Innholdsfortegnelse[Gjemme seg][Forestilling]
Fremtiden er her. Og i fremtiden forstår maskiner verden rundt seg på samme måte som folk gjør. Datamaskiner kan kjøre biler, diagnostisere sykdommer og nøyaktig forutsi fremtiden.
Dette kan virke som science fiction, men dyplæringsmodeller gjør det til en realitet.
Disse sofistikerte algoritmene avslører hemmelighetene til kunstig intelligens, slik at datamaskiner kan lære seg selv og utvikle seg. I dette innlegget skal vi fordype oss i riket av dyplæringsmodeller.
Og vi vil undersøke det enorme potensialet de har for å revolusjonere livene våre. Forbered deg på å lære om banebrytende teknologi som endrer menneskehetens fremtid.

Hva er egentlig dyplæringsmodeller?
Har du noen gang spilt et spill der du må identifisere forskjellene mellom to bilder?
Det er morsomt, men det kan også være tøft, ikke sant? Tenk deg å kunne lære en datamaskin å spille det spillet og vinne hver gang. Dyplæringsmodeller oppnår nettopp det!
Dyplæringsmodeller ligner på supersmarte maskiner som kan undersøke et stort antall bilder og finne ut hva de har til felles. De oppnår dette ved å demontere bildene og studere hvert enkelt individuelt.
Deretter bruker de det de har lært for å identifisere mønstre og lage spådommer om ferske bilder de aldri har sett før.

Dyplæringsmodeller er kunstige nevrale nettverk som kan lære og trekke ut kompliserte mønstre og egenskaper fra massive datasett. Disse modellene består av flere lag med koblede noder, eller nevroner, som analyserer og endrer innkommende data for å generere en utgang.
Dyplæringsmodeller er spesielt godt egnet for jobber som krever stor nøyaktighet og presisjon, som bildeidentifikasjon, talegjenkjenning, naturlig språkbehandling og robotikk.
De har blitt brukt i alt fra selvkjørende biler til medisinsk diagnostikk, anbefalingssystemer og prediktiv analyse.
Her er en forenklet versjon av visualiseringen for å illustrere dataflyt i en dyp læringsmodell.
Inndataene strømmer inn i modellens inputlag, som deretter sender dataene gjennom en rekke skjulte lag før de gir en utgangsprediksjon.
Hvert skjult lag utfører en serie matematiske operasjoner på inndataene før de overføres til neste lag, som gir den endelige prediksjonen.
La oss nå se hva som er dyplæringsmodeller og hvordan vi kan bruke dem i livet vårt.
1. Convolutional Neural Networks (CNN)
CNN-er er en dyp læringsmodell som har forvandlet området med datasyn. CNN-er brukes til å klassifisere bilder, gjenkjenne objekter og segmentere bilder. Strukturen og funksjonen til den menneskelige visuelle cortex informerte utformingen av CNN-er.
Hvordan fungerer de?
Et CNN består av en rekke konvolusjonslag, sammenslåingslag og fullt koblede lag. Inndata er et bilde, og utdata er en prediksjon av klasseetiketten til bildet.
En CNNs konvolusjonslag bygger et funksjonskart ved å utføre et punktprodukt mellom inngangsbildet og et sett med filtre. Sammenslåingslagene reduserer størrelsen på funksjonskartet ved å nedsample det.
Til slutt brukes funksjonskartet av de fullt tilkoblede lagene for å forutsi bildets klasseetikett.

Hvorfor er CNN-er viktige?
CNN-er er viktige fordi de kan lære å oppdage mønstre og egenskaper i bilder som folk synes er vanskelig å legge merke til. CNN-er kan læres å gjenkjenne egenskaper som kanter, hjørner og teksturer ved å bruke store datasett. Etter å ha lært disse egenskapene, kan en CNN bruke dem til å identifisere objekter i ferske bilder. CNN-er har vist banebrytende ytelse på en rekke bildeidentifikasjonsapplikasjoner.
Hvor bruker vi CNN-er
Helsevesenet, bilindustrien og detaljhandelen er bare noen få sektorer som bruker CNN. I helsesektoren kan de være gunstige for sykdomsdiagnostisering, utvikling av medisiner og medisinsk bildeanalyse.
I bilsektoren hjelper de med kjørefeltregistrering, objektdeteksjonog autonom kjøring. De er også mye brukt i detaljhandelen for visuelt søk, bildebasert produktanbefaling og lagerkontroll.
For eksempel; Google bruker CNN i en rekke applikasjoner, inkludert Google-linse, et godt likt bildeidentifikasjonsverktøy. Programmet bruker CNN-er for å vurdere fotografier og gi brukere informasjon.
Google Lens, for eksempel, kan gjenkjenne ting i et bilde og tilby detaljer om dem, for eksempel typen blomst.

Det kan også oversette teksten som er hentet fra et bilde til flere språk. Google Lens er i stand til å gi forbrukere nyttig informasjon på grunn av CNNs bistand til nøyaktig å identifisere varer og trekke ut egenskaper fra bilder.
2. Long Short-Term Memory (LSTM) nettverk
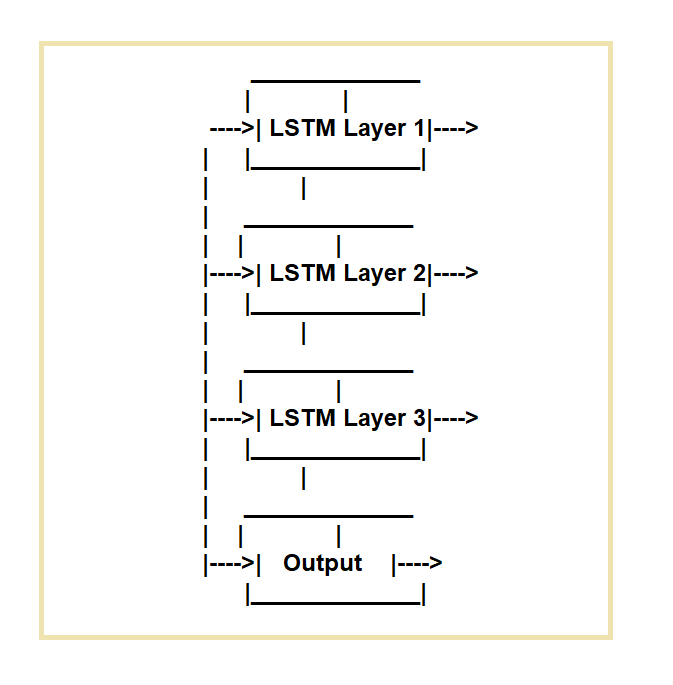
Long Short-Term Memory (LSTM) nettverk er opprettet for å løse manglene ved vanlige tilbakevendende nevrale nettverk (RNN). LSTM-nettverk er ideelle for oppgaver som krever behandling av datasekvenser over tid.
De fungerer ved å bruke en spesifikk minnecelle og tre portmekanismer.
De regulerer strømmen av informasjon inn og ut av cellen. Inngangsporten, glemporten og utgangsporten er de tre portene.
Inngangsporten regulerer strømmen av data inn i minnecellen, glemporten regulerer sletting av data fra cellen, og utgangsporten regulerer strømmen av data ut av cellen.
Hva er deres betydning?
LSTM-nettverk er nyttige fordi de med hell kan representere og forutsi datasekvenser med langsiktige relasjoner. De kan registrere og beholde informasjon om tidligere inndata, slik at de kan lage mer nøyaktige spådommer om fremtidige inndata.
Talegjenkjenning, håndskriftgjenkjenning, naturlig språkbehandling og bildeteksting er bare noen få av programmene som har benyttet seg av LSTM-nettverk.
Hvor bruker vi LSTM-nettverk?
Mange programvare- og teknologiapplikasjoner bruker LSTM-nettverk, inkludert talegjenkjenningssystemer, prosesseringsverktøy for naturlige språk som sentiment analyse, maskinoversettelsessystemer og tekst- og bildegenereringssystemer.
De har også blitt brukt til å lage selvkjørende biler og roboter, samt i finansbransjen for å oppdage svindel og forutse aksjemarked bevegelser.
3. Generative Adversarial Networks (GAN)
GAN-er er en dyp læring teknikk som brukes til å generere nye dataprøver som ligner på et gitt datasett. GAN-er består av to nevrale nettverk: en som lærer å produsere nye prøver og en som lærer å skille mellom ekte og genererte prøver.
I en lignende tilnærming trenes disse to nettverkene sammen til generatoren kan generere prøver som ikke kan skilles fra faktiske.
Hvorfor bruker vi GAN-er
GAN-er er betydelige på grunn av deres kapasitet til å produsere høy kvalitet syntetiske data som kan brukes til en rekke applikasjoner, inkludert bilde- og videoproduksjon, tekstgenerering og til og med musikkgenerering.
GAN-er har også blitt brukt til dataforsterkning, som er genereringen av syntetiske data å supplere virkelige data og forbedre ytelsen til maskinlæringsmodeller.
Videre, ved å lage syntetiske data som kan brukes til å trene modeller og imitere forsøk, har GAN-er potensial til å transformere sektorer som medisin og medikamentutvikling.

Anvendelser av GAN-er
GAN-er kan supplere datasett, lage nye bilder eller filmer, og til og med generere syntetiske data for vitenskapelige simuleringer. Videre har GAN-er potensial til å bli ansatt i en rekke applikasjoner, alt fra underholdning til medisinsk.
aldre og videoer. NVIDIAs StyleGAN2 har for eksempel blitt brukt til å lage høykvalitetsfotografier av kjendiser og kunstverk.
4. Deep Belief Networks (DBN)
Deep Belief Networks (DBNs) er kunstig intelligens systemer som kan lære å oppdage mønstre i data. De oppnår dette ved å segmentere dataene i mindre og mindre biter, og få en mer grundig forståelse av dem på hvert nivå.
DBN-er kan lære av data uten å bli informert om hva det er (dette blir referert til som "uovervåket læring"). Dette gjør dem ekstremt verdifulle for å oppdage mønstre i data som en person vil finne vanskelig eller umulig å skjelne.
Hva gjør DBN-er betydelige?
DBN-er er betydelige på grunn av deres evne til å lære hierarkiske datarepresentasjoner. Disse representasjonene kan brukes til en rekke bruksområder som klassifisering, avviksdeteksjon og dimensjonalitetsreduksjon.
Kapasiteten til DBN-er til å gjennomføre uovervåket foropplæring, som kan øke ytelsen til dyplæringsmodeller med minimalt med merkede data, er en betydelig fordel.

Hva er applikasjonene til DBN-er?
En av de viktigste applikasjonene er objektdeteksjon, der DBN-er brukes til å gjenkjenne visse typer ting som fly, fugler og mennesker. De brukes også til bildegenerering og klassifisering, bevegelsesdeteksjon i filmer og naturlig språkforståelse for stemmebehandling.
Videre er DBN-er ofte brukt i datasett for å vurdere menneskelige stillinger. DBN-er er et flott verktøy for en rekke bransjer, inkludert helsevesen og bank, og teknologi.
5. Deep Reinforcement Learning Networks (DRL)
Dyp Forsterkningslæring Nettverk (DRL) integrerer dype nevrale nettverk med forsterkende læringsteknikker for å tillate agenter å lære i et komplisert miljø via prøving og feiling.
DRL-er brukes til å lære agenter hvordan de kan optimalisere et belønningssignal ved å samhandle med omgivelsene og lære av feilene deres.
Hva gjør dem bemerkelsesverdige?
De har blitt brukt effektivt i en rekke applikasjoner, inkludert spill, robotikk og autonom kjøring. DRL-er er viktige fordi de kan lære direkte fra rå sensoriske input, slik at agenter kan ta avgjørelser basert på deres interaksjoner med miljøet.
Viktige applikasjoner
DRL-er brukes i virkelige omstendigheter fordi de kan håndtere vanskelige problemer.
DRL-er har blitt inkludert i flere fremtredende programvare- og teknologiplattformer, inkludert OpenAI's Gym, Unitys ML-agenter, og Googles DeepMind Lab. AlphaGo, bygget av Google DeepMind, for eksempel, ansetter DRL for å spille brettspillet Go på verdensmesternivå.

En annen bruk av DRL er i robotikk, der den brukes til å kontrollere bevegelsene til robotarmer for å utføre oppgaver som å gripe ting eller stable blokker. DRL-er har mange bruksområder og er et nyttig verktøy for trene agenter til å lære og ta avgjørelser i kompliserte omgivelser.
6. Autoenkodere
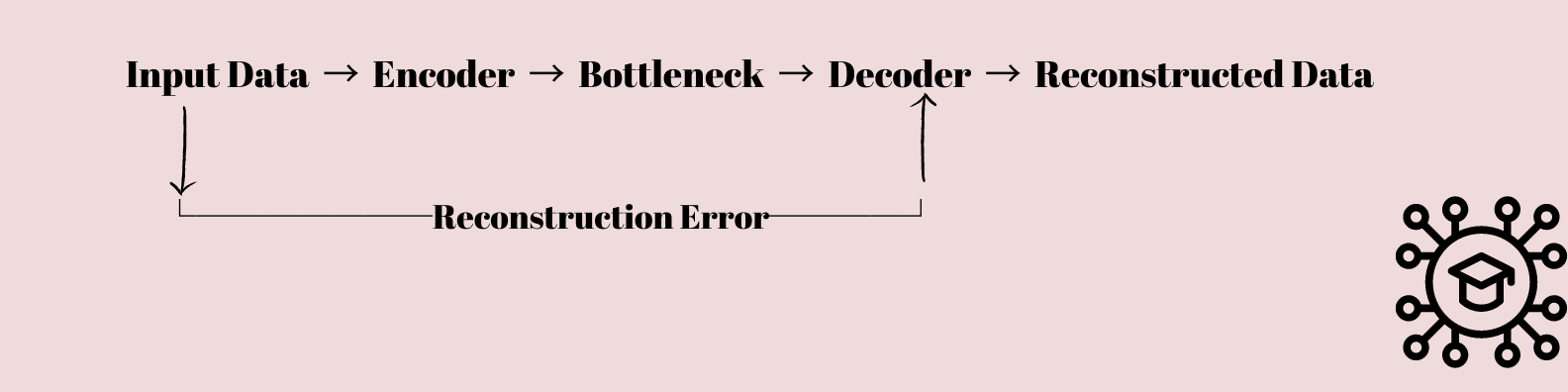
Autoenkodere er en interessant type nevrale nettverket som har fanget interessen til både forskere og dataforskere. De er grunnleggende designet for å lære å komprimere og gjenopprette data.
Inndataene mates gjennom en rekke lag som gradvis senker dimensjonaliteten til dataene til de komprimeres til et flaskehalslag med færre noder enn input- og utgangslagene.
Denne komprimerte representasjonen brukes deretter til å gjenskape de originale inndataene ved å bruke en sekvens av lag som gradvis hever dataens dimensjonalitet tilbake til sin opprinnelige form.
Hvorfor er det viktig?
Autoenkodere er en avgjørende komponent i dyp læring fordi de gjør funksjonsutvinning og datareduksjon mulig.
De er i stand til å identifisere nøkkelelementene i de innkommende dataene og oversette dem til en komprimert form som deretter kan brukes på andre oppgaver som klassifisering, gruppering eller opprettelse av nye data.
Hvor bruker vi autoenkodere?
Anomalideteksjon, naturlig språkbehandling og datasyn er bare noen av disiplinene der autoenkodere brukes. Autoenkodere kan for eksempel brukes til bildekomprimering, bildedenoising og bildesyntese i datasyn.
Vi kan bruke autokodere i oppgaver som tekstoppretting, tekstkategorisering og tekstoppsummering i naturlig språkbehandling. Den kan identifisere uregelmessig aktivitet i data som avviker fra normen ved identifisering av uregelmessigheter.
7. Kapselnettverk
Capsule Networks er en ny dyplæringsarkitektur som ble utviklet som en erstatning for Convolutional Neural Networks (CNN).
Kapselnettverk er basert på ideen om å gruppere hjerneenheter kalt kapsler som er ansvarlige for å gjenkjenne eksistensen av et bestemt element i et bilde og kode dets attributter, som orientering og posisjon, inn i utgangsvektorene deres. Capsule Networks kan derfor håndtere romlige interaksjoner og perspektivsvingninger bedre enn CNN-er.
Hvorfor velger vi Capsule Networks fremfor CNN?
Capsule Networks er nyttige fordi de overvinner CNNs vanskeligheter med å fange hierarkiske forhold mellom elementer i et bilde. CNN-er kan gjenkjenne ting av forskjellige størrelser, men sliter med å forstå hvordan disse elementene kobles til hverandre.
Capsule Networks, på den annen side, kan lære å gjenkjenne ting og delene deres, så vel som hvordan de er plassert romlig i et bilde, noe som gjør dem til en levedyktig konkurrent for datasynsapplikasjoner.
Bruksområder
Capsule Networks har allerede vist lovende resultater i en rekke applikasjoner, inkludert bildeklassifisering, objektidentifikasjon og bildesegmentering.
De har blitt brukt til å skille ting i medisinske bilder, gjenkjenne mennesker i filmer og til og med lage 3D-modeller av 2D-bilder.
For å øke ytelsen har Capsule Networks blitt kombinert med andre dyplæringsarkitekturer som Generative Adversarial Networks (GANs) og Variational Autoencoders (VAEs). Capsule Networks er spådd å spille en stadig viktigere rolle i å forbedre datasynsteknologier etter hvert som vitenskapen om dyp læring utvikler seg.
For eksempel; Nibabel er et velkjent Python-verktøy for lesing og skriving av nevroimaging filtyper. For bildesegmentering bruker den Capsule Networks.
8. Oppmerksomhetsbaserte modeller
Dyplæringsmodeller kjent som oppmerksomhetsbaserte modeller, også kjent som oppmerksomhetsmekanismer, forsøker å øke nøyaktigheten av maskinlæringsmodeller. Disse modellene fungerer ved å konsentrere seg om visse funksjoner ved innkommende data, noe som resulterer i mer effektiv og effektiv behandling.
I naturlig språkbehandlingsoppgaver som maskinoversettelse og sentimentanalyse har oppmerksomhetsmetoder vist seg å være ganske vellykkede.
Hva er deres betydning?
Oppmerksomhetsbaserte modeller er nyttige fordi de muliggjør mer effektiv og effektiv behandling av kompliserte data.
Tradisjonelle nevrale nettverk vurdere alle inndata som like viktige, noe som resulterer i langsommere behandling og redusert nøyaktighet. Oppmerksomhetsprosesser konsentrerer seg om viktige aspekter ved inngangsdata, noe som muliggjør raskere og mer nøyaktige spådommer.

Bruksområder
Innenfor kunstig intelligens har oppmerksomhetsmekanismer et bredt spekter av bruksområder, inkludert naturlig språkbehandling, bilde- og lydgjenkjenning, og til og med førerløse kjøretøy.
Oppmerksomhetsmetoder kan for eksempel brukes til å forbedre maskinoversettelse i naturlig språkbehandling ved å la systemet fokusere på bestemte ord eller setninger som er essensielle for konteksten.
Oppmerksomhetsmetoder i autonome biler kan brukes for å hjelpe systemet med å fokusere på visse elementer eller utfordringer i omgivelsene.
9. Transformatornettverk
Transformatornettverk er dyplæringsmodeller som undersøker og produserer datasekvenser. De fungerer ved å behandle inngangssekvensen ett element om gangen og produsere en utgangssekvens med samme eller forskjellige lengder.
Transformatornettverk, i motsetning til standard sekvens-til-sekvens-modeller, behandler ikke sekvenser ved å bruke tilbakevendende nevrale nettverk (RNN). I stedet bruker de selvoppmerksomhetsprosesser for å lære koblingene mellom sekvensens stykker.
Hva er viktigheten av transformatornettverk?
Transformatornettverk har vokst i popularitet de siste årene som et resultat av deres bedre ytelse i naturlig språkbehandlingsjobber.
De er spesielt godt egnet for tekstskapende oppgaver som språkoversettelse, tekstoppsummering og samtaleproduksjon.
Transformatornettverk er betydelig mer effektive beregningsmessig enn RNN-baserte modeller, noe som gjør dem til et foretrukket valg for store applikasjoner.

Hvor finner du transformatornettverk?
Transformatornettverk er mye brukt i et bredt spekter av applikasjoner, spesielt naturlig språkbehandling.
GPT-serien (Generative Pre-trained Transformer) er en fremtredende transformatorbasert modell som har blitt brukt til oppgaver som språkoversettelse, tekstoppsummering og generering av chatbot.
BERT (Bidirectional Encoder Representations from Transformers) er en annen vanlig transformatorbasert modell som har blitt brukt for naturlig språkforståelsesapplikasjoner som svar på spørsmål og sentimentanalyse.
Begge GPT og BERT ble opprettet med PyTorch, et åpen kildekode dyplæringsrammeverk som har vært populært for utvikling av transformatorbaserte modeller.
10. Begrensede Boltzmann-maskiner (RBM)
Begrensede Boltzmann-maskiner (RBM) er en slags uovervåket nevrale nettverk som lærer på en generativ måte. På grunn av deres evne til å lære og trekke ut essensielle egenskaper fra høydimensjonale data, har de vært mye brukt innen maskinlæring og dyp læring.
RBM-er består av to lag, synlige og skjulte, hvor hvert lag består av en gruppe nevroner forbundet med vektede kanter. RBMer er utformet for å lære en sannsynlighetsfordeling som beskriver inndataene.
Hva er begrensede Boltzmann-maskiner?
RBMer bruker en generativ læringsstrategi. I RBMer reflekterer det synlige laget inngangsdataene, mens det nedgravde laget koder for inngangsdataenes egenskaper. Vektene til de synlige og skjulte lagene viser styrken til koblingen deres.
RBM justerer vektene og skjevhetene mellom lagene under trening ved hjelp av en teknikk kjent som kontrastiv divergens. Kontrastiv divergens er en uovervåket læringsstrategi som maksimerer modellens prediksjonssannsynlighet.
Hva er betydningen av begrensede Boltzmann-maskiner?
RBMer er betydelige i maskinlæring og dyp læring fordi de kan lære og trekke ut relevante egenskaper fra store mengder data.
De er svært effektive for bilde- og talegjenkjenning, og de har blitt brukt i en rekke applikasjoner som anbefalingssystemer, anomalideteksjon og dimensjonalitetsreduksjon. RBM-er kan finne mønstre i enorme datasett, noe som resulterer i overlegne spådommer og innsikt.

Hvor kan begrensede Boltzmann-maskiner brukes?
Applikasjoner for RBMer inkluderer dimensjonalitetsreduksjon, anomalideteksjon og anbefalingssystemer. RBMer er spesielt nyttige for sentimentanalyse og temamodellering i sammenheng med naturlig språkbehandling.
Deep belief-nettverk, et slags nevralt nettverk som brukes til stemme- og bildegjenkjenning, bruker også RBM-er. The Deep Belief Network Toolbox, tensorflowog Theano er noen spesielle eksempler på programvare eller teknologi som bruker RBMer.
Wrap Up
Deep Learning-modeller blir mer og mer avgjørende i en rekke bransjer, inkludert talegjenkjenning, naturlig språkbehandling og datasyn.
Convolutional Neural Networks (CNNs) og Recurrent Neural Networks (RNNs) har vist seg mest lovende og er mye brukt i mange applikasjoner, men alle Deep Learning-modeller har sine fordeler og ulemper.
Imidlertid ser forskere fortsatt på begrensede Boltzmann-maskiner (RBM) og andre varianter av Deep Learning-modeller fordi de også har spesielle fordeler.
Nye og kreative modeller forventes å bli opprettet ettersom området for dyp læring fortsetter å utvikle seg for å håndtere vanskeligere problemer





Legg igjen en kommentar