Spis treści[Ukryć][Pokazać]
Gry wideo nadal stanowią wyzwanie dla miliardów graczy na całym świecie. Być może jeszcze tego nie wiesz, ale algorytmy uczenia maszynowego również zaczęły stawiać czoła wyzwaniu.
Obecnie prowadzi się wiele badań w dziedzinie sztucznej inteligencji, aby sprawdzić, czy metody uczenia maszynowego można zastosować w grach wideo. Znaczący postęp w tej dziedzinie pokazuje, że uczenie maszynowe agentów można używać do naśladowania lub nawet zastępowania ludzkiego gracza.
Co to oznacza dla przyszłości? gier wideo?
Czy te projekty są po prostu dla zabawy, czy też istnieją głębsze powody, dla których tak wielu badaczy skupia się na grach?
W tym artykule pokrótce omówimy historię sztucznej inteligencji w grach wideo. Następnie przedstawimy krótki przegląd niektórych technik uczenia maszynowego, których możemy użyć, aby nauczyć się wygrywać w grach. Następnie przyjrzymy się niektórym udanym aplikacjom sieci neuronowe uczyć się i opanowywać określone gry wideo.
Krótka historia sztucznej inteligencji w grach
Zanim przejdziemy do tego, dlaczego sieci neuronowe stały się idealnym algorytmem do rozwiązywania gier wideo, przyjrzyjmy się pokrótce, w jaki sposób informatycy wykorzystali gry wideo do postępów w badaniach nad sztuczną inteligencją.
Można argumentować, że od samego początku gry wideo były gorącym obszarem badań dla badaczy zainteresowanych sztuczną inteligencją.
Chociaż szachy nie były wyłącznie grą wideo, we wczesnych dniach sztucznej inteligencji były głównym przedmiotem zainteresowania. W 1951 r. dr Dietrich Prinz napisał program do gry w szachy przy użyciu komputera cyfrowego Ferranti Mark 1. To było w epoce, kiedy te nieporęczne komputery musiały odczytywać programy z taśmy papierowej.

Sam program nie był pełną szachową sztuczną inteligencją. Ze względu na ograniczenia komputera, Prinz mógł stworzyć tylko program, który rozwiązywał problemy szachowe z matem w dwójce. Obliczenie każdego możliwego ruchu zawodników białych i czarnych zajmowało programowi średnio 15-20 minut.
Praca nad poprawą szachów i warcabów Sztuczna inteligencja stale się poprawiała przez dziesięciolecia. Postęp osiągnął punkt kulminacyjny w 1997 roku, kiedy Deep Blue IBM pokonał rosyjskiego arcymistrza szachowego Garriego Kasparowa w parze sześciu meczów. W dzisiejszych czasach silniki szachowe, które można znaleźć w telefonie komórkowym, mogą pokonać Deep Blue.
Przeciwnicy AI zaczęli zdobywać popularność w złotym wieku gier zręcznościowych. Space Invaders z 1978 roku i Pac-Man z lat 1980. to jedni z pionierów w branży w tworzeniu sztucznej inteligencji, która może rzucić wyzwanie nawet najbardziej doświadczonym graczom arkadowym.
W szczególności Pac-Man był popularną grą, na której eksperymentowali naukowcy zajmujący się sztuczną inteligencją. Różnorodny konkursy dla pani Pac-Man zostały zorganizowane w celu ustalenia, która drużyna może wymyślić najlepszą sztuczną inteligencję, aby przejść grę.
Sztuczna inteligencja i algorytmy heurystyczne w grach ewoluowały wraz z pojawieniem się mądrzejszych przeciwników. Na przykład popularność walki ze sztuczną inteligencją wzrosła, gdy gatunki takie jak strzelanki pierwszoosobowe stały się bardziej popularne.
Uczenie maszynowe w grach wideo
Ponieważ techniki uczenia maszynowego szybko zyskały na popularności, różne projekty badawcze próbowały wykorzystać te nowe techniki do grania w gry wideo.
Gry takie jak Dota 2, StarCraft i Doom mogą stanowić dla nich problem algorytmy uczenia maszynowego rozwiązać. Algorytmy głębokiego uczenia, w szczególności były w stanie osiągnąć, a nawet przewyższyć wydajność na poziomie człowieka.
Połączenia Arcade Środowisko nauki lub ALE dało naukowcom interfejs dla ponad stu gier na Atari 2600. Platforma open source umożliwiła naukowcom porównanie wydajności technik uczenia maszynowego w klasycznych grach wideo na Atari. Google opublikowało nawet własne papier za pomocą siedmiu gier z ALE

Tymczasem projekty takie jak VizDoom dało naukowcom AI możliwość trenowania algorytmów uczenia maszynowego do grania w strzelanki 3D z perspektywy pierwszej osoby.

Jak to działa: kilka kluczowych pojęć
Sieci neuronowe
Większość podejść do rozwiązywania gier wideo za pomocą uczenia maszynowego obejmuje rodzaj algorytmu znanego jako sieć neuronowa.
Możesz myśleć o sieci neuronowej jako o programie, który próbuje naśladować funkcjonowanie mózgu. Podobnie jak nasz mózg składa się z neuronów, które przekazują sygnał, sieć neuronowa zawiera również sztuczne neurony.
Te sztuczne neurony również przekazują sobie nawzajem sygnały, przy czym każdy sygnał jest rzeczywistą liczbą. Sieć neuronowa zawiera wiele warstw pomiędzy warstwą wejściową i wyjściową, zwaną głęboką siecią neuronową.
Uczenie się przez wzmocnienie
Inną powszechną techniką uczenia maszynowego związaną z nauką gier wideo jest idea uczenia się przez wzmacnianie.
Ta technika to proces szkolenia agenta za pomocą nagród lub kar. Dzięki takiemu podejściu agent powinien być w stanie znaleźć rozwiązanie problemu metodą prób i błędów.
Powiedzmy, że chcemy, aby sztuczna inteligencja dowiedziała się, jak grać w grę Snake. Cel gry jest prosty: zdobądź jak najwięcej punktów, konsumując przedmioty i unikając rosnącego ogona.
Dzięki uczeniu się przez wzmacnianie możemy zdefiniować funkcję nagrody R. Funkcja dodaje punkty, gdy Wąż zjada przedmiot i odejmuje punkty, gdy Wąż uderza w przeszkodę. Biorąc pod uwagę obecne środowisko i zestaw możliwych działań, nasz model uczenia się przez wzmacnianie spróbuje obliczyć optymalną „politykę”, która maksymalizuje naszą funkcję nagrody.
Neuroewolucja
Trzymając się motywu inspiracji naturą, naukowcy odnieśli również sukces w stosowaniu ML w grach wideo za pomocą techniki znanej jako neuroewolucja.
Zamiast używać opadanie gradientu aby zaktualizować neurony w sieci, możemy użyć algorytmów ewolucyjnych, aby osiągnąć lepsze wyniki.
Algorytmy ewolucyjne zazwyczaj rozpoczynają się od wygenerowania początkowej populacji przypadkowych osobników. Następnie oceniamy te osoby według określonych kryteriów. Najlepsze osobniki są wybierane na „rodziców” i są krzyżowane razem, aby stworzyć nowe pokolenie osobników. Osoby te zastąpią następnie najmniej przystosowane osobniki w populacji.
Algorytmy te również zazwyczaj wprowadzają pewną formę operacji mutacji podczas etapu krzyżowania lub „hodowli”, aby zachować różnorodność genetyczną.
Przykładowe badania nad uczeniem maszynowym w grach wideo
OpenAI Pięć

OpenAI Pięć to program komputerowy firmy OpenAI, którego celem jest granie w DOTA 2, popularną mobilną grę wieloosobową (MOBA).
W programie wykorzystano istniejące techniki uczenia się przez wzmacnianie, skalowane do uczenia się z milionów klatek na sekundę. Dzięki rozproszonemu systemowi szkoleniowemu, OpenAI było w stanie codziennie rozgrywać gry, które trwają 180 lat.
Po okresie treningowym OpenAI Five był w stanie osiągnąć wydajność na poziomie eksperckim i zademonstrować współpracę z ludzkimi graczami. W 2019 roku OpenAI XNUMX było w stanie: pokonać 99.4% graczy w meczach publicznych.
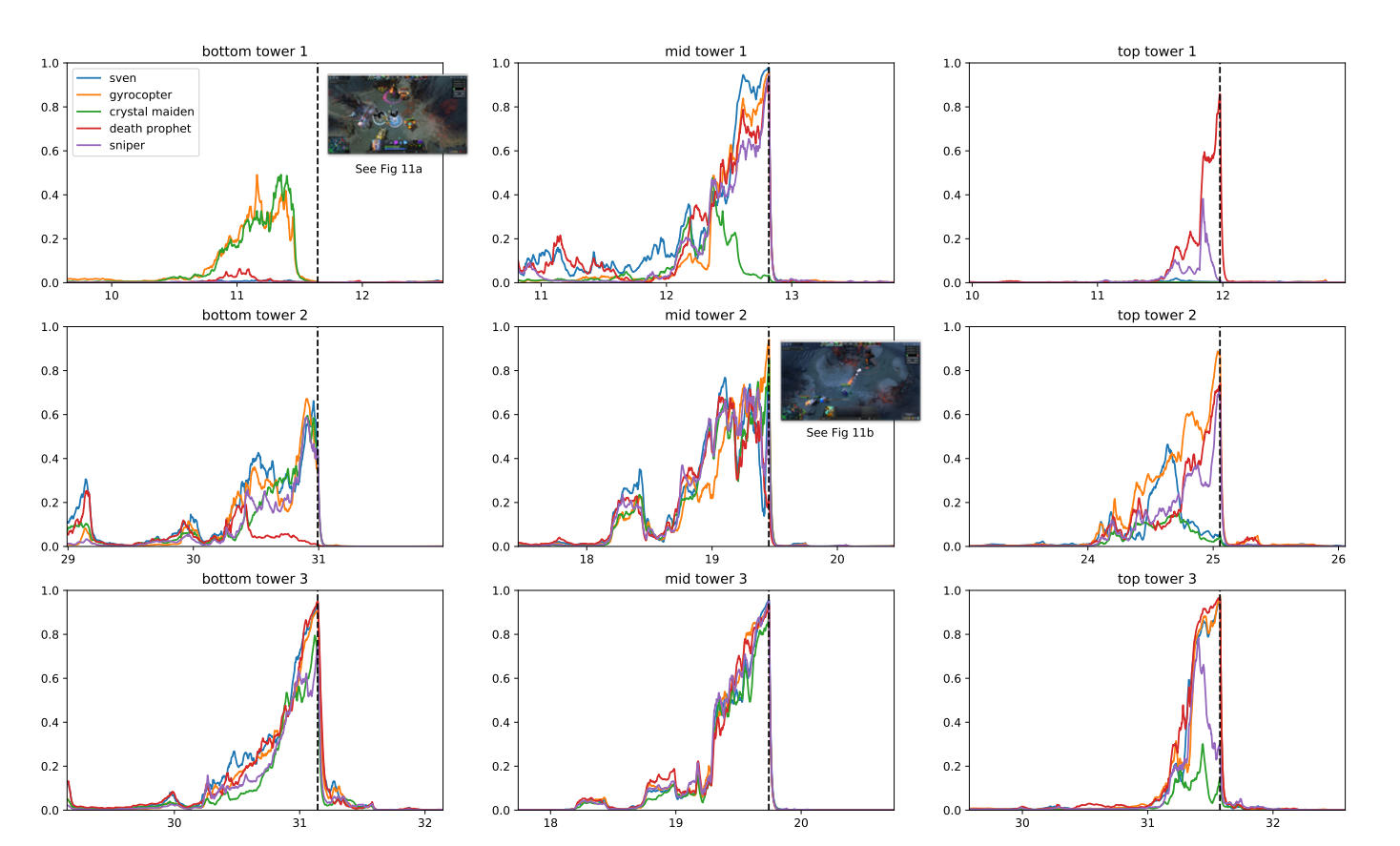
Dlaczego OpenAI zdecydowało się na tę grę? Według badaczy DOTA 2 miała złożoną mechanikę, która była poza zasięgiem istniejącej głębi uczenie się wzmacniania algorytmy.
Super Mario Bros
Innym ciekawym zastosowaniem sieci neuronowych w grach wideo jest wykorzystanie neuroewolucji do grania w platformówki, takie jak Super Mario Bros.
Na przykład to wpis do hackathonu zaczyna się od braku wiedzy o grze i powoli buduje podstawy tego, co jest potrzebne do przejścia przez poziom.
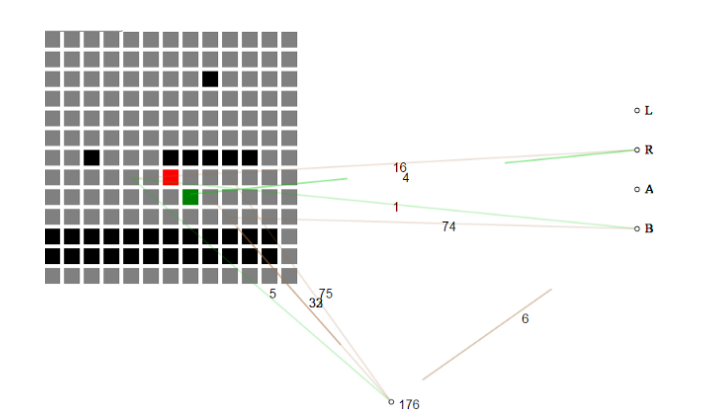
Samorozwijająca się sieć neuronowa przyjmuje obecny stan gry jako siatkę kafelków. Początkowo sieć neuronowa nie rozumie, co oznacza każda płytka, tylko że płytki „powietrza” różnią się od „kafelków naziemnych” i „kafelków wroga”.
Implementacja neuroewolucji w ramach projektu hackathon wykorzystywała algorytm genetyczny NEAT do selektywnego rozmnażania różnych sieci neuronowych.
Znaczenie
Teraz, gdy widziałeś już kilka przykładów sieci neuronowych grających w gry wideo, możesz się zastanawiać, o co w tym wszystkim chodzi.
Ponieważ gry wideo wiążą się ze złożonymi interakcjami między agentami i ich środowiskami, jest to idealny poligon doświadczalny do tworzenia sztucznej inteligencji. Środowiska wirtualne są bezpieczne i można je kontrolować oraz zapewniają nieskończoną ilość danych.
Badania przeprowadzone w tej dziedzinie dały naukowcom wgląd w to, jak można zoptymalizować sieci neuronowe, aby dowiedzieć się, jak rozwiązywać problemy w świecie rzeczywistym.
Sieci neuronowe są inspirowane tym, jak mózgi działają w świecie przyrody. Badając, jak zachowują się sztuczne neurony podczas nauki gry w gry wideo, możemy również uzyskać wgląd w to, jak ludzki mózg działa.
Wnioski
Podobieństwa między sieciami neuronowymi a mózgiem doprowadziły do spostrzeżeń w obu dziedzinach. Ciągłe badania nad tym, jak sieci neuronowe mogą rozwiązywać problemy, mogą kiedyś doprowadzić do bardziej zaawansowanych form sztuczna inteligencja.
Wyobraź sobie, że korzystasz ze sztucznej inteligencji dostosowanej do twoich specyfikacji, która może zagrać w całą grę wideo przed jej zakupem, aby dać ci znać, czy jest warta twojego czasu. Czy firmy zajmujące się grami wideo używałyby sieci neuronowych do ulepszania projektowania gier, dostosowywania poziomu i trudności przeciwników?
Jak myślisz, co się stanie, gdy sieci neuronowe staną się najlepszymi graczami?





Dodaj komentarz