ИИ повсюду, но иногда может быть сложно понять терминологию и жаргон. В этом сообщении блога мы объясняем более 50 терминов и определений ИИ, чтобы вы могли лучше понять эту быстроразвивающуюся технологию.
Будь вы новичок или эксперт, держим пари, что здесь есть несколько терминов, которые вы не знаете!
1. Искусственный интеллект
Artificial Intelligence (ИИ) относится к разработке компьютерных систем, способных обучаться и функционировать независимо, часто путем имитации человеческого интеллекта.
Эти системы анализируют данные, распознают закономерности, принимают решения и адаптируют свое поведение на основе опыта. Используя алгоритмы и модели, ИИ стремится создавать интеллектуальные машины, способные воспринимать и понимать свое окружение.
Конечная цель состоит в том, чтобы позволить машинам эффективно выполнять задачи, учиться на данных и демонстрировать когнитивные способности, подобные человеческим.
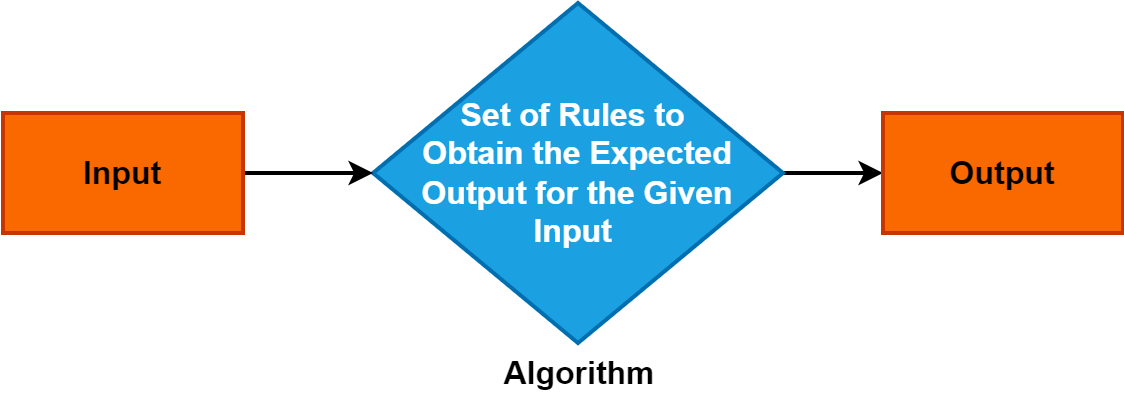
2. Алгоритм
Алгоритм — это точный и систематический набор инструкций или правил, которые определяют процесс решения проблемы или выполнения конкретной задачи.
Он служит фундаментальной концепцией в различных областях и играет ключевую роль в информатике, математике и дисциплинах, решающих задачи. Понимание алгоритмов имеет решающее значение, поскольку они обеспечивают эффективные и структурированные подходы к решению проблем, стимулируя развитие технологий и процессов принятия решений.
3. Большие данные
Большие данные относятся к чрезвычайно большим и сложным наборам данных, которые превосходят возможности традиционных методов анализа. Эти наборы данных обычно характеризуются объемом, скоростью и разнообразием.
Объем относится к огромному количеству данных, сгенерированных из различных источников, таких как социальные сети, датчики и транзакции.
Скорость относится к высокой скорости, с которой данные генерируются и должны обрабатываться в реальном или близком к реальному времени. Разнообразие означает разнообразие типов и форматов данных, включая структурированные, неструктурированные и полуструктурированные данные.
4. Сбор данных
Интеллектуальный анализ данных — это комплексный процесс, направленный на извлечение ценной информации из обширных наборов данных.
Он включает четыре ключевых этапа: сбор данных, включающий сбор соответствующих данных; подготовка данных, обеспечение качества и совместимости данных; интеллектуальный анализ данных с использованием алгоритмов для обнаружения закономерностей и взаимосвязей; а также анализ и интерпретация данных, когда извлеченные знания изучаются и понимаются.
5. Нейронная сеть
Компьютерная система предназначена для работы, как человеческий мозг, состоящий из взаимосвязанных узлов или нейронов. Давайте разберемся в этом немного подробнее, так как большинство ИИ основано на нейронные сети.
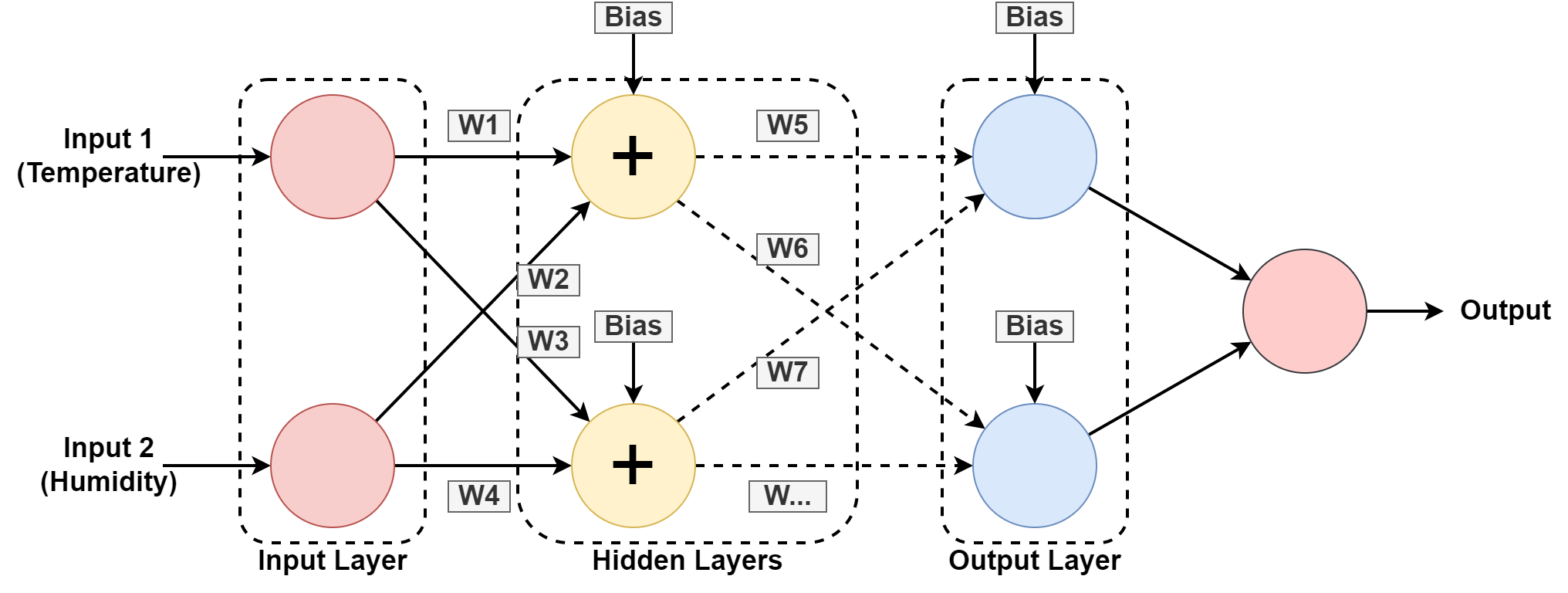
На приведенном выше графике мы прогнозируем влажность и температуру в определенном географическом месте, изучая прошлые закономерности. Входные данные — это набор данных для прошлой записи.
Ассоциация нейронная сеть учится шаблон, играя с весами и применяя значения смещения в скрытых слоях. W1, W2….W7 — соответствующие веса. Он обучается на предоставленном наборе данных и выдает результат в виде прогноза.
Вы можете быть ошеломлены этой сложной информацией. Если это так, вы можете начать с нашего простого руководства здесь.
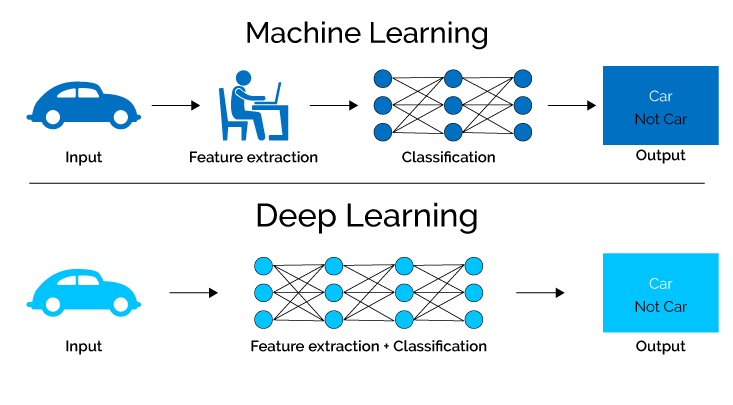
6. Машинное обучение
Машинное обучение фокусируется на разработке алгоритмов и моделей, способных автоматически обучаться на данных и улучшать свою производительность с течением времени.
Он включает в себя использование статистических методов, позволяющих компьютерам выявлять закономерности, делать прогнозы и принимать решения на основе данных без явного программирования.
Алгоритмы машинного обучения анализировать и учиться на больших наборах данных, позволяя системам адаптироваться и улучшать свое поведение на основе информации, которую они обрабатывают.
7. Глубокое обучение
Глубокое обучение, подобласть машинного обучения и нейронных сетей, использует сложные алгоритмы для получения знаний из данных путем моделирования сложных процессов человеческого мозга.
Используя нейронные сети с многочисленными скрытыми слоями, модели глубокого обучения могут автономно извлекать сложные функции и шаблоны, что позволяет им решать сложные задачи с исключительной точностью и эффективностью.
8. Распознавание образов
Распознавание образов, метод анализа данных, использует мощь алгоритмов машинного обучения для автономного обнаружения и распознавания закономерностей и закономерностей в наборах данных.
Используя вычислительные модели и статистические методы, алгоритмы распознавания образов могут выявлять значимые структуры, корреляции и тенденции в сложных и разнообразных данных.
Этот процесс позволяет извлекать ценную информацию, классифицировать данные по отдельным категориям и прогнозировать будущие результаты на основе распознанных закономерностей. Распознавание образов — жизненно важный инструмент в различных областях, расширяющий возможности принятия решений, обнаружения аномалий и прогнозного моделирования.
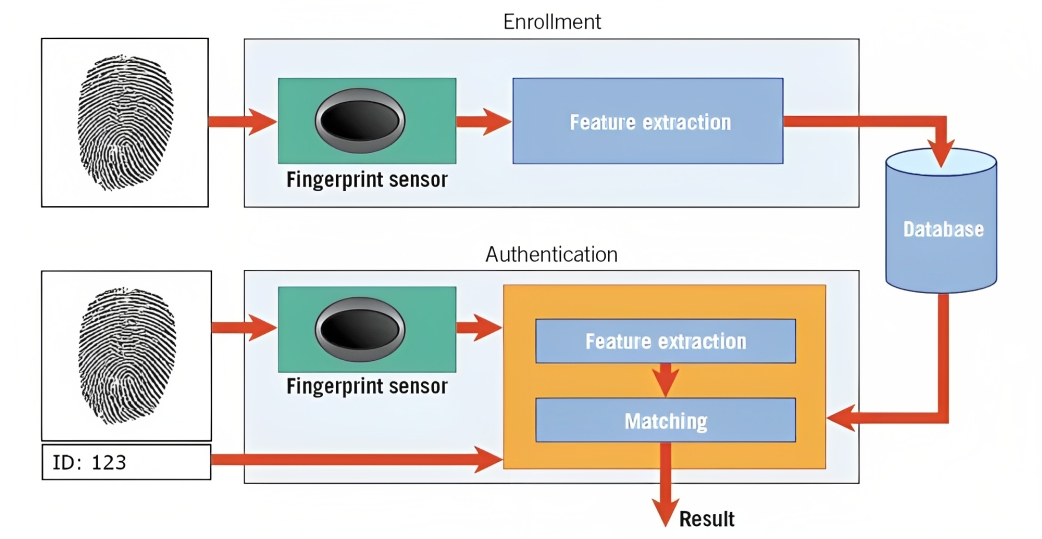
Биометрия является одним из примеров этого. Например, при распознавании отпечатков пальцев алгоритм анализирует выступы, изгибы и уникальные особенности отпечатка пальца человека, чтобы создать цифровое представление, называемое шаблоном.
Когда вы пытаетесь разблокировать свой смартфон или получить доступ к защищенному объекту, система распознавания образов сравнивает захваченные биометрические данные (например, отпечаток пальца) с сохраненными шаблонами в своей базе данных.
Сопоставляя шаблоны и оценивая уровень сходства, система может определить, соответствуют ли предоставленные биометрические данные сохраненному шаблону, и соответственно предоставить доступ.
9. Обучение с учителем
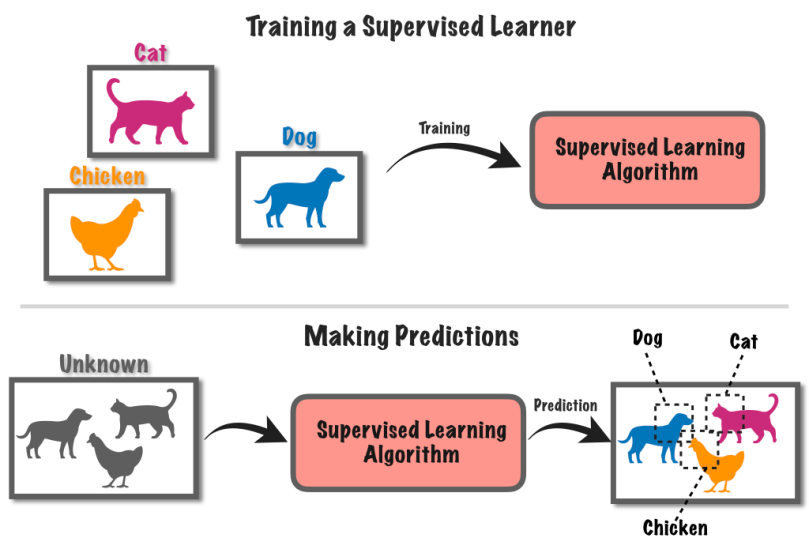
Обучение с учителем — это подход к машинному обучению, который включает в себя обучение компьютерной системы с использованием размеченных данных. В этом методе компьютеру предоставляется набор входных данных вместе с соответствующими известными метками или результатами.
Допустим, у вас есть куча фотографий, на одних с собаками, а на других с кошками.
Вы сообщаете компьютеру, на каких картинках изображены собаки, а на каких — кошки. Затем компьютер учится распознавать различия между собаками и кошками, находя закономерности на картинках.
После того, как он узнает, вы можете дать компьютеру новые картинки, и он попытается выяснить, есть ли у них собаки или кошки, основываясь на том, что он узнал из помеченных примеров. Это похоже на обучение компьютера делать прогнозы, используя известную информацию.
10. Неконтролируемое обучение
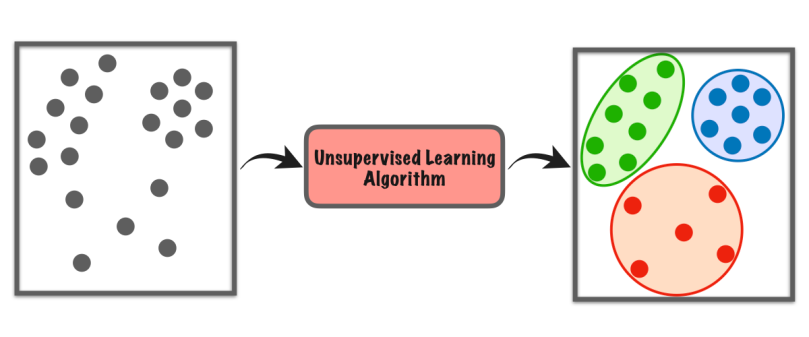
Неконтролируемое обучение — это тип машинного обучения, при котором компьютер самостоятельно исследует набор данных, чтобы найти закономерности или сходства без каких-либо конкретных инструкций.
Он не полагается на помеченные примеры, как в обучении с учителем. Вместо этого он ищет в данных скрытые структуры или группы. Как будто компьютер сам открывает что-то, а учитель не говорит ему, что искать.
Этот тип обучения помогает нам находить новые идеи, систематизировать данные или выявлять необычные вещи, не нуждаясь в предварительных знаниях или явных указаниях.
11. Обработка естественного языка (NLP)
Обработка естественного языка фокусируется на том, как компьютеры понимают и взаимодействуют с человеческим языком. Это помогает компьютерам анализировать, интерпретировать и реагировать на человеческий язык таким образом, который кажется нам более естественным.
NLP — это то, что позволяет нам общаться с голосовыми помощниками и чат-ботами и даже автоматически сортировать наши электронные письма по папкам.
Это включает в себя обучение компьютеров понимать значение слов, предложений и даже целых текстов, чтобы они могли помочь нам в различных задачах и сделать наше взаимодействие с технологиями более плавным.
12. Компьютерное зрение
Компьютерное зрение — это увлекательная технология, которая позволяет компьютерам видеть и понимать изображения и видео так же, как мы, люди, делаем это своими глазами. Все дело в том, чтобы научить компьютеры анализировать визуальную информацию и понимать, что они видят.
Проще говоря, компьютерное зрение помогает компьютерам распознавать и интерпретировать визуальный мир. Он включает в себя такие задачи, как научить их идентифицировать определенные объекты на изображениях, классифицировать изображения по разным категориям или даже делить изображения на значимые части.
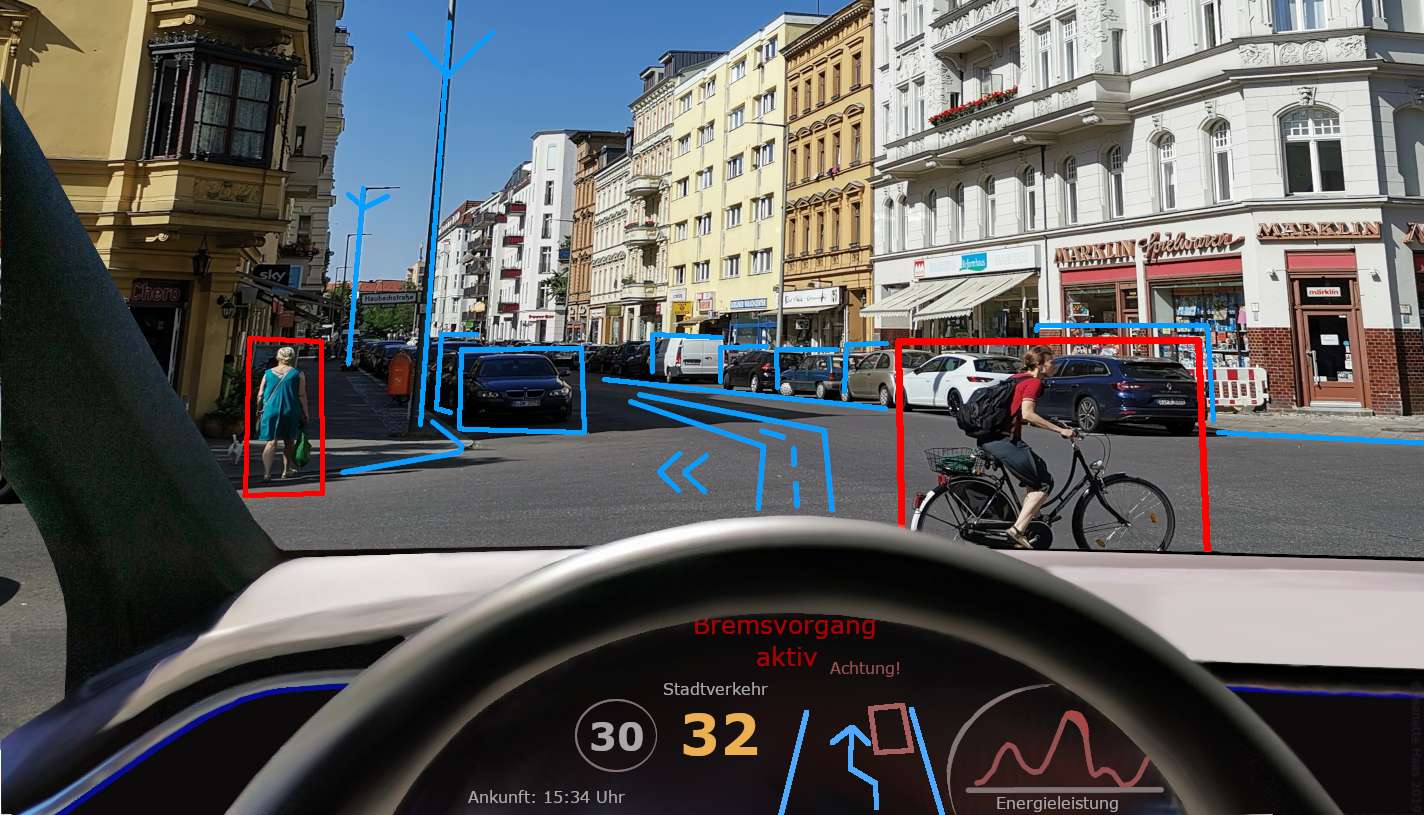
Представьте себе беспилотный автомобиль, использующий компьютерное зрение, чтобы «видеть» дорогу и все вокруг нее.
Он может обнаруживать и отслеживать пешеходов, дорожные знаки и другие транспортные средства, помогая им безопасно перемещаться. Или подумайте о том, как технология распознавания лиц использует компьютерное зрение, чтобы разблокировать наши смартфоны или подтвердить нашу личность, распознав наши уникальные черты лица.
Он также используется в системах наблюдения для наблюдения за людными местами и выявления любых подозрительных действий.
Компьютерное зрение — мощная технология, открывающая целый мир возможностей. Предоставив компьютерам возможность видеть и понимать визуальную информацию, мы можем разрабатывать приложения и системы, способные воспринимать и интерпретировать окружающий мир, делая нашу жизнь проще, безопаснее и эффективнее.
13. Чат-бот
Чат-бот похож на компьютерную программу, которая может разговаривать с людьми так, как будто это настоящий человеческий разговор.
Он часто используется в онлайн-обслуживании клиентов, чтобы помочь клиентам и заставить их почувствовать, что они разговаривают с человеком, хотя на самом деле это программа, работающая на компьютере.
Чат-бот может понимать сообщения или вопросы клиентов и отвечать на них, предоставляя полезную информацию и помощь точно так же, как это сделал бы представитель службы поддержки клиентов.
14. Распознавание голоса
Распознавание голоса относится к способности компьютерной системы понимать и интерпретировать человеческую речь. Он включает в себя технологию, которая позволяет компьютеру или устройству «слушать» произносимые слова и преобразовывать их в текст или команды, которые он может понять.
Доступно распознавания голоса, вы можете взаимодействовать с устройствами или приложениями, просто разговаривая с ними вместо того, чтобы печатать или использовать другие методы ввода.
Система анализирует произнесенные слова, распознает закономерности и звуки, а затем переводит их в понятный текст или действия. Он обеспечивает естественное общение с технологиями без помощи рук, делая возможными такие задачи, как голосовые команды, диктовка или голосовое управление. Наиболее распространенными примерами являются помощники AI, такие как Siri и Google Assistant.
15. Анализ настроений
Анализ настроений это техника, используемая для понимания и интерпретации эмоций, мнений и отношений, выраженных в тексте или речи. Он включает в себя анализ письменного или устного языка, чтобы определить, является ли выраженное настроение положительным, отрицательным или нейтральным.
Используя алгоритмы машинного обучения, алгоритмы анализа настроений могут сканировать и анализировать большие объемы текстовых данных, таких как отзывы клиентов, сообщения в социальных сетях или отзывы клиентов, чтобы определить основное настроение, стоящее за словами.
Алгоритмы ищут определенные слова, фразы или шаблоны, которые указывают на эмоции или мнения.
Этот анализ помогает предприятиям или отдельным лицам понять, как люди относятся к продукту, услуге или теме, и может использоваться для принятия решений на основе данных или получения информации о предпочтениях клиентов.
Например, компания может использовать анализ настроений, чтобы отслеживать удовлетворенность клиентов, определять области для улучшения или отслеживать общественное мнение о своем бренде.
16. Машинный перевод
Машинный перевод в контексте ИИ относится к использованию компьютерных алгоритмов и искусственного интеллекта для автоматического перевода текста или речи с одного языка на другой.
Он включает в себя обучение компьютеров понимать и обрабатывать человеческие языки, чтобы обеспечивать точные переводы. Наиболее распространенным примером является Переводчик Google.
С помощью машинного перевода вы можете вводить текст или речь на одном языке, а система анализирует ввод и генерирует соответствующий перевод на другом языке. Это особенно полезно при общении или доступе к информации на разных языках.
Системы машинного перевода основаны на сочетании лингвистических правил, статистических моделей и алгоритмов машинного обучения. Они учатся на огромном количестве языковых данных, чтобы со временем повышать точность перевода. Некоторые подходы к машинному переводу также включают нейронные сети для повышения качества переводов.
17. робототехника
Робототехника — это сочетание искусственного интеллекта и машиностроения для создания интеллектуальных машин, называемых роботами. Эти роботы предназначены для выполнения задач автономно или с минимальным вмешательством человека.
Роботы — это физические объекты, которые могут ощущать окружающую среду, принимать решения на основе этих сенсорных данных и выполнять определенные действия или задачи.
Они оснащены различными датчиками, такими как камеры, микрофоны или сенсорные датчики, которые позволяют им собирать информацию из окружающего мира. С помощью алгоритмов и программирования ИИ роботы могут анализировать эти данные, интерпретировать их и принимать разумные решения для выполнения назначенных им задач.
ИИ играет решающую роль в робототехнике, позволяя роботам учиться на собственном опыте и адаптироваться к различным ситуациям.
Алгоритмы машинного обучения можно использовать для обучения роботов распознаванию объектов, навигации по окружающей среде или даже взаимодействию с людьми. Это позволяет роботам стать более универсальными, гибкими и способными выполнять сложные задачи.
18. Дроны
Дроны — это тип роботов, которые могут летать или зависать в воздухе без пилота-человека на борту. Они также известны как беспилотные летательные аппараты (БПЛА). Дроны оснащены различными датчиками, такими как камеры, GPS и гироскопы, которые позволяют им собирать данные и ориентироваться в своем окружении.
Они управляются дистанционно человеком-оператором или могут работать автономно, используя предварительно запрограммированные инструкции.
Дроны служат широкому кругу целей, включая аэрофотосъемку и видеосъемку, геодезию и картографирование, службы доставки, поисково-спасательные миссии, мониторинг сельского хозяйства и даже использование в рекреационных целях. Они могут получить доступ к отдаленным или опасным зонам, которые являются трудными или опасными для человека.
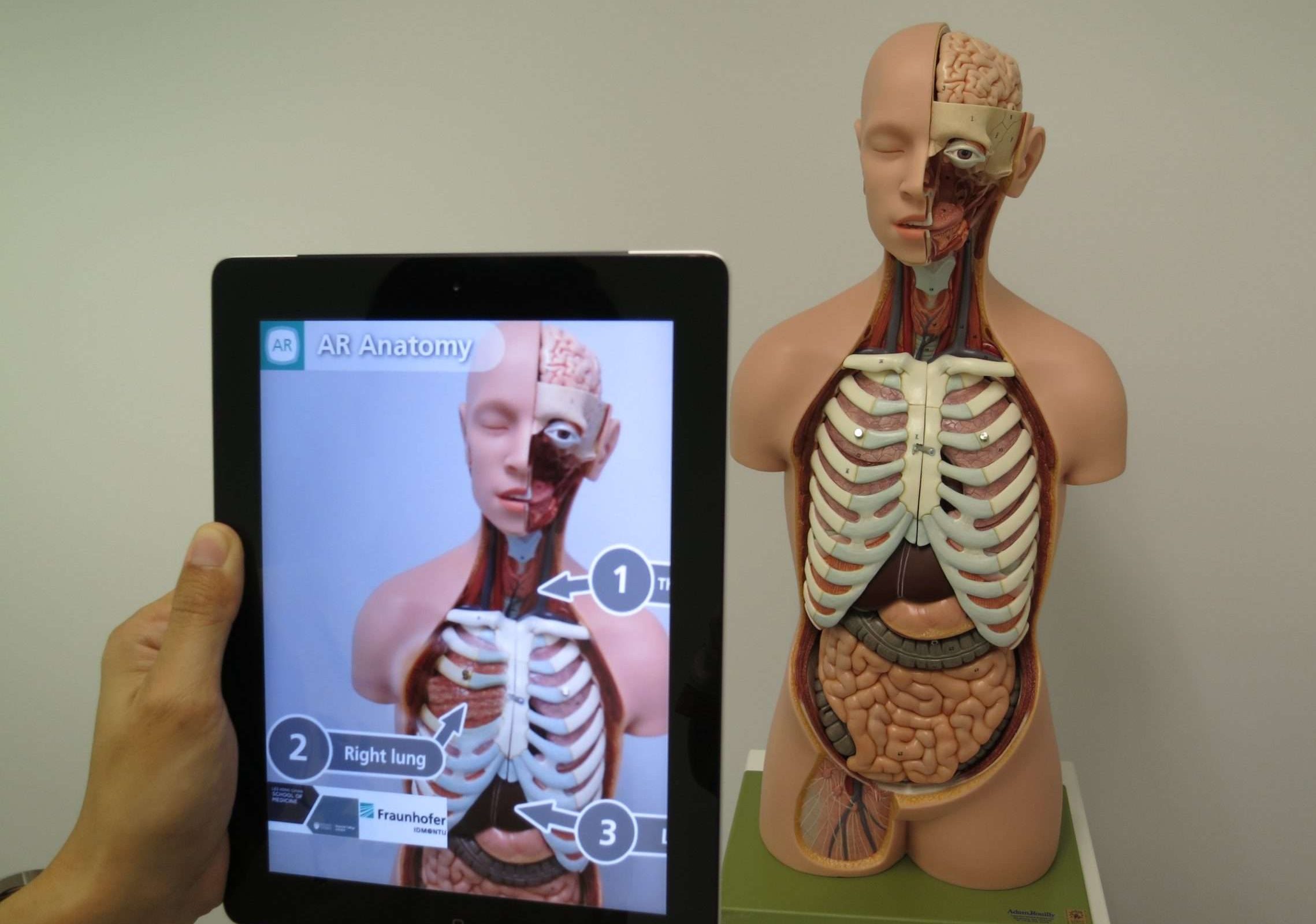
19. Дополненная реальность (AR)
Дополненная реальность (AR) — это технология, которая объединяет реальный мир с виртуальными объектами или информацией для улучшения нашего восприятия и взаимодействия с окружающей средой. Он накладывает созданные компьютером изображения, звуки или другие сенсорные входные данные на реальный мир, создавая захватывающий и интерактивный опыт.
Проще говоря, представьте, что вы носите специальные очки или используете свой смартфон, чтобы увидеть мир вокруг вас, но с добавлением дополнительных виртуальных элементов.
Например, вы можете навести свой смартфон на городскую улицу и увидеть виртуальные указатели, показывающие направления, рейтинги и обзоры близлежащих ресторанов или даже виртуальных персонажей, взаимодействующих с реальной средой.
Эти виртуальные элементы органично сочетаются с реальным миром, улучшая ваше понимание и восприятие окружающего мира. Дополненную реальность можно использовать в различных областях, таких как игры, образование, архитектура, и даже для повседневных задач, таких как навигация или проверка новой мебели в вашем доме перед ее покупкой.
20. Виртуальная реальность (VR)
Виртуальная реальность (VR) — это технология, использующая компьютерное моделирование для создания искусственной среды, которую человек может исследовать и с которой может взаимодействовать. Он погружает пользователя в виртуальный мир, блокируя реальный мир и заменяя его цифровым царством.
Проще говоря, представьте, что вы надеваете специальную гарнитуру, которая закрывает ваши глаза и уши и переносит вас в совершенно другое место. В этом виртуальном мире все, что вы видите и слышите, кажется невероятно реальным, хотя все это создается компьютером.
Вы можете передвигаться, смотреть в любом направлении и взаимодействовать с объектами или персонажами, как если бы они присутствовали физически.
Например, в игре виртуальной реальности вы можете оказаться внутри средневекового замка, где сможете пройтись по его коридорам, подобрать оружие и вступить в бой на мечах с виртуальными противниками. Среда виртуальной реальности реагирует на ваши движения и действия, заставляя вас чувствовать себя полностью погруженным и вовлеченным в процесс.
Виртуальная реальность используется не только для игр, но и для различных других приложений, таких как тренировочные симуляторы для пилотов, хирургов или военнослужащих, архитектурные пошаговые инструкции, виртуальный туризм и даже терапия при определенных психологических состояниях. Он создает ощущение присутствия и переносит пользователей в новые захватывающие виртуальные миры, максимально приближенные к реальности.
21. Наука о данных
Научные исследования данных это область, которая включает использование научных методов, инструментов и алгоритмов для извлечения ценных знаний и идей из данных. Он сочетает в себе элементы математики, статистики, программирования и знаний в предметной области для анализа больших и сложных наборов данных.
Проще говоря, наука о данных — это поиск значимой информации и закономерностей, скрытых в куче данных. Он включает в себя сбор, очистку и организацию данных, а затем использование различных методов для их изучения и анализа. Ученые данных использовать статистические модели и алгоритмы для выявления тенденций, прогнозирования и решения проблем.
Например, в сфере здравоохранения наука о данных может использоваться для анализа историй болезни пациентов и медицинских данных для выявления факторов риска заболеваний, прогнозирования результатов лечения пациентов или оптимизации планов лечения. В бизнесе наука о данных может применяться к данным о клиентах, чтобы понять их предпочтения, рекомендовать продукты или улучшить маркетинговые стратегии.
22. Обработка данных
Обработка данных, также известная как обработка данных, представляет собой процесс сбора, очистки и преобразования необработанных данных в формат, более полезный и подходящий для анализа. Он включает в себя обработку и подготовку данных для обеспечения их качества, согласованности и совместимости с инструментами или моделями анализа.
Проще говоря, обработка данных похожа на подготовку ингредиентов для приготовления пищи. Он включает в себя сбор данных из разных источников, их сортировку и очистку для удаления любых ошибок, несоответствий или ненужной информации.
Кроме того, может потребоваться преобразование, реструктуризация или агрегирование данных, чтобы с ними было проще работать и извлекать из них ценные сведения.
Например, обработка данных может включать удаление повторяющихся записей, исправление опечаток или проблем с форматированием, обработку отсутствующих значений и преобразование типов данных. Это также может включать слияние или объединение различных наборов данных, разделение данных на подмножества или создание новых переменных на основе существующих данных.
23. Рассказывание историй данных
Рассказ о данных — это искусство представления данных в убедительной и увлекательной форме для эффективной передачи повествования или сообщения. Он предполагает использование визуализации данных, нарративы и контекст, чтобы донести идеи и выводы в понятной и запоминающейся для аудитории форме.
Проще говоря, сторителлинг на основе данных — это использование данных для рассказа истории. Это выходит за рамки простого представления цифр и графиков. Он включает в себя создание повествования вокруг данных с использованием визуальных элементов и методов повествования, чтобы оживить данные и сделать их понятными для аудитории.
Например, вместо простого представления таблицы с данными о продажах сторителлинг данных может включать создание интерактивной информационной панели, которая позволяет пользователям визуально изучать тенденции продаж.
Он может включать описательную часть, в которой освещаются основные выводы, объясняются причины тенденций и предлагаются действенные рекомендации на основе данных.
24. Принятие решений на основе данных
Принятие решений на основе данных — это процесс принятия решений или действий на основе анализа и интерпретации соответствующих данных. Это предполагает использование данных в качестве основы для руководства и поддержки процессов принятия решений, а не полагаться исключительно на интуицию или личное суждение.
Проще говоря, принятие решений на основе данных означает использование фактов и доказательств из данных для информирования и руководства при выборе, который мы делаем. Он включает в себя сбор и анализ данных для понимания закономерностей, тенденций и взаимосвязей, а также использование этих знаний для принятия обоснованных решений и решения проблем.
Например, в бизнес-среде принятие решений на основе данных может включать анализ данных о продажах, отзывов клиентов и рыночных тенденций, чтобы определить наиболее эффективную стратегию ценообразования или определить области для улучшения в разработке продукта.
В здравоохранении это может включать анализ данных о пациентах для оптимизации планов лечения или прогнозирования исходов заболевания.
25. Озеро данных
Озеро данных — это централизованное и масштабируемое хранилище данных, в котором хранятся огромные объемы данных в необработанном и необработанном виде. Он предназначен для хранения широкого спектра типов данных, форматов и структур, таких как структурированные, полуструктурированные и неструктурированные данные, без необходимости использования предварительно определенных схем или преобразований данных.
Например, компания может собирать и хранить данные из различных источников, таких как журналы веб-сайтов, транзакции клиентов, каналы социальных сетей и устройства IoT, в озере данных.
Затем эти данные можно использовать для различных целей, таких как проведение расширенной аналитики, выполнение алгоритмов машинного обучения или изучение закономерностей и тенденций в поведении клиентов.
26. Хранилище данных
Хранилище данных — это специализированная система баз данных, специально разработанная для хранения, организации и анализа больших объемов данных из различных источников. Он структурирован таким образом, что поддерживает эффективный поиск данных и сложные аналитические запросы.
Он служит центральным репозиторием, объединяющим данные из различных операционных систем, таких как транзакционные базы данных, системы CRM и другие источники данных внутри организации.
Данные преобразуются, очищаются и загружаются в хранилище данных в структурированном формате, оптимизированном для аналитических целей.
27. Бизнес-аналитика (BI)
Бизнес-аналитика — это процесс сбора, анализа и представления данных таким образом, чтобы помочь предприятиям принимать обоснованные решения и получать ценную информацию. Он включает в себя использование различных инструментов, технологий и методов для преобразования необработанных данных в значимую информацию, полезную для действий.
Например, система бизнес-аналитики может анализировать данные о продажах, чтобы определять наиболее прибыльные продукты, контролировать уровень запасов и отслеживать предпочтения клиентов.
Он может предоставлять информацию о ключевых показателях эффективности (KPI) в режиме реального времени, таких как доход, привлечение клиентов или производительность продукта, что позволяет предприятиям принимать решения на основе данных и предпринимать соответствующие действия для улучшения своей деятельности.
Инструменты бизнес-аналитики часто включают в себя такие функции, как визуализация данных, специальные запросы и возможности исследования данных. Эти инструменты позволяют пользователям, например бизнес-аналитики или менеджеры, чтобы взаимодействовать с данными, нарезать их и создавать отчеты или визуальные представления, которые выделяют важные идеи и тенденции.
28. Прогнозная аналитика
Предиктивный анализ — это практика использования данных и статистических методов для обоснованных предсказаний или прогнозов будущих событий или результатов. Он включает в себя анализ исторических данных, выявление закономерностей и построение моделей для экстраполяции и оценки будущих тенденций, поведения или событий.
Он направлен на выявление взаимосвязей между переменными и использование этой информации для прогнозирования. Это выходит за рамки простого описания прошлых событий; вместо этого он использует исторические данные, чтобы понять и предвидеть, что может произойти в будущем.
Например, в области финансов прогнозный анализ можно использовать для прогнозирования акции цены на основе исторических рыночных данных, экономических показателей и других соответствующих факторов.
В маркетинге его можно использовать для прогнозирования поведения и предпочтений клиентов, что позволяет проводить целевую рекламу и персонализированные маркетинговые кампании.
В здравоохранении прогностический анализ может помочь выявить пациентов с высоким риском определенных заболеваний или предсказать вероятность повторной госпитализации на основе истории болезни и других факторов.
29. Предписывающая аналитика
Предписывающая аналитика — это применение данных и аналитики для определения наилучших возможных действий в конкретной ситуации или сценарии принятия решений.
выходит за рамки описательного и прогнозного анализа не только предоставляя информацию о том, что может произойти в будущем, но и рекомендуя наиболее оптимальный курс действий для достижения желаемого результата.
Он сочетает в себе исторические данные, прогностические модели и методы оптимизации для моделирования различных сценариев и оценки потенциальных результатов различных решений. Он учитывает многочисленные ограничения, цели и факторы для создания действенных рекомендаций, которые максимизируют желаемые результаты или минимизируют риски.
Например, в цепочками поставок управления предписывающая аналитика может анализировать данные об уровне запасов, производственных мощностях, транспортных расходах и потребительском спросе, чтобы определить наиболее эффективный план распределения.
Он может порекомендовать идеальное распределение ресурсов, таких как складские помещения или маршруты транспортировки, чтобы минимизировать затраты и обеспечить своевременную доставку.
30. Маркетинг, управляемый данными
Маркетинг, управляемый данными, относится к практике использования данных и аналитики для управления маркетинговыми стратегиями, кампаниями и процессами принятия решений.
Он включает в себя использование различных источников данных для получения информации о поведении, предпочтениях и тенденциях клиентов и использование этой информации для оптимизации маркетинговых усилий.
Он фокусируется на сборе и анализе данных из нескольких точек соприкосновения, таких как взаимодействие с веб-сайтом, взаимодействие с социальными сетями, демографические данные клиентов, история покупок и многое другое. Затем эти данные используются для создания всестороннего понимания целевой аудитории, ее предпочтений и потребностей.
Используя данные, маркетологи могут принимать обоснованные решения в отношении сегментации клиентов, таргетинга и персонализации.
Они могут определить определенные сегменты клиентов, которые с большей вероятностью положительно отреагируют на маркетинговые кампании, и соответствующим образом адаптировать свои сообщения и предложения.
Кроме того, маркетинг на основе данных помогает оптимизировать маркетинговые каналы, определить наиболее эффективный маркетинговый комплекс и измерить успех маркетинговых инициатив.
Например, подход к маркетингу, основанному на данных, может включать анализ данных о клиентах для выявления закономерностей покупательского поведения и предпочтений. На основе этих данных маркетологи могут создавать целевые кампании с персонализированным контентом и предложениями, которые находят отклик у определенных сегментов клиентов.
Благодаря непрерывному анализу и оптимизации они могут измерять эффективность своих маркетинговых усилий и со временем совершенствовать стратегии.
31. Управление данными
Управление данными — это структура и набор методов, которые организации применяют для обеспечения надлежащего управления, защиты и целостности данных на протяжении всего их жизненного цикла. Он включает в себя процессы, политики и процедуры, которые регулируют сбор, хранение, доступ к данным, их использование и совместное использование внутри организации.
Он направлен на установление подотчетности, ответственности и контроля над активами данных. Это гарантирует, что данные являются точными, полными, непротиворечивыми и заслуживающими доверия, что позволяет организациям принимать обоснованные решения, поддерживать качество данных и соответствовать нормативным требованиям.
Управление данными включает в себя определение ролей и обязанностей по управлению данными, установление стандартов и политик данных, а также внедрение процессов для мониторинга и обеспечения соблюдения требований. В нем рассматриваются различные аспекты управления данными, включая конфиденциальность данных, безопасность данных, качество данных, классификацию данных и управление жизненным циклом данных.
Например, управление данными может включать внедрение процедур, обеспечивающих обработку личных или конфиденциальных данных в соответствии с применимыми правилами конфиденциальности, такими как Общий регламент по защите данных (GDPR).
Это может также включать установление стандартов качества данных и внедрение процессов проверки данных для обеспечения их точности и надежности.
32. Безопасность данных
Безопасность данных заключается в защите нашей ценной информации от несанкционированного доступа или кражи. Это включает в себя принятие мер по защите конфиденциальности, целостности и доступности данных.
По сути, это означает, что только нужные люди могут получить доступ к нашим данным, чтобы они оставались точными и неизменными и чтобы они были доступны, когда это необходимо.
Для обеспечения безопасности данных используются различные стратегии и технологии. Например, контроль доступа и методы шифрования помогают ограничить доступ к авторизованным лицам или системам, что затрудняет доступ посторонних к нашим данным.
Системы мониторинга, брандмауэры и системы обнаружения вторжений действуют как защитники, предупреждая нас о подозрительных действиях и предотвращая несанкционированный доступ.
33. Интернет вещей
Интернет вещей (IoT) относится к сети физических объектов или «вещей», которые подключены к Интернету и могут взаимодействовать друг с другом. Это похоже на большую сеть повседневных предметов, устройств и машин, которые могут обмениваться информацией и выполнять задачи, взаимодействуя через Интернет.
Проще говоря, IoT предполагает предоставление «умных» возможностей различным объектам или устройствам, которые традиционно не были подключены к Интернету. Эти объекты могут включать бытовую технику, носимые устройства, термостаты, автомобили и даже промышленное оборудование.
Подключив эти объекты к Интернету, они могут собирать и обмениваться данными, получать инструкции и выполнять задачи автономно или в ответ на команды пользователя.
Например, интеллектуальный термостат может контролировать температуру, регулировать настройки и отправлять отчеты об использовании энергии в приложение для смартфона. Носимый фитнес-трекер может собирать данные о вашей физической активности и синхронизировать их с облачной платформой для анализа.
34. Дерево принятия решений
Дерево решений — это визуальное представление или диаграмма, которая помогает нам принимать решения или определять курс действий на основе ряда вариантов или условий.
Это похоже на блок-схему, которая ведет нас через процесс принятия решений, рассматривая различные варианты и их потенциальные результаты.
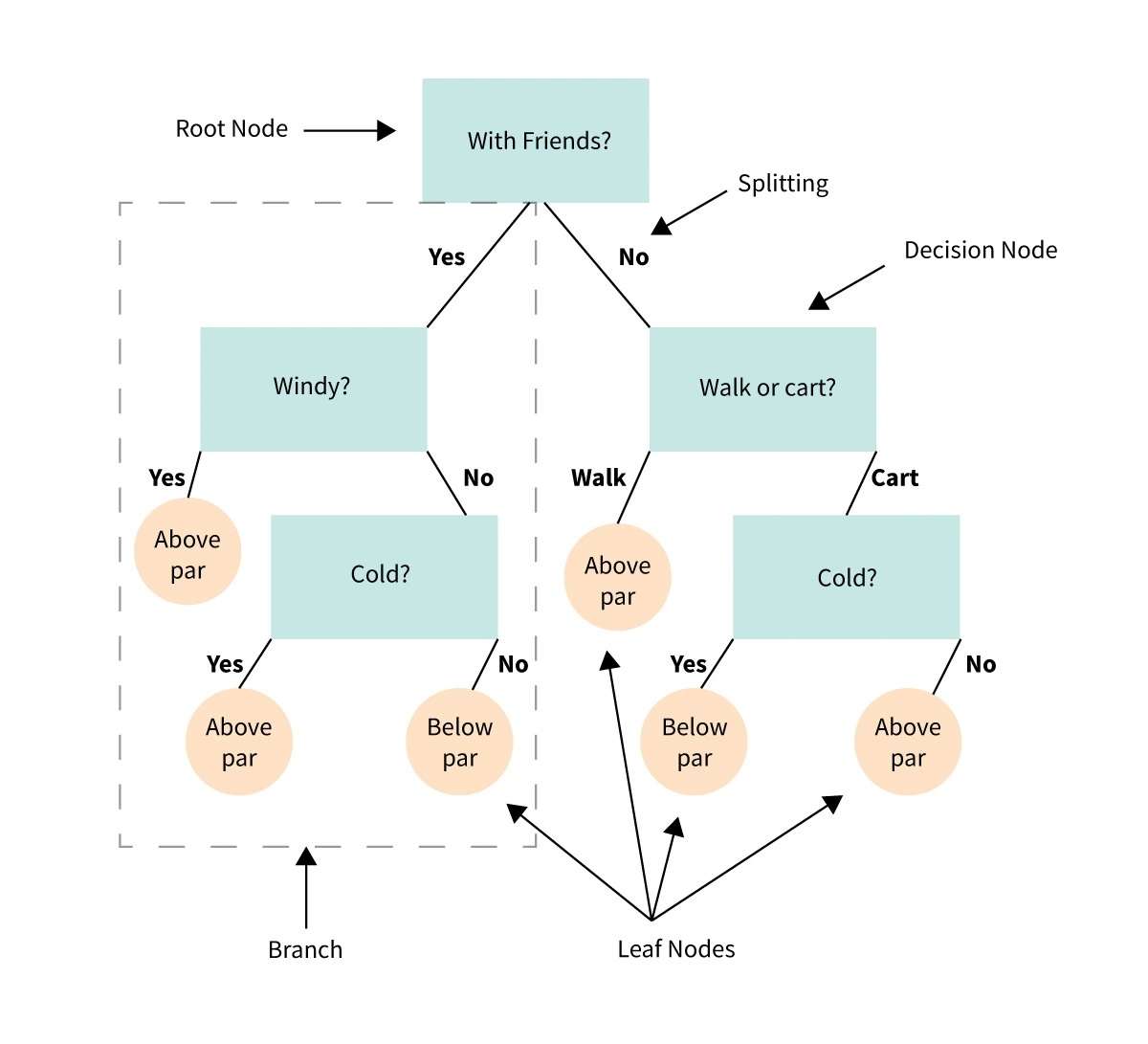
Представьте, что у вас есть проблема или вопрос, и вам нужно сделать выбор.
Дерево решений разбивает решение на более мелкие шаги, начиная с начального вопроса и заканчивая различными возможными ответами или действиями, основанными на условиях или критериях на каждом этапе.
35. Когнитивные вычисления
Проще говоря, когнитивные вычисления относятся к компьютерным системам или технологиям, которые имитируют когнитивные способности человека, такие как обучение, рассуждение, понимание и решение проблем.
Он включает в себя создание компьютерных систем, которые могут обрабатывать и интерпретировать информацию способом, напоминающим человеческое мышление.
Когнитивные вычисления направлены на разработку машин, которые могут понимать людей и взаимодействовать с ними более естественным и разумным образом. Эти системы предназначены для анализа огромных объемов данных, распознавания закономерностей, прогнозирования и предоставления осмысленной информации.
Думайте о когнитивных вычислениях как о попытке заставить компьютеры думать и действовать как люди.
Он включает в себя использование таких технологий, как искусственный интеллект, машинное обучение, обработка естественного языка и компьютерное зрение, чтобы позволить компьютерам выполнять задачи, которые традиционно ассоциировались с человеческим интеллектом.
36. Вычислительная теория обучения
Вычислительная теория обучения — это специализированная ветвь в области искусственного интеллекта, которая вращается вокруг разработки и изучения алгоритмов, специально предназначенных для обучения на основе данных.
В этой области исследуются различные методы и методологии построения алгоритмов, которые могут автономно улучшать свою производительность за счет анализа и обработки больших объемов информации.
Используя силу данных, теория вычислительного обучения стремится выявить закономерности, взаимосвязи и идеи, которые позволяют машинам расширять свои возможности принятия решений и выполнять задачи более эффективно.
Конечная цель состоит в том, чтобы создать алгоритмы, которые могут адаптироваться, обобщать и делать точные прогнозы на основе данных, которым они подверглись, способствуя развитию искусственного интеллекта и его практических приложений.
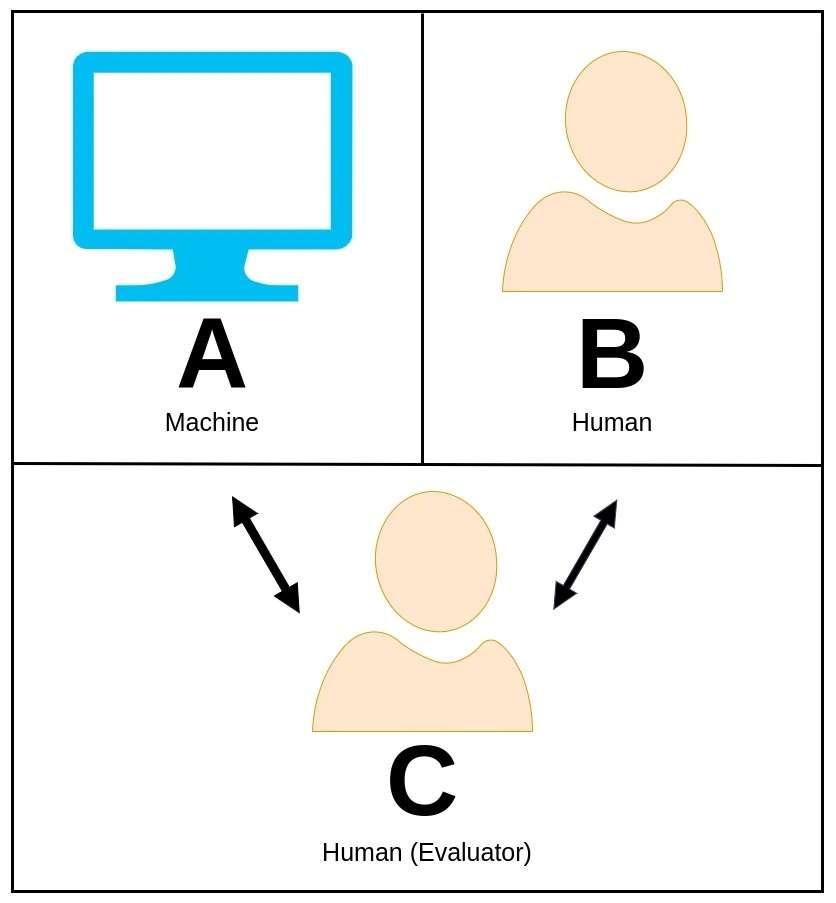
37. Тест Тьюринга
Тест Тьюринга, первоначально предложенный блестящим математиком и ученым Аланом Тьюрингом, представляет собой захватывающую концепцию, используемую для оценки того, может ли машина демонстрировать интеллектуальное поведение, сравнимое с поведением человека или практически неотличимое от него.
В тесте Тьюринга оценщик-человек вступает в разговор на естественном языке как с машиной, так и с другим участником-человеком, не зная, кто из них является машиной.
Роль оценщика состоит в том, чтобы определить, какой объект является машиной, исключительно на основе их ответов. Если машина способна убедить оценщика в том, что она является человеческим аналогом, то говорят, что она прошла тест Тьюринга, тем самым демонстрируя уровень интеллекта, который отражает человеческие способности.
Алан Тьюринг предложил этот тест как средство изучения концепции машинного интеллекта и постановки вопроса о том, могут ли машины достичь познания на уровне человека.
Сформулировав тест с точки зрения неотличимости от человека, Тьюринг подчеркнул способность машин демонстрировать поведение, которое настолько убедительно разумно, что становится сложно отличить их от людей.
Тест Тьюринга вызвал обширные дискуссии и исследования в области искусственного интеллекта и когнитивных наук. Хотя прохождение теста Тьюринга остается важной вехой, это не единственная мера интеллекта.
Тем не менее, тест служит отправной точкой для размышлений, стимулируя постоянные усилия по разработке машин, способных имитировать человеческий интеллект и поведение, и способствуя более широкому изучению того, что значит быть разумным.
38. Обучение с подкреплением
Укрепление обучения это тип обучения, который происходит путем проб и ошибок, когда «агент» (который может быть компьютерной программой или роботом) учится выполнять задачи, получая вознаграждение за хорошее поведение и сталкиваясь с последствиями или наказаниями за плохое поведение.
Представьте себе сценарий, в котором агент пытается выполнить определенную задачу, например пройти лабиринт. Сначала агент не знает правильного пути, поэтому он пробует разные действия и исследует разные маршруты.
Когда он выбирает хорошее действие, приближающее его к цели, он получает вознаграждение, вроде виртуального «похлопывания по спине». Однако, если он принимает неудачное решение, которое заводит в тупик или уводит от цели, он получает наказание или негативную обратную связь.
Благодаря этому процессу проб и ошибок агент учится ассоциировать определенные действия с положительными или отрицательными результатами. Он постепенно определяет наилучшую последовательность действий, чтобы максимизировать свои награды и минимизировать наказания, в конечном итоге становясь более опытным в выполнении задачи.
Обучение с подкреплением черпает вдохновение из того, как люди и животные учатся, получая обратную связь от окружающей среды.
Применяя эту концепцию к машинам, исследователи стремятся разработать интеллектуальные системы, которые могут обучаться и адаптироваться к различным ситуациям, самостоятельно обнаруживая наиболее эффективное поведение посредством процесса положительного подкрепления и отрицательных последствий.
39. Извлечение сущности
Извлечение сущностей относится к процессу, в котором мы идентифицируем и извлекаем важные фрагменты информации, известные как сущности, из блока текста. Этими объектами могут быть различные вещи, такие как имена людей, названия мест, названия организаций и так далее.
Давайте представим, что у вас есть абзац, описывающий новостную статью.
Извлечение сущностей будет включать анализ текста и выбор определенных битов, которые представляют отдельные сущности. Например, если в тексте упоминается имя человека, например «Джон Смит», местонахождение «Нью-Йорк» или организация «OpenAI», это будут объекты, которые мы стремимся идентифицировать и извлечь.
Выполняя извлечение сущностей, мы, по сути, учим компьютерную программу распознавать и выделять важные элементы из текста. Этот процесс позволяет нам более эффективно организовывать и классифицировать информацию, упрощая поиск, анализ и получение информации из больших объемов текстовых данных.
В целом извлечение сущностей помогает нам автоматизировать задачу точного определения важных сущностей, таких как люди, места и организации, в тексте, упрощая извлечение ценной информации и повышая нашу способность обрабатывать и понимать текстовые данные.
40. Лингвистическая аннотация
Лингвистическая аннотация включает в себя обогащение текста дополнительной лингвистической информацией для улучшения нашего понимания и анализа используемого языка. Это похоже на добавление полезных меток или тегов к разным частям текста.
Когда мы выполняем лингвистическую аннотацию, мы выходим за рамки основных слов и предложений в тексте и начинаем маркировать или маркировать определенные элементы. Например, мы можем добавить теги части речи, которые указывают грамматическую категорию каждого слова (например, существительное, глагол, прилагательное и т. д.). Это помогает нам понять роль каждого слова в предложении.
Другой формой лингвистической аннотации является распознавание именованных сущностей, когда мы идентифицируем и помечаем определенные именованные сущности, такие как имена людей, места, организации или даты. Это позволяет нам быстро находить и извлекать из текста важную информацию.
Аннотируя текст таким образом, мы создаем более структурированное и организованное представление языка. Это может быть очень полезно в различных приложениях. Например, это помогает повысить точность поисковых систем за счет понимания намерений, стоящих за запросами пользователей. Он также помогает в машинном переводе, анализе настроений, извлечении информации и многих других задачах обработки естественного языка.
Лингвистическая аннотация служит жизненно важным инструментом для исследователей, лингвистов и разработчиков, позволяя им изучать языковые шаблоны, создавать языковые модели и разрабатывать сложные алгоритмы, которые могут лучше анализировать и понимать текст.
41. Гиперпараметр
In обучение с помощью машины, гиперпараметр подобен специальной настройке или конфигурации, которую нам нужно выбрать перед обучением модели. Это не то, чему модель может научиться самостоятельно из данных; вместо этого мы должны определить это заранее.
Думайте об этом как о ручке или переключателе, который мы можем настроить, чтобы точно настроить то, как модель учится и делает прогнозы. Эти гиперпараметры управляют различными аспектами процесса обучения, такими как сложность модели, скорость обучения и компромисс между точностью и обобщением.
Например, давайте рассмотрим нейронную сеть. Одним из важных гиперпараметров является количество слоев в сети. Мы должны выбрать, насколько глубокой должна быть сеть, и это решение влияет на ее способность фиксировать сложные закономерности в данных.
Другие распространенные гиперпараметры включают скорость обучения, которая определяет, насколько быстро модель корректирует свои внутренние параметры на основе обучающих данных, и силу регуляризации, которая контролирует, насколько модель штрафует сложные шаблоны, чтобы предотвратить переоснащение.
Правильная установка этих гиперпараметров имеет решающее значение, поскольку они могут значительно повлиять на производительность и поведение модели. Это часто связано с пробами и ошибками, экспериментированием с различными значениями и наблюдением за тем, как они влияют на производительность модели в наборе данных проверки.
42. Метаданные
Метаданные относятся к дополнительной информации, которая предоставляет сведения о других данных. Это похоже на набор тегов или меток, которые дают нам больше контекста или описывают характеристики основных данных.
Когда у нас есть данные, будь то документ, фотография, видео или любой другой тип информации, метаданные помогают нам понять важные аспекты этих данных.
Например, в документе метаданные могут включать такие сведения, как имя автора, дату его создания или формат файла. В случае фотографии метаданные могут сообщить нам место, где она была сделана, использованные настройки камеры или даже дату и время ее съемки.
Метаданные помогают нам более эффективно организовывать, искать и интерпретировать данные. Добавляя эти описательные фрагменты информации, мы можем быстро найти определенные файлы или понять их происхождение, назначение или контекст без необходимости копаться во всем содержимом.
43. Уменьшение размерности
Уменьшение размерности — это метод, используемый для упрощения набора данных за счет уменьшения количества содержащихся в нем функций или переменных. Это похоже на сжатие или обобщение информации в наборе данных, чтобы сделать его более управляемым и простым в работе.
Представьте, что у вас есть набор данных с многочисленными столбцами или атрибутами, представляющими различные характеристики точек данных. Каждый столбец увеличивает сложность и вычислительные требования алгоритмов машинного обучения.
В некоторых случаях наличие большого количества измерений может затруднить поиск значимых закономерностей или взаимосвязей в данных.
Уменьшение размерности помогает решить эту проблему путем преобразования набора данных в представление меньшего размера, сохраняя при этом как можно больше релевантной информации. Он направлен на то, чтобы зафиксировать наиболее важные аспекты или различия в данных, отбрасывая избыточные или менее информативные измерения.
44. Классификация текста
Классификация текста — это процесс, который включает присвоение определенных меток или категорий блокам текста на основе их содержания или значения. Это похоже на сортировку или организацию текстовой информации по разным группам или классам для облегчения дальнейшего анализа или принятия решений.
Рассмотрим пример классификации электронной почты. В этом сценарии мы хотим определить, является ли входящее электронное письмо спамом или не спамом (также известным как ветчина). Классификация текста алгоритмы анализируют содержимое письма и присваивают ему соответствующую метку.
Если алгоритм определяет, что электронная почта обладает характеристиками, обычно ассоциируемыми со спамом, он присваивает ей метку «спам». И наоборот, если электронное письмо кажется законным и не является спамом, ему присваивается ярлык «не спам» или «ветчина».
Классификация текста находит применение в различных областях помимо фильтрации электронной почты. Он используется в анализе настроений для определения настроения, выраженного в отзывах клиентов (положительных, отрицательных или нейтральных).
Новостные статьи можно классифицировать по разным темам или категориям, таким как спорт, политика, развлечения и т. д. Журналы чата службы поддержки клиентов можно классифицировать в зависимости от намерения или решаемой проблемы.
45. Слабый ИИ
Слабый ИИ, также известный как узкий ИИ, относится к системам искусственного интеллекта, которые разработаны и запрограммированы для выполнения определенных задач или функций. В отличие от человеческого интеллекта, который включает в себя широкий спектр когнитивных способностей, слабый ИИ ограничен определенной областью или задачей.
Думайте о слабом ИИ как о специализированном программном обеспечении или машинах, которые превосходно выполняют определенные задачи. Например, можно создать программу искусственного интеллекта для игры в шахматы, чтобы анализировать игровые ситуации, разрабатывать стратегии ходов и соревноваться с игроками-людьми.
Другой пример — система распознавания изображений, которая может идентифицировать объекты на фотографиях или видео.
Эти системы искусственного интеллекта обучены и оптимизированы, чтобы преуспеть в своих конкретных областях знаний. Они полагаются на алгоритмы, данные и заранее определенные правила для эффективного выполнения своих задач.
Однако они не обладают общим интеллектом, который позволяет им понимать или выполнять задачи, выходящие за рамки их назначенной области.
46. Сильный ИИ
Сильный ИИ, также известный как общий ИИ или искусственный общий интеллект (AGI), относится к форме искусственного интеллекта, которая обладает способностью понимать, учиться и выполнять любые интеллектуальные задачи, которые может выполнять человек.
В отличие от слабого ИИ, предназначенного для решения конкретных задач, сильный ИИ стремится воспроизвести человеческий интеллект и когнитивные способности. Он стремится создавать машины или программное обеспечение, которые не только превосходно справляются со специализированными задачами, но и обладают более широким пониманием и адаптируемостью для решения широкого круга интеллектуальных задач.
Целью сильного ИИ является разработка систем, которые могут рассуждать, понимать сложную информацию, учиться на собственном опыте, участвовать в разговорах на естественном языке, проявлять творческий подход и проявлять другие качества, связанные с человеческим интеллектом.
По сути, он стремится создать системы искусственного интеллекта, которые могут имитировать или воспроизводить мышление и решение проблем на уровне человека в нескольких областях.
47. Цепочка вперед
Прямая цепочка — это метод рассуждений или логики, который начинается с доступных данных и использует их, чтобы делать выводы и делать новые выводы. Это похоже на соединение точек с помощью имеющейся информации для продвижения вперед и получения дополнительных сведений.
Представьте, что у вас есть набор правил или фактов, и вы хотите получить новую информацию или сделать на их основе конкретные выводы. Прямая цепочка работает путем изучения исходных данных и применения логических правил для получения дополнительных фактов или выводов.
Для упрощения рассмотрим простой сценарий определения того, что надеть, исходя из погодных условий. У вас есть правило, которое гласит: «Если идет дождь, возьмите с собой зонтик», и еще одно правило, которое гласит: «Если холодно, наденьте куртку». Теперь, если вы заметили, что действительно идет дождь, вы можете использовать прямую цепочку, чтобы сделать вывод, что вам следует взять с собой зонт.
48. Обратная цепочка
Обратная цепочка — это метод рассуждений, который начинается с желаемого вывода или цели и работает в обратном направлении, чтобы определить необходимые данные или факты, необходимые для подтверждения этого вывода. Это похоже на отслеживание ваших шагов от желаемого результата до исходной информации, необходимой для его достижения.
Чтобы понять обратную цепочку, давайте рассмотрим простой пример. Предположим, вы хотите определить, подходит ли он для купания. Желаемый вывод заключается в том, подходит ли плавание в определенных условиях.
Вместо того, чтобы начинать с условий, обратная цепочка начинается с заключения и работает в обратном направлении, чтобы найти подтверждающие данные.
В этом случае обратная цепочка будет включать в себя такие вопросы, как «Теплая ли погода?» Если ответ «да», вы спросите: «Есть ли доступный бассейн?» Если ответ снова «да», вы зададите дополнительные вопросы, например: «Есть ли у вас достаточно времени, чтобы поплавать?»
Повторно отвечая на эти вопросы и работая в обратном направлении, вы можете определить необходимые условия, которые должны быть выполнены, чтобы подтвердить вывод о том, что вы собираетесь поплавать.
49. Эвристика
Проще говоря, эвристика — это практическое правило или стратегия, которая помогает нам принимать решения или решать проблемы, обычно основываясь на нашем прошлом опыте или интуиции. Это похоже на мысленный ярлык, который позволяет нам быстро найти разумное решение, не прибегая к длительному или утомительному процессу.
При столкновении со сложными ситуациями или задачами эвристики служат руководящими принципами или «эмпирическими правилами», которые упрощают принятие решений. Они дают нам общие рекомендации или стратегии, которые часто эффективны в определенных ситуациях, даже если они не гарантируют оптимального решения.
Например, давайте рассмотрим эвристику для поиска места для парковки в людном месте. Вместо того, чтобы тщательно анализировать каждое доступное место, вы можете полагаться на эвристику поиска припаркованных автомобилей с работающими двигателями.
Эта эвристика предполагает, что эти автомобили собираются уехать, что увеличивает шансы найти свободное место.
50. Моделирование естественного языка
Проще говоря, моделирование естественного языка — это процесс обучения компьютерных моделей пониманию и генерации человеческого языка таким образом, который похож на то, как люди общаются. Он включает в себя обучение компьютеров обрабатывать, интерпретировать и генерировать текст естественным и осмысленным образом.
Цель моделирования естественного языка состоит в том, чтобы позволить компьютерам понимать и генерировать человеческий язык беглым, связным и контекстуально релевантным способом.
Он включает в себя обучение моделей на огромном количестве текстовых данных, таких как книги, статьи или разговоры, для изучения шаблонов, структур и семантики языка.
После обучения эти модели могут выполнять различные задачи, связанные с языком, такие как языковой перевод, обобщение текста, ответы на вопросы, взаимодействие с чат-ботами и многое другое.
Они могут понимать смысл и контекст предложений, извлекать соответствующую информацию и генерировать грамматически правильный и связный текст.





Оставьте комментарий