Inhoudsopgave[Zich verstoppen][Laten zien]
Dankzij computers kunnen we nu de uitgestrektheid van de ruimte en de kleinste details van subatomaire deeltjes berekenen.
Computers verslaan mensen als het gaat om tellen en rekenen, en ook om logische ja/nee-processen te volgen, dankzij elektronen die via de circuits met de snelheid van het licht reizen.
We zien ze echter niet vaak als 'intelligent', aangezien computers in het verleden niets konden uitvoeren zonder dat ze door mensen werden onderwezen (geprogrammeerd).
Machine learning, inclusief deep learning en kunstmatige intelligentie, is een modewoord geworden in wetenschappelijke en technologische krantenkoppen.
Machine learning lijkt alomtegenwoordig te zijn, maar veel mensen die het woord gebruiken, zouden moeite hebben om adequaat te definiëren wat het is, wat het doet en waarvoor het het beste kan worden gebruikt.
Dit artikel wil machinaal leren verduidelijken en tegelijkertijd concrete, praktijkvoorbeelden geven van hoe de technologie werkt om te illustreren waarom het zo nuttig is.
Vervolgens bekijken we de verschillende machine learning-methodologieën en zien we hoe ze worden gebruikt om zakelijke uitdagingen aan te gaan.
Ten slotte zullen we onze kristallen bol raadplegen voor enkele snelle voorspellingen over de toekomst van machine learning.
Wat is machinaal leren?
Machine learning is een discipline van de informatica die computers in staat stelt patronen uit gegevens af te leiden zonder expliciet te leren wat die patronen zijn.
Deze conclusies zijn vaak gebaseerd op het gebruik van algoritmen om automatisch de statistische kenmerken van de gegevens te beoordelen en het ontwikkelen van wiskundige modellen om de relatie tussen verschillende waarden weer te geven.
Vergelijk dit met klassiek computergebruik, dat gebaseerd is op deterministische systemen, waarin we de computer expliciet een reeks regels geven die hij moet volgen om een bepaalde taak uit te voeren.
Deze manier van programmeren van computers staat bekend als rule-based programming. Machine learning verschilt van en presteert beter dan op regels gebaseerde programmering doordat het deze regels zelf kan afleiden.
Stel dat u een bankmanager bent die wil bepalen of een leningaanvraag op hun lening zal mislukken.
Bij een op regels gebaseerde methode zou de bankmanager (of andere specialisten) de computer uitdrukkelijk informeren dat als de kredietscore van de aanvrager onder een bepaald niveau ligt, de aanvraag moet worden afgewezen.
Een machine learning-programma zou echter eenvoudig eerdere gegevens over kredietbeoordelingen van klanten en leningresultaten analyseren en op zichzelf bepalen wat deze drempel zou moeten zijn.
De machine leert van eerdere gegevens en maakt op deze manier zijn eigen regels. Dit is natuurlijk slechts een inleiding op machine learning; real-world machine learning-modellen zijn aanzienlijk gecompliceerder dan een basisdrempel.
Desalniettemin is het een uitstekende demonstratie van het potentieel van machine learning.
Hoe werkt een machine leren?
Om het simpel te houden, 'leren' machines door patronen in vergelijkbare gegevens te detecteren. Beschouw data als informatie die je van de buitenwereld verzamelt. Hoe meer gegevens een machine krijgt, hoe "slimmer" deze wordt.
Niet alle gegevens zijn echter hetzelfde. Stel dat je een piraat bent met een levensdoel om de begraven rijkdommen op het eiland te ontdekken. U zult een aanzienlijke hoeveelheid kennis nodig hebben om de prijs te lokaliseren.
Deze kennis kan je, net als data, op de juiste of verkeerde manier brengen.
Hoe groter de verkregen informatie/data, hoe minder ambiguïteit er is, en vice versa. Als gevolg hiervan is het van cruciaal belang om na te denken over het soort gegevens dat u uw machine voedt om van te leren.
Zodra er echter een substantiële hoeveelheid gegevens is aangeleverd, kan de computer voorspellingen doen. Machines kunnen anticiperen op de toekomst, zolang deze niet veel afwijkt van het verleden.
Machines "leren" door historische gegevens te analyseren om te bepalen wat er waarschijnlijk gaat gebeuren.
Als de oude gegevens lijken op de nieuwe gegevens, zijn de dingen die u over de vorige gegevens kunt zeggen waarschijnlijk ook van toepassing op de nieuwe gegevens. Het is alsof je terugkijkt om vooruit te kijken.
Wat zijn de soorten machine learning?
Algoritmen voor machine learning worden vaak ingedeeld in drie brede typen (hoewel ook andere classificatieschema's worden gebruikt):
- Leren onder toezicht
- Niet-gecontroleerd leren
- Versterking leren
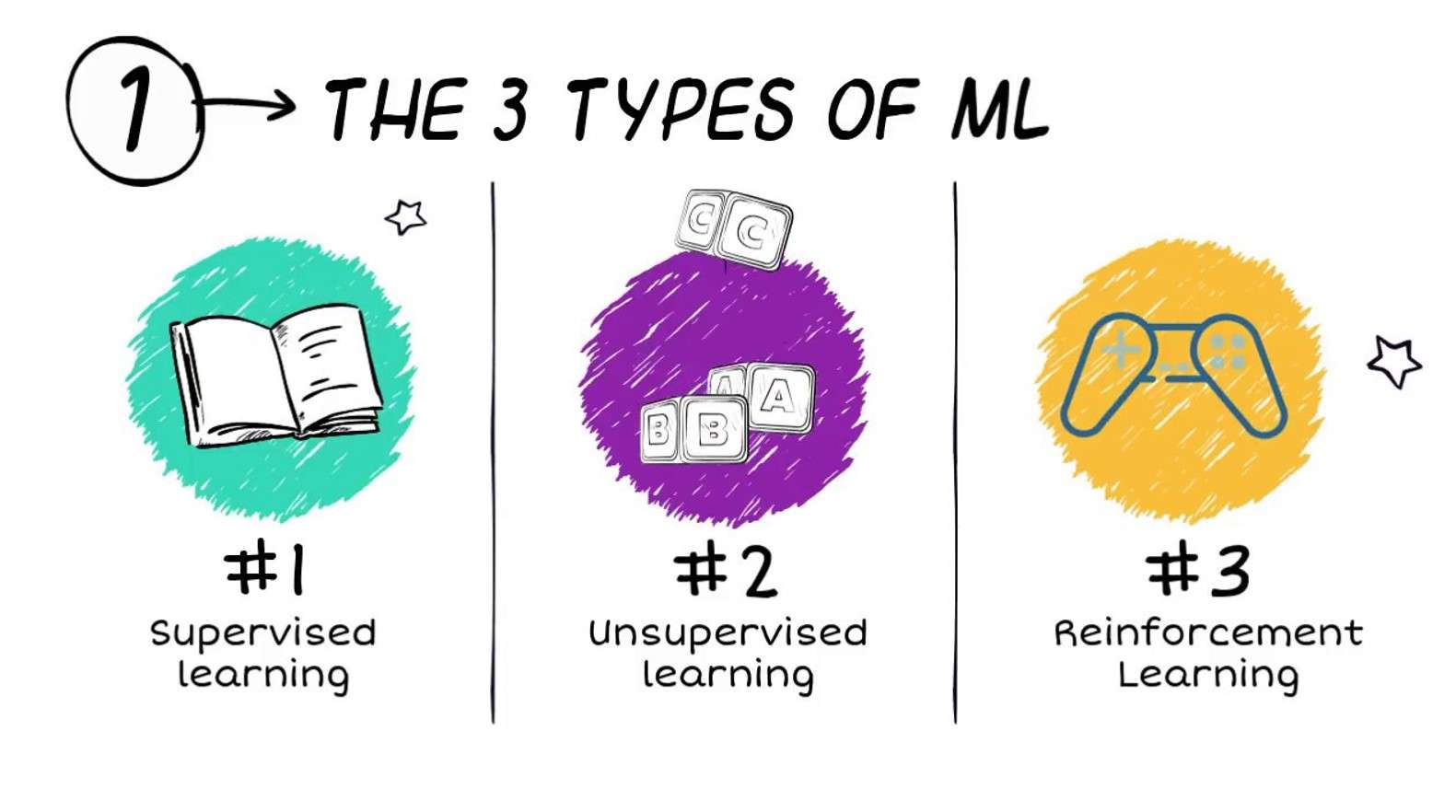
Leren onder toezicht
Supervised machine learning verwijst naar technieken waarbij het machine learning-model een verzameling gegevens krijgt met expliciete labels voor de hoeveelheid van belang (deze hoeveelheid wordt vaak de respons of het doel genoemd).
Om AI-modellen te trainen, maakt semi-gesuperviseerd leren gebruik van een mix van gelabelde en ongelabelde data.
Als u met niet-gelabelde gegevens werkt, moet u gegevens labelen.
Etikettering is het proces van het labelen van monsters om te helpen het trainen van een machine learning model. Etikettering wordt voornamelijk door mensen gedaan, wat kostbaar en tijdrovend kan zijn. Er zijn echter technieken om het etiketteringsproces te automatiseren.
De situatie voor het aanvragen van een lening die we eerder hebben besproken, is een uitstekende illustratie van begeleid leren. We hadden historische gegevens over de kredietwaardigheid van voormalige leningaanvragers (en misschien inkomensniveaus, leeftijd, enzovoort), evenals specifieke labels die ons vertelden of de persoon in kwestie al dan niet in gebreke bleef bij het betalen van zijn lening.
Regressie en classificatie zijn twee subsets van gesuperviseerde leertechnieken.
- Classificatie – Het maakt gebruik van een algoritme om gegevens correct te categoriseren. Spamfilters zijn daar een voorbeeld van. 'Spam' kan een subjectieve categorie zijn - de grens tussen spam en niet-spamcommunicatie is wazig - en het spamfilteralgoritme verfijnt zichzelf voortdurend, afhankelijk van uw feedback (d.w.z. e-mail die mensen markeren als spam).
- Regressie – Het is nuttig bij het begrijpen van het verband tussen afhankelijke en onafhankelijke variabelen. Regressiemodellen kunnen numerieke waarden voorspellen op basis van verschillende gegevensbronnen, zoals schattingen van de verkoopomzet voor een bepaald bedrijf. Lineaire regressie, logistische regressie en polynomiale regressie zijn enkele prominente regressietechnieken.
Niet-gecontroleerd leren
Bij niet-gesuperviseerd leren krijgen we niet-gelabelde gegevens en zijn we gewoon op zoek naar patronen. Laten we doen alsof je Amazon bent. Kunnen we clusters (groepen vergelijkbare consumenten) vinden op basis van de aankoopgeschiedenis van klanten?
Ook al hebben we geen expliciete, afdoende gegevens over iemands voorkeuren, in dit geval kunnen we door simpelweg te weten dat een specifieke groep consumenten vergelijkbare goederen koopt, koopsuggesties doen op basis van wat andere individuen in het cluster ook hebben gekocht.
Amazon's "u bent misschien ook geïnteresseerd in"-carrousel wordt mogelijk gemaakt door vergelijkbare technologieën.
Unsupervised learning kan gegevens groeperen door middel van clustering of associatie, afhankelijk van wat u wilt groeperen.
- Clustering – Unsupervised learning probeert deze uitdaging te overwinnen door te zoeken naar patronen in de gegevens. Als er een vergelijkbare cluster of groep is, zal het algoritme deze op een bepaalde manier categoriseren. Proberen om klanten te categoriseren op basis van eerdere aankoopgeschiedenis is hier een voorbeeld van.
- Vereniging – Unsupervised learning probeert deze uitdaging aan te gaan door te proberen de regels en betekenissen te begrijpen die ten grondslag liggen aan verschillende groepen. Een veelvoorkomend voorbeeld van een associatieprobleem is het leggen van een verband tussen klantaankopen. Winkels kunnen geïnteresseerd zijn om te weten welke goederen samen zijn gekocht en kunnen deze informatie gebruiken om de positionering van deze producten te regelen voor gemakkelijke toegang.
Versterking leren
Reinforcement learning is een techniek om machine learning-modellen aan te leren om een reeks doelgerichte beslissingen te nemen in een interactieve setting. De hierboven genoemde gaming use-cases zijn hier uitstekende voorbeelden van.
U hoeft AlphaZero niet duizenden eerdere schaakpartijen in te voeren, elk met een "goede" of "slechte" zet. Leer hem eenvoudig de spelregels en het doel, en laat hem vervolgens willekeurige handelingen uitproberen.
Positieve versterking wordt gegeven aan activiteiten die het programma dichter bij het doel brengen (zoals het ontwikkelen van een solide pionpositie). Wanneer handelingen het tegenovergestelde effect hebben (zoals het voortijdig verschuiven van de koning), verdienen ze negatieve bekrachtiging.
Met deze methode kan de software het spel uiteindelijk beheersen.
Versterking leren wordt veel gebruikt in de robotica om robots te leren voor gecompliceerde en moeilijk te ontwerpen acties. Het wordt soms gebruikt in combinatie met weginfrastructuur, zoals verkeerslichten, om de verkeersstroom te verbeteren.
Wat kan er met machine learning?
Het gebruik van machine learning in de samenleving en de industrie leidt tot vooruitgang in een breed scala van menselijke inspanningen.
In ons dagelijks leven bestuurt machine learning nu de zoek- en afbeeldingsalgoritmen van Google, waardoor we nauwkeuriger kunnen worden gekoppeld aan de informatie die we nodig hebben wanneer we die nodig hebben.
In de geneeskunde wordt bijvoorbeeld machinaal leren toegepast op genetische gegevens om artsen te helpen begrijpen en voorspellen hoe kanker zich verspreidt, waardoor effectievere therapieën kunnen worden ontwikkeld.
Gegevens uit de verre ruimte worden hier op aarde verzameld via enorme radiotelescopen - en na analyse met machine learning helpt het ons de mysteries van zwarte gaten te ontrafelen.
Machine learning in de detailhandel verbindt kopers met dingen die ze online willen kopen, en helpt winkelmedewerkers ook om de service die ze aan hun klanten bieden in de fysieke wereld af te stemmen.
Machine learning wordt gebruikt in de strijd tegen terreur en extremisme om te anticiperen op het gedrag van degenen die onschuldigen pijn willen doen.
Natuurlijke taalverwerking (NLP) verwijst naar het proces waarbij computers in staat worden gesteld om menselijke taal te begrijpen en met ons te communiceren door middel van machinaal leren, en het heeft geleid tot doorbraken in vertaaltechnologie en de spraakgestuurde apparaten die we steeds meer elke dag gebruiken, zoals Alexa, Google dot, Siri en Google-assistent.
Machine learning laat zonder meer zien dat het een transformationele technologie is.
Robots die naast ons kunnen werken en onze eigen originaliteit en verbeeldingskracht kunnen stimuleren met hun feilloze logica en bovenmenselijke snelheid, zijn niet langer een sciencefictionfantasie - ze worden realiteit in veel sectoren.
Gebruiksscenario's voor machine learning
1. cybersecurity
Naarmate netwerken ingewikkelder zijn geworden, hebben cyberbeveiligingsspecialisten onvermoeibaar gewerkt om zich aan te passen aan het steeds groter wordende scala aan beveiligingsbedreigingen.
Het tegengaan van snel evoluerende malware en hacktactieken is al uitdagend genoeg, maar de verspreiding van Internet of Things (IoT)-apparaten heeft de cyberbeveiligingsomgeving fundamenteel veranderd.
Aanvallen kunnen op elk moment en op elke plaats plaatsvinden.
Gelukkig hebben machine learning-algoritmen cyberbeveiligingsactiviteiten mogelijk gemaakt om deze snelle ontwikkelingen bij te houden.
Voorspellende analyse maakt snellere detectie en beperking van aanvallen mogelijk, terwijl machine learning uw activiteit binnen een netwerk kan analyseren om afwijkingen en zwakke punten in bestaande beveiligingsmechanismen te detecteren.
2. Automatisering van de klantenservice
Het beheren van een toenemend aantal online klantcontacten heeft veel organisatie onder druk gezet.
Ze hebben simpelweg niet genoeg personeel van de klantenservice om het aantal vragen dat ze ontvangen te behandelen, en de traditionele benadering van het uitbesteden van problemen naar een contactcentrum is gewoon onaanvaardbaar voor veel van de huidige klanten.
Chatbots en andere geautomatiseerde systemen kunnen nu aan deze eisen voldoen dankzij de vooruitgang in machine learning-technieken. Bedrijven kunnen personeel vrijmaken voor meer hoogwaardige klantenondersteuning door alledaagse activiteiten met lage prioriteit te automatiseren.
Bij correct gebruik kan machine learning in het bedrijfsleven helpen om de oplossing van problemen te stroomlijnen en consumenten het soort nuttige ondersteuning te bieden waardoor ze toegewijde merkkampioenen worden.
3. Mededeling
Het vermijden van fouten en misvattingen is van cruciaal belang in elk type communicatie, maar meer nog in de hedendaagse zakelijke communicatie.
Eenvoudige grammaticale fouten, onjuiste toon of foutieve vertalingen kunnen een reeks problemen veroorzaken bij e-mailcontact, klantevaluaties, videoconferentie, of op tekst gebaseerde documentatie in vele vormen.
Machine learning-systemen hebben geavanceerde communicatie die veel verder gaat dan de onstuimige dagen van Clippy van Microsoft.
Deze voorbeelden van machine learning hebben individuen geholpen om eenvoudig en nauwkeurig te communiceren door natuurlijke taalverwerking, realtime taalvertaling en spraakherkenning te gebruiken.
Hoewel veel mensen een hekel hebben aan de mogelijkheden voor autocorrectie, vinden ze het ook belangrijk om beschermd te worden tegen gênante fouten en ongepaste toon.
4. Objectherkenning
Hoewel de technologie om gegevens te verzamelen en te interpreteren al een tijdje bestaat, is het een bedrieglijk moeilijke taak gebleken om computersystemen te leren begrijpen waar ze naar kijken.
Objectherkenningsmogelijkheden worden toegevoegd aan een toenemend aantal apparaten vanwege machine learning-toepassingen.
Een zelfrijdende auto herkent bijvoorbeeld een andere auto wanneer hij er een ziet, zelfs als programmeurs hem geen exact voorbeeld van die auto hebben gegeven om als referentie te gebruiken.
Deze technologie wordt nu gebruikt in de detailhandel om het afrekenproces te versnellen. Camera's identificeren de producten in de winkelwagen van consumenten en kunnen automatisch hun rekeningen factureren wanneer ze de winkel verlaten.
5. Digitale marketing
Veel van de hedendaagse marketing gebeurt online, met behulp van een reeks digitale platforms en softwareprogramma's.
Terwijl bedrijven informatie verzamelen over hun consumenten en hun koopgedrag, kunnen marketingteams die informatie gebruiken om een gedetailleerd beeld van hun doelgroep op te bouwen en te ontdekken welke mensen meer geneigd zijn om naar hun producten en diensten te zoeken.
Algoritmen voor machine learning helpen marketeers bij het begrijpen van al die gegevens en het ontdekken van significante patronen en attributen waarmee ze mogelijkheden strak kunnen categoriseren.
Dezelfde technologie maakt grote digitale marketingautomatisering mogelijk. Advertentiesystemen kunnen worden opgezet om nieuwe potentiële consumenten dynamisch te ontdekken en hen op het juiste moment en op de juiste plaats relevante marketinginhoud te bieden.
Toekomst van machinaal leren
Machine learning wint zeker aan populariteit naarmate meer bedrijven en grote organisaties de technologie gebruiken om specifieke uitdagingen aan te pakken of innovatie te stimuleren.
Deze voortdurende investering toont aan dat we begrijpen dat machine learning ROI oplevert, met name door enkele van de bovengenoemde gevestigde en reproduceerbare use-cases.
Immers, als de technologie goed genoeg is voor Netflix, Facebook, Amazon, Google Maps, enzovoort, is de kans groot dat uw bedrijf ook het meeste uit zijn gegevens kan halen.
Als nieuw machine learning modellen worden ontwikkeld en gelanceerd, zullen we getuige zijn van een toename van het aantal toepassingen dat in alle sectoren zal worden gebruikt.
Dit gebeurt al met gezichtsherkenning, wat ooit een nieuwe functie op je iPhone was, maar nu wordt geïmplementeerd in een breed scala aan programma's en applicaties, met name die met betrekking tot openbare veiligheid.
De sleutel voor de meeste organisaties die aan de slag willen met machine learning, is voorbij de heldere futuristische visies te kijken en de echte zakelijke uitdagingen te ontdekken waarmee de technologie u kan helpen.
Conclusie
In het post-geïndustrialiseerde tijdperk hebben wetenschappers en professionals geprobeerd een computer te maken die zich meer als mensen gedraagt.
De denkmachine is de belangrijkste bijdrage van AI aan de mensheid; de fenomenale komst van deze zelfrijdende machine heeft de bedrijfsvoorschriften snel veranderd.
Zelfrijdende voertuigen, geautomatiseerde assistenten, autonome productiemedewerkers en slimme steden hebben de laatste tijd de levensvatbaarheid van slimme machines aangetoond. De revolutie van machine learning en de toekomst van machine learning zullen ons nog lang bijblijven.





Laat een reactie achter