Modelele de difuzie au măturat globul cu furtună odată cu lansarea Dall-E 2, Imagine de la Google, Difuzie stabilă, și Mijlocul călătoriei, declanșând inovația și extinzând limitele învățării automate.
Aceste modele pot produce un număr aproape nelimitat de imagini din solicitări de cuvinte, inclusiv imagini fotorealiste, magice, futuriste și, desigur, drăguțe.
Aceste capabilități reimaginează ce înseamnă pentru oameni să interacționeze cu siliciul, oferindu-ne capacitatea de a face practic orice imagine pe care o putem imagina.
Pe măsură ce aceste modele se dezvoltă sau următoarea paradigmă generativă preia, oamenii vor putea produce imagini, filme și alte experiențe imersive doar cu un gând.
În această postare, vom discuta despre model de difuzie, difuzie stabilă, cum funcționează și un tutorial de pictare a modelului de difuzie, printre altele.
Ce este modelul de difuzie?
Modelele de învățare automată care pot crea date noi din datele de antrenament sunt denumite modele generative. Alte modele generative includ modele bazate pe flux, autoencodere variaționale și rețele adverse generative (GAN).
Fiecare poate genera imagini de o calitate excelentă. Modelele de difuzie învață să recupereze datele inversând acest proces de adăugare a zgomotului după ce au deteriorat datele de antrenament prin adăugarea de zgomot. Altfel spus, modelele de difuzie sunt capabile să creeze imagini coerente din zgomot.
Modelele de difuzie învață introducând zgomot în imagini, pe care modelul îl stăpânește ulterior să-l elimine. Pentru a produce imagini realiste, modelul aplică apoi această tehnică de dezgomot semințelor aleatorii.
Condiționând procesul de producție a imaginii, aceste modele pot fi utilizate împreună cu ghidarea text-to-image pentru a genera un număr aproape nelimitat de imagini numai din text. Semințele pot fi direcționate prin intrări de la înglobare precum CLIP pentru a oferi capabilități puternice de transpunere text la imagine.
Modelele de difuzie pot îndeplini o varietate de sarcini, inclusiv crearea de imagini, eliminarea zgomotului, pictarea în interior, pictarea și difuzarea biților.
Acum, ce este difuzia stabilă?
Stable Diffusion este un model de învățare automată pentru crearea de imagini bazate pe text oferit de Stabilitate.AI. Este capabil să genereze imagini din text.
Componentele difuziei stabile
Difuzie stabilă este un sistem compus din mai multe componente și concepte. Nu este un singur model. Când verificăm în spatele capotei, primul lucru pe care îl vedem este că există o componentă de înțelegere a textului care convertește informațiile textului într-o reprezentare numerică care surprinde conceptele textului.
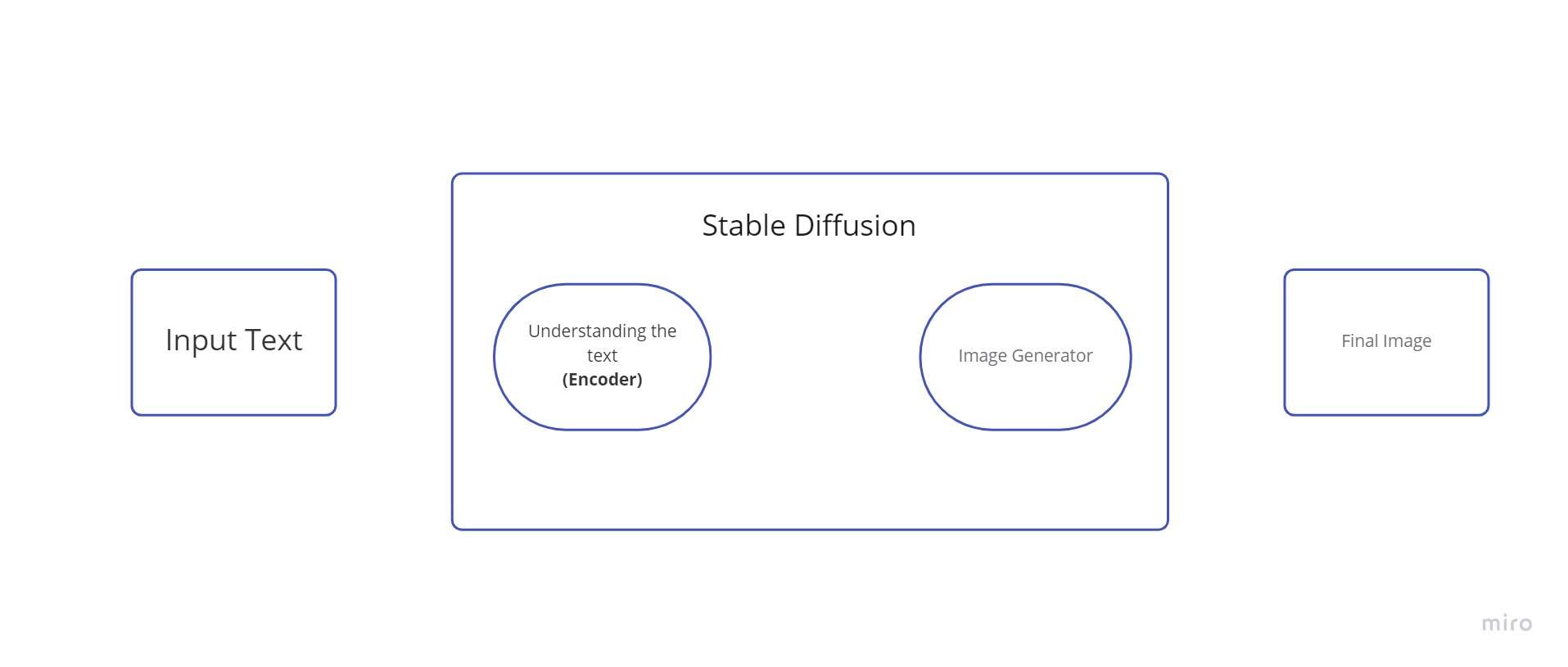
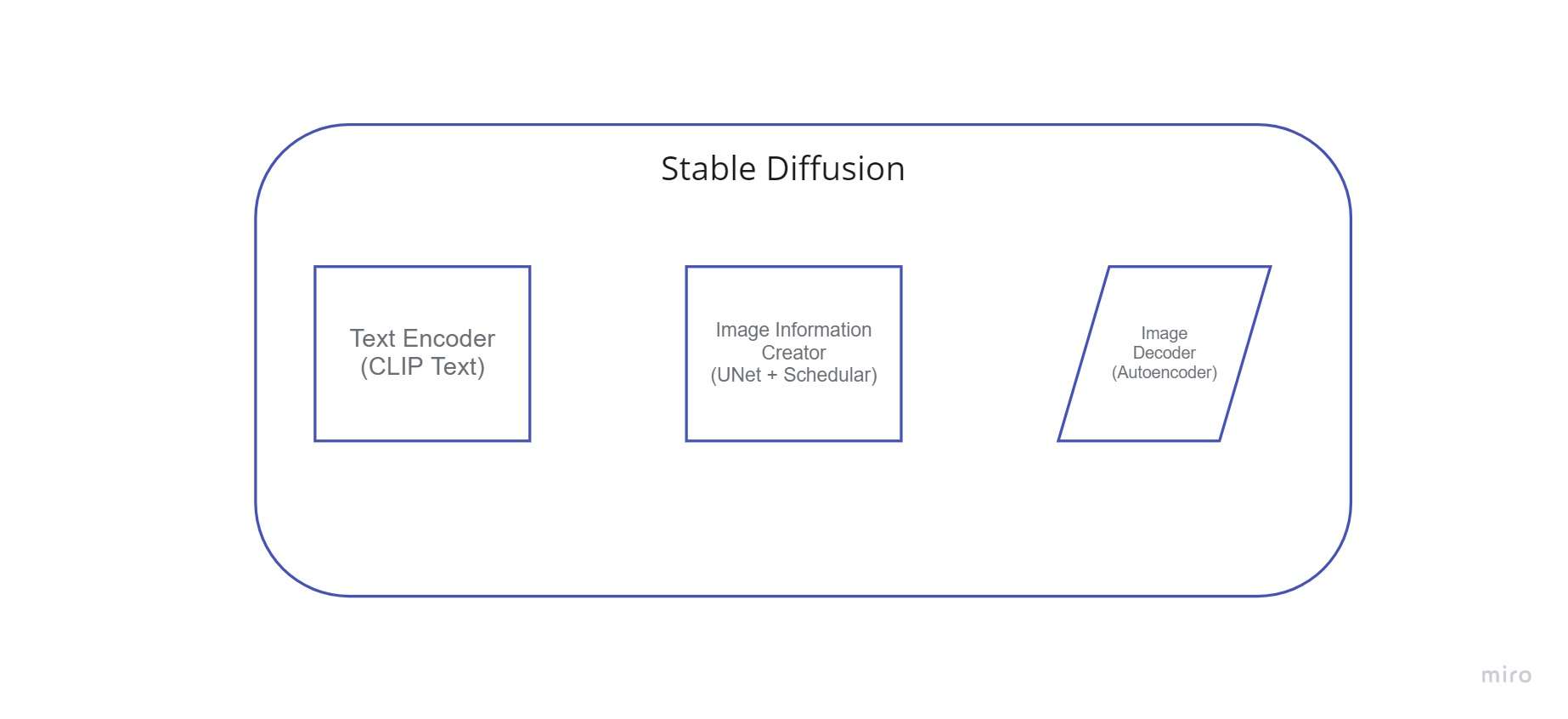
Putem numi acest codificator de text un Transformer model de limbaj (din punct de vedere tehnic: codificatorul de text al unui model CLIP). Acesta preia textul de intrare și generează o listă de numere întregi (un vector) pentru fiecare cuvânt/token din text. Aceste date sunt apoi furnizate la Image Generator, care este alcătuit din mai multe componente.
Există doi pași în generatorul de imagini:
1. Creator de informații despre imagine
Componenta majoră în Stable Diffusion este acest element. Este locul în care se realizează cea mai mare parte a îmbunătățirii performanței față de versiunile anterioare.
Această componentă trece prin mai multe etape pentru a furniza date de imagine. Creatorul de informații despre imagine operează numai în spațiul de informații despre imagine (sau spațiul latent).
Datorită acestei caracteristici, este mai rapid decât modelele de difuzie anterioare care funcționau în spațiul pixelilor. Tehnic vorbind, această componentă este compusă dintr-un algoritm de planificare și un UNet rețele neuronale.
Procesul care are loc în această componentă este denumit „difuzie”. O imagine de înaltă calitate este în cele din urmă produsă ca urmare a procesării informației în pași (de către următoarea componentă, decodorul de imagine).
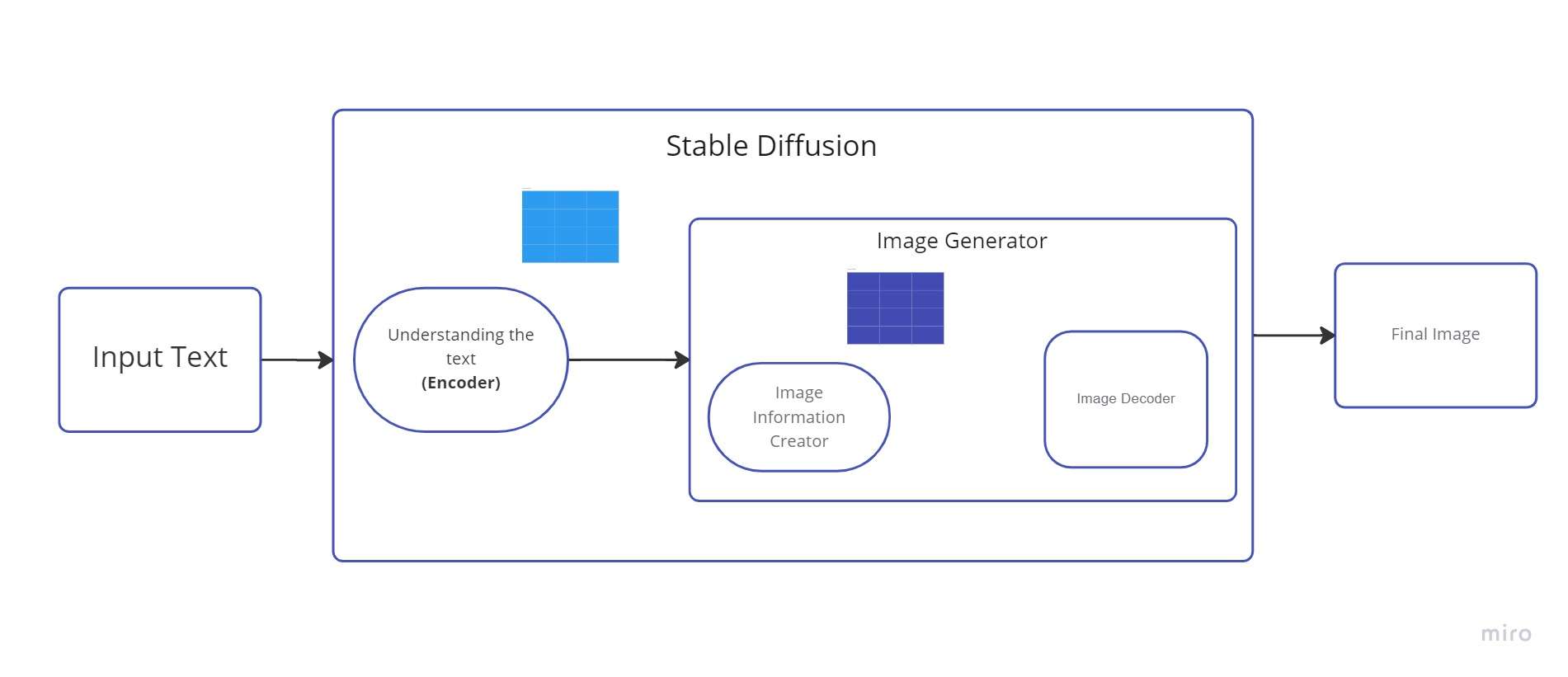
2. Decodor de imagine
Folosind datele pe care le-a primit de la producătorul de informații, decodorul de imagine creează o imagine. Se execută doar o dată pentru a crea imaginea pixelilor terminată la încheierea operației.
Tutorial Stable Diffusion Imppainting
Pictura cu difuzie stabilă a imaginii este tehnica de completare a zonelor lipsă sau deteriorate ale unei imagini. Scopul picturii în pictură este de a ascunde faptul că imaginea a fost restaurată.
Această tehnică este folosită frecvent pentru a elimina lucrurile nedorite dintr-o imagine sau pentru a restaura zonele deteriorate ale fotografiilor istorice. Stabile Diffusion Inpainting este o modalitate relativ recentă de inpainting care dă efecte promițătoare.
Urmând instrucțiunile de mai jos, veți începe să explorați inpainting și să modificați fotografiile existente dacă doriți să încercați inpainting cu difuzie stabilă:
- Accesați Huggingface Difuziune stabilă de imprimare
- Încărcați propria imagine
- Ștergeți partea din imagine care trebuie înlocuită.
- Introduceți solicitarea aici (ce doriți să adăugați în loc de ceea ce eliminați)
- Selectați „a alerga”
În videoclipul de sus, încărcăm o poză cu trei lămâi și le schimbăm cu mere. Recomand personal să-l încercați cu propriile fotografii și recomandări.
Concluzie
În general, difuzia constantă în pictură este o metodă excelentă pentru a produce imagini sau videoclipuri false care par a fi extrem de reale. Pe măsură ce ne îndreptăm către noile progrese tehnologice, va deveni din ce în ce mai greu să facem distincția între autentic și fraudulos pe măsură ce tehnologia avansează.





Prima repriză nu are nicio legătură cu a doua repriză. Ar fi fost foarte grozav dacă autorul ar fi explicat cum funcționează inpaint în cadrul modelului pe care l-a explicat mai devreme, ar fi putut oferi perspective. Dar nu! Asta ar fi necesitat o înțelegere reală, mai degrabă decât colectarea și procesarea unui text aleatoriu.