Inhoudsopgave[Zich verstoppen][Laten zien]
Bedrijven leggen meer gegevens vast dan ooit, omdat ze er steeds meer op vertrouwen om belangrijke zakelijke beslissingen te nemen, het productaanbod te verbeteren en een betere klantenservice te bieden.
Nu de hoeveelheid gegevens exponentieel wordt gecreëerd, biedt de cloud verschillende voordelen voor gegevensverwerking en -analyse, waaronder schaalbaarheid, betrouwbaarheid en beschikbaarheid.
In het cloud-ecosysteem zijn er ook verschillende tools en technologieën voor gegevensverwerking en -analyse. De twee soorten big data-opslagstructuren die het meest worden gebruikt, zijn datawarehouses en datalakes.
Hoewel het gebruik van een data lake minder aantrekkelijk is, omdat je het model en de gegevens niet kunt opvragen zolang het nog relevant is, is het gebruik van een datawarehouse voor streaming dataopslag verspilling.

Wwelk type cloudarchitectuur kiezen we?
Moeten we nieuwere concepten overwegen voor het data-lakehouse, of moeten we tevreden zijn met de beperkingen van het magazijn of de beperkingen van het meer?
Een nieuwe architectuur voor gegevensopslag, een "data lakehouse" genaamd, combineert het aanpassingsvermogen van datameren met het gegevensbeheer van datawarehouses.
Het begrijpen van de verschillende opslagmethoden voor big data is essentieel voor het bouwen van een betrouwbare dataopslagpijplijn voor business intelligence (BI), data-analyse en machine learning (ML) workloads, afhankelijk van de eisen van uw bedrijf.
In dit bericht zullen we Data Warehouse, Data Lake en Data Lakehouse nauwkeurig bekijken, met hun voordelen, beperkingen en voor- en nadelen. Laten we beginnen.
Wat is datawarehouse?
Een datawarehouse is een gecentraliseerde gegevensopslagplaats die door een organisatie wordt gebruikt om enorme hoeveelheden gegevens uit vele bronnen te bewaren. Een datawarehouse fungeert als de enige bron van 'gegevenswaarheid' van een organisatie en is essentieel voor rapportage en bedrijfsanalyse.
Doorgaans combineren datawarehouses relationele gegevenssets uit verschillende bronnen, zoals applicatie-, bedrijfs- en transactiegegevens, om historische gegevens op te slaan. Voordat ze in het warehousingsysteem worden geladen, worden gegevens getransformeerd en opgeschoond in datawarehouses, zodat ze kunnen worden gebruikt als een enkele bron van gegevenswaarheid.
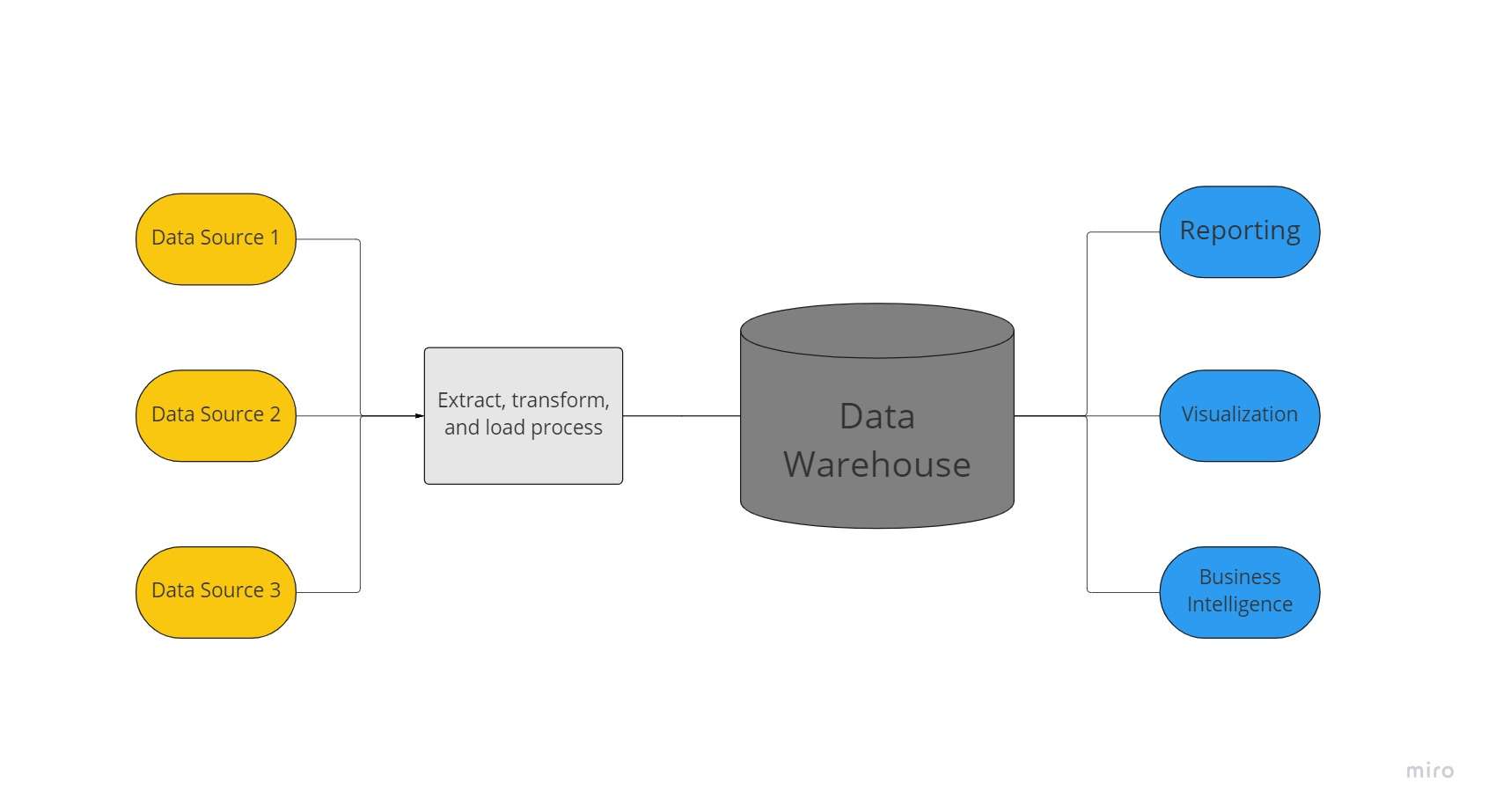
Vanwege hun vermogen om snel zakelijke inzichten uit alle delen van het bedrijf te bieden, investeren bedrijven in datawarehouses. Met het gebruik van BI-tools, SQL-clients en andere minder geavanceerde (dwz niet-gegevenswetenschappelijke) analyseoplossingen, bedrijfsanalisten, data-engineers en besluitvormers hebben toegang tot gegevens uit datawarehouses.
Het is duur om een magazijn te onderhouden met de steeds groter wordende hoeveelheid data, en een datawarehouse kan geen ruwe of ongestructureerde data aan. Bovendien is het niet de ideale optie voor geavanceerde data-analysetechnieken zoals machine learning of voorspellende modellering.
Een datawarehouse zorgt dus voor snellere query-antwoorden en data van een hogere kwaliteit. Google Big Query, Amazon Redshift, Azure SQL Datawarehouse en Snowflake zijn cloudservices die beschikbaar zijn voor datawarehouses.
Voordelen van datawarehouse
- Verhogen van de efficiëntie en snelheid van business intelligence en data-analyse-workloads: Datawarehouses verkorten de tijd die nodig is voor gegevensvoorbereiding en -analyse. Ze kunnen eenvoudig worden gekoppeld aan tools voor data-analyse en business intelligence, aangezien de gegevens uit het datawarehouse betrouwbaar en consistent zijn. Bovendien besparen datawarehouses de tijd die nodig is voor het verzamelen van gegevens en bieden ze teams de mogelijkheid om gegevens te gebruiken voor rapporten, dashboards en andere analysevereisten.
- Het verhogen van de consistentie, kwaliteit en standaardisatie van data: Organisaties verzamelen gegevens uit verschillende bronnen, waaronder gebruikers-, verkoop- en transactiegegevens. Het bedrijf kan de gegevens vertrouwen voor zakelijke vereisten, omdat datawarehousing bedrijfsgegevens verzamelt in een uniform, gestandaardiseerd formaat dat kan fungeren als een enkele bron van gegevenswaarheid.
- Verbetering van de besluitvorming in het algemeen: Datawarehousing vergemakkelijkt betere besluitvorming door een gecentraliseerde opslag aan te bieden voor zowel recente als oude gegevens. Door gegevens in datawarehouses te verwerken voor nauwkeurige inzichten, kunnen besluitvormers risico's beoordelen, de wensen van de klant begrijpen en goederen en diensten verbeteren.
- Betere bedrijfsinformatie leveren: Datawarehousing overbrugt de kloof tussen enorme ruwe data, die regelmatig routinematig wordt verzameld, en de gecureerde data die inzichten verschaffen. Ze vormen de basis voor de gegevensopslag van een organisatie, waardoor ze ingewikkelde vragen over haar gegevens kan beantwoorden en de antwoorden kan gebruiken om verdedigbare zakelijke beslissingen te nemen.
Beperkingen van het datawarehouse
- Gebrek aan dataflexibiliteit: Hoewel datawarehouses uitblinken in het verwerken van gestructureerde gegevens, kunnen semi-gestructureerde en ongestructureerde gegevensindelingen zoals loganalyse, streaming en gegevens van sociale media een uitdaging voor hen zijn. Dit maakt het aanbevelen van datawarehouses voor use cases met machine learning en kunstmatige intelligentie moeilijk.
- Kostbaar om te installeren en te onderhouden: Datawarehouses kunnen duur zijn om te installeren en te onderhouden. Bovendien is het datawarehouse vaak niet statisch; het veroudert en heeft regelmatig onderhoud nodig, wat duur is.
VOORDELEN
- Gegevens zijn eenvoudig te vinden, op te halen en op te vragen.
- Zolang de gegevens al schoon zijn, is de voorbereiding van SQL-gegevens eenvoudig.
NADELEN
- U bent gedwongen om slechts één analyseleverancier te gebruiken.
- Het analyseren en opslaan van ongestructureerde of stromende gegevens is behoorlijk kostbaar.
Wat is Data Lake?
Elk type data wordt beloofd en mogelijk gemaakt door datalakes. Het is gunstig om gegevens op een toegankelijke manier centraal gelokaliseerd en beschikbaar te hebben om uit te lezen.
Een data lake is een gecentraliseerde, uiterst aanpasbare opslagruimte waar enorme hoeveelheden georganiseerde en ongestructureerde gegevens worden bewaard in hun onverwerkte, ongewijzigde en ongeformatteerde vorm.
Een datameer maakt gebruik van een platte architectuur en objecten die in onbewerkte staat zijn opgeslagen om gegevens op te slaan, in tegenstelling tot datawarehouses, die relationele gegevens opslaan die eerder zijn 'opgeschoond'.
Datameren zijn, in tegenstelling tot datawarehouses, die moeite hebben met het verwerken van gegevens in dit formaat, aanpasbaar, betrouwbaar en betaalbaar en stellen ondernemingen in staat meer inzicht te krijgen in ongestructureerde gegevens.
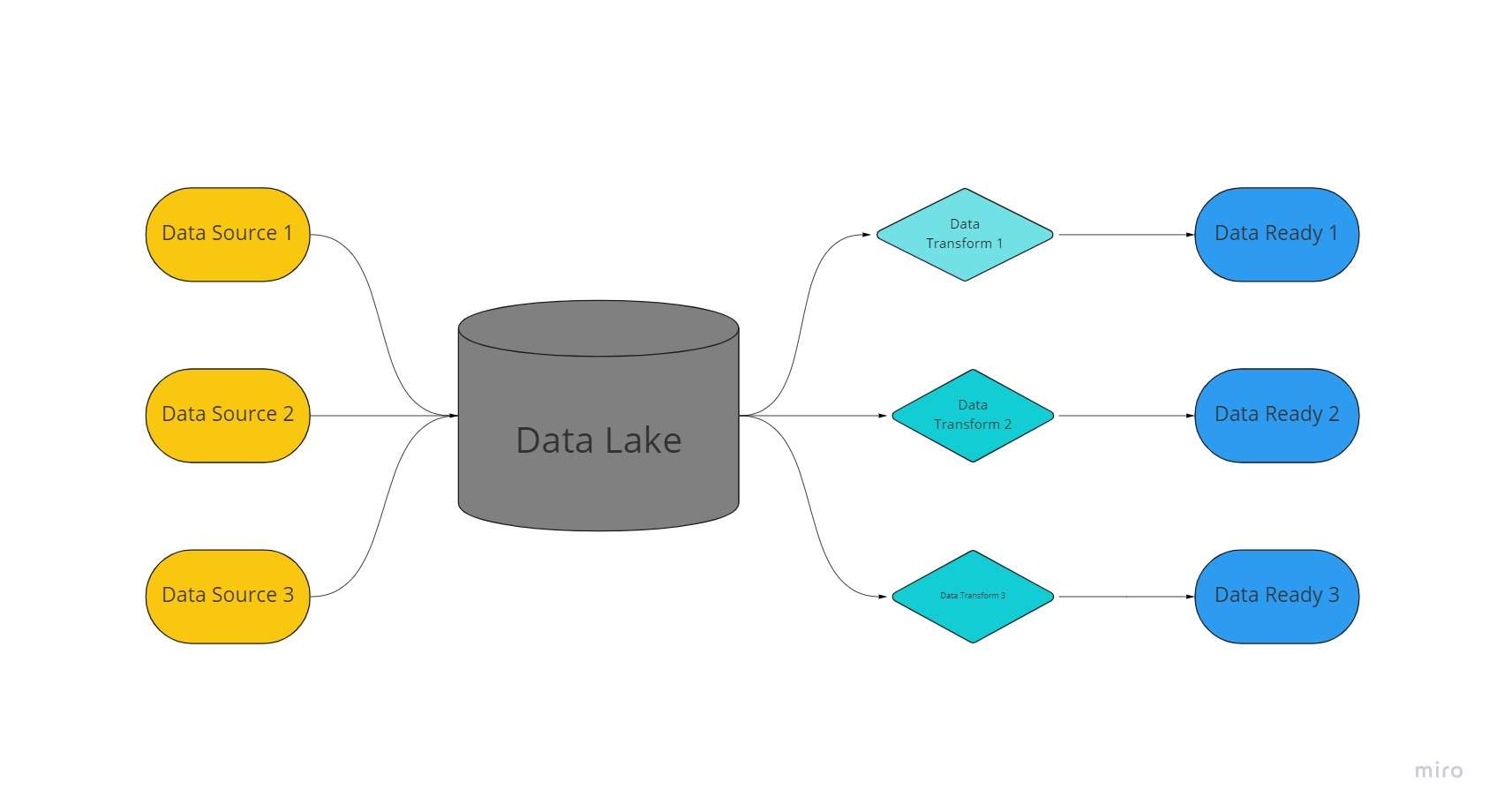
In datameren worden gegevens geëxtraheerd, geladen en getransformeerd (ELT) voor analytische doeleinden in plaats van dat het schema of de gegevens worden vastgesteld op het moment van gegevensverzameling.
Gebruikmakend van technologieën voor veel gegevenssoorten van IoT-apparaten, social mediaen streaming data, data lakes maken machine learning en voorspellende analyses mogelijk.
Daarnaast kan een datawetenschapper die ruwe data kan verwerken het datameer gebruiken. Een datawarehouse daarentegen is voor bedrijven gemakkelijker in het gebruik. Het is perfect voor gebruikersprofilering, predictive analytics, machine learning en andere taken.
Hoewel datalakes verschillende problemen met datawarehouses oplossen, is hun datakwaliteit slecht en is hun querysnelheid onvoldoende. Bovendien zijn er extra tools nodig voor zakelijke gebruikers om SQL-query's uit te voeren. Een datameer dat slecht gestructureerd is, kan te maken krijgen met datastagnatie.
Voordelen van Data Lake
- Ondersteuning voor een breed scala aan toepassingen voor machine learning en data science. Het is eenvoudiger om een andere machine en deep learning-algoritmen te gebruiken om de gegevens in datalakes te verwerken, aangezien de gegevens op een open, onbewerkte manier worden bewaard.
- De veelzijdigheid van datalakes, waarmee u gegevens in elk formaat of medium kunt opslaan zonder dat u een vooraf ingesteld schema nodig heeft, is een groot voordeel. Toekomstige gevallen van gegevensgebruik kunnen worden ondersteund en er kunnen meer gegevens worden geanalyseerd als de gegevens in de oorspronkelijke staat worden gelaten.
- Om te voorkomen dat beide soorten data in verschillende contexten moeten worden opgeslagen, kunnen datalakes zowel gestructureerde als ongestructureerde data bevatten. Voor de opslag van verschillende soorten organisatiegegevens bieden zij één locatie.
- In vergelijking met traditionele datawarehouses zijn datalakes goedkoper omdat ze zijn gebouwd om te worden bewaard op goedkope basishardware, zoals objectopslag, die vaak is afgestemd op lagere kosten per opgeslagen gigabyte.
Beperkingen van Data Lake
- Gebruiksscenario's voor data-analyse en business intelligence scoren slecht: datameren kunnen ongeorganiseerd raken als ze niet adequaat worden onderhouden, waardoor het moeilijk is om ze te koppelen aan business intelligence- en analysetools. Bovendien, indien nodig voor gebruiksgevallen voor rapportage en analyse, een gebrek aan consistente data structuren en ACID (atomiciteit, consistentie, isolatie en duurzaamheid) transactionele ondersteuning kan leiden tot suboptimale queryprestaties.
- De inconsistentie van datameren maakt het onmogelijk om gegevensbetrouwbaarheid en -beveiliging af te dwingen, wat resulteert in een gebrek aan beide. Het kan moeilijk zijn om geschikte gegevensbeveiligings- en governancestandaarden te ontwikkelen om tegemoet te komen aan gevoelige gegevenstypen, aangezien datameren elke gegevensvorm aankunnen.
VOORDELEN
- Oplossingen die betaalbaar zijn voor alle soorten data.
- Kan omgaan met gegevens die zowel georganiseerd als semi-gestructureerd zijn.
- Ideaal voor gecompliceerde gegevensverwerking en streaming.
NADELEN
- Er moet een geavanceerde pijpleiding worden gebouwd.
- Geef gegevens wat tijd om bevraagbaar te worden.
- Het kost tijd om de betrouwbaarheid en kwaliteit van gegevens te garanderen.
Wat is Data Lakehouse?
Een nieuwe architectuur voor big data-opslag, een "data lakehouse" genaamd, combineert de grootste aspecten van datameren en datawarehouses. Al uw gegevens, of ze nu gestructureerd, semi-gestructureerd of ongestructureerd zijn, kunnen op één locatie worden opgeslagen met de beste machine learning-, business intelligence- en streamingmogelijkheden dankzij een data lakehouse.
Data lakes van allerlei aard zijn vaak het startpunt voor data lakehouses; daarna worden de gegevens getransformeerd naar het Delta Lake-formaat (een open-source opslaglaag die betrouwbaarheid toevoegt aan datameren).
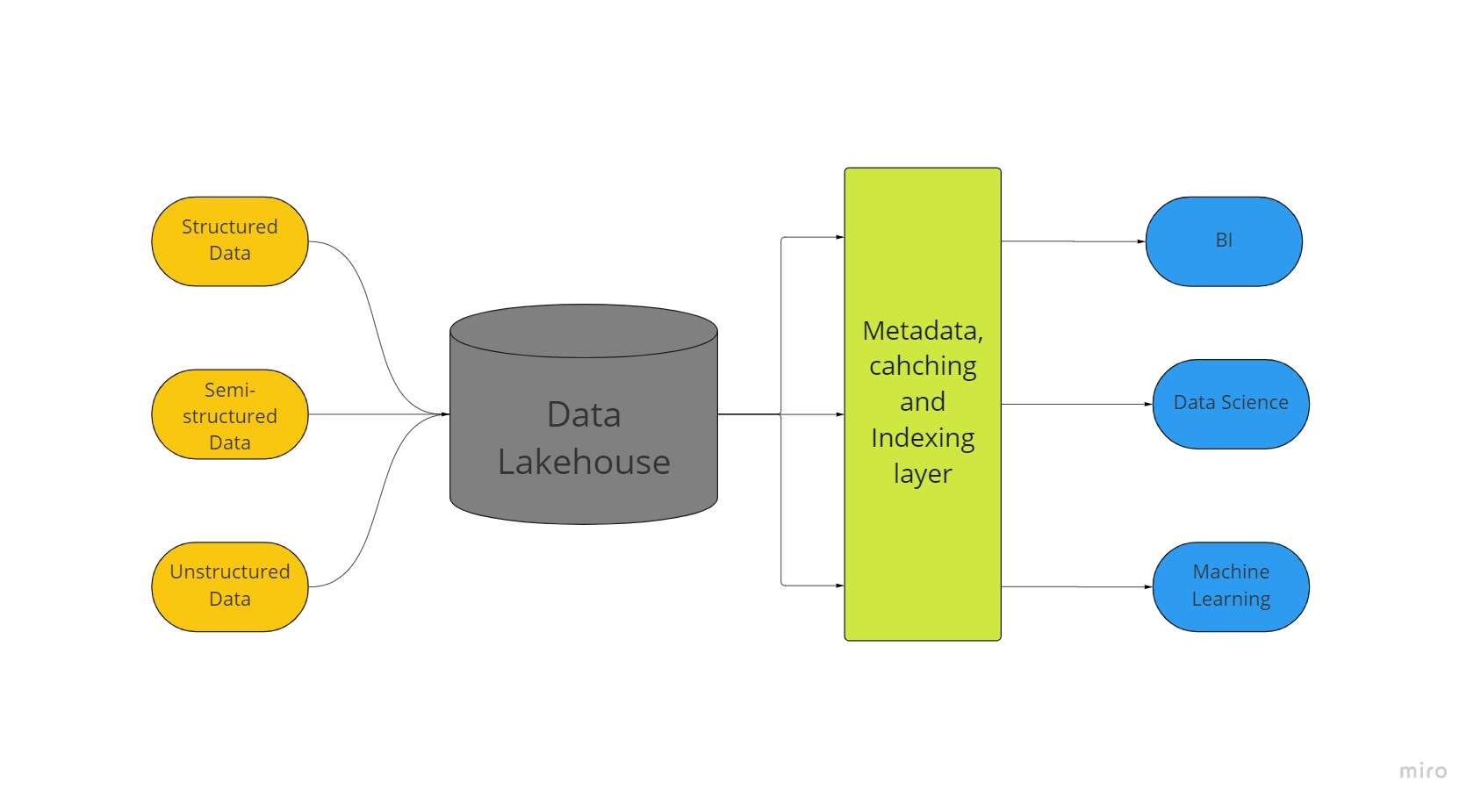
Datameren met deltameren maken ACID-transactieprocedures mogelijk vanuit conventionele datawarehouses. In wezen maakt het Lakehouse-systeem gebruik van goedkope opslag om enorme hoeveelheden gegevens in hun oorspronkelijke vorm te behouden, net als datameren.
Het toevoegen van de metadatalaag bovenop de winkel geeft ook datastructuur en maakt tools voor gegevensbeheer mogelijk, zoals die in datawarehouses.
Dit maakt het voor veel teams mogelijk om via één systeem toegang te krijgen tot alle bedrijfsgegevens voor een verscheidenheid aan initiatieven, zoals datawetenschap, machine learning en business intelligence.
Voordelen van Data Lakehouse
- Ondersteuning voor een groter scala aan workloads: om geavanceerde analyses mogelijk te maken, geven data lakehouses gebruikers direct toegang tot enkele van de meest populaire business intelligence-tools (Tableau, PowerBI). Bovendien kunnen datawetenschappers en machine learning-engineers de gegevens gemakkelijk gebruiken, aangezien data lakehouses open-dataformaten (zoals Parquet) gebruiken in combinatie met API's en machine learning-frameworks, zoals Python/R.
- Kosteneffectiviteit: Data lakehouses maken gebruik van goedkope objectopslagoplossingen om de kosteneffectieve opslagkenmerken van data lakes te implementeren. Door één oplossing aan te bieden, schrappen data lakehouses ook de kosten en tijd die gepaard gaan met het beheer van verschillende dataopslagsystemen.
- Data Lakehouse-ontwerp zorgt voor schema- en data-integriteit, waardoor het eenvoudiger wordt om effectieve databeveiligings- en governancesystemen te bouwen. Gemak versiebeheer van gegevens, bestuur en veiligheid.
- Data Lakehouses bieden een enkelvoudig, multifunctioneel platform voor gegevensopslag dat aan alle gegevensbehoeften van het bedrijf kan voldoen, waardoor gegevensduplicatie wordt verminderd. De meeste bedrijven kiezen voor een hybride oplossing vanwege de voordelen van zowel het datawarehouse als het datameer. Deze strategie kan ondertussen leiden tot kostbare gegevensduplicatie.
- De ondersteuning van open formaten. Open formaten zijn bestandstypen die door veel softwaretoepassingen kunnen worden gebruikt en waarvan de specificaties openbaar beschikbaar zijn. Volgens rapporten zijn Lakehouses in staat om gegevens op te slaan in gangbare bestandsindelingen zoals Apache Parquet en ORC (Optimized Row Columnar).
Beperkingen van Data Lakehouse
Het grootste nadeel van een data lakehouse is dat het nog een jonge en zich ontwikkelende technologie is. Het is onzeker of het daardoor zijn verplichtingen zal nakomen. Voordat data lakehouses kunnen concurreren met gevestigde big data-opslagsystemen, kan het jaren duren.
Gezien de snelheid waarmee moderne innovatie plaatsvindt, is het echter moeilijk te zeggen of een ander gegevensopslagsysteem dit uiteindelijk niet zal vervangen.
VOORDELEN
- Eén platform heeft alle gegevens, wat betekent dat er minder hostnamen zijn om te onderhouden.
- Atomiciteit, consistentie, isolatie en taaiheid blijven onaangetast.
- Het is aanzienlijk voordeliger.
- Eén platform heeft alle gegevens, wat betekent dat er minder hostnamen zijn om te onderhouden.
- Eenvoudig te beheren en eventuele problemen snel op te lossen
- Maak het eenvoudiger om een pijpleiding aan te leggen
NADELEN
- Het opzetten kan even duren.
- Het is te jong en te ver weg om te kwalificeren als een gevestigd opslagsysteem.
Datawarehouse versus Data Lake versus Data Lakehouse
Het datawarehouse heeft een lange geschiedenis in corporate intelligence-, rapportage- en analysetoepassingen en is de eerste opslagtechnologie voor big data.
Datawarehouses daarentegen zijn prijzig en hebben moeite met het omgaan met diverse en ongestructureerde data, zoals streaming data. Voor machine learning en data science-workloads zijn data lakes ontwikkeld om onbewerkte gegevens in verschillende vormen op betaalbare opslag te beheren.
Hoewel datalakes effectief zijn met ongestructureerde gegevens, missen ze de ACID-transactiemogelijkheden van datawarehouses, waardoor het een uitdaging is om gegevensconsistentie en betrouwbaarheid te garanderen.
De nieuwste architectuur voor gegevensopslag, bekend als het 'data lakehouse', combineert de betrouwbaarheid en consistentie van datawarehouses met de betaalbaarheid en aanpasbaarheid van datalakes.
Conclusie
Concluderend kan het moeilijk zijn om vanaf nul een data lakehouse te bouwen. Bovendien gebruikt u vrijwel zeker een platform dat is ontworpen om open data lakehouse-architectuur mogelijk te maken.
Wees daarom voorzichtig met het onderzoeken van de vele functies en implementaties van elk platform voordat u een aankoop doet. Bedrijven die op zoek zijn naar een volwassen, gestructureerde data-oplossing met een focus op business intelligence en data-analyse use cases kunnen een datawarehouse overwegen.
Bedrijven die op zoek zijn naar een schaalbare, betaalbare big data-oplossing om werklasten voor datawetenschap en machine learning op ongestructureerde data aan te drijven, zouden datalakes moeten overwegen.
Bedenk dat uw bedrijf meer gegevens nodig heeft dan de datawarehouse- en datameertechnologieën kunnen bieden, of dat u op zoek bent naar een oplossing om geavanceerde analyse- en machine learning-activiteiten op uw gegevens te integreren. EEN gegevens meerhuis is een verstandige optie in de situatie.





Laat een reactie achter