ສາລະບານ[ເຊື່ອງ][ສະແດງ]
ດຽວນີ້ພວກເຮົາສາມາດຄິດໄລ່ການຂະຫຍາຍອາວະກາດແລະຄວາມຊັບຊ້ອນນາທີຂອງອະນຸພາກ subatomic ຂອບໃຈຄອມພິວເຕີ.
ຄອມພິວເຕີຕີມະນຸດເມື່ອເວົ້າເຖິງການນັບ ແລະ ການຄຳນວນ, ພ້ອມທັງປະຕິບັດຕາມຂະບວນການແມ່ນ/ບໍ່ແມ່ນຢ່າງມີເຫດຜົນ, ຍ້ອນອິເລັກຕອນທີ່ເດີນທາງດ້ວຍຄວາມໄວຂອງແສງຜ່ານວົງຈອນຂອງມັນ.
ຢ່າງໃດກໍຕາມ, ພວກເຮົາບໍ່ຄ່ອຍເຫັນພວກມັນເປັນ "ອັດສະລິຍະ" ເພາະວ່າໃນອະດີດ, ຄອມພິວເຕີບໍ່ສາມາດປະຕິບັດສິ່ງໃດໄດ້ໂດຍບໍ່ມີການສອນ (ໂຄງການ) ໂດຍມະນຸດ.
ການຮຽນຮູ້ເຄື່ອງຈັກ, ລວມທັງການຮຽນຮູ້ເລິກແລະ ປັນຍາປະດິດ, ໄດ້ກາຍເປັນ buzzword ໃນຫົວຂໍ້ວິທະຍາສາດແລະເຕັກໂນໂລຊີ.
ການຮຽນຮູ້ເຄື່ອງຈັກເບິ່ງຄືວ່າມີຢູ່ທົ່ວທຸກແຫ່ງ, ແຕ່ຫຼາຍຄົນທີ່ໃຊ້ ຄຳ ສັບນີ້ຕ້ອງພະຍາຍາມ ກຳ ນົດຢ່າງພຽງພໍວ່າມັນແມ່ນຫຍັງ, ມັນເຮັດຫຍັງ, ແລະມັນໃຊ້ດີທີ່ສຸດ.
ບົດຂຽນນີ້ຊອກຫາຄວາມກະຈ່າງແຈ້ງກ່ຽວກັບການຮຽນຮູ້ຂອງເຄື່ອງຈັກໃນຂະນະທີ່ຍັງໃຫ້ຕົວຢ່າງຈິງໆ, ໃນໂລກທີ່ແທ້ຈິງຂອງວິທີການເຮັດວຽກຂອງເຕັກໂນໂລຢີເພື່ອສະແດງໃຫ້ເຫັນວ່າເປັນຫຍັງມັນຈຶ່ງເປັນປະໂຫຍດຫຼາຍ.
ຈາກນັ້ນ, ພວກເຮົາຈະເບິ່ງວິທີການຮຽນຮູ້ເຄື່ອງຈັກຕ່າງໆ ແລະເບິ່ງວ່າພວກມັນຖືກໃຊ້ເພື່ອແກ້ໄຂສິ່ງທ້າທາຍທາງທຸລະກິດແນວໃດ.
ສຸດທ້າຍ, ພວກເຮົາຈະປຶກສາຫາລືກັບລູກແກ້ວຂອງພວກເຮົາສໍາລັບການຄາດຄະເນໄວກ່ຽວກັບອະນາຄົດຂອງການຮຽນຮູ້ເຄື່ອງຈັກ.
Machine Learning ແມ່ນຫຍັງ?
ການຮຽນຮູ້ຂອງເຄື່ອງຈັກແມ່ນລະບຽບວິໄນຂອງວິທະຍາສາດຄອມພິວເຕີທີ່ຊ່ວຍໃຫ້ຄອມພິວເຕີສາມາດຄາດເດົາຮູບແບບຕ່າງໆຈາກຂໍ້ມູນໂດຍບໍ່ໄດ້ຮັບການສອນຢ່າງຊັດເຈນວ່າຮູບແບບເຫຼົ່ານັ້ນແມ່ນຫຍັງ.
ບົດສະຫຼຸບເຫຼົ່ານີ້ມັກຈະອີງໃສ່ການນໍາໃຊ້ສູດການຄິດໄລ່ອັດຕະໂນມັດເພື່ອປະເມີນລັກສະນະສະຖິຕິຂອງຂໍ້ມູນແລະການພັດທະນາແບບຈໍາລອງທາງຄະນິດສາດເພື່ອສະແດງຄວາມສໍາພັນລະຫວ່າງຄ່າຕ່າງໆ.
ກົງກັນຂ້າມກັບຄອມພິວເຕີ້ຄລາສສິກ, ເຊິ່ງແມ່ນອີງໃສ່ລະບົບການກໍານົດ, ເຊິ່ງພວກເຮົາໃຫ້ກົດລະບຽບທີ່ກໍານົດໄວ້ແກ່ຄອມພິວເຕີຢ່າງຈະແຈ້ງເພື່ອໃຫ້ມັນເຮັດຫນ້າທີ່ສະເພາະໃດຫນຶ່ງ.
ວິທີການຄອມພິວເຕີການຂຽນໂປລແກລມນີ້ແມ່ນເອີ້ນວ່າການຂຽນໂປຼແກຼມຕາມກົດລະບຽບ. ການຮຽນຮູ້ຂອງເຄື່ອງຈັກແຕກຕ່າງຈາກ ແລະ ປະຕິບັດການຂຽນໂປຼແກຼມຕາມກົດລະບຽບທີ່ມັນສາມາດຫັກອອກກົດລະບຽບເຫຼົ່ານີ້ດ້ວຍຕົວມັນເອງ.
ສົມມຸດວ່າທ່ານເປັນຜູ້ຈັດການທະນາຄານທີ່ຕ້ອງການກໍານົດວ່າຄໍາຮ້ອງຂໍເງິນກູ້ຈະລົ້ມເຫລວໃນການກູ້ຢືມຂອງເຂົາເຈົ້າ.
ໃນວິທີການທີ່ອີງໃສ່ກົດລະບຽບ, ຜູ້ຈັດການທະນາຄານ (ຫຼືຜູ້ຊ່ຽວຊານອື່ນໆ) ຈະແຈ້ງໃຫ້ຄອມພິວເຕີຢ່າງຈະແຈ້ງວ່າຖ້າຄະແນນສິນເຊື່ອຂອງຜູ້ສະຫມັກຕ່ໍາກວ່າລະດັບໃດຫນຶ່ງ, ຄໍາຮ້ອງສະຫມັກຄວນຈະຖືກປະຕິເສດ.
ຢ່າງໃດກໍຕາມ, ໂຄງການການຮຽນຮູ້ເຄື່ອງຈັກພຽງແຕ່ຈະວິເຄາະຂໍ້ມູນກ່ອນຫນ້າກ່ຽວກັບການຈັດອັນດັບສິນເຊື່ອຂອງລູກຄ້າແລະຜົນໄດ້ຮັບການກູ້ຢືມແລະກໍານົດວ່າຂອບເຂດນີ້ຄວນຈະເປັນຂອງຕົນເອງ.
ເຄື່ອງຈັກຮຽນຮູ້ຈາກຂໍ້ມູນທີ່ຜ່ານມາແລະສ້າງກົດລະບຽບຂອງຕົນເອງດ້ວຍວິທີນີ້. ແນ່ນອນ, ນີ້ແມ່ນພຽງແຕ່ primer ກ່ຽວກັບການຮຽນຮູ້ເຄື່ອງຈັກ; ຮູບແບບການຮຽນຮູ້ເຄື່ອງຈັກໃນໂລກທີ່ແທ້ຈິງແມ່ນມີຄວາມຊັບຊ້ອນຫຼາຍກ່ວາເກນພື້ນຖານ.
ຢ່າງໃດກໍຕາມ, ມັນເປັນການສະແດງໃຫ້ເຫັນທີ່ດີເລີດຂອງທ່າແຮງຂອງການຮຽນຮູ້ເຄື່ອງຈັກ.
ກ ເຄື່ອງ ຮຽນ?
ເພື່ອຮັກສາສິ່ງທີ່ງ່າຍດາຍ, ເຄື່ອງຈັກ "ຮຽນຮູ້" ໂດຍການກວດສອບຮູບແບບໃນຂໍ້ມູນປຽບທຽບ. ພິຈາລະນາຂໍ້ມູນເປັນຂໍ້ມູນທີ່ເຈົ້າລວບລວມຈາກໂລກພາຍນອກ. ການປ້ອນຂໍ້ມູນເຄື່ອງຈັກຫຼາຍເທົ່າໃດ, ມັນຈະກາຍເປັນ “ສະຫຼາດຂຶ້ນ”.
ຢ່າງໃດກໍຕາມ, ບໍ່ແມ່ນຂໍ້ມູນທັງຫມົດແມ່ນຄືກັນ. ສົມມຸດວ່າທ່ານເປັນໂຈນສະລັດທີ່ມີຈຸດປະສົງຊີວິດເພື່ອເປີດເຜີຍຄວາມອຸດົມສົມບູນທີ່ຝັງຢູ່ໃນເກາະ. ເຈົ້າຈະຕ້ອງການຄວາມຮູ້ຈໍານວນຫຼວງຫຼາຍເພື່ອຊອກຫາລາງວັນ.
ຄວາມຮູ້ນີ້, ເຊັ່ນຂໍ້ມູນ, ສາມາດນໍາທ່ານໄປໃນທາງທີ່ຖືກຕ້ອງຫຼືຜິດ.
ຂໍ້ມູນ / ຂໍ້ມູນທີ່ໄດ້ມາຫຼາຍເທົ່າໃດ, ຄວາມບໍ່ຊັດເຈນຫນ້ອຍມີ, ແລະໃນທາງກັບກັນ. ດັ່ງນັ້ນ, ມັນເປັນສິ່ງ ສຳ ຄັນທີ່ຈະພິຈາລະນາການຈັດລຽງຂອງຂໍ້ມູນທີ່ເຈົ້າ ກຳ ລັງໃຫ້ເຄື່ອງຂອງເຈົ້າທີ່ຈະຮຽນຮູ້ຈາກ.
ຢ່າງໃດກໍຕາມ, ເມື່ອຂໍ້ມູນຈໍານວນຫຼວງຫຼາຍຖືກສະຫນອງ, ຄອມພິວເຕີສາມາດເຮັດໃຫ້ການຄາດຄະເນ. ເຄື່ອງຈັກສາມາດຄາດຄະເນອະນາຄົດໄດ້ຕາບໃດທີ່ມັນບໍ່ deviate ຫຼາຍຈາກອະດີດ.
ເຄື່ອງຈັກ "ຮຽນຮູ້" ໂດຍການວິເຄາະຂໍ້ມູນປະຫວັດສາດເພື່ອກໍານົດສິ່ງທີ່ອາດຈະເກີດຂຶ້ນ.
ຖ້າຂໍ້ມູນເກົ່າຄ້າຍຄືກັບຂໍ້ມູນໃຫມ່, ສິ່ງຕ່າງໆທີ່ທ່ານສາມາດເວົ້າກ່ຽວກັບຂໍ້ມູນທີ່ຜ່ານມາມີແນວໂນ້ມທີ່ຈະນໍາໃຊ້ກັບຂໍ້ມູນໃຫມ່. ມັນຄືກັບວ່າເຈົ້າກຳລັງເບິ່ງຄືນເພື່ອເບິ່ງໄປຂ້າງໜ້າ.
ປະເພດຂອງການຮຽນຮູ້ເຄື່ອງຈັກແມ່ນຫຍັງ?
Algorithms ສໍາລັບການຮຽນຮູ້ເຄື່ອງຈັກໄດ້ຖືກຈັດປະເພດເປັນສາມປະເພດຢ່າງກວ້າງຂວາງ (ເຖິງແມ່ນວ່າລະບົບການຈັດປະເພດອື່ນໆຍັງຖືກນໍາໃຊ້):
- ການຄວບຄຸມການຮຽນຮູ້
- ການຮຽນທີ່ບໍ່ມີການຄວບຄຸມ
- ການຮຽນຮູ້ການເສີມສ້າງ
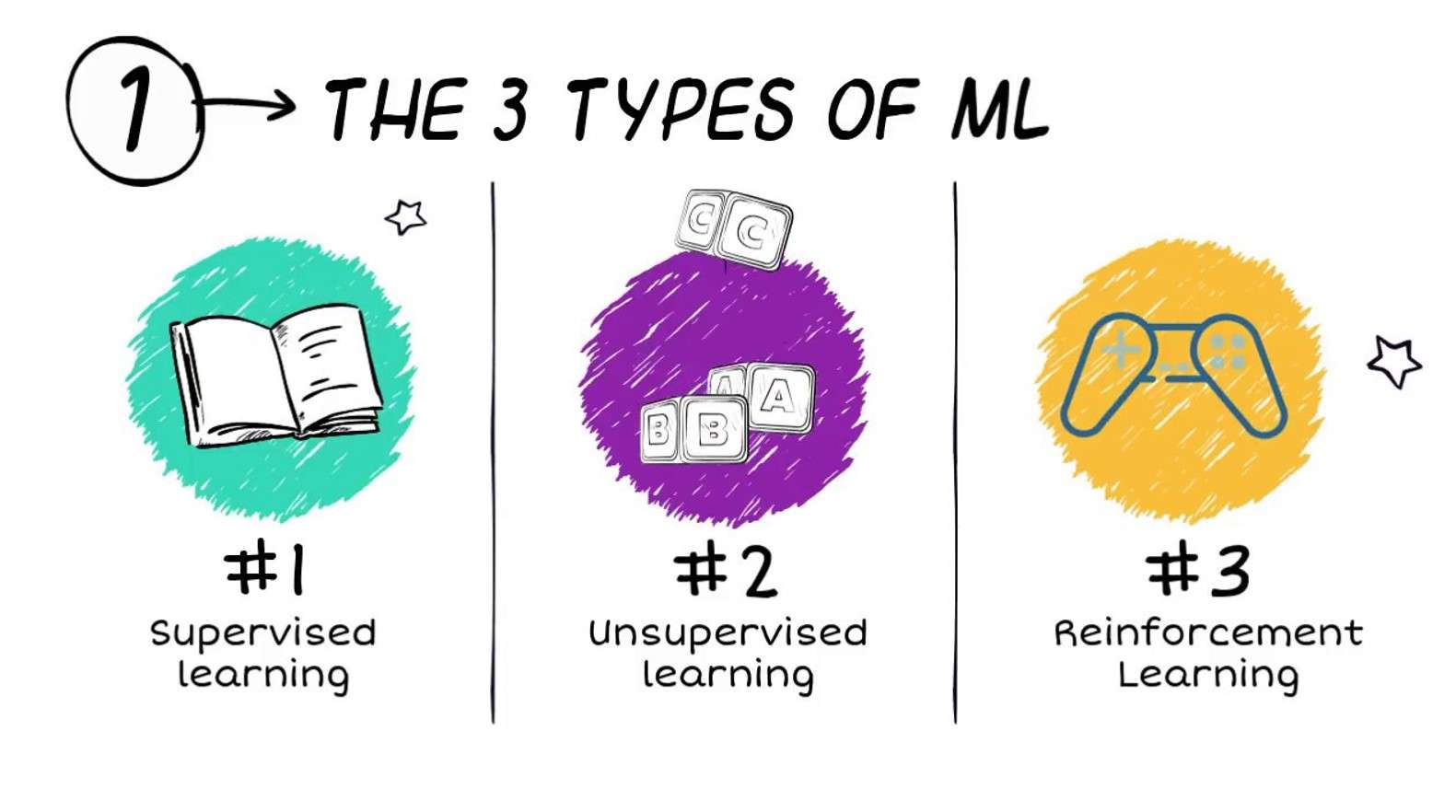
ການຄວບຄຸມການຮຽນຮູ້
Supervised machine learning ຫມາຍເຖິງເຕັກນິກທີ່ຮູບແບບການຮຽນຮູ້ເຄື່ອງຈັກໄດ້ຮັບການລວບລວມຂໍ້ມູນທີ່ມີປ້າຍຊື່ທີ່ຊັດເຈນສໍາລັບປະລິມານຄວາມສົນໃຈ (ປະລິມານນີ້ມັກຈະເອີ້ນວ່າການຕອບສະຫນອງຫຼືເປົ້າຫມາຍ).
ເພື່ອຝຶກອົບຮົມແບບຈໍາລອງ AI, ການຮຽນຮູ້ແບບເຄິ່ງຄວບຄຸມແມ່ນໃຊ້ການປະສົມຂອງຂໍ້ມູນທີ່ຕິດສະຫຼາກ ແລະບໍ່ມີປ້າຍກຳກັບ.
ຖ້າທ່ານກໍາລັງເຮັດວຽກກັບຂໍ້ມູນທີ່ບໍ່ມີປ້າຍຊື່, ທ່ານຈະຕ້ອງເຮັດການຕິດສະຫຼາກຂໍ້ມູນບາງຢ່າງ.
ການຕິດສະຫຼາກແມ່ນຂະບວນການຂອງຕົວຢ່າງການຕິດສະຫຼາກເພື່ອຊ່ວຍໃນ ການຝຶກອົບຮົມການຮຽນຮູ້ເຄື່ອງຈັກ ຕົວແບບ. ການຕິດສະຫຼາກແມ່ນເຮັດໂດຍປະຊາຊົນຕົ້ນຕໍ, ເຊິ່ງສາມາດມີຄ່າໃຊ້ຈ່າຍຫຼາຍແລະໃຊ້ເວລາຫຼາຍ. ຢ່າງໃດກໍຕາມ, ມີເຕັກນິກທີ່ຈະອັດຕະໂນມັດຂະບວນການຕິດສະຫຼາກ.
ສະຖານະການຂໍເງິນກູ້ທີ່ພວກເຮົາໄດ້ສົນທະນາກ່ອນນີ້ແມ່ນຕົວຢ່າງທີ່ດີເລີດຂອງການຮຽນຮູ້ການເບິ່ງແຍງ. ພວກເຮົາມີຂໍ້ມູນປະຫວັດສາດກ່ຽວກັບການໃຫ້ຄະແນນສິນເຊື່ອຂອງຜູ້ຂໍກູ້ຢືມໃນອະດີດ (ແລະບາງທີລະດັບລາຍຮັບ, ອາຍຸ, ແລະອື່ນໆ) ເຊັ່ນດຽວກັນກັບປ້າຍສະເພາະທີ່ບອກພວກເຮົາວ່າ, ຫຼືບໍ່ຜູ້ທີ່ຢູ່ໃນຄໍາຖາມ defaulted ໃນເງິນກູ້ຂອງເຂົາເຈົ້າ.
Regression ແລະການຈັດປະເພດແມ່ນສອງຊຸດຍ່ອຍຂອງເຕັກນິກການຮຽນຮູ້ທີ່ມີການຄວບຄຸມ.
- ການຈັດປະເພດ – ມັນເຮັດໃຫ້ການນໍາໃຊ້ຂອງ algorithm ເພື່ອຈັດປະເພດຂໍ້ມູນຢ່າງຖືກຕ້ອງ. ການກັ່ນຕອງຂີ້ເຫຍື້ອແມ່ນຕົວຢ່າງຫນຶ່ງ. "ຂີ້ເຫຍື້ອ" ສາມາດເປັນປະເພດຫົວຂໍ້ - ເສັ້ນລະຫວ່າງການສື່ສານ spam ແລະບໍ່ແມ່ນ spam ແມ່ນມົວ - ແລະລະບົບການກັ່ນຕອງ spam ປັບປຸງຕົວມັນເອງຢ່າງຕໍ່ເນື່ອງໂດຍອີງຕາມຄໍາຄຶດຄໍາເຫັນຂອງເຈົ້າ (ຫມາຍຄວາມວ່າອີເມວທີ່ມະນຸດຫມາຍວ່າເປັນ spam).
- Regression – ມັນເປັນປະໂຫຍດໃນການເຂົ້າໃຈການເຊື່ອມຕໍ່ລະຫວ່າງຕົວແປທີ່ຂຶ້ນກັບ ແລະເອກະລາດ. ຮູບແບບການຖົດຖອຍສາມາດຄາດຄະເນມູນຄ່າຕົວເລກໂດຍອີງໃສ່ແຫຼ່ງຂໍ້ມູນຈໍານວນຫນຶ່ງ, ເຊັ່ນ: ການຄາດຄະເນລາຍໄດ້ຈາກການຂາຍສໍາລັບບໍລິສັດສະເພາະໃດຫນຶ່ງ. Linear regression, logistic regression, and polynomial regression ແມ່ນບາງເຕັກນິກການຖົດຖອຍທີ່ໂດດເດັ່ນ.
ການຮຽນທີ່ບໍ່ມີການຄວບຄຸມ
ໃນການຮຽນຮູ້ທີ່ບໍ່ມີການເບິ່ງແຍງ, ພວກເຮົາໄດ້ຮັບຂໍ້ມູນທີ່ບໍ່ມີປ້າຍຊື່ແລະພຽງແຕ່ຊອກຫາຮູບແບບ. ໃຫ້ສົມມຸດວ່າທ່ານເປັນ Amazon. ພວກເຮົາສາມາດຊອກຫາກຸ່ມໃດ (ກຸ່ມຂອງຜູ້ບໍລິໂພກທີ່ຄ້າຍຄືກັນ) ໂດຍອີງໃສ່ປະຫວັດການຊື້ຂອງລູກຄ້າບໍ?
ເຖິງແມ່ນວ່າພວກເຮົາບໍ່ມີຂໍ້ມູນທີ່ຊັດເຈນ, ສະຫຼຸບກ່ຽວກັບຄວາມມັກຂອງບຸກຄົນ, ໃນຕົວຢ່າງນີ້, ພຽງແຕ່ຮູ້ວ່າຊຸດສະເພາະຂອງຜູ້ບໍລິໂພກຊື້ສິນຄ້າທີ່ປຽບທຽບໄດ້ຊ່ວຍໃຫ້ພວກເຮົາສະເຫນີຄໍາແນະນໍາການຊື້ໂດຍອີງໃສ່ສິ່ງທີ່ບຸກຄົນອື່ນໃນກຸ່ມໄດ້ຊື້.
Amazon's "ທ່ານອາດຈະສົນໃຈໃນ" carousel ແມ່ນຂັບເຄື່ອນໂດຍເຕັກໂນໂລຢີທີ່ຄ້າຍຄືກັນ.
ການຮຽນຮູ້ແບບບໍ່ມີການຄວບຄຸມສາມາດຈັດກຸ່ມຂໍ້ມູນຜ່ານການຈັດກຸ່ມ ຫຼື ສະມາຄົມ, ຂຶ້ນກັບສິ່ງທີ່ທ່ານຕ້ອງການຈັດກຸ່ມເຂົ້າກັນ.
- Clustering – ຄວາມພະຍາຍາມໃນການຮຽນຮູ້ທີ່ບໍ່ມີການຄວບຄຸມເພື່ອເອົາຊະນະສິ່ງທ້າທາຍນີ້ໂດຍການຊອກຫາຮູບແບບໃນຂໍ້ມູນ. ຖ້າມີກຸ່ມ ຫຼືກຸ່ມທີ່ຄ້າຍຄືກັນ, ສູດການຄິດໄລ່ຈະຈັດປະເພດພວກມັນໃນລັກສະນະສະເພາະ. ການພະຍາຍາມຈັດປະເພດລູກຄ້າໂດຍອີງໃສ່ປະຫວັດການຊື້ທີ່ຜ່ານມາແມ່ນຕົວຢ່າງຂອງເລື່ອງນີ້.
- ສະມາຄົມ – ການຮຽນຮູ້ທີ່ບໍ່ມີການເບິ່ງແຍງພະຍາຍາມຮັບມືກັບສິ່ງທ້າທາຍນີ້ໂດຍການພະຍາຍາມເຂົ້າໃຈກົດລະບຽບ ແລະ ຄວາມໝາຍທີ່ຕິດພັນກັບກຸ່ມຕ່າງໆ. ຕົວຢ່າງເລື້ອຍໆຂອງບັນຫາສະມາຄົມແມ່ນການກໍານົດການເຊື່ອມຕໍ່ລະຫວ່າງການຊື້ຂອງລູກຄ້າ. ຮ້ານຄ້າສາມາດສົນໃຈຢາກຮູ້ວ່າສິນຄ້າໃດຖືກຊື້ຮ່ວມກັນແລະສາມາດນໍາໃຊ້ຂໍ້ມູນນີ້ເພື່ອຈັດຕໍາແຫນ່ງຂອງຜະລິດຕະພັນເຫຼົ່ານີ້ເພື່ອໃຫ້ສາມາດເຂົ້າເຖິງໄດ້ງ່າຍ.
ການຮຽນຮູ້ການເສີມສ້າງ
ການຮຽນຮູ້ເສີມແມ່ນເຕັກນິກການສອນແບບຈໍາລອງການຮຽນຮູ້ຂອງເຄື່ອງຈັກເພື່ອເຮັດການຕັດສິນໃຈຕາມເປົ້າໝາຍໃນແບບໂຕ້ຕອບ. ກໍລະນີການນໍາໃຊ້ການຫຼິ້ນເກມທີ່ໄດ້ກ່າວມາຂ້າງເທິງນີ້ແມ່ນຕົວຢ່າງທີ່ດີເລີດຂອງເລື່ອງນີ້.
ທ່ານບໍ່ຈໍາເປັນຕ້ອງໃສ່ AlphaZero ຫຼາຍພັນເກມຫມາກຮຸກທີ່ຜ່ານມາ, ແຕ່ລະຄົນມີການເຄື່ອນໄຫວ "ດີ" ຫຼື "ທຸກຍາກ" ປ້າຍຊື່. ພຽງແຕ່ສອນມັນກົດລະບຽບຂອງເກມແລະເປົ້າຫມາຍ, ແລະຫຼັງຈາກນັ້ນໃຫ້ມັນພະຍາຍາມອອກການກະທໍາແບບສຸ່ມ.
ການເສີມສ້າງທາງບວກແມ່ນມອບໃຫ້ກັບກິດຈະກໍາທີ່ເອົາໂຄງການເຂົ້າໃກ້ເປົ້າຫມາຍ (ເຊັ່ນ: ການພັດທະນາຕໍາແຫນ່ງທີ່ແຂງ). ເມື່ອການກະທຳມີຜົນກະທົບທາງກົງກັນຂ້າມ (ເຊັ່ນການປ່ຽນກະສັດກ່ອນໄວອັນຄວນ), ເຂົາເຈົ້າໄດ້ຮັບການເສີມສ້າງທາງລົບ.
ຊອບແວສຸດທ້າຍສາມາດເປັນແມ່ບົດເກມໂດຍໃຊ້ວິທີນີ້.
ການຮຽນຮູ້ການເສີມສ້າງ ຖືກນໍາໃຊ້ຢ່າງກວ້າງຂວາງໃນຫຸ່ນຍົນເພື່ອສອນຫຸ່ນຍົນສໍາລັບການປະຕິບັດທີ່ສັບສົນແລະມີຄວາມຫຍຸ້ງຍາກໃນວິສະວະກອນ. ບາງຄັ້ງມັນຖືກນໍາໃຊ້ໂດຍສົມທົບກັບໂຄງສ້າງພື້ນຖານຂອງຖະຫນົນຫົນທາງ, ເຊັ່ນ: ສັນຍານການຈະລາຈອນ, ເພື່ອປັບປຸງການໄຫຼວຽນຂອງການຈະລາຈອນ.
ສິ່ງທີ່ສາມາດເຮັດໄດ້ດ້ວຍການຮຽນຮູ້ເຄື່ອງຈັກ?
ການນໍາໃຊ້ການຮຽນຮູ້ເຄື່ອງຈັກໃນສັງຄົມແລະອຸດສາຫະກໍາແມ່ນສົ່ງຜົນໃຫ້ມີຄວາມກ້າວຫນ້າໃນຄວາມພະຍາຍາມຢ່າງກວ້າງຂວາງຂອງມະນຸດ.
ໃນຊີວິດປະຈໍາວັນຂອງພວກເຮົາ, ການຮຽນຮູ້ເຄື່ອງຈັກໃນປັດຈຸບັນຄວບຄຸມການຄົ້ນຫາແລະລະບົບຮູບພາບຂອງ Google, ຊ່ວຍໃຫ້ພວກເຮົາສາມາດຈັບຄູ່ໄດ້ຢ່າງຖືກຕ້ອງກັບຂໍ້ມູນທີ່ພວກເຮົາຕ້ອງການເມື່ອພວກເຮົາຕ້ອງການ.
ສໍາລັບຕົວຢ່າງ, ໃນຢາປົວພະຍາດ, ການຮຽນຮູ້ເຄື່ອງຈັກແມ່ນຖືກນໍາໃຊ້ກັບຂໍ້ມູນທາງພັນທຸກໍາເພື່ອຊ່ວຍໃຫ້ທ່ານຫມໍເຂົ້າໃຈແລະຄາດຄະເນວ່າມະເຮັງແຜ່ລາມແນວໃດ, ອະນຸຍາດໃຫ້ພັດທະນາການປິ່ນປົວທີ່ມີປະສິດທິພາບຫຼາຍຂຶ້ນ.
ຂໍ້ມູນຈາກອາວະກາດເລິກແມ່ນໄດ້ຖືກເກັບກໍາຢູ່ທີ່ນີ້ໃນໂລກໂດຍຜ່ານ telescopes ວິທະຍຸຂະຫນາດໃຫຍ່ - ແລະຫຼັງຈາກການວິເຄາະດ້ວຍການຮຽນຮູ້ເຄື່ອງຈັກ, ມັນຈະຊ່ວຍໃຫ້ພວກເຮົາແກ້ໄຂຄວາມລຶກລັບຂອງຂຸມດໍາ.
ການຮຽນຮູ້ເຄື່ອງຈັກໃນການຂາຍຍ່ອຍເຊື່ອມຕໍ່ຜູ້ຊື້ກັບສິ່ງທີ່ພວກເຂົາຕ້ອງການຊື້ອອນໄລນ໌, ແລະຍັງຊ່ວຍໃຫ້ພະນັກງານຮ້ານຄ້າສາມາດປັບແຕ່ງການບໍລິການທີ່ພວກເຂົາສະຫນອງໃຫ້ລູກຄ້າຂອງພວກເຂົາໃນໂລກ brick-and-mortar.
ການຮຽນຮູ້ເຄື່ອງຈັກແມ່ນໃຊ້ໃນການຕໍ່ສູ້ກັບການກໍ່ການຮ້າຍ ແລະ ລັດທິຫົວຮຸນແຮງ ເພື່ອຄາດການພຶດຕິກຳຂອງຜູ້ທີ່ຕ້ອງການທຳຮ້າຍຜູ້ບໍລິສຸດ.
ການປະມວນຜົນພາສາທໍາມະຊາດ (NLP) ຫມາຍເຖິງຂະບວນການອະນຸຍາດໃຫ້ຄອມພິວເຕີເຂົ້າໃຈແລະຕິດຕໍ່ສື່ສານກັບພວກເຮົາໃນພາສາຂອງມະນຸດໂດຍຜ່ານການຮຽນຮູ້ເຄື່ອງຈັກ, ແລະມັນໄດ້ຜົນໃນການພັດທະນາເຕັກໂນໂລຊີການແປພາສາເຊັ່ນດຽວກັນກັບອຸປະກອນການຄວບຄຸມສຽງທີ່ພວກເຮົາເພີ່ມຂຶ້ນທຸກໆມື້, ເຊັ່ນ: Alexa, Google dot, Siri, ແລະຜູ້ຊ່ວຍ Google.
ໂດຍບໍ່ມີຄໍາຖາມ, ການຮຽນຮູ້ເຄື່ອງຈັກແມ່ນສະແດງໃຫ້ເຫັນວ່າມັນເປັນເຕັກໂນໂລຢີທີ່ມີການປ່ຽນແປງ.
ຫຸ່ນຍົນທີ່ມີຄວາມສາມາດເຮັດວຽກຄຽງຄູ່ພວກເຮົາ ແລະ ເສີມສ້າງຕົ້ນກຳເນີດ ແລະ ຈິນຕະນາການຂອງພວກເຮົາດ້ວຍເຫດຜົນທີ່ບໍ່ມີຄວາມຜິດພາດ ແລະ ຄວາມໄວຂອງມະນຸດບໍ່ແມ່ນເລື່ອງຈິນຕະນາການທາງວິທະຍາສາດອີກຕໍ່ໄປ - ພວກມັນກາຍເປັນຄວາມເປັນຈິງໃນຫຼາຍຂະແໜງການ.
ກໍລະນີການນໍາໃຊ້ການຮຽນຮູ້ເຄື່ອງຈັກ
1. ຄວາມປອດໄພທາງໄຊເບີ
ເນື່ອງຈາກເຄືອຂ່າຍມີຄວາມສັບສົນຫຼາຍຂຶ້ນ, ຜູ້ຊ່ຽວຊານດ້ານຄວາມປອດໄພທາງອິນເຕີເນັດໄດ້ເຮັດວຽກຢ່າງບໍ່ອິດເມື່ອຍເພື່ອປັບຕົວເຂົ້າກັບໄພຂົ່ມຂູ່ດ້ານຄວາມປອດໄພທີ່ເພີ່ມຂຶ້ນຢ່າງຕໍ່ເນື່ອງ.
ການຕ້ານກັບ malware ແລະການ hacking tactics ທີ່ພັດທະນາຢ່າງໄວວາແມ່ນມີຄວາມທ້າທາຍພຽງພໍ, ແຕ່ການຂະຫຍາຍຕົວຂອງອຸປະກອນ Internet of Things (IoT) ໄດ້ຫັນປ່ຽນພື້ນຖານຂອງສະພາບແວດລ້ອມຄວາມປອດໄພທາງອິນເຕີເນັດ.
ການໂຈມຕີສາມາດເກີດຂຶ້ນໃນທຸກປັດຈຸບັນແລະໃນສະຖານທີ່ໃດຫນຶ່ງ.
ໂຊກດີທີ່ລະບົບການຮຽນຮູ້ຂອງເຄື່ອງຈັກໄດ້ເປີດໃຊ້ງານຄວາມປອດໄພທາງໄຊເບີເພື່ອໃຫ້ທັນກັບການພັດທະນາໄວເຫຼົ່ານີ້.
ການວິເຄາະຄາດຄະເນ ເປີດໃຊ້ການຊອກຄົ້ນຫາ ແລະຫຼຸດຜ່ອນການໂຈມຕີໄດ້ໄວຂຶ້ນ, ໃນຂະນະທີ່ການຮຽນຮູ້ເຄື່ອງຈັກສາມາດວິເຄາະການເຄື່ອນໄຫວຂອງທ່ານໃນເຄືອຂ່າຍເພື່ອກວດຫາຄວາມຜິດປົກກະຕິ ແລະຈຸດອ່ອນໃນກົນໄກຄວາມປອດໄພທີ່ມີຢູ່.
2. ອັດຕະໂນມັດການບໍລິການລູກຄ້າ
ການຄຸ້ມຄອງການເພີ່ມຂຶ້ນຂອງການຕິດຕໍ່ລູກຄ້າອອນໄລນ໌ໄດ້ເຮັດໃຫ້ອົງການຈັດຕັ້ງຫຼາຍເຄັ່ງຕຶງ.
ພວກເຂົາເຈົ້າພຽງແຕ່ບໍ່ມີພະນັກງານບໍລິການລູກຄ້າພຽງພໍເພື່ອຈັດການກັບປະລິມານການສອບຖາມທີ່ເຂົາເຈົ້າໄດ້ຮັບ, ແລະວິທີການແບບດັ້ງເດີມຂອງບັນຫາ outsourcing ກັບ ສູນຕິດຕໍ່ ແມ່ນພຽງແຕ່ບໍ່ສາມາດຍອມຮັບໄດ້ສໍາລັບລູກຄ້າຈໍານວນຫຼາຍໃນມື້ນີ້.
Chatbots ແລະລະບົບອັດຕະໂນມັດອື່ນໆໃນປັດຈຸບັນສາມາດແກ້ໄຂຄວາມຕ້ອງການເຫຼົ່ານີ້ຍ້ອນຄວາມກ້າວຫນ້າໃນເຕັກນິກການຮຽນຮູ້ເຄື່ອງຈັກ. ບໍລິສັດສາມາດປົດປ່ອຍບຸກຄະລາກອນເພື່ອດໍາເນີນການສະຫນັບສະຫນູນລູກຄ້າໃນລະດັບສູງຫຼາຍຂຶ້ນໂດຍອັດຕະໂນມັດກິດຈະກໍາ mundane ແລະຕ່ໍາ.
ເມື່ອຖືກນໍາໃຊ້ຢ່າງຖືກຕ້ອງ, ການຮຽນຮູ້ເຄື່ອງຈັກໃນທຸລະກິດສາມາດຊ່ວຍປັບປຸງການແກ້ໄຂບັນຫາແລະໃຫ້ຜູ້ບໍລິໂພກມີປະເພດຂອງການສະຫນັບສະຫນູນທີ່ເປັນປະໂຫຍດທີ່ປ່ຽນໃຫ້ເຂົາເຈົ້າກາຍເປັນແຊ້ມແບທີ່ມີຄວາມມຸ່ງຫມັ້ນ.
3. ການສື່ສານ
ການຫຼີກເວັ້ນຄວາມຜິດພາດແລະຄວາມເຂົ້າໃຈຜິດແມ່ນສໍາຄັນໃນການສື່ສານປະເພດໃດກໍ່ຕາມ, ແຕ່ຫຼາຍກວ່ານັ້ນໃນການສື່ສານທາງທຸລະກິດໃນມື້ນີ້.
ຄວາມຜິດພາດທາງໄວຍາກອນທີ່ງ່າຍດາຍ, ສຽງທີ່ບໍ່ຖືກຕ້ອງ, ຫຼືການແປພາສາທີ່ຜິດພາດສາມາດເຮັດໃຫ້ເກີດຄວາມຫຍຸ້ງຍາກຫຼາຍໃນການຕິດຕໍ່ອີເມວ, ການປະເມີນຜົນຂອງລູກຄ້າ, ການປະຊຸມທາງວິດີໂອ, ຫຼືເອກະສານທີ່ອີງໃສ່ຂໍ້ຄວາມໃນຫຼາຍຮູບແບບ.
ລະບົບການຮຽນຮູ້ຂອງເຄື່ອງຈັກມີການສື່ສານທີ່ກ້າວຫນ້າດີເກີນກວ່າມື້ທີ່ຫຍຸ້ງຍາກຂອງ Clippy ຂອງ Microsoft.
ຕົວຢ່າງການຮຽນຮູ້ຂອງເຄື່ອງຈັກເຫຼົ່ານີ້ໄດ້ຊ່ວຍໃຫ້ບຸກຄົນສື່ສານຢ່າງງ່າຍດາຍ ແລະຊັດເຈນໂດຍການໃຊ້ການປະມວນຜົນພາສາທໍາມະຊາດ, ການແປພາສາແບບສົດໆ, ແລະການຮັບຮູ້ສຽງເວົ້າ.
ໃນຂະນະທີ່ຫຼາຍຄົນບໍ່ມັກຄວາມສາມາດໃນການແກ້ໄຂອັດຕະໂນມັດ, ພວກເຂົາຍັງໃຫ້ຄຸນຄ່າໃນການປົກປ້ອງຈາກຄວາມຜິດພາດທີ່ຫນ້າອັບອາຍແລະນໍ້າສຽງທີ່ບໍ່ເຫມາະສົມ.
4. ການຮັບຮູ້ວັດຖຸ
ໃນຂະນະທີ່ເທກໂນໂລຍີການເກັບກໍາແລະຕີຄວາມຫມາຍຂໍ້ມູນໄດ້ປະມານໄລຍະຫນຶ່ງ, ການສອນລະບົບຄອມພິວເຕີໃຫ້ເຂົ້າໃຈສິ່ງທີ່ພວກເຂົາກໍາລັງຊອກຫາຢູ່ໄດ້ພິສູດວ່າເປັນວຽກງານທີ່ຍາກທີ່ຈະຫຼອກລວງ.
ຄວາມສາມາດໃນການຮັບຮູ້ວັດຖຸແມ່ນໄດ້ຖືກເພີ່ມເຂົ້າໃນຈໍານວນອຸປະກອນທີ່ເພີ່ມຂຶ້ນເນື່ອງຈາກຄໍາຮ້ອງສະຫມັກການຮຽນຮູ້ເຄື່ອງຈັກ.
ສໍາລັບຕົວຢ່າງ, ລົດໃຫຍ່ທີ່ຂັບລົດດ້ວຍຕົນເອງຈະຮັບຮູ້ລົດອື່ນເມື່ອມັນເຫັນຫນຶ່ງ, ເຖິງແມ່ນວ່ານັກຂຽນໂປລແກລມບໍ່ໄດ້ໃຫ້ຕົວຢ່າງທີ່ແນ່ນອນຂອງລົດນັ້ນເພື່ອໃຊ້ເປັນເອກະສານອ້າງອີງ.
ດຽວນີ້ເທັກໂນໂລຍີນີ້ຖືກໃຊ້ໃນທຸລະກິດຂາຍຍ່ອຍເພື່ອຊ່ວຍເລັ່ງຂະບວນການຈ່າຍເງິນ. ກ້ອງຖ່າຍຮູບລະບຸຜະລິດຕະພັນຢູ່ໃນລົດເຂັນຂອງຜູ້ບໍລິໂພກ ແລະສາມາດເກັບເງິນບັນຊີຂອງເຂົາເຈົ້າໂດຍອັດຕະໂນມັດເມື່ອພວກເຂົາອອກຈາກຮ້ານ.
5. ການຕະຫຼາດດິຈິຕອ
ການຕະຫຼາດໃນມື້ນີ້ຫຼາຍແມ່ນເຮັດອອນໄລນ໌, ການນໍາໃຊ້ລະດັບຂອງເວທີດິຈິຕອນແລະໂຄງການຊອບແວ.
ໃນຂະນະທີ່ທຸລະກິດເກັບກໍາຂໍ້ມູນກ່ຽວກັບຜູ້ບໍລິໂພກແລະພຶດຕິກໍາການຊື້ຂອງພວກເຂົາ, ທີມງານການຕະຫຼາດສາມາດນໍາໃຊ້ຂໍ້ມູນນັ້ນເພື່ອສ້າງຮູບພາບລາຍລະອຽດຂອງຜູ້ຊົມເປົ້າຫມາຍຂອງພວກເຂົາແລະຄົ້ນພົບວ່າປະຊາຊົນມີແນວໂນ້ມທີ່ຈະຊອກຫາຜະລິດຕະພັນແລະການບໍລິການຂອງພວກເຂົາ.
ສູດການຄິດໄລ່ການຮຽນຮູ້ຂອງເຄື່ອງຈັກຊ່ວຍນັກກາລະຕະຫຼາດໃນການເຂົ້າໃຈຂໍ້ມູນທັງໝົດນັ້ນ, ຄົ້ນພົບຮູບແບບ ແລະຄຸນລັກສະນະທີ່ສຳຄັນທີ່ອະນຸຍາດໃຫ້ຈັດປະເພດຄວາມເປັນໄປໄດ້ຢ່າງແໜ້ນໜາ.
ເຕັກໂນໂລຢີດຽວກັນອະນຸຍາດໃຫ້ອັດຕະໂນມັດການຕະຫຼາດດິຈິຕອນຂະຫນາດໃຫຍ່. ລະບົບການໂຄສະນາສາມາດຖືກສ້າງຕັ້ງຂຶ້ນເພື່ອຄົ້ນພົບຜູ້ບໍລິໂພກໃຫມ່ໃນແບບເຄື່ອນໄຫວແລະສະຫນອງເນື້ອຫາການຕະຫຼາດທີ່ກ່ຽວຂ້ອງໃຫ້ພວກເຂົາໃນເວລາແລະສະຖານທີ່ທີ່ເຫມາະສົມ.
ອະນາຄົດຂອງການຮຽນຮູ້ເຄື່ອງຈັກ
ການຮຽນຮູ້ຂອງເຄື່ອງຈັກແມ່ນແນ່ນອນໄດ້ຮັບຄວາມນິຍົມຍ້ອນວ່າທຸລະກິດຫຼາຍຂຶ້ນແລະອົງການຈັດຕັ້ງຂະຫນາດໃຫຍ່ໃຊ້ເຕັກໂນໂລຢີເພື່ອຮັບມືກັບສິ່ງທ້າທາຍສະເພາະຫຼືການປະດິດສ້າງນໍ້າມັນເຊື້ອໄຟ.
ການລົງທຶນຢ່າງຕໍ່ເນື່ອງນີ້ສະແດງໃຫ້ເຫັນຄວາມເຂົ້າໃຈວ່າການຮຽນຮູ້ເຄື່ອງຈັກກໍາລັງຜະລິດ ROI, ໂດຍສະເພາະໂດຍຜ່ານບາງກໍລະນີການນໍາໃຊ້ທີ່ກ່າວມາຂ້າງເທິງແລະສາມາດແຜ່ພັນໄດ້.
ຫຼັງຈາກທີ່ທັງຫມົດ, ຖ້າເທກໂນໂລຍີດີພໍສໍາລັບ Netflix, Facebook, Amazon, Google Maps, ແລະອື່ນໆ, ໂອກາດທີ່ມັນສາມາດຊ່ວຍບໍລິສັດຂອງເຈົ້າໃຊ້ຂໍ້ມູນໄດ້ຫຼາຍທີ່ສຸດເຊັ່ນກັນ.
ເປັນ ໃໝ່ ການຮຽນຮູ້ເຄື່ອງຈັກ ແບບຈໍາລອງໄດ້ຖືກພັດທະນາແລະເປີດຕົວ, ພວກເຮົາຈະເປັນພະຍານເຖິງການເພີ່ມຂຶ້ນຂອງຈໍານວນຂອງຄໍາຮ້ອງສະຫມັກທີ່ຈະຖືກນໍາໃຊ້ໃນທົ່ວອຸດສາຫະກໍາ.
ອັນນີ້ແມ່ນເກີດຂຶ້ນແລ້ວກັບ ການຮັບຮູ້ໃບຫນ້າ, ເຊິ່ງເຄີຍເປັນຫນ້າທີ່ໃຫມ່ໃນ iPhone ຂອງທ່ານແຕ່ປະຈຸບັນໄດ້ຖືກປະຕິບັດເຂົ້າໄປໃນລະດັບຄວາມກ້ວາງຂອງບັນດາໂຄງການແລະຄໍາຮ້ອງສະຫມັກ, ໂດຍສະເພາະທີ່ກ່ຽວຂ້ອງກັບຄວາມປອດໄພສາທາລະນະ.
ກຸນແຈສໍາລັບອົງການຈັດຕັ້ງສ່ວນໃຫຍ່ທີ່ພະຍາຍາມເລີ່ມຕົ້ນດ້ວຍການຮຽນຮູ້ເຄື່ອງຈັກແມ່ນເພື່ອເບິ່ງຜ່ານວິໄສທັດໃນອະນາຄົດທີ່ສົດໃສແລະຄົ້ນພົບສິ່ງທ້າທາຍທາງທຸລະກິດທີ່ແທ້ຈິງທີ່ເຕັກໂນໂລຢີສາມາດຊ່ວຍທ່ານໄດ້.
ສະຫຼຸບ
ໃນຍຸກຫລັງອຸດສາຫະກໍາ, ນັກວິທະຍາສາດແລະຜູ້ຊ່ຽວຊານໄດ້ພະຍາຍາມສ້າງຄອມພິວເຕີທີ່ມີພຶດຕິກໍາຄືກັບມະນຸດ.
ເຄື່ອງຈັກຄິດແມ່ນການປະກອບສ່ວນສໍາຄັນທີ່ສຸດຂອງ AI ໃຫ້ແກ່ມະນຸດ; ການມາເຖິງອັນມະຫັດສະຈັນຂອງເຄື່ອງຈັກທີ່ຜະລິດດ້ວຍຕົວມັນເອງນີ້ ໄດ້ຫັນປ່ຽນລະບຽບການດຳເນີນງານຂອງບໍລິສັດຢ່າງໄວວາ.
ຍານພາຫະນະຂັບລົດດ້ວຍຕົນເອງ, ຜູ້ຊ່ວຍອັດຕະໂນມັດ, ພະນັກງານການຜະລິດເປັນເອກະລາດ, ແລະຕົວເມືອງ smart ໄດ້ສະແດງໃຫ້ເຫັນຫວ່າງມໍ່ໆມານີ້ຄວາມເປັນໄປໄດ້ຂອງເຄື່ອງມື smart ໄດ້. ການປະຕິວັດການຮຽນຮູ້ເຄື່ອງຈັກ, ແລະອະນາຄົດຂອງການຮຽນຮູ້ເຄື່ອງຈັກ, ຈະຢູ່ກັບພວກເຮົາເປັນເວລາດົນ.





ອອກຈາກ Reply ເປັນ