Innholdsfortegnelse[Gjemme seg][Forestilling]
Bedrifter fanger opp mer data enn noen gang ettersom de i økende grad stoler på dem for å informere viktige forretningsbeslutninger, forbedre produkttilbud og gi bedre kundeservice.
Med mengden data som opprettes i en eksponentiell hastighet, tilbyr skyen flere fordeler for databehandling og analyse, inkludert skalerbarhet, pålitelighet og tilgjengelighet.
I skyøkosystemet er det også flere verktøy og teknologier for databehandling og analyse. De to typene store datalagringsstrukturer som brukes oftest er datavarehus og datainnsjøer.
Selv om det er mindre attraktivt å bruke en datainnsjø, siden du ikke kan spørre etter modellen og dataene mens de fortsatt er relevante, er det bortkastet å bruke et datavarehus for strømming av datalagring.

Whvilken type skyarkitektur velger vi?
Bør vi vurdere nyere konsepter for datainnsjøhuset, eller bør vi nøye oss med lagerets begrensninger eller innsjøens begrensninger?
En ny datalagringsarkitektur kalt et "data lakehouse" kombinerer tilpasningsevnen til datainnsjøer med datahåndteringen til datavarehus.
Å forstå de ulike lagringsmetodene for stordata er avgjørende for å bygge en pålitelig datalagringspipeline for business intelligence (BI), dataanalyse og maskinlæring (ML) arbeidsbelastning, avhengig av bedriftens krav.
I dette innlegget vil vi se nærmere på Data Warehouse, Data Lake og Data Lakehouse, med fordeler, begrensninger samt fordeler og ulemper ved dem. La oss begynne.
Hva er datavarehus?
Et datavarehus er et sentralisert datalager som brukes av en organisasjon til å holde enorme mengder data fra mange kilder. Et datavarehus fungerer som en organisasjons eneste kilde til "datasannhet" og er avgjørende for rapportering og forretningsanalyse.
Vanligvis kombinerer datavarehus relasjonsdatasett fra flere kilder, for eksempel applikasjons-, forretnings- og transaksjonsdata, for å lagre historiske data. Før de lastes inn i lagersystemet, transformeres og renses data i datavarehus slik at de kan brukes som en enkelt kilde til datasannhet.
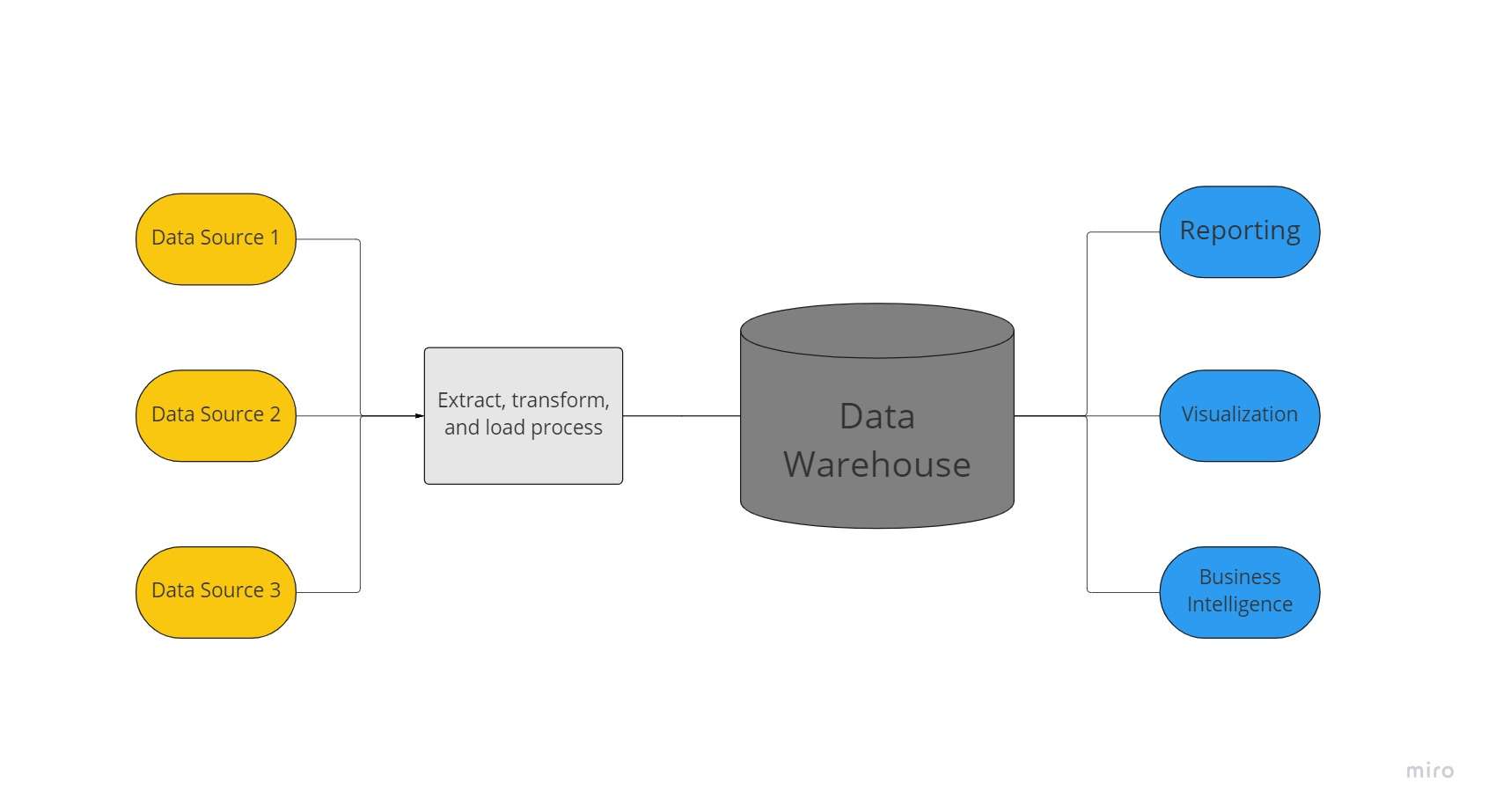
På grunn av deres kapasitet til raskt å tilby forretningsinnsikt fra alle områder av selskapet, investerer bedrifter i datavarehus. Med bruk av BI-verktøy, SQL-klienter og andre mindre sofistikerte (dvs. ikke-datavitenskapelige) analyseløsninger, forretningsanalytikere, dataingeniører og beslutningstakere kan få tilgang til data fra datavarehus.
Det er dyrt å vedlikeholde et lager med stadig økende datamengde, og et datavarehus kan ikke håndtere rå eller ustrukturert data. I tillegg er det ikke det ideelle alternativet for sofistikerte dataanalyseteknikker som maskinlæring eller prediktiv modellering.
Et datavarehus gir derfor raskere spørringssvar og data av høyere kvalitet. Google Big Query, Amazon Redshift, Azure SQL Data warehouse og Snowflake er skytjenester som er tilgjengelige for datavarehus.
Fordeler med Data Warehouse
- Øke effektiviteten og hastigheten til arbeidsbelastninger for forretningsintelligens og dataanalyse: Datavarehus forkorter tiden som trengs for dataforberedelse og analyse. De kan enkelt koble til dataanalyse- og business intelligence-verktøy siden dataene fra datavarehuset er pålitelige og konsistente. I tillegg sparer datavarehus tiden som trengs for datainnsamling og gir teamene muligheten til å bruke data til rapporter, dashbord og andre analysekrav.
- Øke konsistensen, kvaliteten og standardiseringen av data: Organisasjoner samler inn data fra en rekke kilder, inkludert bruker-, salgs- og transaksjonsdata. Firmaet kan stole på dataene for forretningskrav fordi datavarehus kompilerer bedriftsdata til et enhetlig, standardisert format som kan fungere som en enkelt kilde til datasannhet.
- Bedre beslutningstaking generelt: Datavarehus letter bedre beslutningstaking ved å tilby en sentralisert butikk for både nyere og gamle data. Ved å behandle data i datavarehus for presis innsikt, kan beslutningstakere vurdere risikoer, forstå kundens ønsker og forbedre varer og tjenester.
- Gir bedre forretningsintelligens: Datavarehus bygger bro mellom massive rådata, som ofte samles inn rutinemessig som en selvfølge, og de kurerte dataene som gir innsikt. De fungerer som grunnlaget for en organisasjons datalagring, og gjør det mulig for den å svare på kompliserte spørsmål om dataene og bruke svarene til å ta forsvarlige forretningsbeslutninger.
Begrensninger for datavarehus
- Mangel på datafleksibilitet: Mens datavarehus utmerker seg med å håndtere strukturerte data, kan semistrukturerte og ustrukturerte dataformater som logganalyse, strømming og sosiale medier være utfordrende for dem. Dette gjør å anbefale datavarehus for brukstilfeller som involverer maskinlæring og kunstig intelligens vanskelig.
- Kostbart å installere og vedlikeholde: Datavarehus kan være kostbart å installere og vedlikeholde. Dessuten er datavarehuset ofte ikke statisk; den eldes og trenger hyppig vedlikehold, noe som er dyrt.
Pros
- Data er enkelt å finne, hente og søke etter.
- Så lenge dataene allerede er rene, er SQL-dataforberedelse enkel.
Ulemper
- Du er tvunget til å bruke bare én analyseleverandør.
- Å analysere og lagre ustrukturerte eller flytende data er ganske kostbart.
Hva er Data Lake?
Alle typer data er lovet og muliggjort av datainnsjøer. Det er en fordel å ha data på en tilgjengelig måte sentralt plassert og tilgjengelig for lesing.
En datainnsjø er en sentralisert, ekstremt tilpasningsdyktig lagringsplass der enorme mengder organiserte og ustrukturerte data holdes i deres ubehandlede, uendrede og uformaterte former.
En datainnsjø bruker en flat arkitektur og objekter lagret i ubehandlet tilstand for å lagre data, i motsetning til datavarehus, som lagrer relasjonsdata som tidligere har blitt "renset".
Datainnsjøer, i motsetning til datavarehus, som har problemer med å håndtere data i dette formatet, er tilpasningsdyktige, pålitelige og rimelige og lar bedrifter få forbedret innsikt fra ustrukturerte data.
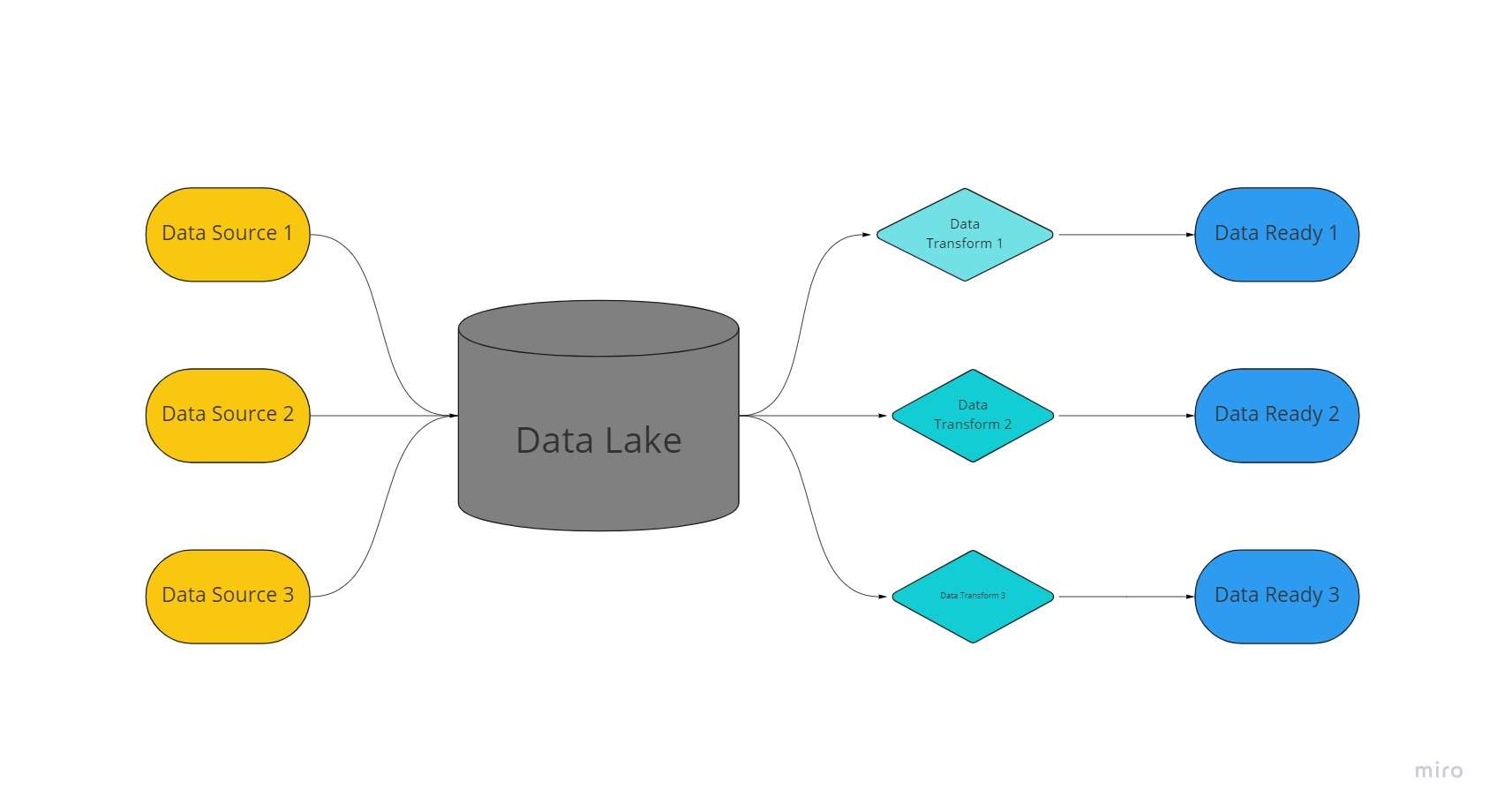
I datainnsjøer trekkes data ut, lastes og transformeres (ELT) for analytiske formål i stedet for å ha skjemaet eller dataene etablert på tidspunktet for datainnsamlingen.
Ved å bruke teknologier for mange datatyper fra IoT-enheter, sosiale medier, og strømming av data, datainnsjøer muliggjør maskinlæring og prediktiv analyse.
I tillegg kan en dataforsker som kan behandle rådata bruke datainnsjøen. Et datavarehus er derimot enklere å bruke for bedrifter. Den er perfekt for brukerprofilering, prediktiv analyse, maskinlæring og andre oppgaver.
Selv om datainnsjøer løser flere problemer med datavarehus, er datakvaliteten deres dårlig og spørringshastigheten er utilstrekkelig. I tillegg krever det ekstra verktøy for forretningsbrukere å utføre SQL-spørringer. En datainnsjø som er dårlig strukturert kan oppleve et problem med datastagnasjon.
Fordeler med Data Lake
- Støtte for et bredt spekter av applikasjonssaker for maskinlæring og datavitenskap Det er enklere å bruke en annen maskin- og dyplæringsalgoritmer for å håndtere dataene i datainnsjøer siden dataene holdes på en åpen, rå måte.
- Data lakes allsidighet, som lar deg lagre data i alle formater eller medier uten krav om et forhåndsinnstilt skjema, er en stor fordel. Fremtidige databrukstilfeller kan støttes, og flere data kan analyseres hvis dataene blir stående i sin opprinnelige tilstand.
- For å unngå å måtte lagre begge typer data i ulike sammenhenger, kan datainnsjøer inneholde både strukturerte og ustrukturerte data. For lagring av ulike typer organisasjonsdata tilbyr de ett enkelt sted.
- Sammenlignet med tradisjonelle datavarehus er datainnsjøer rimeligere fordi de er bygd for å holdes på billig råvaremaskinvare, for eksempel objektlagring, som ofte er rettet mot en lavere kostnad per lagret gigabyte.
Begrensninger for Data Lake
- Brukstilfeller for dataanalyse og business intelligence scorer dårlig: Datainnsjøer kan bli uorganiserte hvis de ikke vedlikeholdes tilstrekkelig, noe som gjør det vanskelig å koble dem til business intelligence og analyseverktøy. I tillegg, når det er nødvendig for rapportering og analysebruk, mangel på konsistent datastrukturer og ACID (atomisitet, konsistens, isolasjon og holdbarhet) transaksjonsstøtte kan føre til suboptimal spørringsytelse.
- Datainnsjøers inkonsekvens gjør det umulig å håndheve datapålitelighet og sikkerhet, noe som resulterer i mangel på begge deler. Det kan være vanskelig å utvikle passende datasikkerhets- og styringsstandarder for å imøtekomme sensitive datatyper, siden datainnsjøer kan håndtere alle dataformer.
Pros
- Løsninger som er rimelige for alle typer data.
- Kan håndtere data som er både organisert og semi-strukturert.
- Ideell for komplisert databehandling og streaming.
Ulemper
- Trenger en sofistikert rørledning for å bygges.
- Gi data litt tid til å bli søkbare.
- Det tar tid å garantere datapålitelighet og kvalitet.
Hva er Data Lakehouse?
En ny stordatalagringsarkitektur kalt et "datalakehouse" kombinerer de største aspektene ved datainnsjøer og datavarehus. Alle dataene dine, enten de er strukturerte, semistrukturerte eller ustrukturerte, kan lagres på ett sted med de beste maskinlærings-, forretningsintelligens- og strømmefunksjonene som er mulig takket være et datainnsjøhus.
Datainnsjøer av alle slag er ofte utgangspunktet for datainnsjøer; etter det transformeres dataene til Delta Lake-format (et åpen kildekode-lagringslag som gir datainnsjøer pålitelighet).
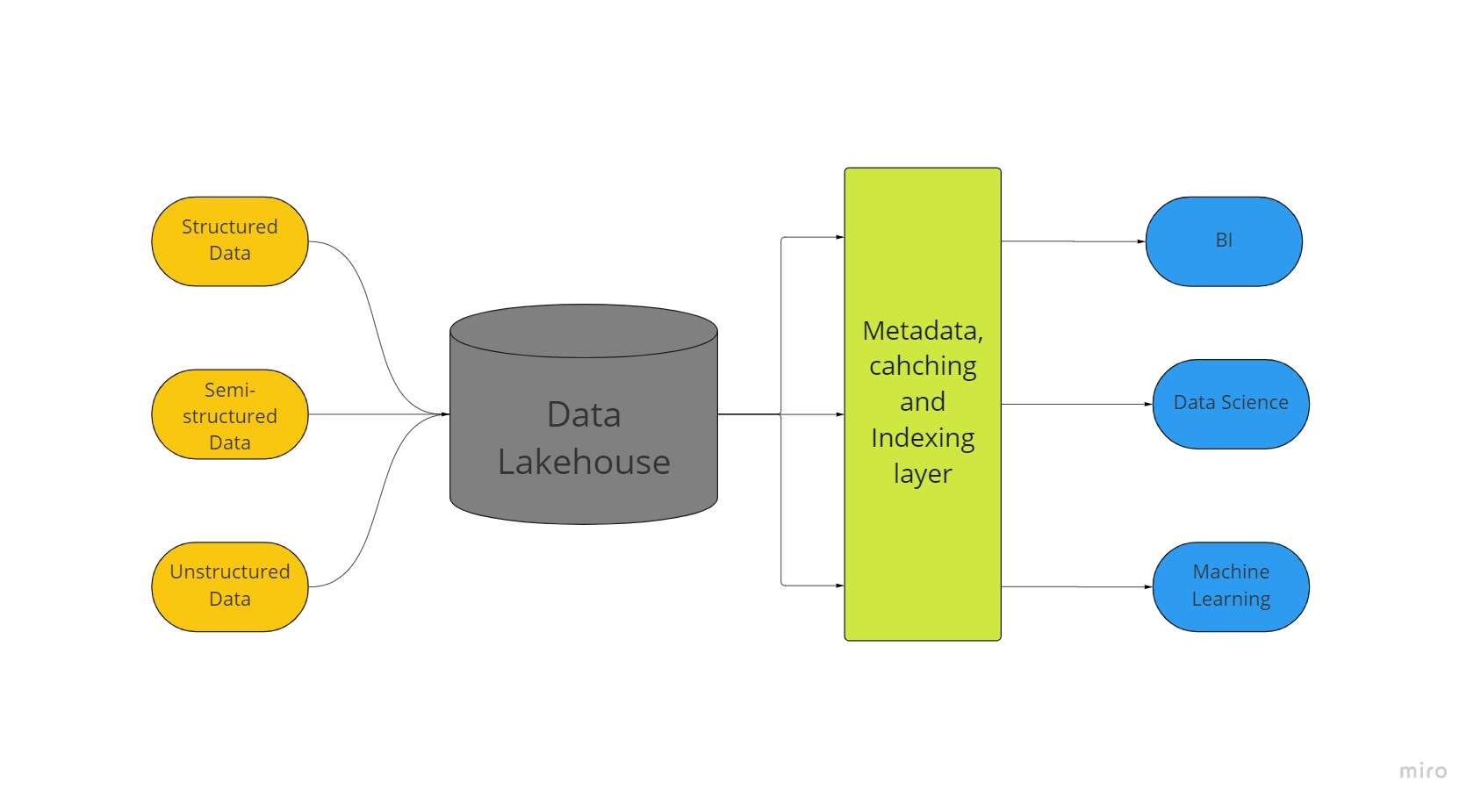
Datainnsjøer med deltasjøer muliggjør ACID-transaksjonsprosedyrer fra konvensjonelle datavarehus. I hovedsak bruker lakehouse-systemet rimelig lagring for å opprettholde enorme mengder data i sine opprinnelige former, omtrent som datainnsjøer.
Å legge til metadatalaget på toppen av butikken gir også datastruktur og gir dataadministrasjonsverktøy som de som finnes i datavarehus.
Dette gjør det mulig for mange team å få tilgang til alle bedriftsdataene gjennom ett enkelt system for en rekke initiativer, for eksempel datavitenskap, maskinlæring og business intelligence.
Fordeler med Data Lakehouse
- Støtte for et større spekter av arbeidsbelastninger: For å lette sofistikerte analyser gir datainnsjøer brukere direkte tilgang til noen av de mest populære business intelligence-verktøyene (Tableau, PowerBI). I tillegg kan dataforskere og maskinlæringsingeniører enkelt bruke dataene siden datainnsjøer bruker åpne dataformater (som Parquet) sammen med APIer og maskinlæringsrammeverk, som Python/R.
- Kostnadseffektivitet: Data Lakehouses bruker rimelige objektlagringsløsninger for å implementere datainnsjøers kostnadseffektive lagringsegenskaper. Ved å tilby én enkelt løsning slipper datainnsjøer også utgiftene og tiden forbundet med å administrere ulike datalagringssystemer.
- Data Lakehouse-design sikrer skjema og dataintegritet, noe som gjør det enklere å bygge effektive datasikkerhets- og styringssystemer. Enkelhet av dataversjon, styring og sikkerhet.
- Data Lakehouses tilbyr en enkelt, flerbruks datalagringsplattform som kan imøtekomme alle bedriftens databehov, noe som reduserer dataduplisering. Flertallet av virksomheter velger en hybridløsning på grunn av fordelene med både datavarehuset og datasjøen. Denne strategien kan i mellomtiden resultere i kostbar dataduplisering.
- Støtte for åpne formater. Åpne formater er filtyper som kan brukes av mange programmer og hvis spesifikasjoner er offentlig tilgjengelige. Ifølge rapporter er Lakehouses i stand til å lagre data i vanlige filformater som Apache Parquet og ORC (Optimized Row Columnar).
Begrensninger for Data Lakehouse
Et data Lakehouses største ulempe er at det fortsatt er en ung og utviklende teknologi. Det er usikkert om den vil oppfylle sine forpliktelser som et resultat. Før datainnsjøer kan konkurrere med etablerte lagringssystemer for store data, kan det ta år.
Med tanke på hastigheten moderne innovasjon skjer med, er det imidlertid vanskelig å si om et annet datalagringssystem ikke til slutt vil erstatte det.
Pros
- Én plattform har alle dataene, noe som betyr at det er færre vertsnavn å vedlikeholde.
- Atomitet, konsistens, isolasjon og seighet påvirkes ikke.
- Det er betydelig rimeligere.
- Én plattform har alle dataene, noe som betyr at det er færre vertsnavn å vedlikeholde.
- Enkel å administrere, og rask til å løse eventuelle problemer
- Gjør det enklere å bygge en rørledning
Ulemper
- Oppsett kan ta litt tid.
- Det er for ungt og for langt unna til å kvalifisere som et etablert lagringssystem.
Data Warehouse vs Data Lake vs Data Lakehouse
Datavarehuset har en lang historie innen bedriftsintelligens, rapportering og analyseapplikasjoner og er den første lagringsteknologien for store data.
Datavarehus er derimot kostbare og har problemer med å håndtere mangfoldige og ustrukturerte data, for eksempel strømmedata. For maskinlæring og datavitenskap-arbeidsmengder ble datainnsjøer utviklet for å administrere rådata i forskjellige former på rimelig lagring.
Selv om datainnsjøer er effektive med ustrukturerte data, mangler de ACID-transaksjonsevnen til datavarehus, noe som gjør det utfordrende å garantere datakonsistens og pålitelighet.
Den nyeste datalagringsarkitekturen, kjent som «data lakehouse», kombinerer påliteligheten og konsistensen til datavarehus med rimeligheten og tilpasningsevnen til datainnsjøer.
konklusjonen
Avslutningsvis kan det være vanskelig å bygge et datainnsjø fra bunnen av. Videre vil du nesten helt sikkert bruke en plattform designet for å muliggjøre åpen data-lakehouse-arkitektur.
Vær derfor forsiktig med å undersøke de mange funksjonene og implementeringene til hver plattform før du kjøper. Bedrifter som leter etter en moden, strukturert dataløsning med fokus på business intelligence og dataanalysebruk, kan vurdere et datavarehus.
Imidlertid bør bedrifter som leter etter en skalerbar, rimelig stordataløsning for å drive arbeidsbelastninger for datavitenskap og maskinlæring på ustrukturerte data vurdere datainnsjøer.
Tenk på at bedriften din trenger mer data enn datavarehuset og datainnsjøteknologiene kan gi, eller at du leter etter en løsning for å integrere sofistikerte analyser og maskinlæringsoperasjoner på dataene dine. EN data lakehouse er et fornuftig alternativ i situasjonen.





Legg igjen en kommentar