अनुक्रमणिका[लपवा][दाखवा]
आता आपण संगणकाच्या सहाय्याने अवकाशाचा विस्तार आणि उपअणु कणांच्या सूक्ष्म गुंतागुंतीची गणना करू शकतो.
गणने आणि गणना करताना, तसेच तार्किक होय/नाही प्रक्रियेचे पालन करताना संगणक मानवांवर मात करतात, इलेक्ट्रॉन्स त्याच्या सर्किटरीद्वारे प्रकाशाच्या वेगाने प्रवास करतात.
तथापि, आम्ही त्यांना "बुद्धिमान" म्हणून पाहत नाही कारण, भूतकाळात, संगणक मानवाकडून शिकवल्याशिवाय (प्रोग्राम केलेले) काहीही करू शकत नव्हते.
सखोल शिक्षणासह मशीन लर्निंग आणि कृत्रिम बुद्धिमत्ता, वैज्ञानिक आणि तंत्रज्ञानाच्या मथळ्यांमध्ये एक गूढ शब्द बनला आहे.
मशीन लर्निंग हे सर्वव्यापी असल्याचे दिसून येते, परंतु अनेक लोक जे हा शब्द वापरतात त्यांना ते काय आहे, ते काय करते आणि ते कशासाठी वापरले जाते याची पुरेशी व्याख्या करण्यासाठी संघर्ष करतात.
हा लेख मशीन लर्निंगचे स्पष्टीकरण देण्याचा प्रयत्न करतो आणि ते इतके फायदेशीर का आहे हे स्पष्ट करण्यासाठी तंत्रज्ञान कसे कार्य करते याची ठोस, वास्तविक-जगातील उदाहरणे देखील प्रदान करते.
त्यानंतर, आम्ही विविध मशीन लर्निंग पद्धती पाहू आणि व्यावसायिक आव्हानांना तोंड देण्यासाठी त्यांचा कसा वापर केला जातो ते पाहू.
शेवटी, मशीन लर्निंगच्या भविष्याविषयी काही द्रुत अंदाजांसाठी आम्ही आमच्या क्रिस्टल बॉलचा सल्ला घेऊ.
मशीन लर्निंग म्हणजे काय?
मशीन लर्निंग ही संगणक विज्ञानाची एक शाखा आहे जी संगणकांना डेटावरून नमुन्यांची अनुमान काढण्यास सक्षम करते आणि ते नमुने काय आहेत हे स्पष्टपणे शिकवले जात नाही.
हे निष्कर्ष डेटाच्या सांख्यिकीय वैशिष्ट्यांचे स्वयंचलितपणे मूल्यांकन करण्यासाठी अल्गोरिदम वापरणे आणि विविध मूल्यांमधील संबंध चित्रित करण्यासाठी गणितीय मॉडेल विकसित करणे यावर आधारित असतात.
शास्त्रीय संगणनाशी याचा विरोधाभास करा, जे निर्धारक प्रणालींवर आधारित आहे, ज्यामध्ये आम्ही स्पष्टपणे संगणकाला विशिष्ट कार्य करण्यासाठी त्याचे पालन करण्यासाठी नियमांचा संच देतो.
संगणक प्रोग्रामिंगचा हा मार्ग नियम-आधारित प्रोग्रामिंग म्हणून ओळखला जातो. मशिन लर्निंग हे नियम-आधारित प्रोग्रामिंगपेक्षा वेगळे आहे आणि त्यापेक्षा जास्त कामगिरी करते कारण ते हे नियम स्वतःच काढू शकतात.
गृहीत धरा की तुम्ही एक बँक व्यवस्थापक आहात ज्यांना त्यांच्या कर्जावर कर्जाचा अर्ज अयशस्वी होणार आहे की नाही हे निर्धारित करायचे आहे.
नियम-आधारित पद्धतीमध्ये, बँक व्यवस्थापक (किंवा इतर विशेषज्ञ) संगणकाला स्पष्टपणे सूचित करतात की अर्जदाराचा क्रेडिट स्कोअर एका विशिष्ट पातळीपेक्षा कमी असल्यास, अर्ज नाकारला जावा.
तथापि, एक मशीन लर्निंग प्रोग्राम क्लायंट क्रेडिट रेटिंग आणि कर्ज परिणामांवरील आधीच्या डेटाचे विश्लेषण करेल आणि हा थ्रेशोल्ड स्वतःच काय असावा हे निर्धारित करेल.
मशीन मागील डेटावरून शिकते आणि अशा प्रकारे स्वतःचे नियम तयार करते. अर्थात, हा केवळ मशीन लर्निंगचा प्राइमर आहे; रिअल-वर्ल्ड मशीन लर्निंग मॉडेल मूलभूत थ्रेशोल्डपेक्षा लक्षणीयरीत्या अधिक क्लिष्ट आहेत.
तरीही, हे मशीन लर्निंगच्या क्षमतेचे उत्कृष्ट प्रदर्शन आहे.
कसे नाही मशीन शिका
गोष्टी सोप्या ठेवण्यासाठी, तुलनात्मक डेटामधील नमुने शोधून मशीन "शिकतात". तुम्ही बाहेरच्या जगातून गोळा करत असलेल्या माहितीचा विचार करा. मशीनला जितका जास्त डेटा दिला जातो तितका तो “स्मार्ट” होतो.
तथापि, सर्व डेटा समान नाही. बेटावर दफन केलेल्या संपत्तीचा पर्दाफाश करण्यासाठी जीवनाच्या उद्देशाने तुम्ही समुद्री डाकू आहात असे समजा. बक्षीस शोधण्यासाठी तुम्हाला भरपूर ज्ञान हवे असेल.
हे ज्ञान, डेटासारखे, एकतर तुम्हाला योग्य किंवा चुकीच्या मार्गाने घेऊन जाऊ शकते.
जितकी जास्त माहिती/डेटा मिळवला जाईल तितकी संदिग्धता कमी असेल आणि त्याउलट. परिणामी, शिकण्यासाठी तुम्ही तुमच्या मशीनला कोणत्या प्रकारचा डेटा देत आहात याचा विचार करणे महत्त्वाचे आहे.
तथापि, एकदा का भरीव प्रमाणात डेटा प्रदान केला की, संगणक अंदाज बांधू शकतो. भूतकाळापासून फारसे विचलित होत नाही तोपर्यंत मशीन भविष्याचा अंदाज लावू शकतात.
काय होण्याची शक्यता आहे हे निर्धारित करण्यासाठी यंत्रे ऐतिहासिक डेटाचे विश्लेषण करून "शिकतात".
जर जुना डेटा नवीन डेटासारखा दिसत असेल, तर तुम्ही मागील डेटाबद्दल सांगू शकता त्या गोष्टी नवीन डेटावर लागू होण्याची शक्यता आहे. जणू काही तुम्ही पुढे पाहण्यासाठी मागे वळून पाहत आहात.
मशीन लर्निंगचे प्रकार कोणते आहेत?
मशीन लर्निंगसाठी अल्गोरिदमचे वारंवार तीन मोठ्या प्रकारांमध्ये वर्गीकरण केले जाते (जरी इतर वर्गीकरण योजना देखील वापरल्या जातात):
- पर्यवेक्षित शिक्षण
- अप्रकाशित शिक्षण
- मजबुतीकरण शिक्षण
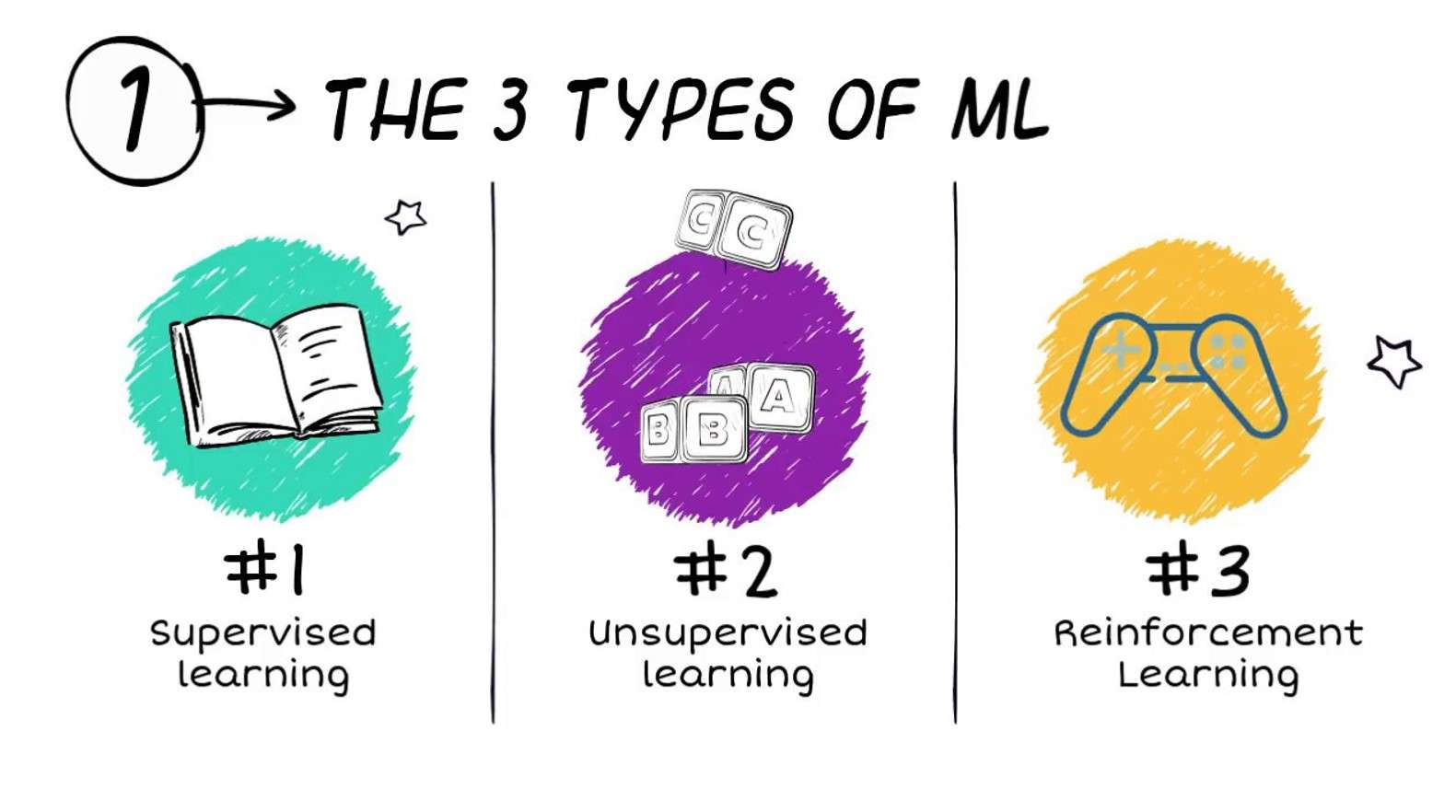
पर्यवेक्षित शिक्षण
पर्यवेक्षित मशीन लर्निंग हे तंत्रांचा संदर्भ देते ज्यामध्ये मशीन लर्निंग मॉडेलला व्याजाच्या प्रमाणासाठी स्पष्ट लेबल्ससह डेटाचा संग्रह दिला जातो (या प्रमाणाला सहसा प्रतिसाद किंवा लक्ष्य म्हणून संबोधले जाते).
AI मॉडेल्सना प्रशिक्षित करण्यासाठी, अर्ध-पर्यवेक्षित शिक्षणामध्ये लेबल नसलेल्या आणि लेबल नसलेल्या डेटाचे मिश्रण वापरले जाते.
तुम्ही लेबल न केलेल्या डेटासह काम करत असल्यास, तुम्हाला काही डेटा लेबलिंग करणे आवश्यक आहे.
लेबलिंग ही मदत करण्यासाठी नमुने लेबल करण्याची प्रक्रिया आहे मशीन लर्निंगचे प्रशिक्षण मॉडेल लेबलिंग प्रामुख्याने लोकांकडून केले जाते, जे महाग आणि वेळ घेणारे असू शकते. तथापि, लेबलिंग प्रक्रिया स्वयंचलित करण्यासाठी तंत्रे आहेत.
आम्ही आधी चर्चा केलेली कर्ज अर्ज परिस्थिती हे पर्यवेक्षित शिक्षणाचे उत्कृष्ट उदाहरण आहे. आमच्याकडे पूर्वीच्या कर्ज अर्जदारांच्या क्रेडिट रेटिंग्स (आणि कदाचित उत्पन्न पातळी, वय आणि इतर) तसेच विशिष्ट लेबले संबंधित ऐतिहासिक डेटा होता ज्याने आम्हाला सांगितले की प्रश्नातील व्यक्तीने त्यांचे कर्ज चुकवले किंवा नाही.
प्रतिगमन आणि वर्गीकरण हे पर्यवेक्षी शिक्षण तंत्राचे दोन उपसंच आहेत.
- वर्गीकरण - डेटाचे वर्गीकरण योग्यरित्या करण्यासाठी ते अल्गोरिदम वापरते. स्पॅम फिल्टर हे एक उदाहरण आहे. “स्पॅम” ही व्यक्तिनिष्ठ श्रेणी असू शकते—स्पॅम आणि नॉन-स्पॅम संप्रेषणांमधील रेषा अस्पष्ट आहे—आणि स्पॅम फिल्टर अल्गोरिदम तुमच्या फीडबॅकवर (म्हणजे मनुष्यांनी स्पॅम म्हणून चिन्हांकित केलेला ईमेल) सतत परिष्कृत होत आहे.
- प्रतिगमन - आश्रित आणि स्वतंत्र व्हेरिएबल्समधील कनेक्शन समजून घेण्यासाठी हे उपयुक्त आहे. रीग्रेशन मॉडेल अनेक डेटा स्रोतांवर आधारित संख्यात्मक मूल्यांचा अंदाज लावू शकतात, जसे की एखाद्या विशिष्ट कंपनीसाठी विक्री महसूल अंदाज. रेखीय प्रतिगमन, लॉजिस्टिक प्रतिगमन आणि बहुपदी प्रतिगमन ही काही प्रमुख प्रतिगमन तंत्रे आहेत.
अप्रकाशित शिक्षण
पर्यवेक्षित नसलेल्या शिक्षणामध्ये, आम्हाला लेबल नसलेला डेटा दिला जातो आणि आम्ही फक्त नमुने शोधत असतो. आपण Amazon आहात असे भासवू या. क्लायंटच्या खरेदीच्या इतिहासावर आधारित आम्हाला कोणतेही क्लस्टर (समान ग्राहकांचे गट) सापडतील का?
आमच्याकडे एखाद्या व्यक्तीच्या प्राधान्यांबद्दल स्पष्ट, निर्णायक डेटा नसला तरीही, या उदाहरणात, ग्राहकांचा एक विशिष्ट संच तुलनात्मक वस्तू खरेदी करतो हे जाणून घेतल्याने आम्हाला क्लस्टरमधील इतर व्यक्तींनी काय खरेदी केले आहे यावर आधारित खरेदीच्या सूचना देऊ शकतात.
Amazon चे "तुम्हाला देखील स्वारस्य असू शकते" कॅरोसेल समान तंत्रज्ञानाद्वारे समर्थित आहे.
पर्यवेक्षित नसलेले शिक्षण तुम्हाला एकत्र काय गटबद्ध करायचे आहे यावर अवलंबून क्लस्टरिंग किंवा असोसिएशनद्वारे डेटाचे गटबद्ध करू शकते.
- क्लस्टरिंग - पर्यवेक्षित नसलेले शिक्षण डेटामधील नमुने शोधून या आव्हानावर मात करण्याचा प्रयत्न करते. समान क्लस्टर किंवा गट असल्यास, अल्गोरिदम त्यांना एका विशिष्ट पद्धतीने वर्गीकृत करेल. मागील खरेदी इतिहासाच्या आधारे क्लायंटचे वर्गीकरण करण्याचा प्रयत्न करणे हे याचे एक उदाहरण आहे.
- असोसिएशन - पर्यवेक्षित नसलेले शिक्षण विविध गटांचे नियम आणि अर्थ समजून घेण्याचा प्रयत्न करून या आव्हानाचा सामना करण्याचा प्रयत्न करते. असोसिएशन समस्येचे वारंवार उदाहरण म्हणजे ग्राहकांच्या खरेदीमधील दुवा निश्चित करणे. कोणत्या वस्तू एकत्र खरेदी केल्या आहेत हे जाणून घेण्यात स्टोअर्सना स्वारस्य असू शकते आणि सहज प्रवेशासाठी या उत्पादनांची स्थिती व्यवस्था करण्यासाठी या माहितीचा वापर करू शकतात.
मजबुतीकरण शिक्षण
रीइन्फोर्समेंट लर्निंग हे मशीन लर्निंग मॉडेल्सना परस्परसंवादी सेटिंगमध्ये ध्येय-केंद्रित निर्णयांची मालिका घेण्यासाठी शिकवण्याचे तंत्र आहे. वर नमूद केलेली गेमिंग वापर प्रकरणे याचे उत्कृष्ट उदाहरण आहेत.
तुम्हाला AlphaZero चे हजारो मागील बुद्धिबळ खेळ इनपुट करावे लागणार नाहीत, प्रत्येकाला “चांगले” किंवा “खराब” असे लेबल लावलेले आहे. त्याला फक्त खेळाचे नियम आणि ध्येय शिकवा आणि नंतर यादृच्छिक कृती करून पहा.
कार्यक्रमाला उद्दिष्टाच्या जवळ नेणार्या क्रियाकलापांना सकारात्मक मजबुतीकरण दिले जाते (जसे की एक ठोस मोहरा स्थिती विकसित करणे). जेव्हा कृतींचा विपरीत परिणाम होतो (जसे की राजाला अकाली बदलणे), तेव्हा ते नकारात्मक मजबुतीकरण मिळवतात.
ही पद्धत वापरून सॉफ्टवेअर शेवटी गेममध्ये प्रभुत्व मिळवू शकते.
मजबुतीकरण शिक्षण रोबोटिक्समध्ये क्लिष्ट आणि अभियंता-ते-कठीण क्रिया करण्यासाठी रोबोट्स शिकवण्यासाठी मोठ्या प्रमाणावर वापरले जाते. काही वेळा रहदारीचा प्रवाह सुधारण्यासाठी ट्रॅफिक सिग्नल सारख्या रस्त्याच्या पायाभूत सुविधांच्या संयोगाने त्याचा वापर केला जातो.
मशीन लर्निंगने काय करता येईल?
समाज आणि उद्योगात मशीन लर्निंगच्या वापरामुळे मानवी प्रयत्नांच्या विस्तृत श्रेणीत प्रगती होत आहे.
आमच्या दैनंदिन जीवनात, मशिन लर्निंग आता Google च्या शोध आणि प्रतिमा अल्गोरिदम नियंत्रित करते, जे आम्हाला आवश्यक असताना आम्हाला आवश्यक असलेल्या माहितीशी अधिक अचूकपणे जुळवून घेण्यास अनुमती देते.
वैद्यकशास्त्रात, उदाहरणार्थ, डॉक्टरांना कर्करोग कसा पसरतो हे समजून घेण्यास आणि अंदाज लावण्यास मदत करण्यासाठी अनुवांशिक डेटावर मशीन लर्निंग लागू केले जात आहे, ज्यामुळे अधिक प्रभावी उपचार पद्धती विकसित होऊ शकतात.
खोल अंतराळातील डेटा येथे मोठ्या रेडिओ दुर्बिणीद्वारे पृथ्वीवर संकलित केला जात आहे – आणि मशीन लर्निंगसह विश्लेषण केल्यानंतर, ते आम्हाला कृष्णविवरांचे रहस्य उलगडण्यात मदत करत आहे.
किरकोळ क्षेत्रातील मशीन लर्निंग खरेदीदारांना ऑनलाइन खरेदी करू इच्छिणाऱ्या गोष्टींशी जोडते आणि दुकानातील कर्मचाऱ्यांना त्यांच्या क्लायंटला ब्रिक-अँड-मोर्टार जगामध्ये प्रदान केलेली सेवा तयार करण्यात मदत करते.
जे निष्पापांना दुखावू इच्छितात त्यांच्या वागणुकीचा अंदाज घेण्यासाठी दहशतवाद आणि अतिरेकाविरुद्धच्या लढाईत मशीन लर्निंगचा वापर केला जातो.
नॅचरल लँग्वेज प्रोसेसिंग (NLP) म्हणजे संगणकांना मशीन लर्निंगद्वारे मानवी भाषेत आम्हाला समजून घेण्याची आणि आमच्याशी संवाद साधण्याची परवानगी देण्याच्या प्रक्रियेचा संदर्भ आहे आणि त्याचा परिणाम भाषांतर तंत्रज्ञानामध्ये तसेच आम्ही दररोज वापरत असलेल्या आवाज-नियंत्रित उपकरणांमध्ये प्रगती झाली आहे, जसे की Alexa, Google dot, Siri आणि Google सहाय्यक.
कोणत्याही प्रश्नाशिवाय, मशीन लर्निंग हे एक परिवर्तनीय तंत्रज्ञान असल्याचे दाखवत आहे.
आपल्या सोबत काम करण्यास सक्षम असलेले रोबोट्स आणि आपली स्वतःची मौलिकता आणि कल्पकता त्यांच्या निर्दोष तर्कशास्त्र आणि अतिमानवी गतीने वाढवणे ही आता विज्ञान कल्पनारम्य कल्पना राहिलेली नाही – ते अनेक क्षेत्रांमध्ये वास्तव बनत आहेत.
मशीन लर्निंग वापर प्रकरणे
1. सायबर सुरक्षा
नेटवर्क अधिक क्लिष्ट झाल्यामुळे, सायबरसुरक्षा तज्ञांनी सुरक्षा धोक्यांच्या सतत विस्तारणाऱ्या श्रेणीशी जुळवून घेण्यासाठी अथक परिश्रम केले आहेत.
वेगाने विकसित होत असलेल्या मालवेअर आणि हॅकिंग रणनीतींचा मुकाबला करणे पुरेसे आव्हानात्मक आहे, परंतु इंटरनेट ऑफ थिंग्ज (IoT) उपकरणांच्या प्रसाराने सायबरसुरक्षा वातावरणात मूलभूतपणे परिवर्तन केले आहे.
हल्ले कोणत्याही क्षणी आणि कोणत्याही ठिकाणी होऊ शकतात.
कृतज्ञतापूर्वक, मशीन लर्निंग अल्गोरिदमने या वेगवान घडामोडींसह चालू ठेवण्यासाठी सायबरसुरक्षा ऑपरेशन्स सक्षम केले आहेत.
भविष्यवाणी करणारी विश्लेषणे झटपट शोधणे आणि हल्ले कमी करणे सक्षम करा, तर मशीन लर्निंग नेटवर्कमधील तुमच्या क्रियाकलापांचे विश्लेषण करू शकते आणि विद्यमान सुरक्षा यंत्रणेतील असामान्यता आणि कमकुवतता शोधू शकते.
2. ग्राहक सेवेचे ऑटोमेशन
ऑनलाइन क्लायंट संपर्कांच्या वाढत्या संख्येचे व्यवस्थापन केल्याने संस्थेवर ताण आला आहे.
त्यांना मिळत असलेल्या चौकशीचे प्रमाण हाताळण्यासाठी त्यांच्याकडे पुरेसे ग्राहक सेवा कर्मचारी नाहीत आणि आउटसोर्सिंगच्या समस्यांचा पारंपारिक दृष्टिकोन संपर्क केंद्र आजच्या अनेक क्लायंटसाठी फक्त अस्वीकार्य आहे.
मशीन लर्निंग तंत्रातील प्रगतीमुळे चॅटबॉट्स आणि इतर स्वयंचलित प्रणाली आता या मागण्या पूर्ण करू शकतात. सांसारिक आणि कमी-प्राधान्य क्रियाकलाप स्वयंचलित करून अधिक उच्च-स्तरीय ग्राहक समर्थन हाती घेण्यासाठी कंपन्या कर्मचार्यांना मुक्त करू शकतात.
योग्यरितीने वापरल्यास, व्यवसायातील मशीन लर्निंग समस्येचे निराकरण सुव्यवस्थित करण्यात मदत करू शकते आणि ग्राहकांना उपयुक्त समर्थनाचा प्रकार प्रदान करते ज्यामुळे ते वचनबद्ध ब्रँड चॅम्पियन बनतात.
एक्सएनयूएमएक्स. संप्रेषण
कोणत्याही प्रकारच्या संप्रेषणामध्ये त्रुटी आणि गैरसमज टाळणे महत्वाचे आहे, परंतु आजच्या व्यावसायिक संप्रेषणांमध्ये ते अधिक आहे.
साध्या व्याकरणाच्या चुका, चुकीचा टोन किंवा चुकीचे भाषांतर यामुळे ईमेल संपर्क, ग्राहक मूल्यांकन, व्हिडिओ कॉन्फरन्सिंग, किंवा मजकूर-आधारित दस्तऐवजीकरण अनेक स्वरूपात.
मशिन लर्निंग सिस्टीममध्ये मायक्रोसॉफ्टच्या क्लिपीच्या दिवसांच्या पलीकडे प्रगत संप्रेषण आहे.
या मशीन लर्निंग उदाहरणांमुळे व्यक्तींना नैसर्गिक भाषा प्रक्रिया, रिअल-टाइम भाषा भाषांतर आणि उच्चार ओळख वापरून सहज आणि अचूकपणे संवाद साधण्यास मदत झाली आहे.
बर्याच व्यक्तींना स्वयं दुरुस्त करण्याची क्षमता नापसंत असताना, त्यांना लाजिरवाण्या चुका आणि अयोग्य टोनपासून संरक्षण मिळणे देखील महत्त्व असते.
4. ऑब्जेक्ट ओळख
डेटा संकलित करणे आणि त्याचा अर्थ लावणे हे तंत्रज्ञान काही काळापासून चालू असताना, संगणक प्रणाली ते काय पहात आहेत हे समजून घेण्यासाठी शिकवणे हे एक फसवे अवघड काम असल्याचे सिद्ध झाले आहे.
मशीन लर्निंग ऍप्लिकेशन्समुळे उपकरणांच्या वाढत्या संख्येत ऑब्जेक्ट ओळखण्याची क्षमता जोडली जात आहे.
उदाहरणार्थ, स्व-ड्रायव्हिंग ऑटोमोबाईल दुसरी कार पाहते तेव्हा ओळखते, जरी प्रोग्रामरने संदर्भ म्हणून वापरण्यासाठी त्या कारचे अचूक उदाहरण दिले नसले तरीही.
चेकआउट प्रक्रियेला गती देण्यासाठी हे तंत्रज्ञान आता किरकोळ व्यवसायांमध्ये वापरले जात आहे. कॅमेरे ग्राहकांच्या कार्टमधील उत्पादने ओळखतात आणि जेव्हा ते स्टोअरमधून बाहेर पडतात तेव्हा त्यांच्या खात्यांचे बिल स्वयंचलितपणे भरू शकतात.
5. डिजिटल विपणन
डिजिटल प्लॅटफॉर्म आणि सॉफ्टवेअर प्रोग्राम्सचा वापर करून आजचे बरेच मार्केटिंग ऑनलाइन केले जाते.
व्यवसाय त्यांच्या ग्राहकांबद्दल आणि त्यांच्या खरेदीच्या वर्तनाबद्दल माहिती संकलित करत असल्याने, विपणन कार्यसंघ त्यांच्या लक्ष्यित प्रेक्षकांचे तपशीलवार चित्र तयार करण्यासाठी आणि त्यांची उत्पादने आणि सेवा शोधण्यासाठी कोणते लोक अधिक इच्छुक आहेत हे शोधण्यासाठी त्या माहितीचा वापर करू शकतात.
मशीन लर्निंग अल्गोरिदम मार्केटर्सना त्या सर्व डेटाचा अर्थ काढण्यात, महत्त्वपूर्ण नमुने आणि गुणधर्म शोधण्यात मदत करतात जे त्यांना शक्यतांचे काटेकोरपणे वर्गीकरण करण्यास अनुमती देतात.
हेच तंत्रज्ञान मोठ्या डिजिटल मार्केटिंग ऑटोमेशनला अनुमती देते. नवीन संभाव्य ग्राहकांना गतिशीलपणे शोधण्यासाठी आणि त्यांना योग्य वेळी आणि ठिकाणी संबंधित विपणन सामग्री प्रदान करण्यासाठी जाहिरात प्रणाली सेट केल्या जाऊ शकतात.
मशीन लर्निंगचे भविष्य
मशीन लर्निंग निश्चितपणे लोकप्रिय होत आहे कारण अधिक व्यवसाय आणि मोठ्या संस्था विशिष्ट आव्हानांना सामोरे जाण्यासाठी किंवा इंधन नवकल्पनासाठी तंत्रज्ञानाचा वापर करतात.
ही निरंतर गुंतवणूक हे समज दर्शवते की मशीन लर्निंग ROI तयार करत आहे, विशेषत: वर नमूद केलेल्या काही स्थापित आणि पुनरुत्पादक वापर प्रकरणांद्वारे.
शेवटी, जर तंत्रज्ञान नेटफ्लिक्स, फेसबुक, ऍमेझॉन, Google नकाशे आणि इतरांसाठी पुरेसे चांगले असेल तर, ते आपल्या कंपनीला त्याच्या डेटाचा जास्तीत जास्त वापर करण्यास मदत करू शकते.
नवीन म्हणून मशीन शिक्षण मॉडेल विकसित आणि लॉन्च केले जातात, आम्ही सर्व उद्योगांमध्ये वापरल्या जाणार्या अनुप्रयोगांच्या संख्येत वाढ पाहणार आहोत.
हे आधीच सोबत घडत आहे चेहरा ओळख, जे तुमच्या iPhone वर एकेकाळी नवीन फंक्शन होते परंतु आता ते प्रोग्राम्स आणि ऍप्लिकेशन्सच्या विस्तृत श्रेणीमध्ये लागू केले जात आहे, विशेषत: सार्वजनिक सुरक्षिततेशी संबंधित.
मशीन लर्निंगसह प्रारंभ करण्याचा प्रयत्न करणार्या बर्याच संस्थांसाठी महत्त्वाची गोष्ट म्हणजे उज्ज्वल भविष्यवादी दृष्टीकोन पाहणे आणि तंत्रज्ञान आपल्याला मदत करू शकणारी वास्तविक व्यावसायिक आव्हाने शोधणे.
निष्कर्ष
उत्तर-औद्योगिक युगात, शास्त्रज्ञ आणि व्यावसायिक एक संगणक तयार करण्याचा प्रयत्न करीत आहेत जे मानवांसारखे वागू शकेल.
थिंकिंग मशीन हे AI चे मानवतेसाठी सर्वात महत्त्वपूर्ण योगदान आहे; या स्वयं-चालित मशीनच्या अभूतपूर्व आगमनाने कॉर्पोरेट ऑपरेटिंग नियमांमध्ये झपाट्याने बदल केले आहेत.
सेल्फ-ड्रायव्हिंग वाहने, स्वयंचलित सहाय्यक, स्वायत्त उत्पादन कर्मचारी आणि स्मार्ट शहरे यांनी अलीकडेच स्मार्ट मशीनची व्यवहार्यता दर्शविली आहे. मशीन लर्निंग क्रांती आणि मशीन लर्निंगचे भविष्य दीर्घकाळ आपल्यासोबत असेल.





प्रत्युत्तर द्या