Innehållsförteckning[Dölj][Visa]
Stora text-till-bild-modeller gjorde ett betydande framsteg i utvecklingen av AI genom att producera högkvalitativ och diversifierad bildsyntes från en given textprompt.
Dessa modeller kan inte syntetisera unika representationer av ämnen i olika miljöer eller att replikera utseendet på ämnen i en given referensuppsättning.
Nysläppta teknologier som OpenAI:s DALL.E2 eller StabilityAI:s Stabil diffusion och Midjourney tar redan internet med storm. Det är nu dags att anpassa resultaten. Men hur?
Google DreamBooth AI har anlänt.
DreamBooth har förmågan att känna igen ämnet för en bild, dekonstruera den från dess ursprungliga kontext och sedan exakt syntetisera den till en ny önskad kontext. Dessutom kan den användas med nuvarande AI-bildgeneratorer.
I den här artikeln tar vi en djupgående titt på DreamBooth, dess användning, dess handledning, dess begränsningar och mycket mer.
Vad är Dreambooth?
drömbås, en helt ny modell för spridning av text-till-bild, presenterades av Google. En skriftlig uppmaning kan användas som vägledning av Google DreamBooth AI för att generera ett brett utbud av foton av användarens valda motiv i olika inställningar.
En forskargrupp från Boston University och Google utvecklade DreamBooth, en banbrytande teknik för att ändra text-till-bild-modeller som har genomgått omfattande förträning.
Det övergripande konceptet är ganska okomplicerat: de vill utöka språkvisionsordboken så att ovanliga token-ID:n associeras med anpassade ämnen som användarna kan definiera.
Huvudmålet med modellen är att ansluta användare till text-till-bild spridningsmodell genom att ge dem de resurser de behöver för att producera fotorealistiska representationer av förekomsterna av det valda ämnet.
Som en konsekvens verkar denna teknik fungera bra för att sammanfatta utmaningar i en rad olika situationer.
Googles DreamBooth skiljer sig från tidigare text-till-bild-verktyg, som t.ex DALL-E2, Stabil diffusionoch midjourney, genom att det ger användarna mer kontroll över ämnesbilden innan de låter dem manipulera spridningsmodellen med hjälp av textbaserade indata.
Funktioner
- DreamBooth AI kan förbättra en text-till-bild-modell med 3-5 bilder.
- Original fotorealistiska bilder kan skapas med DreamBooth AI.
- Dessutom kan DreamBooth AI skapa foton av ett ämne från flera vinklar.
Ansökan
Konstframställningar
Denna uppgift skiljer sig specifikt från stilöverföring, som behåller källscenens semantik samtidigt som stilen för en annan bild införlivas i originalscenen.

Baserat på det kreativa tillvägagångssättet kan AI:n utföra betydande scenförändringar samtidigt som identifieringen och ämnesförekomsten bibehålls.
Fastighetsändring
Ämnesinstansens egenskaper kan modifieras av DreamBooth AI.

Tillbehör
Den starka kompositionen före generationsmodellen är det som gör DreamBooth AI:s förmåga att pryda föremål så intressant.

Rekontextualisering
DreamBooth AI kan producera distinkta bilder för en viss ämnesinstans genom att ge en tränad modell en mening som innehåller den unika identifieraren och klassens substantiv.

Det kan generera motivet i unika, tidigare oerhörda ställningar, artikulationer och scenstruktur snarare än att förändra omgivningen. Realistiska reflektioner och skuggor, samt interaktioner mellan motivet och omgivande objekt.
Handledning för Dreambooth
I den här handledningen kommer vi att följa Google Collab-anteckningsbok, och jag kommer att leda dig genom det, vilket kommer att få dig att förstå och använda det på egen hand.
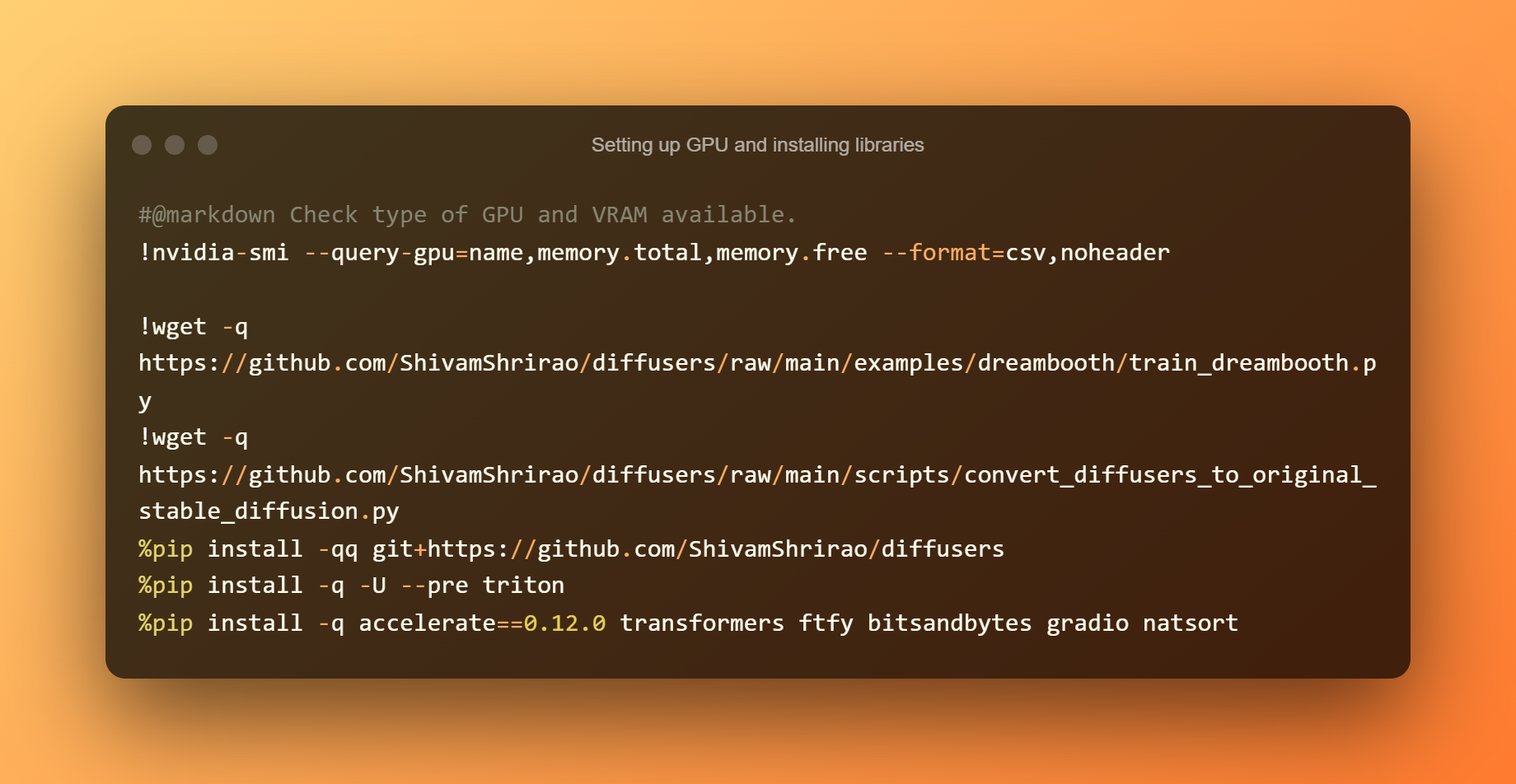
Konfigurera GPU och installera bibliotek
Att ta reda på vilka GPU- och VRAM-typer som finns tillgängliga är det första steget. Det är också nödvändigt att installera några krav och beroenden. Tryck bara på uppspelningsknappen och vänta sedan tills det är klart.
Skapa ett konto på Huggingface och generera en token
Nästa steg är att registrera dig för ett Huggingface-konto. När du är klar klickar du på inställningar i det övre högra hörnet. Du kommer till nästa sida.
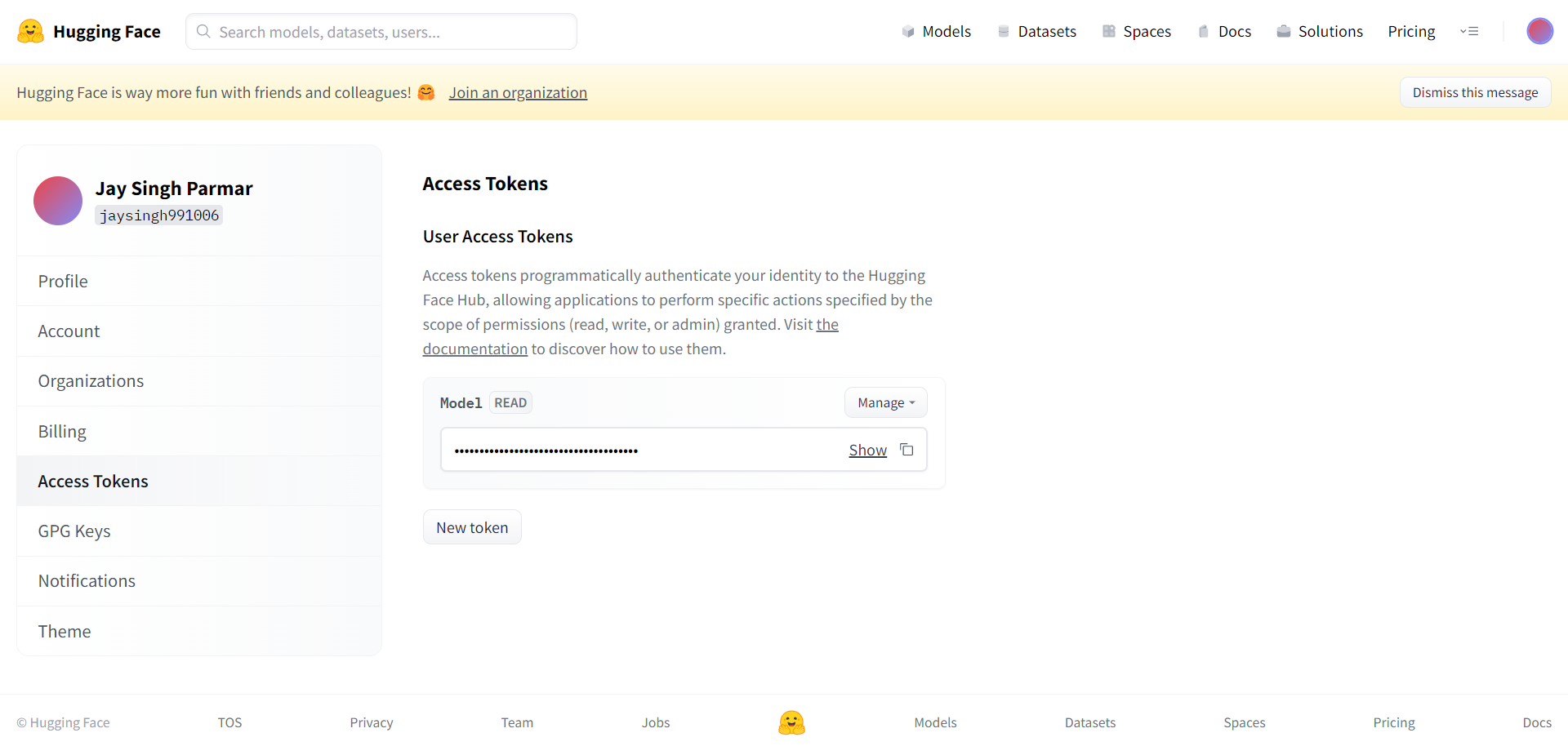
Skapa token och namn enligt begäran härifrån. Token ska kopieras och klistras in i Google Collab i cellen nedan.

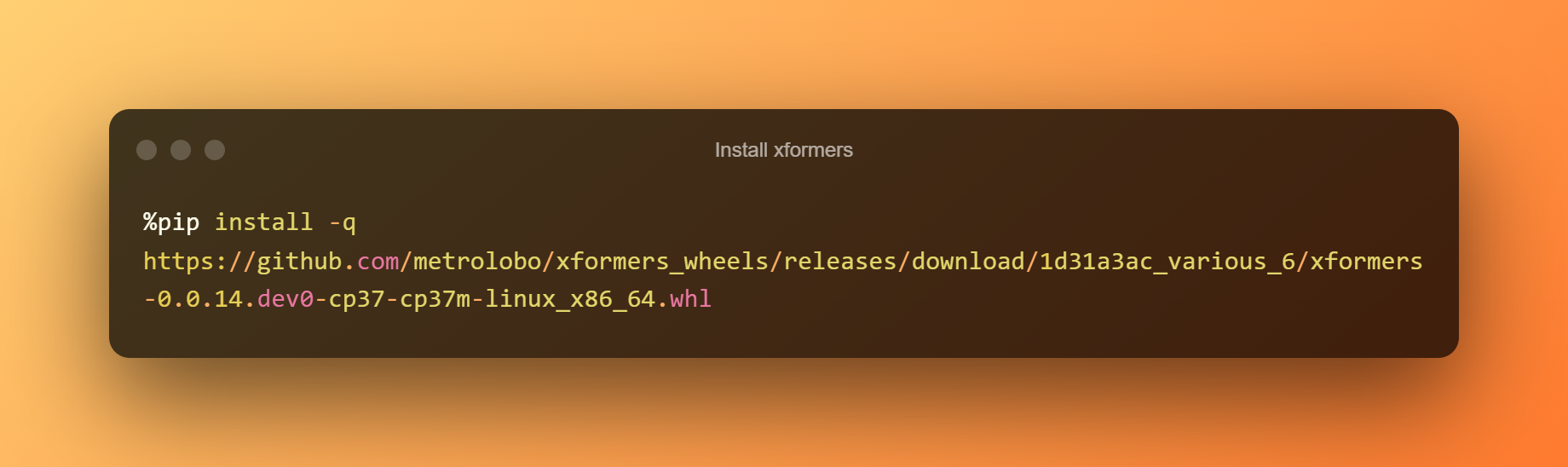
Installera xformers
I det här skedet kan du helt enkelt trycka på play-knappen för att installera xformers genom att klicka på runtime.
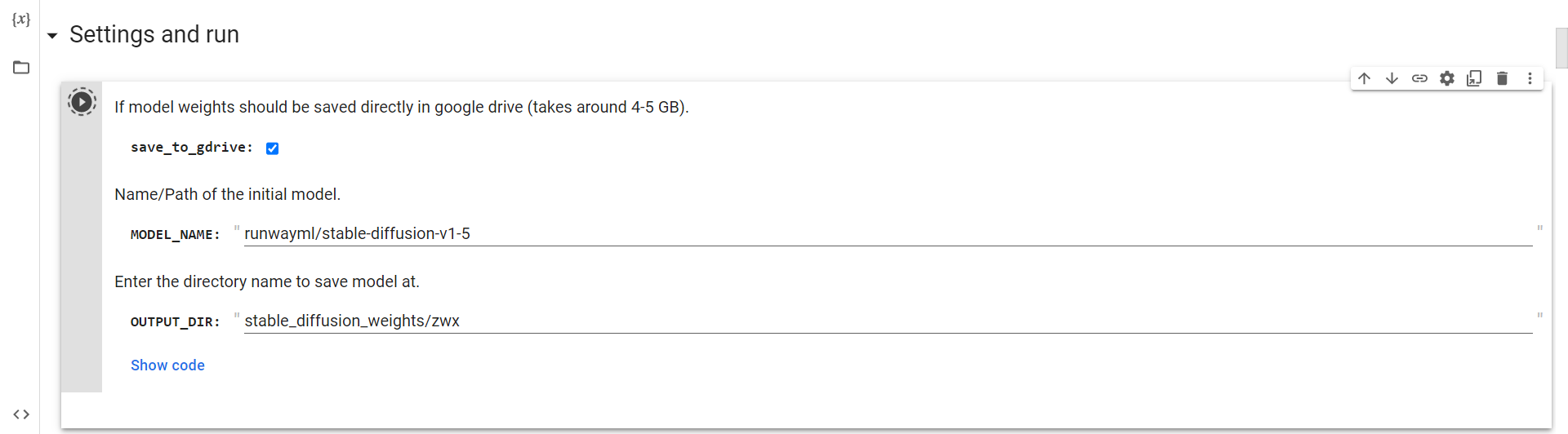
Anslut till Drive
Nu behöver du bara köra den här cellen för att ansluta till Google Drive.
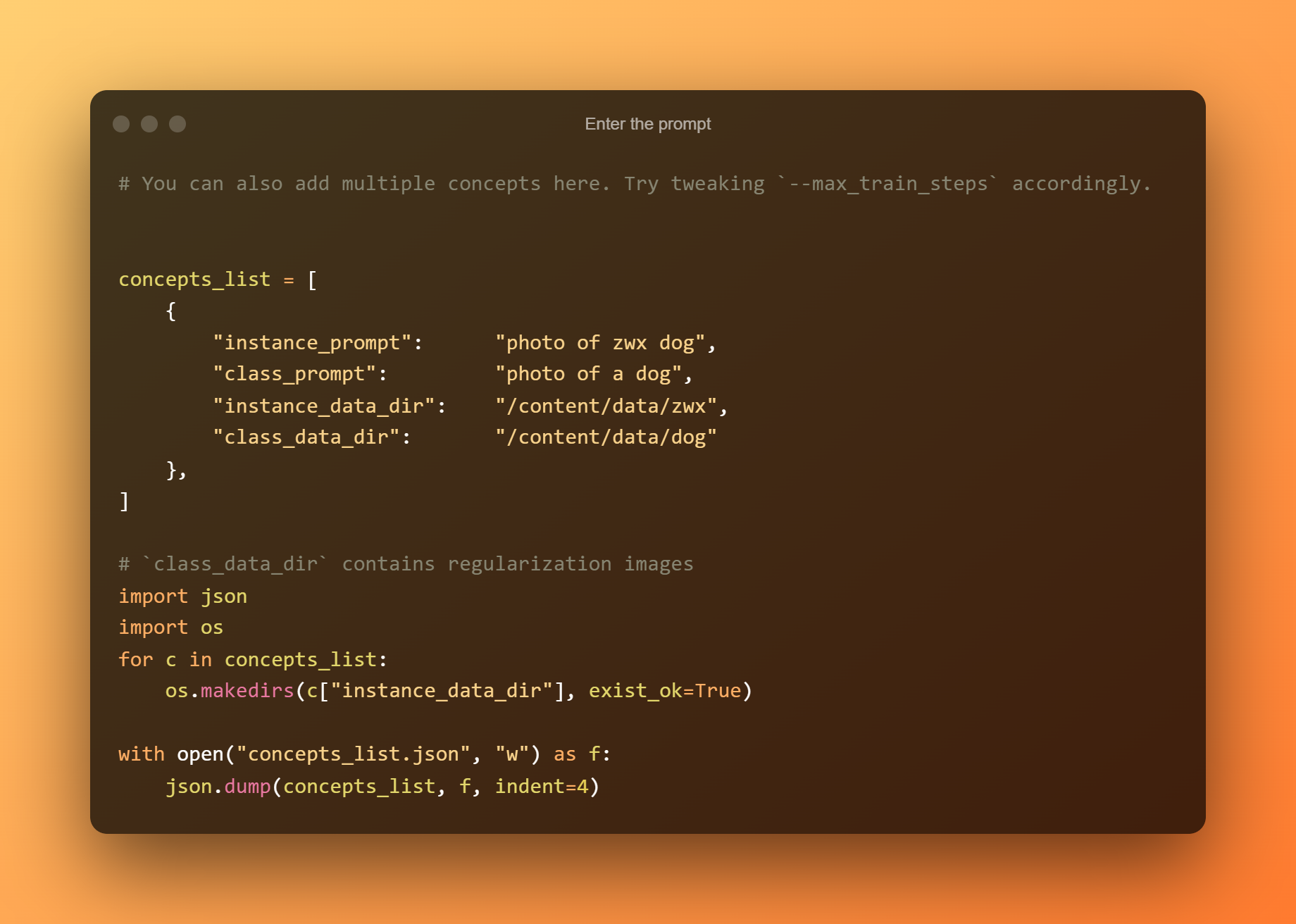
Ange prompten
I följande cell behöver du bara ange prompten.
Laddar upp bilder
I det här steget behöver du bara ladda upp bilderna du ville träna.

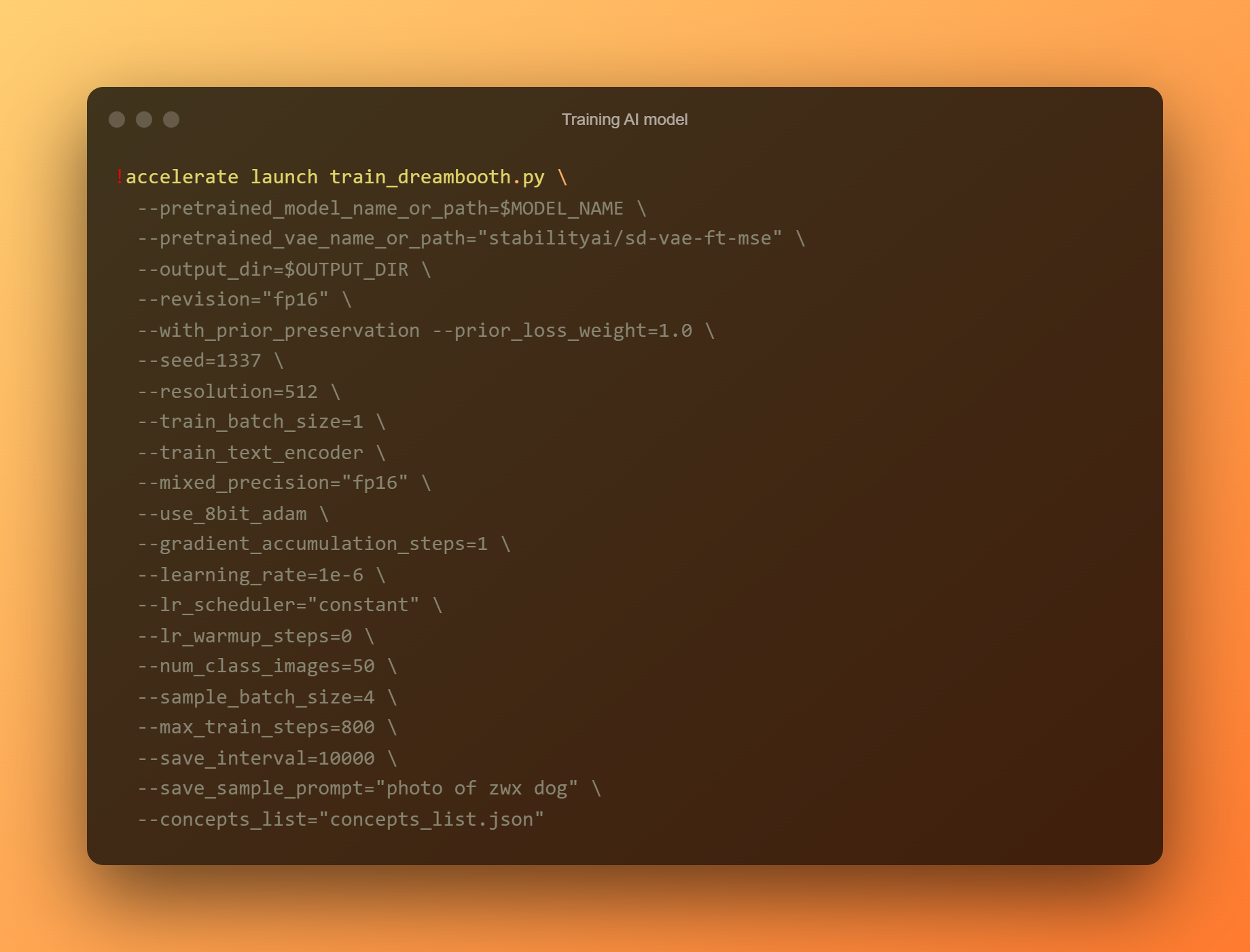
Träna AI-modell
Detta är den viktigaste fasen, eftersom du kommer att använda DreamBooth för att träna en ny AI-modell baserat på alla dina inskickade referensbilder. Du måste begränsa din uppmärksamhet till två inmatningsfält. "—instansprompt" är den första parametern. Du måste ange ett mycket distinkt namn här.
Argumentet '–concept list' är det andra kritiska inmatningsfältet. Den måste bytas om för att matcha den som används i avsnittet "Ändra uppmaningen".
Generera AI-bilder
AI-bilderna kommer att skapas i detta skede, där du kan mata in textinstruktionerna.

Dreambooths begränsningar
- Kommandotolken blir ett hinder för att göra iterationer i ämnet med höga detaljer. DreamBooth kan ändra ämnets kontext, men om modellen vill byta ämnet själv finns det problem med ramen.
- Ett annat problem är att överanpassa utdatabilden till ingångsbilden. Om det inte finns tillräckligt med bilder kan ämnet inte beaktas eller blandas med sammanhanget för de inskickade bilderna. När ett sammanhang för en udda generation frågas sker samma sak.
Slutsats
För att producera utdata från en enda textinmatning kräver huvuddelen av text-till-bild-modeller miljontals parametrar och bibliotek.
DreamBooth förenklar innehållsinhämtning och användning för konsumenter genom att bara kräva inmatning av tre till fem ämnesfotografier tillsammans med en textbakgrund.





Kommentera uppropet