Cuprins[Ascunde][Spectacol]
Modelele mari text-to-image au făcut un progres semnificativ în dezvoltarea IA prin producerea de sinteză a imaginii de înaltă calitate și diversificată dintr-un prompt text dat.
Aceste modele nu sunt capabile să sintetizeze reprezentări unice ale subiecților în diferite setări sau să reproducă aspectul subiecților într-un set de referință dat.
Tehnologii recent lansate, cum ar fi DALL.E2 de la OpenAI sau StabilityAI Difuzie stabilă și Midjourney iau deja internetul cu asalt. Acum este timpul să personalizați rezultatele. Dar cum?
Google DreamBooth AI a sosit.
DreamBooth are capacitatea de a recunoaște subiectul unei imagini, de a o deconstrui din contextul său original și apoi de a o sintetiza cu precizie într-un nou context dorit. În plus, poate fi folosit cu generatoarele actuale de imagini AI.
În acest articol, vom arunca o privire profundă asupra DreamBooth, utilizarea sa, tutorialul său, limitările sale și multe altele.
Ce este Dreambooth?
cabină de vis, un nou model de difuzare text-to-image, a fost prezentat de Google. O solicitare scrisă poate fi folosită ca ghid de Google DreamBooth AI pentru a genera o gamă largă de fotografii ale subiectului selectat de utilizator în diferite setări.
Un grup de cercetare de la Universitatea din Boston și Google a dezvoltat DreamBooth, o tehnică de ultimă oră pentru modificarea modelelor text-to-image care au suferit o pregătire prealabilă extinsă.
Conceptul general este destul de simplu: ei doresc să mărească dicționarul de viziune lingvistică, astfel încât ID-urile de token neobișnuite să fie asociate cu subiecte personalizate pe care utilizatorii le pot defini.
Scopul principal al modelului este de a conecta utilizatorii la model de difuzie text-la-imagine oferindu-le resursele de care au nevoie pentru a produce reprezentări fotorealiste ale instanțelor subiectului lor selectat.
În consecință, această tehnică pare să funcționeze bine pentru a rezuma provocările într-o serie de situații.
DreamBooth de la Google diferă de instrumentele anterioare text-to-image, cum ar fi DALL-E2, Difuzie stabilă, și Mijlocul călătoriei, prin faptul că oferă utilizatorilor mai mult control asupra imaginii subiectului înainte de a le permite să manipuleze modelul de difuzie folosind intrări bazate pe text.
DESCRIERE
- DreamBooth AI ar putea îmbunătăți un model text-to-image cu 3-5 imagini.
- Fotografiile fotorealiste originale pot fi create cu DreamBooth AI.
- În plus, DreamBooth AI poate crea fotografii ale unui subiect din mai multe unghiuri.
aplicație
Reprezentări de artă
Această sarcină diferă în mod specific de transferul de stil, care păstrează semantica scenei sursă în timp ce încorporează stilul unei alte imagini în scena originală.

Pe baza abordării creative, AI poate realiza modificări semnificative ale scenei, păstrând în același timp identificarea și specificul subiectului.
Modificarea proprietății
Caracteristicile instanței subiectului pot fi modificate de DreamBooth AI.

Accesorizare
Compoziția puternică anterioară modelului de generație este ceea ce face ca abilitatea DreamBooth AI de a împodobi obiectele să fie atât de interesantă.

Recontextualizare
DreamBooth AI poate produce imagini distinctive pentru un anumit subiect, oferind unui model antrenat o propoziție care include identificatorul unic și substantivul clasei.

Poate genera subiectul în posturi, articulații și structură a scenei unice, nemaiauzite anterior, decât să schimbe împrejurimile. Reflecții și umbre realiste, precum și interacțiuni între subiect și obiectele din jur.
Tutorial Dreambooth
În acest tutorial, vom urmări Blocnotes Google Colab, și vă voi ghida prin el, ceea ce vă va face să înțelegeți și să îl folosiți singur.
Configurarea GPU-ului și instalarea bibliotecilor
Aflați ce tipuri de GPU și VRAM sunt disponibile este primul pas. Este, de asemenea, necesară instalarea câtorva cerințe și dependențe. Pur și simplu apăsați butonul de redare, apoi așteptați să se termine.
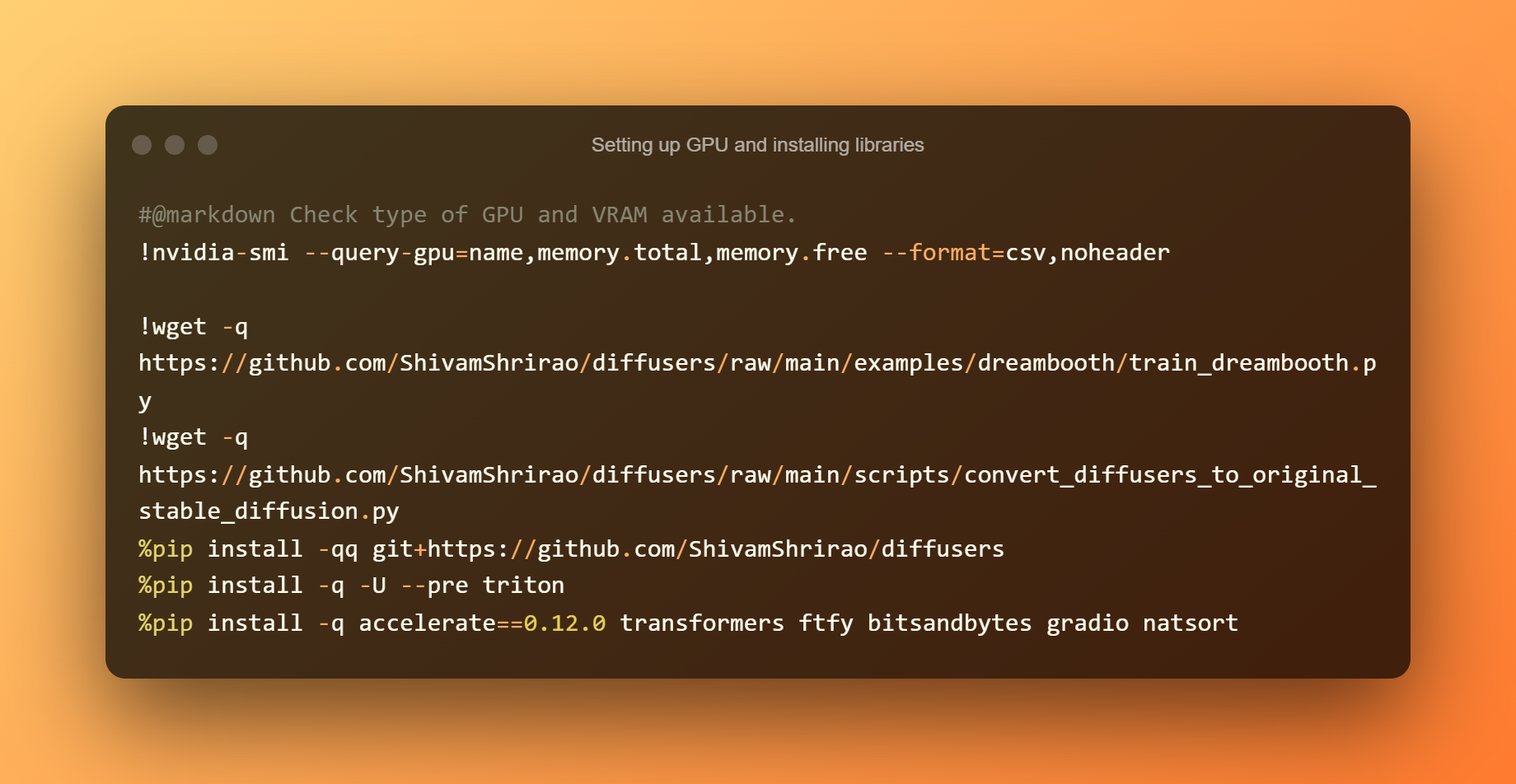
Creează un cont pe Huggingface și generează un token
Următorul pas este să vă înregistrați pentru un cont Huggingface. Când ați terminat, faceți clic pe setări în colțul din dreapta sus. Vei ajunge pe pagina următoare.
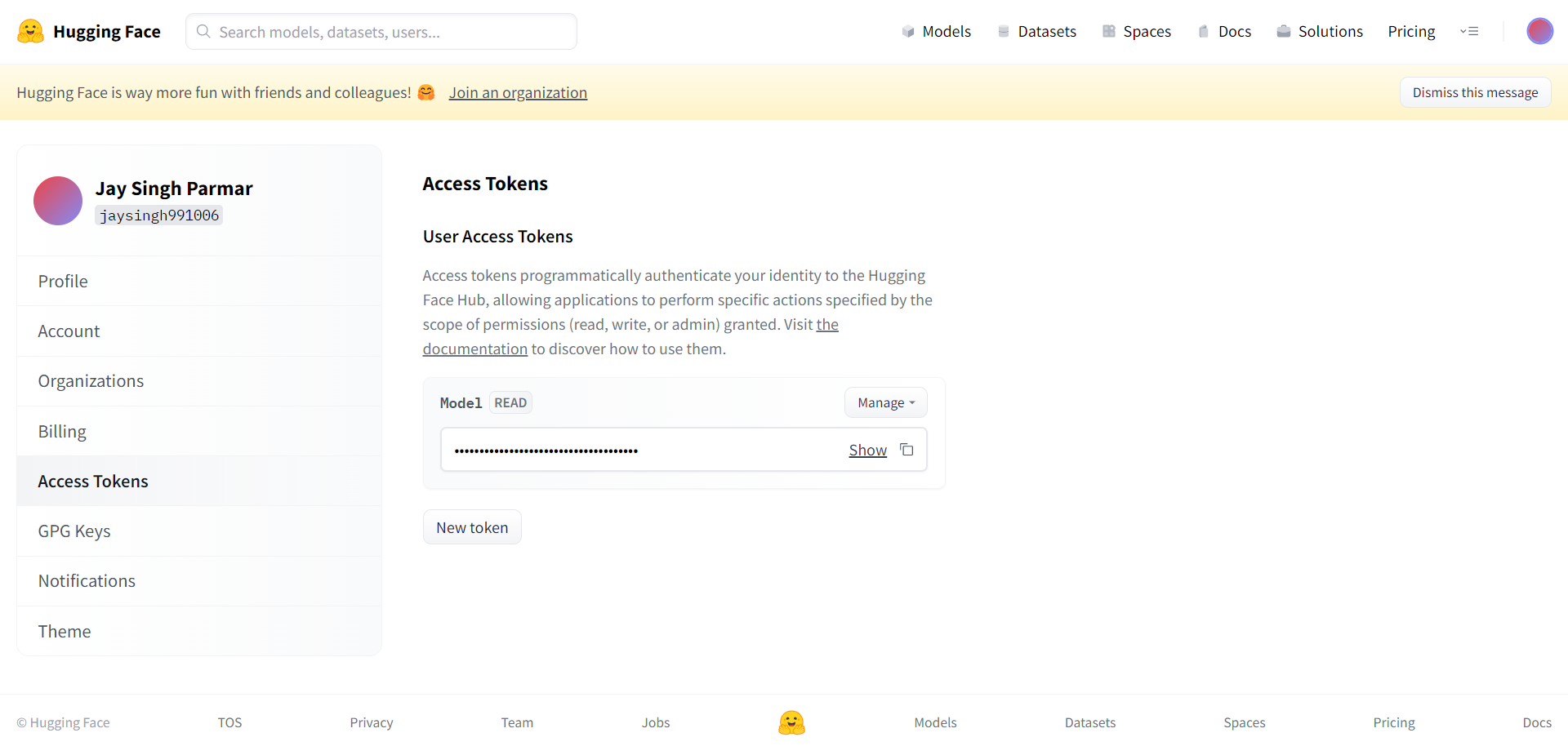
Creați simbolul și numele așa cum este solicitat de aici. Indicatorul trebuie copiat și lipit în colaborarea Google din celula de mai jos.

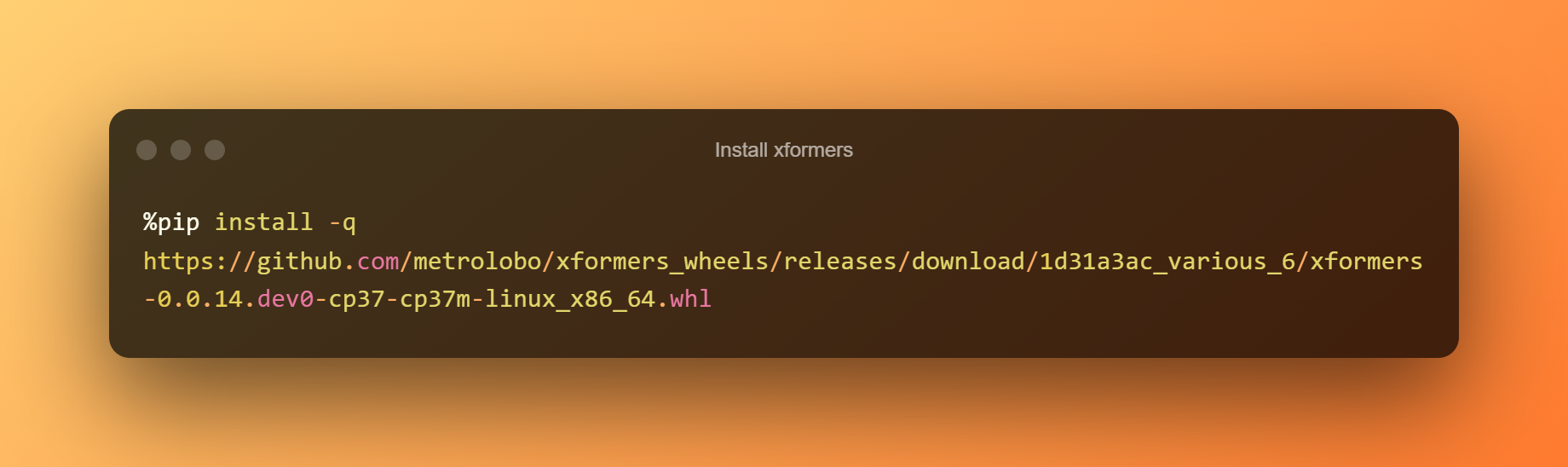
Instalați xformers
În această etapă, puteți apăsa pur și simplu butonul de redare pentru a instala xformers făcând clic pe runtime.
Conectați-vă la Drive
Acum, trebuie doar să rulați această celulă pentru a vă conecta la Google Drive.
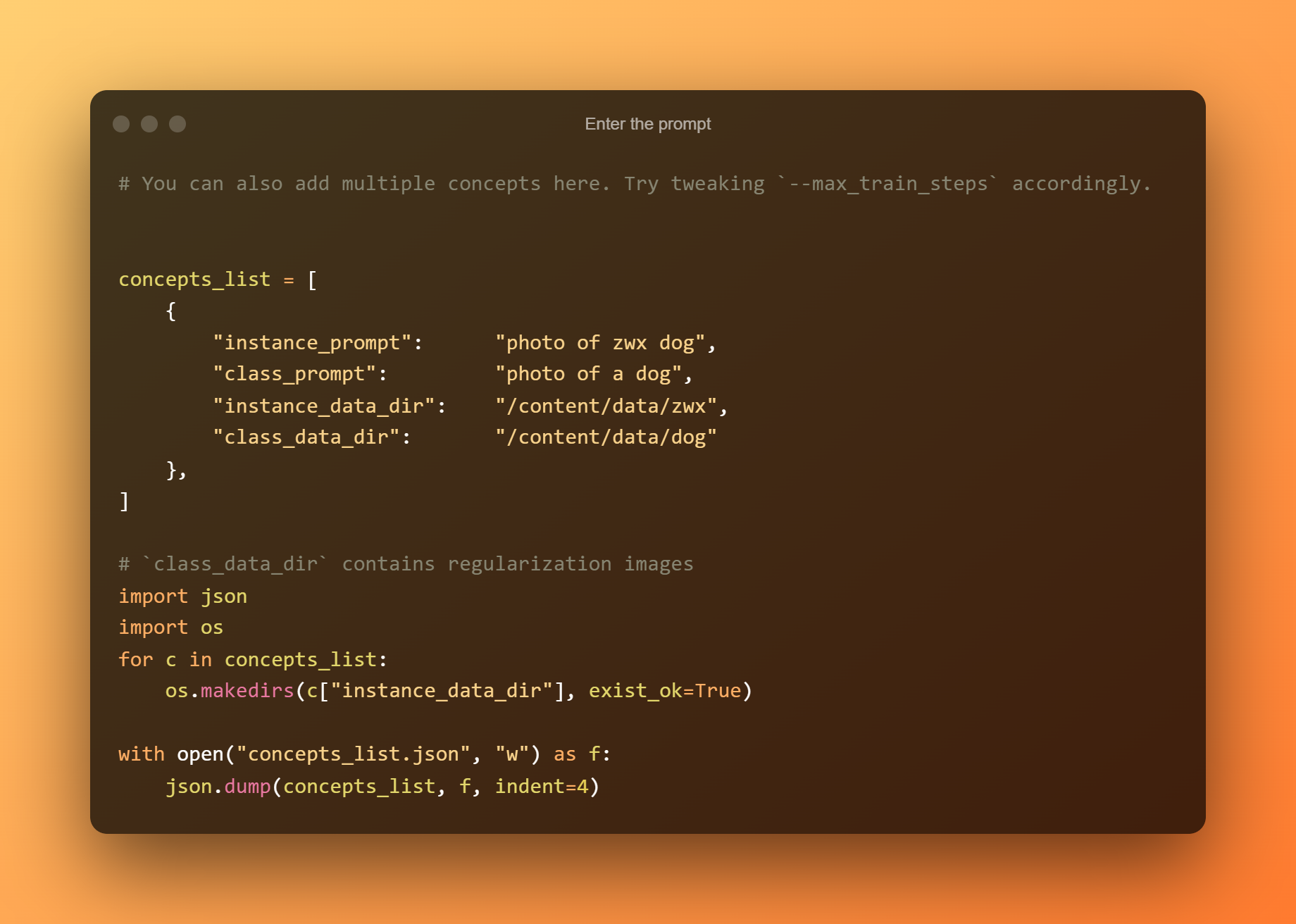
Introduceți solicitarea
În celula următoare, trebuie doar să introduceți promptul.
Încărcarea imaginilor
În acest pas, trebuie doar să încarci imaginile pe care ai vrut să le antrenezi.

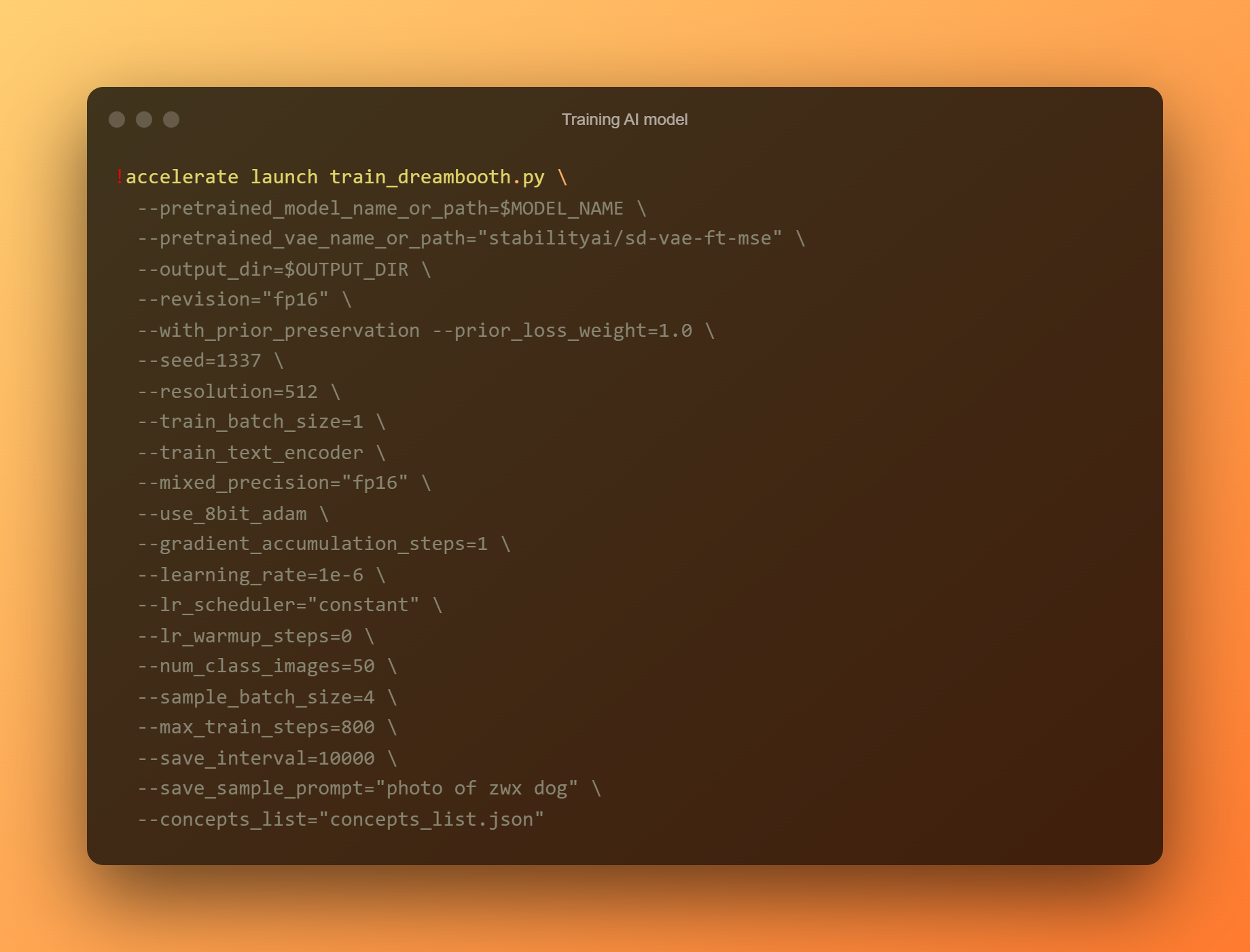
Antrenează modelul AI
Aceasta este cea mai importantă fază, deoarece veți folosi DreamBooth pentru a antrena un nou model AI bazat pe toate fotografiile de referință trimise. Trebuie să vă limitați atenția la două câmpuri de introducere. „—instance prompt” este primul parametru. Trebuie să furnizați un nume foarte distinct aici.
Argumentul „–lista de concepte” este al doilea câmp de intrare critic. Trebuie redenumit pentru a se potrivi cu cel utilizat în secțiunea „Schimbați solicitarea”.
Generați imagini AI
Imaginile AI vor fi create în această etapă, unde puteți introduce instrucțiunile text.

Limitări Dreambooth
- Promptul de comandă devine o barieră în a face iterații în subiect cu grade ridicate de detaliu. DreamBooth poate schimba contextul subiectului, dar dacă modelul dorește să schimbe subiectul în sine, există probleme cu cadrul.
- O altă problemă este supraadaptarea imaginii de ieșire la imaginea de intrare. Dacă nu sunt suficiente imagini furnizate, subiectul poate să nu fie luat în considerare sau poate fi amestecat cu contextul imaginilor trimise. Când este întrebat un context pentru o generație ciudată, același lucru are loc.
Concluzie
Pentru a produce rezultate dintr-o singură intrare de text, cea mai mare parte a modelelor text-to-image necesită milioane de parametri și biblioteci.
DreamBooth simplifică achiziția și utilizarea conținutului de către consumatori, necesitând doar introducerea a trei până la cinci fotografii tematice împreună cu un fundal textual.





Lasă un comentariu