Conteúdo[Esconder][Mostrar]
O futuro está aqui. E, neste futuro, as máquinas compreendem o mundo ao seu redor da mesma forma que as pessoas. Os computadores podem dirigir automóveis, diagnosticar doenças e prever com precisão o futuro.
Isso pode parecer ficção científica, mas os modelos de aprendizado profundo estão tornando isso uma realidade.
Esses algoritmos sofisticados estão revelando os segredos da inteligência artificial, permitindo que os computadores aprendam e se desenvolvam sozinhos. Neste post, vamos nos aprofundar no domínio dos modelos de aprendizado profundo.
E investigaremos o enorme potencial que eles têm para revolucionar nossas vidas. Prepare-se para aprender sobre a tecnologia de ponta que está mudando o futuro da humanidade.

O que exatamente são modelos de aprendizado profundo?
Você já jogou um jogo em que precisa identificar as diferenças entre duas imagens?
É divertido no entanto, também pode ser difícil, certo? Imagine ser capaz de ensinar um computador a jogar esse jogo e ganhar todas as vezes. Os modelos de aprendizado profundo realizam exatamente isso!
Os modelos de aprendizado profundo são semelhantes a máquinas superinteligentes que podem examinar um grande número de imagens e determinar o que elas têm em comum. Eles conseguem isso desmontando as imagens e estudando cada uma individualmente.
Eles então aplicam o que aprenderam para identificar padrões e fazer previsões sobre novas imagens que nunca viram antes.

Os modelos de aprendizado profundo são redes neurais artificiais que podem aprender e extrair padrões e características complicadas de conjuntos de dados massivos. Esses modelos são compostos de várias camadas de nós vinculados, ou neurônios, que analisam e alteram os dados recebidos para gerar uma saída.
Os modelos de aprendizado profundo são particularmente adequados para trabalhos que exigem grande exatidão e precisão, como identificação de imagem, reconhecimento de fala, processamento de linguagem natural e robótica.
Eles têm sido utilizados em tudo, desde carros autônomos até diagnósticos médicos, sistemas de recomendação e análise preditiva.
Aqui está uma versão simplificada da visualização para ilustrar o fluxo de dados em um modelo de aprendizado profundo.
Os dados de entrada fluem para a camada de entrada do modelo, que passa os dados por várias camadas ocultas antes de fornecer uma previsão de saída.
Cada camada oculta executa uma série de operações matemáticas nos dados de entrada antes de passá-los para a próxima camada, que fornece a previsão final.
Agora, vamos ver o que são modelos de aprendizagem profunda e como podemos usá-los em nossa vida.
1. Redes Neurais Convolucionais (CNNs)
As CNNs são um modelo de aprendizado profundo que transformou a área de visão computacional. As CNNs são usadas para classificar imagens, reconhecer objetos e segmentar imagens. A estrutura e a função do córtex visual humano informaram o design das CNNs.
Como eles funcionam?
Uma CNN é composta de várias camadas convolucionais, camadas de pooling e camadas totalmente vinculadas. A entrada é uma imagem e a saída é uma previsão do rótulo de classe da imagem.
As camadas convolucionais de uma CNN constroem um mapa de recursos realizando um produto escalar entre a imagem de entrada e um conjunto de filtros. As camadas de agrupamento diminuem o tamanho do mapa de recursos reduzindo sua resolução.
Por fim, o mapa de recursos é usado pelas camadas totalmente conectadas para prever o rótulo de classe da imagem.

Por que as CNNs são importantes?
As CNNs são essenciais porque podem aprender a detectar padrões e características em imagens que as pessoas acham difíceis de perceber. As CNNs podem ser ensinadas a reconhecer características como arestas, cantos e texturas usando grandes conjuntos de dados. Depois de aprender essas propriedades, uma CNN pode usá-las para identificar objetos em novas fotos. As CNNs demonstraram desempenho de ponta em uma variedade de aplicações de identificação de imagens.
Onde usamos CNNs
Saúde, indústria automobilística e varejo são apenas alguns setores que empregam CNNs. No setor de saúde, eles podem ser benéficos para diagnóstico de doenças, desenvolvimento de medicamentos e análise de imagens médicas.
No setor automobilístico, auxiliam na detecção de faixas, detecção de objetos, e condução autónoma. Eles também são muito usados no varejo para pesquisa visual, recomendação de produtos baseada em imagens e controle de estoque.
Por exemplo; O Google emprega CNNs em uma variedade de aplicações, incluindo Google Lens, uma ferramenta de identificação de imagem popular. O programa usa CNNs para avaliar fotografias e fornecer informações aos usuários.
O Google Lens, por exemplo, pode reconhecer coisas em uma imagem e oferecer detalhes sobre elas, como o tipo de flor.

Também pode traduzir o texto extraído de uma imagem para vários idiomas. O Google Lens é capaz de fornecer informações úteis aos consumidores por causa da assistência das CNNs na identificação precisa de itens e na extração de características das fotos.
2. Redes de memória de longo prazo (LSTM)
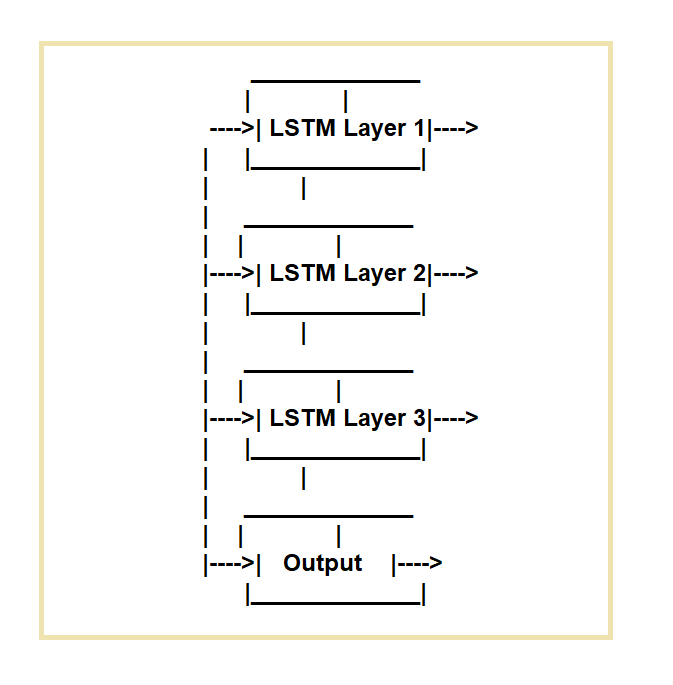
As redes Long Short-Term Memory (LSTM) são criadas para resolver as deficiências das redes neurais recorrentes regulares (RNNs). As redes LSTM são ideais para tarefas que exigem o processamento de sequências de dados ao longo do tempo.
Eles funcionam empregando uma célula de memória específica e três mecanismos de controle.
Eles regulam o fluxo de informações para dentro e para fora da célula. O portão de entrada, o portão de esquecimento e o portão de saída são os três portões.
A porta de entrada regula o fluxo de dados para a célula de memória, a porta de esquecimento regula a exclusão de dados da célula e a porta de saída regula o fluxo de dados para fora da célula.
Qual é o seu significado?
As redes LSTM são úteis porque podem representar e prever com sucesso sequências de dados com relacionamentos de longo prazo. Eles podem registrar e reter informações sobre entradas anteriores, permitindo que façam previsões mais precisas sobre entradas futuras.
Reconhecimento de fala, reconhecimento de manuscrito, processamento de linguagem natural e legendagem de imagens são apenas alguns dos aplicativos que fizeram uso das redes LSTM.
Onde usamos redes LSTM?
Muitos aplicativos de software e tecnologia empregam redes LSTM, incluindo sistemas de reconhecimento de fala, ferramentas de processamento de linguagem natural como análise de sentimentos, sistemas de tradução automática e sistemas de geração de texto e imagem.
Eles também foram utilizados na criação de carros e robôs autônomos, bem como no setor financeiro para detectar fraudes e antecipar mercado de ações movimentos.
3. Redes Geradoras Adversariais (GANs)
GANs são um deep learning técnica que é usada para gerar novas amostras de dados que são semelhantes a um determinado conjunto de dados. As GANs são compostas por dois redes neurais: aquele que aprende a produzir novas amostras e aquele que aprende a distinguir entre amostras genuínas e geradas.
Em uma abordagem semelhante, essas duas redes são treinadas juntas até que o gerador possa gerar amostras indistinguíveis das reais.
Por que usamos GANs
As GANs são importantes devido à sua capacidade de produzir dados sintéticos que podem ser utilizados para uma variedade de aplicações, incluindo produção de imagem e vídeo, geração de texto e até mesmo geração de música.
As GANs também foram usadas para aumento de dados, que é a geração de dados sintéticos para complementar os dados do mundo real e melhorar o desempenho dos modelos de aprendizado de máquina.
Além disso, ao criar dados sintéticos que podem ser usados para treinar modelos e imitar ensaios, as GANs têm o potencial de transformar setores como medicina e desenvolvimento de medicamentos.

Aplicações de GANs
Os GANs podem complementar conjuntos de dados, criar novas imagens ou filmes e até mesmo gerar dados sintéticos para simulações científicas. Além disso, as GANs têm potencial para serem empregadas em uma variedade de aplicações, desde entretenimento até medicina.
idades e vídeos. O StyleGAN2 da NVIDIA, por exemplo, foi usado para criar fotografias de alta qualidade de celebridades e obras de arte.
4. Redes de Crença Profunda (DBNs)
Deep Belief Networks (DBNs) são inteligência artificial sistemas que podem aprender a detectar padrões nos dados. Eles conseguem isso segmentando os dados em pedaços cada vez menores, obtendo uma compreensão mais completa deles em cada nível.
Os DBNs podem aprender com os dados sem serem informados sobre o que são (isso é chamado de “aprendizado não supervisionado”). Isso os torna extremamente valiosos para detectar padrões em dados que uma pessoa acharia difíceis ou impossíveis de discernir.
O que torna os DBNs significativos?
DBNs são importantes por causa de sua capacidade de aprender representações hierárquicas de dados. Essas representações podem ser utilizadas para uma variedade de aplicações, como classificação, detecção de anomalias e redução de dimensionalidade.
A capacidade dos DBNs de realizar pré-treinamento não supervisionado, que pode aumentar o desempenho de modelos de aprendizado profundo com o mínimo de dados rotulados, é um benefício significativo.

Quais são as aplicações dos DBNs?
Uma das aplicações mais significativas é detecção de objetos, em que DBNs são usados para reconhecer certos tipos de coisas, como aviões, pássaros e humanos. Eles também são utilizados para geração e classificação de imagens, detecção de movimento em filmes e compreensão de linguagem natural para processamento de voz.
Além disso, DBNs são comumente empregados em conjuntos de dados para avaliar posturas humanas. Os DBNs são uma ótima ferramenta para uma variedade de setores, incluindo saúde, bancos e tecnologia.
5. Redes de Aprendizagem por Reforço Profundo (DRLs)
profundo Aprendizagem por Reforço As redes (DRLs) integram redes neurais profundas com técnicas de aprendizado por reforço para permitir que os agentes aprendam em um ambiente complicado por meio de tentativa e erro.
Os DRLs são usados para ensinar aos agentes como otimizar um sinal de recompensa, interagindo com o ambiente e aprendendo com seus erros.
O que os torna notáveis?
Eles têm sido usados efetivamente em uma variedade de aplicações, incluindo jogos, robótica e direção autônoma. Os DRLs são importantes porque podem aprender diretamente com a entrada sensorial bruta, permitindo que os agentes tomem decisões com base em suas interações com o ambiente.
Aplicações Importantes
Os DRLs são empregados em circunstâncias do mundo real porque podem lidar com questões difíceis.
Os DRLs foram incluídos em várias plataformas proeminentes de software e tecnologia, incluindo OpenAI's Gym, Agentes de ML do Unitye o Laboratório DeepMind do Google. AlphaGo, criado pelo Google DeepMind, por exemplo, emprega DRL para jogar o jogo de tabuleiro Go em nível de campeão mundial.

Outro uso do DRL é na robótica, onde é usado para controlar os movimentos dos braços robóticos para executar tarefas como agarrar coisas ou empilhar blocos. DRLs têm muitos usos e são uma ferramenta útil para agentes de treinamento para aprender e tomar decisões em ambientes complicados.
6. Codificadores automáticos
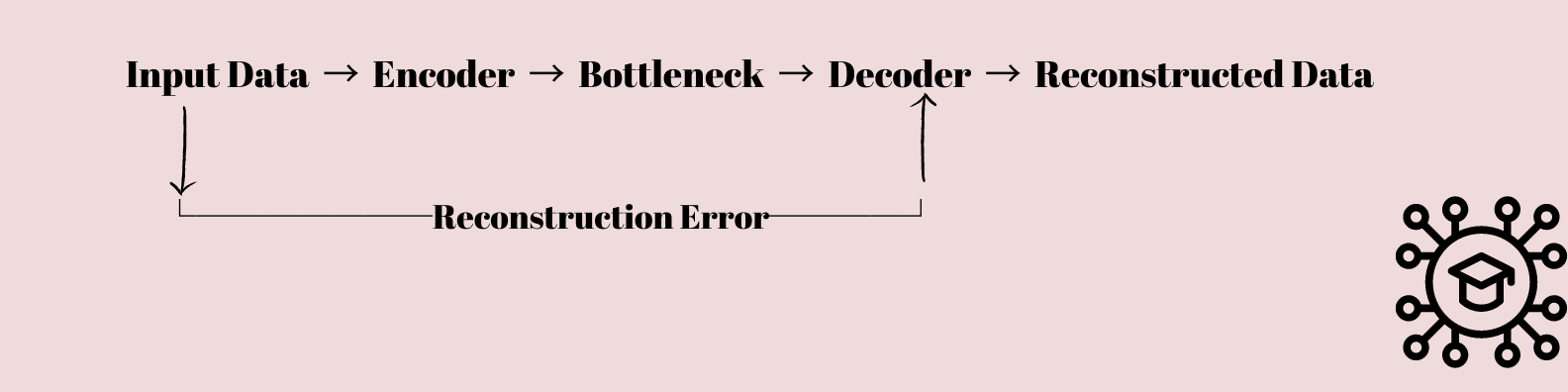
Autoencoders são um tipo interessante de rede neural que despertou o interesse de estudiosos e cientistas de dados. Eles são projetados fundamentalmente para aprender como compactar e restaurar dados.
Os dados de entrada são alimentados por uma sucessão de camadas que diminuem gradualmente a dimensionalidade dos dados até que sejam compactados em uma camada de gargalo com menos nós do que as camadas de entrada e saída.
Essa representação compactada é então usada para recriar os dados de entrada originais usando uma sequência de camadas que aumentam gradualmente a dimensionalidade dos dados de volta à sua forma original.
Por que isso é importante?
Autoencoders são um componente crucial de deep learning porque eles possibilitam a extração de recursos e a redução de dados.
Eles são capazes de identificar os elementos-chave dos dados recebidos e traduzi-los em um formato compactado que pode ser aplicado a outras tarefas, como classificação, agrupamento ou criação de novos dados.
Onde usamos Autoencoders?
Detecção de anomalias, processamento de linguagem natural e visão computacional são apenas algumas das disciplinas em que os autoencoders são usados. Autoencoders, por exemplo, podem ser usados para compressão de imagem, redução de ruído de imagem e síntese de imagem em visão computacional.
Podemos usar Autoencoders em tarefas como criação de texto, categorização de texto e resumo de texto no processamento de linguagem natural. Ele pode identificar atividades anômalas em dados que se desviam da norma na identificação de anomalias.
7. Redes Cápsulas
Capsule Networks é uma nova arquitetura de aprendizado profundo que foi desenvolvida para substituir as Redes Neurais Convolucionais (CNNs).
As Capsule Networks são baseadas na noção de agrupamento de unidades cerebrais chamadas cápsulas que são responsáveis por reconhecer a existência de um determinado item em uma imagem e codificar seus atributos, como orientação e posição, em seus vetores de saída. As Capsule Networks podem, portanto, gerenciar interações espaciais e flutuações de perspectiva melhor do que as CNNs.
Por que escolhemos redes de cápsulas em vez de CNN?
As Capsule Networks são úteis porque superam as dificuldades da CNN em capturar relações hierárquicas entre itens em uma imagem. As CNNs podem reconhecer coisas de vários tamanhos, mas lutam para entender como esses itens se conectam uns aos outros.
A Capsule Networks, por outro lado, pode aprender a reconhecer as coisas e suas partes, bem como como elas são posicionadas espacialmente em uma imagem, tornando-as um concorrente viável para aplicativos de visão computacional.
Áreas de Aplicações
A Capsule Networks já demonstrou resultados promissores em uma variedade de aplicações, incluindo classificação de imagens, identificação de objetos e segmentação de imagens.
Eles têm sido usados para distinguir coisas em fotos médicas, reconhecer pessoas em filmes e até mesmo criar modelos 3D a partir de imagens 2D.
Para aumentar seu desempenho, as Capsule Networks foram combinadas com outras arquiteturas de aprendizado profundo, como Generative Adversarial Networks (GANs) e Variational Autoencoders (VAEs). Prevê-se que as Capsule Networks desempenhem um papel cada vez mais vital no aprimoramento das tecnologias de visão computacional à medida que a ciência do aprendizado profundo evolui.
Por exemplo; nibabel é uma ferramenta Python conhecida para ler e escrever tipos de arquivos de neuroimagem. Para segmentação de imagem, emprega Capsule Networks.
8. Modelos baseados em atenção
Modelos de aprendizado profundo conhecidos como modelos baseados em atenção, também conhecidos como mecanismos de atenção, se esforçam para aumentar a precisão de modelos de aprendizado de máquina. Esses modelos funcionam concentrando-se em determinados recursos dos dados recebidos, resultando em um processamento mais eficiente e eficaz.
Em tarefas de processamento de linguagem natural, como tradução automática e análise de sentimentos, os métodos de atenção têm se mostrado bastante bem-sucedidos.
Qual é o seu significado?
Os modelos baseados em atenção são úteis porque permitem um processamento mais eficaz e eficiente de dados complicados.
Redes neurais tradicionais avaliar todos os dados de entrada como igualmente importantes, resultando em processamento mais lento e menor precisão. Os processos de atenção concentram-se em aspectos cruciais dos dados de entrada, permitindo previsões mais rápidas e precisas.

Áreas de uso
No campo da inteligência artificial, os mecanismos de atenção têm uma ampla gama de aplicações, incluindo processamento de linguagem natural, reconhecimento de imagem e áudio e até mesmo veículos sem motorista.
Os métodos de atenção, por exemplo, podem ser usados para melhorar a tradução automática no processamento de linguagem natural, permitindo que o sistema se concentre em certas palavras ou frases que são essenciais para o contexto.
Métodos de atenção em carros autônomos podem ser empregados para auxiliar o sistema a focar em certos itens ou desafios em seu entorno.
9. Redes Transformadoras
Redes transformadoras são modelos de aprendizado profundo que examinam e produzem sequências de dados. Eles funcionam processando a sequência de entrada, um elemento por vez, e produzindo uma sequência de saída com comprimentos iguais ou diferentes.
As redes transformadoras, ao contrário dos modelos padrão de sequência a sequência, não processam sequências usando redes neurais recorrentes (RNNs). Em vez disso, eles empregam processos de auto-atenção para aprender as ligações entre as peças da sequência.
Qual é a importância das redes de transformadores?
Redes de transformadores têm crescido em popularidade nos últimos anos como resultado de seu melhor desempenho em tarefas de processamento de linguagem natural.
Eles são especialmente adequados para tarefas de criação de texto, como tradução de idiomas, resumo de texto e produção de conversas.
As redes de transformadores são significativamente mais eficientes computacionalmente do que os modelos baseados em RNN, tornando-as uma escolha preferencial para aplicações de grande escala.

Onde você pode encontrar redes de transformadores?
As redes de transformadores são amplamente empregadas em uma ampla gama de aplicações, principalmente no processamento de linguagem natural.
A série GPT (Transformador pré-treinado generativo) é um modelo proeminente baseado em transformador que tem sido utilizado para tarefas como tradução de idiomas, resumo de texto e geração de chatbot.
BERT (representações de codificador bidirecional de transformadores) é outro modelo comum baseado em transformador que tem sido utilizado para aplicativos de compreensão de linguagem natural, como resposta a perguntas e análise de sentimento.
Ambos GPT e BERT foram criados com PyTorch, uma estrutura de aprendizagem profunda de código aberto que tem sido popular para desenvolver modelos baseados em transformadores.
10. Máquinas Boltzmann Restritas (RBMs)
Máquinas de Boltzmann restritas (RBMs) são uma espécie de rede neural não supervisionada que aprende de maneira generativa. Devido à sua capacidade de aprender e extrair características essenciais de dados de alta dimensão, eles têm sido amplamente empregados nas áreas de aprendizado de máquina e aprendizado profundo.
Os RBMs são compostos de duas camadas, visíveis e ocultas, com cada camada consistindo de um grupo de neurônios conectados por arestas ponderadas. RBMs são projetados para aprender uma distribuição de probabilidade que descreve os dados de entrada.
O que são máquinas de Boltzmann restritas?
RBMs empregam uma estratégia de aprendizagem generativa. Nos RBMs, a camada visível reflete os dados de entrada, enquanto a camada oculta codifica as características dos dados de entrada. Os pesos das camadas visíveis e ocultas mostram a força de sua ligação.
Os RBMs ajustam os pesos e vieses entre as camadas durante o treinamento usando uma técnica conhecida como divergência contrastiva. A divergência contrastiva é uma estratégia de aprendizado não supervisionado que maximiza a probabilidade de previsão do modelo.
Qual é o significado das Máquinas Boltzmann Restritas?
RBMs são importantes em aprendizado de máquina e aprendizagem profunda porque podem aprender e extrair características relevantes de grandes quantidades de dados.
Eles são muito eficazes para reconhecimento de imagem e fala e têm sido empregados em uma variedade de aplicações, como sistemas de recomendação, detecção de anomalias e redução de dimensionalidade. RBMs podem encontrar padrões em vastos conjuntos de dados, resultando em previsões e insights superiores.

Onde as Máquinas Boltzmann Restritas podem ser usadas?
Os aplicativos para RBMs incluem redução de dimensionalidade, detecção de anomalias e sistemas de recomendação. RBMs são particularmente úteis para análise de sentimentos e modelagem de tópicos no contexto do processamento de linguagem natural.
Redes de crenças profundas, um tipo de rede neural usada para reconhecimento de voz e imagem, também empregam RBMs. A caixa de ferramentas da Deep Belief Network, TensorFlow e Theano são alguns exemplos particulares de software ou tecnologia que usa RBMs.
Embrulhar
Os modelos de Deep Learning estão se tornando cada vez mais cruciais em uma variedade de setores, incluindo reconhecimento de fala, processamento de linguagem natural e visão computacional.
As Redes Neurais Convolucionais (CNNs) e as Redes Neurais Recorrentes (RNNs) têm se mostrado as mais promissoras e são amplamente utilizadas em muitas aplicações, no entanto, todos os modelos de Deep Learning têm suas vantagens e desvantagens.
No entanto, os pesquisadores ainda estão analisando as Máquinas de Boltzmann Restritas (RBMs) e outras variedades de modelos de Deep Learning porque eles também têm vantagens especiais.
Espera-se que modelos novos e criativos sejam criados à medida que a área de aprendizado profundo continua avançando para lidar com problemas mais difíceis





Deixe um comentário