Umetna inteligenca je povsod, včasih pa je lahko težko razumeti terminologijo in žargon. V tej objavi v spletnem dnevniku razlagamo več kot 50 izrazov in definicij umetne inteligence, da boste lahko bolje razumeli to hitro rastočo tehnologijo.
Ne glede na to, ali ste začetnik ali strokovnjak, stavimo, da je tukaj nekaj izrazov, ki jih ne poznate!
1. Umetna inteligenca
Umetna inteligenca (AI) se nanaša na razvoj računalniških sistemov, ki se lahko učijo in delujejo neodvisno, pogosto s posnemanjem človeške inteligence.
Ti sistemi analizirajo podatke, prepoznavajo vzorce, sprejemajo odločitve in prilagajajo svoje vedenje na podlagi izkušenj. Z uporabo algoritmov in modelov želi AI ustvariti inteligentne stroje, ki so sposobni zaznati in razumeti svojo okolico.
Končni cilj je omogočiti strojem, da učinkovito opravljajo naloge, se učijo iz podatkov in kažejo kognitivne sposobnosti, podobne ljudem.
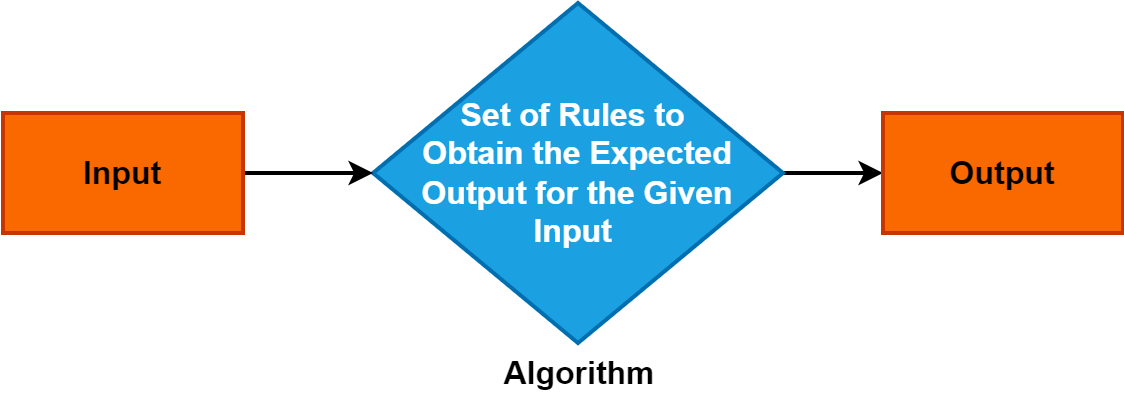
2. algoritem
Algoritem je natančen in sistematičen niz navodil ali pravil, ki vodijo postopek reševanja problema ali izpolnjevanja določene naloge.
Služi kot temeljni koncept na različnih področjih in igra ključno vlogo v računalniški znanosti, matematiki in disciplinah reševanja problemov. Razumevanje algoritmov je ključnega pomena, saj omogočajo učinkovite in strukturirane pristope k reševanju problemov, spodbujajo napredek v tehnologiji in procesih odločanja.
3. Veliki podatki
Veliki podatki se nanašajo na izjemno velike in kompleksne nize podatkov, ki presegajo zmogljivosti tradicionalnih analiznih metod. Za te nabore podatkov so značilni obseg, hitrost in raznolikost.
Količina se nanaša na ogromno količino podatkov, ustvarjenih iz različnih virov, kot npr družbeni mediji, senzorji in transakcije.
Hitrost se nanaša na visoko hitrost, s katero se podatki generirajo in jih je treba obdelati v realnem ali skoraj realnem času. Raznolikost označuje različne vrste in formate podatkov, vključno s strukturiranimi, nestrukturiranimi in polstrukturiranimi podatki.
4. Podatkovno rudarjenje
Podatkovno rudarjenje je obsežen proces, katerega cilj je pridobivanje dragocenih vpogledov iz obsežnih naborov podatkov.
Zajema štiri ključne faze: zbiranje podatkov, ki vključuje zbiranje ustreznih podatkov; priprava podatkov, zagotavljanje kakovosti in združljivosti podatkov; rudarjenje podatkov, uporaba algoritmov za odkrivanje vzorcev in odnosov; ter analizo in interpretacijo podatkov, kjer se pridobljeno znanje preuči in razume.
5. Nevronska mreža
Računalniški sistem je zasnovan tako, da deluje kot človeških možganov, sestavljen iz med seboj povezanih vozlišč ali nevronov. Razumejmo to nekoliko bolj, saj večina AI temelji na nevronske mreže.
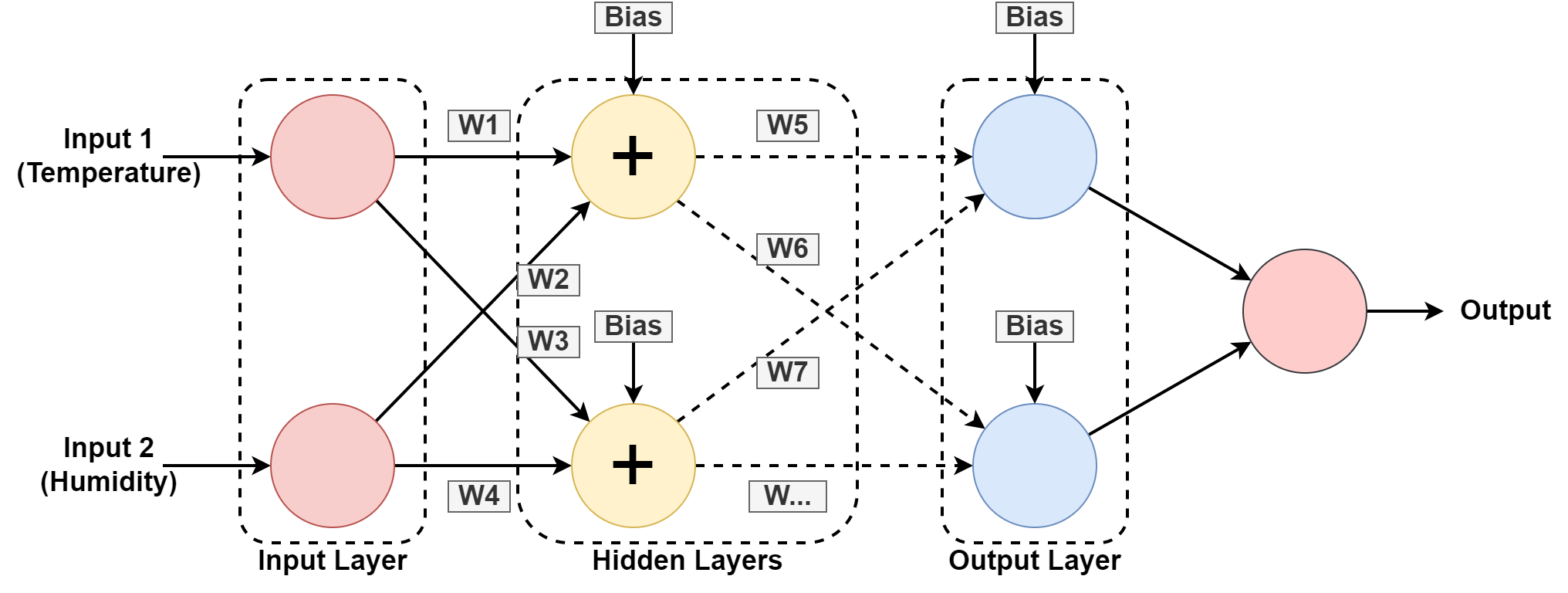
V zgornji grafiki napovedujemo vlažnost in temperaturo geografske lokacije z učenjem iz preteklih vzorcev. Vhodi so nabor podatkov za pretekli zapis.
O nevronska mreža se uči vzorec z igranjem z utežmi in uporabo vrednosti pristranskosti v skritih slojih. W1, W2….W7 so ustrezne uteži. Uri se na ponujenem naboru podatkov in daje rezultate kot napoved.
Morda boste preobremenjeni s temi zapletenimi informacijami. Če je temu tako, lahko začnete z našim preprostim vodnikom tukaj.
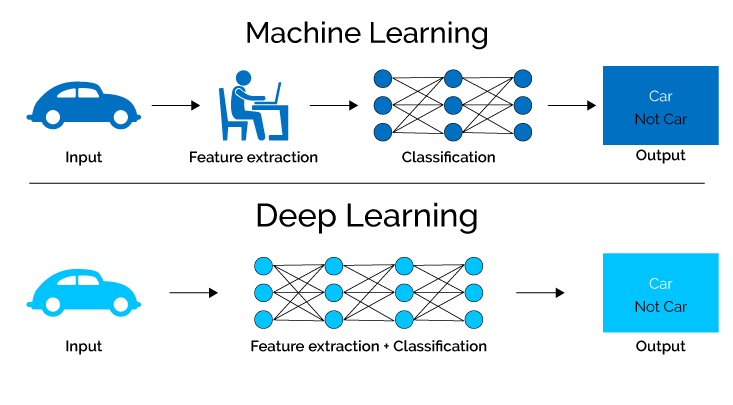
6. Strojno učenje
Strojno učenje se osredotoča na razvoj algoritmov in modelov, ki se lahko samodejno učijo iz podatkov in sčasoma izboljšajo svojo učinkovitost.
Vključuje uporabo statističnih tehnik, ki računalnikom omogočajo prepoznavanje vzorcev, napovedovanje in sprejemanje odločitev na podlagi podatkov, ne da bi bili izrecno programirani.
Algoritmi strojnega učenja analizirajo in se učijo iz velikih naborov podatkov, kar omogoča sistemom, da prilagodijo in izboljšajo svoje vedenje na podlagi informacij, ki jih obdelujejo.
7. Globoko učenje
Globoko učenje, podpodročje strojnega učenja in nevronskih mrež, izkorišča sofisticirane algoritme za pridobivanje znanja iz podatkov s simulacijo zapletenih procesov človeških možganov.
Z uporabo nevronskih mrež s številnimi skritimi plastmi lahko modeli globokega učenja avtonomno izločijo zapletene lastnosti in vzorce, kar jim omogoča reševanje zapletenih nalog z izjemno natančnostjo in učinkovitostjo.
8. Prepoznavanje vzorcev
Prepoznavanje vzorcev, tehnika analize podatkov, izkorišča moč algoritmov strojnega učenja za avtonomno zaznavanje in razločevanje vzorcev in pravilnosti v naborih podatkov.
Z uporabo računalniških modelov in statističnih metod lahko algoritmi za prepoznavanje vzorcev identificirajo pomembne strukture, korelacije in trende v kompleksnih in raznolikih podatkih.
Ta postopek omogoča pridobivanje dragocenih vpogledov, razvrščanje podatkov v različne kategorije in napovedovanje prihodnjih rezultatov na podlagi prepoznanih vzorcev. Prepoznavanje vzorcev je bistveno orodje na različnih področjih, saj omogoča sprejemanje odločitev, odkrivanje nepravilnosti in napovedno modeliranje.
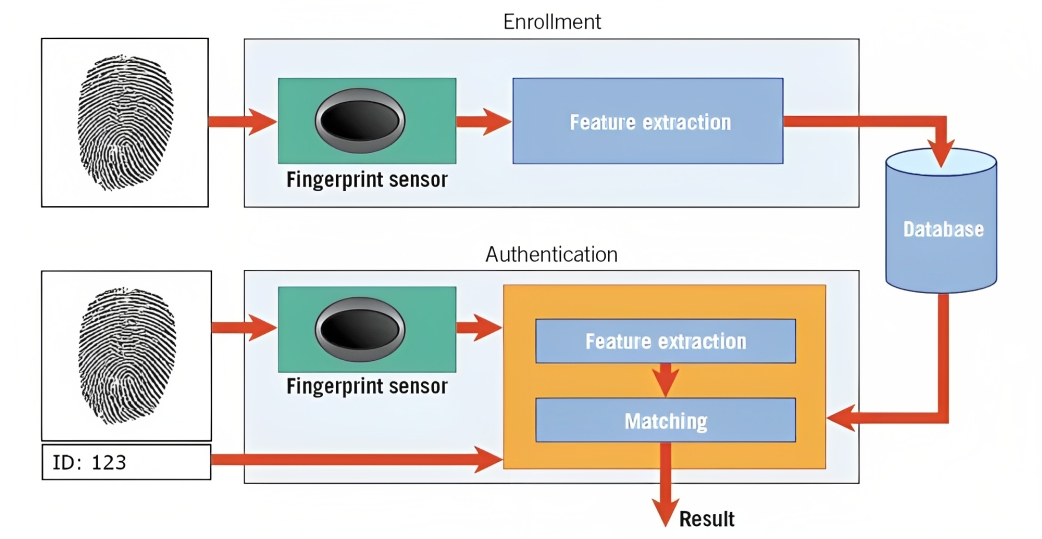
Biometrija je en primer tega. Na primer, pri prepoznavanju prstnih odtisov algoritem analizira grebene, krivulje in edinstvene značilnosti prstnega odtisa osebe, da ustvari digitalno predstavitev, imenovano predloga.
Ko poskušate odkleniti pametni telefon ali dostopati do varnega objekta, sistem za prepoznavanje vzorcev primerja zajete biometrične podatke (npr. prstni odtis) s shranjenimi predlogami v svoji zbirki podatkov.
Z ujemanjem vzorcev in ocenjevanjem stopnje podobnosti lahko sistem ugotovi, ali se predloženi biometrični podatki ujemajo s shranjeno predlogo, in temu primerno odobri dostop.
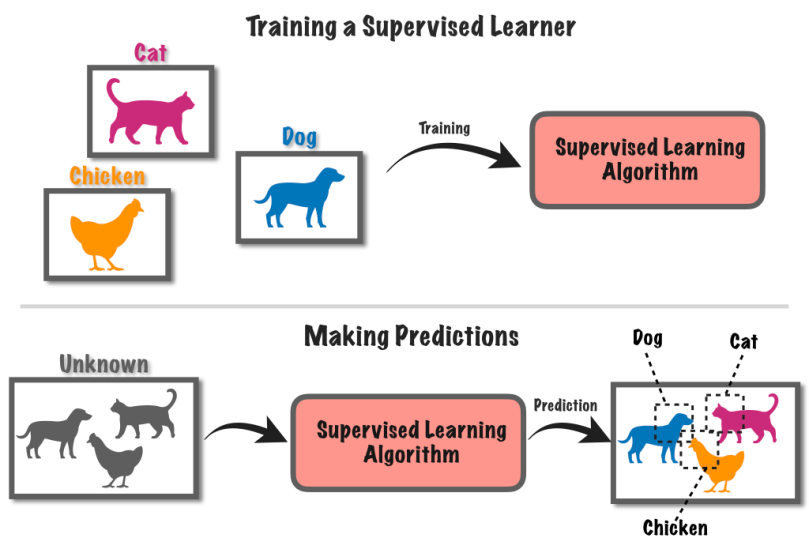
9. Nadzorovano učenje
Nadzorovano učenje je pristop strojnega učenja, ki vključuje usposabljanje računalniškega sistema z uporabo označenih podatkov. Pri tej metodi je računalniku na voljo niz vhodnih podatkov skupaj z ustreznimi znanimi oznakami ali rezultati.
Recimo, da imate kup slik, nekatere s psi in nekatere z mačkami.
Računalniku poveš, na katerih slikah so psi in na katerih mačke. Računalnik se nato nauči prepoznati razlike med psi in mačkami tako, da poišče vzorce na slikah.
Ko se nauči, lahko računalniku posredujete nove slike in ta bo na podlagi tega, kar se je naučil iz označenih primerov, poskušal ugotoviti, ali imajo pse ali mačke. To je kot usposobiti računalnik za napovedovanje z uporabo znanih informacij.
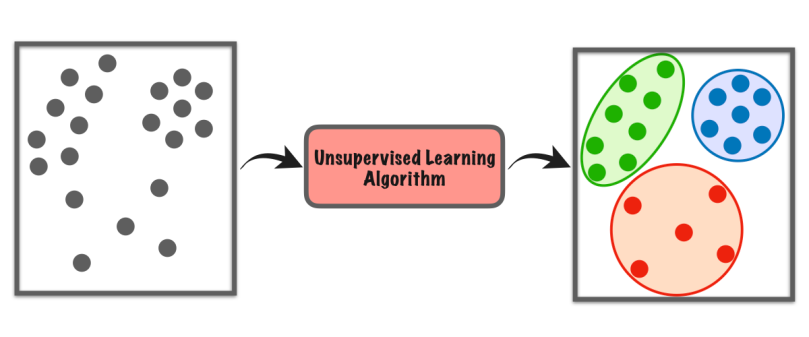
10. Nenadzorovano učenje
Nenadzorovano učenje je vrsta strojnega učenja, kjer računalnik sam raziskuje nabor podatkov, da bi našel vzorce ali podobnosti brez posebnih navodil.
Ne opira se na označene primere kot pri nadzorovanem učenju. Namesto tega išče skrite strukture ali skupine v podatkih. Kot da računalnik odkriva stvari sam, ne da bi mu učitelj povedal, kaj naj išče.
Ta vrsta učenja nam pomaga najti nove vpoglede, organizirati podatke ali prepoznati nenavadne stvari, ne da bi potrebovali predhodno znanje ali izrecna navodila.
11. Obdelava naravnega jezika (NLP)
Obdelava naravnega jezika se osredotoča na to, kako računalniki razumejo človeški jezik in komunicirajo z njim. Pomaga računalnikom analizirati, interpretirati in se odzivati na človeški jezik na način, ki se nam zdi bolj naraven.
NLP je tisto, kar nam omogoča komunikacijo z glasovnimi pomočniki in klepetalnimi roboti ter celo samodejno razvrščanje e-pošte v mape.
Vključuje učenje računalnikov, da razumejo pomen besed, stavkov in celo celotnih besedil, tako da nam lahko pomagajo pri različnih nalogah in naredijo naše interakcije s tehnologijo bolj brezhibnimi.
12. Računalniški vid
Računalniški vid je fascinantna tehnologija, ki omogoča računalnikom, da vidijo in razumejo slike in video posnetke, tako kot mi ljudje počnemo s svojimi očmi. Gre za učenje računalnikov, da analizirajo vizualne informacije in razumejo, kar vidijo.
Preprosteje rečeno, računalniški vid pomaga računalnikom prepoznati in interpretirati vizualni svet. Vključuje naloge, kot je učenje prepoznavanja določenih predmetov na slikah, razvrščanje slik v različne kategorije ali celo razdelitev slik na pomembne dele.
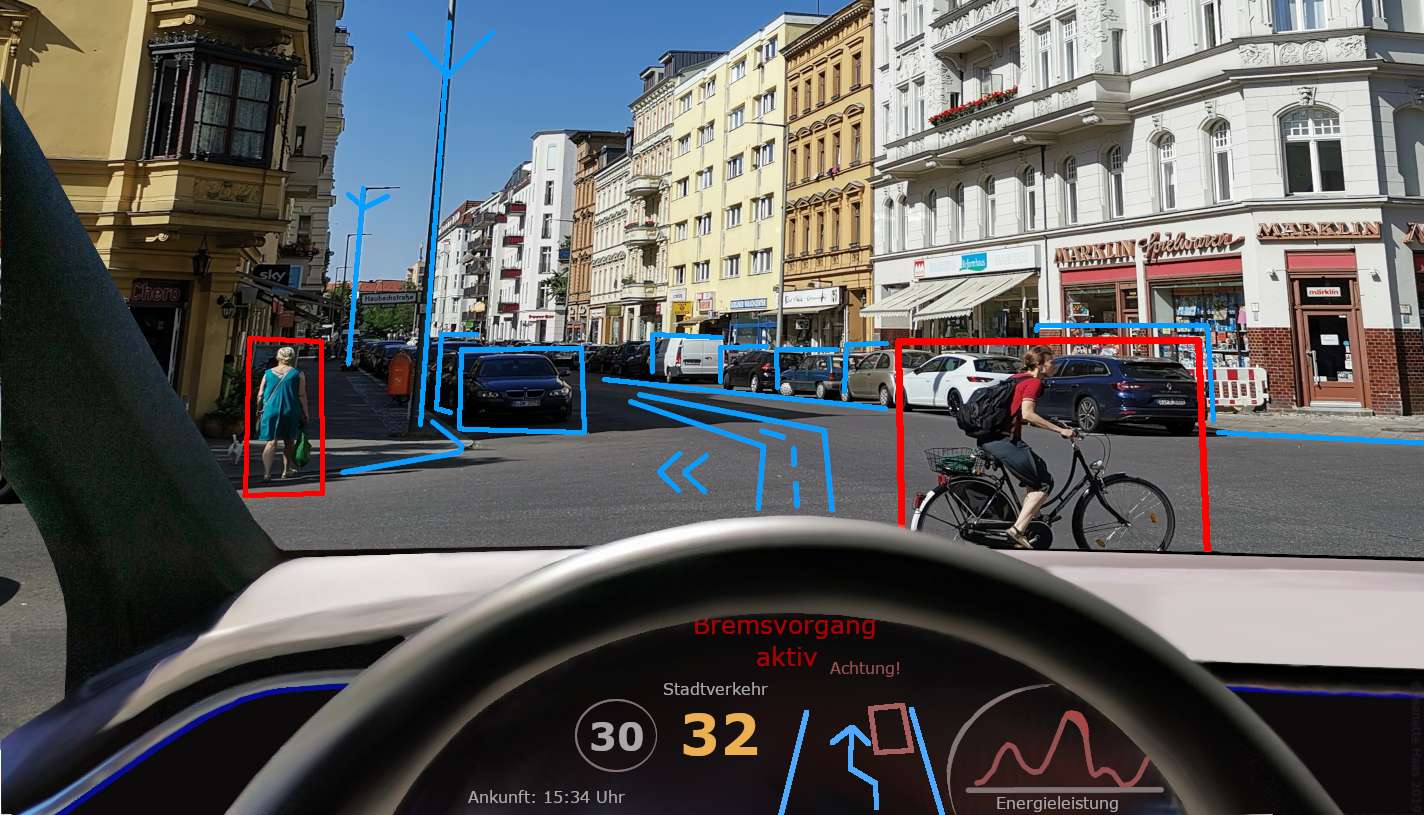
Predstavljajte si samovozeči avto, ki uporablja računalniški vid, da »vidi« cesto in vse okoli nje.
Lahko zazna in sledi pešcem, prometnim znakom in drugim vozilom ter jim pomaga pri varni navigaciji. Ali pa pomislite, kako tehnologija za prepoznavanje obraza uporablja računalniški vid za odklepanje naših pametnih telefonov ali preverjanje naše identitete s prepoznavanjem naših edinstvenih obraznih potez.
Uporablja se tudi v nadzornih sistemih za spremljanje gneče in odkrivanje kakršnih koli sumljivih dejavnosti.
Računalniški vid je zmogljiva tehnologija, ki odpira svet možnosti. Če računalnikom omogočimo, da vidijo in razumejo vizualne informacije, lahko razvijemo aplikacije in sisteme, ki lahko zaznavajo in interpretirajo svet okoli nas, zaradi česar je naše življenje lažje, varnejše in učinkovitejše.
13. Klepet
Klepetalni robot je kot računalniški program, ki se lahko pogovarja z ljudmi na način, ki se zdi kot pravi človeški pogovor.
Pogosto se uporablja v spletnih storitvah za stranke, da strankam pomaga in jim daje občutek, kot da se pogovarjajo z osebo, čeprav gre dejansko za program, ki se izvaja v računalniku.
Klepetalni robot lahko razume sporočila ali vprašanja strank in se nanje odzove ter zagotavlja koristne informacije in pomoč, tako kot bi to storil človeški predstavnik službe za stranke.
14. Prepoznavanje govora
Prepoznavanje glasu se nanaša na sposobnost računalniškega sistema, da razume in interpretira človeški govor. Vključuje tehnologijo, ki računalniku ali napravi omogoča, da »posluša« izgovorjene besede in jih pretvori v besedilo ali ukaze, ki jih razume.
z prepoznavanje glasu, lahko komunicirate z napravami ali aplikacijami tako, da preprosto govorite z njimi, namesto da tipkate ali uporabljate druge metode vnosa.
Sistem analizira izgovorjene besede, prepozna vzorce in zvoke ter jih nato prevede v razumljivo besedilo ali dejanja. Omogoča prostoročno in naravno komunikacijo s tehnologijo, kar omogoča opravila, kot so glasovni ukazi, narekovanje ali glasovno nadzorovane interakcije. Najpogostejši primeri so pomočniki AI, kot sta Siri in Google Assistant.
15. Analiza sentimenta
Analiza občutka je tehnika, ki se uporablja za razumevanje in interpretacijo čustev, mnenj in stališč, izraženih v besedilu ali govoru. Vključuje analizo pisnega ali govorjenega jezika, da se ugotovi, ali je izraženo čustvo pozitivno, negativno ali nevtralno.
Z uporabo algoritmov strojnega učenja lahko algoritmi za analizo razpoloženja skenirajo in analizirajo velike količine besedilnih podatkov, kot so ocene strank, objave v družabnih medijih ali povratne informacije strank, da prepoznajo osnovno razpoloženje za besedami.
Algoritmi iščejo določene besede, besedne zveze ali vzorce, ki kažejo na čustva ali mnenja.
Ta analiza pomaga podjetjem ali posameznikom razumeti, kako se ljudje počutijo o izdelku, storitvi ali temi, in jo je mogoče uporabiti za sprejemanje odločitev na podlagi podatkov ali pridobitev vpogleda v želje strank.
Na primer, podjetje lahko uporabi analizo razpoloženja za spremljanje zadovoljstva strank, prepoznavanje področij za izboljšave ali spremljanje javnega mnenja o svoji blagovni znamki.
16. Strojno prevajanje
Strojno prevajanje se v kontekstu umetne inteligence nanaša na uporabo računalniških algoritmov in umetne inteligence za samodejno prevajanje besedila ali govora iz enega jezika v drugega.
Vključuje učenje računalnikov za razumevanje in obdelavo človeških jezikov, da bi zagotovili natančne prevode. Najpogostejši primer je Google prevajalnik.
S strojnim prevajanjem lahko vnesete besedilo ali govor v enem jeziku, sistem pa bo analiziral vnos in ustvaril ustrezen prevod v drugem jeziku. To je še posebej uporabno pri komunikaciji ali dostopu do informacij v različnih jezikih.
Sistemi za strojno prevajanje temeljijo na kombinaciji jezikovnih pravil, statističnih modelov in algoritmov strojnega učenja. Učijo se iz ogromnih količin jezikovnih podatkov, da sčasoma izboljšajo natančnost prevoda. Nekateri pristopi strojnega prevajanja vključujejo tudi nevronske mreže za izboljšanje kakovosti prevodov.
17. Robotika
Robotika je kombinacija umetne inteligence in strojništva za ustvarjanje inteligentnih strojev, imenovanih roboti. Ti roboti so zasnovani za opravljanje nalog samostojno ali z minimalnim človeškim posredovanjem.
Roboti so fizične entitete, ki lahko zaznavajo svoje okolje, sprejemajo odločitve na podlagi teh senzoričnih vnosov in izvajajo določena dejanja ali naloge.
Opremljeni so z različnimi senzorji, kot so kamere, mikrofoni ali senzorji za dotik, ki jim omogočajo zbiranje informacij iz sveta okoli njih. S pomočjo algoritmov umetne inteligence in programiranja lahko roboti analizirajo te podatke, jih interpretirajo in sprejemajo inteligentne odločitve za opravljanje dodeljenih nalog.
Umetna inteligenca igra ključno vlogo v robotiki, saj robotom omogoča učenje iz svojih izkušenj in prilagajanje različnim situacijam.
Algoritme strojnega učenja je mogoče uporabiti za usposabljanje robotov za prepoznavanje predmetov, krmarjenje po okoljih ali celo interakcijo z ljudmi. To robotom omogoča, da postanejo bolj vsestranski, prilagodljivi in sposobni obvladovanja zapletenih nalog.
18 Droni
Droni so vrsta robota, ki lahko leti ali lebdi v zraku brez človeškega pilota. Znani so tudi kot brezpilotna letala (UAV). Droni so opremljeni z različnimi senzorji, kot so kamere, GPS in žiroskopi, ki jim omogočajo zbiranje podatkov in krmarjenje po okolici.
Na daljavo jih upravlja človeški operater ali pa lahko delujejo samostojno z uporabo vnaprej programiranih navodil.
Brezpilotna letala služijo širokemu spektru namenov, vključno z aerofotografiranjem in videografiranjem, geodetstvom in kartiranjem, storitvami dostave, misijami iskanja in reševanja, spremljanjem kmetijstva in celo rekreacijsko uporabo. Lahko dostopajo do oddaljenih ali nevarnih območij, ki so težka ali nevarna za ljudi.
19. Povečana resničnost (AR)
Razširjena resničnost (AR) je tehnologija, ki združuje resnični svet z virtualnimi predmeti ali informacijami, da izboljša naše zaznavanje in interakcijo z okoljem. Računalniško ustvarjene slike, zvoke ali druge senzorične vnose prekriva z resničnim svetom ter ustvarja poglobljeno in interaktivno izkušnjo.
Preprosto povedano, predstavljajte si, da nosite posebna očala ali uporabljate svoj pametni telefon, da vidite svet okoli sebe, vendar z dodanimi dodatnimi virtualnimi elementi.
Svoj pametni telefon lahko na primer usmerite na mestno ulico in si ogledate virtualne smerokaze, ki prikazujejo navodila, ocene in ocene za bližnje restavracije ali celo virtualne like, ki komunicirajo z resničnim okoljem.
Ti virtualni elementi se brezhibno zlijejo z resničnim svetom ter izboljšajo vaše razumevanje in izkušnjo okolice. Razširjeno resničnost je mogoče uporabiti na različnih področjih, kot so igre, izobraževanje, arhitektura in celo za vsakdanja opravila, kot je navigacija ali preizkušanje novega pohištva v vašem domu, preden ga kupite.
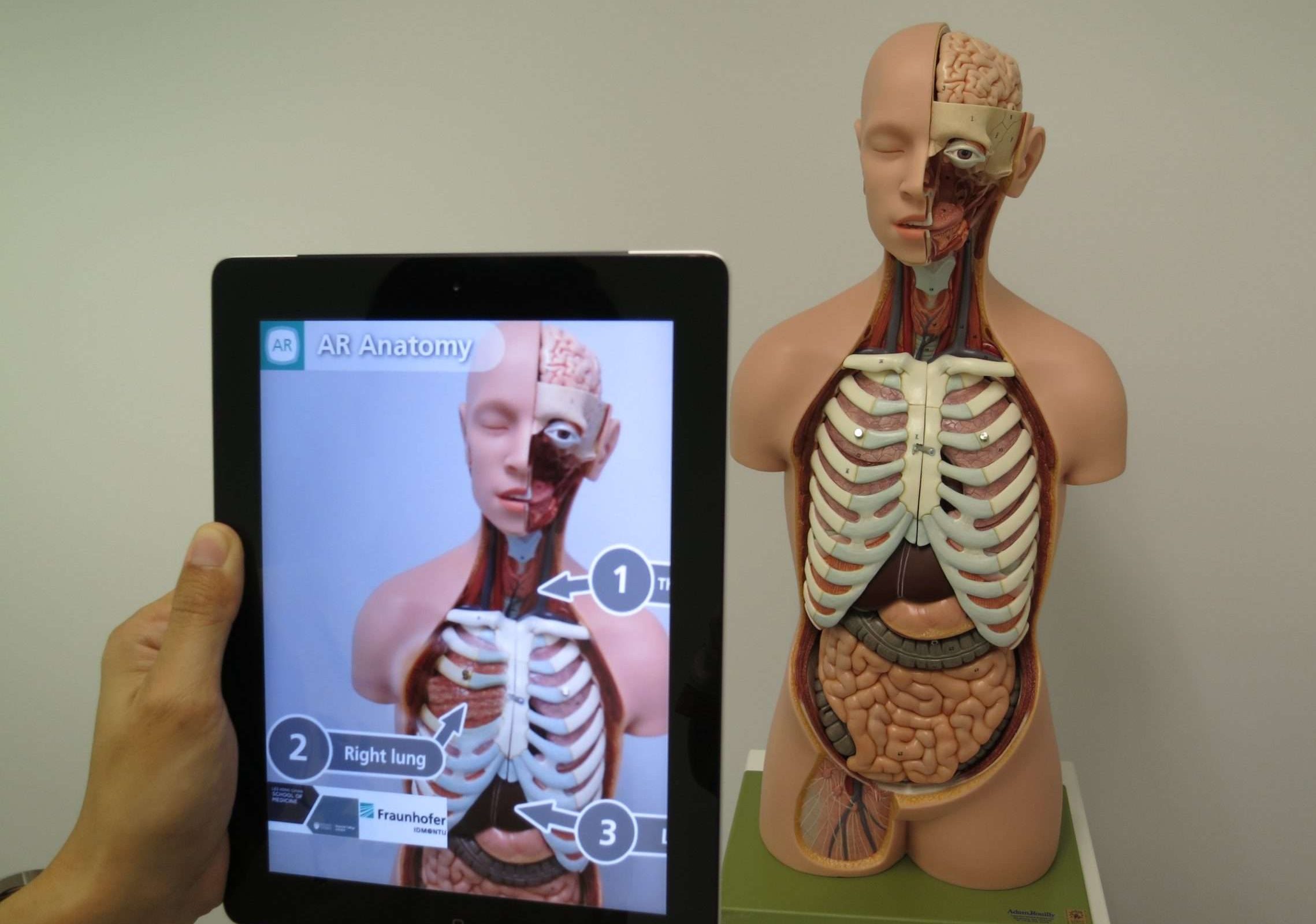
20 Navidezna resničnost (VR)
Virtualna resničnost (VR) je tehnologija, ki uporablja računalniško ustvarjene simulacije za ustvarjanje umetnega okolja, ki ga lahko oseba raziskuje in z njim komunicira. Uporabnika potopi v virtualni svet, blokira resnični svet in ga nadomesti z digitalnim kraljestvom.
Preprosto povedano, predstavljajte si, da si nadenete posebne slušalke, ki vam pokrijejo oči in ušesa ter vas popeljejo na popolnoma drug kraj. V tem virtualnem svetu se zdi vse, kar vidite in slišite, neverjetno resnično, čeprav je vse ustvaril računalnik.
Lahko se premikate, gledate v katero koli smer in komunicirate s predmeti ali liki, kot da bi bili fizično prisotni.
Na primer, v igri navidezne resničnosti se lahko znajdete v srednjeveškem gradu, kjer se lahko sprehodite po njegovih hodnikih, poberete orožje in se udeležite mečevanj z virtualnimi nasprotniki. Okolje virtualne resničnosti se odziva na vaše gibe in dejanja, zaradi česar se počutite popolnoma potopljeni in vključeni v izkušnjo.
Navidezna resničnost se ne uporablja samo za igranje iger, ampak tudi za različne druge aplikacije, kot so simulacije usposabljanja za pilote, kirurge ali vojaško osebje, arhitekturni sprehodi, virtualni turizem in celo terapija za določena psihološka stanja. Ustvarja občutek prisotnosti in uporabnike popelje v nove in vznemirljive virtualne svetove, zaradi česar je izkušnja čim bližja resničnosti.
21. Podatkovna znanost
Znanost o podatkih je področje, ki vključuje uporabo znanstvenih metod, orodij in algoritmov za pridobivanje dragocenega znanja in vpogledov iz podatkov. Združuje elemente matematike, statistike, programiranja in domenskega strokovnega znanja za analizo velikih in zapletenih naborov podatkov.
Preprosteje rečeno, znanost o podatkih je iskanje pomembnih informacij in vzorcev, skritih v množici podatkov. Vključuje zbiranje, čiščenje in organiziranje podatkov ter uporabo različnih tehnik za njihovo raziskovanje in analizo. Podatkovni strokovnjaki uporabljajo statistične modele in algoritme za odkrivanje trendov, napovedovanje in reševanje problemov.
Na področju zdravstvenega varstva se lahko na primer znanost o podatkih uporablja za analizo kartotek pacientov in zdravstvenih podatkov za prepoznavanje dejavnikov tveganja za bolezni, napovedovanje rezultatov za paciente ali optimizacijo načrtov zdravljenja. V poslu je podatkovno znanost mogoče uporabiti za podatke o strankah, da bi razumeli njihove želje, priporočili izdelke ali izboljšali trženjske strategije.
22. Prepir podatkov
Prerekanje podatkov, znano tudi kot zbiranje podatkov, je postopek zbiranja, čiščenja in preoblikovanja neobdelanih podatkov v obliko, ki je bolj uporabna in primerna za analizo. Vključuje obdelavo in pripravo podatkov, da se zagotovi njihova kakovost, doslednost in združljivost z orodji za analizo ali modeli.
Preprosteje rečeno, prepiranje podatkov je kot priprava sestavin za kuhanje. Vključuje zbiranje podatkov iz različnih virov, njihovo razvrščanje in čiščenje, da se odstranijo morebitne napake, nedoslednosti ali nepomembne informacije.
Poleg tega bo morda treba podatke preoblikovati, prestrukturirati ali združiti, da bo lažje delati z njimi in iz njih pridobivati vpoglede.
Prerekanje podatkov lahko na primer vključuje odstranjevanje podvojenih vnosov, popravljanje napak pri črkovanju ali oblikovanju, obravnavanje manjkajočih vrednosti in pretvorbo vrst podatkov. Vključuje lahko tudi združevanje ali združevanje različnih naborov podatkov, razdelitev podatkov na podnabore ali ustvarjanje novih spremenljivk na podlagi obstoječih podatkov.
23. Pripovedovanje podatkov
Pripovedovanje podatkov je umetnost predstavitve podatkov na privlačen in privlačen način za učinkovito posredovanje pripovedi ali sporočila. Vključuje uporabo vizualizacije podatkov, pripovedi in kontekst za posredovanje vpogledov in ugotovitev na način, ki je občinstvu razumljiv in nepozaben.
Preprosteje povedano, pri pripovedovanju podatkov gre za uporabo podatkov za pripovedovanje zgodbe. Presega le predstavitev številk in grafikonov. Vključuje oblikovanje pripovedi okoli podatkov z uporabo vizualnih elementov in tehnik pripovedovanja zgodb, da oživijo podatke in jih naredijo primerljive z občinstvom.
Na primer, namesto preproste predstavitve tabele prodajnih številk lahko pripovedovanje podatkov vključuje ustvarjanje interaktivne nadzorne plošče, ki uporabnikom omogoča vizualno raziskovanje prodajnih trendov.
Vključuje lahko pripoved, ki poudarja ključne ugotovitve, pojasnjuje razloge za trende in predlaga uporabna priporočila na podlagi podatkov.
24. Odločanje na podlagi podatkov
Podatkovno vodeno odločanje je proces odločanja ali ukrepanja na podlagi analize in interpretacije ustreznih podatkov. Vključuje uporabo podatkov kot temelj za usmerjanje in podporo procesov odločanja, namesto da bi se zanašal zgolj na intuicijo ali osebno presojo.
Preprosteje povedano, odločanje na podlagi podatkov pomeni uporabo dejstev in dokazov iz podatkov za obveščanje in vodenje odločitev, ki jih sprejemamo. Vključuje zbiranje in analiziranje podatkov za razumevanje vzorcev, trendov in odnosov ter uporabo tega znanja za sprejemanje premišljenih odločitev in reševanje problemov.
Na primer, v poslovnem okolju lahko odločanje na podlagi podatkov vključuje analizo prodajnih podatkov, povratnih informacij strank in tržnih trendov, da se določi najučinkovitejša cenovna strategija ali prepoznajo področja za izboljšave pri razvoju izdelkov.
V zdravstvu lahko vključuje analizo podatkov o bolnikih za optimizacijo načrtov zdravljenja ali napovedovanje izidov bolezni.
25. Podatkovno jezero
Podatkovno jezero je centralizirano in razširljivo skladišče podatkov, ki shranjuje ogromne količine podatkov v surovi in neobdelani obliki. Zasnovan je za shranjevanje najrazličnejših vrst podatkov, formatov in struktur, kot so strukturirani, polstrukturirani in nestrukturirani podatki, brez potrebe po vnaprej določenih shemah ali transformacijah podatkov.
Podjetje lahko na primer zbira in hrani podatke iz različnih virov, kot so dnevniki spletnih mest, transakcije strank, viri družbenih medijev in naprave IoT, v podatkovnem jezeru.
Te podatke je nato mogoče uporabiti za različne namene, kot je izvajanje napredne analitike, izvajanje algoritmov strojnega učenja ali raziskovanje vzorcev in trendov v vedenju strank.
26. Skladišče podatkov
Skladišče podatkov je specializiran sistem podatkovnih baz, ki je posebej zasnovan za shranjevanje, organiziranje in analiziranje velikih količin podatkov iz različnih virov. Strukturiran je tako, da podpira učinkovito iskanje podatkov in kompleksne analitične poizvedbe.
Služi kot osrednji repozitorij, ki združuje podatke iz različnih operativnih sistemov, kot so transakcijske baze podatkov, sistemi CRM in drugi viri podatkov znotraj organizacije.
Podatki se transformirajo, očistijo in naložijo v podatkovno skladišče v strukturiranem formatu, optimiziranem za analitične namene.
27. Poslovna inteligenca (BI)
Poslovno obveščanje se nanaša na proces zbiranja, analiziranja in predstavljanja podatkov na način, ki podjetjem pomaga sprejemati odločitve na podlagi informacij in pridobiti dragocene vpoglede. Vključuje uporabo različnih orodij, tehnologij in tehnik za pretvorbo neobdelanih podatkov v smiselne in uporabne informacije.
Na primer, sistem poslovne inteligence lahko analizira podatke o prodaji, da prepozna najbolj donosne izdelke, spremlja ravni zalog in sledi željam strank.
Zagotavlja lahko vpogled v ključne kazalnike uspešnosti (KPI) v realnem času, kot so prihodki, pridobivanje strank ali uspešnost izdelka, kar podjetjem omogoča sprejemanje odločitev na podlagi podatkov in sprejemanje ustreznih ukrepov za izboljšanje njihovega poslovanja.
Orodja za poslovno inteligenco pogosto vključujejo funkcije, kot so vizualizacija podatkov, ad hoc poizvedovanje in zmožnosti raziskovanja podatkov. Ta orodja uporabnikom omogočajo, kot npr poslovni analitiki ali menedžerji za interakcijo s podatki, njihovo rezanje in ustvarjanje poročil ali vizualnih predstavitev, ki poudarjajo pomembne vpoglede in trende.
28. Napovedna analitika
Napovedna analiza je praksa uporabe podatkov in statističnih tehnik za pripravo informiranih napovedi ali napovedi o prihodnjih dogodkih ali rezultatih. Vključuje analizo zgodovinskih podatkov, prepoznavanje vzorcev in gradnjo modelov za ekstrapolacijo in oceno prihodnjih trendov, vedenj ali dogodkov.
Njegov cilj je odkriti razmerja med spremenljivkami in uporabiti te informacije za napovedi. Presega zgolj opisovanje preteklih dogodkov; namesto tega uporablja zgodovinske podatke za razumevanje in predvidevanje, kaj se bo verjetno zgodilo v prihodnosti.
Na primer, na področju financ se napovedna analiza lahko uporablja za napovedovanje zaloge cene na podlagi preteklih tržnih podatkov, ekonomskih kazalnikov in drugih pomembnih dejavnikov.
V trženju se lahko uporablja za napovedovanje vedenja in preferenc kupcev, kar omogoča ciljno usmerjeno oglaševanje in prilagojene marketinške akcije.
V zdravstvu lahko napovedna analiza pomaga prepoznati bolnike z velikim tveganjem za določene bolezni ali napovedati verjetnost ponovnega sprejema na podlagi zdravstvene anamneze in drugih dejavnikov.
29. Predpisana analitika
Predpisana analitika je uporaba podatkov in analitike za določitev najboljših možnih ukrepov v določeni situaciji ali scenariju odločanja.
To presega opisno in napovedna analitika ne le z zagotavljanjem vpogledov o tem, kaj se lahko zgodi v prihodnosti, temveč tudi s priporočilom najbolj optimalnega načina ukrepanja za doseganje želenega rezultata.
Združuje zgodovinske podatke, napovedne modele in tehnike optimizacije za simulacijo različnih scenarijev in ovrednotenje možnih izidov različnih odločitev. Upošteva več omejitev, ciljev in dejavnikov za ustvarjanje izvedljivih priporočil, ki povečajo želene rezultate ali zmanjšajo tveganja.
Na primer, v dobavne verige Predpisujoča analitika lahko analizira podatke o ravni zalog, proizvodnih zmogljivostih, transportnih stroških in povpraševanju strank, da določi najučinkovitejši distribucijski načrt.
Lahko priporoči idealno razporeditev virov, kot so lokacije skladiščenja inventarja ali transportne poti, da zmanjša stroške in zagotovi pravočasno dostavo.
30. Podatkovno usmerjeno trženje
Podatkovno usmerjeno trženje se nanaša na prakso uporabe podatkov in analitike za vodenje tržnih strategij, kampanj in postopkov odločanja.
Vključuje uporabo različnih virov podatkov za pridobitev vpogleda v vedenje strank, preference in trende ter uporabo teh informacij za optimizacijo trženjskih prizadevanj.
Osredotoča se na zbiranje in analiziranje podatkov iz več stičnih točk, kot so interakcije s spletnimi stranmi, sodelovanje v družabnih medijih, demografija strank, zgodovina nakupov in več. Ti podatki se nato uporabijo za ustvarjanje celovitega razumevanja ciljne publike, njihovih preferenc in potreb.
Z uporabo podatkov lahko tržniki sprejemajo informirane odločitve glede segmentacije strank, ciljanja in personalizacije.
Prepoznajo lahko specifične segmente strank, za katere je verjetneje, da se bodo pozitivno odzvali na marketinške akcije, in temu primerno prilagodijo svoja sporočila in ponudbe.
Poleg tega trženje, ki temelji na podatkih, pomaga pri optimizaciji tržnih kanalov, določanju najučinkovitejšega trženjskega spleta in merjenju uspeha trženjskih pobud.
Na primer, pristop k trženju, ki temelji na podatkih, lahko vključuje analizo podatkov o strankah za prepoznavanje vzorcev nakupovalnega vedenja in preferenc. Na podlagi teh vpogledov lahko tržniki ustvarijo ciljno usmerjene akcije s prilagojeno vsebino in ponudbami, ki ustrezajo določenim segmentom strank.
S stalno analizo in optimizacijo lahko merijo učinkovitost svojih marketinških prizadevanj in sčasoma izpopolnijo strategije.
31. Upravljanje podatkov
Upravljanje podatkov je okvir in nabor praks, ki jih organizacije sprejmejo, da zagotovijo pravilno upravljanje, zaščito in celovitost podatkov skozi njihov življenjski cikel. Zajema procese, politike in postopke, ki urejajo, kako se podatki zbirajo, shranjujejo, dostopajo do njih, uporabljajo in delijo znotraj organizacije.
Njegov namen je vzpostaviti odgovornost, odgovornost in nadzor nad podatkovnimi sredstvi. Zagotavlja, da so podatki natančni, popolni, dosledni in vredni zaupanja, kar organizacijam omogoča sprejemanje odločitev na podlagi informacij, ohranjanje kakovosti podatkov in izpolnjevanje regulativnih zahtev.
Upravljanje podatkov vključuje opredelitev vlog in odgovornosti za upravljanje podatkov, vzpostavitev podatkovnih standardov in politik ter izvajanje procesov za spremljanje in uveljavljanje skladnosti. Obravnava različne vidike upravljanja podatkov, vključno z zasebnostjo podatkov, varnostjo podatkov, kakovostjo podatkov, klasifikacijo podatkov in upravljanjem življenjskega cikla podatkov.
Na primer, upravljanje podatkov lahko vključuje izvajanje postopkov za zagotovitev, da se z osebnimi ali občutljivimi podatki ravna v skladu z veljavnimi predpisi o zasebnosti, kot je Splošna uredba o varstvu podatkov (GDPR).
Vključuje lahko tudi vzpostavitev standardov kakovosti podatkov in izvajanje postopkov potrjevanja podatkov, da se zagotovi točnost in zanesljivost podatkov.
32. Varnost podatkov
Pri varnosti podatkov gre za varovanje naših dragocenih informacij pred nepooblaščenim dostopom ali krajo. Vključuje sprejemanje ukrepov za zaščito zaupnosti, celovitosti in razpoložljivosti podatkov.
V bistvu to pomeni zagotoviti, da lahko le pravi ljudje dostopajo do naših podatkov, da ostanejo točni in nespremenjeni ter da so na voljo, ko je to potrebno.
Za doseganje varnosti podatkov se uporabljajo različne strategije in tehnologije. Na primer, nadzor dostopa in metode šifriranja pomagajo omejiti dostop pooblaščenim posameznikom ali sistemom, kar otežuje zunanjim osebam dostop do naših podatkov.
Nadzorni sistemi, požarni zidovi in sistemi za zaznavanje vdorov delujejo kot varuhi, nas opozarjajo na sumljive dejavnosti in preprečujejo nepooblaščen dostop.
33. Internet stvari
Internet stvari (IoT) se nanaša na omrežje fizičnih objektov ali »stvari«, ki so povezane z internetom in lahko komunicirajo med seboj. Je kot velika mreža vsakdanjih predmetov, naprav in strojev, ki si lahko izmenjujejo informacije in opravljajo naloge z interakcijo prek interneta.
Preprosto povedano, IoT vključuje dajanje "pametnih" zmogljivosti različnim predmetom ali napravam, ki tradicionalno niso bile povezane z internetom. Ti predmeti lahko vključujejo gospodinjske aparate, nosljive naprave, termostate, avtomobile in celo industrijske stroje.
Če te objekte povežejo z internetom, lahko zbirajo in delijo podatke, prejemajo navodila in izvajajo naloge samostojno ali kot odgovor na ukaze uporabnika.
Pametni termostat lahko na primer spremlja temperaturo, prilagaja nastavitve in pošilja poročila o porabi energije aplikaciji za pametni telefon. Nosljiv fitnes sledilnik lahko zbira podatke o vaših telesnih dejavnostih in jih sinhronizira s platformo v oblaku za analizo.
34. Drevo odločitev
Odločitveno drevo je vizualna predstavitev ali diagram, ki nam pomaga sprejemati odločitve ali določiti smer delovanja na podlagi niza izbir ali pogojev.
Je kot diagram poteka, ki nas vodi skozi proces odločanja z upoštevanjem različnih možnosti in njihovih možnih rezultatov.
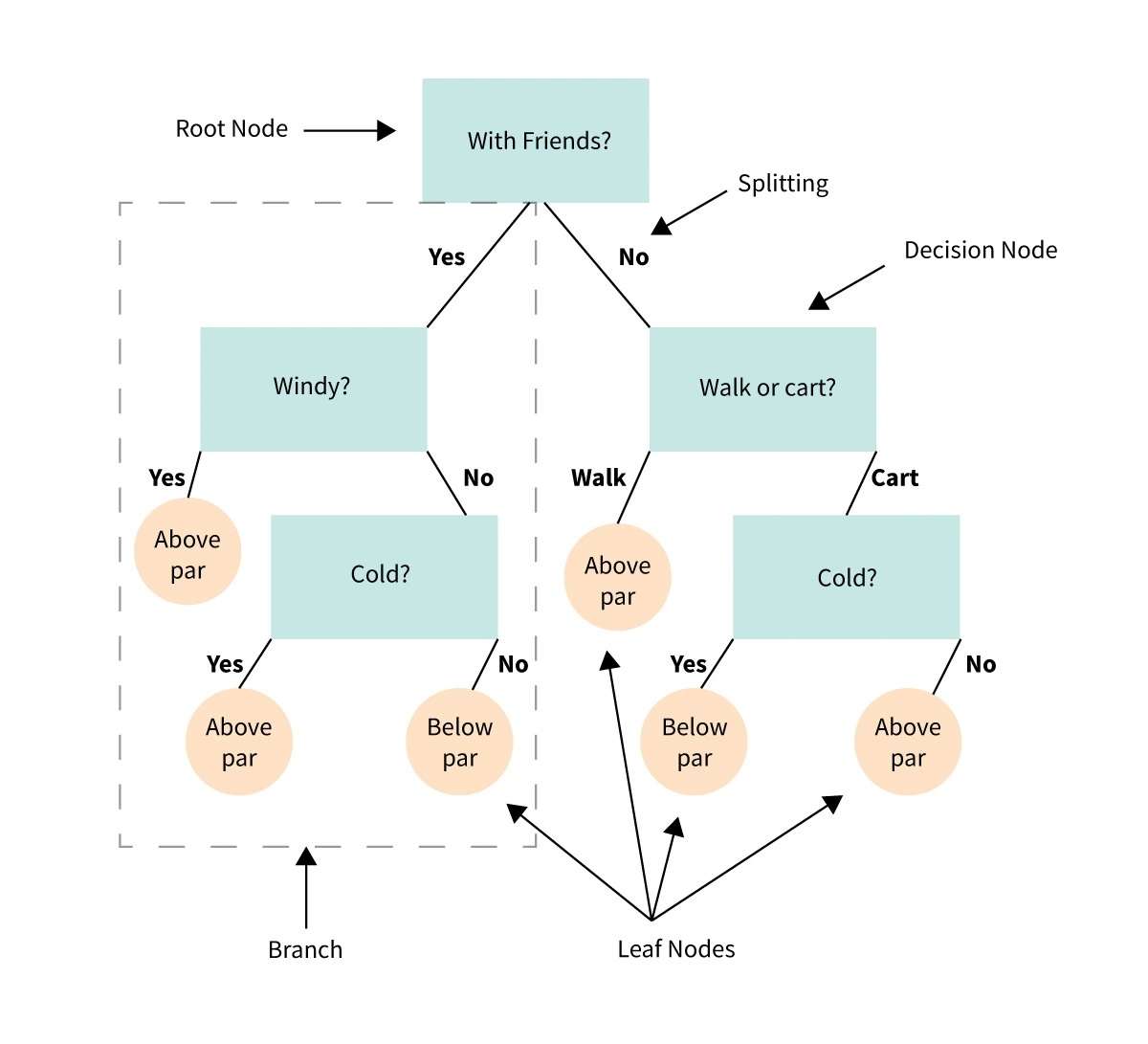
Predstavljajte si, da imate težavo ali vprašanje in se morate odločiti.
Odločitveno drevo odločitev razdeli na manjše korake, ki se začnejo z začetnim vprašanjem in se razvejajo na različne možne odgovore ali dejanja, ki temeljijo na pogojih ali merilih v vsakem koraku.
35. Kognitivno računalništvo
Preprosto povedano, kognitivno računalništvo se nanaša na računalniške sisteme ali tehnologije, ki posnemajo človeške kognitivne sposobnosti, kot so učenje, sklepanje, razumevanje in reševanje problemov.
Vključuje ustvarjanje računalniških sistemov, ki lahko obdelujejo in interpretirajo informacije na način, ki spominja na človeško razmišljanje.
Cilj kognitivnega računalništva je razviti stroje, ki lahko razumejo in komunicirajo z ljudmi na bolj naraven in inteligenten način. Ti sistemi so zasnovani za analizo ogromnih količin podatkov, prepoznavanje vzorcev, napovedovanje in zagotavljanje pomembnih vpogledov.
Zamislite si kognitivno računalništvo kot poskus, da bi računalniki razmišljali in delovali bolj kot ljudje.
Vključuje uporabo tehnologij, kot so umetna inteligenca, strojno učenje, obdelava naravnega jezika in računalniški vid, da se računalnikom omogoči opravljanje nalog, ki so bile tradicionalno povezane s človeško inteligenco.
36. Teorija računalniškega učenja
Teorija računalniškega učenja je specializirana veja na področju umetne inteligence, ki se vrti okoli razvoja in preučevanja algoritmov, posebej zasnovanih za učenje iz podatkov.
To področje raziskuje različne tehnike in metodologije za konstruiranje algoritmov, ki lahko avtonomno izboljšajo svoje delovanje z analizo in obdelavo velikih količin informacij.
Z izkoriščanjem moči podatkov želi teorija računalniškega učenja odkriti vzorce, odnose in vpoglede, ki omogočajo strojem izboljšanje njihovih zmožnosti odločanja in učinkovitejše izvajanje nalog.
Končni cilj je ustvariti algoritme, ki se lahko prilagajajo, posplošujejo in dajejo natančne napovedi na podlagi podatkov, ki so jim bili izpostavljeni, kar prispeva k napredku umetne inteligence in njenih praktičnih aplikacij.
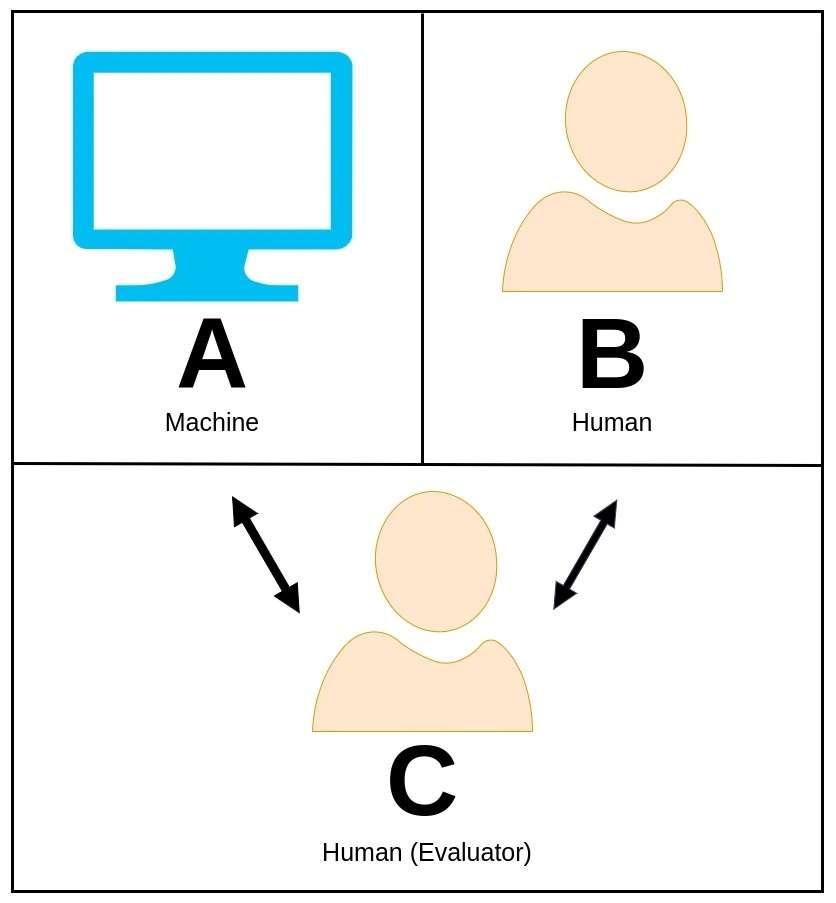
37. Turingov test
Turingov test, ki ga je prvotno predlagal briljantni matematik in računalničar Alan Turing, je očarljiv koncept, ki se uporablja za oceno, ali lahko stroj izkazuje inteligentno vedenje, ki je primerljivo s človeškim ali praktično neločljivo od njega.
V Turingovem testu se človeški ocenjevalec vključi v pogovor v naravnem jeziku s strojem in drugim človeškim udeležencem, ne da bi vedel, kateri je stroj.
Vloga ocenjevalca je, da samo na podlagi njihovih odgovorov ugotovi, katera entiteta je stroj. Če je stroj sposoben prepričati ocenjevalca, da je človeški dvojnik, potem naj bi prestal Turingov test in s tem pokazal raven inteligence, ki odraža človeške sposobnosti.
Alan Turing je predlagal ta test kot sredstvo za raziskovanje koncepta strojne inteligence in za zastavitev vprašanja, ali lahko stroji dosežejo kognicijo na ravni človeka.
Z uokvirjanjem testa v smislu človeške nerazločnosti je Turing poudaril potencial strojev, da pokažejo vedenje, ki je tako prepričljivo inteligentno, da jih postane težko razlikovati od ljudi.
Turingov test je sprožil obsežne razprave in raziskave na področju umetne inteligence in kognitivne znanosti. Čeprav uspešnost Turingovega testa ostaja pomemben mejnik, ni edino merilo inteligence.
Kljub temu test služi kot merilo, ki spodbuja razmišljanje in spodbuja nenehna prizadevanja za razvoj strojev, ki so sposobni posnemati človeško podobno inteligenco in vedenje, ter prispeva k širšemu raziskovanju tega, kaj pomeni biti inteligenten.
38. Učenje s krepitvijo
Okrepitveno učenje je vrsta učenja, ki poteka s poskusi in napakami, kjer se »agent« (ki je lahko računalniški program ali robot) nauči opravljati naloge tako, da prejme nagrade za dobro vedenje in se sooči s posledicami ali kaznimi za slabo vedenje.
Predstavljajte si scenarij, v katerem poskuša agent dokončati določeno nalogo, kot je navigacija po labirintu. Agent sprva ne pozna pravilne poti, zato poskuša z različnimi dejanji in raziskuje različne poti.
Ko izbere dobro dejanje, ki ga približa cilju, prejme nagrado, kot je virtualni "potrepljaj po rami". Če pa sprejme slabo odločitev, ki vodi v slepo ulico ali ga oddalji od cilja, prejme kazen ali negativno povratno informacijo.
Skozi ta proces poskusov in napak se agent nauči povezovati določena dejanja s pozitivnimi ali negativnimi rezultati. Postopoma ugotovi najboljše zaporedje dejanj, da poveča svoje nagrade in zmanjša kazni, na koncu pa postane bolj izkušen pri nalogi.
Učenje s krepitvijo črpa navdih iz tega, kako se ljudje in živali učijo s prejemanjem povratnih informacij iz okolja.
Z uporabo tega koncepta na strojih želijo raziskovalci razviti inteligentne sisteme, ki se lahko učijo in prilagajajo različnim situacijam z avtonomnim odkrivanjem najučinkovitejših vedenj skozi proces pozitivne okrepitve in negativnih posledic.
39. Ekstrakcija entitete
Ekstrakcija entitete se nanaša na postopek, v katerem prepoznamo in izvlečemo pomembne dele informacij, znane kot entitete, iz bloka besedila. Te entitete so lahko različne stvari, kot so imena ljudi, imena krajev, imena organizacij itd.
Recimo, da imate odstavek, ki opisuje novico.
Ekstrakcija entitet bi vključevala analizo besedila in izbiranje določenih bitov, ki predstavljajo različne entitete. Na primer, če je v besedilu omenjeno ime osebe, kot je »John Smith«, lokacija »New York City« ali organizacija »OpenAI«, bi bile to entitete, ki jih želimo identificirati in izluščiti.
Z ekstrakcijo entitet v bistvu učimo računalniški program, da prepozna in izolira pomembne elemente iz besedila. Ta postopek nam omogoča učinkovitejšo organizacijo in kategorizacijo informacij, kar olajša iskanje, analizo in pridobivanje vpogledov iz velikih količin besedilnih podatkov.
Na splošno nam ekstrakcija entitet pomaga avtomatizirati nalogo natančnega določanja pomembnih entitet, kot so ljudje, kraji in organizacije, znotraj besedila, kar poenostavi ekstrakcijo dragocenih informacij in izboljša našo sposobnost obdelave in razumevanja besedilnih podatkov.
40. Jezikoslovna opomba
Jezikovna opomba vključuje obogatitev besedila z dodatnimi jezikovnimi informacijami za izboljšanje našega razumevanja in analize uporabljenega jezika. To je kot dodajanje uporabnih nalepk ali oznak različnim delom besedila.
Ko izvajamo jezikovno opombo, presežemo osnovne besede in stavke v besedilu in začnemo označevati ali označevati določene elemente. Na primer, lahko dodamo delne oznake, ki označujejo slovnično kategorijo vsake besede (na primer samostalnik, glagol, pridevnik itd.). To nam pomaga razumeti vlogo, ki jo ima vsaka beseda v stavku.
Druga oblika jezikovnega označevanja je prepoznavanje poimenovanih entitet, kjer prepoznamo in označimo določene poimenovane entitete, kot so imena ljudi, krajev, organizacij ali datumov. To nam omogoča, da hitro poiščemo in izluščimo pomembne informacije iz besedila.
Z označevanjem besedila na te načine ustvarimo bolj strukturirano in organizirano predstavitev jezika. To je lahko izjemno uporabno v različnih aplikacijah. Na primer, pomaga izboljšati natančnost iskalnikov z razumevanjem namena za uporabniškimi poizvedbami. Pomaga tudi pri strojnem prevajanju, analizi razpoloženja, pridobivanju informacij in številnih drugih nalogah obdelave naravnega jezika.
Jezikovna opomba služi kot bistveno orodje za raziskovalce, jezikoslovce in razvijalce, ki jim omogoča preučevanje jezikovnih vzorcev, gradnjo jezikovnih modelov in razvoj sofisticiranih algoritmov, ki lahko bolje analizirajo in razumejo besedilo.
41. Hiperparameter
In strojno učenje, je hiperparameter kot posebna nastavitev ali konfiguracija, za katero se moramo odločiti, preden urimo model. To ni nekaj, česar se lahko model sam nauči iz podatkov; namesto tega ga moramo določiti vnaprej.
Predstavljajte si to kot gumb ali stikalo, ki ga lahko prilagodimo, da natančno prilagodimo, kako se model uči in daje napovedi. Ti hiperparametri urejajo različne vidike učnega procesa, kot so kompleksnost modela, hitrost usposabljanja in kompromis med natančnostjo in posploševanjem.
Na primer, razmislimo o nevronski mreži. Eden od pomembnih hiperparametrov je število plasti v omrežju. Izbrati moramo, kako globoko želimo imeti omrežje, in ta odločitev vpliva na njegovo sposobnost zajemanja zapletenih vzorcev v podatkih.
Drugi pogosti hiperparametri vključujejo stopnjo učenja, ki določa, kako hitro model prilagodi svoje notranje parametre na podlagi podatkov o usposabljanju, in moč regulacije, ki nadzoruje, koliko model kaznuje kompleksne vzorce, da prepreči prekomerno prilagajanje.
Pravilna nastavitev teh hiperparametrov je ključnega pomena, saj lahko znatno vplivajo na zmogljivost in obnašanje modela. Pogosto vključuje nekaj poskusov in napak, eksperimentiranje z različnimi vrednostmi in opazovanje, kako vplivajo na delovanje modela na naboru podatkov o validaciji.
42. Metapodatki
Metapodatki se nanašajo na dodatne informacije, ki zagotavljajo podrobnosti o drugih podatkih. Je kot niz oznak ali oznak, ki nam dajejo več konteksta ali opisujejo značilnosti glavnih podatkov.
Ko imamo podatke, ne glede na to, ali gre za dokument, fotografijo, videoposnetek ali katero koli drugo vrsto informacije, nam metapodatki pomagajo razumeti pomembne vidike teh podatkov.
Na primer, v dokumentu lahko metapodatki vključujejo podrobnosti, kot so ime avtorja, datum, ko je bil ustvarjen, ali oblika datoteke. V primeru fotografije nam lahko metapodatki povedo lokacijo, kjer je bila posneta, uporabljene nastavitve fotoaparata ali celo datum in čas, ko je bila posneta.
Metapodatki nam pomagajo organizirati, iskati in učinkoviteje razlagati podatke. Z dodajanjem teh opisnih informacij lahko hitro najdemo določene datoteke ali razumemo njihov izvor, namen ali kontekst, ne da bi morali brskati po celotni vsebini.
43. Zmanjšanje dimenzij
Zmanjšanje dimenzij je tehnika, ki se uporablja za poenostavitev nabora podatkov z zmanjšanjem števila funkcij ali spremenljivk, ki jih vsebuje. To je kot zgoščevanje ali povzemanje informacij v naboru podatkov, da bi bilo lažje obvladljivo in z njim lažje delati.
Predstavljajte si, da imate nabor podatkov s številnimi stolpci ali atributi, ki predstavljajo različne značilnosti podatkovnih točk. Vsak stolpec povečuje kompleksnost in računalniške zahteve algoritmov strojnega učenja.
V nekaterih primerih je lahko zaradi velikega števila razsežnosti iskanje pomembnih vzorcev ali odnosov v podatkih težko.
Zmanjšanje dimenzionalnosti pomaga rešiti to težavo s preoblikovanjem nabora podatkov v nizkodimenzionalno predstavitev, pri čemer ohrani čim več ustreznih informacij. Njegov namen je zajeti najpomembnejše vidike ali variacije v podatkih, medtem ko zavrže odvečne ali manj informativne dimenzije.
44. Klasifikacija besedila
Klasifikacija besedila je postopek, ki vključuje dodeljevanje posebnih oznak ali kategorij blokom besedila glede na njihovo vsebino ali pomen. To je kot razvrščanje ali organiziranje besedilnih informacij v različne skupine ali razrede za lažjo nadaljnjo analizo ali sprejemanje odločitev.
Oglejmo si primer klasifikacije e-pošte. V tem scenariju želimo ugotoviti, ali je dohodna e-pošta vsiljena pošta ali ne (znana tudi kot ham). Razvrstitev besedila algoritmi analizirajo vsebino elektronske pošte in ji dodelijo ustrezno oznako.
Če algoritem ugotovi, da ima e-poštno sporočilo značilnosti, ki so običajno povezane z vsiljeno pošto, dodeli oznako »neželena pošta«. Nasprotno, če je e-poštno sporočilo videti legitimno in ne vsebuje neželene pošte, dodeli oznako »ni vsiljena pošta« ali »ham«.
Klasifikacija besedila najde aplikacije na različnih področjih poleg filtriranja e-pošte. Uporablja se pri analizi razpoloženja za določanje razpoloženja, izraženega v ocenah strank (pozitivno, negativno ali nevtralno).
Novičarske članke je mogoče razvrstiti v različne teme ali kategorije, kot so šport, politika, zabava itd. Dnevnike klepetov podpore strankam je mogoče kategorizirati glede na namen ali težavo, ki se obravnava.
45. Šibek AI
Šibka umetna inteligenca, znana tudi kot ozka umetna inteligenca, se nanaša na sisteme umetne inteligence, ki so zasnovani in programirani za izvajanje določenih nalog ali funkcij. Za razliko od človeške inteligence, ki zajema širok razpon kognitivnih sposobnosti, je šibka umetna inteligenca omejena na določeno področje ali nalogo.
Šibko umetno inteligenco si predstavljajte kot specializirano programsko opremo ali stroje, ki blestijo pri opravljanju določenih nalog. Na primer, program umetne inteligence za igranje šaha je lahko ustvarjen za analizo situacij v igri, strategijo potez in tekmovanje s človeškimi igralci.
Drug primer je sistem za prepoznavanje slik, ki lahko identificira predmete na fotografijah ali videoposnetkih.
Ti sistemi umetne inteligence so usposobljeni in optimizirani za uspeh na svojih specifičnih strokovnih področjih. Za učinkovito izpolnjevanje svojih nalog se zanašajo na algoritme, podatke in vnaprej določena pravila.
Vendar pa nimajo splošne inteligence, ki bi jim omogočala razumevanje ali opravljanje nalog zunaj njihovega določenega področja.
46. Močan AI
Močna umetna inteligenca, znana tudi kot splošna umetna inteligenca ali umetna splošna inteligenca (AGI), se nanaša na obliko umetne inteligence, ki ima sposobnost razumevanja, učenja in izvajanja katere koli intelektualne naloge, ki jo lahko človek.
Za razliko od šibke umetne inteligence, ki je zasnovana za posebne naloge, je močna umetna inteligenca namenjena posnemanju človeške inteligence in kognitivnih sposobnosti. Prizadeva si ustvariti stroje ali programsko opremo, ki ne blestijo samo pri specializiranih nalogah, temveč imajo tudi širše razumevanje in prilagodljivost za spopadanje s širokim naborom intelektualnih izzivov.
Cilj močne umetne inteligence je razviti sisteme, ki lahko sklepajo, razumejo kompleksne informacije, se učijo iz izkušenj, sodelujejo v pogovorih v naravnem jeziku, izkazujejo ustvarjalnost in izkazujejo druge lastnosti, povezane s človeško inteligenco.
V bistvu si prizadeva ustvariti sisteme umetne inteligence, ki lahko simulirajo ali posnemajo razmišljanje in reševanje problemov na ravni človeka na več področjih.
47. Naprej veriženje
Naprejšnje veriženje je metoda sklepanja ali logike, ki se začne z razpoložljivimi podatki in jih uporablja za sklepanje in nove zaključke. To je kot povezovanje pik z uporabo dostopnih informacij za napredovanje in doseganje dodatnih vpogledov.
Predstavljajte si, da imate nabor pravil ali dejstev in želite na podlagi njih pridobiti nove informacije ali doseči določene zaključke. Veriženje naprej deluje tako, da preuči začetne podatke in uporabi logična pravila za ustvarjanje dodatnih dejstev ali zaključkov.
Za poenostavitev si oglejmo preprost scenarij določanja, kaj obleči glede na vremenske razmere. Imate pravilo, ki pravi: "Če dežuje, prinesite dežnik," in drugo pravilo, ki pravi: "Če je mraz, oblecite jakno." Zdaj, če opazite, da res dežuje, lahko uporabite veriženje naprej, da sklepate, da bi morali prinesti dežnik.
48. Povratno veriženje
Veriženje nazaj je metoda sklepanja, ki se začne z želenim zaključkom ali ciljem in deluje nazaj, da določi potrebne podatke ali dejstva, potrebna za podporo tega sklepa. To je kot sledenje korakom od želenega rezultata do začetnih informacij, potrebnih za njegovo dosego.
Da bi razumeli veriženje nazaj, si oglejmo preprost primer. Recimo, da želite ugotoviti, ali je primerno za kopanje. Želeni sklep je, ali je plavanje primerno glede na določene pogoje ali ne.
Namesto da bi začeli s pogoji, se veriženje nazaj začne z zaključkom in deluje nazaj, da bi našli podporne podatke.
V tem primeru bi veriženje nazaj vključevalo postavljanje vprašanj, kot je "Ali je vreme toplo?" Če je odgovor pritrdilen, bi potem vprašali: "Ali je na voljo bazen?" Če je odgovor spet pritrdilen, bi postavili dodatna vprašanja, kot je: "Ali je dovolj časa, da gremo plavat?"
Z iterativnim odgovarjanjem na ta vprašanja in delom nazaj lahko določite potrebne pogoje, ki morajo biti izpolnjeni, da podprete sklep, da greste plavat.
49. Hevristika
Preprosto povedano, hevristika je praktično pravilo ali strategija, ki nam pomaga sprejemati odločitve ali reševati težave, običajno na podlagi naših preteklih izkušenj ali intuicije. Je kot miselna bližnjica, ki nam omogoča, da hitro pridemo do razumne rešitve, ne da bi šli skozi dolgotrajen ali izčrpen postopek.
Ko se soočimo s kompleksnimi situacijami ali nalogami, hevristika služi kot vodilna načela ali "pravila palca", ki poenostavijo odločanje. Zagotavljajo nam splošne smernice ali strategije, ki so pogosto učinkovite v določenih situacijah, čeprav morda ne zagotavljajo optimalne rešitve.
Na primer, razmislimo o hevristiki za iskanje parkirnega mesta v gneči. Namesto natančnega analiziranja vsakega razpoložljivega mesta se lahko zanašate na hevristiko iskanja parkiranih avtomobilov s prižganimi motorji.
Ta hevristika predvideva, da bodo ti avtomobili kmalu odšli, kar povečuje možnosti, da najdejo prosto mesto.
50. Modeliranje naravnega jezika
Modeliranje naravnega jezika, preprosto povedano, je proces usposabljanja računalniških modelov za razumevanje in ustvarjanje človeškega jezika na način, ki je podoben načinu, kako ljudje komunicirajo. Vključuje učenje računalnikov za obdelavo, interpretacijo in ustvarjanje besedila na naraven in smiseln način.
Cilj modeliranja naravnega jezika je omogočiti računalnikom razumevanje in ustvarjanje človeškega jezika na način, ki je tekoč, koherenten in kontekstualno ustrezen.
Vključuje učne modele na ogromnih količinah besedilnih podatkov, kot so knjige, članki ali pogovori, za učenje vzorcev, struktur in semantike jezika.
Ko so usposobljeni, lahko ti modeli izvajajo različne naloge, povezane z jezikom, kot so jezikovno prevajanje, povzemanje besedila, odgovarjanje na vprašanja, interakcije chatbotov in še več.
Lahko razumejo pomen in kontekst stavkov, izluščijo pomembne informacije in ustvarijo besedilo, ki je slovnično pravilno in koherentno.





Pustite Odgovori