АИ је свуда, али понекад може бити изазовно разумети терминологију и жаргон. У овом посту на блогу објашњавамо преко 50 термина и дефиниција вештачке интелигенције како бисте имали више смисла за ову технологију која се брзо развија.
Било да сте почетник или стручњак, кладимо се да овде постоји неколико појмова које не знате!
КСНУМКС. Вештачка интелигенција
Вештачка интелигенција (АИ) се односи на развој компјутерских система који имају способност да уче и функционишу независно, често опонашајући људску интелигенцију.
Ови системи анализирају податке, препознају обрасце, доносе одлуке и прилагођавају своје понашање на основу искуства. Користећи алгоритме и моделе, АИ има за циљ да створи интелигентне машине способне да перципирају и разумеју своју околину.
Крајњи циљ је омогућити машинама да ефикасно обављају задатке, уче из података и покажу когнитивне способности сличне људима.
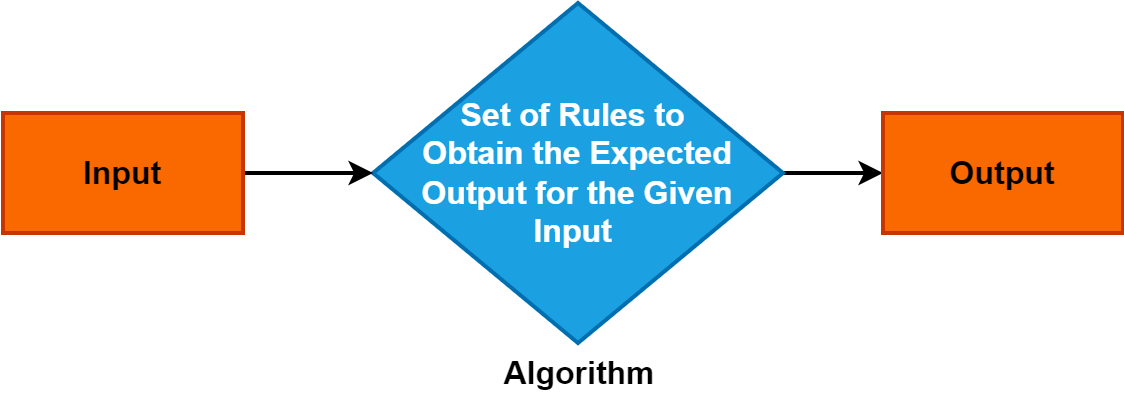
2. Алгоритам
Алгоритам је прецизан и систематичан скуп упутстава или правила која усмеравају процес решавања проблема или остваривања одређеног задатка.
Он служи као фундаментални концепт у различитим доменима и игра кључну улогу у рачунарским наукама, математици и дисциплинама за решавање проблема. Разумевање алгоритама је кључно јер омогућавају ефикасне и структуриране приступе решавању проблема, подстичући напредак у технологији и процесима доношења одлука.
3. Велики подаци
Велики подаци се односе на изузетно велике и сложене скупове података који превазилазе могућности традиционалних метода анализе. Ове скупове података обично карактерише њихов волумен, брзина и разноликост.
Обим се односи на огромну количину података генерисаних из различитих извора као што су друштвени медији, сензори и трансакције.
Брзина се односи на велику брзину којом се подаци генеришу и треба да се обрађују у реалном времену или скоро у реалном времену. Разноликост означава различите типове и формате података, укључујући структуриране, неструктуриране и полуструктуриране податке.
4. Дата Мининг
Дата мининг је свеобухватан процес који има за циљ извлачење вредних увида из огромних скупова података.
Обухвата четири кључне фазе: прикупљање података, укључујући прикупљање релевантних података; припрема података, обезбеђивање квалитета и компатибилности података; рударење података, коришћење алгоритама за откривање образаца и односа; и анализу и интерпретацију података, где се извучено знање испитује и разуме.
5. Неурална мрежа
Рачунарски систем је дизајниран да ради као људски мозак, састављен од међусобно повезаних чворова или неурона. Хајде да разумемо ово мало више јер је већина АИ заснована на неуронске мреже.
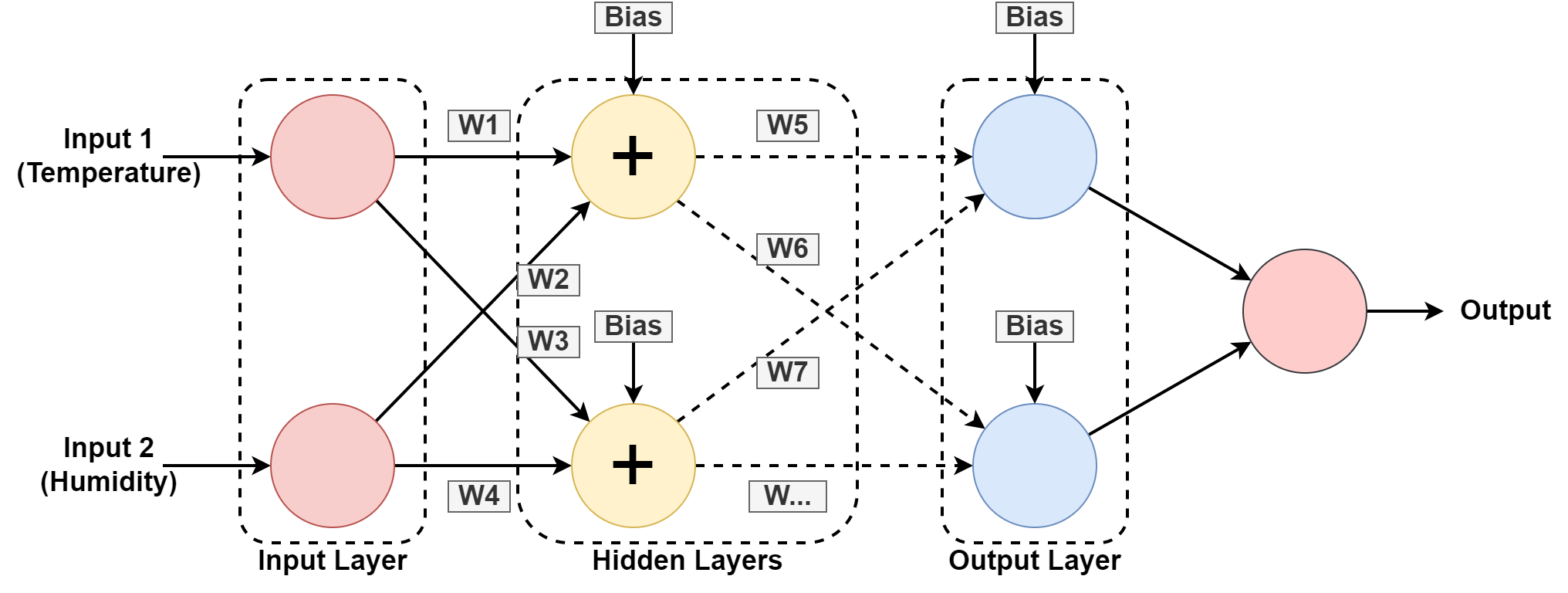
У горњој графики предвиђамо влажност и температуру географске локације учећи из претходног обрасца. Улази су скуп података за прошли запис.
неуронска мрежа учи образац играјући се са тежинама и применом вредности пристрасности у скривеним слојевима. В1, В2….В7 су одговарајуће тежине. Он се тренира на приложеном скупу података и даје излаз као предвиђање.
Можда ћете бити преплављени овим сложеним информацијама. Ако је то случај, можете почети са нашим једноставним водичем ovde.
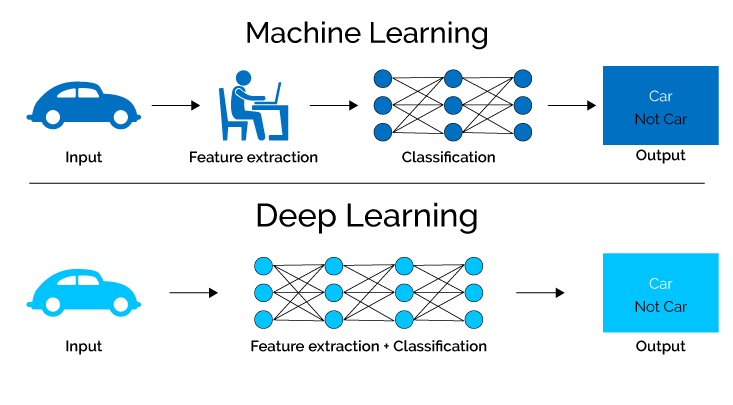
6. Машинско учење
Машинско учење се фокусира на развој алгоритама и модела способних за аутоматско учење из података и побољшање њихових перформанси током времена.
Укључује употребу статистичких техника како би се омогућило рачунарима да идентификују обрасце, праве предвиђања и доносе одлуке засноване на подацима без експлицитног програмирања.
Алгоритми машинског учења анализирају и уче из великих скупова података, омогућавајући системима да се прилагоде и побољшају своје понашање на основу информација које обрађују.
7. Дубоко учење
Дееп леарнинг, подобласт машинског учења и неуронских мрежа, користи софистициране алгоритме за стицање знања из података симулацијом сложених процеса у људском мозгу.
Коришћењем неуронских мрежа са бројним скривеним слојевима, модели дубоког учења могу аутономно издвојити сложене карактеристике и обрасце, омогућавајући им да се баве сложеним задацима са изузетном тачношћу и ефикасношћу.
8. Препознавање образаца
Препознавање образаца, техника анализе података, користи моћ алгоритама машинског учења за аутономно откривање и уочавање образаца и правилности унутар скупова података.
Користећи рачунарске моделе и статистичке методе, алгоритми за препознавање образаца могу идентификовати смислене структуре, корелације и трендове у сложеним и разноврсним подацима.
Овај процес омогућава извлачење вредних увида, класификацију података у различите категорије и предвиђање будућих исхода на основу препознатих образаца. Препознавање образаца је витално средство у различитим доменима, омогућава доношење одлука, откривање аномалија и предиктивно моделирање.
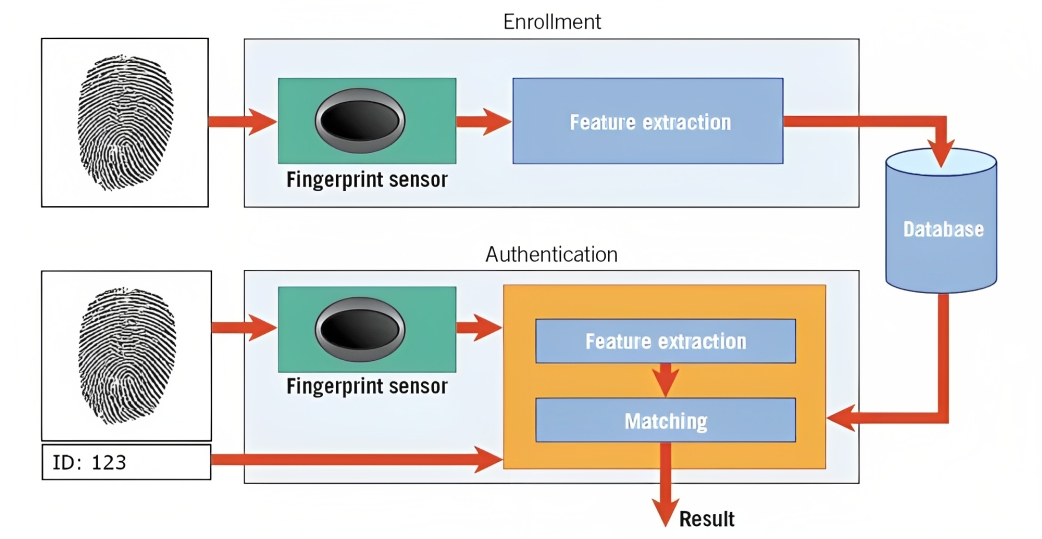
Биометрија је један пример овога. На пример, у препознавању отиска прста, алгоритам анализира избочине, кривине и јединствене карактеристике отиска прста особе да би створио дигитални приказ који се зове шаблон.
Када покушате да откључате свој паметни телефон или приступите безбедном објекту, систем за препознавање образаца упоређује снимљене биометријске податке (нпр. отисак прста) са ускладиштеним шаблонима у својој бази података.
Упоређивањем образаца и проценом нивоа сличности, систем може да утврди да ли се дати биометријски подаци поклапају са сачуваним шаблоном и у складу са тим одобри приступ.
9. Учење под надзором
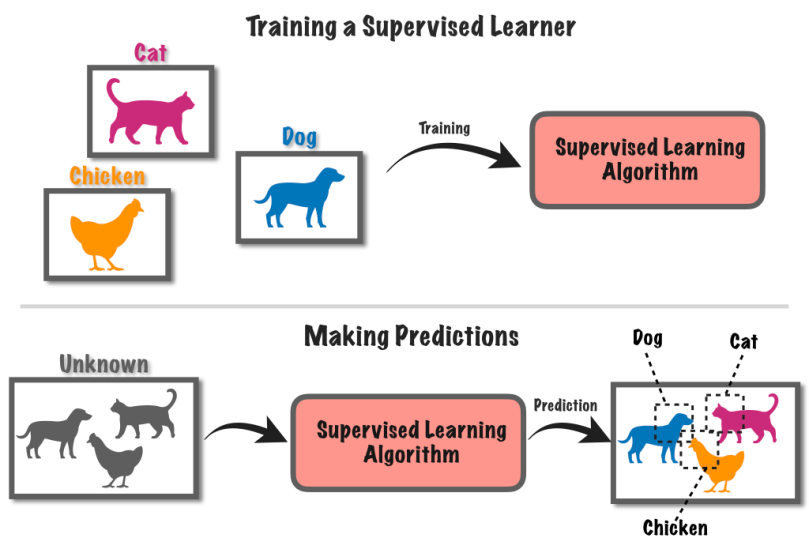
Учење под надзором је приступ машинском учењу који укључује обуку рачунарског система користећи означене податке. У овој методи, рачунар добија скуп улазних података заједно са одговарајућим познатим ознакама или исходима.
Рецимо да имате гомилу слика, неке са псима, а неке са мачкама.
Кажете компјутеру на којим сликама су пси, а на којима мачке. Компјутер затим учи да препозна разлике између паса и мачака проналазећи обрасце на сликама.
Након што научи, можете дати рачунару нове слике, а он ће покушати да открије да ли има псе или мачке на основу онога што је научио из означених примера. То је као да обучавате рачунар да предвиђа предвиђања користећи познате информације.
10. Учење без надзора
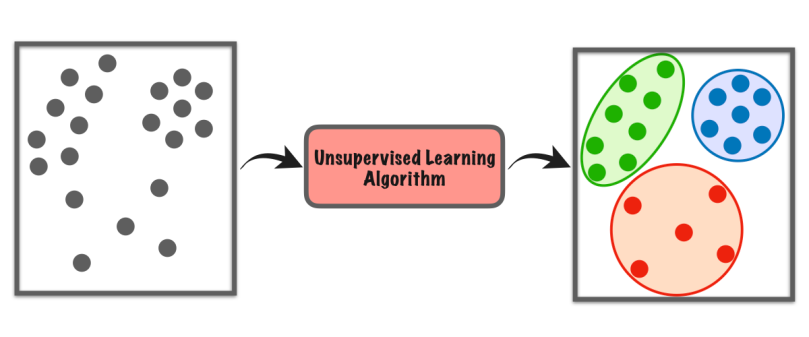
Учење без надзора је врста машинског учења где рачунар сам истражује скуп података како би пронашао обрасце или сличности без икаквих посебних упутстава.
Не ослања се на означене примере као у надгледаном учењу. Уместо тога, тражи скривене структуре или групе у подацима. То је као да рачунар сам открива ствари, а да му учитељ не говори шта да тражи.
Ова врста учења нам помаже да пронађемо нове увиде, организујемо податке или идентификујемо необичне ствари без претходног знања или експлицитног упутства.
11. Обрада природног језика (НЛП)
Обрада природног језика се фокусира на то како рачунари разумеју људски језик и комуницирају са њим. Помаже рачунарима да анализирају, тумаче и реагују на људски језик на начин који нам се чини природнијим.
НЛП је оно што нам омогућава да комуницирамо са гласовним асистентима и цхатботовима, па чак и да наше е-поруке аутоматски сортирају у фасцикле.
То укључује подучавање рачунара да разумеју значење речи, реченица, па чак и читавих текстова, тако да нам могу помоћи у различитим задацима и учинити нашу интеракцију са технологијом лакшом.
12. Компјутерски вид
Цомпутер висион је фасцинантна технологија која омогућава рачунарима да виде и разумеју слике и видео записе, баш као што ми људи радимо очима. Све је у учењу рачунара да анализирају визуелне информације и да дају смисао ономе што виде.
Једноставније речено, компјутерски вид помаже рачунарима да препознају и тумаче визуелни свет. То укључује задатке попут подучавања да идентификују одређене објекте на сликама, класификују слике у различите категорије или чак поделе слике на значајне делове.
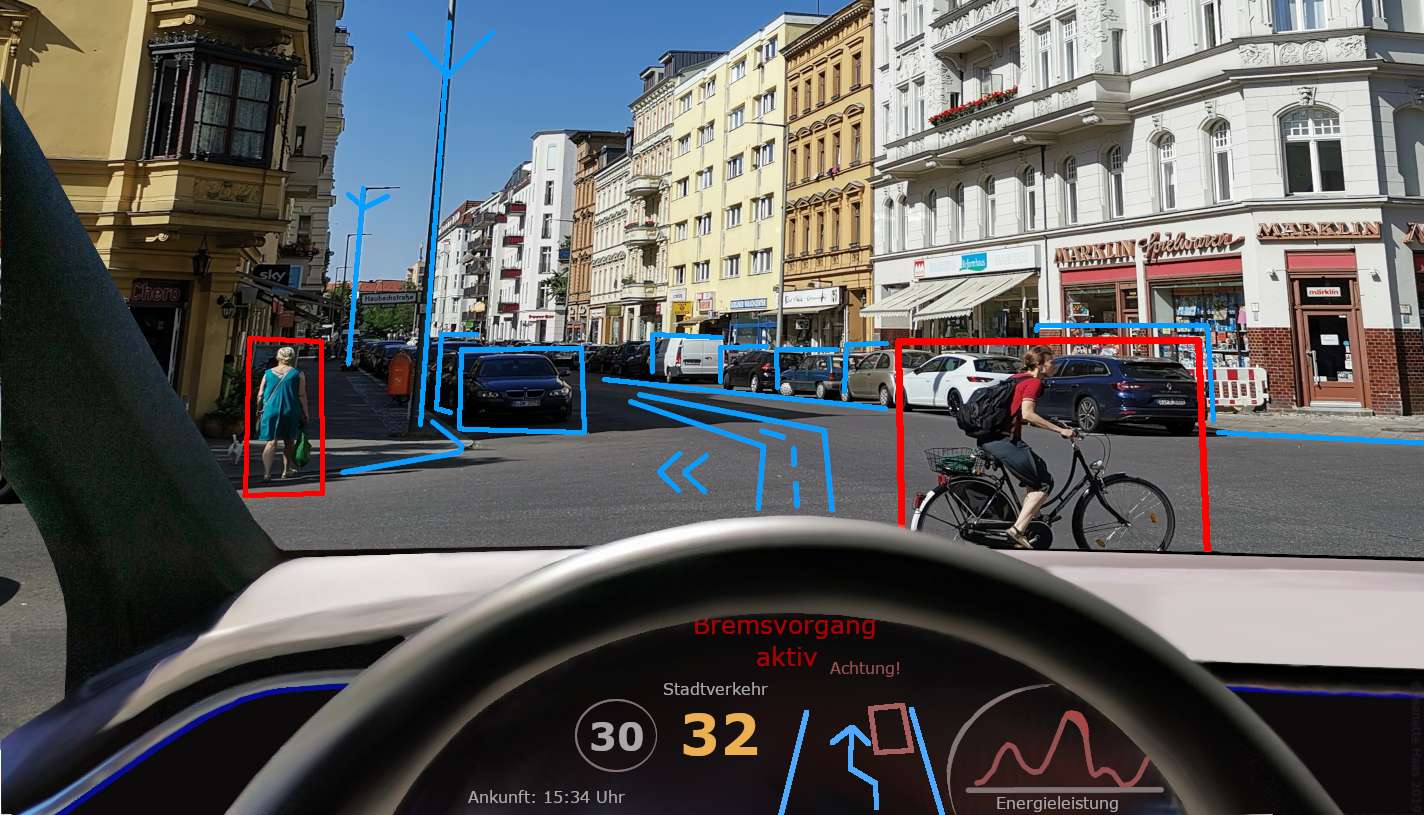
Замислите самовозећи аутомобил који користи компјутерски вид да „види“ пут и све око њега.
Може да открије и прати пешаке, саобраћајне знакове и друга возила, помажући им да се безбедно крећу. Или размислите о томе како технологија препознавања лица користи компјутерски вид за откључавање наших паметних телефона или верификацију наших идентитета препознавањем наших јединствених црта лица.
Такође се користи у системима за надзор за надгледање гужви и уочавање било каквих сумњивих активности.
Компјутерски вид је моћна технологија која отвара свет могућности. Омогућавајући рачунарима да виде и разумеју визуелне информације, можемо да развијемо апликације и системе који могу да перципирају и тумаче свет око нас, чинећи наш живот лакшим, безбеднијим и ефикаснијим.
13. Цхатбот
Цхатбот је попут компјутерског програма који може разговарати са људима на начин који изгледа као прави људски разговор.
Често се користи у онлајн корисничкој служби да би се помогло клијентима и да би се осећали као да разговарају са особом, иако је то заправо програм који ради на рачунару.
Цхатбот може да разуме и одговори на поруке или питања клијената, пружајући корисне информације и помоћ баш као што би то чинио представник корисничке службе.
14. Препознавање гласа
Препознавање гласа се односи на способност компјутерског система да разуме и тумачи људски говор. То укључује технологију која омогућава рачунару или уређају да „слуша“ изговорене речи и конвертује их у текст или команде које може да разуме.
sa препознавање гласа, можете комуницирати са уређајима или апликацијама тако што ћете једноставно разговарати са њима уместо да куцате или користите друге методе уноса.
Систем анализира изговорене речи, препознаје обрасце и звукове, а затим их преводи у разумљив текст или радње. Омогућава природну комуникацију са технологијом без употребе руку, омогућавајући задатке попут гласовних команди, диктата или интеракције контролисане гласом. Најчешћи примери су АИ асистенти као што су Сири и Гоогле Ассистант.
15. Анализа расположења
Анализа сентимента је техника која се користи за разумевање и тумачење емоција, мишљења и ставова изражених у тексту или говору. То укључује анализу писаног или говорног језика како би се утврдило да ли је изражено осећање позитивно, негативно или неутрално.
Користећи алгоритме за машинско учење, алгоритми за анализу осећања могу да скенирају и анализирају велике количине текстуалних података, као што су рецензије купаца, постови на друштвеним мрежама или повратне информације купаца, да би идентификовали основно осећање иза речи.
Алгоритми траже одређене речи, фразе или обрасце који указују на емоције или мишљења.
Ова анализа помаже предузећима или појединцима да разумеју како људи мисле о производу, услузи или теми и може се користити за доношење одлука на основу података или за стицање увида у преференције купаца.
На пример, компанија може да користи анализу расположења да прати задовољство купаца, идентификује области за побољшање или прати јавно мњење о свом бренду.
16. Машинско превођење
Машинско превођење, у контексту вештачке интелигенције, односи се на коришћење компјутерских алгоритама и вештачке интелигенције за аутоматско превођење текста или говора са једног језика на други.
То укључује подучавање рачунара да разумеју и обрађују људске језике како би се обезбедили тачни преводи. Најчешћи пример је Гугл преводилац.
Са машинским превођењем, можете унети текст или говор на једном језику, а систем ће анализирати унос и генерисати одговарајући превод на другом језику. Ово је посебно корисно када комуницирате или приступате информацијама на различитим језицима.
Системи машинског превођења ослањају се на комбинацију лингвистичких правила, статистичких модела и алгоритама машинског учења. Они уче из огромне количине података о језику како би временом побољшали тачност превода. Неки приступи машинског превођења такође укључују неуронске мреже како би побољшали квалитет превода.
17. Роботика
Роботика је комбинација вештачке интелигенције и машинског инжењеринга за стварање интелигентних машина званих роботи. Ови роботи су дизајнирани да обављају задатке аутономно или уз минималну људску интервенцију.
Роботи су физички ентитети који могу да осете своје окружење, доносе одлуке на основу тог сензорног уноса и обављају одређене радње или задатке.
Опремљени су разним сензорима, као што су камере, микрофони или сензори за додир, који им омогућавају да прикупљају информације из света око себе. Уз помоћ АИ алгоритама и програмирања, роботи могу анализирати ове податке, интерпретирати их и доносити интелигентне одлуке како би извршили своје одређене задатке.
АИ игра кључну улогу у роботици омогућавајући роботима да уче из својих искустава и прилагођавају се различитим ситуацијама.
Алгоритми машинског учења могу се користити за обуку робота да препознају објекте, навигацију у окружењу или чак интеракцију са људима. Ово омогућава роботима да постану свестранији, флексибилнији и способнији за руковање сложеним задацима.
КСНУМКС Дронови
Дронови су врста робота који могу да лете или лебде у ваздуху без људског пилота. Они су такође познати као беспилотне летелице (УАВ). Дронови су опремљени разним сензорима, као што су камере, ГПС и жироскопи, који им омогућавају прикупљање података и навигацију у околини.
Њима даљински управља људски оператер или могу да раде аутономно користећи унапред програмирана упутства.
Беспилотне летелице служе за широк спектар намена, укључујући фотографисање из ваздуха и видео снимање, снимање и мапирање, услуге испоруке, мисије потраге и спасавања, праћење пољопривреде, па чак и рекреативну употребу. Они могу приступити удаљеним или опасним подручјима која су тешка или опасна за људе.
19. Проширена стварност (АР)
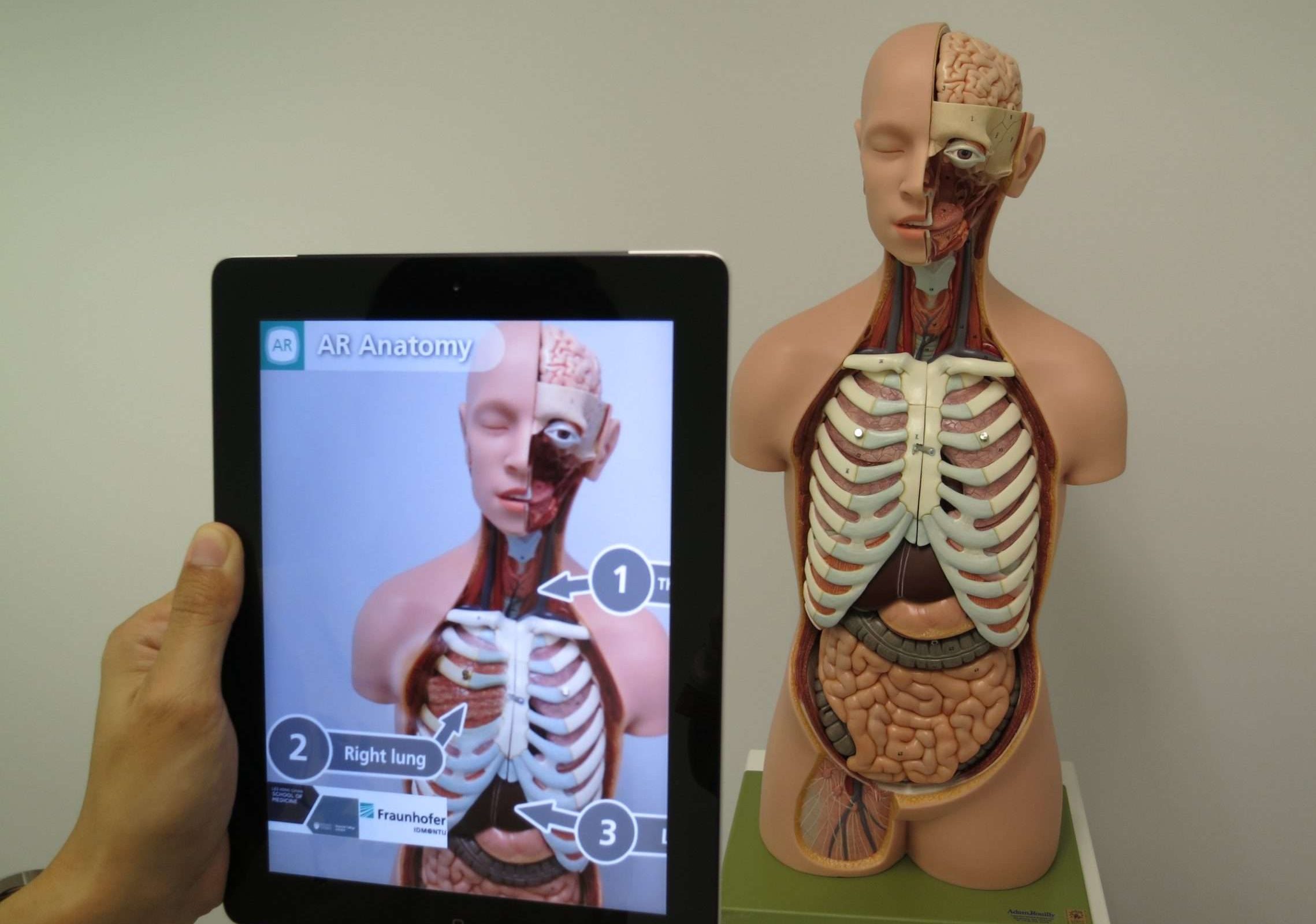
Проширена стварност (АР) је технологија која комбинује стварни свет са виртуелним објектима или информацијама како би побољшала нашу перцепцију и интеракцију са окружењем. Он прекрива компјутерски генерисане слике, звукове или друге сензорне инпуте на стварни свет, стварајући импресивно и интерактивно искуство.
Једноставно, замислите да носите посебне наочаре или користите паметни телефон да видите свет око себе, али са додатним виртуелним елементима.
На пример, можете да усмерите свој паметни телефон ка градској улици и видите виртуелне путоказе који показују упутства, оцене и критике за оближње ресторане или чак виртуелне ликове који комуницирају са стварним окружењем.
Ови виртуелни елементи се неприметно спајају са стварним светом, побољшавајући ваше разумевање и доживљај околине. Проширена стварност се може користити у различитим областима као што су игре, образовање, архитектура, па чак и за свакодневне задатке као што су навигација или испробавање новог намештаја у вашем дому пре куповине.
20. Виртуелна стварност (ВР)
Виртуелна стварност (ВР) је технологија која користи компјутерски генерисане симулације за стварање вештачког окружења које особа може да истражује и да са њим комуницира. Он урања корисника у виртуелни свет, блокирајући стварни свет и замењујући га дигиталним.
Једноставно речено, замислите да ставите специјалне слушалице које покривају ваше очи и уши и преносе вас на потпуно друго место. У овом виртуелном свету, све што видите и чујете делује невероватно стварно, иако је све генерисано рачунаром.
Можете се кретати около, гледати у било ком правцу и комуницирати са објектима или ликовима као да су физички присутни.
На пример, у игри виртуелне реалности, можете се наћи унутар средњовековног замка, где можете да шетате његовим ходницима, узимате оружје и учествујете у борби мачевима са виртуелним противницима. Окружење виртуелне реалности реагује на ваше покрете и радње, чинећи да се осећате потпуно уроњени и укључени у искуство.
Виртуелна стварност се не користи само за играње игара већ и за разне друге апликације као што су симулације обуке за пилоте, хирурге или војно особље, архитектонска упутства, виртуелни туризам, па чак и терапија за одређена психолошка стања. Ствара осећај присуства и преноси кориснике у нове и узбудљиве виртуелне светове, чинећи искуство што ближе стварности.
21. Наука о подацима
Наука о подацима је област која укључује коришћење научних метода, алата и алгоритама за извлачење драгоценог знања и увида из података. Комбинује елементе математике, статистике, програмирања и експертизе у домену за анализу великих и сложених скупова података.
Једноставније речено, наука о подацима је проналажење значајних информација и образаца скривених у гомили података. То укључује прикупљање, чишћење и организовање података, затим коришћење различитих техника за њихово истраживање и анализу. Научници података користе статистичке моделе и алгоритме за откривање трендова, предвиђања и решавање проблема.
На пример, у области здравствене заштите, наука о подацима може да се користи за анализу картона пацијената и медицинских података да би се идентификовали фактори ризика за болести, предвидели исходи пацијената или оптимизовали планови лечења. У пословању, наука о подацима се може применити на податке о клијентима да би се разумеле њихове преференције, препоручили производи или побољшале маркетиншке стратегије.
22. Дата Вранглинг
Разматрање података, такође познато као прикупљање података, је процес прикупљања, чишћења и трансформације необрађених података у формат који је кориснији и погоднији за анализу. То укључује руковање и припрему података како би се осигурао њихов квалитет, доследност и компатибилност са алатима или моделима за анализу.
Једноставније речено, свађање података је као припрема састојака за кување. То укључује прикупљање података из различитих извора, њихово сортирање и чишћење како би се уклониле све грешке, недоследности или небитне информације.
Поред тога, подаци ће можда морати да се трансформишу, реструктурирају или агрегирају да би се олакшало рад са њима и извлачење увида.
На пример, свађање података може укључивати уклањање дуплих уноса, исправљање грешака у писању или форматирању, руковање вредностима које недостају и претварање типова података. То такође може укључивати спајање или спајање различитих скупова података заједно, раздвајање података у подскупове или креирање нових променљивих на основу постојећих података.
23. Дата Сторителлинг
Приповедање података је уметност представљања података на убедљив и привлачан начин за ефикасно преношење нарације или поруке. То укључује коришћење визуелизације података, нарације и контекст како би пренели увиде и налазе на начин који је разумљив и за памћење публици.
Једноставније речено, приповедање података је коришћење података за причање приче. То иде даље од само представљања бројева и графикона. То укључује прављење нарације око података, коришћење визуелних елемената и техника приповедања како би се подаци оживјели и учинили их повезаним са публиком.
На пример, уместо једноставног представљања табеле са подацима о продаји, приповедање података може укључивати креирање интерактивне контролне табле која омогућава корисницима да визуелно истраже трендове продаје.
Може укључивати наратив који истиче кључне налазе, објашњава разлоге иза трендова и предлаже препоруке које се могу предузети на основу података.
24. Доношење одлука на основу података
Доношење одлука засновано на подацима је процес доношења избора или предузимања радњи на основу анализе и интерпретације релевантних података. То укључује коришћење података као основе за вођење и подршку процеса доношења одлука, а не ослањање искључиво на интуицију или личну процену.
Једноставније речено, доношење одлука засновано на подацима значи коришћење чињеница и доказа из података за информисање и вођење избора које доносимо. То укључује прикупљање и анализу података да би се разумели обрасци, трендови и односи и коришћење тог знања за доношење информисаних одлука и решавање проблема.
На пример, у пословном окружењу, доношење одлука засновано на подацима може укључивати анализу података о продаји, повратних информација купаца и тржишних трендова како би се одредила најефикаснија стратегија одређивања цена или идентификовала подручја за побољшање у развоју производа.
У здравству, то може укључивати анализу података о пацијентима ради оптимизације планова лечења или предвиђања исхода болести.
25. Дата Лаке
Језеро података је централизовано и скалабилно складиште података које чува огромне количине података у сировом и необрађеном облику. Дизајниран је да садржи широк спектар типова података, формата и структура, као што су структурирани, полуструктурирани и неструктурирани подаци, без потребе за унапред дефинисаним шемама или трансформацијама података.
На пример, компанија може да прикупља и складишти податке из различитих извора, као што су евиденције веб локација, трансакције клијената, фидови друштвених медија и ИоТ уређаји, у језеру података.
Ови подаци се затим могу користити у различите сврхе, као што је спровођење напредне аналитике, извођење алгоритама машинског учења или истраживање образаца и трендова у понашању купаца.
26. Складиште података
Складиште података је специјализовани систем базе података који је посебно дизајниран за складиштење, организовање и анализу великих количина података из различитих извора. Структуриран је на начин који подржава ефикасно проналажење података и сложене аналитичке упите.
Служи као централно спремиште које интегрише податке из различитих оперативних система, као што су трансакцијске базе података, ЦРМ системи и други извори података унутар организације.
Подаци се трансформишу, чисте и учитавају у складиште података у структурираном формату оптимизованом за аналитичке сврхе.
27. Пословна интелигенција (БИ)
Пословна интелигенција се односи на процес прикупљања, анализе и презентовања података на начин који помаже предузећима да доносе одлуке на основу информација и стекну вредне увиде. То укључује коришћење различитих алата, технологија и техника за трансформацију необрађених података у смислене, корисне информације.
На пример, систем пословне интелигенције може да анализира податке о продаји како би идентификовао најпрофитабилније производе, прати нивое залиха и прати жеље купаца.
Може да пружи увид у реалном времену у кључне индикаторе учинка (КПИ) као што су приход, стицање купаца или учинак производа, омогућавајући предузећима да доносе одлуке засноване на подацима и предузму одговарајуће радње да побољшају своје пословање.
Алати за пословну интелигенцију често укључују функције као што су визуелизација података, ад хоц упити и могућности истраживања података. Ови алати омогућавају корисницима, као нпр пословни аналитичари или менаџере, да комуницирају са подацима, да их исеку на коцкице и да генеришу извештаје или визуелне представе које истичу важне увиде и трендове.
28. Предиктивна аналитика
Предиктивна анализа је пракса коришћења података и статистичких техника за прављење информисаних предвиђања или прогноза о будућим догађајима или исходима. То укључује анализу историјских података, идентификацију образаца и изградњу модела за екстраполацију и процену будућих трендова, понашања или појава.
Има за циљ да открије односе између варијабли и искористи те информације за предвиђања. То иде даље од једноставног описивања прошлих догађаја; уместо тога, користи историјске податке да би разумео и предвидео шта ће се вероватно догодити у будућности.
На пример, у области финансија, предиктивна анализа се може користити за предвиђање акције цене засноване на историјским тржишним подацима, економским показатељима и другим релевантним факторима.
У маркетингу се може користити за предвиђање понашања и преференција купаца, омогућавајући циљано оглашавање и персонализоване маркетиншке кампање.
У здравству, предиктивна анализа може помоћи да се идентификују пацијенти са високим ризиком за одређене болести или да се предвиди вероватноћа поновног пријема на основу медицинске историје и других фактора.
29. Прескриптивна аналитика
Прескриптивна аналитика је примена података и аналитике за одређивање најбољих могућих радњи које треба предузети у одређеној ситуацији или сценарију доношења одлука.
Она превазилази дескриптивне и предиктивна аналитика не само пружањем увида о томе шта би се могло догодити у будућности, већ и препоруком најоптималнијег правца деловања за постизање жељеног исхода.
Комбинује историјске податке, предиктивне моделе и технике оптимизације за симулацију различитих сценарија и процену потенцијалних исхода различитих одлука. Он узима у обзир вишеструка ограничења, циљеве и факторе како би се генерисале препоруке које могу да раде, које максимизирају жељене резултате или минимизирају ризике.
На пример, у ланац снабдевања менаџмент, прескриптивна аналитика може анализирати податке о нивоима залиха, производним капацитетима, трошковима транспорта и потражњи купаца како би се одредио најефикаснији план дистрибуције.
Може да препоручи идеалну алокацију ресурса, као што су локације за складиштење залиха или транспортне руте, како би се минимизирали трошкови и обезбедила благовремена испорука.
30. Маркетинг вођен подацима
Маркетинг вођен подацима односи се на праксу коришћења података и аналитике за покретање маркетиншких стратегија, кампања и процеса доношења одлука.
То укључује коришћење различитих извора података како би се стекао увид у понашање купаца, преференције и трендови и коришћење тих информација за оптимизацију маркетиншких напора.
Фокусира се на прикупљање и анализу података са више додирних тачака, као што су интеракције на веб локацији, ангажовање друштвених медија, демографија купаца, историја куповине и још много тога. Ови подаци се затим користе за стварање свеобухватног разумевања циљне публике, њених преференција и потреба.
Користећи податке, трговци могу донети информисане одлуке у вези са сегментацијом купаца, циљањем и персонализацијом.
Они могу да идентификују специфичне сегменте купаца за које је већа вероватноћа да ће позитивно реаговати на маркетиншке кампање и према томе прилагодити своје поруке и понуде.
Поред тога, маркетинг вођен подацима помаже у оптимизацији маркетиншких канала, одређивању најефикаснијег маркетинг микса и мерењу успеха маркетиншких иницијатива.
На пример, маркетиншки приступ заснован на подацима може укључивати анализу података о клијентима да би се идентификовали обрасци понашања и преференција при куповини. На основу ових увида, трговци могу креирати циљане кампање са персонализованим садржајем и понудама које одговарају одређеним сегментима купаца.
Кроз сталну анализу и оптимизацију, они могу мерити ефикасност својих маркетиншких напора и прецизирати стратегије током времена.
31. Управљање подацима
Управљање подацима је оквир и скуп пракси које организације усвајају како би осигурале правилно управљање, заштиту и интегритет података током њиховог животног циклуса. Обухвата процесе, политике и процедуре које регулишу начин на који се подаци прикупљају, чувају, приступају, користе и деле унутар организације.
Има за циљ успостављање одговорности, одговорности и контроле над имовином података. Обезбеђује да су подаци тачни, потпуни, доследни и веродостојни, омогућавајући организацијама да доносе информисане одлуке, одржавају квалитет података и испуњавају регулаторне захтеве.
Управљање подацима укључује дефинисање улога и одговорности за управљање подацима, успостављање стандарда и политика података и имплементацију процеса за праћење и спровођење усклађености. Он се бави различитим аспектима управљања подацима, укључујући приватност података, безбедност података, квалитет података, класификацију података и управљање животним циклусом података.
На пример, управљање подацима може укључивати спровођење процедура како би се осигурало да се личним или осетљивим подацима рукује у складу са важећим прописима о приватности, као што је Општа уредба о заштити података (ГДПР).
То такође може укључивати успостављање стандарда квалитета података и имплементацију процеса валидације података како би се осигурало да су подаци тачни и поуздани.
32. Сигурност података
Безбедност података се односи на чување наших вредних информација од неовлашћеног приступа или крађе. То укључује предузимање мера за заштиту поверљивости, интегритета и доступности података.
У суштини, то значи да обезбедимо да само прави људи могу да приступе нашим подацима, да они остану тачни и непромењени и да су доступни када је потребно.
За постизање сигурности података користе се различите стратегије и технологије. На пример, контроле приступа и методе шифровања помажу да се ограничи приступ овлашћеним појединцима или системима, што отежава приступ нашим подацима страним особама.
Системи за надгледање, заштитни зидови и системи за откривање упада делују као чувари, упозоравајући нас на сумњиве активности и спречавајући неовлашћени приступ.
КСНУМКС. Интернет Ствари
Интернет ствари (ИоТ) се односи на мрежу физичких објеката или „ствари“ које су повезане на Интернет и могу међусобно да комуницирају. То је попут велике мреже свакодневних предмета, уређаја и машина које су у стању да деле информације и обављају задатке интеракцијом путем интернета.
Једноставно речено, ИоТ укључује давање „паметних“ могућности различитим објектима или уређајима који традиционално нису били повезани на интернет. Ови предмети могу укључивати кућне апарате, уређаје за ношење, термостате, аутомобиле, па чак и индустријске машине.
Повезивањем ових објеката на интернет, они могу прикупљати и делити податке, примати упутства и обављати задатке самостално или као одговор на команде корисника.
На пример, паметни термостат може да прати температуру, подешава подешавања и шаље извештаје о потрошњи енергије апликацији за паметни телефон. Носиви фитнес трацкер може прикупљати податке о вашим физичким активностима и синхронизовати их са платформом заснованом на облаку за анализу.
34. Стабло одлучивања
Стабло одлучивања је визуелни приказ или дијаграм који нам помаже да донесемо одлуке или одредимо правац деловања на основу низа избора или услова.
То је као дијаграм тока који нас води кроз процес доношења одлука разматрањем различитих опција и њихових потенцијалних исхода.
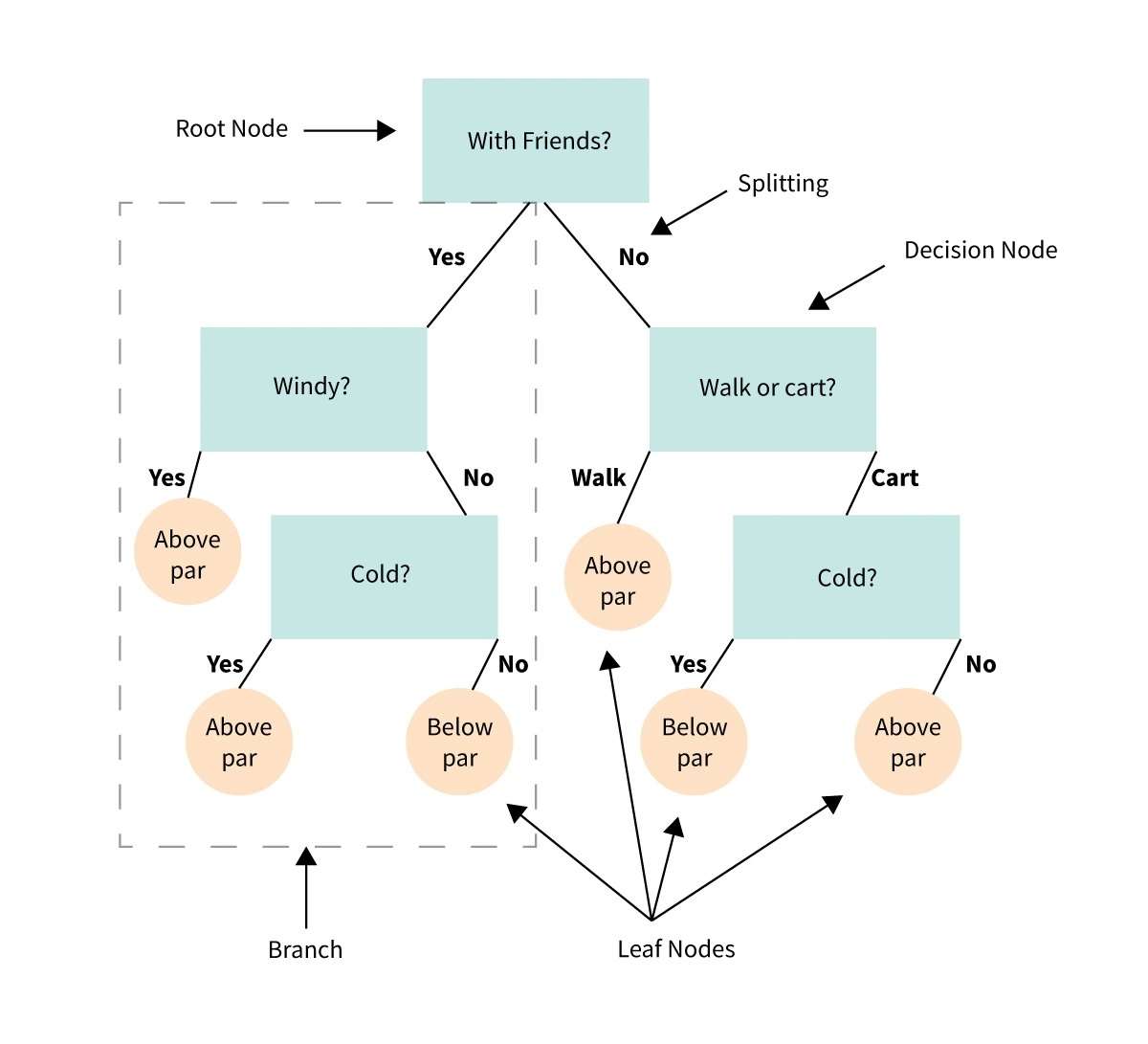
Замислите да имате проблем или питање и морате да направите избор.
Стабло одлучивања дели одлуку на мање кораке, почевши од почетног питања и гранајући се на различите могуће одговоре или акције на основу услова или критеријума у сваком кораку.
35. Когнитивно рачунарство
Когнитивно рачунарство, једноставним речима, односи се на рачунарске системе или технологије које опонашају људске когнитивне способности, као што су учење, расуђивање, разумевање и решавање проблема.
То укључује стварање компјутерских система који могу да обрађују и тумаче информације на начин који личи на људско размишљање.
Когнитивно рачунарство има за циљ да развије машине које могу да разумеју и комуницирају са људима на природнији и интелигентнији начин. Ови системи су дизајнирани да анализирају огромне количине података, препознају обрасце, дају предвиђања и дају смислене увиде.
Замислите когнитивно рачунарство као покушај да се компјутери натерају да размишљају и делују више као људи.
Укључује коришћење технологија као што су вештачка интелигенција, машинско учење, обрада природног језика и компјутерска визија како би се омогућило рачунарима да обављају задатке који су традиционално били повезани са људском интелигенцијом.
36. Рачунарска теорија учења
Теорија рачунарског учења је специјализована грана у домену вештачке интелигенције која се врти око развоја и испитивања алгоритама посебно дизајнираних да уче из података.
Ово поље истражује различите технике и методологије за конструисање алгоритама који могу аутономно побољшати своје перформансе анализом и обрадом великих количина информација.
Користећи моћ података, теорија рачунарског учења има за циљ да открије обрасце, односе и увиде који омогућавају машинама да унапреде своје способности доношења одлука и ефикасније обављају задатке.
Крајњи циљ је стварање алгоритама који могу да се прилагођавају, генерализују и праве тачна предвиђања на основу података којима су били изложени, доприносећи напретку вештачке интелигенције и њене практичне примене.
37. Тјурингов тест
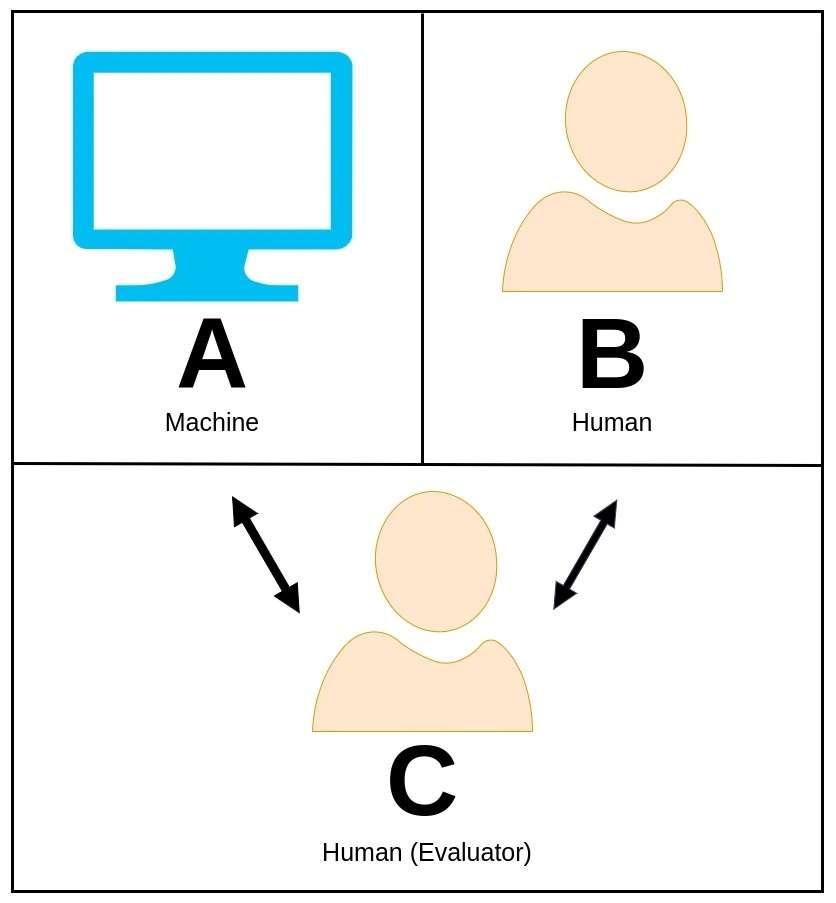
Тјурингов тест, који је првобитно предложио бриљантни математичар и информатичар Алан Тјуринг, је задивљујући концепт који се користи за процену да ли машина може да покаже интелигентно понашање које се може упоредити или се практично не разликује од људског бића.
У Тјуринговом тесту, човек евалуатор учествује у разговору на природном језику и са машином и са другим људским учесником, а да не зна који је од њих машина.
Улога оцењивача је да утврди који је ентитет машина искључиво на основу њихових одговора. Ако је машина у стању да убеди оцењивача да је људски пандан, онда се каже да је прошла Тјурингов тест, показујући на тај начин ниво интелигенције који одражава људске способности.
Алан Туринг је предложио овај тест као средство за истраживање концепта машинске интелигенције и за постављање питања да ли машине могу постићи спознају на нивоу човека.
Уоквирујући тест у смислу људске неразлучивости, Тјуринг је истакао потенцијал машина да покажу понашање које је толико убедљиво интелигентно да постаје изазовно разликовати их од људи.
Тјурингов тест је изазвао опсежне дискусије и истраживања у областима вештачке интелигенције и когнитивне науке. Иако полагање Тјуринговог теста остаје значајна прекретница, то није једина мера интелигенције.
Без обзира на то, тест служи као мерило за размишљање, подстичући сталне напоре да се развију машине способне да опонашају интелигенцију и понашање налик људима и доприносе ширем истраживању шта значи бити интелигентан.
38. Учење са појачањем
Ојачавање учења је врста учења која се дешава путем покушаја и грешака, где „агент“ (који може бити компјутерски програм или робот) учи да обавља задатке примајући награде за добро понашање и суочавање са последицама или казнама за лоше понашање.
Замислите сценарио у којем агент покушава да заврши одређени задатак, као што је навигација лавиринтом. У почетку, агент не зна прави пут којим треба да крене, па покушава различите акције и истражује различите руте.
Када изабере добру акцију која га приближава циљу, добија награду, попут виртуелног „тапшања по леђима“. Међутим, ако донесе лошу одлуку која води у ћорсокак или га удаљи од циља, добија казну или негативну повратну информацију.
Кроз овај процес покушаја и грешака, агент учи да повеже одређене радње са позитивним или негативним исходима. Постепено проналази најбољи редослед радњи како би максимизирао своје награде и минимизирао казне, на крају постаје вештији у задатку.
Учење са појачањем црпи инспирацију из начина на који људи и животиње уче примајући повратне информације из околине.
Примењујући овај концепт на машине, истраживачи имају за циљ да развију интелигентне системе који могу да уче и прилагођавају се различитим ситуацијама аутономно откривајући најефикаснија понашања кроз процес позитивног појачања и негативних последица.
39. Екстракција ентитета
Екстракција ентитета се односи на процес у којем идентификујемо и издвајамо важне делове информација, познате као ентитети, из блока текста. Ови ентитети могу бити различите ствари као што су имена људи, имена места, имена организација итд.
Замислимо да имате параграф који описује новински чланак.
Екстракција ентитета би укључивала анализу текста и одабир специфичних битова који представљају различите ентитете. На пример, ако се у тексту помиње име особе као што је „Јохн Смитх“, локација „Нев Иорк Цити“ или организација „ОпенАИ“, то би били ентитети које желимо да идентификујемо и издвојимо.
Извођењем екстракције ентитета, ми у суштини учимо компјутерски програм да препозна и изолује значајне елементе из текста. Овај процес нам омогућава да ефикасније организујемо и категоризујемо информације, што олакшава претрагу, анализу и добијање увида из великих количина текстуалних података.
Све у свему, издвајање ентитета нам помаже да аутоматизујемо задатак прецизирања важних ентитета, као што су људи, места и организације, унутар текста, поједностављујући издвајање вредних информација и побољшавајући нашу способност да обрађујемо и разумемо текстуалне податке.
40. Лингвистичка анотација
Лингвистичке белешке подразумевају обогаћивање текста додатним лингвистичким информацијама како бисмо побољшали наше разумевање и анализу језика који се користи. То је као додавање корисних ознака или ознака различитим деловима текста.
Када вршимо лингвистичку нотацију, идемо даље од основних речи и реченица у тексту и почињемо да означавамо или означавамо одређене елементе. На пример, можемо додати ознаке за део говора, које означавају граматичку категорију сваке речи (као што су именица, глагол, придев, итд.). Ово нам помаже да разумемо улогу коју свака реч игра у реченици.
Други облик лингвистичке белешке је препознавање именованих ентитета, где идентификујемо и означавамо одређене именоване ентитете, као што су имена људи, места, организација или датуми. Ово нам омогућава да брзо лоцирамо и извучемо важне информације из текста.
Анотирањем текста на ове начине стварамо структуриранију и организованију репрезентацију језика. Ово може бити изузетно корисно у различитим апликацијама. На пример, помаже у побољшању тачности претраживача разумевањем намере иза упита корисника. Такође помаже у машинском превођењу, анализи осећања, екстракцији информација и многим другим задацима обраде природног језика.
Лингвистичке белешке служе као витални алат за истраживаче, лингвисте и програмере, омогућавајући им да проучавају језичке обрасце, граде језичке моделе и развијају софистициране алгоритме који могу боље анализирати и разумети текст.
41. Хиперпараметар
In Машина учење, хиперпараметар је као посебна поставка или конфигурација за коју морамо да одлучимо пре него што обучимо модел. То није нешто што модел може сам да научи из података; уместо тога, морамо га унапред одредити.
Замислите то као дугме или прекидач који можемо да прилагодимо да бисмо фино подесили како модел учи и предвиђа. Ови хиперпараметри управљају различитим аспектима процеса учења, као што су сложеност модела, брзина обуке и компромис између тачности и генерализације.
На пример, размотримо неуронску мрежу. Један важан хиперпараметар је број слојева у мрежи. Морамо да изаберемо колико дубоко желимо да мрежа буде, а ова одлука утиче на њену способност да ухвати сложене обрасце у подацима.
Други уобичајени хиперпараметри укључују брзину учења, која одређује колико брзо модел прилагођава своје интерне параметре на основу података о обуци, и јачину регуларизације, која контролише колико модел кажњава сложене обрасце да би спречио прекомерно прилагођавање.
Исправно подешавање ових хиперпараметара је кључно јер они могу значајно утицати на перформансе и понашање модела. Често укључује мало покушаја и грешака, експериментисање са различитим вредностима и посматрање како оне утичу на перформансе модела на скупу података за валидацију.
42. Метаподаци
Метаподаци се односе на додатне информације које пружају детаље о другим подацима. То је као скуп ознака или ознака које нам дају више контекста или описују карактеристике главних података.
Када имамо податке, било да се ради о документу, фотографији, видео снимку или било којој другој врсти информација, метаподаци нам помажу да разумемо важне аспекте тих података.
На пример, у документу, метаподаци могу да садрже детаље као што су име аутора, датум када је креиран или формат датотеке. У случају фотографије, метаподаци нам могу рећи локацију на којој је снимљена, коришћена подешавања камере или чак датум и време када је снимљена.
Метаподаци нам помажу да ефикасније организујемо, претражујемо и тумачимо податке. Додавањем ових описних информација можемо брзо пронаћи одређене датотеке или разумети њихово порекло, сврху или контекст без потребе да копамо по целом садржају.
43. Смањење димензионалности
Смањење димензионалности је техника која се користи за поједностављење скупа података смањењем броја карактеристика или варијабли које садржи. То је као сажимање или сумирање информација у скупу података како би се њиме лакше управљало и са њим лакше радити.
Замислите да имате скуп података са бројним колонама или атрибутима који представљају различите карактеристике тачака података. Свака колона доприноси сложености и рачунским захтевима алгоритама машинског учења.
У неким случајевима, велики број димензија може да изазове проналажење смислених образаца или односа у подацима.
Смањење димензионалности помаже у решавању овог проблема трансформацијом скупа података у нижедимензионални приказ задржавајући што је могуће више релевантних информација. Циљ му је да обухвати најважније аспекте или варијације у подацима уз одбацивање сувишних или мање информативних димензија.
44. Класификација текста
Класификација текста је процес који укључује додељивање специфичних ознака или категорија блоковима текста на основу њиховог садржаја или значења. То је као сортирање или организовање текстуалних информација у различите групе или класе да би се олакшала даља анализа или доношење одлука.
Хајде да размотримо пример класификације е-поште. У овом сценарију желимо да утврдимо да ли је долазна е-пошта непожељна или непожељна (позната и као шунка). Класификација текста алгоритми анализирају садржај е-поште и у складу с тим му додељују ознаку.
Ако алгоритам утврди да имејл показује карактеристике које се обично повезују са нежељеном поштом, додељује ознаку „непожељна пошта“. Супротно томе, ако е-пошта изгледа легитимно и није нежељена, она додељује ознаку „није нежељена пошта“ или „шунка“.
Класификација текста проналази апликације у различитим доменима изван филтрирања е-поште. Користи се у анализи сентимента да би се одредило расположење изражено у рецензијама купаца (позитивно, негативно или неутрално).
Новински чланци се могу класификовати у различите теме или категорије као што су спорт, политика, забава и још много тога. Дневници ћаскања корисничке подршке могу се категоризовати на основу намере или проблема који се решава.
45. Слаб АИ
Слаба вештачка интелигенција, такође позната као уска АИ, односи се на системе вештачке интелигенције који су дизајнирани и програмирани да обављају одређене задатке или функције. За разлику од људске интелигенције, која обухвата широк спектар когнитивних способности, слаба АИ је ограничена на одређени домен или задатак.
Замислите слабу вештачку интелигенцију као специјализовани софтвер или машине које се истичу у обављању одређених послова. На пример, АИ програм за играње шаха може бити креиран за анализу ситуација у игри, стратегију потеза и такмичење против људских играча.
Други пример је систем за препознавање слика који може да идентификује објекте на фотографијама или видео снимцима.
Ови системи вештачке интелигенције су обучени и оптимизовани да се истичу у својим специфичним областима стручности. Они се ослањају на алгоритме, податке и унапред дефинисана правила да би ефикасно извршили своје задатке.
Међутим, они не поседују општу интелигенцију која им омогућава да разумеју или обављају задатке изван њиховог домена.
46. Јака АИ
Јака АИ, такође позната као општа АИ или вештачка општа интелигенција (АГИ), односи се на облик вештачке интелигенције која поседује способност да разуме, научи и изврши било који интелектуални задатак који људско биће може.
За разлику од слабе АИ, која је дизајнирана за специфичне задатке, јака АИ има за циљ да реплицира интелигенцију и когнитивне способности сличне људској. Настоји да створи машине или софтвер који не само да се истичу у специјализованим задацима, већ и поседују шире разумевање и прилагодљивост за решавање широког спектра интелектуалних изазова.
Циљ јаке вештачке интелигенције је да развије системе који могу да расуђују, разумеју сложене информације, уче из искуства, учествују у разговорима на природном језику, покажу креативност и покажу друге квалитете повезане са људском интелигенцијом.
У суштини, тежи да створи системе вештачке интелигенције који могу да симулирају или реплицирају размишљање на људском нивоу и решавање проблема у више домена.
47. Проследно повезивање
Уланчавање унапред је метода расуђивања или логике која почиње од доступних података и користи их за доношење закључака и извођење нових закључака. То је као повезивање тачака коришћењем доступних информација да бисте кренули напред и дошли до додатних увида.
Замислите да имате скуп правила или чињеница и желите да извучете нове информације или да донесете конкретне закључке на основу њих. Уланчавање унапред функционише испитивањем почетних података и применом логичких правила за генерисање додатних чињеница или закључака.
Да поједноставимо, размотримо једноставан сценарио одређивања шта да обучемо на основу временских услова. Имате правило које каже: „Ако пада киша, понесите кишобран“, и друго правило које каже „Ако је хладно, носите јакну“. Сада, ако приметите да заиста пада киша, можете користити ланчано повезивање да бисте закључили да бисте требали понети кишобран.
48. Ланац уназад
Уланчавање уназад је метода резоновања која почиње са жељеним закључком или циљем и ради уназад како би се утврдили потребни подаци или чињенице које су потребне да подрже тај закључак. То је као да пратите своје кораке од жељеног исхода до почетних информација потребних да бисте га постигли.
Да бисмо разумели уланчавање уназад, размотримо једноставан пример. Претпоставимо да желите да утврдите да ли је погодно за пливање. Жељени закључак је да ли је пливање прикладно или не на основу одређених услова.
Уместо да почне са условима, уланчавање уназад почиње са закључком и ради уназад како би се пронашли пратећи подаци.
У овом случају, уланчавање уназад би укључивало постављање питања попут „Да ли је топло време?“ Ако је одговор да, онда бисте питали: „Да ли постоји базен?“ Ако је одговор поново потврдан, поставили бисте додатна питања као што су: „Има ли довољно времена за пливање?“
Итеративним одговарањем на ова питања и радом уназад, можете одредити неопходне услове који треба да буду испуњени да бисте подржали закључак о одласку на пливање.
49. Хеуристички
Хеуристика, једноставно речено, је практично правило или стратегија која нам помаже да доносимо одлуке или решавамо проблеме, обично на основу наших прошлих искустава или интуиције. То је као ментална пречица која нам омогућава да брзо дођемо до разумног решења без проласка кроз дуг или исцрпан процес.
Када се суочи са сложеним ситуацијама или задацима, хеуристика служи као водећи принципи или „правила палца“ која поједностављују доношење одлука. Они нам пружају опште смернице или стратегије које су често ефикасне у одређеним ситуацијама, иако можда не гарантују оптимално решење.
На пример, хајде да размотримо хеуристику за проналажење паркинг места у гужви. Уместо да пажљиво анализирате свако доступно место, можете се ослонити на хеуристику тражења паркираних аутомобила са упаљеним моторима.
Ова хеуристика претпоставља да се ови аутомобили спремају да оду, повећавајући шансе за проналажење слободног места.
50. Моделирање природног језика
Моделирање природног језика, једноставно речено, је процес обуке компјутерских модела да разумеју и генеришу људски језик на начин који је сличан начину на који људи комуницирају. То укључује подучавање рачунара да обрађују, тумаче и генеришу текст на природан и смислен начин.
Циљ моделирања природног језика је да омогући рачунарима да схвате и генеришу људски језик на начин који је течан, кохерентан и контекстуално релевантан.
Укључује моделе обуке на огромним количинама текстуалних података, као што су књиге, чланци или разговори, како би се научили обрасци, структуре и семантика језика.
Једном обучени, ови модели могу да обављају различите задатке у вези са језиком, као што су превод језика, сумирање текста, одговарање на питања, интеракције са четботовима и још много тога.
Они могу разумети значење и контекст реченица, извући релевантне информације и генерисати текст који је граматички исправан и кохерентан.





Ostavite komentar