A IA está em toda parte, mas às vezes pode ser difícil entender a terminologia e o jargão. Nesta postagem do blog, explicamos mais de 50 termos e definições de IA para que você possa entender melhor essa tecnologia em rápido crescimento.
Seja você um iniciante ou um especialista, apostamos que existem alguns termos aqui que você não conhece!
1. Inteligência artificial
Inteligência artificial (AI) refere-se ao desenvolvimento de sistemas de computador que têm a capacidade de aprender e funcionar de forma independente, muitas vezes emulando a inteligência humana.
Esses sistemas analisam dados, reconhecem padrões, tomam decisões e adaptam seu comportamento com base na experiência. Ao alavancar algoritmos e modelos, a IA visa criar máquinas inteligentes capazes de perceber e entender seus arredores.
O objetivo final é permitir que as máquinas executem tarefas com eficiência, aprendam com os dados e exibam habilidades cognitivas semelhantes aos humanos.
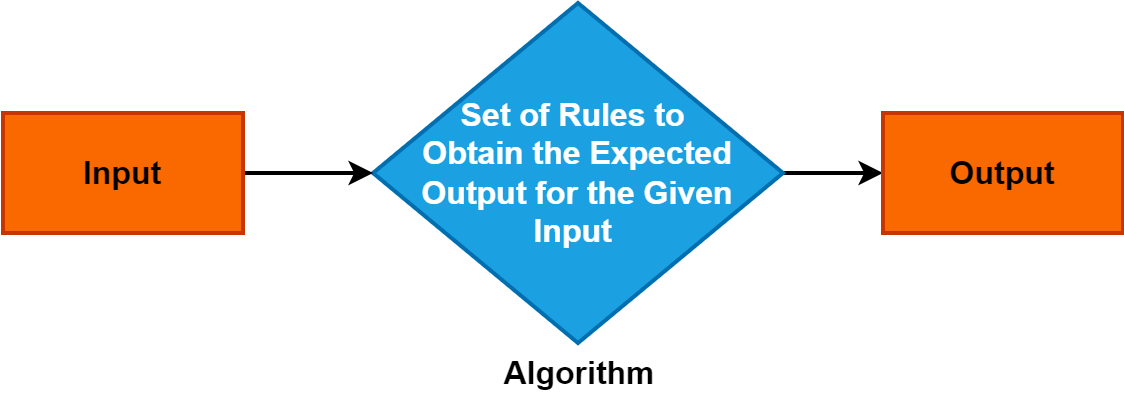
2. Algoritmo
Um algoritmo é um conjunto preciso e sistemático de instruções ou regras que orientam o processo de resolução de um problema ou realização de uma tarefa específica.
Ele serve como um conceito fundamental em vários domínios e desempenha um papel fundamental na ciência da computação, matemática e disciplinas de resolução de problemas. Compreender os algoritmos é crucial, pois eles permitem abordagens eficientes e estruturadas de solução de problemas, impulsionando avanços na tecnologia e nos processos de tomada de decisão.
3.Big Data
Big data refere-se a conjuntos de dados extremamente grandes e complexos que excedem as capacidades dos métodos de análise tradicionais. Esses conjuntos de dados são tipicamente caracterizados por seu volume, velocidade e variedade.
Volume refere-se à grande quantidade de dados gerados a partir de várias fontes, como meios de comunicação social, sensores e transações.
Velocidade refere-se à alta velocidade na qual os dados são gerados e precisam ser processados em tempo real ou quase em tempo real. Variedade significa os diversos tipos e formatos de dados, incluindo dados estruturados, não estruturados e semiestruturados.
4. Mineração de dados
A mineração de dados é um processo abrangente destinado a extrair informações valiosas de vastos conjuntos de dados.
Abrange quatro etapas principais: coleta de dados, envolvendo a coleta de dados relevantes; preparação de dados, garantindo a qualidade e compatibilidade dos dados; mineração dos dados, empregando algoritmos para descobrir padrões e relacionamentos; e análise e interpretação dos dados, onde o conhecimento extraído é examinado e compreendido.
5. Rede Neural
Um sistema de computador é projetado para funcionar como o cérebro humano, composta por nós ou neurônios interconectados. Vamos entender isso um pouco mais, já que a maioria da IA é baseada em redes neurais.
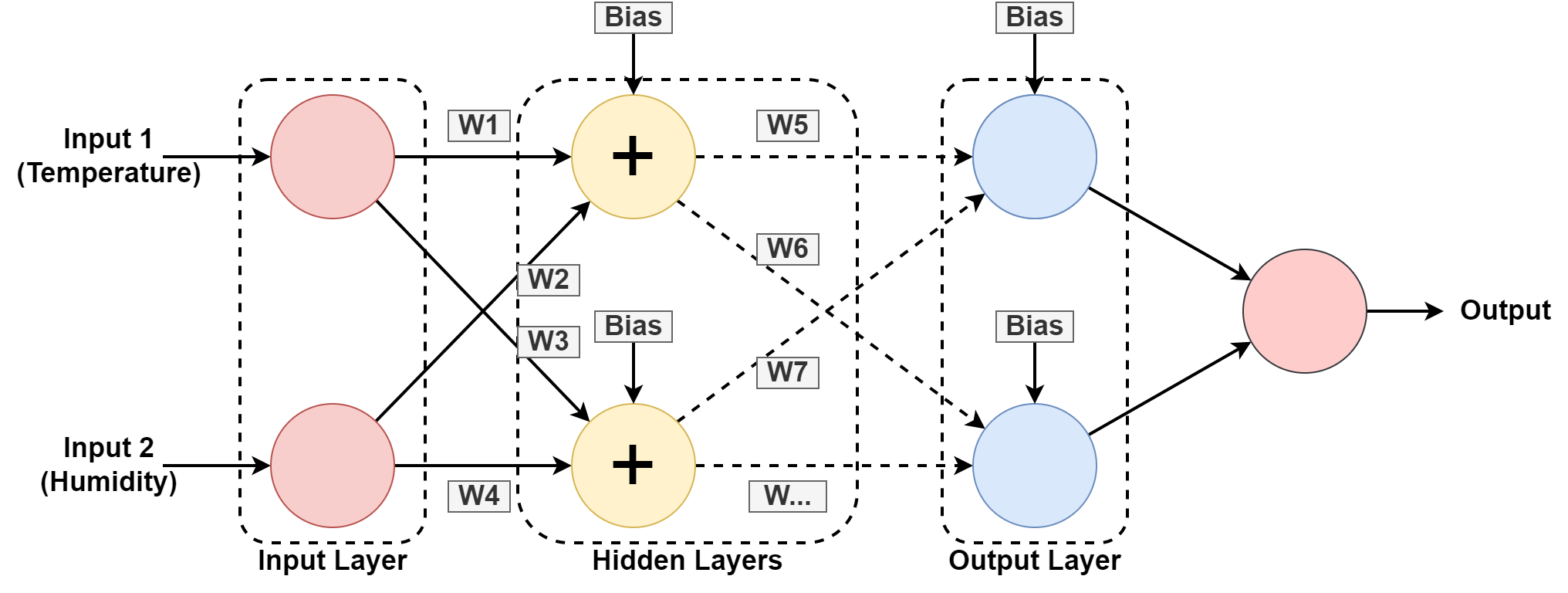
Nos gráficos acima, estamos prevendo a umidade e a temperatura de uma localização geográfica aprendendo com o padrão passado. As entradas são o conjunto de dados para o registro passado.
A rede neural aprende o padrão brincando com pesos e aplicando valores de viés nas camadas ocultas. W1, W2….W7 são os respectivos pesos. Ele se treina no conjunto de dados fornecido e fornece a saída como uma previsão.
Você pode ficar sobrecarregado com essas informações complexas. Se for esse o caso, você pode começar com nosso guia simples SUA PARTICIPAÇÃO FAZ A DIFERENÇA.
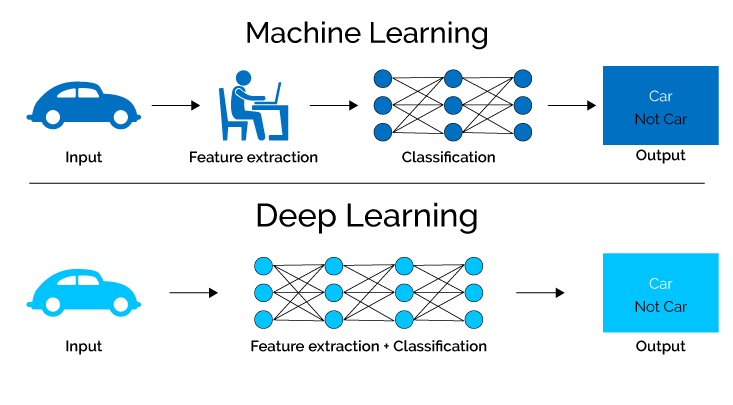
6. Aprendizado de Máquina
O aprendizado de máquina se concentra no desenvolvimento de algoritmos e modelos capazes de aprender automaticamente com os dados e melhorar seu desempenho ao longo do tempo.
Envolve o uso de técnicas estatísticas para permitir que os computadores identifiquem padrões, façam previsões e tomem decisões baseadas em dados sem serem explicitamente programados.
Algoritmos de aprendizado de máquina analise e aprenda com grandes conjuntos de dados, permitindo que os sistemas se adaptem e melhorem seu comportamento com base nas informações que processam.
7. Aprendizado profundo
Aprendizado profundo, um subcampo de aprendizado de máquina e redes neurais, utiliza algoritmos sofisticados para adquirir conhecimento de dados, simulando os intrincados processos do cérebro humano.
Ao empregar redes neurais com várias camadas ocultas, os modelos de aprendizagem profunda podem extrair autonomamente recursos e padrões intrincados, permitindo-lhes lidar com tarefas complexas com precisão e eficiência excepcionais.
8. Reconhecimento de Padrões
O reconhecimento de padrões, uma técnica de análise de dados, aproveita o poder dos algoritmos de aprendizado de máquina para detectar e discernir padrões e regularidades de forma autônoma nos conjuntos de dados.
Ao alavancar modelos computacionais e métodos estatísticos, os algoritmos de reconhecimento de padrões podem identificar estruturas, correlações e tendências significativas em dados complexos e diversos.
Esse processo permite a extração de insights valiosos, classificação de dados em categorias distintas e previsão de resultados futuros com base em padrões reconhecidos. O reconhecimento de padrões é uma ferramenta vital em vários domínios, capacitando a tomada de decisões, a detecção de anomalias e a modelagem preditiva.
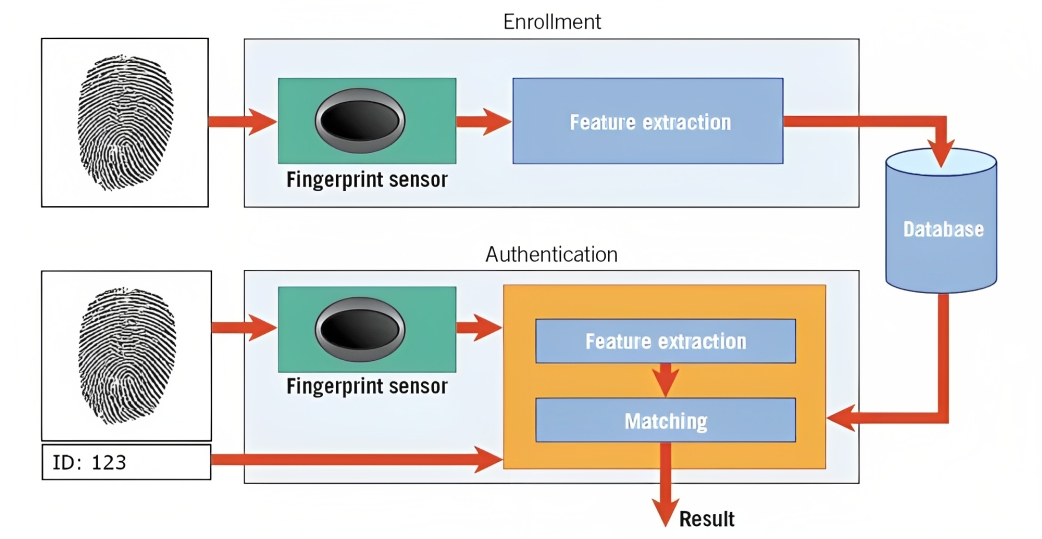
A biometria é um exemplo disso. Por exemplo, no reconhecimento de impressão digital, o algoritmo analisa os sulcos, curvas e características únicas da impressão digital de uma pessoa para criar uma representação digital chamada modelo.
Quando você tenta desbloquear seu smartphone ou acessar uma instalação segura, o sistema de reconhecimento de padrões compara os dados biométricos capturados (por exemplo, impressão digital) com os modelos armazenados em seu banco de dados.
Ao combinar os padrões e avaliar o nível de similaridade, o sistema pode determinar se os dados biométricos fornecidos correspondem ao modelo armazenado e conceder acesso de acordo.
9. Aprendizagem Supervisionada
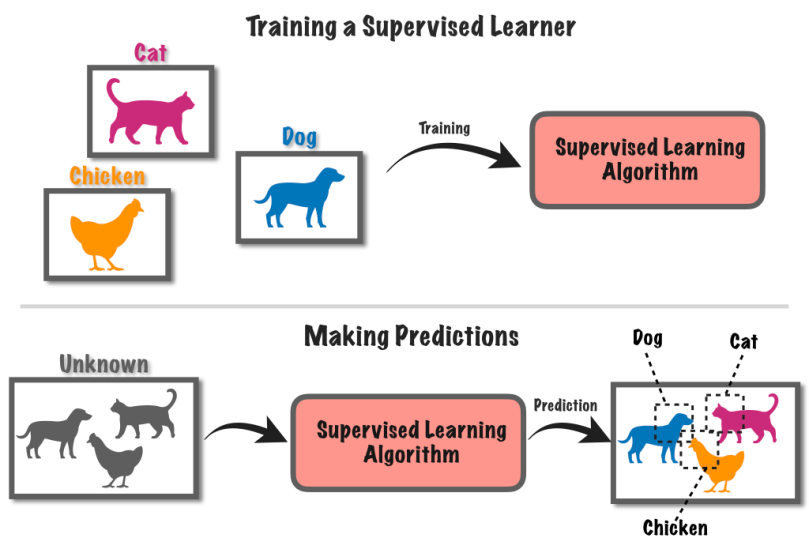
O aprendizado supervisionado é uma abordagem de aprendizado de máquina que envolve o treinamento de um sistema de computador usando dados rotulados. Nesse método, o computador recebe um conjunto de dados de entrada junto com rótulos ou resultados conhecidos correspondentes.
Digamos que você tenha várias fotos, algumas com cachorros e outras com gatos.
Você diz ao computador quais fotos têm cachorros e quais têm gatos. O computador então aprende a reconhecer as diferenças entre cães e gatos encontrando padrões nas fotos.
Depois que ele aprender, você pode fornecer novas imagens ao computador, e ele tentará descobrir se eles têm cães ou gatos com base no que aprendeu com os exemplos rotulados. É como treinar um computador para fazer previsões usando informações conhecidas.
10. Aprendizagem não supervisionada
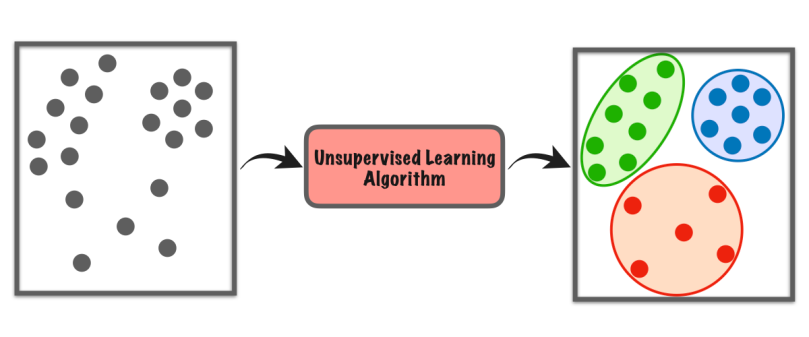
O aprendizado não supervisionado é um tipo de aprendizado de máquina em que o computador explora um conjunto de dados por conta própria para encontrar padrões ou semelhanças sem nenhuma instrução específica.
Não depende de exemplos rotulados como no aprendizado supervisionado. Em vez disso, ele procura estruturas ou grupos ocultos nos dados. É como se o computador descobrisse as coisas sozinho, sem que um professor lhe dissesse o que procurar.
Esse tipo de aprendizado nos ajuda a encontrar novos insights, organizar dados ou identificar coisas incomuns sem a necessidade de conhecimento prévio ou orientação explícita.
11. Processamento de linguagem natural (PNL)
O processamento de linguagem natural concentra-se em como os computadores entendem e interagem com a linguagem humana. Ele ajuda os computadores a analisar, interpretar e responder à linguagem humana de uma forma que pareça mais natural para nós.
O NLP é o que nos permite comunicar com assistentes de voz e chatbots, e até mesmo ter nossos e-mails classificados automaticamente em pastas.
Envolve ensinar computadores a entender o significado por trás de palavras, frases e até textos inteiros, para que possam nos ajudar em várias tarefas e tornar nossas interações com a tecnologia mais integradas.
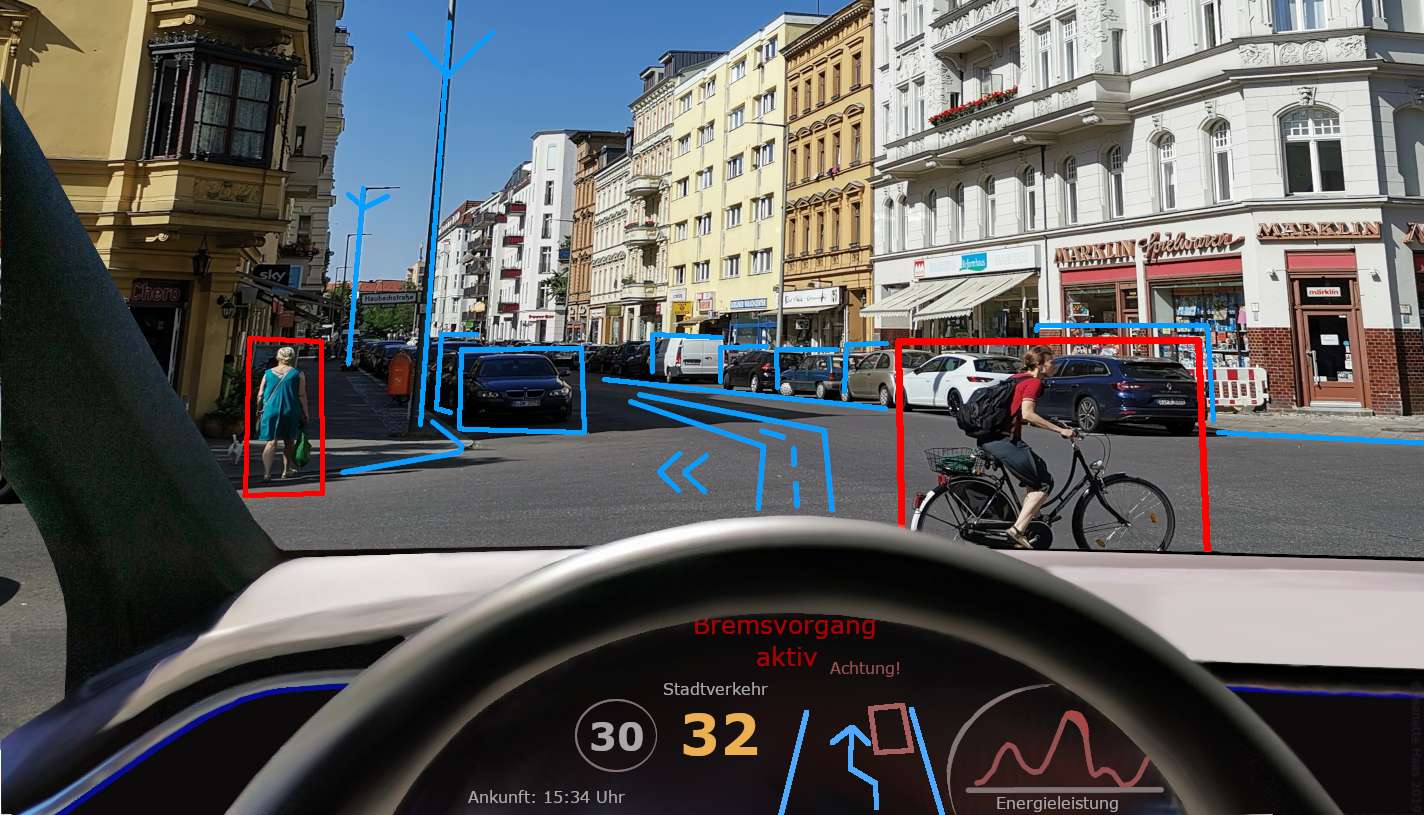
12. Visão computacional
Visão computacional é uma tecnologia fascinante que permite que os computadores vejam e entendam imagens e vídeos, assim como nós humanos fazemos com nossos olhos. Trata-se de ensinar computadores a analisar informações visuais e dar sentido ao que veem.
Em termos mais simples, a visão computacional ajuda os computadores a reconhecer e interpretar o mundo visual. Envolve tarefas como ensiná-los a identificar objetos específicos em imagens, classificar imagens em diferentes categorias ou até mesmo dividir imagens em partes significativas.
Imagine um carro autônomo usando visão computacional para “ver” a estrada e tudo ao seu redor.
Ele pode detectar e rastrear pedestres, sinais de trânsito e outros veículos, ajudando-os a navegar com segurança. Ou pense em como a tecnologia de reconhecimento facial usa visão computacional para desbloquear nossos smartphones ou verificar nossas identidades reconhecendo nossos recursos faciais exclusivos.
Também é usado em sistemas de vigilância para monitorar lugares lotados e detectar atividades suspeitas.
A visão computacional é uma tecnologia poderosa que abre um mundo de possibilidades. Ao permitir que os computadores vejam e compreendam informações visuais, podemos desenvolver aplicativos e sistemas que podem perceber e interpretar o mundo ao nosso redor, tornando nossa vida mais fácil, segura e eficiente.
13. chatbot
Um chatbot é como um programa de computador que pode falar com as pessoas de uma forma que parece uma conversa humana real.
É frequentemente usado no atendimento ao cliente online para ajudar os clientes e fazê-los sentir que estão conversando com uma pessoa, mesmo que seja um programa executado em um computador.
O chatbot pode entender e responder a mensagens ou perguntas dos clientes, fornecendo informações úteis e assistência como faria um representante humano de atendimento ao cliente.
14. Reconhecimento de voz
O reconhecimento de voz refere-se à capacidade de um sistema de computador para compreender e interpretar a fala humana. Envolve a tecnologia que permite a um computador ou dispositivo “ouvir” palavras faladas e convertê-las em texto ou comandos que possam ser compreendidos.
Com o reconhecimento de voz, você pode interagir com dispositivos ou aplicativos simplesmente falando com eles em vez de digitar ou usar outros métodos de entrada.
O sistema analisa as palavras faladas, reconhece os padrões e sons e depois os traduz em texto ou ações compreensíveis. Ele permite comunicação mãos-livres e natural com a tecnologia, possibilitando tarefas como comandos de voz, ditado ou interações controladas por voz. Os exemplos mais comuns são os assistentes de IA como Siri e Google Assistant.
15. Análise de sentimento
Análise de sentimentos é uma técnica usada para entender e interpretar as emoções, opiniões e atitudes expressas em texto ou fala. Envolve a análise da linguagem escrita ou falada para determinar se o sentimento expresso é positivo, negativo ou neutro.
Usando algoritmos de aprendizado de máquina, os algoritmos de análise de sentimentos podem escanear e analisar grandes quantidades de dados de texto, como avaliações de clientes, publicações em mídias sociais ou comentários de clientes, para identificar o sentimento subjacente por trás das palavras.
Os algoritmos procuram palavras, frases ou padrões específicos que indiquem emoções ou opiniões.
Essa análise ajuda empresas ou indivíduos a entender como as pessoas se sentem em relação a um produto, serviço ou tópico e pode ser usada para tomar decisões baseadas em dados ou obter informações sobre as preferências do cliente.
Por exemplo, uma empresa pode usar a análise de sentimento para rastrear a satisfação do cliente, identificar áreas de melhoria ou monitorar a opinião pública sobre sua marca.
16. Tradução automática
A tradução automática, no contexto da IA, refere-se ao uso de algoritmos de computador e inteligência artificial para traduzir automaticamente texto ou fala de um idioma para outro.
Envolve ensinar computadores a entender e processar idiomas humanos para fornecer traduções precisas. O exemplo mais comum é Google Tradutor.
Com a tradução automática, você pode inserir texto ou fala em um idioma, e o sistema analisará a entrada e gerará uma tradução correspondente em outro idioma. Isso é particularmente útil ao comunicar ou acessar informações em diferentes idiomas.
Os sistemas de tradução automática dependem de uma combinação de regras linguísticas, modelos estatísticos e algoritmos de aprendizado de máquina. Eles aprendem com grandes quantidades de dados de idiomas para melhorar a precisão da tradução ao longo do tempo. Algumas abordagens de tradução automática também incorporam redes neurais para melhorar a qualidade das traduções.
17. Robótica
A robótica é a combinação de inteligência artificial e engenharia mecânica para criar máquinas inteligentes chamadas robôs. Esses robôs são projetados para executar tarefas de forma autônoma ou com o mínimo de intervenção humana.
Os robôs são entidades físicas que podem sentir seu ambiente, tomar decisões com base nessa entrada sensorial e executar ações ou tarefas específicas.
Eles são equipados com vários sensores, como câmeras, microfones ou sensores de toque, que permitem coletar informações do mundo ao seu redor. Com a ajuda de algoritmos e programação de IA, os robôs podem analisar esses dados, interpretá-los e tomar decisões inteligentes para executar suas tarefas designadas.
A IA desempenha um papel crucial na robótica, permitindo que os robôs aprendam com suas experiências e se adaptem a diferentes situações.
Os algoritmos de aprendizado de máquina podem ser usados para treinar robôs para reconhecer objetos, navegar em ambientes ou até mesmo interagir com humanos. Isso permite que os robôs se tornem mais versáteis, flexíveis e capazes de lidar com tarefas complexas.
18. Drones
Drones são um tipo de robô que pode voar ou pairar no ar sem um piloto humano a bordo. Eles também são conhecidos como veículos aéreos não tripulados (UAVs). Os drones são equipados com vários sensores, como câmeras, GPS e giroscópios, que permitem coletar dados e navegar ao seu redor.
Eles são controlados remotamente por um operador humano ou podem operar de forma autônoma usando instruções pré-programadas.
Os drones atendem a uma ampla gama de propósitos, incluindo fotografia aérea e videografia, levantamento e mapeamento, serviços de entrega, missões de busca e salvamento, monitoramento agrícola e até mesmo uso recreativo. Eles podem acessar áreas remotas ou perigosas que são difíceis ou perigosas para os humanos.
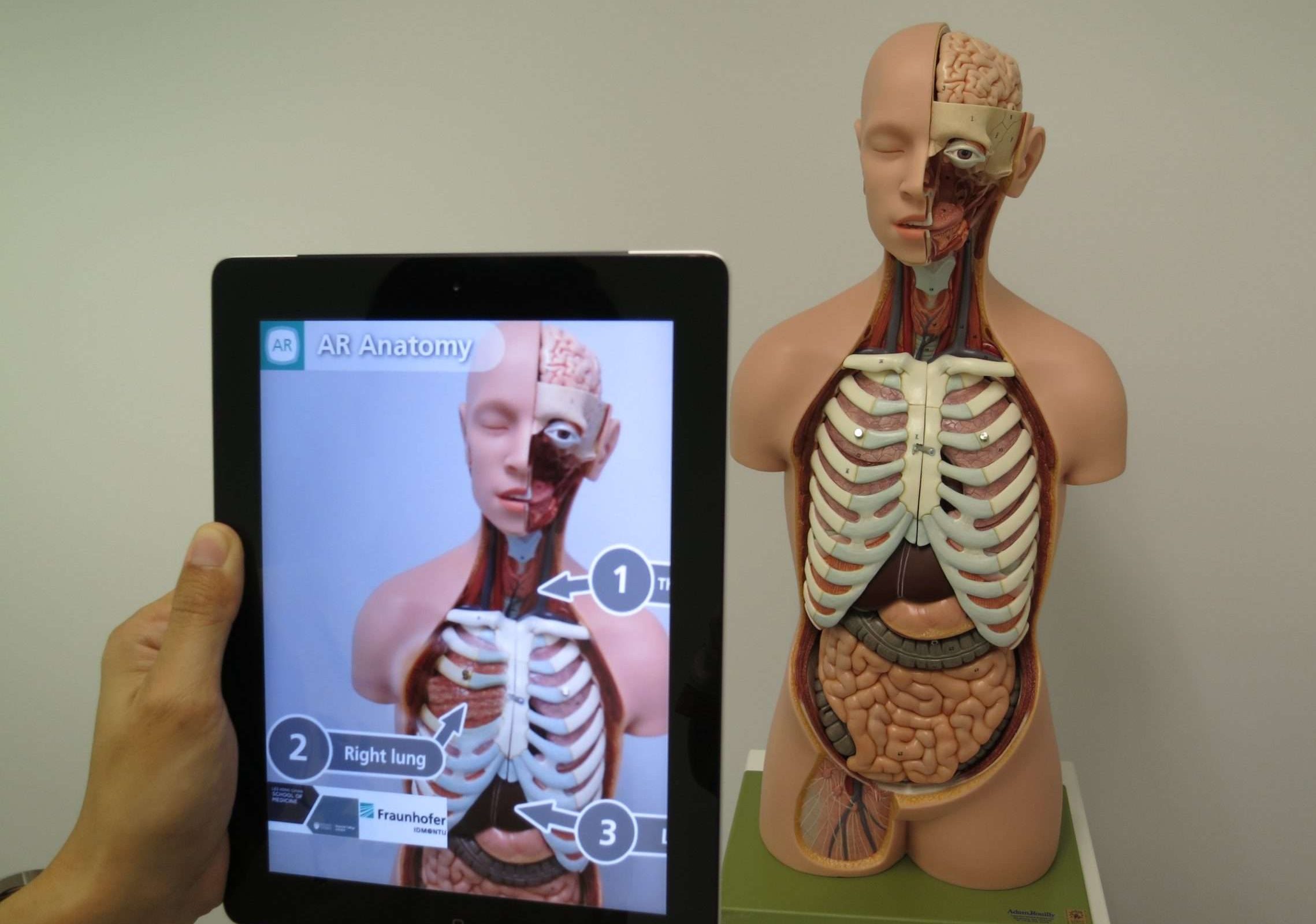
19. Realidade Aumentada (AR)
A realidade aumentada (AR) é uma tecnologia que combina o mundo real com objetos ou informações virtuais para aprimorar nossa percepção e interação com o ambiente. Ele sobrepõe imagens, sons ou outras entradas sensoriais geradas por computador ao mundo real, criando uma experiência imersiva e interativa.
Simplificando, imagine usar óculos especiais ou usar seu smartphone para ver o mundo ao seu redor, mas com elementos virtuais adicionais adicionados.
Por exemplo, você pode apontar seu smartphone para uma rua da cidade e ver placas de sinalização virtuais mostrando direções, classificações e avaliações de restaurantes próximos ou até mesmo personagens virtuais interagindo com o ambiente real.
Esses elementos virtuais combinam perfeitamente com o mundo real, aprimorando sua compreensão e experiência do ambiente. A realidade aumentada pode ser usada em vários campos, como jogos, educação, arquitetura e até mesmo para tarefas cotidianas, como navegação ou experimentar novos móveis em sua casa antes de comprá-los.
20. Realidade Virtual (VR)
A realidade virtual (VR) é uma tecnologia que usa simulações geradas por computador para criar um ambiente artificial que uma pessoa pode explorar e interagir. Ele imerge o usuário em um mundo virtual, bloqueando o mundo real e substituindo-o por um reino digital.
Simplificando, imagine colocar um fone de ouvido especial que cobre seus olhos e ouvidos e o transporta para um lugar completamente diferente. Neste mundo virtual, tudo o que você vê e ouve parece incrivelmente real, mesmo que tudo seja gerado por um computador.
Você pode se mover, olhar em qualquer direção e interagir com objetos ou personagens como se estivessem fisicamente presentes.
Por exemplo, em um jogo de realidade virtual, você pode se encontrar dentro de um castelo medieval, onde pode caminhar por seus corredores, pegar armas e se envolver em lutas de espadas com oponentes virtuais. O ambiente de realidade virtual responde aos seus movimentos e ações, fazendo com que você se sinta totalmente imerso e envolvido na experiência.
A realidade virtual não é usada apenas para jogos, mas também para várias outras aplicações, como simulações de treinamento para pilotos, cirurgiões ou militares, caminhadas arquitetônicas, turismo virtual e até terapia para certas condições psicológicas. Ele cria uma sensação de presença e transporta os usuários para novos e emocionantes mundos virtuais, tornando a experiência o mais próxima possível da realidade.
21. Ciência de dados
Ciência dos dados é um campo que envolve o uso de métodos, ferramentas e algoritmos científicos para extrair conhecimento e insights valiosos dos dados. Ele combina elementos de matemática, estatística, programação e conhecimento de domínio para analisar conjuntos de dados grandes e complexos.
Em termos mais simples, a ciência de dados trata de encontrar informações e padrões significativos ocultos em um monte de dados. Envolve coletar, limpar e organizar dados e, em seguida, usar várias técnicas para explorá-los e analisá-los. Cientistas de dados use modelos estatísticos e algoritmos para descobrir tendências, fazer previsões e resolver problemas.
Por exemplo, no campo da saúde, a ciência de dados pode ser usada para analisar registros de pacientes e dados médicos para identificar fatores de risco para doenças, prever resultados de pacientes ou otimizar planos de tratamento. Nos negócios, a ciência de dados pode ser aplicada aos dados do cliente para entender suas preferências, recomendar produtos ou melhorar as estratégias de marketing.
22. Disputa de Dados
Data wrangling, também conhecido como data munging, é o processo de coleta, limpeza e transformação de dados brutos em um formato mais útil e adequado para análise. Envolve manipular e preparar dados para garantir sua qualidade, consistência e compatibilidade com ferramentas ou modelos de análise.
Em termos mais simples, a disputa de dados é como preparar ingredientes para cozinhar. Envolve coletar dados de diferentes fontes, classificá-los e limpá-los para remover quaisquer erros, inconsistências ou informações irrelevantes.
Além disso, os dados podem precisar ser transformados, reestruturados ou agregados para facilitar o trabalho e a extração de insights.
Por exemplo, a disputa de dados pode envolver a remoção de entradas duplicadas, correção de erros ortográficos ou problemas de formatação, manipulação de valores ausentes e conversão de tipos de dados. Também pode envolver mesclar ou unir diferentes conjuntos de dados, dividir dados em subconjuntos ou criar novas variáveis com base nos dados existentes.
23. Narração de dados
Narrativa de dados é a arte de apresentar dados de uma forma convincente e envolvente para comunicar eficazmente uma narrativa ou mensagem. Envolve usar visualizações de dados, narrativas e contexto para transmitir insights e descobertas de uma maneira que seja compreensível e memorável para o público.
Em termos mais simples, contar histórias com dados é usar dados para contar uma história. Vai além de apenas apresentar números e gráficos. Envolve a elaboração de uma narrativa em torno dos dados, usando elementos visuais e técnicas de narrativa para dar vida aos dados e torná-los relacionáveis ao público.
Por exemplo, em vez de simplesmente apresentar uma tabela de números de vendas, a narrativa de dados pode envolver a criação de um painel interativo que permite aos usuários explorar visualmente as tendências de vendas.
Pode incluir uma narrativa que destaque as principais descobertas, explique as razões por trás das tendências e sugira recomendações acionáveis com base nos dados.
24. Tomada de decisão baseada em dados
A tomada de decisão baseada em dados é um processo de fazer escolhas ou tomar ações com base na análise e interpretação de dados relevantes. Envolve o uso de dados como base para orientar e apoiar os processos de tomada de decisão, em vez de confiar apenas na intuição ou no julgamento pessoal.
Em termos mais simples, a tomada de decisão baseada em dados significa usar fatos e evidências de dados para informar e orientar as escolhas que fazemos. Envolve coletar e analisar dados para entender padrões, tendências e relacionamentos e usar esse conhecimento para tomar decisões informadas e resolver problemas.
Por exemplo, em um ambiente de negócios, a tomada de decisão baseada em dados pode envolver a análise de dados de vendas, feedback de clientes e tendências de mercado para determinar a estratégia de preços mais eficaz ou identificar áreas para melhoria no desenvolvimento de produtos.
Na área da saúde, pode envolver a análise de dados do paciente para otimizar os planos de tratamento ou prever os resultados da doença.
25. Lago de dados
Um data lake é um repositório de dados centralizado e escalável que armazena grandes quantidades de dados em sua forma bruta e não processada. Ele foi projetado para conter uma ampla variedade de tipos, formatos e estruturas de dados, como dados estruturados, semiestruturados e não estruturados, sem a necessidade de esquemas predefinidos ou transformações de dados.
Por exemplo, uma empresa pode coletar e armazenar dados de várias fontes, como logs de sites, transações de clientes, feeds de mídia social e dispositivos IoT, em um data lake.
Esses dados podem ser usados para várias finalidades, como conduzir análises avançadas, executar algoritmos de aprendizado de máquina ou explorar padrões e tendências no comportamento do cliente.
26. Armazém de Dados
Um data warehouse é um sistema de banco de dados especializado, projetado especificamente para armazenar, organizar e analisar grandes quantidades de dados de várias fontes. Ele é estruturado de forma a oferecer suporte à recuperação de dados eficiente e consultas analíticas complexas.
Ele serve como um repositório central que integra dados de diferentes sistemas operacionais, como bancos de dados transacionais, sistemas de CRM e outras fontes de dados dentro de uma organização.
Os dados são transformados, limpos e carregados no data warehouse em um formato estruturado otimizado para fins analíticos.
27. Inteligência de Negócios (BI)
Business Intelligence refere-se ao processo de coleta, análise e apresentação de dados de forma a ajudar as empresas a tomar decisões informadas e obter insights valiosos. Envolve o uso de várias ferramentas, tecnologias e técnicas para transformar dados brutos em informações significativas e acionáveis.
Por exemplo, um sistema de business intelligence pode analisar dados de vendas para identificar os produtos mais lucrativos, monitorar os níveis de estoque e rastrear as preferências do cliente.
Ele pode fornecer informações em tempo real sobre os principais indicadores de desempenho (KPIs), como receita, aquisição de clientes ou desempenho do produto, permitindo que as empresas tomem decisões baseadas em dados e tomem as medidas apropriadas para melhorar suas operações.
As ferramentas de inteligência de negócios geralmente incluem recursos como visualização de dados, consultas ad hoc e recursos de exploração de dados. Essas ferramentas permitem que os usuários, como business analysts ou gerentes, para interagir com os dados, dividi-los e gerar relatórios ou representações visuais que destacam insights e tendências importantes.
28. Análise preditiva
A análise preditiva é a prática de usar dados e técnicas estatísticas para fazer previsões informadas ou previsões sobre eventos ou resultados futuros. Envolve a análise de dados históricos, identificação de padrões e construção de modelos para extrapolar e estimar tendências, comportamentos ou ocorrências futuras.
Destina-se a descobrir relações entre variáveis e usar essa informação para fazer previsões. Vai além de simplesmente descrever eventos passados; em vez disso, utiliza dados históricos para entender e antecipar o que provavelmente acontecerá no futuro.
Por exemplo, na área de finanças, a análise preditiva pode ser usada para prever estoque preços baseados em dados históricos de mercado, indicadores econômicos e outros fatores relevantes.
No marketing, pode ser empregado para prever o comportamento e as preferências do cliente, permitindo publicidade direcionada e campanhas de marketing personalizadas.
Na área da saúde, a análise preditiva pode ajudar a identificar pacientes com alto risco para certas doenças ou prever a probabilidade de reinternação com base no histórico médico e em outros fatores.
29. Análise Prescritiva
A análise prescritiva é a aplicação de dados e análises para determinar as melhores ações possíveis a serem tomadas em uma situação específica ou cenário de tomada de decisão.
Vai além de descritivo e análise preditiva não apenas fornecendo insights sobre o que pode acontecer no futuro, mas também recomendando o curso de ação ideal para alcançar o resultado desejado.
Ele combina dados históricos, modelos preditivos e técnicas de otimização para simular diferentes cenários e avaliar os possíveis resultados de várias decisões. Ele considera várias restrições, objetivos e fatores para gerar recomendações acionáveis que maximizam os resultados desejados ou minimizam os riscos.
Por exemplo, em cadeia de suprimentos gerenciamento, a análise prescritiva pode analisar dados sobre níveis de estoque, capacidades de produção, custos de transporte e demanda do cliente para determinar o plano de distribuição mais eficiente.
Ele pode recomendar a alocação ideal de recursos, como locais de estocagem de estoque ou rotas de transporte, para minimizar custos e garantir entrega pontual.
30. Marketing orientado a dados
O marketing orientado a dados refere-se à prática de usar dados e análises para conduzir estratégias de marketing, campanhas e processos de tomada de decisão.
Envolve alavancar várias fontes de dados para obter insights sobre o comportamento, preferências e tendências do cliente e usar essas informações para otimizar os esforços de marketing.
Ele se concentra na coleta e análise de dados de vários pontos de contato, como interações no site, engajamento de mídia social, dados demográficos do cliente, histórico de compras e muito mais. Esses dados são usados para criar uma compreensão abrangente do público-alvo, suas preferências e necessidades.
Ao aproveitar os dados, os profissionais de marketing podem tomar decisões informadas sobre segmentação, direcionamento e personalização de clientes.
Eles podem identificar segmentos específicos de clientes com maior probabilidade de responder positivamente a campanhas de marketing e adaptar suas mensagens e ofertas de acordo.
Além disso, o marketing orientado a dados ajuda a otimizar os canais de marketing, determinando o mix de marketing mais eficaz e medindo o sucesso das iniciativas de marketing.
Por exemplo, uma abordagem de marketing orientada por dados pode envolver a análise de dados do cliente para identificar comportamentos de compra e padrões de preferências. Com base nesses insights, os profissionais de marketing podem criar campanhas direcionadas com conteúdo personalizado e ofertas que ressoam com segmentos específicos de clientes.
Por meio de análise e otimização contínuas, eles podem medir a eficácia de seus esforços de marketing e refinar as estratégias ao longo do tempo.
31. Governança de dados
A governança de dados é a estrutura e o conjunto de práticas que as organizações adotam para garantir o gerenciamento, a proteção e a integridade adequados dos dados durante todo o seu ciclo de vida. Abrange os processos, políticas e procedimentos que governam como os dados são coletados, armazenados, acessados, usados e compartilhados dentro de uma organização.
Destina-se a estabelecer responsabilidade, responsabilidade e controle sobre os ativos de dados. Ele garante que os dados sejam precisos, completos, consistentes e confiáveis, permitindo que as organizações tomem decisões informadas, mantenham a qualidade dos dados e atendam aos requisitos regulamentares.
A governança de dados envolve definir funções e responsabilidades para o gerenciamento de dados, estabelecer padrões e políticas de dados e implementar processos para monitorar e fazer cumprir a conformidade. Ele aborda vários aspectos do gerenciamento de dados, incluindo privacidade de dados, segurança de dados, qualidade de dados, classificação de dados e gerenciamento do ciclo de vida dos dados.
Por exemplo, a governança de dados pode envolver a implementação de procedimentos para garantir que os dados pessoais ou confidenciais sejam tratados em conformidade com os regulamentos de privacidade aplicáveis, como o Regulamento Geral de Proteção de Dados (GDPR).
Também pode incluir o estabelecimento de padrões de qualidade de dados e a implementação de processos de validação de dados para garantir que os dados sejam precisos e confiáveis.
32. Segurança de dados
A segurança de dados trata de manter nossas informações valiosas protegidas contra acesso não autorizado ou roubo. Envolve tomar medidas para proteger a confidencialidade, integridade e disponibilidade dos dados.
Essencialmente, significa garantir que apenas as pessoas certas possam acessar nossos dados, que permaneçam precisos e inalterados e que estejam disponíveis quando necessário.
Para alcançar a segurança dos dados, várias estratégias e tecnologias são usadas. Por exemplo, controles de acesso e métodos de criptografia ajudam a limitar o acesso a indivíduos ou sistemas autorizados, dificultando o acesso de terceiros aos nossos dados.
Sistemas de monitoramento, firewalls e sistemas de detecção de intrusão atuam como guardiões, alertando-nos sobre atividades suspeitas e impedindo o acesso não autorizado.
33 Internet das coisas
A Internet das Coisas (IoT) refere-se a uma rede de objetos físicos ou “coisas” que estão conectadas à Internet e podem se comunicar entre si. É como uma grande teia de objetos, dispositivos e máquinas do cotidiano que são capazes de compartilhar informações e realizar tarefas interagindo por meio da internet.
Em termos simples, a IoT envolve fornecer recursos “inteligentes” a vários objetos ou dispositivos que tradicionalmente não estavam conectados à Internet. Esses objetos podem incluir eletrodomésticos, dispositivos vestíveis, termostatos, carros e até máquinas industriais.
Ao conectar esses objetos à internet, eles podem coletar e compartilhar dados, receber instruções e realizar tarefas de forma autônoma ou em resposta a comandos do usuário.
Por exemplo, um termostato inteligente pode monitorar a temperatura, ajustar configurações e enviar relatórios de uso de energia para um aplicativo de smartphone. Um rastreador de fitness vestível pode coletar dados sobre suas atividades físicas e sincronizá-los com uma plataforma baseada em nuvem para análise.
34. Árvore de Decisão
Uma árvore de decisão é uma representação visual ou diagrama que nos ajuda a tomar decisões ou determinar um curso de ação com base em uma série de escolhas ou condições.
É como um fluxograma que nos orienta em um processo de tomada de decisão, considerando diferentes opções e seus possíveis resultados.
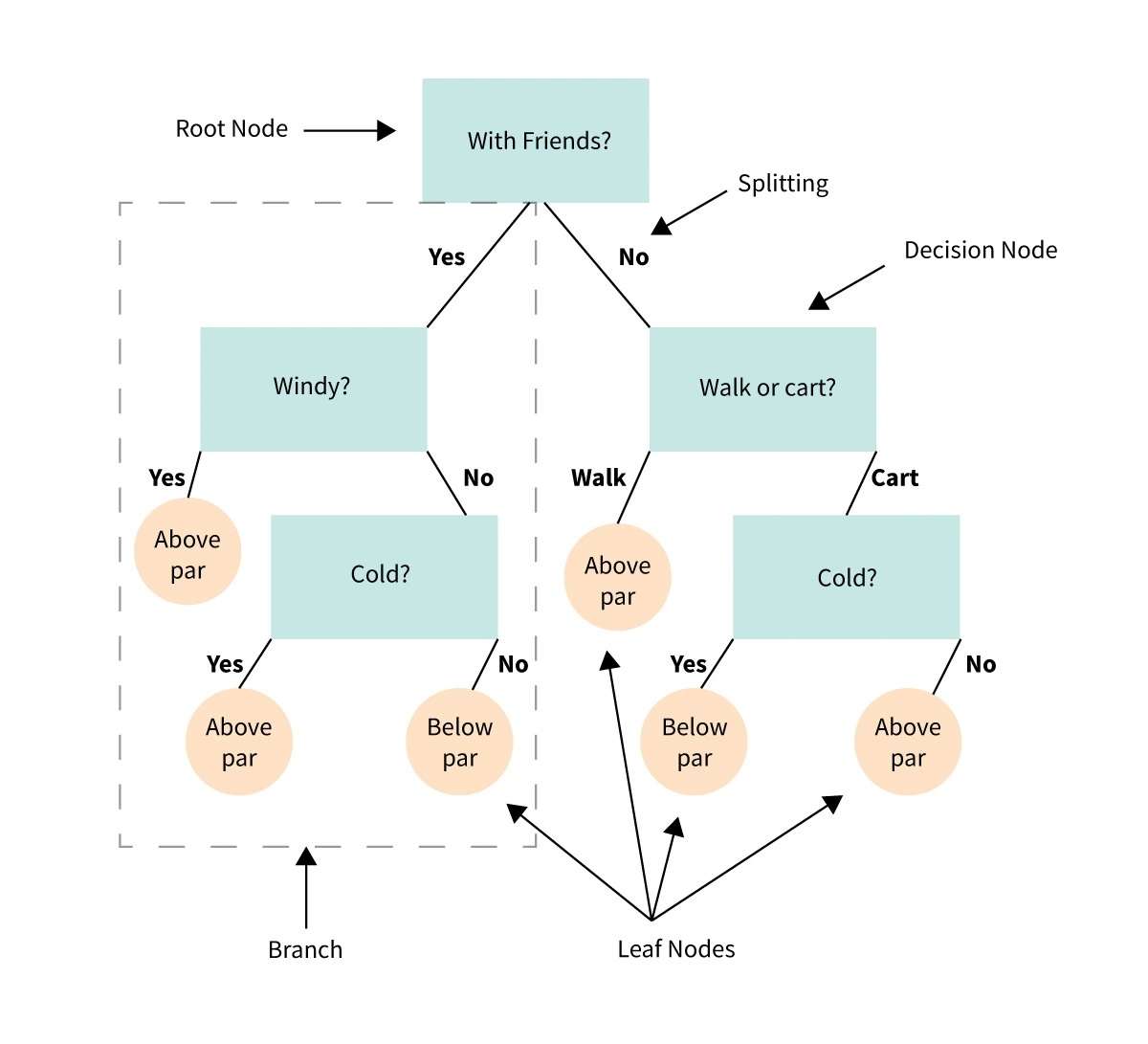
Imagine que você tem um problema ou uma dúvida e precisa fazer uma escolha.
Uma árvore de decisão divide a decisão em etapas menores, começando com uma pergunta inicial e ramificando-se em diferentes respostas ou ações possíveis com base nas condições ou critérios de cada etapa.
35. Computação Cognitiva
A computação cognitiva, em termos simples, refere-se a sistemas ou tecnologias de computador que imitam as habilidades cognitivas humanas, como aprendizado, raciocínio, compreensão e resolução de problemas.
Envolve a criação de sistemas de computador que podem processar e interpretar informações de uma forma que se assemelha ao pensamento humano.
A computação cognitiva visa desenvolver máquinas que possam entender e interagir com humanos de maneira mais natural e inteligente. Esses sistemas são projetados para analisar grandes quantidades de dados, reconhecer padrões, fazer previsões e fornecer insights significativos.
Pense na computação cognitiva como uma tentativa de fazer os computadores pensarem e agirem mais como humanos.
Envolve alavancar tecnologias como inteligência artificial, aprendizado de máquina, processamento de linguagem natural e visão computacional para permitir que os computadores executem tarefas tradicionalmente associadas à inteligência humana.
36. Teoria da Aprendizagem Computacional
A Teoria da Aprendizagem Computacional é um ramo especializado dentro do reino da inteligência artificial que gira em torno do desenvolvimento e exame de algoritmos especificamente projetados para aprender com dados.
Este campo explora várias técnicas e metodologias para a construção de algoritmos que podem melhorar seu desempenho de forma autônoma, analisando e processando grandes quantidades de informação.
Ao aproveitar o poder dos dados, a Teoria da Aprendizagem Computacional visa descobrir padrões, relacionamentos e insights que permitem que as máquinas aprimorem suas capacidades de tomada de decisão e executem tarefas com mais eficiência.
O objetivo final é criar algoritmos que possam adaptar, generalizar e fazer previsões precisas com base nos dados aos quais foram expostos, contribuindo para o avanço da inteligência artificial e suas aplicações práticas.
37. Teste de Turing
O teste de Turing, originalmente proposto pelo brilhante matemático e cientista da computação Alan Turing, é um conceito cativante usado para avaliar se uma máquina pode exibir um comportamento inteligente comparável ou praticamente indistinguível do de um ser humano.
No teste de Turing, um avaliador humano se envolve em uma conversa em linguagem natural com uma máquina e outro participante humano sem saber qual é a máquina.
O papel do avaliador é discernir qual entidade é a máquina apenas com base em suas respostas. Se a máquina for capaz de convencer o avaliador de que é a contraparte humana, diz-se que passou no teste de Turing, demonstrando assim um nível de inteligência que espelha as capacidades humanas.
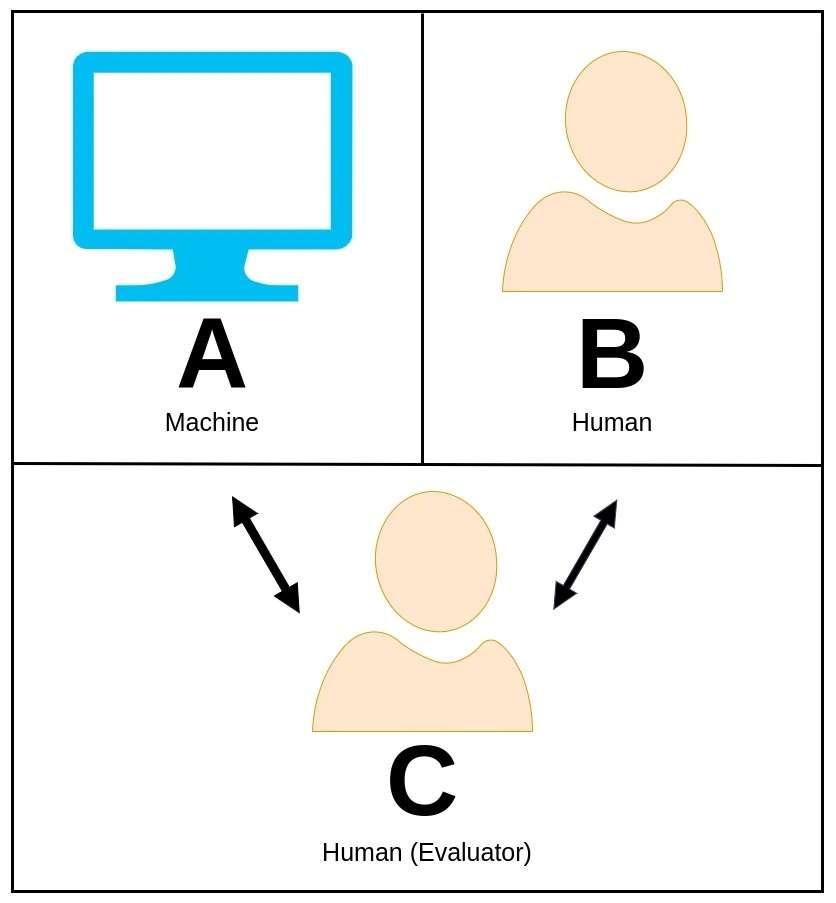
Alan Turing propôs este teste como um meio de explorar o conceito de inteligência de máquina e colocar a questão de saber se as máquinas podem alcançar a cognição em nível humano.
Ao enquadrar o teste em termos de indistinguibilidade humana, Turing destacou o potencial para as máquinas exibirem um comportamento tão convincentemente inteligente que se torna um desafio diferenciá-las dos humanos.
O teste de Turing gerou extensas discussões e pesquisas nos campos da inteligência artificial e da ciência cognitiva. Embora passar no teste de Turing continue sendo um marco significativo, não é a única medida de inteligência.
No entanto, o teste serve como uma referência instigante, estimulando esforços contínuos para desenvolver máquinas capazes de emular inteligência e comportamento semelhantes aos humanos e contribuir para uma exploração mais ampla do que significa ser inteligente.
38. Aprendizagem por reforço
Aprendizagem de reforço é um tipo de aprendizado que acontece por tentativa e erro, onde um “agente” (que pode ser um programa de computador ou um robô) aprende a realizar tarefas recebendo recompensas por bom comportamento e enfrentando as consequências ou punições por mau comportamento.
Imagine um cenário em que o agente está tentando concluir uma tarefa específica, como navegar em um labirinto. A princípio, o agente não sabe o caminho correto a seguir, então ele tenta diferentes ações e explora várias rotas.
Ao escolher uma boa ação que o aproxime do objetivo, ele recebe uma recompensa, como um “tapinha nas costas” virtual. No entanto, se ele tomar uma decisão ruim que o leve a um beco sem saída ou o afaste do objetivo, ele recebe punição ou feedback negativo.
Por meio desse processo de tentativa e erro, o agente aprende a associar determinadas ações a resultados positivos ou negativos. Ele gradualmente descobre a melhor sequência de ações para maximizar suas recompensas e minimizar as punições, tornando-se mais proficiente na tarefa.
O aprendizado por reforço se inspira em como os humanos e os animais aprendem recebendo feedback do ambiente.
Ao aplicar esse conceito às máquinas, os pesquisadores pretendem desenvolver sistemas inteligentes que possam aprender e se adaptar a diferentes situações, descobrindo de forma autônoma os comportamentos mais eficazes por meio de um processo de reforço positivo e consequências negativas.
39. Extração de Entidade
A extração de entidades refere-se a um processo no qual identificamos e extraímos informações importantes, conhecidas como entidades, de um bloco de texto. Essas entidades podem ser várias coisas, como nomes de pessoas, nomes de lugares, nomes de organizações e assim por diante.
Vamos imaginar que você tenha um parágrafo descrevendo uma notícia.
A extração de entidades envolveria a análise do texto e a seleção de bits específicos que representam entidades distintas. Por exemplo, se o texto menciona o nome de uma pessoa como “John Smith”, o local “New York City” ou a organização “OpenAI”, essas seriam as entidades que pretendemos identificar e extrair.
Ao realizar a extração de entidade, estamos essencialmente ensinando um programa de computador a reconhecer e isolar elementos significativos do texto. Esse processo nos permite organizar e categorizar as informações com mais eficiência, tornando mais fácil pesquisar, analisar e obter insights de grandes volumes de dados textuais.
No geral, a extração de entidades nos ajuda a automatizar a tarefa de identificar entidades importantes, como pessoas, lugares e organizações, dentro do texto, simplificando a extração de informações valiosas e aprimorando nossa capacidade de processar e compreender dados textuais.
40. Anotação Linguística
A anotação linguística envolve o enriquecimento do texto com informações linguísticas adicionais para aprimorar nossa compreensão e análise do idioma usado. É como adicionar rótulos ou tags úteis a diferentes partes de um texto.
Quando realizamos a anotação linguística, vamos além das palavras e frases básicas de um texto e começamos a rotular ou marcar elementos específicos. Por exemplo, podemos adicionar tags de parte do discurso, que indicam a categoria gramatical de cada palavra (como substantivo, verbo, adjetivo, etc.). Isso nos ajuda a entender o papel que cada palavra desempenha em uma frase.
Outra forma de anotação linguística é o reconhecimento de entidades nomeadas, onde identificamos e rotulamos entidades nomeadas específicas, como nomes de pessoas, lugares, organizações ou datas. Isso nos permite localizar e extrair rapidamente informações importantes do texto.
Ao anotar o texto dessa maneira, criamos uma representação mais estruturada e organizada do idioma. Isso pode ser imensamente útil em uma variedade de aplicações. Por exemplo, ajuda a melhorar a precisão dos mecanismos de pesquisa ao entender a intenção por trás das consultas do usuário. Ele também auxilia na tradução automática, análise de sentimentos, extração de informações e muitas outras tarefas de processamento de linguagem natural.
A anotação linguística serve como uma ferramenta vital para pesquisadores, linguistas e desenvolvedores, permitindo-lhes estudar padrões de linguagem, construir modelos de linguagem e desenvolver algoritmos sofisticados que podem analisar e entender melhor o texto.
41. Hiperparâmetro
In aprendizado de máquina, um hiperparâmetro é como uma definição ou configuração especial que precisamos decidir antes de treinar um modelo. Não é algo que o modelo possa aprender sozinho com os dados; em vez disso, temos que determiná-lo de antemão.
Pense nisso como um botão ou chave que podemos ajustar para ajustar como o modelo aprende e faz previsões. Esses hiperparâmetros governam vários aspectos do processo de aprendizado, como a complexidade do modelo, a velocidade do treinamento e a compensação entre precisão e generalização.
Por exemplo, vamos considerar uma rede neural. Um hiperparâmetro importante é o número de camadas na rede. Temos que escolher a profundidade que queremos que a rede seja, e essa decisão afeta sua capacidade de capturar padrões complexos nos dados.
Outros hiperparâmetros comuns incluem a taxa de aprendizado, que determina a rapidez com que o modelo ajusta seus parâmetros internos com base nos dados de treinamento, e a força de regularização, que controla o quanto o modelo penaliza padrões complexos para evitar o overfitting.
Definir esses hiperparâmetros corretamente é crucial porque eles podem afetar significativamente o desempenho e o comportamento do modelo. Geralmente envolve um pouco de tentativa e erro, experimentando diferentes valores e observando como eles afetam o desempenho do modelo em um conjunto de dados de validação.
42. Metadados
Metadados referem-se a informações adicionais que fornecem detalhes sobre outros dados. É como um conjunto de tags ou rótulos que nos dão mais contexto ou descrevem as características dos dados principais.
Quando temos dados, seja um documento, uma fotografia, um vídeo ou qualquer outro tipo de informação, os metadados nos ajudam a entender aspectos importantes desses dados.
Por exemplo, em um documento, os metadados podem incluir detalhes como o nome do autor, a data em que foi criado ou o formato do arquivo. No caso de uma fotografia, os metadados podem nos dizer o local onde foi tirada, as configurações da câmera ou até mesmo a data e hora em que foi capturada.
Os metadados nos ajudam a organizar, pesquisar e interpretar os dados com mais eficiência. Ao adicionar essas informações descritivas, podemos encontrar rapidamente arquivos específicos ou entender sua origem, propósito ou contexto sem precisar vasculhar todo o conteúdo.
43. Redução de Dimensionalidade
A redução de dimensionalidade é uma técnica usada para simplificar um conjunto de dados reduzindo o número de recursos ou variáveis que ele contém. É como condensar ou resumir as informações em um conjunto de dados para torná-lo mais gerenciável e fácil de trabalhar.
Imagine que você tenha um conjunto de dados com várias colunas ou atributos representando diferentes características dos pontos de dados. Cada coluna aumenta a complexidade e os requisitos computacionais dos algoritmos de aprendizado de máquina.
Em alguns casos, ter um grande número de dimensões pode dificultar a localização de padrões ou relacionamentos significativos nos dados.
A redução de dimensionalidade ajuda a resolver esse problema, transformando o conjunto de dados em uma representação de dimensão inferior, mantendo o máximo possível de informações relevantes. Visa capturar os aspectos ou variações mais importantes nos dados, descartando dimensões redundantes ou menos informativas.
44. Classificação de texto
A classificação de texto é um processo que envolve a atribuição de rótulos ou categorias específicas a blocos de texto com base em seu conteúdo ou significado. É como classificar ou organizar informações textuais em diferentes grupos ou classes para facilitar uma análise mais aprofundada ou a tomada de decisões.
Vamos considerar um exemplo de classificação de email. Neste cenário, queremos determinar se um e-mail recebido é spam ou não spam (também conhecido como ham). Classificação de texto os algoritmos analisam o conteúdo do e-mail e atribuem a ele um rótulo adequado.
Se o algoritmo determinar que o e-mail exibe características comumente associadas a spam, ele atribui o rótulo “spam”. Por outro lado, se o e-mail parecer legítimo e sem spam, ele atribuirá o rótulo “não spam” ou “presunto”.
A classificação de texto encontra aplicativos em vários domínios além da filtragem de e-mail. É usado na análise de sentimento para determinar o sentimento expresso nas avaliações dos clientes (positivo, negativo ou neutro).
Os artigos de notícias podem ser classificados em diferentes tópicos ou categorias, como esportes, política, entretenimento e muito mais. Os logs de bate-papo do suporte ao cliente podem ser categorizados com base na intenção ou problema que está sendo tratado.
45. IA fraca
AI fraca, também conhecida como AI estreita, refere-se a sistemas de inteligência artificial que são projetados e programados para executar tarefas ou funções específicas. Ao contrário da inteligência humana, que abrange uma ampla gama de habilidades cognitivas, a IA fraca é limitada a um determinado domínio ou tarefa.
Pense em IA fraca como software especializado ou máquinas que se destacam na execução de trabalhos específicos. Por exemplo, um programa de IA para jogar xadrez pode ser criado para analisar situações de jogo, criar estratégias de movimentos e competir contra jogadores humanos.
Outro exemplo é um sistema de reconhecimento de imagem que pode identificar objetos em fotografias ou vídeos.
Esses sistemas de IA são treinados e otimizados para se destacar em suas áreas específicas de especialização. Eles contam com algoritmos, dados e regras predefinidas para realizar suas tarefas com eficácia.
No entanto, eles não possuem uma inteligência geral que lhes permita compreender ou realizar tarefas fora de seu domínio designado.
46. IA forte
IA forte, também conhecida como IA geral ou inteligência artificial geral (AGI), refere-se a uma forma de inteligência artificial que possui a capacidade de entender, aprender e realizar qualquer tarefa intelectual que um ser humano possa.
Ao contrário da IA fraca, projetada para tarefas específicas, a IA forte visa replicar inteligência e habilidades cognitivas semelhantes às humanas. Ela se esforça para criar máquinas ou softwares que não apenas se destaquem em tarefas especializadas, mas também possuam uma compreensão mais ampla e adaptabilidade para enfrentar uma ampla gama de desafios intelectuais.
O objetivo da IA forte é desenvolver sistemas que possam raciocinar, compreender informações complexas, aprender com a experiência, envolver-se em conversas em linguagem natural, exibir criatividade e exibir outras qualidades associadas à inteligência humana.
Em essência, aspira a criar sistemas de IA que possam simular ou replicar o pensamento de nível humano e a solução de problemas em vários domínios.
47. Encadeamento para frente
O encadeamento direto é um método de raciocínio ou lógica que começa com os dados disponíveis e os utiliza para fazer inferências e tirar novas conclusões. É como ligar os pontos usando as informações disponíveis para avançar e obter insights adicionais.
Imagine que você tem um conjunto de regras ou fatos e deseja obter novas informações ou chegar a conclusões específicas com base neles. O encadeamento direto funciona examinando os dados iniciais e aplicando regras lógicas para gerar fatos ou conclusões adicionais.
Para simplificar, vamos considerar um cenário simples para determinar o que vestir com base nas condições climáticas. Você tem uma regra que diz: “Se estiver chovendo, traga um guarda-chuva” e outra regra que diga: “Se estiver frio, use uma jaqueta”. Agora, se você observar que realmente está chovendo, poderá usar o encadeamento progressivo para inferir que deve trazer um guarda-chuva.
48. Encadeamento Reverso
O encadeamento reverso é um método de raciocínio que começa com uma conclusão ou objetivo desejado e trabalha para trás para determinar os dados ou fatos necessários para apoiar essa conclusão. É como rastrear suas etapas desde o resultado desejado até as informações iniciais necessárias para alcançá-lo.
Para entender o encadeamento reverso, vamos considerar um exemplo simples. Suponha que você queira determinar se é adequado para um mergulho. A conclusão desejada é se a natação é apropriada ou não com base em certas condições.
Em vez de começar com as condições, o encadeamento reverso começa com a conclusão e trabalha para trás para encontrar os dados de suporte.
Nesse caso, o encadeamento reverso envolveria fazer perguntas como "O tempo está quente?" Se a resposta for sim, você perguntaria: “Existe uma piscina disponível?” Se a resposta for sim novamente, você faria outras perguntas, como: “Há tempo suficiente para nadar?”
Ao responder iterativamente a essas perguntas e trabalhar de trás para frente, você pode determinar as condições necessárias que precisam ser atendidas para apoiar a conclusão de nadar.
49. Heurística
Uma heurística, em termos simples, é uma regra prática ou estratégia que nos ajuda a tomar decisões ou resolver problemas, geralmente com base em nossas experiências passadas ou intuição. É como um atalho mental que nos permite chegar rapidamente a uma solução razoável sem passar por um processo demorado ou exaustivo.
Diante de situações ou tarefas complexas, as heurísticas servem como princípios orientadores ou “regras práticas” que simplificam a tomada de decisões. Eles nos fornecem orientações gerais ou estratégias que muitas vezes são eficazes em determinadas situações, mesmo que não garantam a solução ideal.
Por exemplo, vamos considerar uma heurística para encontrar uma vaga de estacionamento em uma área movimentada. Em vez de analisar meticulosamente cada vaga disponível, você pode confiar na heurística de procurar carros estacionados com os motores ligados.
Essa heurística assume que esses carros estão prestes a sair, aumentando as chances de encontrar uma vaga disponível.
50. Modelagem de Linguagem Natural
A modelagem de linguagem natural, em termos simples, é o processo de treinamento de modelos de computador para entender e gerar a linguagem humana de maneira semelhante à forma como os humanos se comunicam. Envolve ensinar computadores a processar, interpretar e gerar texto de maneira natural e significativa.
O objetivo da modelagem de linguagem natural é permitir que os computadores compreendam e gerem a linguagem humana de uma forma que seja fluente, coerente e contextualmente relevante.
Envolve modelos de treinamento em grandes quantidades de dados textuais, como livros, artigos ou conversas, para aprender os padrões, estruturas e semântica da linguagem.
Depois de treinados, esses modelos podem executar várias tarefas relacionadas ao idioma, como tradução de idiomas, resumo de texto, resposta a perguntas, interações de chatbot e muito mais.
Eles podem entender o significado e o contexto das frases, extrair informações relevantes e gerar um texto gramaticalmente correto e coerente.





Deixe um comentário