မာတိကာ[ဖျောက်][ရှိုး]
ယခု ကျွန်ုပ်တို့သည် ကွန်ပျူတာများကြောင့် အာကာသ၏ အကျယ်အဝန်းနှင့် အက်တမ်အမှုန်များ၏ မိနစ်ပိုင်းရှုပ်ထွေးမှုများကို တွက်ချက်နိုင်ပြီဖြစ်သည်။
ကွန်ပြူတာများသည် ရေတွက်ခြင်းနှင့် တွက်ချက်ခြင်းအပြင် ယုတ္တိရှိ/မရှိ လုပ်ငန်းစဉ်များအတိုင်း လုပ်ဆောင်သည့်အခါ၊ ၎င်း၏ circuitry မှတဆင့် အလင်း၏အမြန်နှုန်းဖြင့် အီလက်ထရွန်များ သွားလာနေသောကြောင့် လူများကို အနိုင်ယူပါသည်။
သို့ရာတွင်၊ ၎င်းတို့ကို “ဉာဏ်ရည်ဉာဏ်သွေး” ဟု ကျွန်ုပ်တို့ မကြာခဏ မမြင်ကြသောကြောင့်၊ ယခင်က ကွန်ပျူတာများသည် လူသားများက သင်ကြားခြင်း (ပရိုဂရမ်မွမ်းမံခြင်း) မရှိဘဲ မည်သည့်အရာမှ လုပ်ဆောင်နိုင်ခြင်း မရှိပေ။
နက်ရှိုင်းသောသင်ယူမှုနှင့် စက်သင်ယူမှုတို့ပါဝင်သည်။ ဉာဏ်ရည်တု၊ သည် သိပ္ပံနှင့်နည်းပညာခေါင်းကြီးပိုင်းများတွင် buzzword ဖြစ်လာသည်။
Machine Learning သည် အလုံးစုံ ပြည့်စုံနေပုံပေါ်သော်လည်း စကားလုံးကို အသုံးပြုသူ အများအပြားသည် ၎င်းကို မည်သည့်အရာ၊ မည်သည့်အရာနှင့် အကောင်းဆုံးအသုံးပြုကြောင်းကို လုံလောက်စွာ သတ်မှတ်ရန် ခက်ခဲနေပါသည်။
ဤဆောင်းပါးသည် အဘယ်ကြောင့် ဤမျှအကျိုးရှိသော နည်းပညာကို သရုပ်ဖော်ရန် ခိုင်မာသော၊ လက်တွေ့ကမ္ဘာနမူနာများကို ပေးဆောင်နေချိန်တွင် ဤဆောင်းပါးတွင် စက်သင်ယူခြင်းအား ရှင်းလင်းရန် ကြိုးစားသည်။
ထို့နောက်၊ ကျွန်ုပ်တို့သည် အမျိုးမျိုးသော machine learning methodologies ကိုကြည့်ရှုပြီး လုပ်ငန်းစိန်ခေါ်မှုများကို ဖြေရှင်းရန် ၎င်းတို့ကို မည်သို့အသုံးပြုနေကြသည်ကို ကြည့်ရှုပါမည်။
နောက်ဆုံးတွင်၊ စက်သင်ယူမှု၏အနာဂတ်နှင့်ပတ်သက်၍ အမြန်ခန့်မှန်းချက်အချို့အတွက် ကျွန်ုပ်တို့၏ crystal ball နှင့် တိုင်ပင်ပါမည်။
စက်သင်ယူခြင်းဆိုသည်မှာအဘယ်နည်း။
Machine Learning သည် ကွန်ပြူတာ ပညာရပ်၏ စည်းကမ်းတစ်ခုဖြစ်ပြီး ထိုပုံစံများကို အတိအကျ မသင်ကြားဘဲ ဒေတာများမှ ပုံစံများကို ကောက်ချက်ချနိုင်စေသည့် ကွန်ပျူတာပညာရပ်တစ်ခုဖြစ်သည်။
ဤကောက်ချက်များသည် ဒေတာ၏ ကိန်းဂဏန်းဆိုင်ရာ အင်္ဂါရပ်များကို အလိုအလျောက် အကဲဖြတ်ရန် အယ်လဂိုရီသမ်များကို အသုံးပြုကာ အမျိုးမျိုးသော တန်ဖိုးများအကြား ဆက်နွယ်မှုကို ပုံဖော်ရန်အတွက် သင်္ချာမော်ဒယ်များကို တီထွင်ထုတ်လုပ်ခြင်းအပေါ် မကြာခဏ အခြေခံထားသည်။
၎င်းကို တိကျသေချာသော စနစ်များပေါ်တွင် အခြေခံထားသည့် ဂန္တဝင်ကွန်ပြူတာ ကွန်ပြူတာနှင့် ဆန့်ကျင်ဘက်ဖြစ်ပြီး၊ အချို့သော အလုပ်တစ်ခုကို လုပ်ဆောင်ရန်အတွက် ကွန်ပျူတာအား လိုက်နာရမည့် စည်းမျဉ်းများ အတိအလင်း ပေးထားသည်။
ကွန်ပျူတာ ပရိုဂရမ်ရေးနည်းကို rule-based programming ဟုခေါ်သည်။ Machine Learning သည် ဤစည်းမျဉ်းများကို သူ့ဘာသာသူ နုတ်ယူနိုင်သောကြောင့် စည်းမျဉ်းအခြေခံ ပရိုဂရမ်များကို စွမ်းဆောင်ရည်ထက် သာလွန်စေပါသည်။
သင်ဟာ ချေးငွေလျှောက်လွှာမှာ သူတို့ရဲ့ချေးငွေမှာ ကျရှုံးမလားဆိုတာ ဆုံးဖြတ်ချင်တဲ့ ဘဏ်မန်နေဂျာတစ်ယောက်လို့ ယူဆပါ။
စည်းမျဉ်းအခြေခံနည်းလမ်းတစ်ခုတွင်၊ ဘဏ်မန်နေဂျာ (သို့မဟုတ် အခြားကျွမ်းကျင်သူများ) သည် လျှောက်ထားသူ၏ခရက်ဒစ်ရမှတ်သည် သတ်မှတ်ထားသည့်အဆင့်အောက်ရောက်ပါက၊ လျှောက်လွှာကို ပယ်ချသင့်သည်ဟု ကွန်ပျူတာအား အတိအလင်း အသိပေးမည်ဖြစ်သည်။
သို့သော်၊ စက်သင်ယူမှုပရိုဂရမ်သည် ဖောက်သည်ခရက်ဒစ်အဆင့်သတ်မှတ်ချက်များနှင့် ချေးငွေရလဒ်များအပေါ် ရိုးရှင်းစွာ ခွဲခြမ်းစိတ်ဖြာပြီး ဤအဆင့်သတ်မှတ်ချက်သည် ၎င်း၏ကိုယ်ပိုင်ဖြစ်သင့်သည်များကို ဆုံးဖြတ်ပေးမည်ဖြစ်သည်။
စက်သည် ယခင်ဒေတာများမှ သင်ယူပြီး ဤနည်းဖြင့် ၎င်း၏ကိုယ်ပိုင်စည်းမျဉ်းများကို ဖန်တီးသည်။ ဟုတ်ပါတယ်၊ ဒါက machine learning အတွက် primer တစ်ခုသာဖြစ်ပါတယ်။ real-world machine learning မော်ဒယ်များသည် အခြေခံအဆင့်ထက် သိသိသာသာ ပိုရှုပ်ထွေးပါသည်။
မည်သို့ပင်ဆိုစေကာမူ၊ ၎င်းသည် machine learning ၏ အလားအလာကောင်းများကို သရုပ်ပြခြင်းဖြစ်သည်။
ဘယ်လိုလုပ်ပြီး စက်ယန္တရား သင်ယူ?
အရာများကို ရိုးရိုးရှင်းရှင်းထားရန်၊ နှိုင်းယှဉ်နိုင်သောဒေတာရှိ ပုံစံများကို ရှာဖွေခြင်းဖြင့် စက်များသည် “လေ့လာရန်” ဖြစ်သည်။ ပြင်ပကမ္ဘာမှ စုဆောင်းထားသော အချက်အလက်များကို အချက်အလက်များအဖြစ် မှတ်ယူပါ။ စက်တစ်လုံးအား ဒေတာများများကျွေးလေ၊ ၎င်းသည် "စမတ်ကျ" ဖြစ်လာသည်။
သို့သော် အချက်အလက်အားလုံးသည် တူညီသည်မဟုတ်ပါ။ သင်သည် ကျွန်းပေါ်တွင် မြှုပ်နှံထားသော စည်းစိမ်ဥစ္စာများကို ရှာဖွေဖော်ထုတ်ရန် ဘဝရည်ရွယ်ချက်ဖြင့် ပင်လယ်ဓားပြတစ်ဦးဟု ယူဆပါ။ ဆုရဖို့အတွက် ဗဟုသုတများစွာ လိုချင်ပါလိမ့်မယ်။
ဒေတာကဲ့သို့ ဤအသိပညာသည် သင့်အား မှန်ကန်သော သို့မဟုတ် မှားသောနည်းလမ်းဖြင့် ယူဆောင်သွားနိုင်သည်။
သတင်းအချက်အလက်/ဒေတာရရှိမှု များလေလေ၊ မရှင်းလင်းမှု နည်းပါးလေလေ၊ အပြန်အလှန်အားဖြင့်။ ရလဒ်အနေဖြင့်၊ သင်လေ့လာရန် သင့်စက်ကို ကျွေးမွေးနေသည့် ဒေတာအမျိုးအစားကို ထည့်သွင်းစဉ်းစားရန် အရေးကြီးပါသည်။
သို့သော်လည်း များပြားလှသော ဒေတာပမာဏကို ပံ့ပိုးပေးသည်နှင့် တပြိုင်နက် ကွန်ပျူတာသည် ခန့်မှန်းချက်များကို ပြုလုပ်နိုင်သည်။ စက်များသည် ယခင်ကနှင့် များစွာမလွဲသရွေ့ အနာဂတ်ကို မျှော်မှန်းနိုင်သည်။
ဖြစ်ပေါ်လာမည့်အရာများကို ဆုံးဖြတ်ရန် သမိုင်းအချက်အလက်များကို ခွဲခြမ်းစိတ်ဖြာခြင်းဖြင့် စက်များသည် "လေ့လာပါ"။
ဒေတာအဟောင်းသည် ဒေတာအသစ်နှင့် ဆင်တူပါက၊ ယခင်ဒေတာနှင့် ပတ်သက်၍ သင်ပြောနိုင်သည့်အရာများသည် ဒေတာအသစ်နှင့် သက်ဆိုင်ဖွယ်ရှိသည်။ ရှေ့ကိုကြည့်ဖို့ နောက်ပြန်ကြည့်နေသလိုပဲ။
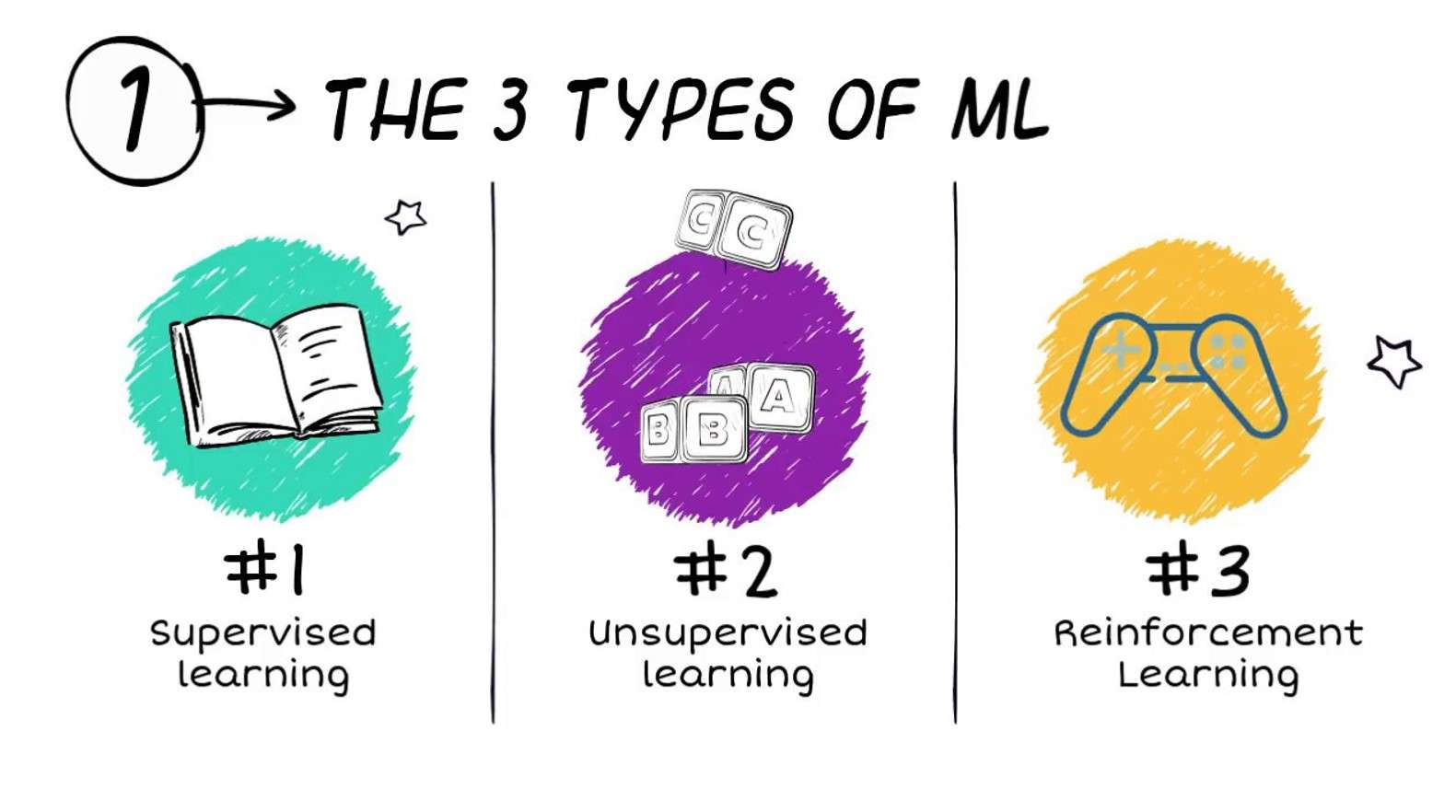
machine learning အမျိုးအစားတွေက ဘာတွေလဲ။
စက်သင်ယူခြင်းအတွက် အယ်လဂိုရီသမ်များကို ကျယ်ပြန့်သော အမျိုးအစားသုံးမျိုးဖြင့် မကြာခဏ ခွဲခြားထားပါသည် (အခြားအမျိုးအစားခွဲခြားမှုပုံစံများကိုလည်း အသုံးပြုထားသော်လည်း)
- ကြီးကြပ်သင်ယူသည်
- မကြီးကြပ်တဲ့သင်ယူမှု
- အားဖြည့်သင်ယူမှု
ကြီးကြပ်သင်ယူသည်
ကြီးကြပ်ထားသော စက်သင်ယူခြင်းဆိုသည်မှာ စက်သင်ယူမှုပုံစံအား စိတ်ဝင်စားမှုပမာဏအတွက် တိကျပြတ်သားသော အညွှန်းများပါသည့် ဒေတာအစုအဝေးကို ပေးအပ်သည့် နည်းပညာများကို ရည်ညွှန်းသည် (ဤပမာဏကို တုံ့ပြန်မှု သို့မဟုတ် ပစ်မှတ်အဖြစ် မကြာခဏရည်ညွှန်းသည်)။
AI မော်ဒယ်များကို လေ့ကျင့်ရန်၊ တစ်ပိုင်း ကြီးကြပ်မှု သင်ယူမှုတွင် တံဆိပ်တပ်ထားသော နှင့် အညွှန်းမပါသော ဒေတာ ရောနှောမှုကို အသုံးပြုသည်။
အကယ်၍ သင်သည် တံဆိပ်မကပ်ထားသော ဒေတာဖြင့် အလုပ်လုပ်နေပါက၊ ဒေတာတံဆိပ်တပ်ခြင်းအချို့ကို လုပ်ဆောင်ရန် လိုအပ်ပါသည်။
Labeling သည် အထောက်အကူဖြစ်စေရန် နမူနာတံဆိပ်ကပ်ခြင်းလုပ်ငန်းစဉ်ဖြစ်သည်။ machine learning လေ့ကျင့်ခြင်း။ မော်ဒယ်။ ငွေကုန်ကြေးကျများပြီး အချိန်ကုန်နိုင်သောကြောင့် တံဆိပ်တပ်ခြင်းကို လူများက အဓိကလုပ်ဆောင်သည်။ သို့သော် တံဆိပ်ကပ်ခြင်းလုပ်ငန်းစဉ်ကို အလိုအလျောက်လုပ်ဆောင်ရန် နည်းလမ်းများရှိပါသည်။
ချေးငွေလျှောက်ထားမှုအခြေအနေသည် ကြီးကြပ်သင်ကြားမှု၏ အကောင်းဆုံးပုံဥပမာဖြစ်သည်။ ယခင်က ချေးငွေလျှောက်ထားသူများ၏ ခရက်ဒစ်အဆင့်သတ်မှတ်ချက်များ (ဝင်ငွေအဆင့်၊ အသက်၊ စသည်ဖြင့်) နှင့် ပတ်သက်သည့် သမိုင်းဆိုင်ရာ အချက်အလက်များအပြင် ၎င်းတို့ချေးငွေအပေါ် ပျက်ကွက်ခြင်း ရှိ၊ မရှိ မေးခွန်းထုတ်ခံရသူက ကျွန်ုပ်တို့ကို ပြောပြသော သီးခြားတံဆိပ်များရှိသည်။
ဆုတ်ယုတ်မှု နှင့် အမျိုးအစား ခွဲခြားခြင်း သည် ကြီးကြပ် သင်ကြားရေး နည်းစနစ် ၏ အခွဲ နှစ်ခု ဖြစ်သည်။
- အမြိုးခှဲခွားခွငျး - ဒေတာကို မှန်ကန်စွာ အမျိုးအစားခွဲရန် algorithm ကို အသုံးပြုသည်။ Spam filter များသည် ဥပမာတစ်ခုဖြစ်သည်။ “စပမ်း” သည် အကြောင်းအရာဆိုင်ရာ အမျိုးအစားတစ်ခု ဖြစ်နိုင်သည်—စပမ်းနှင့် စပမ်းမဟုတ်သော ဆက်သွယ်မှုကြားမျဉ်းသည် မှုန်ဝါးနေသည်—နှင့် spam filter algorithm သည် သင့်တုံ့ပြန်ချက်အပေါ် မူတည်ပြီး (လူများက spam အဖြစ်သတ်မှတ်ထားသည့် အီးမေးလ်ကို ဆိုလိုသည်)။
- Regression - မှီခိုမှုနှင့် အမှီအခိုကင်းသော ကိန်းရှင်များကြား ဆက်စပ်မှုကို နားလည်ရန် အထောက်အကူဖြစ်သည်။ Regression မော်ဒယ်များသည် အချို့သော ကုမ္ပဏီအတွက် ရောင်းရငွေ ခန့်မှန်းချက်များကဲ့သို့သော ဒေတာရင်းမြစ်များစွာအပေါ် အခြေခံ၍ ကိန်းဂဏန်းတန်ဖိုးများကို ခန့်မှန်းနိုင်သည်။ Linear regression၊ logistic regression နှင့် polynomial regression တို့သည် ထင်ရှားသော ဆုတ်ယုတ်မှုနည်းစနစ်အချို့ဖြစ်သည်။
မကြီးကြပ်တဲ့သင်ယူမှု
ကြီးကြပ်မှုမရှိသော သင်ယူမှုတွင်၊ ကျွန်ုပ်တို့သည် တံဆိပ်မကပ်ထားသော ဒေတာကို ရရှိထားပြီး ပုံစံများကို ရှာဖွေနေပါသည်။ မင်း Amazon လို့ ဟန်ဆောင်လိုက်ရအောင်။ ဖောက်သည်ဝယ်ယူမှုမှတ်တမ်းအပေါ်အခြေခံ၍ မည်သည့်အစုအဖွဲ့များ (အလားတူစားသုံးသူအုပ်စုများ) ကို ရှာတွေ့နိုင်သနည်း။
ကျွန်ုပ်တို့တွင် လူတစ်ဦး၏ဦးစားပေးမှုများနှင့်ပတ်သက်သည့် တိကျသေချာသောအချက်အလက်များမရှိသော်လည်း၊ ဤဥပမာတွင်၊ နှိုင်းယှဉ်နိုင်သောကုန်ပစ္စည်းဝယ်ယူသည့်စားသုံးသူတစ်စုသည် အစုအဝေးရှိ အခြားတစ်ဦးချင်းစီမှလည်းဝယ်ယူထားသည့်အရာအပေါ်အခြေခံ၍ ဝယ်ယူမှုအကြံပြုချက်များကို ကျွန်ုပ်တို့ပြုလုပ်နိုင်သည်ဟူသောအချက်ကို ရိုးရိုးရှင်းရှင်းသိရှိနားလည်စေပါသည်။
Amazon ၏ "သင်လည်းစိတ်ဝင်စားနိုင်သည်" ဝိုင်းလေးအား အလားတူနည်းပညာများဖြင့် ပံ့ပိုးထားသည်။
ကြီးကြပ်မှုမရှိသော သင်ယူမှုသည် သင်အတူတကွစုလိုသည့်အရာပေါ် မူတည်၍ အုပ်စုဖွဲ့ခြင်း သို့မဟုတ် ပေါင်းစည်းခြင်းမှတဆင့် အချက်အလက်များကို အုပ်စုဖွဲ့နိုင်သည်။
- အစုလိုက်အပြုံလိုက် – ဒေတာရှိ ပုံစံများကို ရှာဖွေခြင်းဖြင့် ဤစိန်ခေါ်မှုကို ကျော်လွှားရန် ကြီးကြပ်မထားသော သင်ယူမှု ကြိုးပမ်းမှုများ။ အလားတူ အစုအဝေး သို့မဟုတ် အုပ်စုတစ်ခုရှိလျှင် အယ်လဂိုရီသမ်သည် ၎င်းတို့အား အမျိုးအစားခွဲခြားသတ်မှတ်မည်ဖြစ်သည်။ ယခင်ဝယ်ယူမှုသမိုင်းကို အခြေခံ၍ သုံးစွဲသူများကို အမျိုးအစားခွဲရန် ကြိုးစားခြင်းသည် ဤဥပမာတစ်ခုဖြစ်သည်။
- အသင်း - အုပ်စုအမျိုးမျိုး၏အခြေခံစည်းမျဉ်းများနှင့်အဓိပ္ပါယ်များကိုနားလည်သဘောပေါက်ရန်ကြိုးစားခြင်းဖြင့်ဤစိန်ခေါ်မှုကိုကိုင်တွယ်ဖြေရှင်းရန်ကြီးကြပ်မထားသောသင်ယူမှုကြိုးပမ်းသည်။ အသင်းအဖွဲ့ပြဿနာတစ်ခု၏ မကြာခဏဥပမာတစ်ခုမှာ ဖောက်သည်ဝယ်ယူမှုများကြား ချိတ်ဆက်မှုကို ဆုံးဖြတ်ခြင်းဖြစ်သည်။ စတိုးဆိုင်များသည် မည်သည့်ကုန်ပစ္စည်းများကို အတူတကွဝယ်ယူခဲ့သည်ကို သိရှိရန် စိတ်ဝင်စားနိုင်ပြီး ဤထုတ်ကုန်များကို အလွယ်တကူဝင်ရောက်နိုင်ရန် နေရာချထားမှုကို စီစဉ်ရန် ဤအချက်အလက်ကို အသုံးပြုနိုင်သည်။
အားဖြည့်သင်ယူခြင်း
အားဖြည့်သင်ယူခြင်းသည် အပြန်အလှန်အကျိုးသက်ရောက်မှုရှိသော ဆက်တင်တစ်ခုတွင် ပန်းတိုင်ကို ဦးတည်သည့် ဆုံးဖြတ်ချက်များကို ဆက်တိုက်ချရန် စက်သင်ယူမှုပုံစံများကို သင်ကြားခြင်းအတွက် နည်းစနစ်တစ်ခုဖြစ်သည်။ အထက်ဖော်ပြပါ ဂိမ်းအသုံးပြုမှုကိစ္စများသည် ဤအရာအတွက် အလွန်ကောင်းမွန်သော သရုပ်ဖော်ပုံများဖြစ်သည်။
သင်သည် AlphaZero ထောင်ပေါင်းများစွာသော ယခင်စစ်တုရင်ဂိမ်းများကို ထည့်သွင်းရန် မလိုအပ်ပါ၊ တစ်ခုစီတိုင်းသည် "ကောင်း" သို့မဟုတ် "ညံ့သည်" ဟုတံဆိပ်တပ်ထားသော ရွေ့လျားမှုတစ်ခုရှိသည်။ ဂိမ်း၏ စည်းမျဉ်းများနှင့် ပန်းတိုင်ကို ရိုးရှင်းစွာ သင်ပေးပါ၊ ထို့နောက် ကျပန်းလုပ်ဆောင်မှုများကို စမ်းကြည့်ပါ။
အပြုသဘောဆောင်သော အားဖြည့်အား ပရိုဂရမ်ကို ပန်းတိုင်သို့ ပိုမိုနီးကပ်စေသော လှုပ်ရှားမှုများ (ဥပမာ အပေါင်ခံသည့် အနေအထားကို ဖော်ဆောင်ခြင်းကဲ့သို့သော) လုပ်ဆောင်ချက်များကို ပေးပါသည်။ လုပ်ရပ်များသည် ဆန့်ကျင်ဘက်အကျိုးသက်ရောက်မှုများ (ဥပမာ ဘုရင်ကို အချိန်မတန်မီ ရွှေ့ပြောင်းခြင်းကဲ့သို့သော) တွင် ၎င်းတို့သည် အပျက်သဘောဆောင်သော အားဖြည့်မှုကို ရရှိကြသည်။
ဆော့ဖ်ဝဲလ်သည် ဤနည်းလမ်းကို အသုံးပြု၍ ဂိမ်းကို နောက်ဆုံးတွင် ကျွမ်းကျင်နိုင်သည်။
အားဖြည့်သင်ယူမှု ရှုပ်ထွေးပြီး ခက်ခဲသော အင်ဂျင်နီယာ လုပ်ဆောင်ချက်များအတွက် စက်ရုပ်များကို သင်ကြားရန် စက်ရုပ်များတွင် တွင်ကျယ်စွာ အသုံးပြုပါသည်။ ယာဉ်ကြောစီးဆင်းမှုကို ပိုမိုကောင်းမွန်စေရန်အတွက် တစ်ခါတစ်ရံတွင် ၎င်းအား ယာဉ်လမ်းကြောင်းဆိုင်ရာ အချက်ပြများကဲ့သို့သော လမ်းအခြေခံအဆောက်အအုံများနှင့် တွဲဖက်အသုံးပြုသည်။
machine learning နဲ့ ဘာလုပ်နိုင်မလဲ။
လူ့အဖွဲ့အစည်းနှင့် လုပ်ငန်းနယ်ပယ်များတွင် စက်သင်ယူမှုကို အသုံးပြုခြင်းသည် လူသားများ၏ ကြိုးပမ်းအားထုတ်မှု ကျယ်ပြန့်မှုကို တိုးတက်စေသည်။
ကျွန်ုပ်တို့၏နေ့စဉ်ဘဝတွင်၊ ယခုအခါ စက်သင်ယူမှုသည် Google ၏ ရှာဖွေမှုနှင့် ရုပ်ပုံဆိုင်ရာ အယ်လဂိုရီသမ်များကို ထိန်းချုပ်ထားပြီး ကျွန်ုပ်တို့ကို လိုအပ်သည့်အခါ ကျွန်ုပ်တို့လိုအပ်သည့် အချက်အလက်များနှင့် ပိုမိုတိကျစွာကိုက်ညီနိုင်စေမည်ဖြစ်သည်။
ဥပမာအားဖြင့် ဆေးပညာတွင်၊ ပိုမိုထိရောက်သောကုထုံးများကို ဖန်တီးနိုင်စေရန် ဆရာဝန်များအား နားလည်သဘောပေါက်ပြီး ကြိုတင်ခန့်မှန်းနိုင်စေရန်အတွက် အထောက်အကူဖြစ်စေရန်အတွက် မျိုးရိုးဗီဇဒေတာတွင် စက်သင်ယူမှုကို အသုံးချလျက်ရှိသည်။
နက်ရှိုင်းသော အာကာသမှ ဒေတာများကို ဤနေရာတွင် ဧရာမ ရေဒီယို တယ်လီစကုပ်များမှတစ်ဆင့် ကမ္ဘာမြေပေါ်တွင် စုဆောင်းနေပြီး စက်သင်ယူမှုဖြင့် ခွဲခြမ်းစိတ်ဖြာပြီးနောက်၊ ၎င်းသည် ကျွန်ုပ်တို့အား တွင်းနက်များ၏ နက်နဲသောအရာများကို ဖော်ထုတ်ရန် ကူညီပေးပါသည်။
လက်လီရောင်းချမှုတွင် စက်သင်ယူခြင်းသည် ဝယ်သူများကို အွန်လိုင်းတွင်ဝယ်လိုသည့်အရာများနှင့် ချိတ်ဆက်ပေးသည့်အပြင် အုတ်နှင့်အင်္ဂတေလောကရှိ ၎င်းတို့၏ဖောက်သည်များအတွက် ၎င်းတို့ပေးဆောင်သည့် ဝန်ဆောင်မှုကို စျေးဆိုင်ဝန်ထမ်းများအား အံဝင်ခွင်ကျဖြစ်စေရန် ကူညီပေးပါသည်။
အပြစ်မဲ့သူများကို ထိခိုက်စေလိုသော အပြုအမူများကို ကြိုတင်ခန့်မှန်းနိုင်ရန် အကြမ်းဖက်နှင့် အစွန်းရောက်ဝါဒကို တိုက်ဖျက်ရာတွင် စက်သင်ယူမှုကို အသုံးပြုသည်။
သဘာဝဘာသာစကားဖြင့် လုပ်ဆောင်ခြင်း (NLP) သည် စက်သင်ယူမှုမှတစ်ဆင့် ကွန်ပျူတာများကို လူသားဘာသာစကားဖြင့် ကျွန်ုပ်တို့နှင့် နားလည်သဘောပေါက်ပြီး ဆက်သွယ်နိုင်စေမည့် လုပ်ငန်းစဉ်ကို ရည်ညွှန်းပြီး ဘာသာပြန်နည်းပညာနှင့် ကျွန်ုပ်တို့နေ့စဥ်အသုံးပြုနေကြသော အသံထိန်းချုပ်ကိရိယာများကဲ့သို့သော အောင်မြင်မှုများရရှိစေပါသည်။ Alexa၊ Google dot၊ Siri နှင့် Google Assistant။
မေးခွန်းမထုတ်ဘဲ၊ စက်သင်ယူခြင်းသည် အသွင်ပြောင်းနည်းပညာတစ်ခုဖြစ်ကြောင်း သက်သေပြနေသည်။
ကျွန်ုပ်တို့နှင့်အတူ လက်တွဲလုပ်ဆောင်နိုင်သော စက်ရုပ်များသည် ၎င်းတို့၏ မှားယွင်းမှုမရှိသော ယုတ္တိဗေဒနှင့် လူသာလွန်သောအမြန်နှုန်းဖြင့် ကျွန်ုပ်တို့၏ကိုယ်ပိုင်မူလနှင့် စိတ်ကူးစိတ်သန်းများကို မြှင့်တင်ပေးနိုင်သော စက်ရုပ်များသည် သိပ္ပံစိတ်ကူးယဉ်စိတ်ကူးယဉ်မဟုတ်တော့ပါ - ၎င်းတို့သည် ကဏ္ဍများစွာတွင် လက်တွေ့ဖြစ်လာလျက်ရှိသည်။
Machine Learning အသုံးပြုမှုတွေ
၆
ကွန်ရက်များ ပိုမိုရှုပ်ထွေးလာသည်နှင့်အမျှ၊ ဆိုက်ဘာလုံခြုံရေးဆိုင်ရာ အထူးကျွမ်းကျင်သူများသည် အမြဲတမ်းတိုးချဲ့နေသော လုံခြုံရေးခြိမ်းခြောက်မှုအကွာအဝေးကို လိုက်လျောညီထွေဖြစ်အောင် မမောမပန်းလုပ်ဆောင်ခဲ့ကြသည်။
လျင်မြန်စွာပြောင်းလဲနေသော malware နှင့် ဟက်ကာနည်းဗျူဟာများကို တန်ပြန်ခြင်းသည် လုံလောက်သောစိန်ခေါ်မှုဖြစ်သည်၊ သို့သော် Internet of Things (IoT) ကိရိယာများ တိုးပွားလာမှုသည် ဆိုက်ဘာလုံခြုံရေးပတ်ဝန်းကျင်ကို အခြေခံကျကျ ပြောင်းလဲသွားစေပါသည်။
တိုက်ခိုက်မှုများသည် အချိန်မရွေး၊ နေရာမရွေး ဖြစ်ပွားနိုင်သည်။
ကျေးဇူးတင်စွာဖြင့်၊ စက်သင်ယူမှု အယ်လဂိုရီသမ်များသည် အဆိုပါ လျင်မြန်သော တိုးတက်မှုများကို လိုက်လျောညီထွေဖြစ်စေရန်အတွက် ဆိုက်ဘာလုံခြုံရေးလုပ်ဆောင်မှုများကို ဖွင့်ပေးခဲ့သည်။
ခန့်မှန်း analytics တိုက်ခိုက်မှုများကို ပိုမိုမြန်ဆန်စွာ သိရှိနိုင်စေရန်နှင့် လျော့ပါးသက်သာစေရန် စက်သင်ယူခြင်းသည် လက်ရှိလုံခြုံရေးယန္တရားများတွင် မူမမှန်မှုများနှင့် အားနည်းချက်များကို သိရှိနိုင်စေရန် ကွန်ရက်အတွင်း၌ သင်၏လုပ်ဆောင်ချက်ကို ပိုင်းခြားစိတ်ဖြာနိုင်သော်လည်း စက်သင်ယူမှုပြုလုပ်နိုင်သည်။
2. ဖောက်သည်ဝန်ဆောင်မှု၏အလိုအလျောက်လုပ်ဆောင်ခြင်း။
တိုးပွားလာသော အွန်လိုင်းဖောက်သည် အဆက်အသွယ်များကို စီမံခန့်ခွဲခြင်းသည် အဖွဲ့အစည်းများစွာကို တင်းမာစေသည်။
၎င်းတို့တွင် ၎င်းတို့လက်ခံရရှိသည့် စုံစမ်းမေးမြန်းမှုပမာဏကို ကိုင်တွယ်ရန် ဖောက်သည်ဝန်ဆောင်မှုဝန်ထမ်း လုံလောက်မှု မရှိခြင်း နှင့် outsourcing ပြဿနာများဆီသို့ ရိုးရာချဉ်းကပ်နည်း၊ ဆက်သွယ်ရန်စင်တာ ယနေ့ခေတ်ဖောက်သည်များစွာအတွက် လက်မခံနိုင်ပါ။
Chatbots နှင့် အခြားသော အလိုအလျောက်စနစ်များသည် စက်သင်ယူမှုနည်းပညာများ တိုးတက်လာမှုကြောင့် ယခုတောင်းဆိုချက်များကို ဖြည့်ဆည်းပေးနိုင်ပါသည်။ ကုမ္ပဏီများသည် လူသားဆန်သောနှင့် ဦးစားပေးမှုနည်းသော လှုပ်ရှားမှုများကို အလိုအလျောက်လုပ်ဆောင်ခြင်းဖြင့် ပိုမိုအဆင့်မြင့်သော ဖောက်သည်ပံ့ပိုးမှုရယူရန် ဝန်ထမ်းများကို လွတ်လွတ်လပ်လပ်လုပ်နိုင်ပါသည်။
မှန်ကန်စွာအသုံးပြုသည့်အခါ၊ လုပ်ငန်းတွင် စက်သင်ယူခြင်းသည် ပြဿနာဖြေရှင်းမှုကို ချောမွေ့စေပြီး သုံးစွဲသူများအား အမှတ်တံဆိပ်ချန်ပီယံများဖြစ်လာစေသည့် အထောက်အကူအမျိုးအစားကို ပံ့ပိုးပေးနိုင်သည်။
3 ။ ဆက်သွယ်ရေး
မည်သည့်ဆက်သွယ်ရေး အမျိုးအစားတွင်မဆို အမှားအယွင်းများနှင့် အထင်အမြင်လွဲမှားမှုများကို ရှောင်ကြဉ်ရန်မှာ အရေးကြီးသော်လည်း ယနေ့ခေတ် လုပ်ငန်းဆက်သွယ်ရေးများတွင် ပိုမိုများပြားပါသည်။
ရိုးရှင်းသောသဒ္ဒါအမှားများ၊ မမှန်သောလေသံ သို့မဟုတ် မှားယွင်းသောဘာသာပြန်ဆိုမှုများသည် အီးမေးလ်ဆက်သွယ်မှု၊ ဖောက်သည်အကဲဖြတ်မှုများတွင် အခက်အခဲများစွာဖြစ်စေနိုင်သည်။ video conferencingသို့မဟုတ် ပုံစံများစွာဖြင့် စာသားအခြေခံစာရွက်စာတမ်းများ။
စက်သင်ယူမှုစနစ်များသည် Microsoft ၏ Clippy ၏ ခေါင်းခဲစရာနေ့ရက်များထက် ပိုမိုကောင်းမွန်သော ဆက်သွယ်ရေးစနစ်များရှိသည်။
ဤစက်သင်ယူမှုနမူနာများသည် လူတစ်ဦးချင်းစီကို သဘာဝဘာသာစကားဖြင့် စီမံဆောင်ရွက်ပေးခြင်း၊ အချိန်နှင့်တစ်ပြေးညီ ဘာသာပြန်ဆိုခြင်းနှင့် စကားပြောမှတ်သားခြင်းတို့ကို အသုံးပြုခြင်းဖြင့် တစ်ဦးချင်းစီကို ရိုးရိုးရှင်းရှင်းနှင့် တိကျစွာ ဆက်သွယ်ရန် ကူညီပေးခဲ့ပါသည်။
လူများစွာသည် အလိုအလျောက်ပြုပြင်ခြင်းစွမ်းရည်များကို မကြိုက်သော်လည်း အရှက်ရစေသောအမှားများနှင့် လျော်ကန်သောလေသံတို့မှ ကာကွယ်ပေးခြင်းကို တန်ဖိုးထားကြသည်။
4. Object အသိအမှတ်ပြုမှု
ဒေတာစုဆောင်းခြင်းနှင့် အဓိပ္ပာယ်ပြန်ဆိုခြင်းနည်းပညာသည် အချိန်အတော်ကြာအောင် တည်ရှိနေသော်လည်း ၎င်းတို့ကြည့်ရှုနေသည့်အရာကို နားလည်ရန် ကွန်ပျူတာစနစ်များကို သင်ကြားခြင်းသည် လှည့်စားရန်ခက်ခဲသော အလုပ်ဖြစ်ကြောင်း သက်သေပြခဲ့သည်။
စက်သင်ယူမှုအပလီကေးရှင်းများကြောင့် အရာဝတ္တုမှတ်သားခြင်းစွမ်းရည်ကို စက်ပစ္စည်းအများအပြားတွင် တိုးလာနေပါသည်။
ဥပမာအားဖြင့် မောင်းသူမဲ့မော်တော်ကားသည် အခြားကားတစ်စီးကိုမြင်သောအခါတွင် အခြားကားကို ရည်ညွှန်းရန်အတွက် ပရိုဂရမ်မာများက ၎င်းကိုအသုံးပြုရန်အတွက် ထိုကား၏အတိအကျဥပမာကို မပေးခဲ့လျှင်ပင် မှတ်မိသည်။
ငွေရှင်းခြင်းလုပ်ငန်းစဉ်ကို အရှိန်မြှင့်ရန် ဤနည်းပညာကို လက်လီစီးပွားရေးလုပ်ငန်းများတွင် အသုံးပြုလျက်ရှိသည်။ ကင်မရာများသည် စားသုံးသူများ၏ တွန်းလှည်းများရှိ ထုတ်ကုန်များကို ခွဲခြားသတ်မှတ်နိုင်ပြီး စတိုးဆိုင်မှ ထွက်ခွာသည့်အခါ ၎င်းတို့၏အကောင့်များကို အလိုအလျောက် ဘီလ်ပေးနိုင်သည်။
၃။ ဒစ်ဂျစ်တယ်စျေးကွက်
ယနေ့ခေတ်စျေးကွက်ရှာဖွေရေးအများစုသည် ဒစ်ဂျစ်တယ်ပလပ်ဖောင်းများနှင့် ဆော့ဖ်ဝဲလ်ပရိုဂရမ်အမြောက်အမြားကို အသုံးပြု၍ အွန်လိုင်းတွင်ပြုလုပ်ကြသည်။
စီးပွားရေးလုပ်ငန်းများသည် ၎င်းတို့၏စားသုံးသူများနှင့် ၎င်းတို့၏ဝယ်ယူမှုအမူအကျင့်များအကြောင်း အချက်အလက်များကို စုဆောင်းသည့်အခါ၊ စျေးကွက်ရှာဖွေရေးအဖွဲ့များသည် ၎င်းတို့၏ပစ်မှတ်ပရိသတ်၏ အသေးစိတ်ပုံတစ်ပုံကို တည်ဆောက်ကာ မည်သည့်လူများက ၎င်းတို့၏ထုတ်ကုန်နှင့် ဝန်ဆောင်မှုများကို ရှာဖွေလိုသည်ကို ရှာဖွေတွေ့ရှိရန် အဆိုပါအချက်အလက်များကို အသုံးပြုနိုင်သည်။
စက်သင်ယူမှု အယ်လဂိုရီသမ်များသည် စျေးကွက်ရှာဖွေသူများကို ထိုဒေတာအားလုံးကို နားလည်သဘောပေါက်စေရန် ကူညီပေးသည်၊ ဖြစ်နိုင်ခြေများကို တင်းတင်းကြပ်ကြပ် အမျိုးအစားခွဲနိုင်စေမည့် သိသာထင်ရှားသောပုံစံများနှင့် အရည်အချင်းများကို ရှာဖွေတွေ့ရှိရန် ကူညီပေးသည်။
တူညီသောနည်းပညာသည်ကြီးမားသောဒစ်ဂျစ်တယ်စျေးကွက်ရှာဖွေရေးအလိုအလျောက်ခွင့်ပြုသည်။ အလားအလာရှိသော စားသုံးသူအသစ်များကို တက်ကြွစွာရှာဖွေတွေ့ရှိရန်နှင့် သင့်လျော်သောအချိန်နှင့်နေရာအလိုက် သင့်လျော်သောစျေးကွက်ရှာဖွေရေးအကြောင်းအရာများကို ပေးဆောင်ရန် ကြော်ငြာစနစ်များကို ဖန်တီးနိုင်သည်။
Machine Learning ၏အနာဂတ်
စိန်ခေါ်မှုများ သို့မဟုတ် ဆန်းသစ်တီထွင်မှုကို ကိုင်တွယ်ဖြေရှင်းရန် နည်းပညာကို ပိုမိုစီးပွားရေးလုပ်ငန်းများနှင့် ကြီးမားသောအဖွဲ့အစည်းများက အသုံးပြုခြင်းကြောင့် စက်သင်ယူမှုသည် သေချာပေါက် ရေပန်းစားလာပါသည်။
ဤဆက်လက်ရင်းနှီးမြုပ်နှံမှုသည် အထူးသဖြင့် အထက်ဖော်ပြပါ တည်ထောင်ပြီး ပြန်လည်ထုတ်လုပ်နိုင်သော အသုံးပြုမှုကိစ္စရပ်အချို့မှတစ်ဆင့် စက်သင်ယူမှု ROI ကို ထုတ်လုပ်နေကြောင်း နားလည်မှုကို ပြသသည်။
အကယ်၍ နည်းပညာသည် Netflix၊ Facebook၊ Amazon၊ Google Maps နှင့် အခြားအရာများအတွက် လုံလောက်ကောင်းမွန်ပါက၊ ၎င်းသည် သင့်ကုမ္ပဏီ၏ ဒေတာအများစုကို အသုံးပြုနိုင်စေရန် ကူညီပေးနိုင်သည်။
အသစ်အတိုင်း စက်သင်ယူမှု မော်ဒယ်များကို တီထွင်ပြီး စတင်ထုတ်လုပ်လိုက်ရာ စက်မှုလုပ်ငန်းခွင်များတွင် အသုံးပြုမည့် အက်ပလီကေးရှင်းအရေအတွက် တိုးလာသည်ကို ကျွန်ုပ်တို့ သက်သေပြပါမည်။
ဒီလိုဖြစ်နေပြီလေ။ မျက်နှာအသိအမှတ်ပြုမှုတစ်ချိန်က သင့် iPhone တွင် လုပ်ဆောင်ချက်အသစ်တစ်ခုဖြစ်ခဲ့သော်လည်း ယခုအခါတွင် အထူးသဖြင့် အများသူငှာလုံခြုံရေးနှင့်သက်ဆိုင်သည့် ပရိုဂရမ်များနှင့် အက်ပ်လီကေးရှင်းများစွာတွင် အကောင်အထည်ဖော်လျက်ရှိသည်။
စက်သင်ယူမှုစတင်ရန် ကြိုးစားနေသည့် အဖွဲ့အစည်းအများစုအတွက် အဓိကသော့ချက်မှာ တောက်ပသော အနာဂတ်အမြင်များကို ကျော်ဖြတ်ပြီး နည်းပညာဖြင့် သင့်အား ကူညီပေးနိုင်သည့် တကယ့်စီးပွားရေးစိန်ခေါ်မှုများကို ရှာဖွေတွေ့ရှိရန်ဖြစ်သည်။
ကောက်ချက်
စက်မှုခေတ်လွန်ခေတ်တွင်၊ သိပ္ပံပညာရှင်များနှင့် ပညာရှင်များသည် လူသားများနှင့်ပိုတူသော ကွန်ပြူတာတစ်လုံးကို ဖန်တီးရန် ကြိုးပမ်းခဲ့ကြသည်။
တွေးခေါ်မှုဆိုင်ရာ စက်သည် AI ၏ လူသားမျိုးနွယ်အပေါ် အထင်ရှားဆုံး ပံ့ပိုးကူညီမှု၊ ဤကိုယ်ကိုတိုင်တွန်းအားပေးစက်၏ အံ့မခန်းရောက်ရှိလာမှုသည် ကော်ပိုရိတ်လည်ပတ်မှုစည်းမျဉ်းများကို လျင်မြန်စွာပြောင်းလဲစေခဲ့သည်။
မောင်းသူမဲ့ယာဉ်များ၊ အလိုအလျောက်လက်ထောက်များ၊ ကိုယ်ပိုင်အုပ်ချုပ်ခွင့်ရထုတ်လုပ်ရေးဝန်ထမ်းများနှင့် စမတ်မြို့များတွင် စမတ်စက်များ၏ ရှင်သန်နိုင်စွမ်းကို မကြာသေးမီက ပြသခဲ့သည်။ စက်သင်ယူမှုတော်လှန်ရေးနှင့် စက်သင်ယူမှု၏အနာဂတ်သည် ကျွန်ုပ်တို့နှင့်အတူ အချိန်အကြာကြီးရှိနေမည်ဖြစ်သည်။





တစ်ဦးစာပြန်ရန် Leave