Важность перемещения и хранения данных возросла в результате постоянного расширения ИТ-индустрии и миллионов точек данных, которые создаются каждую секунду.
Кроме того, эти данные должны быть четкими и простыми для понимания, чтобы поддерживать точное принятие решений.
Для поддержания конкурентоспособности и достижения долгосрочного успеха ваша компания должна хранить и перемещать данные, используя самые эффективные доступные решения.
Из-за этого все больше компаний используют фабрики данных. Один из лучших способов сэкономить ваше время, деньги и ресурсы — использовать структуру данных для обработки данных и включения машинного обучения ИИ.
В этой статье мы подробно рассмотрим Data Fabric, включая ее использование, основные компоненты, преимущества и другие важные детали.
Итак, что такое Data Fabric?
Независимо от того, где они находятся, управляйте и следите за своими данными и приложениями. По своей сути фабрика данных представляет собой интегрированную архитектуру данных, которая является безопасной, универсальной и адаптируемой.
Фабрика данных, которая сочетает в себе лучшее из облака, ядра и периферии, во многом представляет собой новый стратегический подход к работе вашего бизнес-хранилища.
Несмотря на централизованное управление, он может работать везде, включая локальные, общедоступные и частные облака, а также периферийные устройства и устройства IoT.
Хранилища данных размером с небоскреб и разнообразные несвязанные инфраструктуры остались в прошлом. Структура данных основана на комплексном наборе инструментов управления данными, которые гарантируют согласованность во всех связанных средах.
Автоматизация оптимизирует трудоемкое управление, ускоряет разработку, тестирование и развертывание, а также обеспечивает круглосуточную защиту ваших активов.
Независимо от того, где находятся ваши данные и приложения, вы можете отслеживать расходы на хранение, производительность и эффективность с единой платформы.
Вы можете быстро (а в некоторых случаях и автоматически) вносить изменения в свою гибридную облачную инфраструктуру, если у вас есть практические знания о ней, такие как исправление ошибок, решение проблем с безопасностью и соответствием требованиям, а также масштабирование вычислений.
Вкратце, Data Fabric повышает эффективность развертывания и обслуживания инфраструктуры, снижает затраты и повышает производительность.
Почему вам следует использовать Data Fabric?
Любая компания, ориентированная на данные, нуждается в комплексной стратегии, которая преодолевает такие препятствия, как время, пространство, различные виды программного обеспечения и расположение данных. Данные не должны быть скрыты за брандмауэрами или рассредоточены по нескольким местам, а должны быть доступны для людей, которым они нужны.
Чтобы добиться успеха, компаниям требуется перспективное решение для обработки данных, а также безопасная, эффективная и унифицированная среда. Это можно сделать с помощью фабрики данных.
Потребности современного бизнеса в подключении в режиме реального времени, самообслуживании, автоматизации и универсальных изменениях не могут быть удовлетворены за счет традиционной интеграции данных.
Хотя сбор данных из многих источников часто не является проблемой, многим предприятиям сложно интегрировать, обрабатывать, курировать и преобразовывать данные с данными из других источников.
Чтобы получить более глубокое представление о потребителях, партнерах и товарах, необходимо сделать этот важный шаг в процессе управления данными. Благодаря их способности модернизировать свои системы, лучше обслуживать клиентов и использовать облачных вычисленийВ результате фирмы получают конкурентное преимущество.
Где бы ни находились пользователи организации, фабрику данных можно представить как ткань, раскинувшуюся по всему миру. В этой сети пользователь может находиться в любом месте и при этом иметь неограниченный доступ в режиме реального времени к данным в любом другом месте.
Основные компоненты Data Fabric
Основные компоненты, из которых состоит структура данных, можно выбирать и собирать различными способами. Таким образом, структура данных может быть реализована различными способами. Давайте рассмотрим основные элементы структуры данных.
- Расширенный каталог данных
- Слой стойкости
- График знаний
- Механизм анализа и рекомендаций
- Уровень подготовки данных и доставки данных
- Оркестрация и операции с данными
Вы можете ознакомиться с ключевыми столпами архитектуры Data Fabric в соответствии с Gartner.
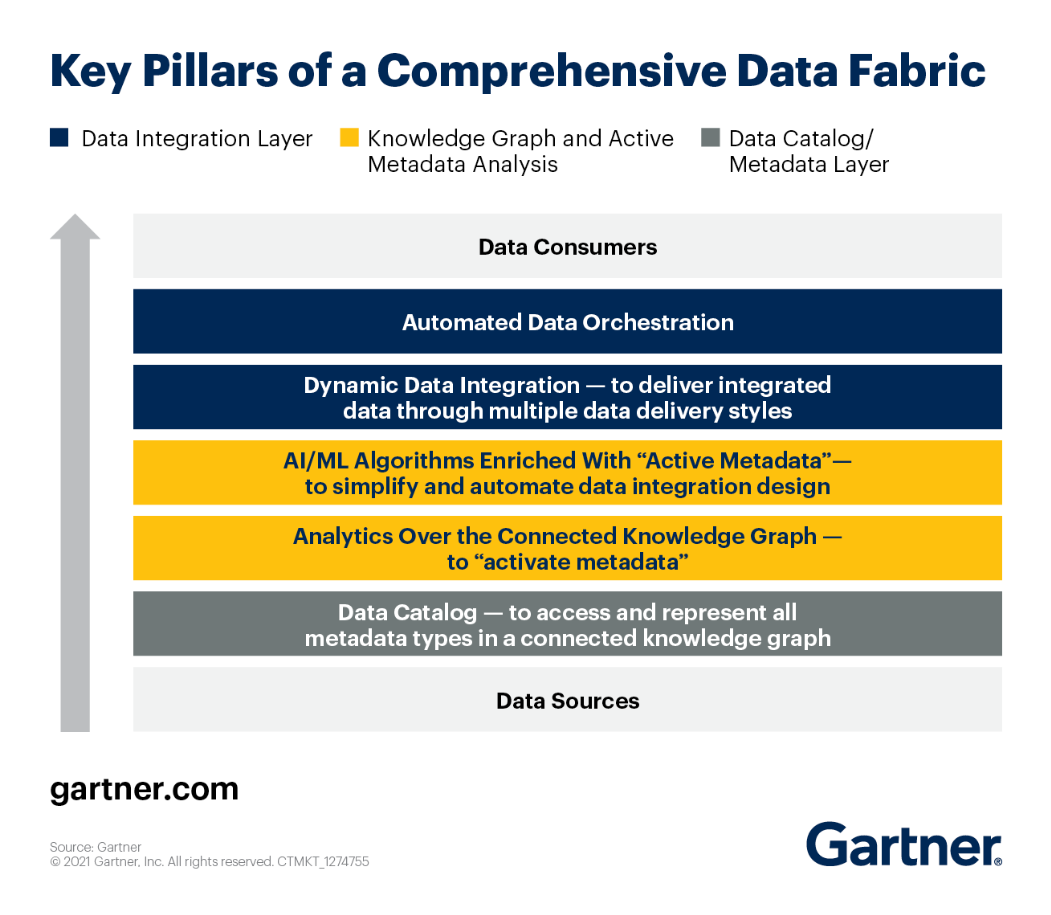
Давайте внимательно рассмотрим каждый из них.
- Расширенный каталог данных – предоставляет пользователям доступ ко всем видам метаданных через надежный граф знаний. Кроме того, он развивает отличительные ассоциации между существующей информацией и визуально показывает ее в понятной форме. Используя обучение с помощью машины чтобы связать активы данных с организационной терминологией, расширенные каталоги данных создают бизнес-семантический уровень для структуры данных.
- Слой стойкости – В зависимости от варианта использования для динамического хранения данных могут использоваться различные реляционные и нереляционные модели.
- Активные метаданные – отличительная часть структуры данных. дает фабрике данных возможность собирать, совместно использовать и анализировать многие виды метаданных. В отличие от пассивных метаданных, активные метаданные отслеживают текущее использование данных системами и людьми (метаданные на основе проектирования и во время выполнения).
- График знаний – Еще одна фундаментальная единица для фабрик данных. Они используют стандартные идентификаторы, адаптируемые схемы и т. д. для отображения связанной среды данных. Графы знаний делают структуру данных доступной для поиска и помогают в ее понимании.
- Система анализа и рекомендаций – создает надежные и надежные конвейеры данных как для оперативного, так и для аналитического использования.
- Уровень подготовки данных и доставки данных – Данные можно извлекать из любого источника и отправлять любой цели с использованием любого механизма, включая ETL (массовую передачу), обмен сообщениями, CDC, виртуализацию и API.
- Оркестрация и операции с данными – Этот компонент использует данные для координации всех задач на каждом этапе сквозного рабочего процесса. Это позволяет вам выбирать, когда и как часто запускать конвейеры, а также как управлять данными, которые производят эти конвейеры.
Преимущества
Здоровые данные в распределенном контексте доступны, загружаются, интегрируются и совместно используются в структуре данных. Делая это, предприятия могут ускорить цифровой переход и максимизировать ценность своих данных.
Ниже описаны основные преимущества модели фабрики данных.
Эффективность:
Структура данных может компилировать результаты более ранних запросов, позволяя системе сканировать агрегированную таблицу, а не необработанные данные в серверной части.
Из-за более быстрого времени отклика на отдельные запросы предоставление запросам доступа к меньшим наборам данных вместо сканирования необработанных данных всего хранилища также решает проблему нескольких одновременных запросов.
Предприятия могут быстро отвечать на срочные запросы благодаря способности структуры данных значительно сократить время ответа на запрос.
Умная интеграция
Для интеграции данных из различных типов данных и конечных точек в структурах данных используются графы семантических знаний, управление метаданными и машинное обучение.
Это помогает командам по управлению данными группировать соответствующие наборы данных и включать совершенно новые источники данных в экосистему данных компании.
Эта функция автоматизирует части управления задачами с данными, что приводит к указанной выше экономии производительности, но также помогает разбивать разрозненные системы данных, централизовать процедуры управления данными и повышать общее качество данных.
Более эффективная защита данных
Это также не означает жертвовать безопасностью данных и защитой конфиденциальности ради расширения доступа к данным.
На самом деле это требует ужесточения барьеров контроля доступа и реализации дополнительных мер управления данными, чтобы гарантировать, что определенные роли являются единственными, кто имеет доступ к заданному набору данных.
Кроме того, архитектура фабрики данных обеспечивает техническую и службы безопасности внедряют маскировку данных и шифрование конфиденциальной и конфиденциальной информации, что снижает вероятность обмена данными и взлома системы.
Демократизация данных
Приложения самообслуживания облегчаются структурой данных, расширяя доступ к данным за пределы более технического персонала, такого как инженеры данных, разработчики и группы аналитиков данных.
Позволяя бизнес-пользователям быстрее принимать бизнес-решения и позволяя техническим пользователям расставлять приоритеты в действиях, которые наилучшим образом используют их навыки, устранение узких мест в данных приводит к повышению производительности.
Use cases
Архитектура фабрики данных призвана предложить всеобъемлющую структуру для обработки всех форм хранимой информации, чтобы их можно было использовать при необходимости.
Эти виды данных можно использовать для чего угодно: от прогноза продаж до отчета о состоянии ИТ-инфраструктуры организации или конечных точек пользователей.
Варианты использования архитектуры структуры данных идентичны вариантам использования любых других данных в бизнесе, включая продажи, маркетинг, ИТ, кибербезопасность и т. д.
Однако данные в организации часто бывают организованными, полуструктурированными или неструктурированными почти во всех случаях использования. Реляционная база данных может хранить структурированные данные и быстро использоваться, например, записи базы данных.
Данные, которые не были очищены или классифицированы, называются неструктурированными данными и должны быть подготовлены для использования при необходимости.
Несколько форм неструктурированных данных, которые многие фирмы могут приобретать и хранить для будущего использования, включают: обучение с помощью машины, аналитика, данные датчиков, облачные вычисления и приложения для повышения производительности.
В полуструктурированных данных, которые включают в себя данные распознанного типа, сохраненные с неструктурированными данными (например, zip-файлы, веб-страницы и электронные письма), присутствуют оба аспекта.
Многочисленные возможные варианты использования, основанные на способности фабрики данных помочь компаниям в более быстром и эффективном доступе к своим данным и их использовании, могут быть обнаружены путем исследования ее использования.
Типичные примеры включают:
- Обнаружение мошенничества
- IoT аналитика
- Логистика цепочки поставок
- Аналитика данных в реальном времени
- Интеллект клиентов
- Повышение операционной эффективности
- Анализ планово-предупредительного ремонта
- Кроме того, модели риска возвращения на работу
- Безопасность транзакций с кредитными картами
- Прогнозирование оттока, обнаружение мошенничества и кредитный скоринг
Заключение
В заключение, хранилища данных должны постепенно распадаться по мере увеличения уровня использования данных, чтобы освободить место для связанных компаний.
Развертывание фабрик данных представляет собой значительный шаг вперед на этом пути и входит в число самых новаторских открытий с момента разработки реляционных баз данных в 1970-х годах.
Это связано с тем, что фабрика данных — это больше, чем технология или отдельный элемент..
Данные и бизнес-операции неразрывно переплетаются благодаря дизайну архитектуры, систематической процедуре и изменению менталитета.
Data Fabric снижает затраты, повышает производительность и способствует более эффективному развертыванию и обслуживанию инфраструктуры. Это может быть ключевым компонентом для обеспечения того, чтобы каждый процесс, приложение и бизнес-решение управлялись данными.





Оставьте комментарий