Gegevensverplaatsing en -opslag zijn belangrijker geworden als gevolg van de constante uitbreiding van de IT-industrie en de miljoenen datapunten die elke seconde worden geproduceerd.
Bovendien moeten deze gegevens duidelijk en eenvoudig te begrijpen zijn om nauwkeurige besluitvorming te ondersteunen.
Om uw concurrentievermogen te behouden en succes op de lange termijn te behalen, moet uw bedrijf gegevens opslaan en verplaatsen met behulp van de meest efficiënte oplossingen die beschikbaar zijn.
Hierdoor maken steeds meer bedrijven gebruik van datafabrics. Een van de beste manieren om tijd, geld en middelen te besparen, is door een datafabric te gebruiken om gegevens te verwerken en AI-machine learning mogelijk te maken.
In dit artikel gaan we dieper in op Data Fabric, inclusief het gebruik, de belangrijkste onderdelen, voordelen en andere essentiële details.
Dus, wat is Data Fabric?
Waar ze zich ook bevinden, beheer en waak over uw gegevens en apps. In de kern is een datafabric een geïntegreerde data-architectuur die veilig, veelzijdig en aanpasbaar is.
Een datafabric, die het beste van de cloud, core en edge combineert, is in veel opzichten een nieuwe strategische benadering van uw zakelijke opslagactiviteiten.
Hoewel het centraal wordt beheerd, kan het overal worden bereikt, inclusief on-premises, openbare en privéclouds, evenals edge- en IoT-apparaten.
Gegevenssilo's ter grootte van wolkenkrabbers en diverse, niet-verbonden infrastructuren behoren tot het verleden. Een datafabric is gebaseerd op een uitgebreide verzameling gegevensbeheertools die consistentie garanderen in al uw gekoppelde omgevingen.
Door automatisering stroomlijnt u tijdrovend beheer, versnelt u ontwikkeling, testen en implementatie, en beveiligt u uw bedrijfsmiddelen de klok rond.
Waar uw gegevens en apps zich ook bevinden, u kunt opslagkosten, prestaties en efficiëntie bijhouden vanaf één enkel platform.
U kunt snel (en in sommige gevallen automatisch) wijzigingen aanbrengen in uw hybride cloudinfrastructuur zodra u er bruikbare kennis over heeft, zoals het oplossen van fouten, het aanpakken van beveiligings- en nalevingsproblemen en het op- en afschalen van computing.
Kortom, Data Fabric verbetert de efficiëntie van de implementatie en het onderhoud van de infrastructuur, verlaagt de kosten en verhoogt de prestaties.
Waarom zou u een Data Fabric gebruiken?
Elk datacentrisch bedrijf heeft een uitgebreide strategie nodig die obstakels zoals tijd, ruimte, verschillende soorten software en datalocaties overwint. Gegevens mogen niet worden verborgen achter firewalls of verspreid over meerdere plaatsen, maar moeten beschikbaar zijn voor mensen die ze nodig hebben.
Om te slagen, hebben bedrijven een toekomstbestendige data-oplossing en een veilige, effectieve en uniforme omgeving nodig. Dit kan met een datafabric.
Aan de behoeften van moderne bedrijven aan realtime verbinding, selfservice, automatisering en universele veranderingen kan niet worden voldaan door traditionele data-integratie.
Hoewel het verzamelen van gegevens uit vele bronnen vaak geen probleem is, worstelen veel bedrijven met het integreren, verwerken, beheren en transformeren van gegevens met gegevens uit andere bronnen.
Om een diepgaand inzicht te krijgen in consumenten, partners en goederen, moet deze cruciale stap in het gegevensbeheerproces plaatsvinden. Vanwege hun vermogen om hun systemen te upgraden, klanten beter van dienst te zijn en gebruik te maken van cloud computing, krijgen bedrijven hierdoor een concurrentievoordeel.
Waar de gebruikers van de organisatie zich ook bevinden, de datafabric kan worden voorgesteld als een doek dat wereldwijd wordt uitgespreid. Op dit netwerk kan de gebruiker zich op elke locatie bevinden en toch onbeperkte, realtime toegang hebben tot gegevens op elke andere locatie.
Kerncomponenten van Data Fabric
De kerncomponenten waaruit een datafabric bestaat, kunnen op verschillende manieren worden gekozen en verzameld. De datafabric kan dus op verschillende manieren worden geïmplementeerd. Laten we eens kijken naar de primaire elementen van een datafabric.
- Uitgebreide gegevenscatalogus
- Persistentie laag
- Kennis Grafiek
- Inzichten en Aanbevelingen Engine
- Gegevensvoorbereiding en gegevensleveringslaag
- Orkestratie en gegevensverwerking
U kunt de belangrijkste pijlers van de Data Fabric-architectuur bekijken volgens: Gartner.
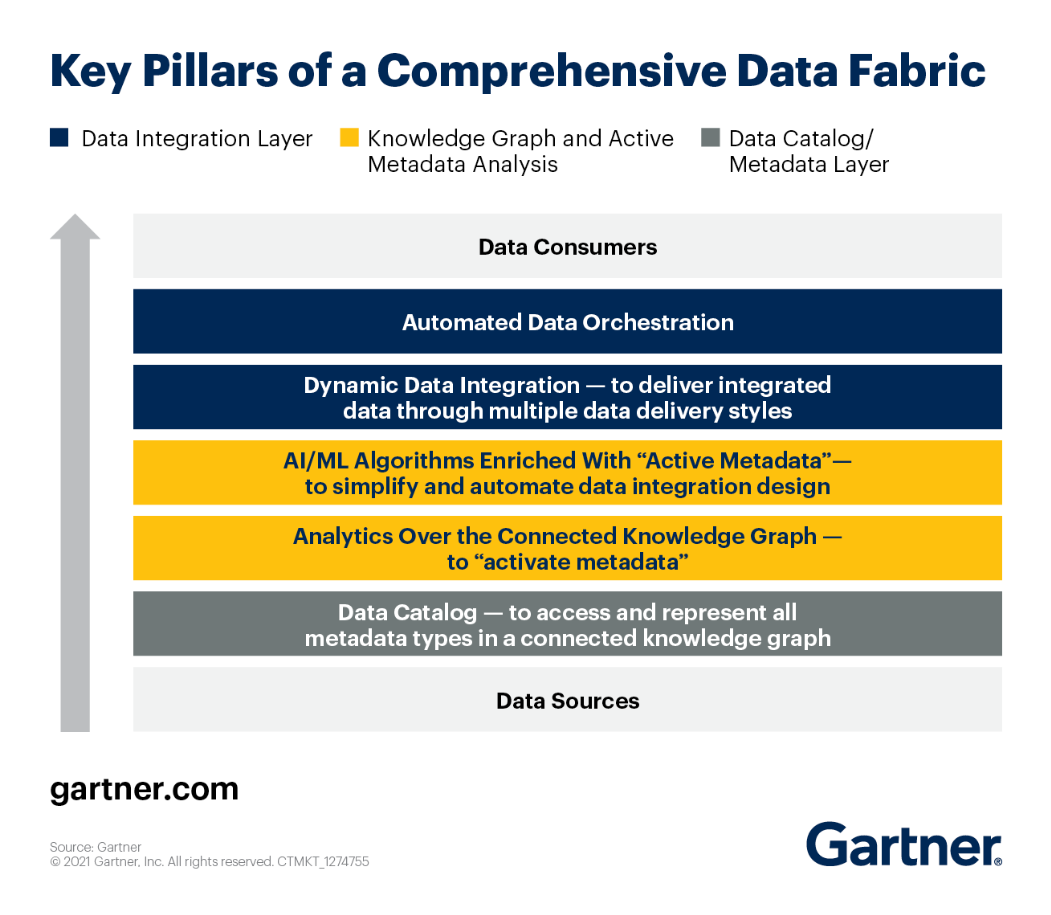
Laten we elk van hen eens nader bekijken.
- Uitgebreide datacatalogus – geeft gebruikers toegang tot allerlei metadata via een sterke kennisgrafiek. Daarnaast ontwikkelt het onderscheidende associaties tussen bestaande informatie en toont deze visueel op een begrijpelijke manier. Door het gebruiken van machine learning om data-assets te koppelen aan organisatieterminologie, creëren verbeterde datacatalogi de zakelijke semantische laag voor de datafabric.
- Persistentie laag – Afhankelijk van de use case kan een verscheidenheid aan relationele en niet-relationele modellen worden gebruikt om gegevens dynamisch op te slaan.
- Actieve metagegevens – een onderscheidend onderdeel van een datafabric. geeft de datafabric de mogelijkheid om vele soorten metadata te verzamelen, te delen en te analyseren. In tegenstelling tot passieve metadata volgt actieve metadata het voortdurende gebruik van data door systemen en mensen (design-based en runtime metadata).
- Kennis Grafiek – Nog een fundamentele eenheid voor datafabrics. Ze gebruiken standaard ID's, aanpasbare schema's, enz. om een gekoppelde data-omgeving weer te geven. Kennisgrafieken maken de datafabric doorzoekbaar en helpen bij het begrijpen ervan.
- Inzichten en aanbevelingsengine – bouwt betrouwbare, sterke datapijplijnen voor zowel operationele als analytische use cases.
- Gegevensvoorbereiding en gegevensleveringslaag – Gegevens kunnen van elke bron worden opgehaald en naar elk doel worden verzonden met elk mechanisme, inclusief ETL (bulk), berichten, CDC, virtualisatie en API.
- Orkestratie en gegevensverwerking – Dit onderdeel gebruikt gegevens om alle taken in elke fase van de end-to-end-workflow te coördineren. Hiermee kunt u kiezen wanneer en hoe vaak pijplijnen moeten worden uitgevoerd en hoe u de gegevens beheert die deze pijplijnen produceren.
Voordelen
Gezonde gegevens in een gedistribueerde context zijn toegankelijk, geladen, geïntegreerd en gedeeld via een datafabric. Door dit te doen, kunnen bedrijven de digitale transitie versnellen en de waarde van hun data maximaliseren.
Hieronder worden de belangrijkste voordelen van het datafabricmodel uiteengezet.
Efficiëntie:
Een datafabric kan resultaten van eerdere query's compileren, waardoor het systeem de geaggregeerde tabel kan scannen in plaats van de onbewerkte gegevens in de backend.
Vanwege de snellere reactietijden van individuele verzoeken, lost het probleem van meerdere gelijktijdige verzoeken ook op als verzoeken toegang krijgen tot kleinere datasets in plaats van de onbewerkte gegevens van de volledige winkel te moeten scannen.
Ondernemingen kunnen snel reageren op dringende vragen vanwege het vermogen van de datafabric om de reactietijd voor vragen aanzienlijk te verkorten.
Slimme integratie
Om gegevens over verschillende soorten gegevens en eindpunten te integreren, maken datafabrics gebruik van semantische kennisgrafieken, metagegevensbeheer en machine learning.
Dit helpt datamanagementteams om relevante datasets te groeperen en gloednieuwe databronnen op te nemen in het data-ecosysteem van een bedrijf.
Deze functie automatiseert delen van het gegevenstaakbeheer, wat resulteert in de hierboven vermelde productiviteitsbesparingen, maar het helpt ook bij het doorbreken van gegevenssysteemsilo's, het centraliseren van procedures voor gegevensbeheer en het verbeteren van de algehele gegevenskwaliteit.
Effectievere gegevensbeveiliging
Het betekent ook niet dat gegevensbeveiliging en privacybescherming moeten worden opgeofferd om de toegang tot gegevens uit te breiden.
Het vereist in feite de aanscherping van de vangrails voor toegangscontrole en de implementatie van meer maatregelen op het gebied van datagovernance om te garanderen dat bepaalde rollen de enige zijn die toegang hebben tot een bepaalde set gegevens.
Bovendien maken datafabric-architecturen technische en beveiligingsteams om gegevensmaskering te implementeren en encryptie rond vertrouwelijke en gevoelige informatie, waardoor de kans op het delen van gegevens en systeemhacks wordt verkleind.
Democratisering van gegevens
Selfservice-applicaties worden gefaciliteerd door datafabric-ontwerpen, waardoor het bereik van datatoegang wordt uitgebreid tot meer technisch personeel zoals data-engineers, ontwikkelaars en data-analyseteams.
Door zakelijke gebruikers in staat te stellen snellere zakelijke keuzes te maken en door technische gebruikers vrij te laten om prioriteiten te stellen voor activiteiten die hun vaardigheden het beste gebruiken, leidt het elimineren van gegevensknelpunten tot een verhoging van de productiviteit.
Use cases
Een datafabric-architectuur is bedoeld om een overkoepelende structuur te bieden voor het verwerken van alle vormen van de opgeslagen informatie, zodat ze bruikbaar kunnen worden gemaakt wanneer dat nodig is.
Dit soort gegevens kan voor alles worden gebruikt, van een verkoopvoorspelling tot een rapport over de status van de IT-infrastructuur van een organisatie of gebruikerseindpunten.
Gebruiksscenario's voor datafabricarchitectuur zijn identiek aan gebruiksscenario's voor andere soorten gegevens in een bedrijf, waaronder verkoop, marketing, IT, cyberbeveiliging en meer.
Gegevens in een organisatie zijn echter in bijna alle gevallen vaak georganiseerd, semi-gestructureerd of ongestructureerd. Een relationele database kan gestructureerde gegevens opslaan en onmiddellijk worden gebruikt, zoals databaserecords.
Gegevens die niet zijn opgeschoond of gecategoriseerd, worden ongestructureerde gegevens genoemd en moeten indien nodig worden voorbereid voor gebruik.
Verschillende vormen van ongestructureerde gegevens die veel bedrijven kunnen verkrijgen en opslaan voor toekomstig gebruik zijn onder meer: machine learning, analytics, sensordata, cloud computing en productiviteitsapps.
In semi-gestructureerde gegevens, waaronder gegevens van een erkende soort die zijn opgeslagen met ongestructureerde gegevens (zoals zip-bestanden, webpagina's en e-mails), zijn beide aspecten aanwezig.
Door het gebruik ervan te onderzoeken, kunnen tal van mogelijke use-cases worden gevonden op basis van het vermogen van de datafabric om bedrijven te helpen bij het sneller en effectiever toegang krijgen tot en gebruik maken van hun gegevens.
Typische voorbeelden zijn:
- Fraude detectie
- IoT-analyse
- Supply chain logistiek
- Realtime gegevensanalyse
- Klantinformatie
- Verhoogde operationele efficiëntie
- Analyse van preventief onderhoud
- Bovendien, risicomodellen voor terugkeer naar werk
- Transacties beveiligen met creditcards
- Churn-voorspelling, fraudedetectie en kredietscores
Conclusie
Kortom, datasilo's moeten geleidelijk aan desintegreren naarmate ons datagebruik toeneemt om ruimte te maken voor verbonden bedrijven.
De inzet van datafabrics betekent een aanzienlijke vooruitgang op dit pad en behoort tot de meest baanbrekende ontdekkingen sinds de ontwikkeling van relationele databases in de jaren zeventig.
Dit komt omdat datafabric meer is dan een technologie of een enkel item.
Data en bedrijfsvoering zijn nauw met elkaar verweven door het ontwerpen van architectuur, een systematische procedure en een mentaliteitsverandering.
Data Fabric verlaagt de kosten, verbetert de prestaties en maakt een effectievere implementatie en onderhoud van de infrastructuur mogelijk. Het kan de belangrijkste component zijn om ervoor te zorgen dat elk proces, elke toepassing en de zakelijke beslissing gegevensgestuurd is.





Laat een reactie achter