Диффузионные модели штурмом захватили мир с выпуском Далл-Э 2, Имиджэн от Google, Стабильная диффузияи Середина пути, стимулируя инновации и расширяя границы машинного обучения.
Эти модели могут создавать практически неограниченное количество изображений из словесных подсказок, включая фотореалистичные, волшебные, футуристические и, конечно же, милые изображения.
Эти возможности переосмысливают то, что для людей означает взаимодействие с кремнием, давая нам возможность создавать практически любую картину, которую мы можем себе представить.
По мере развития этих моделей или прихода к власти следующей генеративной парадигмы люди смогут создавать изображения, фильмы и другие иммерсивные впечатления, используя только мысль.
В этом посте мы обсудим диффузионная модель, стабильная диффузия, как это работает, а также учебник по рисованию модели диффузии, среди прочего.
Что такое Диффузионная модель?
Модели машинного обучения, которые могут создавать новые данные из обучающих данных, называются генеративными моделями. Другие генеративные модели включают модели на основе потоков, вариационные автокодировщики и генеративно-состязательные сети (GAN).
Каждый может генерировать изображения отличного качества. Диффузионные модели учатся восстанавливать данные, обращая этот процесс добавления шума после повреждения обучающих данных добавлением шума. Иными словами, диффузионные модели способны создавать связные изображения из шума.
Диффузионные модели учатся, добавляя к изображениям шум, который позже модель научается удалять. Чтобы создать реалистичные визуальные эффекты, модель затем применяет этот метод шумоподавления к случайным начальным значениям.
Обусловливая процесс создания изображений, эти модели можно использовать в сочетании с руководством по преобразованию текста в изображение для создания почти неограниченного количества изображений только из текста. Семена могут направляться входными данными от вложений, таких как CLIP, чтобы обеспечить мощные возможности преобразования текста в изображение.
Модели диффузии могут выполнять множество задач, включая создание изображения, шумоподавление изображения, закрашивание, закрашивание и диффузию битов.
Итак, что такое стабильная диффузия?
Stable Diffusion — это модель машинного обучения для создания текстовых изображений, предоставляемая Стабильность.ИИ. Он способен генерировать изображения из текста.
Компоненты стабильной диффузии
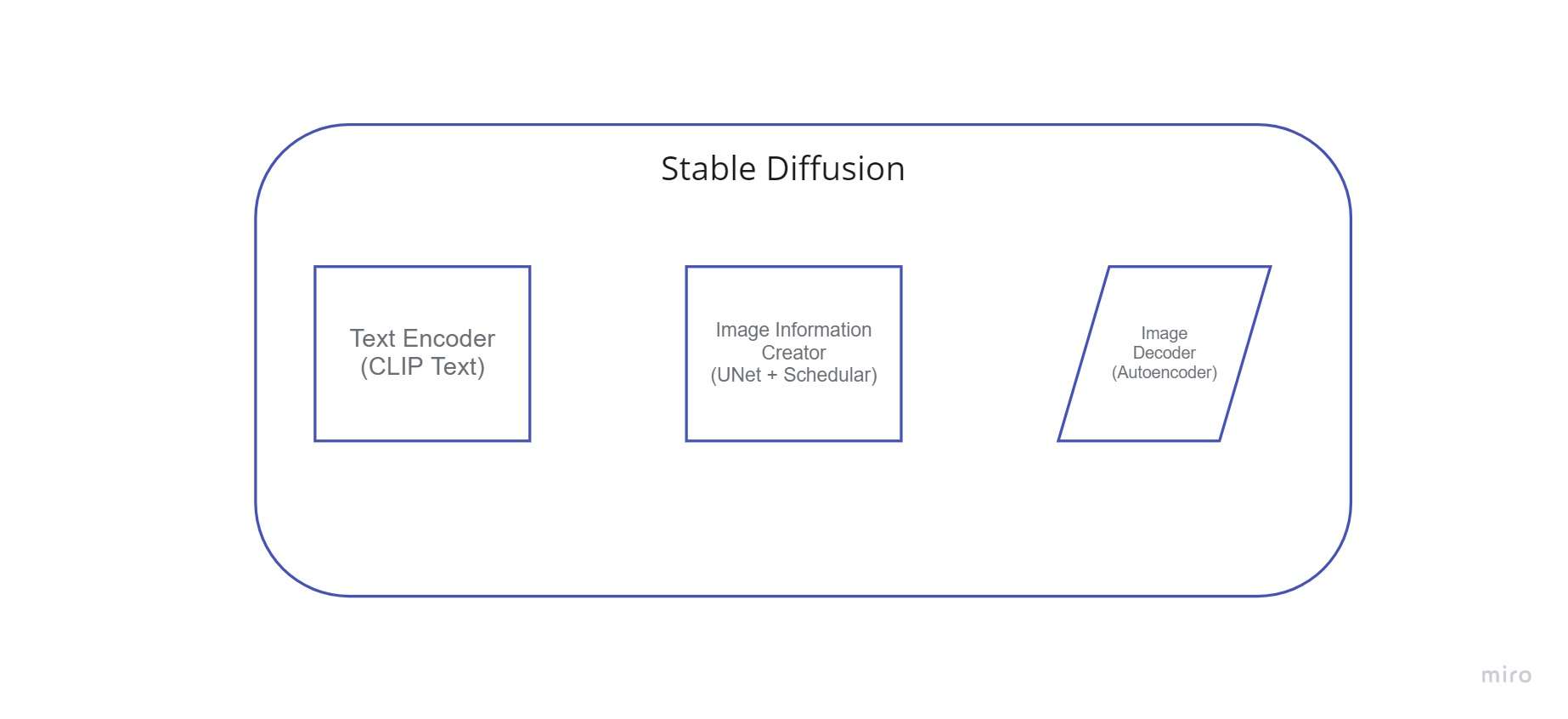
Стабильная диффузия представляет собой систему, состоящую из нескольких компонентов и концепций. Это не одна модель. Когда мы проверяем, что скрывается за капотом, первое, что мы видим, это наличие компонента понимания текста, который преобразует текстовую информацию в числовое представление, которое фиксирует концепции текста.
Мы можем назвать этот кодировщик текста преобразователем. языковая модель (технически: кодировщик текста модели CLIP). Он принимает входной текст и генерирует список целых чисел (вектор) для каждого слова/токена в тексте. Затем эти данные передаются генератору изображений, состоящему из нескольких компонентов.
Генератор изображений состоит из двух шагов:
1. Создатель информации об изображении
Этот элемент является основным компонентом Stable Diffusion. Именно здесь достигается большая часть улучшения производительности по сравнению с более ранними версиями.
Этот компонент проходит несколько этапов для предоставления данных изображения. Создатель информации изображения работает только в информационном пространстве изображения (или скрытом пространстве).
Из-за этой характеристики он быстрее, чем более ранние модели диффузии, которые работали в пространстве пикселей. С технической точки зрения, этот компонент состоит из алгоритма планирования и сети UNet. нейронной сети.
Процесс, происходящий в этом компоненте, называется «диффузией». Высококачественное изображение в конечном итоге получается в результате пошаговой обработки информации (следующим компонентом, декодером изображения).
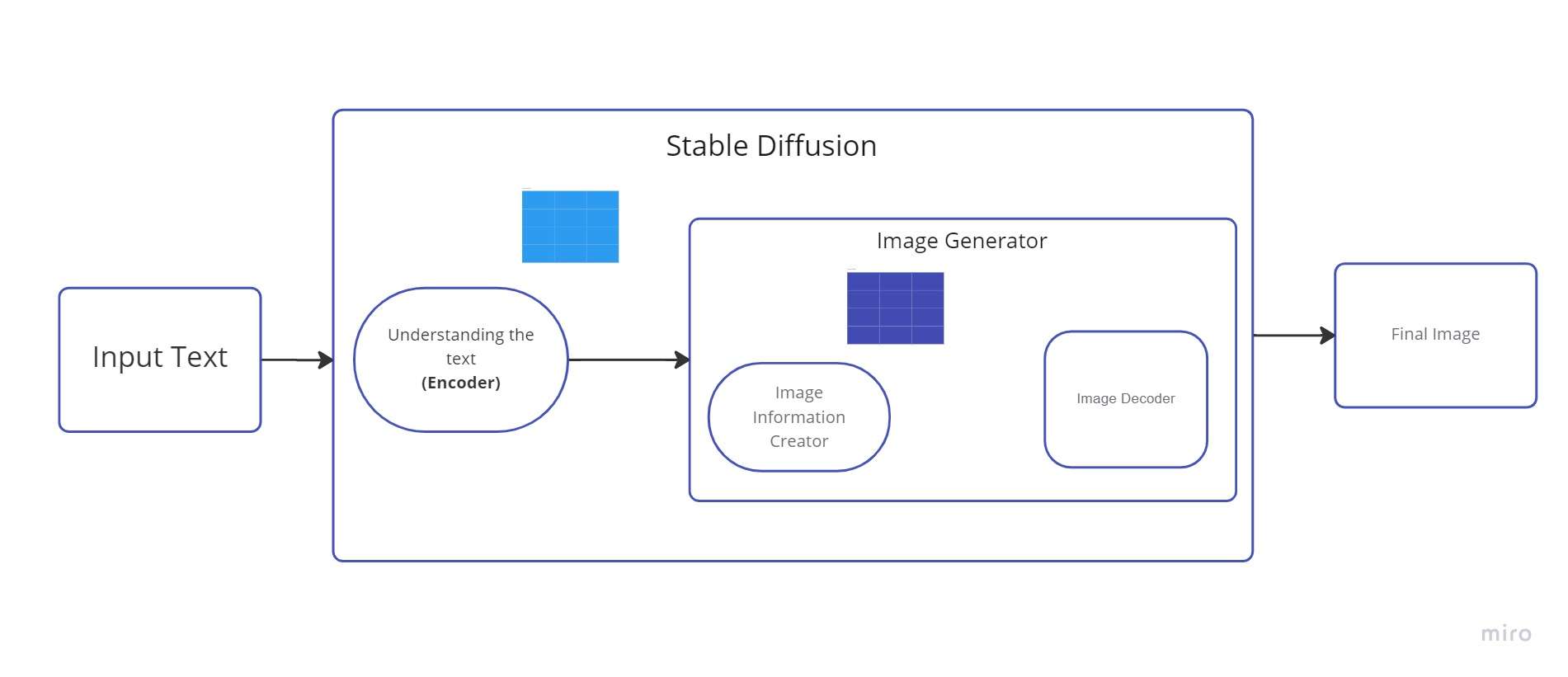
2. Декодер изображений
Используя данные, полученные от производителя информации, декодер изображений создает изображение. Он просто выполняется один раз для создания готового пиксельного изображения по завершении операции.
Учебное пособие по стабильной диффузной импайнтинге
Стабильная диффузия — это техника заполнения отсутствующих или поврежденных областей изображения. Цель закрашивания картины — скрыть факт реставрации изображения.
Этот метод часто используется для удаления ненужных вещей с изображения или для восстановления поврежденных участков исторических фотографий. Stable Diffusion Inpainting — это относительно новый способ рисования, дающий многообещающие эффекты.
Следуя приведенным ниже инструкциям, вы начнете изучать закрашивание и изменение существующих фотографий, если хотите попробовать закрашивание со стабильной диффузией:
- Перейти к Huggingface Стабильная диффузионная импайнтинг
- Загрузите собственное изображение
- Сотрите часть изображения, которую необходимо заменить.
- Введите здесь свое приглашение (что вы хотите добавить вместо того, что вы удаляете)
- Выберите «запустить»
В видео вверху мы загружаем картинку с тремя лимонами и заменяем их на яблоки. Я лично рекомендую попробовать его с вашими собственными фотографиями и подсказками.
Заключение
В общем, устойчивая диффузионная живопись — отличный метод для создания поддельных изображений или видео, которые кажутся очень реальными. По мере того, как мы движемся к новым технологиям, становится все труднее и труднее различать подлинные и мошеннические по мере развития технологий.





Первая половина никак не связана со второй половиной. Было бы очень круто, если бы автор объяснил, как работает inpaint в рамках модели, которую он объяснил ранее, мог бы дать инсайты. Но нет! Это потребовало бы настоящего понимания, а не сбора и обработки случайного текста.