Det er en avgjørende og ønskelig oppgave innen datasyn og grafikk å produsere kreative portrettfilmer av høyeste kaliber.
Selv om det har blitt foreslått flere effektive modeller for portrettbildevisning basert på den potente StyleGAN, har disse bildeorienterte teknikkene klare ulemper når de brukes med videoer, som den faste rammestørrelsen, kravet til ansiktsjustering, fraværet av ikke-ansiktsdetaljer , og tidsmessig inkonsekvens.
Et revolusjonerende VToonify-rammeverk brukes til å takle den vanskelige kontrollerte høyoppløselige portrettvideostiloverføringen.
Vi vil undersøke den nyeste studien om VToonify i denne artikkelen, inkludert funksjonalitet, ulemper og andre faktorer.
Hva er Vtoonify?
VToonify-rammeverket gir mulighet for tilpassbar høyoppløselig overføring av portrettvideostil.
VToonify bruker StyleGANs mellom- og høyoppløselige lag for å lage kunstneriske portretter av høy kvalitet basert på multi-skala innholdsegenskaper hentet av en koder for å beholde bildedetaljer.
Den resulterende fullt konvolusjonsarkitekturen tar ikke-justerte ansikter i filmer med variabel størrelse som input, noe som resulterer i hele ansiktsområder med realistiske bevegelser i utdataene.

Dette rammeverket er kompatibelt med nåværende StyleGAN-baserte bildevisningsmodeller, slik at de kan utvides til videovisning, og arver attraktive egenskaper som justerbar farge- og intensitetstilpasning.
Dette studere introduserer to eksemplarer av VToonify basert på Toonify og DualStyleGAN for henholdsvis samlingsbasert og eksemplarbasert portrettvideostiloverføring.
Omfattende eksperimentelle funn viser at det foreslåtte VToonify-rammeverket overgår eksisterende tilnærminger når det gjelder å lage høykvalitets, tidsmessig sammenhengende kunstneriske portrettfilmer med variable stilparametere.
Forskere gir Google Colab notatbok, slik at du kan skitne hendene på den.
Hvordan virker det?
For å oppnå justerbar høyoppløselig portrettvideostiloverføring, kombinerer VToonify fordelene med bildeoversettelsesrammeverket med det StyleGAN-baserte rammeverket.
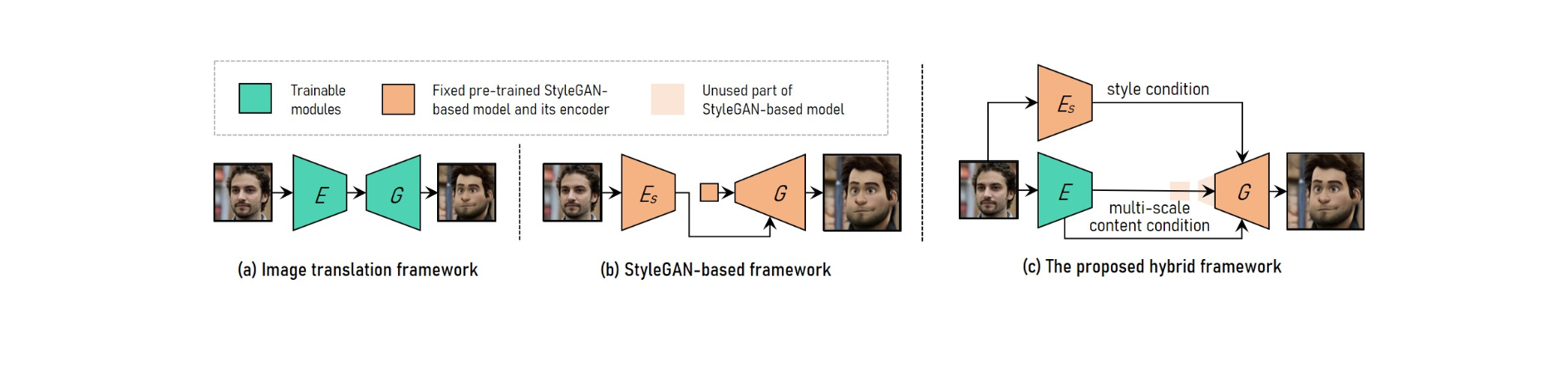
For å imøtekomme varierende inndatastørrelser, bruker bildeoversettelsessystemet fullt konvolusjonelle nettverk. Trening fra bunnen av gjør derimot høyoppløselig og kontrollert stiloverføring umulig.
Den forhåndstrente StyleGAN-modellen brukes i det StyleGAN-baserte rammeverket for høyoppløselig og kontrollert stiloverføring, selv om den er begrenset til fast bildestørrelse og detaljtap.
StyleGAN er modifisert i det hybride rammeverket ved å slette inndatafunksjonen med fast størrelse og lag med lav oppløsning, noe som resulterer i en fullstendig konvolusjonell koder-generatorarkitektur som ligner på rammeverket for bildeoversettelse.
For å opprettholde rammedetaljer, tren en koder til å trekke ut multi-skala innholdskarakteristikker for inngangsrammen som et ekstra innholdskrav til generatoren. Vtoonify arver StyleGAN-modellens stilkontrollfleksibilitet ved å sette den inn i generatoren for å destillere både data og modell.
Begrensninger for StyleGAN og foreslåtte Vtoonify
Kunstneriske portretter er vanlige i våre daglige liv så vel som i kreative virksomheter som kunst, sosiale medier avatarer, filmer, underholdningsreklame og så videre.
Med utviklingen av dyp læring teknologi, er det nå mulig å lage kunstneriske portretter av høy kvalitet fra virkelige ansiktsbilder ved hjelp av automatisert portrettstiloverføring.
Det finnes en rekke vellykkede måter laget for bildebasert stiloverføring, hvorav mange er lett tilgjengelige for nybegynnere i form av mobilapplikasjoner. Videomateriale har raskt blitt en bærebjelke i våre sosiale medier i løpet av de siste årene.
Fremveksten av sosiale medier og flyktige filmer har økt etterspørselen etter nyskapende videoredigering, for eksempel overføring av portrettvideostiler, for å generere vellykkede og interessante videoer.
Eksisterende bildeorienterte teknikker har betydelige ulemper når de brukes på filmer, og begrenser deres nytte i automatisert portrettvideostilisering.
StyleGAN er en vanlig ryggrad for å utvikle en portrettbildestiloverføringsmodell på grunn av dens kapasitet til å lage ansikter av høy kvalitet med justerbar stilstyring.
Et StyleGAN-basert system (også kjent som bildevisning) koder et ekte ansikt inn i StyleGANs latente rom og bruker deretter den resulterende stilkoden til en annen StyleGAN finjustert på det kunstneriske portrettdatasettet for å lage en stilisert versjon.
StyleGAN lager bilder med justerte ansikter og i en fast størrelse, som ikke favoriserer dynamiske ansikter i opptak fra den virkelige verden. Ansiktsbeskjæring og justering i videoen resulterer noen ganger i et delvis ansikt og vanskelige bevegelser. Forskere kaller dette problemet for StyleGANs 'restriksjon for faste avlinger.'
For ujusterte ansikter har StyleGAN3 blitt foreslått; den støtter imidlertid bare en angitt bildestørrelse.
Videre oppdaget en fersk studie at koding av ujusterte ansikter er mer utfordrende enn justerte ansikter. Feil ansiktskoding er skadelig for overføring av portrettstil, noe som resulterer i problemer som identitetsendring og manglende komponenter i de rekonstruerte og stiliserte rammene.
Som diskutert må en effektiv teknikk for overføring av portrettvideostil håndtere følgende problemer:
- For å bevare realistiske bevegelser, må tilnærmingen være i stand til å håndtere ujusterte ansikter og varierte videostørrelser. En stor videostørrelse, eller en vid visningsvinkel, kan fange opp mer informasjon samtidig som ansiktet ikke beveger seg ut av bildet.
- For å konkurrere med dagens ofte brukte HD-dingser, er høyoppløselig video nødvendig.
- Fleksibel stilkontroll bør tilbys slik at brukere kan endre og velge valg når de utvikler et realistisk brukerinteraksjonssystem.
For det formålet foreslår forskere VToonify, et nytt hybridrammeverk for videotonifisering. For å overvinne den faste avlingsbegrensningen, studerer forskere først oversettelsesekvivarians i StyleGAN.
VToonify kombinerer fordelene med den StyleGAN-baserte arkitekturen og rammeverket for bildeoversettelse for å oppnå justerbar høyoppløselig portrettvideostiloverføring.
Følgende er de viktigste bidragene:
- Forskere undersøker StyleGANs faste avlingsbegrensning og foreslår en løsning basert på oversettelsesekvivarians.
- Forskere presenterer et unikt fullstendig konvolusjonelt VToonify-rammeverk for kontrollert høyoppløselig portrettvideostiloverføring som støtter ujusterte ansikter og forskjellige videostørrelser.
- Forskere konstruerer VToonify på ryggradene til Toonify og DualStyleGAN og kondenserer ryggradene når det gjelder både data og modell for å muliggjøre samlingsbasert og eksemplarbasert portrettvideostiloverføring.
Sammenligning av Vtoonify med andre toppmoderne modeller
Toonify
Den fungerer som grunnlaget for samlingsbasert stiloverføring på justerte ansikter ved hjelp av StyleGAN. For å hente stilkodene må forskere justere ansikter og beskjære 256256 bilder for PSP. Toonify brukes til å generere et stilisert resultat med 1024*1024 stilkoder.
Til slutt justerer de resultatet i videoen til den opprinnelige plasseringen. Det ustiliserte området er satt til svart.

DualStyleGAN
Det er en ryggrad for eksempelbasert stiloverføring basert på StyleGAN. De bruker de samme datafor- og etterbehandlingsteknikkene som Toonify.
Pix2pixHD
Det er en bilde-til-bilde-oversettelsesmodell som vanligvis brukes til å kondensere ferdigtrente modeller for høyoppløselig redigering. Den trenes opp ved hjelp av sammenkoblede data.
Forskere bruker pix2pixHD som ekstra instanskartinnganger siden den bruker utvunnet parsingkart.
First Order Motion
FOM er en typisk bildeanimasjonsmodell. Den ble trent på 256256 bilder og fungerer dårlig med andre bildestørrelser. Som en konsekvens skalerer forskere først videobildene til 256*256 for FOM til animasjon og endrer deretter størrelsen på resultatene til den opprinnelige størrelsen.
For en rettferdig sammenligning bruker FOM den første stiliserte rammen av sin tilnærming som sitt referansestilbilde.
DaGAN
Det er en 3D-ansiktsanimasjonsmodell. De bruker samme dataforberedelse og etterbehandlingsmetoder som FOM.

Fordeler
- Det kan brukes i kunst, sosiale medier avatarer, filmer, underholdningsreklame og så videre.
- Vtoonify kan også brukes i metaversen.
Begrensninger
- Denne metodikken trekker ut både dataene og modellen fra de StyleGAN-baserte ryggradene, noe som resulterer i data- og modellskjevhet.
- Artefaktene er hovedsakelig forårsaket av størrelsesforskjeller mellom den stiliserte ansiktsregionen og de andre seksjonene.
- Denne strategien er mindre vellykket når du arbeider med ting i ansiktsregionen.
konklusjonen
Til slutt, VToonify er et rammeverk for stilkontrollert høyoppløselig videotonifisering.
Dette rammeverket oppnår god ytelse ved håndtering av videoer og muliggjør bred kontroll over strukturstilen, fargestilen og stilgraden ved å kondensere StyleGAN-baserte bildetoneringsmodeller når det gjelder både deres syntetiske data og nettverksstrukturer.





Legg igjen en kommentar