Kazalo[Skrij][Pokaži]
Zahvaljujoč računalnikom lahko zdaj izračunamo prostorsko širino in najmanjše zapletenosti subatomskih delcev.
Računalniki premagajo ljudi, ko gre za štetje in računanje, pa tudi pri sledenju logičnim procesom da/ne, zahvaljujoč elektronom, ki potujejo s svetlobno hitrostjo prek svojega vezja.
Vendar jih pogosto ne vidimo kot »inteligentne«, saj v preteklosti računalniki niso mogli izvesti ničesar, ne da bi jih ljudje naučili (programirali).
Strojno učenje, vključno z globokim učenjem in Umetna inteligenca, je postala modna beseda v znanstvenih in tehnoloških naslovih.
Zdi se, da je strojno učenje vseprisotno, toda mnogi ljudje, ki uporabljajo to besedo, bi se trudili, da bi ustrezno opredelili, kaj je, kaj počne in za kaj je najbolje uporabiti.
Ta članek želi razjasniti strojno učenje, hkrati pa zagotoviti konkretne primere iz resničnega sveta, kako tehnologija deluje, da ponazori, zakaj je tako koristna.
Nato si bomo ogledali različne metodologije strojnega učenja in videli, kako se uporabljajo za reševanje poslovnih izzivov.
Na koncu si bomo ogledali našo kristalno kroglo za nekaj hitrih napovedi o prihodnosti strojnega učenja.
Kaj je strojno učenje?
Strojno učenje je disciplina računalništva, ki računalnikom omogoča sklepanje vzorcev iz podatkov, ne da bi jih izrecno poučili, kaj so ti vzorci.
Ti sklepi pogosto temeljijo na uporabi algoritmov za samodejno ocenjevanje statističnih značilnosti podatkov in razvoju matematičnih modelov za prikaz razmerja med različnimi vrednostmi.
Primerjajte to s klasičnim računalništvom, ki temelji na determinističnih sistemih, v katerih računalniku izrecno damo nabor pravil, ki jih mora upoštevati, da lahko opravi določeno nalogo.
Ta način programiranja računalnikov je znan kot programiranje na podlagi pravil. Strojno učenje se razlikuje od programiranja, ki temelji na pravilih, in ga prekaša, saj lahko ta pravila sklepa sam.
Predpostavimo, da ste upravitelj banke, ki želi ugotoviti, ali bo prošnja za posojilo neuspešna za njihovo posojilo.
Pri metodi, ki temelji na pravilih, bi upravitelj banke (ali drugi strokovnjaki) izrecno obvestil računalnik, da je treba vlogo zavrniti, če je bonitetna ocena prosilca nižja od določene ravni.
Vendar pa bi program strojnega učenja preprosto analiziral predhodne podatke o bonitetnih ocenah strank in rezultatih posojil ter določil, kakšen bi moral biti ta prag sam.
Stroj se uči iz prejšnjih podatkov in na ta način ustvarja svoja pravila. Seveda je to le začetnica o strojnem učenju; modeli strojnega učenja v resničnem svetu so bistveno bolj zapleteni od osnovnega praga.
Kljub temu je odličen prikaz potenciala strojnega učenja.
Kako deluje a stroj naučiti?
Da bi bile stvari preproste, se stroji »učijo« z odkrivanjem vzorcev v primerljivih podatkih. Podatke obravnavajte kot informacije, ki jih zbirate iz zunanjega sveta. Več podatkov kot je napajana naprava, »pametnejši« postane.
Vendar pa niso vsi podatki enaki. Predpostavimo, da ste pirat z življenjskim namenom odkriti zakopano bogastvo na otoku. Za lociranje nagrade boste potrebovali veliko znanja.
To znanje, tako kot podatki, vas lahko odpelje na pravilen ali napačen način.
Več kot je pridobljenih informacij/podatkov, manj je dvoumnosti in obratno. Posledično je ključnega pomena, da razmislite o vrsti podatkov, s katerimi napajate svoj stroj, da se iz njih učite.
Ko pa je zagotovljena velika količina podatkov, lahko računalnik naredi napovedi. Stroji lahko predvidevajo prihodnost, dokler ne odstopajo veliko od preteklosti.
Stroji se »učijo« z analizo preteklih podatkov, da ugotovijo, kaj se bo verjetno zgodilo.
Če so stari podatki podobni novim, bodo stvari, ki jih lahko poveste o prejšnjih podatkih, verjetno veljale za nove podatke. Kot da gledaš nazaj, da vidiš naprej.
Kakšne so vrste strojnega učenja?
Algoritmi za strojno učenje so pogosto razvrščeni v tri široke vrste (čeprav se uporabljajo tudi druge klasifikacijske sheme):
- Nadzorovano učenje
- Nenadzorovano učenje
- Okrepitveno učenje
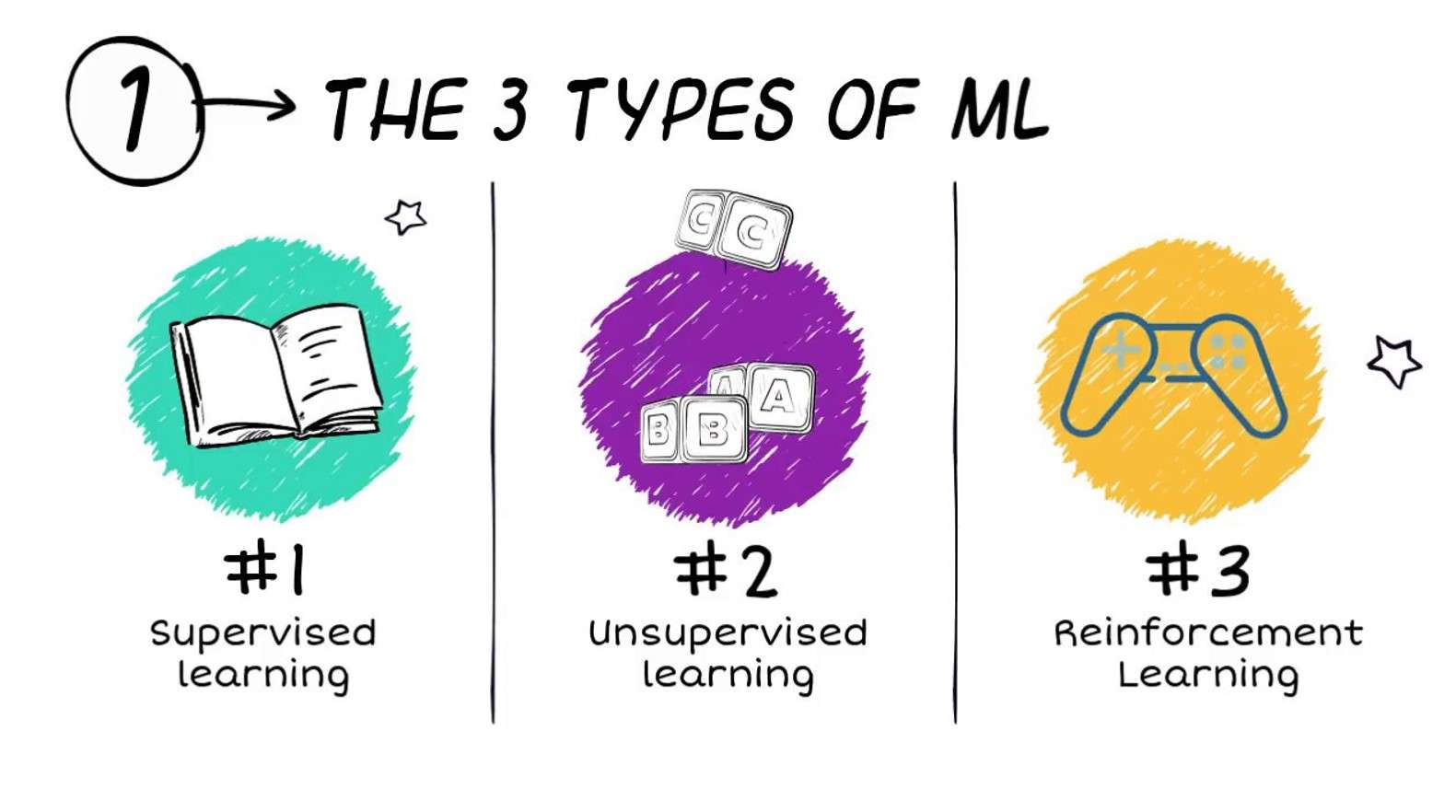
Nadzorovano učenje
Nadzorovano strojno učenje se nanaša na tehnike, pri katerih je modelu strojnega učenja dana zbirka podatkov z eksplicitnimi oznakami za količino, ki vas zanima (ta količina se pogosto imenuje odziv ali cilj).
Za usposabljanje modelov AI delno nadzorovano učenje uporablja mešanico označenih in neoznačenih podatkov.
Če delate z neoznačenimi podatki, boste morali opraviti nekaj označevanja podatkov.
Označevanje je postopek označevanja vzorcev za pomoč pri usposabljanje strojnega učenja model. Označevanje izvajajo predvsem ljudje, kar je lahko drago in dolgotrajno. Vendar pa obstajajo tehnike za avtomatizacijo postopka označevanja.
Situacija vloge za posojilo, o kateri smo razpravljali prej, je odlična ponazoritev nadzorovanega učenja. Imeli smo pretekle podatke o bonitetnih ocenah nekdanjih prosilcev za posojilo (in morda ravni dohodka, starosti in tako naprej) ter posebne oznake, ki so nam povedale, ali je zadevna oseba zamudila svoje posojilo ali ne.
Regresija in klasifikacija sta dve podskupini tehnik nadzorovanega učenja.
- Razvrstitev – Uporablja algoritem za pravilno kategorizacijo podatkov. Filtri za neželeno pošto so en primer. »Neželena pošta« je lahko subjektivna kategorija – meja med neželeno pošto in komunikacijo, ki ni neželena, je zamegljena – in algoritem filtra neželene pošte se nenehno izpopolnjuje glede na vaše povratne informacije (kar pomeni e-pošto, ki jo ljudje označijo kot vsiljeno pošto).
- regresija – V pomoč je pri razumevanju povezave med odvisnimi in neodvisnimi spremenljivkami. Regresijski modeli lahko napovedujejo številčne vrednosti na podlagi več virov podatkov, kot so ocene prihodkov od prodaje za določeno podjetje. Linearna regresija, logistična regresija in polinomska regresija so nekatere pomembne tehnike regresije.
Nenadzorovano učenje
Pri nenadzorovanem učenju dobimo neoznačene podatke in iščemo le vzorce. Pretvarjajmo se, da ste Amazon. Ali lahko najdemo kakšne grozde (skupine podobnih potrošnikov) na podlagi zgodovine nakupov strank?
Čeprav nimamo izrecnih, dokončnih podatkov o preferencah osebe, nam v tem primeru preprosto poznavanje, da določen niz potrošnikov kupuje primerljivo blago, omogoča, da predlagamo nakup na podlagi tega, kar so kupili tudi drugi posamezniki v skupini.
Amazonov vrtiljak »mogoče bi vas tudi zanimal« poganjajo podobne tehnologije.
Nenadzorovano učenje lahko združuje podatke z združevanjem v skupine ali povezovanjem, odvisno od tega, kaj želite združiti.
- Grozdenje – Nenadzorovano učenje poskuša premagati ta izziv z iskanjem vzorcev v podatkih. Če obstaja podobna gruča ali skupina, jih bo algoritem kategoriziral na določen način. Primer tega je poskus kategorizacije strank na podlagi prejšnje zgodovine nakupov.
- Združenje – Nenadzorovano učenje se skuša spopasti s tem izzivom tako, da poskuša razumeti pravila in pomene, na katerih temeljijo različne skupine. Pogost primer problema povezovanja je določanje povezave med nakupi strank. Trgovine lahko zanimajo, katero blago je bilo kupljeno skupaj, in lahko te informacije uporabijo za urejanje položaja teh izdelkov za enostaven dostop.
Okrepitveno učenje
Učenje s krepitvijo je tehnika za poučevanje modelov strojnega učenja za sprejemanje niza ciljno usmerjenih odločitev v interaktivnem okolju. Zgoraj omenjeni primeri uporabe iger so odlične ilustracije tega.
Ni vam treba vnesti AlphaZero na tisoče prejšnjih šahovskih iger, od katerih je vsaka označena z "dobro" ali "slabo" potezo. Preprosto ga naučite pravil igre in cilja, nato pa pustite, da preizkusi naključna dejanja.
Pozitivno okrepitev dobijo dejavnosti, ki program približajo cilju (kot je razvoj trdnega položaja pešake). Kadar imajo dejanja nasproten učinek (na primer prezgodnja zamenjava kralja), si prislužijo negativno okrepitev.
Programska oprema lahko na koncu obvlada igro s to metodo.
Okrepitveno učenje se pogosto uporablja v robotiki za učenje robotov za zapletena dejanja, ki jih je težko načrtovati. Včasih se uporablja v povezavi s cestno infrastrukturo, kot je prometna signalizacija, za izboljšanje pretoka prometa.
Kaj je mogoče narediti s strojnim učenjem?
Uporaba strojnega učenja v družbi in industriji povzroča napredek v številnih človeških prizadevanjih.
V našem vsakdanjem življenju zdaj strojno učenje nadzoruje Googlove algoritme iskanja in slik, kar nam omogoča natančnejše ujemanje z informacijami, ki jih potrebujemo, ko jih potrebujemo.
V medicini se na primer strojno učenje uporablja za genetske podatke, da bi zdravnikom pomagali razumeti in predvideti, kako se rak širi, kar omogoča razvoj učinkovitejših terapij.
Podatki iz globokega vesolja se zbirajo tukaj na Zemlji z ogromnimi radijskimi teleskopi – in po analizi s strojnim učenjem nam pomagajo razkriti skrivnosti črnih lukenj.
Strojno učenje v maloprodaji povezuje kupce s stvarmi, ki jih želijo kupiti na spletu, in tudi pomaga zaposlenim v trgovinah, da prilagodijo storitve, ki jih nudijo svojim strankam v običajnem svetu.
Strojno učenje se uporablja v boju proti terorizmu in ekstremizmu za predvidevanje vedenja tistih, ki želijo raniti nedolžne.
Obdelava naravnega jezika (NLP) se nanaša na proces, ki omogoča računalnikom, da razumejo in komunicirajo z nami v človeškem jeziku s pomočjo strojnega učenja, kar je povzročilo preboj v tehnologiji prevajanja in glasovno nadzorovanih naprav, ki jih vsak dan vse pogosteje uporabljamo, kot je npr. Alexa, Google dot, Siri in Googlov pomočnik.
Brez dvoma strojno učenje dokazuje, da je transformacijska tehnologija.
Roboti, ki lahko delajo skupaj z nami ter s svojo brezhibno logiko in nadčloveško hitrostjo krepijo našo lastno izvirnost in domišljijo, niso več znanstvenofantastična fantazija – postajajo resničnost v mnogih sektorjih.
Primeri uporabe strojnega učenja
1. Kibernetska varnost
Ker so omrežja postajala vse bolj zapletena, so strokovnjaki za kibernetsko varnost neutrudno delali, da bi se prilagodili vedno širši paleti varnostnih groženj.
Boj proti hitro razvijajoči se zlonamerni programski opremi in taktikam vdiranja je dovolj zahteven, vendar je širjenje naprav interneta stvari (IoT) bistveno spremenilo okolje kibernetske varnosti.
Napadi se lahko pojavijo kadarkoli in kjer koli.
Na srečo so algoritmi strojnega učenja omogočili operacijam kibernetske varnosti, da sledijo tem hitremu razvoju.
Napovedna analitika omogoča hitrejše odkrivanje in ublažitev napadov, medtem ko lahko strojno učenje analizira vašo dejavnost v omrežju, da odkrije nenormalnosti in slabosti v obstoječih varnostnih mehanizmih.
2. Avtomatizacija storitev za stranke
Upravljanje vse večjega števila spletnih stikov s strankami je močno obremenilo organizacijo.
Preprosto nimajo dovolj osebja za pomoč strankam, da bi obravnavali obseg povpraševanj, ki jih prejemajo, in tradicionalni pristop zunanjega izvajanja težav kontaktni center je za mnoge današnje stranke preprosto nesprejemljivo.
Chatboti in drugi avtomatizirani sistemi lahko zdaj obravnavajo te zahteve zahvaljujoč napredku v tehnikah strojnega učenja. Podjetja lahko z avtomatizacijo vsakdanjih dejavnosti in dejavnosti z nizko prioriteto sprostijo osebje za boljšo podporo strankam.
Če se pravilno uporablja, lahko strojno učenje v podjetju pomaga poenostaviti reševanje težav in potrošnikom zagotoviti vrsto koristne podpore, ki jih spremeni v predane prvake blagovne znamke.
3. Komunikacija
Izogibanje napakam in napačnim predstavam je ključnega pomena pri vseh vrstah komunikacije, še bolj pa v današnjem poslovnem komuniciranju.
Preproste slovnične napake, nepravilen ton ali napačni prevodi lahko povzročijo vrsto težav pri stiku po e-pošti, ocenjevanju strank, video konferencaali besedilno dokumentacijo v številnih oblikah.
Sistemi strojnega učenja so komunikacijo napredovali daleč od Microsoftovega Clippyjevega omamljanja.
Ti primeri strojnega učenja so posameznikom pomagali pri preprosti in natančni komunikaciji z uporabo obdelave naravnega jezika, jezikovnega prevoda v realnem času in prepoznavanja govora.
Čeprav mnogi posamezniki ne marajo zmožnosti samodejnega popravljanja, cenijo tudi zaščito pred neprijetnimi napakami in neustreznim tonom.
4. Prepoznavanje predmetov
Čeprav tehnologija za zbiranje in interpretacijo podatkov obstaja že nekaj časa, se je izkazalo, da je učenje računalniških sistemov, da razumejo, kaj gledajo, zavajajoče težko opravilo.
Zmogljivosti za prepoznavanje predmetov se dodajajo vse večjemu številu naprav zaradi aplikacij strojnega učenja.
Samovozeči avtomobil, na primer, prepozna drug avto, ko ga vidi, tudi če mu programerji niso dali natančnega primera tega avtomobila, da bi ga uporabili kot referenco.
Ta tehnologija se zdaj uporablja v maloprodajnih podjetjih, da bi pospešila postopek nakupa. Kamere prepoznajo izdelke v košaricah potrošnikov in lahko samodejno zaračunajo njihove račune, ko zapustijo trgovino.
5. Digitalno trženje
Velik del današnjega trženja poteka na spletu z uporabo različnih digitalnih platform in programov.
Ko podjetja zbirajo informacije o svojih potrošnikih in njihovem nakupovalnem vedenju, lahko marketinške ekipe te informacije uporabijo za izgradnjo podrobne slike o svojem ciljnem občinstvu in odkrijejo, kateri ljudje so bolj nagnjeni k iskanju njihovih izdelkov in storitev.
Algoritmi strojnega učenja pomagajo tržnikom pri razumevanju vseh teh podatkov, odkrivanju pomembnih vzorcev in atributov, ki jim omogočajo, da natančno kategorizirajo možnosti.
Ista tehnologija omogoča veliko avtomatizacijo digitalnega trženja. Oglasne sisteme je mogoče nastaviti tako, da dinamično odkrijejo nove potencialne potrošnike in jim ob pravem času in na pravem mestu zagotovijo ustrezno marketinško vsebino.
Prihodnost strojnega učenja
Strojno učenje zagotovo pridobiva na priljubljenosti, saj vse več podjetij in velikih organizacij uporablja tehnologijo za spopadanje s specifičnimi izzivi ali spodbujanje inovacij.
Ta nadaljnja naložba dokazuje razumevanje, da strojno učenje ustvarja donosnost naložbe, zlasti z nekaterimi od zgoraj omenjenih uveljavljenih in ponovljivih primerov uporabe.
Konec koncev, če je tehnologija dovolj dobra za Netflix, Facebook, Amazon, Google Maps in tako naprej, obstaja velika verjetnost, da lahko pomaga tudi vašemu podjetju kar najbolje izkoristiti svoje podatke.
Kot novo strojno učenje modeli razviti in lansirani, bomo priča povečanju števila aplikacij, ki se bodo uporabljale v panogah.
To se že dogaja z prepoznavanje obraza, ki je bila nekoč nova funkcija na vašem iPhoneu, zdaj pa se izvaja v številnih programih in aplikacijah, zlasti v tistih, ki so povezani z javno varnostjo.
Ključno za večino organizacij, ki poskušajo začeti s strojnim učenjem, je pogledati mimo svetlih futurističnih vizij in odkriti resnične poslovne izzive, pri katerih vam lahko tehnologija pomaga.
zaključek
V postindustrializirani dobi znanstveniki in strokovnjaki poskušajo ustvariti računalnik, ki se obnaša bolj kot ljudje.
Razmišljalni stroj je najpomembnejši prispevek AI k človeštvu; Fenomenalni prihod tega samohodnega stroja je hitro spremenil poslovne predpise podjetja.
Samovozeča vozila, avtomatizirani pomočniki, zaposleni v avtonomni proizvodnji in pametna mesta so v zadnjem času dokazali sposobnost preživetja pametnih strojev. Revolucija strojnega učenja in prihodnost strojnega učenja bosta z nami še dolgo.





Pustite Odgovori