Spis treści[Ukryć][Pokazać]
Dzięki komputerom możemy teraz obliczyć przestrzeń kosmiczną i najdrobniejsze zawiłości cząstek subatomowych.
Komputery pokonały ludzi, jeśli chodzi o liczenie i obliczenia, a także podążanie za logicznymi procesami tak/nie, dzięki elektronom poruszającym się z prędkością światła przez ich obwody.
Jednak często nie postrzegamy ich jako „inteligentnych”, ponieważ w przeszłości komputery nie mogły niczego wykonywać bez nauki (programowania) przez ludzi.
Uczenie maszynowe, w tym uczenie głębokie i sztuczna inteligencja, stał się modnym hasłem w nagłówkach naukowych i technologicznych.
Uczenie maszynowe wydaje się być wszechobecne, ale wiele osób, które używają tego słowa, miałoby trudności z odpowiednim zdefiniowaniem, czym ono jest, do czego służy i do czego najlepiej się nadaje.
Ten artykuł ma na celu wyjaśnienie uczenia maszynowego, a także dostarczenie konkretnych, rzeczywistych przykładów działania tej technologii, aby zilustrować, dlaczego jest ona tak korzystna.
Następnie przyjrzymy się różnym metodologiom uczenia maszynowego i zobaczymy, jak są one wykorzystywane do rozwiązywania problemów biznesowych.
Na koniec skonsultujemy się z naszą kryształową kulą, aby uzyskać kilka szybkich prognoz dotyczących przyszłości uczenia maszynowego.
Co to jest uczenie maszynowe?
Uczenie maszynowe to dyscyplina informatyki, która umożliwia komputerom wnioskowanie o wzorach na podstawie danych bez wyraźnego nauczania, jakie to są wzorce.
Wnioski te często opierają się na zastosowaniu algorytmów do automatycznej oceny cech statystycznych danych i opracowaniu modeli matematycznych do zobrazowania relacji między różnymi wartościami.
Porównaj to z klasyczną informatyką, która opiera się na systemach deterministycznych, w których wyraźnie dajemy komputerowi zestaw reguł, których musi przestrzegać, aby mógł wykonać określone zadanie.
Ten sposób programowania komputerów jest znany jako programowanie oparte na regułach. Uczenie maszynowe różni się i przewyższa programowanie oparte na regułach, ponieważ może samodzielnie wydedukować te reguły.
Załóżmy, że jesteś kierownikiem banku, który chce ustalić, czy wniosek o pożyczkę zakończy się niepowodzeniem.
W metodzie opartej na regułach kierownik banku (lub inni specjaliści) wyraźnie informowałby komputer, że jeśli ocena kredytowa wnioskodawcy jest poniżej pewnego poziomu, wniosek powinien zostać odrzucony.
Jednak program uczenia maszynowego po prostu przeanalizowałby wcześniejsze dane dotyczące ratingów kredytowych klientów i wyników kredytowych i samodzielnie określiłby, jaki powinien być ten próg.
Maszyna uczy się na podstawie poprzednich danych i tworzy w ten sposób własne reguły. Oczywiście to tylko wstęp do uczenia maszynowego; rzeczywiste modele uczenia maszynowego są znacznie bardziej skomplikowane niż podstawowy próg.
Niemniej jednak jest to doskonała demonstracja potencjału uczenia maszynowego.
Jak działa maszyna uczyć się?
Aby uprościć sprawę, maszyny „uczą się”, wykrywając wzorce w porównywalnych danych. Traktuj dane jako informacje, które zbierasz ze świata zewnętrznego. Im więcej danych jest dostarczanych do maszyny, tym staje się „mądrzejsza”.
Jednak nie wszystkie dane są takie same. Załóżmy, że jesteś piratem, którego życiowym celem jest odkrycie zakopanych bogactw na wyspie. Będziesz potrzebować znacznej wiedzy, aby zlokalizować nagrodę.
Ta wiedza, podobnie jak dane, może zaprowadzić cię we właściwy lub zły sposób.
Im więcej uzyskanych informacji/danych, tym mniej niejasności i na odwrót. W rezultacie bardzo ważne jest rozważenie rodzaju danych, które przekazujesz swojej maszynie w celu uczenia się.
Jednak po dostarczeniu znacznej ilości danych komputer może przewidywać. Maszyny mogą przewidywać przyszłość, o ile nie odbiega ona zbytnio od przeszłości.
Maszyny „uczą się”, analizując dane historyczne, aby określić, co może się wydarzyć.
Jeśli stare dane przypominają nowe, to rzeczy, które możesz powiedzieć o poprzednich danych, prawdopodobnie będą miały zastosowanie do nowych danych. To tak, jakbyś spoglądał wstecz, by zobaczyć przyszłość.
Jakie są rodzaje uczenia maszynowego?
Algorytmy uczenia maszynowego są często podzielone na trzy szerokie typy (chociaż stosowane są również inne schematy klasyfikacji):
- Nadzorowana nauka
- Uczenie się bez nadzoru
- Uczenie się przez wzmocnienie
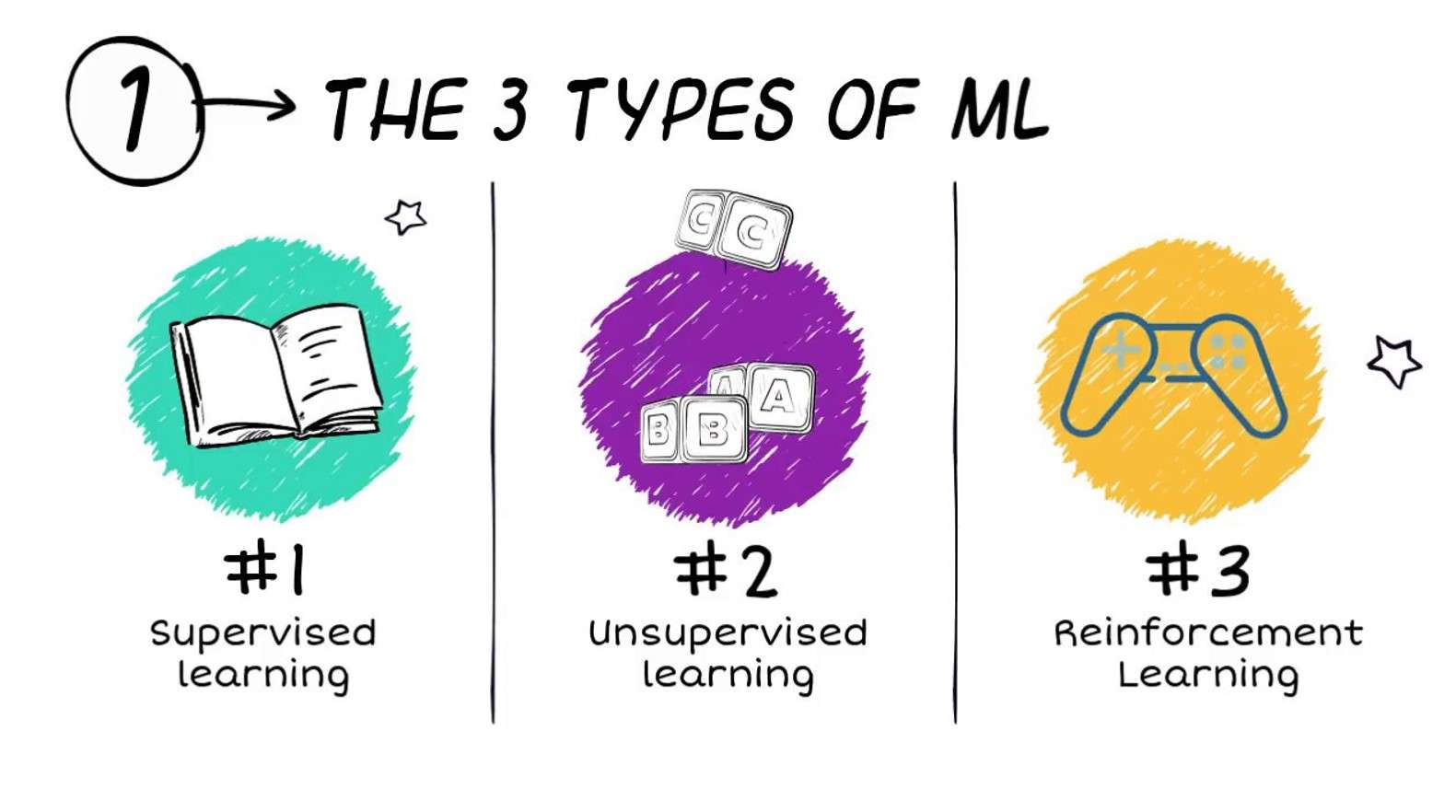
Nadzorowana nauka
Nadzorowane uczenie maszynowe odnosi się do technik, w których model uczenia maszynowego otrzymuje zbiór danych z wyraźnymi etykietami dla ilości będącej przedmiotem zainteresowania (ta wielkość jest często określana jako odpowiedź lub cel).
Aby wyszkolić modele AI, uczenie częściowo nadzorowane wykorzystuje mieszankę danych oznaczonych i nieoznakowanych.
Jeśli pracujesz z danymi nieoznaczonymi etykietami, musisz wykonać pewne etykietowanie danych.
Etykietowanie to proces oznaczania próbek w celu ułatwienia trenowanie uczenia maszynowego Model. Etykietowanie jest wykonywane głównie przez ludzi, co może być kosztowne i czasochłonne. Istnieją jednak techniki automatyzacji procesu etykietowania.
Omówiona wcześniej sytuacja związana z wnioskiem o pożyczkę jest doskonałą ilustracją nadzorowanego uczenia się. Mieliśmy historyczne dane dotyczące ratingów kredytowych byłych osób ubiegających się o pożyczkę (i być może poziomów dochodów, wieku itd.), A także konkretne etykiety, które mówiły nam, czy dana osoba nie spłacała pożyczki.
Regresja i klasyfikacja to dwa podzbiory technik uczenia nadzorowanego.
- Klasyfikacja – Wykorzystuje algorytm do prawidłowego kategoryzowania danych. Jednym z przykładów są filtry antyspamowe. „Spam” może być kategorią subiektywną — granica między komunikacją spamową a niespamową jest niewyraźna — a algorytm filtrowania spamu stale się udoskonala w zależności od opinii użytkowników (co oznacza wiadomości e-mail oznaczane przez ludzi jako spam).
- Regresja – Jest pomocny w zrozumieniu związku między zmiennymi zależnymi i niezależnymi. Modele regresji mogą prognozować wartości liczbowe na podstawie kilku źródeł danych, takich jak szacunki przychodów ze sprzedaży dla określonej firmy. Regresja liniowa, regresja logistyczna i regresja wielomianowa to niektóre znane techniki regresji.
Uczenie się bez nadzoru
W uczeniu się bez nadzoru otrzymujemy nieoznakowane dane i szukamy tylko wzorców. Udawajmy, że jesteś Amazonką. Czy możemy znaleźć klastry (grupy podobnych konsumentów) na podstawie historii zakupów klientów?
Nawet jeśli nie mamy jednoznacznych, rozstrzygających danych na temat preferencji danej osoby, w tym przypadku po prostu wiedząc, że określona grupa konsumentów kupuje porównywalne towary, możemy zaproponować zakup na podstawie tego, co kupiły również inne osoby w klastrze.
Karuzela Amazona „Może Cię też zainteresuje” jest oparta na podobnych technologiach.
Uczenie bez nadzoru może grupować dane za pomocą grupowania lub asocjacji, w zależności od tego, co chcesz zgrupować.
- Klastry – Uczenie bez nadzoru próbuje przezwyciężyć to wyzwanie, szukając wzorców w danych. Jeśli istnieje podobny klaster lub grupa, algorytm kategoryzuje je w określony sposób. Przykładem tego jest próba kategoryzowania klientów na podstawie historii zakupów.
- Stowarzyszenie – Uczenie się bez nadzoru próbuje stawić czoła temu wyzwaniu, próbując zrozumieć zasady i znaczenia leżące u podstaw różnych grup. Częstym przykładem problemu z asocjacją jest określenie powiązania między zakupami klientów. Sklepy mogą być zainteresowane wiedzą, jakie towary zostały zakupione razem, i mogą wykorzystać te informacje do rozmieszczenia tych produktów w celu ułatwienia dostępu.
Uczenie się ze wzmocnieniem
Uczenie się przez wzmacnianie to technika uczenia modeli uczenia maszynowego w celu podejmowania serii decyzji zorientowanych na cel w środowisku interaktywnym. Wspomniane powyżej przypadki użycia w grach są tego doskonałą ilustracją.
Nie musisz wprowadzać do AlphaZero tysięcy poprzednich partii szachowych, z których każda miała oznaczony „dobry” lub „zły” ruch. Po prostu naucz go zasad gry i celu, a następnie pozwól mu wypróbować losowe działania.
Pozytywne wzmocnienie jest przyznawane działaniom, które przybliżają program do celu (takie jak wypracowanie solidnej pozycji pionka). Kiedy działania mają odwrotny skutek (np. przedwczesne przesunięcie króla), przynoszą negatywne wzmocnienie.
Oprogramowanie może ostatecznie opanować grę przy użyciu tej metody.
Uczenie się przez wzmocnienie jest szeroko stosowany w robotyce do uczenia robotów skomplikowanych i trudnych do zaprojektowania działań. Czasami jest używany w połączeniu z infrastrukturą drogową, taką jak sygnalizacja świetlna, w celu poprawy płynności ruchu.
Co można zrobić z uczeniem maszynowym?
Wykorzystanie uczenia maszynowego w społeczeństwie i przemyśle skutkuje postępem w szerokim zakresie ludzkich przedsięwzięć.
W naszym codziennym życiu uczenie maszynowe steruje teraz algorytmami wyszukiwania i grafiki Google, umożliwiając nam dokładniejsze dopasowywanie potrzebnych informacji wtedy, gdy ich potrzebujemy.
Na przykład w medycynie uczenie maszynowe jest stosowane do danych genetycznych, aby pomóc lekarzom zrozumieć i przewidzieć sposób rozprzestrzeniania się raka, co pozwala na opracowanie skuteczniejszych terapii.
Dane z przestrzeni kosmicznej są zbierane tutaj, na Ziemi, za pomocą masywnych radioteleskopów – a po analizie za pomocą uczenia maszynowego pomagają nam rozwikłać tajemnice czarnych dziur.
Uczenie maszynowe w handlu detalicznym łączy kupujących z rzeczami, które chcą kupić online, a także pomaga pracownikom sklepów dostosować usługi świadczone do klientów w świecie stacjonarnym.
Uczenie maszynowe jest wykorzystywane w walce z terroryzmem i ekstremizmem, aby przewidywać zachowanie tych, którzy chcą skrzywdzić niewinnych.
Przetwarzanie języka naturalnego (NLP) odnosi się do procesu umożliwiającego komputerom rozumienie i komunikowanie się z nami w ludzkim języku poprzez uczenie maszynowe, co zaowocowało przełomami w technologii tłumaczenia, a także urządzeniami sterowanymi głosem, z których coraz częściej korzystamy na co dzień, takimi jak Alexa, kropka Google, Siri i asystent Google.
Bez wątpienia uczenie maszynowe pokazuje, że jest technologią transformacyjną.
Roboty zdolne do współpracy z nami i pobudzania własnej oryginalności i wyobraźni swoją nienaganną logiką i nadludzką szybkością nie są już fantazją science fiction – w wielu sektorach stają się rzeczywistością.
Przypadki użycia uczenia maszynowego
1. Cyberbezpieczeństwo
W miarę jak sieci stawały się coraz bardziej skomplikowane, specjaliści ds. cyberbezpieczeństwa pracowali niestrudzenie, aby dostosować się do stale rosnącego zakresu zagrożeń bezpieczeństwa.
Zwalczanie szybko ewoluującego złośliwego oprogramowania i taktyk hakerskich jest wystarczająco trudne, ale rozprzestrzenianie się urządzeń Internetu rzeczy (IoT) zasadniczo zmieniło środowisko cyberbezpieczeństwa.
Ataki mogą nastąpić w dowolnym momencie iw dowolnym miejscu.
Na szczęście algorytmy uczenia maszynowego umożliwiły operacjom cyberbezpieczeństwa nadążanie za tymi szybkimi zmianami.
Analityka predykcyjna umożliwiają szybsze wykrywanie i łagodzenie ataków, podczas gdy uczenie maszynowe może analizować Twoją aktywność w sieci, aby wykrywać nieprawidłowości i słabości w istniejących mechanizmach bezpieczeństwa.
2. Automatyzacja obsługi klienta
Zarządzanie rosnącą liczbą kontaktów z klientami online nadwyrężyło wiele organizacji.
Po prostu nie mają wystarczającej liczby pracowników obsługi klienta, aby obsłużyć liczbę otrzymywanych zapytań, a tradycyjne podejście polegające na outsourcingu contact center jest po prostu nie do przyjęcia dla wielu dzisiejszych klientów.
Chatboty i inne zautomatyzowane systemy mogą teraz sprostać tym wymaganiom dzięki postępowi w technikach uczenia maszynowego. Firmy mogą zwolnić personel, aby zajmował się obsługą klienta na wyższym poziomie, automatyzując przyziemne czynności o niskim priorytecie.
Przy prawidłowym stosowaniu uczenie maszynowe w biznesie może pomóc usprawnić rozwiązywanie problemów i zapewnić konsumentom pomocne wsparcie, które sprawi, że staną się zaangażowanymi mistrzami marki.
3. Komunikacja
Unikanie błędów i nieporozumień ma kluczowe znaczenie w każdym rodzaju komunikacji, ale jest to szczególnie ważne we współczesnej komunikacji biznesowej.
Proste błędy gramatyczne, niewłaściwy ton lub błędne tłumaczenia mogą powodować szereg trudności w kontaktach e-mailowych, ocenach klientów, wideokonferencjelub dokumentacja tekstowa w wielu formach.
Systemy uczenia maszynowego mają zaawansowaną komunikację znacznie wykraczającą poza szczytowe dni Clippy firmy Microsoft.
Te przykłady uczenia maszynowego pomogły poszczególnym osobom komunikować się w prosty i precyzyjny sposób za pomocą przetwarzania języka naturalnego, tłumaczenia języka w czasie rzeczywistym i rozpoznawania mowy.
Chociaż wiele osób nie lubi funkcji autokorekty, cenią sobie również ochronę przed kłopotliwymi błędami i niewłaściwym tonem.
4. Rozpoznawanie obiektów
Chociaż technologia zbierania i interpretowania danych istnieje już od jakiegoś czasu, nauczenie systemów komputerowych zrozumienia tego, na co patrzą, okazało się zwodniczo trudnym zadaniem.
Możliwości rozpoznawania obiektów są dodawane do coraz większej liczby urządzeń dzięki aplikacjom uczenia maszynowego.
Na przykład samojezdny samochód rozpoznaje inny samochód, gdy go widzi, nawet jeśli programiści nie podali mu dokładnego przykładu tego samochodu do wykorzystania jako odniesienie.
Ta technologia jest obecnie wykorzystywana w handlu detalicznym, aby przyspieszyć proces realizacji transakcji. Kamery identyfikują produkty w koszykach konsumentów i mogą automatycznie obciążać ich konta, gdy opuszczają sklep.
5. Marketing cyfrowy
Wiele dzisiejszych działań marketingowych odbywa się online, przy użyciu szeregu platform cyfrowych i programów.
Gdy firmy zbierają informacje o swoich konsumentach i ich zachowaniach zakupowych, zespoły marketingowe mogą wykorzystać te informacje do zbudowania szczegółowego obrazu swoich docelowych odbiorców i odkrycia, którzy ludzie są bardziej skłonni do poszukiwania ich produktów i usług.
Algorytmy uczenia maszynowego pomagają marketerom w zrozumieniu wszystkich tych danych, odkrywaniu znaczących wzorców i atrybutów, które pozwalają im ściśle kategoryzować możliwości.
Ta sama technologia pozwala na dużą automatyzację marketingu cyfrowego. Systemy reklamowe można skonfigurować tak, aby dynamicznie odkrywały nowych potencjalnych konsumentów i dostarczały im odpowiednie treści marketingowe we właściwym czasie i miejscu.
Przyszłość uczenia maszynowego
Uczenie maszynowe z pewnością zyskuje na popularności, ponieważ coraz więcej firm i dużych organizacji korzysta z tej technologii, aby stawić czoła określonym wyzwaniom lub napędzać innowacje.
Ta ciągła inwestycja świadczy o zrozumieniu, że uczenie maszynowe generuje zwrot z inwestycji, szczególnie dzięki niektórym z wyżej wymienionych ustalonych i powtarzalnych przypadków użycia.
W końcu, jeśli technologia jest wystarczająco dobra dla Netflix, Facebooka, Amazona, Google Maps i tak dalej, istnieje duże prawdopodobieństwo, że pomoże również Twojej firmie w pełni wykorzystać swoje dane.
Jak nowy uczenie maszynowe modele są opracowywane i wprowadzane na rynek, będziemy świadkami wzrostu liczby aplikacji, które będą wykorzystywane w różnych branżach.
To już się dzieje z rozpoznawanie twarzy, która kiedyś była nową funkcją w iPhonie, ale teraz jest wdrażana w wielu programach i aplikacjach, zwłaszcza tych związanych z bezpieczeństwem publicznym.
Kluczem dla większości organizacji, które próbują zacząć korzystać z uczenia maszynowego, jest spojrzenie poza jasne futurystyczne wizje i odkrycie prawdziwych wyzwań biznesowych, w których technologia może pomóc.
Wnioski
W epoce postindustrialnej naukowcy i profesjonaliści próbowali stworzyć komputer, który zachowywałby się bardziej jak człowiek.
Myśląca maszyna jest najbardziej znaczącym wkładem sztucznej inteligencji w ludzkość; fenomenalne pojawienie się tej samobieżnej maszyny szybko zmieniło korporacyjne przepisy operacyjne.
Samojezdne pojazdy, zautomatyzowani asystenci, autonomiczni pracownicy produkcyjni i inteligentne miasta wykazały ostatnio opłacalność inteligentnych maszyn. Rewolucja uczenia maszynowego i przyszłość uczenia maszynowego będą z nami przez długi czas.





Dodaj komentarz