Inhoudsopgave[Zich verstoppen][Laten zien]
Grote tekst-naar-beeld-modellen hebben een aanzienlijke vooruitgang geboekt in de ontwikkeling van AI door hoogwaardige en gediversifieerde beeldsynthese te produceren op basis van een bepaalde tekstprompt.
Deze modellen zijn niet in staat om unieke representaties van onderwerpen in verschillende omgevingen te synthetiseren of om het uiterlijk van onderwerpen in een bepaalde referentieset te repliceren.
Nieuw uitgebrachte technologieën zoals OpenAI's DALL.E2 of StabilityAI's Stabiele diffusie en Midjourney veroveren het internet al stormenderhand. Het is nu tijd om de resultaten aan te passen. Maar hoe?
Google DreamBooth AI is gearriveerd.
DreamBooth heeft het vermogen om het onderwerp van een foto te herkennen, het uit zijn oorspronkelijke context te deconstrueren en het vervolgens precies te synthetiseren tot een nieuwe gewenste context. Bovendien kan het worden gebruikt met de huidige AI-beeldgeneratoren.
In dit artikel gaan we dieper in op DreamBooth, het gebruik, de zelfstudie, de beperkingen en nog veel meer.
Wat is Dreambooth?
droomcabine, een gloednieuw tekst-naar-beeld-diffusiemodel, werd gepresenteerd door Google. Een schriftelijke prompt kan door Google DreamBooth AI worden gebruikt als leidraad om een breed scala aan foto's van het door de gebruiker geselecteerde onderwerp in verschillende instellingen te genereren.
Een onderzoeksgroep van Boston University en Google ontwikkelde DreamBooth, een geavanceerde techniek voor het wijzigen van tekst-naar-beeldmodellen die een uitgebreide vooropleiding hebben ondergaan.
Het algemene concept is vrij eenvoudig: ze willen het woordenboek voor taalvisie uitbreiden zodat ongebruikelijke token-ID's worden gekoppeld aan aangepaste onderwerpen die gebruikers kunnen definiëren.
Het belangrijkste doel van het model is om gebruikers te verbinden met de tekst-naar-beeld diffusiemodel door ze de middelen te geven die ze nodig hebben om fotorealistische weergaven te maken van de voorbeelden van hun geselecteerde onderwerp.
Als gevolg hiervan lijkt deze techniek goed te werken voor het samenvatten van uitdagingen in verschillende situaties.
DreamBooth van Google verschilt van eerdere tekst-naar-afbeelding-tools, zoals DALL-E2, Stabiele diffusie en halverwege de reis, in die zin dat het gebruikers meer controle geeft over het onderwerpbeeld voordat ze het diffusiemodel kunnen manipuleren met behulp van op tekst gebaseerde invoer.
Voordelen
- DreamBooth AI zou een tekst-naar-afbeelding-model kunnen verbeteren met 3-5 afbeeldingen.
- Met DreamBooth AI kunnen originele fotorealistische foto's worden gemaakt.
- Bovendien kan de DreamBooth AI foto's maken van een onderwerp vanuit meerdere hoeken.
Aanvraag
Kunstuitvoeringen
Deze taak verschilt specifiek van stijloverdracht, waarbij de semantiek van de bronscène behouden blijft terwijl de stijl van een andere afbeelding in de originele scène wordt opgenomen.

Op basis van de creatieve benadering kan de AI aanzienlijke scènewijzigingen doorvoeren met behoud van de identificatie en de specifieke kenmerken van de onderwerpinstantie.
Eigenschap Wijziging
De kenmerken van de betreffende instantie kunnen worden gewijzigd door DreamBooth AI.

Accessoires
De sterke compositie voorafgaand aan het generatiemodel maakt het vermogen van DreamBooth AI om objecten te versieren zo interessant.

Recontextualisering
DreamBooth AI kan onderscheidende afbeeldingen produceren voor een bepaalde onderwerpinstantie door een getraind model een zin te geven die de unieke identifier en het klasse-zelfstandig naamwoord bevat.

Het kan het onderwerp genereren in unieke, voorheen ongehoorde houdingen, articulaties en scènestructuur in plaats van de omgeving te veranderen. Realistische reflecties en schaduwen, evenals interacties tussen het onderwerp en omringende objecten.
Dreambooth-zelfstudie
In deze zelfstudie volgen we de Google Collab-notitieblok, en ik zal je er doorheen leiden, waardoor je het zelf zult begrijpen en gebruiken.
GPU instellen en bibliotheken installeren
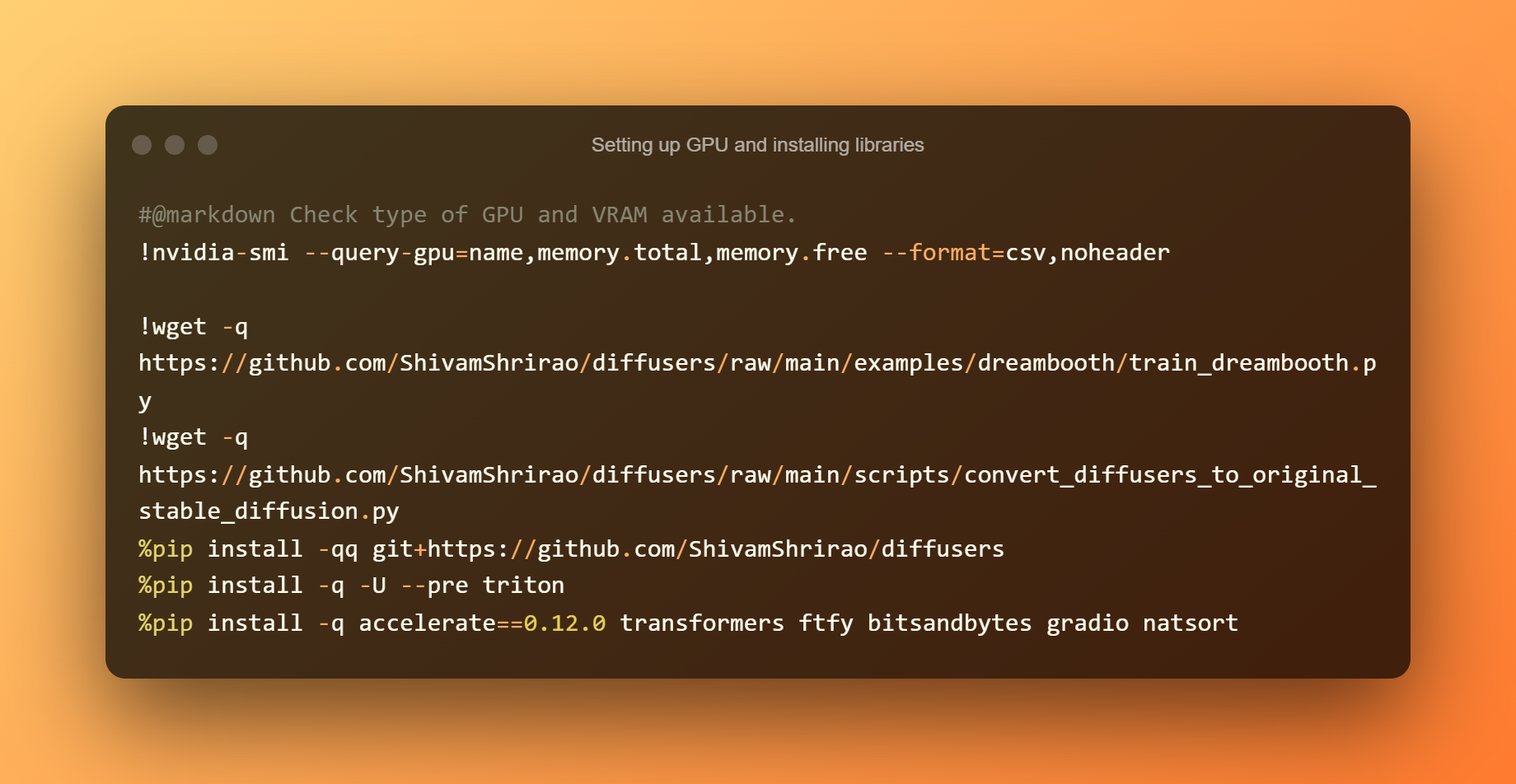
Uitzoeken welke GPU- en VRAM-soorten beschikbaar zijn, is de eerste stap. Het installeren van enkele vereisten en afhankelijkheden is ook noodzakelijk. Druk gewoon op de afspeelknop en wacht tot het klaar is.
Maak een account aan op Huggingface en genereer een token
De volgende stap is het registreren voor een Huggingface-account. Als je klaar bent, klik je op instellingen in de rechterbovenhoek. U komt op de volgende pagina.
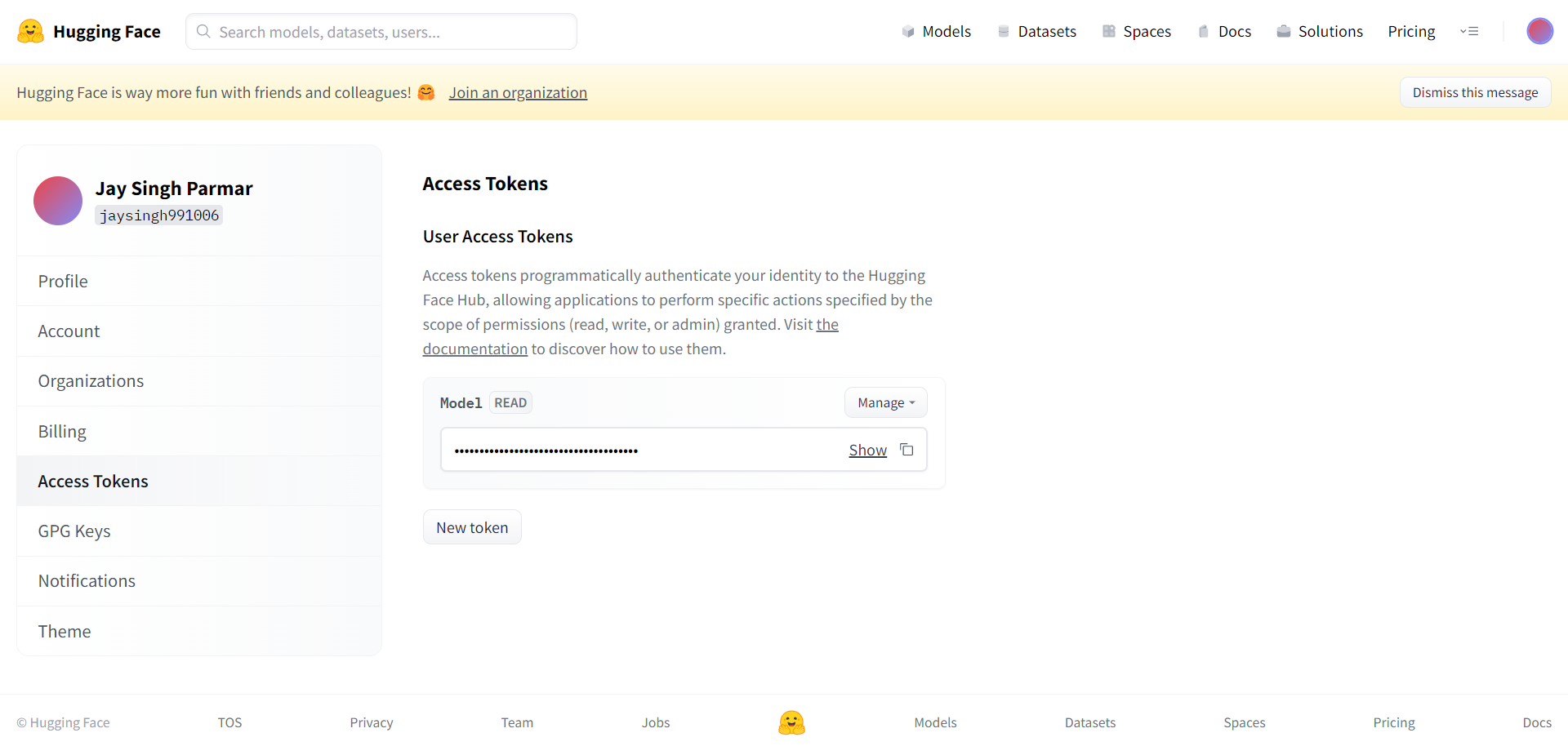
Maak het token en de naam aan zoals gevraagd vanaf hier. Het token moet worden gekopieerd en geplakt in de Google-samenwerking in de onderstaande cel.

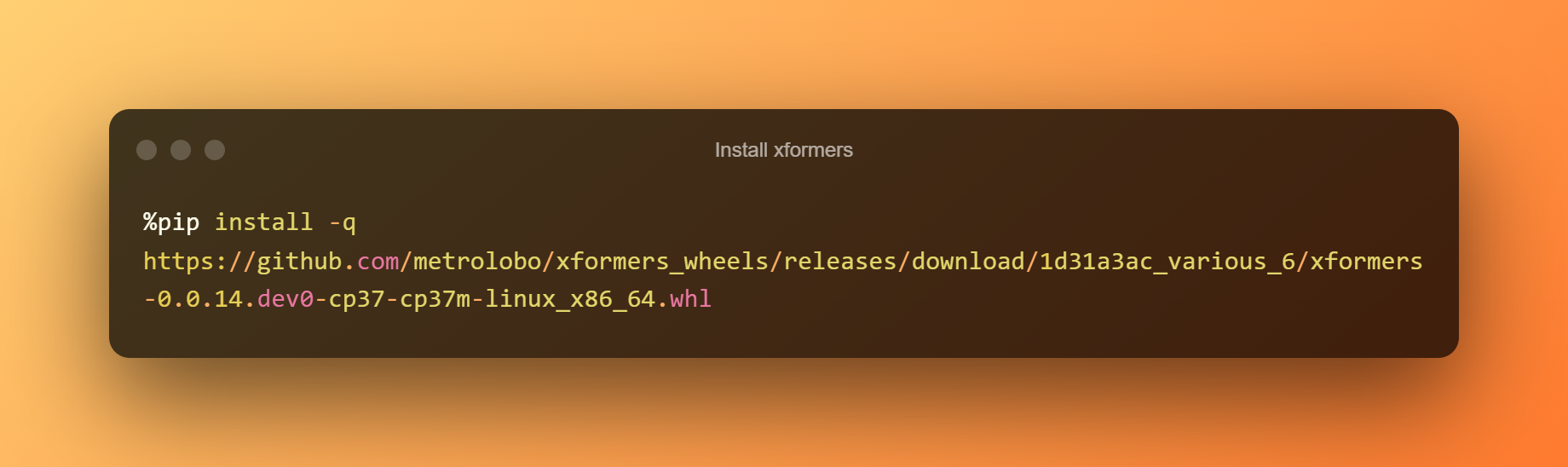
Installeer xformers
In deze fase kunt u eenvoudig op de afspeelknop drukken om xformers te installeren door op de looptijd te klikken.
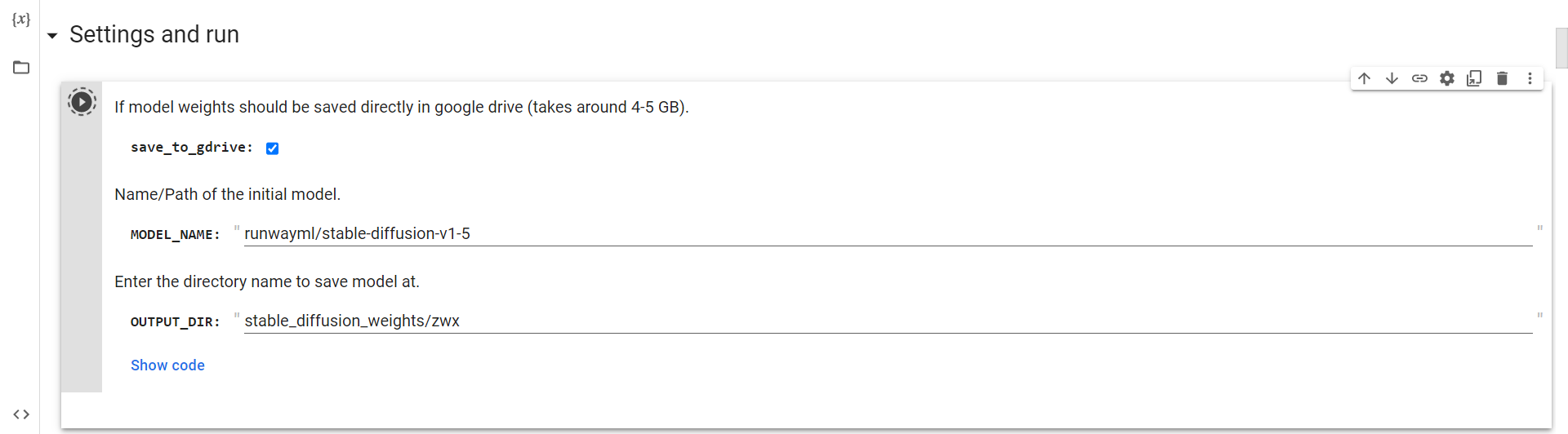
Maak verbinding met Drive
Nu hoef je alleen maar deze cel uit te voeren om verbinding te maken met Google Drive.
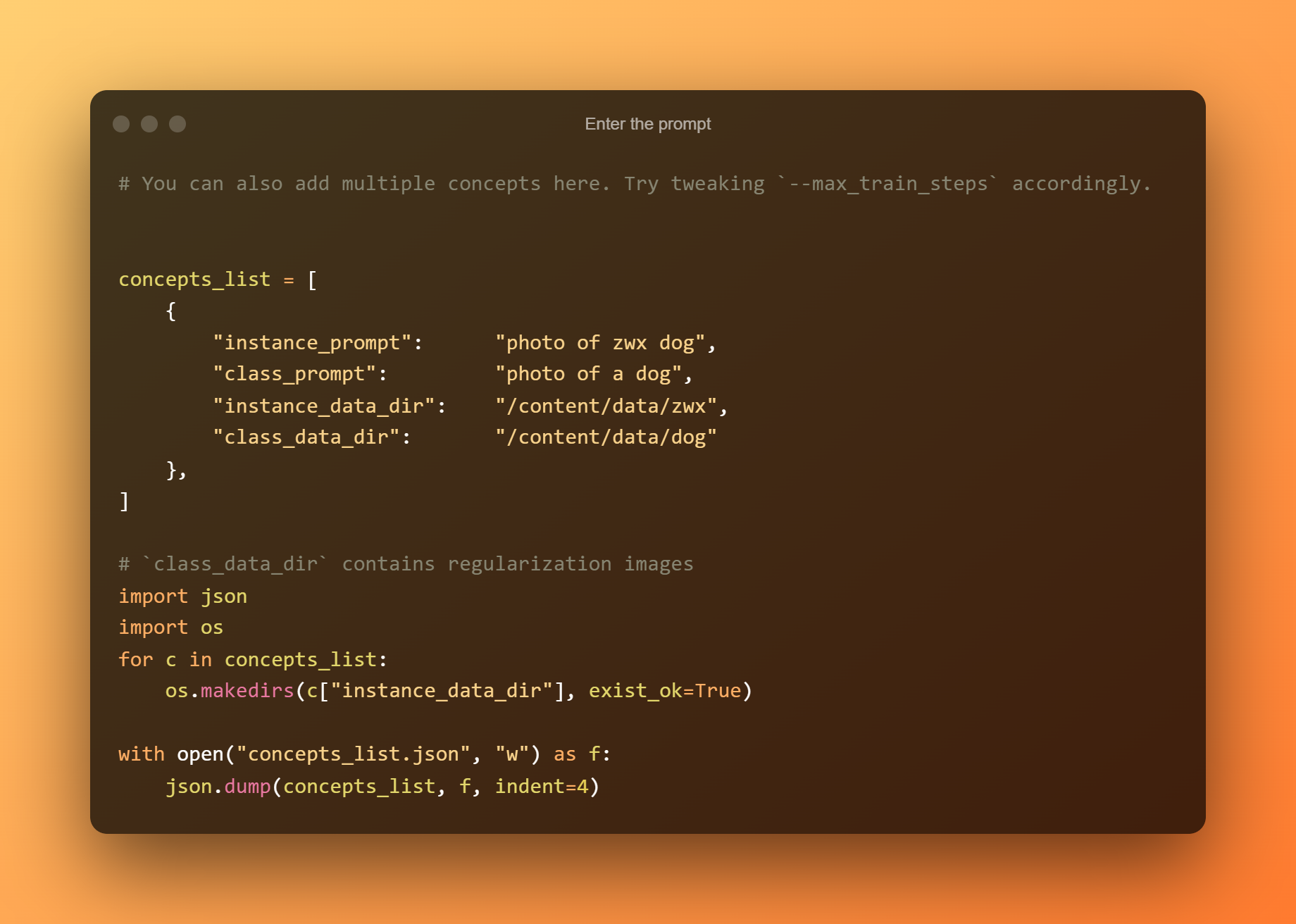
Voer de prompt in
In de volgende cel hoeft u alleen maar de prompt in te voeren.
Afbeeldingen uploaden
In deze stap hoef je alleen maar de foto's te uploaden die je wilde trainen.

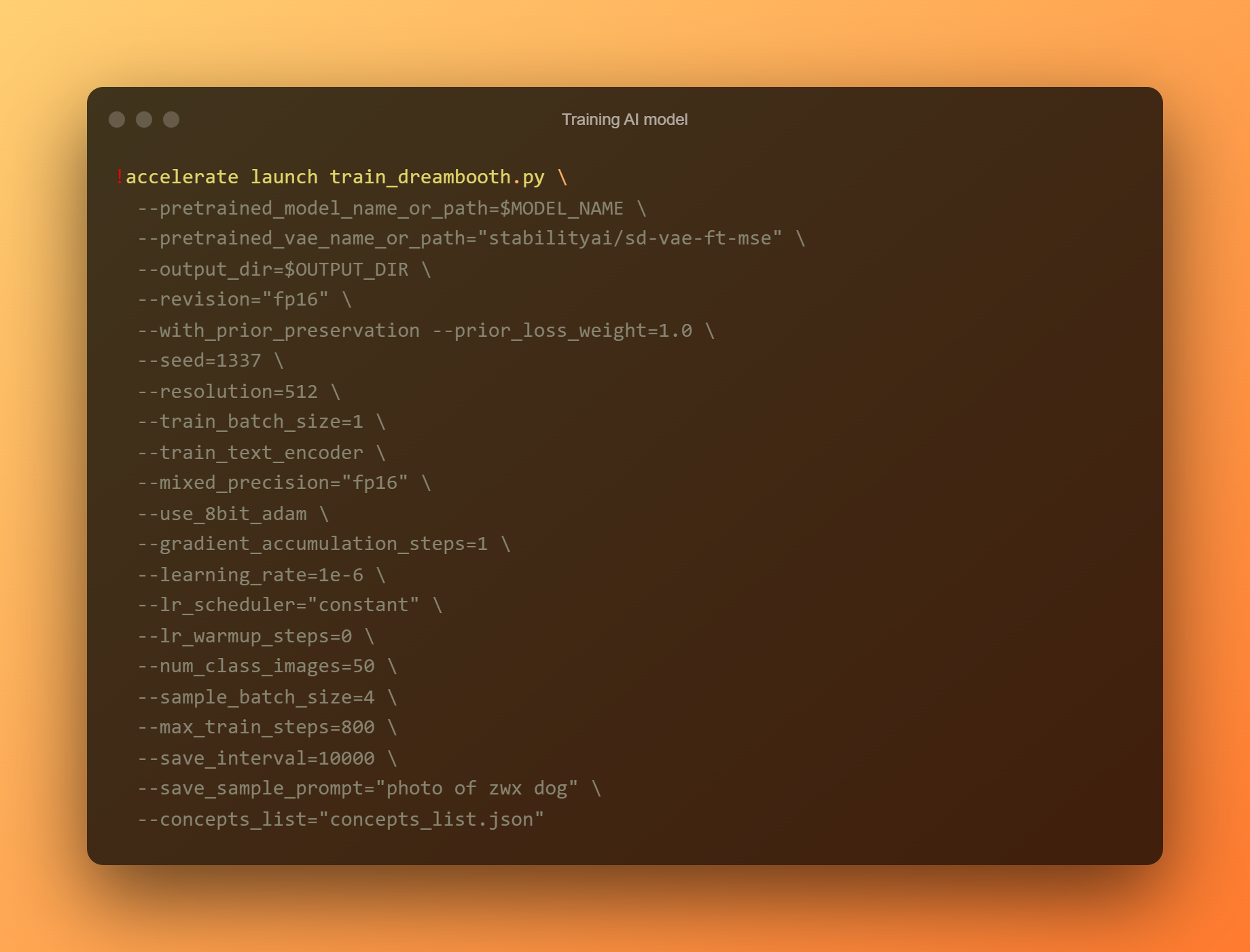
AI-model trainen
Dit is de belangrijkste fase, aangezien je DreamBooth gaat gebruiken om een nieuw AI-model te trainen op basis van al je ingediende referentiefoto's. U moet uw aandacht beperken tot twee invoervelden. "—instance prompt" is de eerste parameter. U moet hier een zeer duidelijke naam opgeven.
Het argument '–conceptenlijst' is het tweede kritische invoerveld. Het moet worden hernoemd zodat het overeenkomt met de naam die wordt gebruikt in het gedeelte 'Wijzig de prompt'.
Genereer AI-afbeeldingen
In dit stadium worden de AI-afbeeldingen gemaakt, waar u de tekstinstructies kunt invoeren.

Dreambooth-beperkingen
- De opdrachtprompt wordt een belemmering voor het maken van iteraties in het onderwerp met een hoge mate van detail. DreamBooth kan de context van het onderwerp veranderen, maar als het model het onderwerp zelf wil veranderen, zijn er problemen met het kader.
- Een ander probleem is dat het uitvoerbeeld te veel past bij het invoerbeeld. Als er niet genoeg foto's worden aangeleverd, wordt het onderwerp mogelijk niet in overweging genomen of wordt het vermengd met de context van de ingezonden afbeeldingen. Wanneer een context voor een vreemde generatie wordt gevraagd, gebeurt hetzelfde.
Conclusie
Om uitvoer te produceren van een enkele tekstinvoer, heeft het merendeel van de tekst-naar-afbeelding-modellen miljoenen parameters en bibliotheken nodig.
DreamBooth vereenvoudigt de verwerving en het gebruik van inhoud voor consumenten door slechts de invoer van drie tot vijf onderwerpfoto's samen met een tekstuele achtergrond te vereisen.





Laat een reactie achter