Spis treści[Ukryć][Pokazać]
Dane są wszędzie wokół Ciebie. W rzeczywistości wpływa to na każdy aspekt Twojej działalności. Może się wydawać, że nie ma wystarczająco dużo czasu na zbadanie, jak dobrze służy Twojej firmie, gdy jesteś zajęty decyzjami dotyczącymi sposobu postępowania z danymi.
Obserwuj to. Twoja organizacja korzysta z danych 24 godziny na dobę. Dlatego zrozumienie, skąd się wzięło, jak się tam dostało i jak przechodzi przez firmę, ma kluczowe znaczenie dla zrozumienia jego wartości.
Pochodzenie danych staje się ważne w tej sytuacji. Łatwiej jest zrozumieć, w jaki sposób dane zostały utworzone, skąd pochodzą i dokąd zmierzają, gdy możemy śledzić pochodzenie, migracje i zmiany danych.
W tym poście przyjrzymy się dokładnie Data Lineage, jak to działa, jego przypadkom użycia, technikom i wielu innym.
Co to jest pochodzenie danych?
Pochodzenie danych służy jako rodzaj paszportu cyfrowego. Jest to najobszerniejszy opis podróży z danymi, wyszczególniający wszystkie jej przystanki, objazdy i modyfikacje od początku do ostatecznego miejsca docelowego.
IZasadniczo pochodzenie danych opisuje pochodzenie, modyfikację i wykorzystanie fragmentu danych w wielu systemach i platformach. Działa jako narzędzie detektywistyczne, dostarczając użytkownikom informacji o tym, jak dane zostały wyprodukowane, skąd pochodzą i jak zostały wykorzystane. Informacje te umożliwiają użytkownikom rozpoznawanie i rozwiązywanie wszelkich potencjalnych problemów.
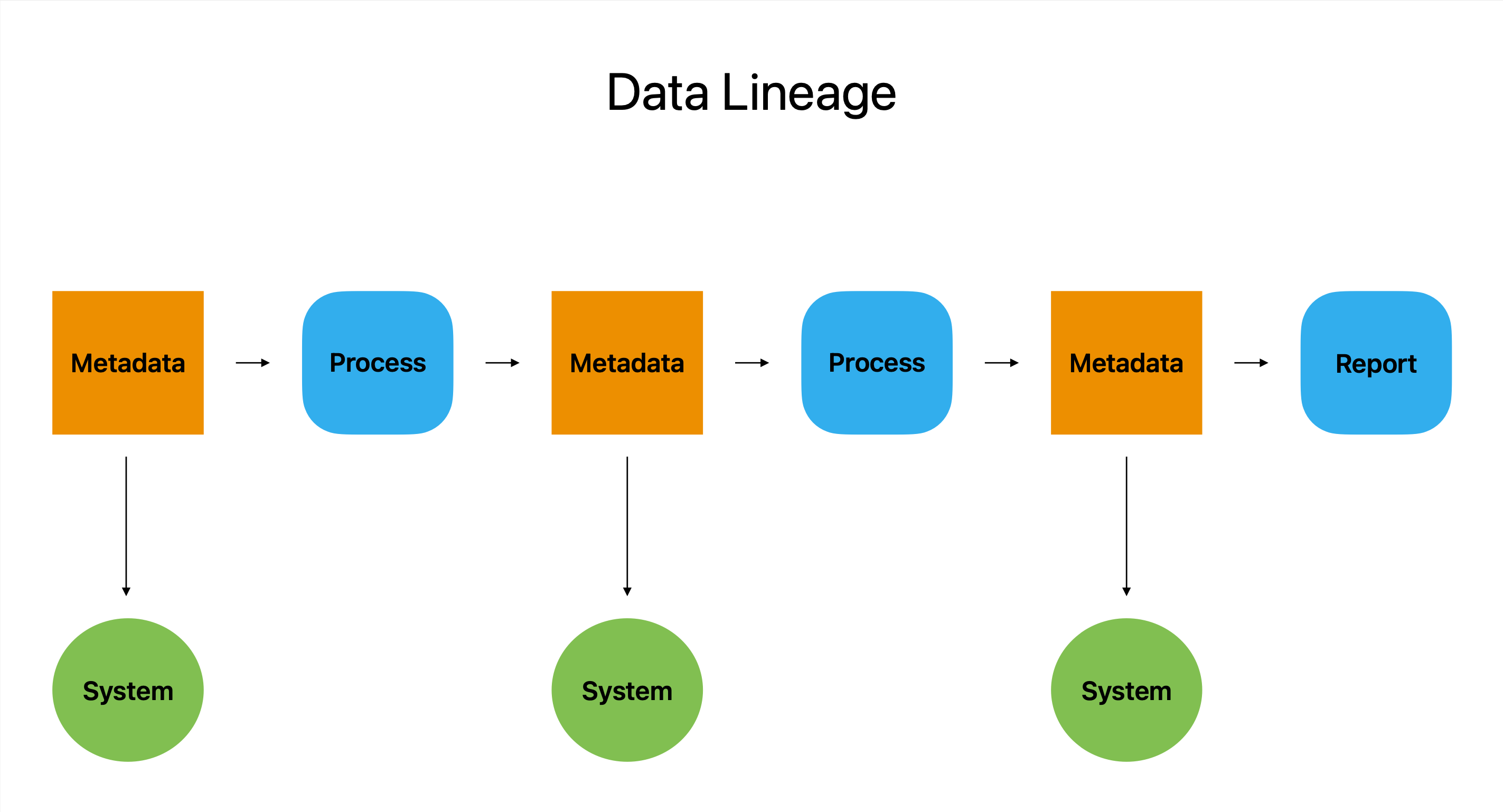
Pochodzenie danych jest bezcennym zasobem dla firm, które polegają na danych, aby prowadzić swoją działalność, ponieważ pozwala użytkownikom odpowiadać na kluczowe pytania, takie jak kto, co, kiedy i gdzie.
Pochodzenie danych to, mówiąc prościej, ostateczny ślad danych, który gwarantuje dokładność, kompletność i spójność danych, oferując jednocześnie jasną i zwięzłą perspektywę pełnej ścieżki danych.
Jak działa Data Lineage?
Pochodzenie danych to mapa drogowa, która pozwala nam śledzić fragment danych od punktu początkowego do punktu końcowego. Rozważ punkt danych jako podróżnika, a jego paszport jako linię danych, aby lepiej zrozumieć, jak działa.
Źródła danych, transformacja danych, przechowywanie danych i dane wyjściowe składają się na cztery podstawowe elementy paszportu.
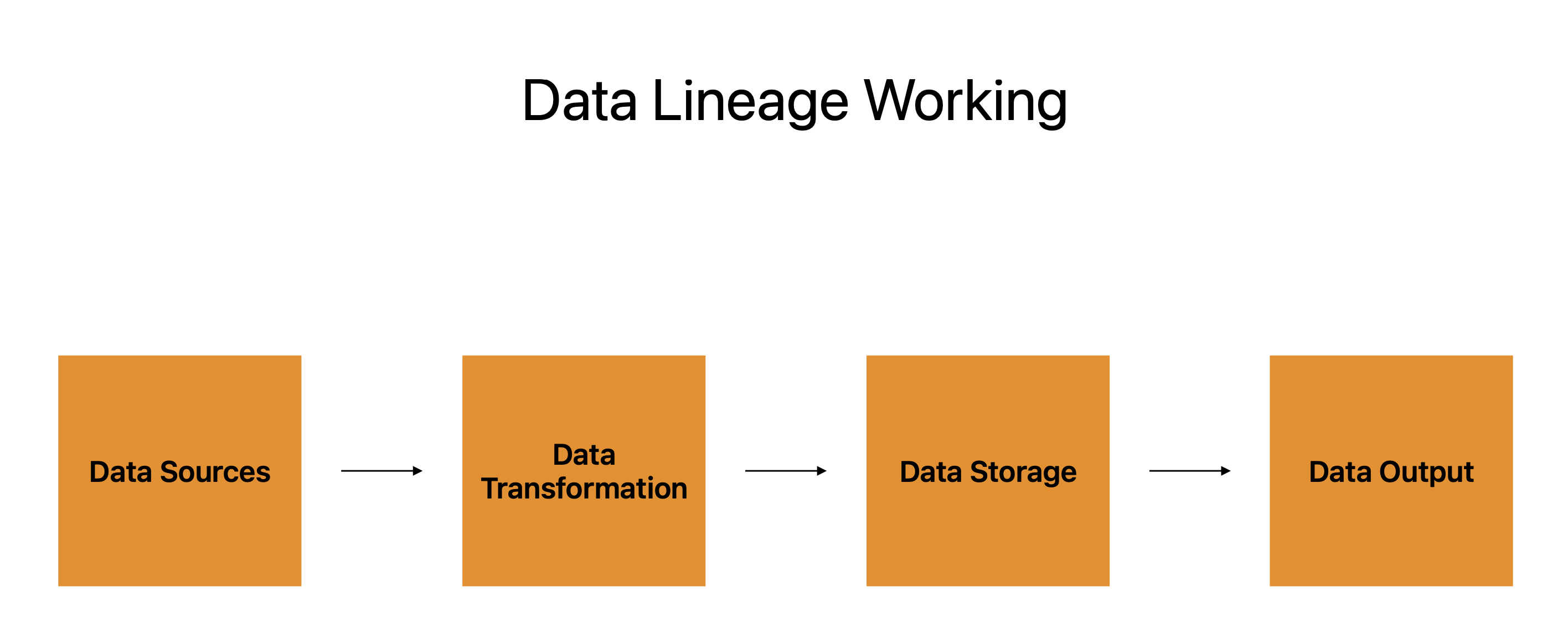
Wiele systemów, aplikacji i platform, z których pochodzą dane, jest reprezentowanych przez źródła danych, które służą jako punkty początkowe w podróży danych. Transformacja danych jest kolejnym etapem, a pochodzenie danych przedstawia wykres postępu danych od tych źródeł do nich.
Transformacja danych odnosi się do kształtowania, modyfikowania i manipulowania danymi w celu zaspokojenia potrzeb użytkownika. Pełni funkcję postoju podczas podróży danych, przygotowując go do następnego etapu.
Dane są następnie przechowywane przed przeniesieniem do ostatecznej lokalizacji. Może być przechowywany na serwerach w chmurze, bazach danych lub na innym urządzeniu pamięci masowej. Pochodzenie danych śledzi miejsce przechowywania danych, a także sposób ich ochrony, tworzenia kopii zapasowych i odzyskiwania.
Ostatnim krokiem jest wyjście danych, czyli miejsce, w którym dane są wysyłane do użycia. Do jej prezentacji można wykorzystać raporty, infografiki lub jakikolwiek inny produkt danych. Pochodzenie danych śledzi dane wyjściowe i gwarantuje spójność, dokładność i kompletność danych.
Pochodzenie danych zasadniczo polega na rejestrowaniu każdego etapu podróży danych, od ich powstania do wyjścia, i upewnieniu się, że pozostają one niezawodne, spójne i poprawne przez cały czas. Pochodzenie danych pomaga organizacjom podejmować przemyślane decyzje, rozwiązywać problemy i przestrzegać zobowiązań prawnych, dając pełny wgląd w istnienie danych.
Aby zrozumieć zasoby danych i sposób, w jaki przechodzą one przez potok danych, metadane są kluczową częścią procesu pochodzenia danych.
Możesz zobaczyć, jak dane są konwertowane i wykorzystywane w organizacji za pomocą narzędzi do ustalania pochodzenia danych, które wykorzystują metadane do wizualnego przedstawienia przepływu danych. Umożliwia to użytkownikom ocenę potencjału danych, pomagając im w podejmowaniu bardziej świadomych decyzji.
Rodzaje rodowodu danych
Istnieją trzy podstawowe formy rodowodu danych: rodowód danych do przodu, rodowód danych do tyłu i rodowód danych dwukierunkowych.
Pochodzenie danych do przodu
Podobnie jak w przypadku ulicy jednokierunkowej, pochodzenie danych w przód polega na śledzeniu fragmentu danych od punktu początkowego do punktu końcowego. Zaczynając od źródła danych, śledzi dane, które przechodzą przez kilka transformacji i systemów przechowywania, aby osiągnąć swoje dane wyjściowe.
Zrozumienie przetwarzania i przekształcania danych oraz wszelkich problemów, które mogą pojawić się po drodze, jest ułatwione dzięki tego rodzaju rodowodom danych. Każdy krok prowadzi do następnego; to jak podążanie śladem okruszków chleba.
Pochodzenie danych wstecz
Pochodzenie wsteczne danych jest podobne do podróży w odwrotną stronę, w której śledzimy wyjście danych z powrotem do ich źródła. Proces rozpoczyna się w ostatecznej lokalizacji danych i cofa się poprzez różne techniki przechowywania i przekształcania, aż dotrze do źródła danych.
Identyfikacja pierwotnego źródła danych, zrozumienie ich transformacji oraz weryfikacja ich poprawności i kompletności są możliwe przy pomocy tego rodzaju rodowodu danych. Działa jak narzędzie detektywa, pozwalając nam prześledzić ścieżkę danych wstecz.
Dwukierunkowa linia danych
Dwukierunkowa ulica, dwukierunkowa linia danych łączy zalety linii danych do przodu i do tyłu. Zapewnia kompleksowy widok trasy danych, śledząc je od źródła do miejsca docelowego, a także od tej lokalizacji do punktu początkowego.
Aby określić oryginalne źródło danych, zrozumieć, w jaki sposób zostały one zmienione i zagwarantować ich jakość, spójność i kompletność przez cały czas, pomocne jest śledzenie pochodzenia danych. Dzięki informacjom w czasie rzeczywistym o jego lokalizacji i statusie to tak, jakby mieć urządzenie śledzące GPS do przechowywania danych.
Implementacja Data Lineage
Wdrażanie rodowodu danych w organizacji często obejmuje następujące fazy.
Zdefiniuj źródła danych
Należy zidentyfikować systemy i bazy danych zawierające dane, które chcesz śledzić. Aby to zrobić, musisz najpierw zidentyfikować różne źródła danych, w tym pliki, interfejsy API i usługi w chmurze.
Zbierz metadane
Kolejnym etapem jest pozyskanie szczegółowych informacji na temat danych, w tym ich lokalizacji, formatu i organizacji. Zrozumienie cech danych i sposobu ich wykorzystania jest możliwe dzięki tym metadanym.
Zidentyfikuj błędy danych
Łatwiej jest zrozumieć, w jaki sposób dane są aktualizowane i wykorzystywane w organizacji, jeśli przepływ danych jest mapowany od źródła do miejsca docelowego, w tym wszelkie przekształcenia lub przetwarzanie, które mają miejsce na trasie.
Śledź dostęp do danych
Aby zachować bezpieczeństwo i zgodność danych, śledź i rejestruj, kto ma dostęp do danych.
Przechowuj i wizualizuj rodowód
Wykorzystaj narzędzia do wizualizacji, aby przedstawić linię w celu prostego zrozumienia i analizy. Przechowuj zebrane metadane i informacje o przepływie danych w jednym repozytorium.
Wdrażaj zautomatyzowane rozwiązanie
Możesz sprawdzić, czy pochodzenie danych jest gromadzone i monitorowane za pomocą automatyzacji, co również pomoże ograniczyć liczbę błędów i zwiększyć produktywność.
Przejrzyj i zaktualizuj
Regularnie dbaj o to, aby zapisy dotyczące rodowodu były prawidłowe i aktualne oraz aktualizuj je w razie potrzeby.
Proces wdrażania może wymagać modyfikacji lub dodania do faz w zależności od unikalnych wymagań i ograniczeń każdej organizacji.
Techniki rodowodu danych
Pochodzenie oparte na wzorach
Dzięki tej metodzie pochodzenie jest przeprowadzane bez konieczności interakcji z oprogramowaniem, które wygenerowało lub przekształciło dane. Częścią tego jest ocena metadanych dla tabel, kolumn i raportów biznesowych. Bada rodowód, szukając trendów za pomocą tych metadanych.
Na przykład jest całkiem prawdopodobne, że kolumna w dwóch zestawach danych o tej samej nazwie i identycznych wartościach danych reprezentuje te same dane w różnych fazach swojego istnienia. Wykres pochodzenia danych jest następnie używany do łączenia tych dwóch kolumn.
Pochodzenie oparte na wzorach ma znaczącą zaletę polegającą na niezależności od technologii, ponieważ sprawdza tylko dane, a nie metody przetwarzania danych. Każda technologia bazodanowa, w tym Oracle, MySQL i Spark, może zostać zaimplementowana w ten sam sposób. Wadą jest to, że takie podejście nie zawsze jest precyzyjne.
Kiedy logika przetwarzania danych jest ukryta w kodzie komputerowym i nie jest łatwo widoczna w metadanych czytelnych dla człowieka, może czasami przeoczyć relacje między zestawami danych.
Pochodzenie według znakowania danych
Ta metoda opiera się na założeniu, że mechanizm transformacji taguje lub w inny sposób oznacza dane. Śledzi tag od początku do końca, aby znaleźć rodowód. Takie podejście może być skuteczne tylko wtedy, gdy masz niezawodne narzędzie do transformacji, które zarządza wszystkimi transferami danych, i znasz strukturę tagowania stosowaną przez to narzędzie.
Nawet gdyby takie narzędzie istniało, żadne dane, które zostały utworzone lub zmienione bez niego, nie mogłyby zostać poddane pochodzeniu poprzez tagowanie danych. Ogranicza się w tym zakresie do wykonywania rodowodu danych w zamkniętych systemach danych.
Samowystarczalny rodowód
Niektóre firmy mają środowisko danych, które obejmuje przechowywanie metadanych, logikę przetwarzania i zarządzanie danymi głównymi (MDM). Te ustawienia często obejmują a jezioro danych gdzie wszystkie dane są przechowywane przez cały okres jej użytkowania.
Linia rodowa może być naturalnie zapewniona przez tego rodzaju samowystarczalny system bez wymogu dodatkowych zasobów. Jednak, podobnie jak w przypadku metody znakowania danych, rodowód nie będzie świadomy niczego, co dzieje się poza tym regulowanym środowiskiem.
Data Lineage przez parsowanie
Najbardziej wyrafinowanym typem rodowodu jest ten, który automatycznie odczytuje logikę przetwarzania danych. W celu dokładnego, kompleksowego śledzenia ta metoda odtwarza logikę transformacji danych.
Ponieważ to rozwiązanie musi obejmować wszystkie języki programowania oraz narzędzi służących do konwersji i transportu danych, jego wdrożenie jest skomplikowane. Może to wykorzystywać logikę wyodrębniania-transformacji-ładowania (ETL), rozwiązania oparte na SQL i Javie, stare formaty danych, rozwiązania oparte na XML i inne techniki.
Przypadki użycia rodowodu danych
Modelowanie danych
Firmy muszą ustanowić podstawowe struktury danych, które je wspierają, aby wizualizować wiele elementów danych i powiązań między nimi wewnątrz firmy. Te połączenia są modelowane przy użyciu rodowodu danych, który pokazuje również wiele zależności obecnych w ekosystemie danych.
Ponieważ dane zmieniają się w czasie, stale pojawiają się nowe źródła danych, wymagające nowych integracji danych itp. Z tego powodu ogólne modele danych firm do zarządzania ich danymi również muszą się zmieniać, aby odzwierciedlać środowisko.
Zobowiązania
Pochodzenie danych oferuje metodę kontroli zgodności, usprawniającą zarządzanie ryzykiem i zapewniającą, że dane są przechowywane i przetwarzane zgodnie z zasadami i przepisami dotyczącymi zarządzania danymi.
Analiza wpływu
Efekty niektórych zmian biznesowych, takich jak wszelkie raporty niższego szczebla, można zobaczyć za pomocą narzędzi do ustalania pochodzenia danych. Na przykład pochodzenie danych może pomóc kierownictwu w określeniu, na ile pulpitów nawigacyjnych wpłynie zmiana nazwy, a co za tym idzie, ile osób uzyska dostęp do tych raportów.
Migracja danych
Organizacje stosują migrację danych, aby zrozumieć, gdzie się znajdują i jak długo tam są, zanim przeniosą je do nowego systemu przechowywania lub wdrożą nowe oprogramowanie.
Pochodzenie danych pomaga zespołom przygotować się do aktualizacji systemu lub migracji, dając im przegląd tego, w jaki sposób dane zostały przeniesione w całej organizacji. Przyspiesza to ogólnie transfer do nowego środowiska pamięci masowej.
Dodatkowo daje zespołom szansę na uporządkowanie systemu danych poprzez archiwizację lub usunięcie nieaktualnych lub bezużytecznych danych. W ten sposób system danych będzie ogólnie działał lepiej i będzie wymagał mniej zarządzania danymi.
Wyzwania związane z wdrażaniem linii danych
- Bezpieczeństwo danych: bezpieczeństwo danych jest głównym problemem podczas budowania rodowodu danych. Aby śledzić podróż danych od punktu początkowego do miejsca docelowego, należy zapewnić dostęp do danych wrażliwych, a dane te muszą być chronione przed nieautoryzowanym dostępem i naruszeniami.
- Brak standaryzacji: Jedną z głównych barier w przyjmowaniu rodowodu danych jest brak standardów. Ponieważ wiele platform, aplikacji i systemów wykorzystuje unikalne metody śledzenia i rejestrowania pochodzenia danych, stworzenie spójnego obrazu podróży danych może być trudne.
- Silosy danych: Silosy danych to kolejny problem, który pojawia się podczas wdrażania rodowodu danych. Gdy dane są rozproszone w kilku aplikacjach i systemach, śledzenie ich podróży z jednej do drugiej może być trudne. Może to prowadzić do niedokładnego lub niekompletnego pochodzenia danych.
Wnioski
Podsumowując, pochodzenie danych jest istotną częścią każdego przedsiębiorstwa opartego na danych. Oferuje kompleksową perspektywę ścieżki danych od punktu początkowego do punktu końcowego, gwarantując ich dokładność, kompletność i spójność.
Oczekuje się, że w przyszłości nastąpi wzrost automatyzacji i standaryzacji linii danych, co ułatwi organizacjom wdrażanie i konserwację. Ostatecznie nie można podkreślić znaczenia rodowodu danych.
Daje firmom narzędzia potrzebne do dokonywania mądrych wyborów, wydajniejszego prowadzenia działalności i osiągania sukcesów.





Dodaj komentarz