Innholdsfortegnelse[Gjemme seg][Forestilling]
Data er overalt rundt deg. I en reell forstand påvirker det alle aspekter av virksomheten din. Det kan føles som om det ikke er nok tid til å undersøke detaljene om hvor godt det tjener bedriften din når du er opptatt av beslutninger om hvordan du skal håndtere dataene dine.
Legg merke til dette. Organisasjonen din bruker data 24 timer i døgnet. Så å forstå hvor det kom fra, hvordan det kom dit, og hvordan det beveger seg gjennom selskapet, er avgjørende for å forstå verdien.
Dataavstamning blir viktig i denne situasjonen. Det er enklere å forstå hvordan data ble dannet, hvor de kom fra, og hvor de går når vi kan spore opprinnelsen, migrasjonene og endringene til dataene.
I dette innlegget skal vi se nærmere på Data Lineage, hvordan det fungerer, dets brukstilfeller, teknikker og mye mer.
Hva er datalinje?
Dataavstamning fungerer som et slags digitalt pass. Det er den mest omfattende beretningen om en datareise, som beskriver alle stopp, omveier og endringer fra opprinnelsen til den endelige destinasjonen.
Ii hovedsak beskriver dataavstamning opprinnelsen, modifikasjonen og bruken av et datastykke på tvers av mange systemer og plattformer. Det fungerer som et detektivverktøy ved å gi brukere informasjon om hvordan data ble produsert, hvor de stammer fra og hvordan de ble brukt. Denne informasjonen gjør det mulig for brukere å gjenkjenne og løse eventuelle problemer.
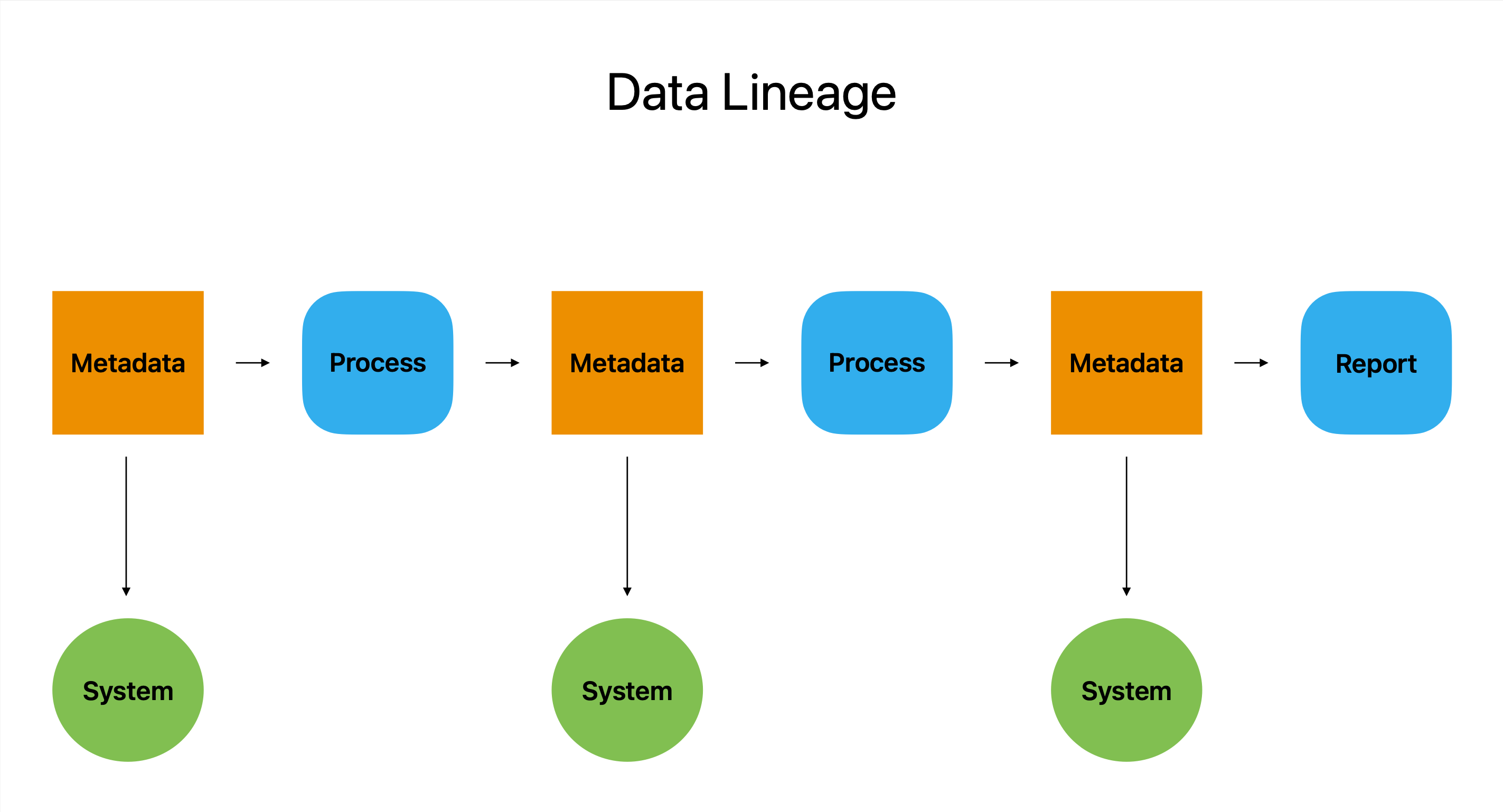
Dataavstamning er en uvurderlig ressurs for selskaper som er avhengige av data for å drive driften, fordi den lar brukere svare på avgjørende spørsmål som hvem, hva, når og hvor.
Dataavstamning er, for å si det enkelt, det ultimate datasporet som garanterer datanøyaktighet, fullstendighet og konsistens samtidig som det tilbyr et klart og kortfattet perspektiv på dataens fulle bane.
Hvordan fungerer Data Lineage?
Datalinje er veikartet som gjør oss i stand til å følge et stykke data fra startpunktet til endepunktet. Betrakt et datapunkt som en reisende, og passet som dets datalinje for bedre å forstå hvordan det fungerer.
Datakilder, datatransformasjon, datalagring og datautgang utgjør passets fire hovedkomponenter.
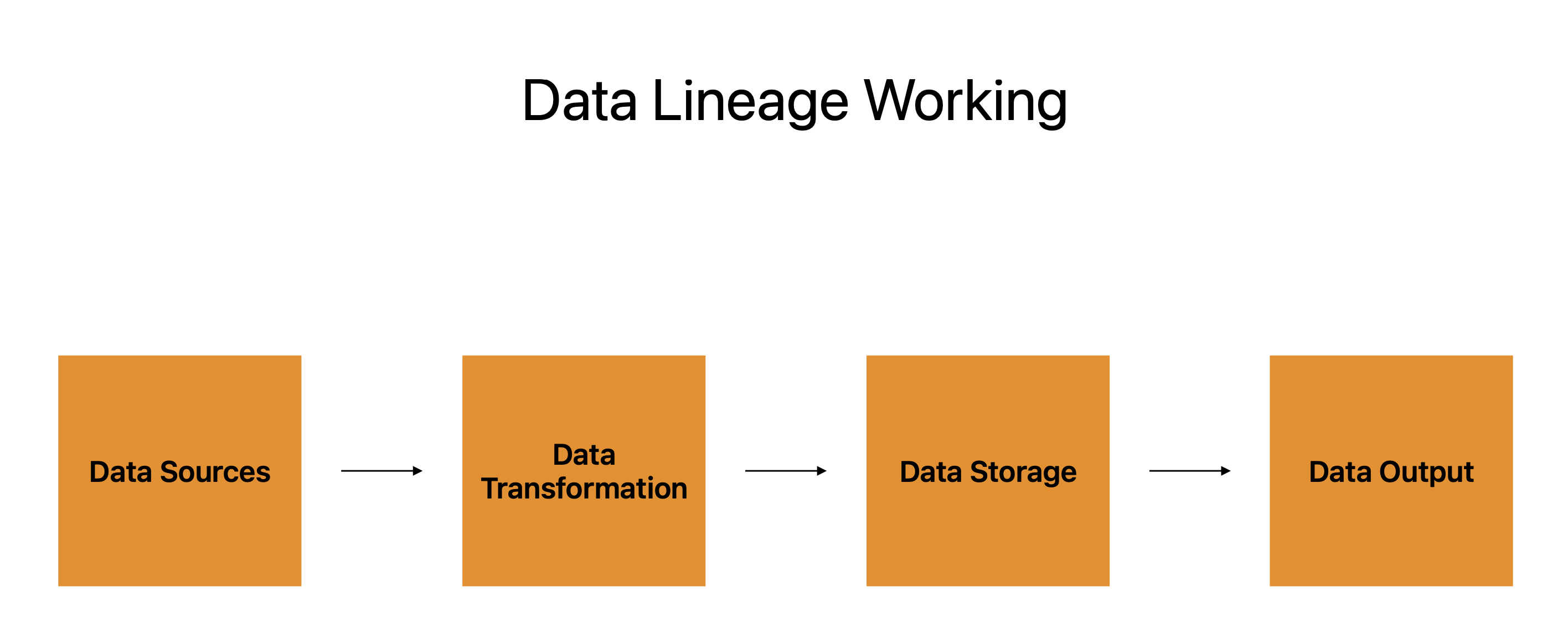
De mange systemene, applikasjonene og plattformene som dataene stammer fra er representert av datakilder, som fungerer som utgangspunkt for dataenes reise. Datatransformasjon er det påfølgende stadiet, og datalinje kartlegger dataenes progresjon fra disse kildene til dem.
Datatransformasjon refererer til utforming, modifisering og manipulering av data for å møte brukerbehov. Den fungerer som et hvilestopp under dataenes tur, og forbereder den for neste etappe.
Dataene lagres deretter før de går til den endelige plasseringen. Den kan oppbevares på skyservere, databaser eller en annen type lagringsenhet. Dataavstamning holder styr på hvor dataene er lagret, samt hvordan de beskyttes, sikkerhetskopieres og gjenopprettes.
Det siste trinnet er datautgang, som er hvor dataene sendes for å brukes. Rapporter, infografikk eller andre typer dataprodukter kan brukes til å presentere det. Dataavstamning holder styr på utdataene og garanterer konsistensen, nøyaktigheten og fullstendigheten til dataene.
Dataavstamning fungerer i utgangspunktet ved å registrere hvert trinn av dataenes reise, fra starten til utdata, og sørge for at den forblir pålitelig, konsistent og korrekt hele veien gjennom. Dataavstamning hjelper organisasjoner med å ta veloverveide avgjørelser, fikse problemer og overholde juridiske forpliktelser ved å gi en full oversikt over en datas eksistens.
For å forstå datamidlene og hvordan de beveger seg gjennom datarørledningen, er metadata en avgjørende del av dataavstamningsprosessen.
Du kan se hvordan data konverteres og brukes i organisasjonen ved å bruke datalinjeverktøy, som utnytter metadata for å gi en visuell skildring av dataflyten. Dette gjør det mulig for brukere å vurdere dataens potensiale og hjelpe dem med å ta bedre informerte beslutninger.
Typer av datalinje
Det er tre grunnleggende former for datalinje: forover datalinje, bakover datalinje og toveis datalinje.
Videresend datalinje
Som med en enveiskjørt gate, innebærer videregående datalinje sporing av et datastykke fra startpunktet til sluttpunktet. Fra datakilden følger den dataene når de går gjennom flere transformasjoner og lagringssystemer for å nå utgangen.
Forståelse av behandling og transformasjon av data samt eventuelle problemer som kan ha oppstått underveis, forenkles ved å ha en datalinje av denne typen. Hvert trinn fører til det neste; det er som å følge et spor av brødsmuler.
Bakover datalinje
Bakover datalinje ligner på en reise i revers der vi sporer dataens utdata tilbake til kilden. Prosessen begynner på dataens endelige plassering og beveger seg bakover gjennom en rekke lagrings- og transformasjonsteknikker til den når datakilden.
Identifikasjon av dataens opprinnelige kilde, forståelse av transformasjonen og verifisering av korrekthet og fullstendighet er alt mulig ved hjelp av denne typen datalinje. Det fungerer som en detektivs verktøy, og lar oss følge banen til dataene bakover.
Toveis datalinje
En toveis, toveis datalinje kombinerer fordelene med forover og bakover datalinje. Den gir en omfattende oversikt over ruten til dataene ved å spore den fra kilden til destinasjonen så vel som fra den plasseringen til startpunktet.
For å bestemme dataens opprinnelige kilde, forstå hvordan de ble endret, og garantere dens kvalitet, konsistens og fullstendighet hele veien, er det nyttig å spore dataenes avstamning. Med sanntidsinformasjon om plassering og status, er det som å ha en GPS-tracker for data.
Implementering av Data Lineage
Implementering av datalinje i en organisasjon involverer ofte følgende faser.
Definer datakildene
Systemene og databasene som inneholder dataene du ønsker å spore, bør alle identifiseres. For å gjøre dette må du først identifisere de ulike datakildene, inkludert filer, APIer og skytjenester.
Samle inn metadata
Det neste trinnet er å innhente detaljer om dataene, inkludert plassering, format og organisering. Å forstå funksjonene til dataene og hvordan de brukes er muliggjort av disse metadataene.
Identifiser datafeil
Det er enklere å forstå hvordan data oppdateres og brukes i organisasjonen hvis dataflyten kartlegges fra kilden til destinasjonen, inkludert eventuelle transformasjoner eller behandlinger som finner sted langs ruten.
Spor datatilgang
For å opprettholde datasikkerhet og samsvar, spor og registrer hvem som får tilgang til dataene.
Lagre og visualiser avstamningen
Bruk visualiseringsverktøy for å presentere avstamningen for enkel forståelse og analyse. Lagre de innsamlede metadataene og dataflytinformasjonen i ett enkelt depot.
Implementere en automatisert løsning
Du kan bekrefte at dataavstamning samles inn og overvåkes gjennom automatisering, noe som også vil hjelpe til med å kutte ned på feil og øke produktiviteten.
Gjennomgå og oppdater
Sørg for at avstamningspostene er korrekte og aktuelle med jevne mellomrom, og oppdater dem etter behov.
Implementeringsprosessen må kanskje endres eller legges til faser avhengig av de unike kravene og begrensningene til hver organisasjon.
Datalinjeteknikker
Mønsterbasert avstamning
Med denne metoden utføres avstamning uten å måtte samhandle med programmeringen som genererte eller transformerte dataene. Metadatavurdering for tabeller, kolonner og forretningsrapporter er alle en del av det. Den utforsker avstamning ved å se etter trender ved å bruke disse metadataene.
For eksempel er det ganske sannsynlig at en kolonne i to datasett med samme navn og identiske dataverdier representerer de samme dataene i forskjellige faser av dens eksistens. Et datalinjediagram brukes deretter til å koble sammen disse to kolonnene.
Mønsterbasert avstamning har den betydelige fordelen av å være teknologiuavhengig fordi den bare sjekker data, ikke databehandlingsmetoder. Enhver databaseteknologi, inkludert Oracle, MySQL og Spark, kan implementere den på samme måte. Ulempen er at denne tilnærmingen ikke alltid er presis.
Når databehandlingslogikken er skjult i datakoden og ikke lett synlig i menneskelesbare metadata, kan den av og til overse forhold mellom datasett.
Avstamning etter datatagging
Denne metoden er basert på ideen om at en transformasjonsmotor tagger eller på annen måte markerer data. Den sporer taggen fra begynnelse til slutt for å finne avstamning. Denne tilnærmingen kan bare være vellykket hvis du har et pålitelig transformasjonsverktøy som håndterer all dataoverføring og du er kjent med taggingstrukturen verktøyet bruker.
Selv om et slikt verktøy skulle eksistere, kunne ingen data som ble opprettet eller endret uten det bli utsatt for avstamning via datatagging. Det er begrenset i denne forbindelse til å utføre datalinje på lukkede datasystemer.
Selvstendig avstamning
Noen virksomheter har et datamiljø som inkluderer metadatalagring, prosesseringslogikk og masterdata management (MDM). Disse innstillingene inkluderer ofte en data innsjø hvor alle data oppbevares gjennom hele levetiden.
Avstamning kan naturlig gis av denne typen selvstendige system uten behov for ekstra ressurser. Imidlertid, akkurat som med datamerkingsmetoden, vil avstamning ikke være klar over noe som skjer utenfor dette regulerte miljøet.
Datalinje ved parsing
Den mest sofistikerte typen avstamning er en som leser databehandlingslogikk automatisk. For grundig ende-til-ende-sporing reverserer denne metoden datatransformasjonslogikken.
Siden denne løsningen må forstå alt programmerings språk og verktøy som brukes til å konvertere og transportere dataene, er implementeringen komplisert. Dette kan bruke ETL-logikk (extract-transform-load), SQL- og Java-baserte løsninger, gamle dataformater, XML-baserte løsninger og andre teknikker.
Brukstilfeller av dataavstamning
Datamodellering
Bedrifter må etablere de underliggende datastrukturene som støtter dem for å visualisere de mange dataelementene og sammenhengene mellom dem i en bedrift. Disse forbindelsene er modellert ved hjelp av datalinje, som også viser de mange avhengighetene som finnes i dataøkosystemet.
Siden data endres over tid, dukker det stadig opp nye datakilder, som krever nye dataintegrasjoner osv. På grunn av dette må også bedrifters generelle datamodeller for å administrere dataene deres endres for å reflektere miljøet.
Samsvar
Datalinje tilbyr en samsvarsmetode for revisjon, forbedring av risikostyring og sørge for at data oppbevares og håndteres i samsvar med retningslinjer og lover for datastyring.
Konsekvensanalyse
Effektene av visse forretningsendringer, for eksempel nedstrømsrapportering, kan sees ved hjelp av datalinjeverktøy. Dataavstamning, for eksempel, kan hjelpe ledere med å bestemme hvor mange dashbord en navneendring vil påvirke, og følgelig hvor mange personer som får tilgang til denne rapporteringen.
Dataoverføring
Organisasjoner bruker datamigrering for å forstå hvor dataene er plassert og hvor lenge de har vært der før de flyttes til et nytt lagringssystem eller implementerer ny programvare.
Dataavstamning hjelper teamene med å forberede seg på systemoppgraderinger eller migreringer ved å gi dem en oversikt over hvordan dataene har beveget seg gjennom hele organisasjonen. Dette setter fart på overføringen til det nye lagringsmiljøet totalt sett.
I tillegg gir det teamene muligheten til å rydde opp i datasystemet ved å arkivere eller eliminere utdaterte eller ubrukelige data. Ved å gjøre det vil datasystemet yte bedre totalt sett og trenge mindre håndtering av data.
Utfordringer ved å implementere datalinje
- Datasikkerhet: Datasikkerhet er en primær bekymring når du bygger dataavstamning. For å følge en datareise fra startpunkt til endelig destinasjon må det gis tilgang til sensitive data, og disse dataene må beskyttes mot uautorisert tilgang og brudd.
- Mangel på standardisering: En av de viktigste barrierene for å omfavne datalinje er mangelen på standarder. Siden mange plattformer, apper og systemer bruker unike metoder for å spore og registrere dataopprinnelse, kan det være vanskelig å sette sammen et sammenhengende bilde av en datareise.
- Datasiloer: Datasiloer er et annet problem som oppstår under implementering av datalinje. Når data er spredt over flere applikasjoner og systemer, kan det være utfordrende å spore reisen fra den ene til den andre. Dette kan føre til unøyaktig eller ufullstendig dataavstamning.
konklusjonen
Avslutningsvis er dataavstamning en viktig del av enhver datadrevet virksomhet. Den tilbyr et omfattende perspektiv av en datas vei fra startpunktet til sluttpunktet, og garanterer nøyaktigheten, fullstendigheten og konsistensen.
Fremtidig datalinjeautomatisering og standardisering forventes å øke, noe som gjør implementering og vedlikehold enklere for organisasjoner. Til syvende og sist kan ikke betydningen av dataavstamning understrekes.
Det gir bedrifter verktøyene de trenger for å ta kloke valg, drive sin virksomhet mer effektivt og oppnå suksess.





Legg igjen en kommentar