Data er en kritisk komponent i moderne bedrifter. Bedrifter henter data fra mange kilder, for eksempel forbrukere, leverandører og interne systemer, og bruker dem til å ta utdannede beslutninger. Likevel, ettersom datavolumet og kompleksiteten vokser, kan det bli vanskelig å administrere og bruke dem effektivt.
En datakatalog kan hjelpe med dette. Det er et verktøy som brukes av bedrifter til å administrere datamidlene sine. Med andre ord, det er rett og slett en katalog med fakta om et selskap. Disse faktaene kan inkludere plassering, struktur og applikasjoner.
For effektiv databehandling er en datakatalog avgjørende. Uten en datakatalog står bedrifter i fare for å miste oversikten over dataene sine. Det hindrer dem i å vite hvilke data de har, hvor de er og hvordan de skal bruke dem. Datafeil, duplisering og inkonsekvenser forårsaket av dette kan ha alvorlige konsekvenser for virksomheter.
Komponenter i en datakatalog
Metadata, datalinje, og datakvalitetsdetaljer er de tre nøkkeldelene i en datakatalog.
metadata
Detaljene som karakteriserer dataene i katalogen er kjent som metadata. Den inneholder detaljer som dataens navn, plassering, format og tiltenkt bruk. Ved å gi datakonteksten gjør metadata det mulig for brukere å finne og forstå datamidlene raskere.
Datahistorikk
Datalinje er dokumentasjonen av dataenes opprettelse, transformasjon og bevegelse mellom ulike systemer. Det gir et omfattende perspektiv av dataens rute, noe som gjør det enklere å bestemme nøyaktigheten til dataene og spore historien.
Kvalitetsdatainformasjon
Informasjon om datakvalitet undersøker faktorer inkludert fullstendighet, korrekthet, konsistens og aktualitet. Det tilbyr et middel til å bestemme dataenes egnethet for visse bruksområder. Det garanterer også at dataene samsvarer med organisasjonens krav.
Forstå datakataloger
En datakatalog er en komplett oversikt over dataressurser som inneholder nøyaktig informasjon om hver datainnsamling. Den inkluderer metadata, dataavstamning og datakvalitetsinformasjon for å hjelpe organisasjoner med å effektivt administrere datamidlene sine.
Metadata beskriver et datasetts viktige funksjoner, for eksempel skjema, format, datatype og datakilde. Dataavstamning forklarer et datasetts historie, inkludert opprinnelse, modifikasjoner og avhengigheter. Og informasjon om datakvalitet demonstrerer et datasetts korrekthet, fullstendighet og pålitelighet.
Datakataloger blir ofte forvekslet med dataordbøker eller databeholdninger, selv om de ikke er det samme. Selv om dataordbøker definerer og beskriver datadeler, gir datakataloger detaljert informasjon om komplette datasett. I motsetning til dette viser databeholdninger bare datamidlene uten å gi ytterligere informasjon.
Planlegge en datakatalog
Det er avgjørende å forberede seg ordentlig før du bygger en datakatalog for å sikre at den oppfyller kravene til selskapet. Å identifisere datakilder, etablere metadatastandarder og forstå brukerkrav er alle viktige spørsmål.
Relevansen og verdien av datakilder for organisasjonen bør vurderes nøye. For å opprettholde enhetlighet og interoperabilitet i hele selskapet, bør metadatastandarder brukes. Brukerkrav bør defineres for å sikre at datakatalogen opprettes med dem i tankene.
Trinn for å lage en datakatalog
Trinn 1: Finn datakilder
Det første trinnet i å lage en datakatalog er å identifisere alle organisasjonens datakilder. Dette omfatter databaser, datavarehus, regneark og andre datalagre. Når du har identifisert alle kildene, kan du begynne å samle inn metadata.
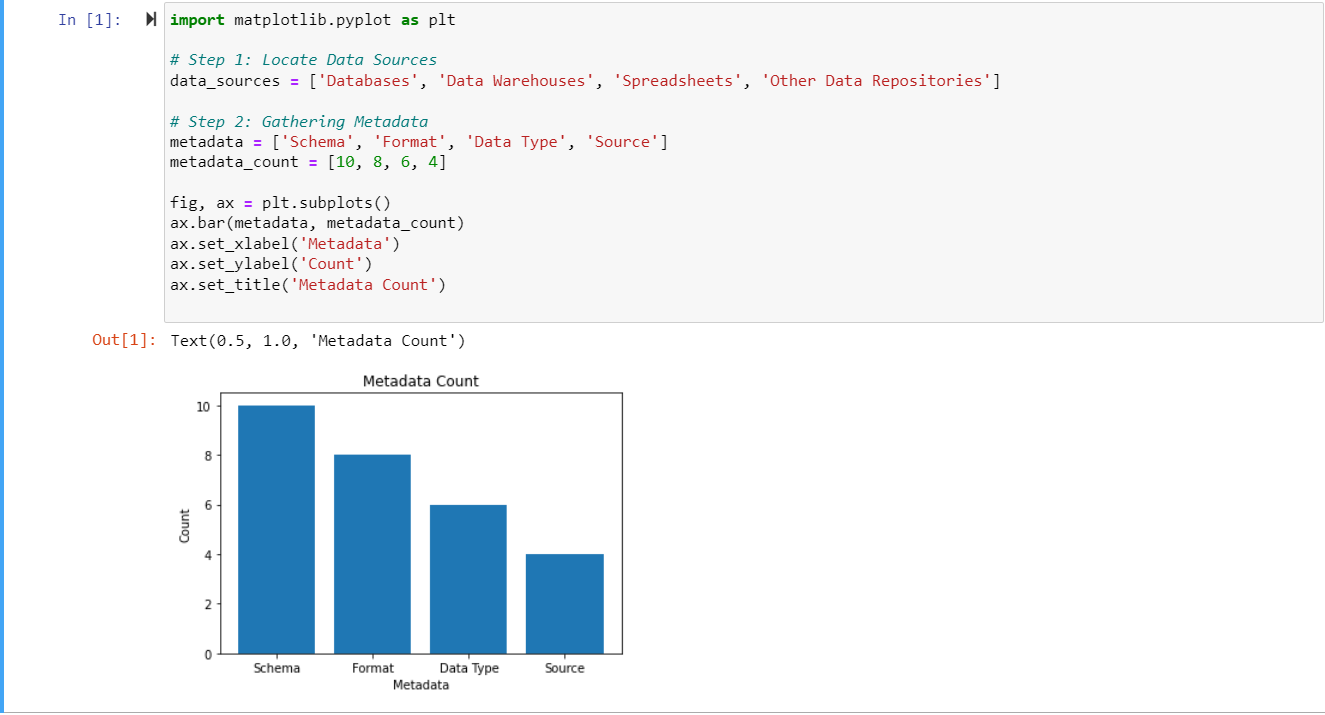
Trinn 2: Innsamling av metadata
Det følgende trinnet er å samle metadata fra alle de oppførte datakildene. Metadata spesifiserer et datasetts nøkkelegenskaper, for eksempel skjema, format, datatype og kilde. Metadatainnsamling hjelper til med dataorganisering og gjør det enklere å søke og finne.
Trinn 3: Dataprofilering
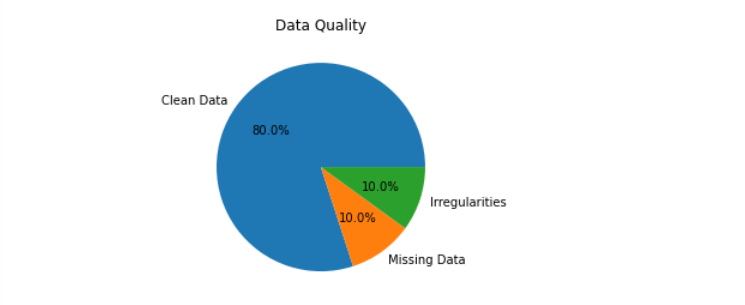
Etter innsamling av metadata blir dataene profilert. Prosessen med å gjennomgå datasett for å identifisere deres struktur, substans og kvalitet er kjent som dataprofilering. Profilering hjelper til med å identifisere problemer med datakvalitet, for eksempel manglende data. Det sikrer at dataene er rene og egnet for bruk.
Trinn 4: Lag en dataordbok
Følgende trinn er å lage en dataordbok. En dataordbok er en uttømmende oversikt over alle dataene i din bedrift. Den tilbyr rike metadatabeskrivelser, datakvalitetsinformasjon og datalinje. En dataordbok er avgjørende for å forstå organisasjonens data og sikre at de brukes riktig.
Trinn 5: Identifisere datarelasjoner
Det neste trinnet er å identifisere koblingen mellom dataene. Dette innebærer å oppdage og fremheve koblingen mellom datasett. Dette gjør at interessenter lett kan forstå sammenhengen mellom datakilder.
Trinn 6: Bygg en avstamning
Å lage en grafisk avbildet avstamning er avgjørende for å bestemme dataenes reise. Avstamningen forklarer de mange prosedyrene som er involvert i dataflyten. Dette gjør det mulig for interessenter å raskt identifisere den underliggende årsaken til et problem ved ganske enkelt å spore avstamningen.
7. trinn: Dataorganisasjon
Data som finnes i en fil eller en tabell er teknisk eksisterende. I henhold til forretningskravene kan dette være fornuftig eller ikke. Som et resultat er manuell innsats nødvendig for å organisere dataene på en måte som forretningsbrukere kan forstå og stole på. Merking av data, organisering av data basert på bruk og brukerrolle og automatisering av dataorganisering er alle metoder for dataorganisering.
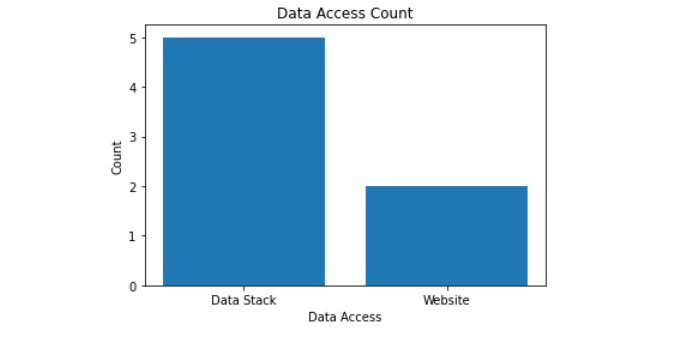
Trinn 8: Gir enkel tilgang
Datakatalogen bør være lett tilgjengelig inne i datastakken for å kunne brukes mer effektivt. Du kan bruke datakatalogen på nettstedet hvis du bruker et verktøy som Sprinkle, som øker datakatalogens brukervennlighet.

Trinn 9: Sett sikkerhetstiltak på plass
Fordi datakatalogen har oversikt over alle en organisasjons data, er det avgjørende å følge sikkerhetskravene. En datakatalog må ha rollebasert sikkerhet, informasjon om hvem som brukte hvilke data og når, revisjon og kryptering.
Bruk av datakatalogen din
Ved å gi brukerne full informasjon om dataressurser, kan en datakatalog bidra til å forbedre dataadministrasjon og beslutningstaking.
En dataanalytiker kan for eksempel bruke datakatalogen til å finne relevante datasett for en bestemt studie. Og de kan bruke metadataene til å forstå dataenes struktur og substans. Datakatalogen kan brukes av en bedriftsbruker til å studere ulike datasett og få innsikt i forbrukeratferd, produktytelse eller markedstrender.
For å oppsummere innebærer vedlikehold av en datakatalog nøye planlegging og konsekvent arbeid. Likevel er fordelen med å ha en grundig oversikt over dataressurser mye. Det kan forbedre beslutningstaking og øke produktiviteten.
Forskjeller mellom dataordbøker, databeholdninger og datakatalog
Selv om dataordbøker, databeholdninger og datakataloger alle tilbyr detaljer om datamidlene til en organisasjon, varierer omfanget og mengden av detaljer.
Ordbokdata
Dataordbøker inkluderer detaljer om strukturen til dataene, inkludert navn og beskrivelser av tabellene, feltene og forbindelsene. De er ofte utviklet av databaseadministratorer og konsentrerer seg om spesifikk teknisk informasjon.
Inventar av data
Databeholdninger inkluderer detaljer om de fysiske datamidlene, inkludert deres plassering, eier og sikkerhetsnivå. De er ofte utviklet av IT-enheter med et ledelsesorientert fokus på inventar av dataressurser.
Datakataloger
Datakataloger kombinerer metadata, dataavstamning og datakvalitetsinformasjon for å gi et komplett bilde av en organisasjons dataressurser. De er ment å være brukervennlige og tilgjengelige for forretningsbrukere, dataforskere og andre interessenter som må forstå og bruke datamidlene.
Viktige ting å ta hensyn til
Mange variabler må vurderes når man utvikler en datakatalog. Til å begynne med er det viktig å bestemme datakildene som må inkluderes i katalogen. Dette garanterer at all data er registrert og tilgjengelig.
I tillegg må det etableres metadatastandarder og datastyringsprosedyrer for å garantere at dataene i katalogen er korrekte, fullstendige og oppdaterte. Dataorganisering og tilgjengelighet er også viktige faktorer å vurdere siden katalogen bør ordnes på en måte som gir mening for brukerne og er lett tilgjengelig inne i datastakken.





Legg igjen en kommentar