E se pudéssemos usar a inteligência artificial para responder a um dos maiores mistérios da vida – dobramento de proteínas? Os cientistas vêm trabalhando nisso há décadas.
As máquinas agora podem prever estruturas de proteínas com incrível precisão usando modelos de aprendizado profundo, alterando o desenvolvimento de medicamentos, a biotecnologia e nosso conhecimento de processos biológicos fundamentais.
Junte-se a mim em uma exploração do intrigante domínio do dobramento de proteínas de IA, onde a tecnologia de ponta colide com a complexidade da própria vida.
Desvendando o mistério do dobramento de proteínas
As proteínas funcionam em nossos corpos como pequenas máquinas para realizar tarefas cruciais, como quebrar alimentos ou transportar oxigênio. Eles devem ser dobrados corretamente para que funcionem de maneira eficaz, assim como uma chave deve ser cortada corretamente para caber em uma fechadura. Assim que a proteína é criada, começa um processo de dobramento muito complicado.
O dobramento de proteínas é o processo pelo qual longas cadeias de aminoácidos, os blocos de construção da proteína, se dobram em estruturas tridimensionais que ditam a função da proteína.
Considere um longo cordão de contas que deve ser ordenado em uma forma precisa; é isso que ocorre quando uma proteína se dobra. No entanto, ao contrário dos grânulos, os aminoácidos têm características únicas e interagem uns com os outros de várias maneiras, tornando o dobramento de proteínas um processo complexo e sensível.
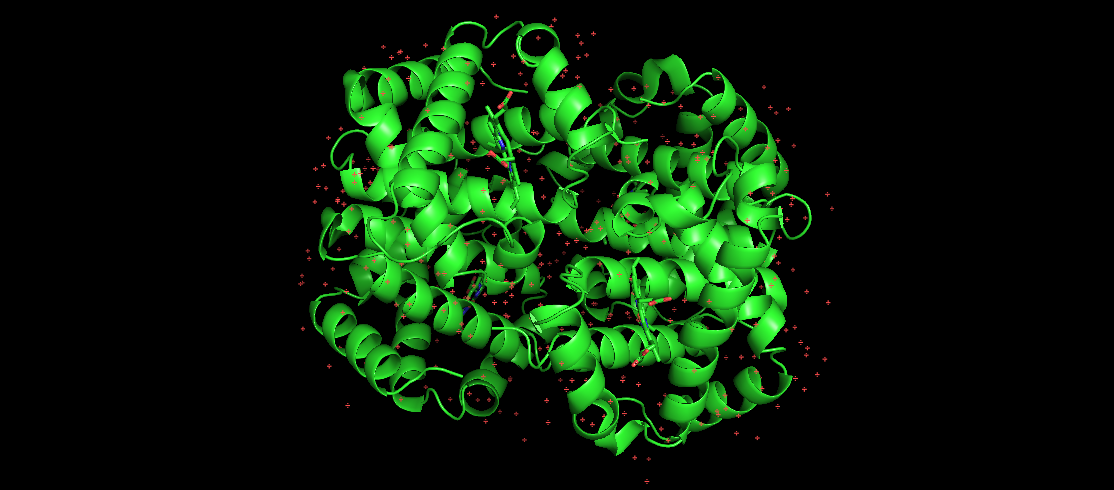
A imagem aqui representa a hemoglobina humana, que é uma proteína dobrada bem conhecida
As proteínas devem se dobrar de forma rápida e precisa, ou se tornarão mal dobradas e defeituosas. Isso pode levar a doenças como Alzheimer e Parkinson. Temperatura, pressão e a presença de outras moléculas na célula têm efeito no processo de dobramento.
Após décadas de pesquisa, os cientistas ainda estão tentando descobrir exatamente como as proteínas se dobram.
Felizmente, os avanços na inteligência artificial estão melhorando o desenvolvimento do setor. Os cientistas podem antecipar a estrutura das proteínas com mais precisão do que nunca, usando algoritmos de aprendizado de máquina para examinar grandes volumes de dados.
Isso tem o potencial de mudar o desenvolvimento de medicamentos e aumentar nosso conhecimento molecular da doença.
As máquinas podem ter um desempenho melhor?
Técnicas convencionais de dobramento de proteínas têm limitações
Os cientistas tentam descobrir o dobramento de proteínas há décadas, mas a complexidade do processo tornou isso um assunto desafiador.
Abordagens convencionais de previsão de estrutura de proteína usam uma combinação de metodologias experimentais e modelagem por computador, no entanto, todos esses métodos têm desvantagens.
Técnicas experimentais como cristalografia de raios-X e ressonância magnética nuclear (NMR) podem ser demoradas e caras. E, às vezes, os modelos de computador dependem de suposições simples, que podem levar a previsões errôneas.
A IA pode superar esses obstáculos
Felizmente, inteligência artificial está fornecendo uma nova promessa para uma previsão de estrutura de proteína mais precisa e eficiente. Algoritmos de aprendizado de máquina podem examinar grandes volumes de dados. E eles descobrem padrões que as pessoas sentiriam falta.
Isso resultou na criação de novas ferramentas e plataformas de software capazes de prever a estrutura da proteína com precisão incomparável.
Os algoritmos de aprendizado de máquina mais promissores para previsão da estrutura de proteínas
O sistema AlphaFold construído pelo Google DeepMind equipe é um dos avanços mais promissores nesta área. Ele ganhou grande progresso nos últimos anos usando algoritmos de aprendizagem profunda para prever a estrutura das proteínas com base em suas sequências de aminoácidos.
Redes neurais, máquinas de vetores de suporte e florestas aleatórias estão entre os métodos de aprendizado de máquina que se mostram promissores para prever a estrutura de proteínas.
Esses algoritmos podem aprender com enormes conjuntos de dados. E eles podem antecipar as correlações entre diferentes aminoácidos. Então, vamos ver como funciona.

Análises Coevolutivas e a Primeira Geração AlphaFold
O sucesso do AlfaFold é construído em um modelo de rede neural profunda que foi desenvolvido utilizando análise coevolutiva. O conceito de coevolução afirma que, se dois aminoácidos em uma proteína interagirem entre si, eles se desenvolverão juntos para manter seu vínculo funcional.
Os pesquisadores podem detectar quais pares de aminoácidos provavelmente estão em contato na estrutura 3D comparando as sequências de aminoácidos de várias proteínas semelhantes.
Esses dados servem como base para a primeira iteração do AlphaFold. Ele prevê os comprimentos entre os pares de aminoácidos, bem como os ângulos das ligações peptídicas que os ligam. Este método superou todas as abordagens anteriores para prever a estrutura da proteína a partir da sequência, embora a precisão ainda fosse restrita para proteínas sem moldes aparentes.

AlphaFold 2: uma metodologia radicalmente nova
AlphaFold2 é um software de computador criado pela DeepMind que usa a sequência de aminoácidos de uma proteína para prever a estrutura 3D da proteína.
Isso é significativo porque a estrutura de uma proteína determina como ela funciona, e entender sua função pode ajudar os cientistas a desenvolver medicamentos que tenham como alvo a proteína.
A rede neural AlphaFold2 recebe como entrada a sequência de aminoácidos da proteína, bem como detalhes sobre como essa sequência se compara a outras sequências em um banco de dados (isso é chamado de “alinhamento de sequência”).
A rede neural faz uma previsão sobre a estrutura 3D da proteína com base nessa entrada.
O que o diferencia do AlphaFold2?
Em contraste com outras abordagens, o AlphaFold2 prevê a estrutura 3D real da proteína, em vez de apenas a separação entre pares de aminoácidos ou os ângulos entre as ligações que os conectam (como faziam os algoritmos anteriores).
Para que a rede neural antecipe a estrutura completa de uma só vez, a estrutura é codificada de ponta a ponta.
Outra característica importante do AlphaFold2 é que ele oferece uma estimativa de quão confiante está em sua previsão. Isso é apresentado como um código de cores na estrutura antecipada, com vermelho representando alta confiança e azul sugerindo baixa confiança.
Isso é útil, pois informa os cientistas sobre a estabilidade da previsão.
Prevendo a estrutura combinada de várias sequências
A mais recente expansão do Alphafold2, conhecida como Alphafold Multimer, prevê a estrutura combinada de várias sequências. Ele ainda apresenta altas taxas de erros, mesmo que tenha um desempenho muito melhor do que as técnicas anteriores. Apenas 25% de 4500 complexos proteicos foram previstos com sucesso.
70% das regiões rugosas de formação de contato foram previstas corretamente, mas a orientação relativa das duas proteínas estava incorreta. Quando a profundidade de alinhamento mediana é inferior a aproximadamente 30 sequências, a precisão das previsões do multímero Alphafold diminui significativamente.
Como usar previsões alfabéticas
Os modelos previstos do AlphaFold são oferecidos nos mesmos formatos de arquivo e podem ser usados da mesma forma que as estruturas experimentais. É crucial levar em consideração as estimativas de precisão oferecidas com o modelo para evitar mal-entendidos.
É especialmente útil para estruturas complicadas como homômeros entrelaçados ou proteínas que só se dobram na presença de um
ligante desconhecido.
Alguns desafios
O principal problema no uso de estruturas previstas é entender a dinâmica, seletividade do ligante, controle, alosteria, mudanças pós-traducionais e cinética de ligação sem acesso a dados de proteínas e biofísicos.
Aprendizado de máquinas e a pesquisa de dinâmica molecular baseada na física pode ser utilizada para superar esse problema.
Essas investigações podem se beneficiar de uma arquitetura computacional especializada e eficiente. Embora o AlphaFold tenha alcançado grandes avanços na previsão de estruturas de proteínas, ainda há muito a aprender no campo da biologia estrutural, e as previsões do AlphaFold são apenas o ponto de partida para estudos futuros.
Quais são outras ferramentas notáveis?
RosaTTAFold
O RoseTTAFold, criado por pesquisadores da Universidade de Washington, também emprega algoritmos de aprendizado profundo para prever estruturas de proteínas, mas também integra uma nova abordagem conhecida como “simulações de dinâmica de ângulo de torção” para melhorar as estruturas previstas.
Este método produziu resultados encorajadores e pode ser útil para superar as limitações das ferramentas existentes de dobramento de proteínas AI.
trRosetta
Outra ferramenta, trRosetta, prevê o dobramento de proteínas usando um rede neural treinados em milhões de sequências e estruturas de proteínas.
Ele também usa uma técnica de “modelagem baseada em modelo” para criar previsões mais precisas comparando a proteína-alvo com estruturas conhecidas comparáveis.
Foi demonstrado que o trRosetta é capaz de prever as estruturas de pequenas proteínas e complexos de proteínas.
DeepMeta PSICOV
DeepMetaPSICOV é outra ferramenta que se concentra na previsão de mapas de contato de proteínas. Estes, são usados como um guia para prever o dobramento de proteínas. ele usa deep learning abordagens para prever a probabilidade de interações de resíduos dentro de uma proteína.
Estes são subsequentemente usados para prever o mapa geral de contato. O DeepMetaPSICOV demonstrou potencial na previsão de estruturas de proteínas com grande precisão, mesmo quando as abordagens anteriores falharam.
O que o futuro guarda?
O futuro do dobramento de proteínas AI é brilhante. Algoritmos baseados em aprendizado profundo, principalmente o AlphaFold2, fizeram recentemente grandes progressos na previsão confiável de estruturas de proteínas.
Essa descoberta tem o potencial de transformar o desenvolvimento de medicamentos, permitindo que os cientistas entendam melhor a estrutura e a função das proteínas, que são alvos terapêuticos comuns.
No entanto, questões como prever complexos de proteínas e detectar o estado funcional real de estruturas antecipadas permanecem. Mais pesquisas são necessárias para resolver esses problemas e aumentar a precisão e a confiabilidade dos algoritmos de dobramento de proteínas AI.
No entanto, os benefícios potenciais dessa tecnologia são enormes e podem levar à produção de medicamentos mais eficazes e precisos.





Deixe um comentário