนซึ่งอยู่นอกเหนือขอบเขตของความลึกที่มีอยู่ การเรียนรู้การเสริมแรง อัลกอริทึม
ซูเปอร์มาริโอบราเธอร์ส
แอปพลิเคชั่นที่น่าสนใจอีกอย่างหนึ่งของโครงข่ายประสาทในวิดีโอเกมคือการใช้วิวัฒนาการทางระบบประสาทในการเล่นแพลตฟอร์มเช่น Super Mario Bros.
ตัวอย่างเช่นสิ่งนี้ รายการแฮกกาธอน เริ่มต้นด้วยการไม่มีความรู้เกี่ยวกับเกมและค่อยๆ สร้างรากฐานของสิ่งที่จำเป็นเพื่อความก้าวหน้าผ่านด่านต่างๆ
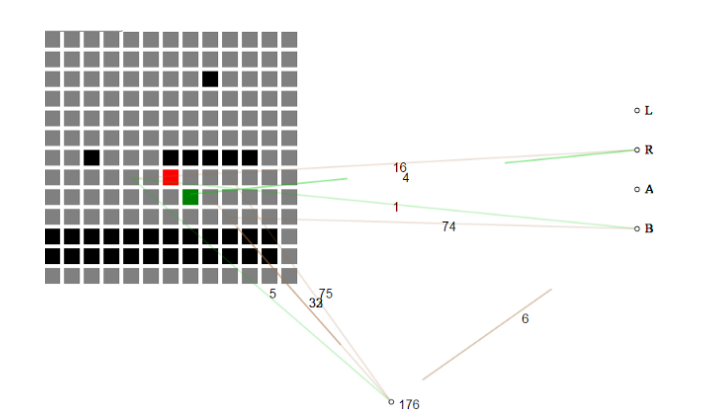
โครงข่ายประสาทที่พัฒนาตัวเองจะอยู่ในสถานะปัจจุบันของเกมเป็นตารางของไทล์ ในตอนแรก โครงข่ายประสาทไม่เข้าใจความหมายของกระเบื้องแต่ละแผ่น มีเพียงแผ่น "อากาศ" เท่านั้นที่แตกต่างจาก "กระเบื้องปูพื้น" และ "กระเบื้องของศัตรู"
การนำนิวโรอีโวลูชันของโปรเจ็กต์ Hackathon ไปใช้นั้นใช้อัลกอริธึมทางพันธุกรรม NEAT เพื่อสร้างโครงข่ายประสาทต่างๆ
ความสำคัญ
ตอนนี้คุณได้เห็นตัวอย่างของโครงข่ายประสาทที่เล่นวิดีโอเกมแล้ว คุณอาจสงสัยว่าประเด็นทั้งหมดนี้คืออะไร
เนื่องจากวิดีโอเกมเกี่ยวข้องกับการโต้ตอบที่ซับซ้อนระหว่างเจ้าหน้าที่และสภาพแวดล้อม จึงเป็นสนามทดสอบที่สมบูรณ์แบบสำหรับการสร้าง AI สภาพแวดล้อมเสมือนจริงนั้นปลอดภัยและควบคุมได้ และให้ข้อมูลที่ไม่สิ้นสุด
การวิจัยในสาขานี้ทำให้นักวิจัยมีความเข้าใจอย่างลึกซึ้งว่าโครงข่ายประสาทสามารถปรับให้เหมาะสมเพื่อเรียนรู้วิธีแก้ปัญหาในโลกแห่งความเป็นจริงได้อย่างไร
โครงข่ายประสาท ได้รับแรงบันดาลใจจากการทำงานของสมองในโลกธรรมชาติ โดยการศึกษาว่าเซลล์ประสาทเทียมมีพฤติกรรมอย่างไรเมื่อเรียนรู้วิธีเล่นวิดีโอเกม เราอาจได้รับข้อมูลเชิงลึกว่า สมองมนุษย์ โรงงาน
สรุป
ความคล้ายคลึงกันระหว่างโครงข่ายประสาทเทียมและสมองได้นำไปสู่ข้อมูลเชิงลึกในทั้งสองสาขา การวิจัยอย่างต่อเนื่องเกี่ยวกับวิธีที่โครงข่ายประสาทสามารถแก้ปัญหาได้ในสักวันหนึ่งอาจนำไปสู่รูปแบบขั้นสูงของ ปัญญาประดิษฐ์.
ลองนึกภาพการใช้ AI ที่ปรับแต่งให้เหมาะกับข้อกำหนดของคุณซึ่งสามารถเล่นวิดีโอเกมทั้งหมดได้ก่อนที่คุณจะซื้อเพื่อแจ้งให้คุณทราบว่าควรค่าแก่เวลาของคุณหรือไม่ บริษัทวิดีโอเกมจะใช้โครงข่ายประสาทเพื่อปรับปรุงการออกแบบเกม ระดับการบิด และความยากของคู่ต่อสู้หรือไม่
คุณคิดว่าจะเกิดอะไรขึ้นเมื่อโครงข่ายประสาทกลายเป็นสุดยอดเกมเมอร์?





เขียนความเห็น