기계 학습, 인공 지능 또는 컴퓨터 과학 애호가라면 해당 시스템이나 서비스를 개선하는 데 도움이 되는 데이터의 개념과 필요성을 이해하고 있을 것입니다.
거대 기술 기업과 다국적 기업은 데이터를 이해하기 위한 고급 비즈니스 인텔리전스 기술을 채택하여 고객 경험과 전반적인 서비스 품질을 향상시키기 위해 대용량 데이터를 사용합니다. 새롭게 등장하고 가장 중요한 기술 중 하나는 예측 분석이라고 합니다.
이 기사에서는 예측 분석 도구의 개념, 해당 응용 프로그램 및 여러 예에 대해 설명합니다. 오픈 소스 사용할 수 있는 도구!
예측 분석 도구란 무엇입니까?
예측 분석 도구는 기존 데이터 세트에서 정보를 분석하고 추출하여 패턴과 추세를 결정하는 소프트웨어입니다. 이러한 도구는 데이터 마이닝, 예측 모델링 및 머신 러닝을 포함한 다양한 통계 기술을 사용하여 주어진 데이터를 분석하고 예측합니다.
이러한 도구는 특정 서비스의 수익성과 성공을 높이기 위해 특정 기간에 대한 계획을 작성하기 위해 소비자 행동 및 이전 추세의 패턴을 이해하는 데 사용할 수 있습니다.
예측 분석의 응용
다음을 포함하여 다양한 분야에 걸쳐 예측 분석 도구의 많은 응용 프로그램이 있습니다.
전자 상거래
- 고객 데이터를 분석하여 구매 선호도에 따라 사람들을 그룹화한 다음 이러한 그룹이 제품을 구매할 가능성을 예측합니다.
- 타겟 마케팅 캠페인의 투자 수익(ROI) 예측.
- Amazon Marketplace와 같은 최신 유행 온라인 상점에서 데이터 수집.
소셜 미디어 마케팅
- 게시할 콘텐츠의 유형과 종류를 계획합니다.
- 주어진 콘텐츠를 게시하기에 가장 좋은 날짜와 시간을 예측합니다.
- Google Ads 및 광고 전반을 처리합니다.
은행 및 보험
- 신용 등급을 파악합니다.
- 사기 행위 식별.
의료
- 일반적으로 건강을 모니터링합니다.
- 개인의 건강 문제의 초기 징후를 식별합니다.
제조
- 재고 및 공급망 관리.
- 배송 및 이행 프로세스를 지원합니다.
오픈 소스 예측 분석 도구
1. 오렌지 데이터 마이닝
Orange는 시각적 프로그래밍 또는 Python 스크립팅을 통해 예측 분석을 수행하는 데이터 시각화 및 분석 도구입니다. 이 툴킷은 Python 라이브러리로 가져오고 다음을 위한 구성 요소를 포함합니다. 기계 학습, 생물정보학, 텍스트 마이닝 및 기타 데이터 분석 특성.
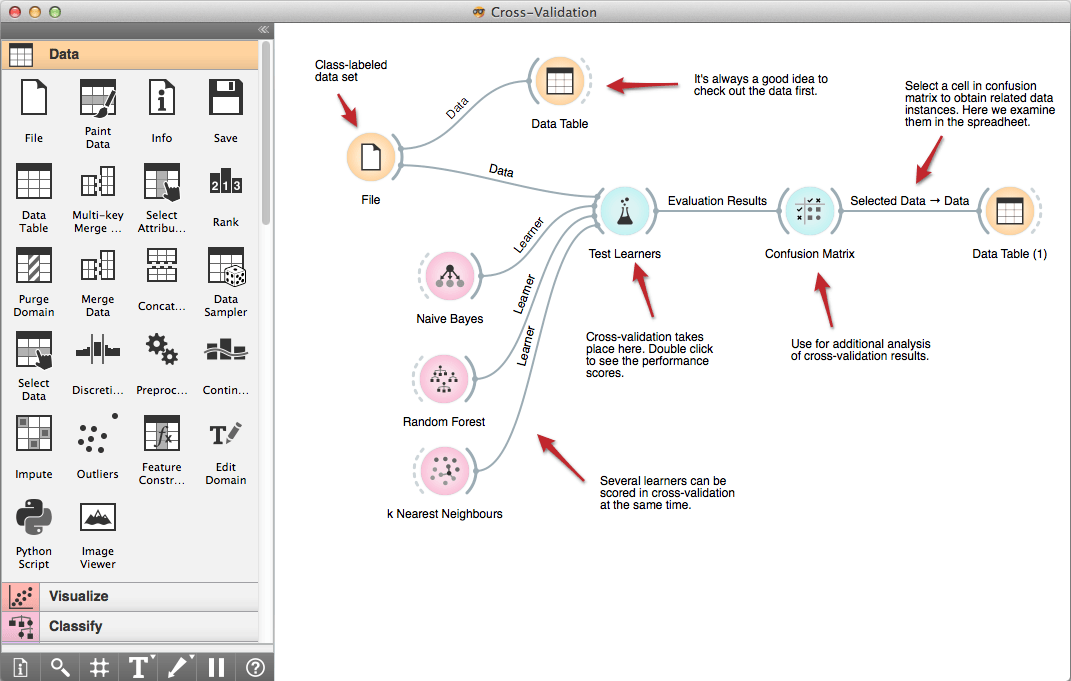
주요 기능
- 대화 형 데이터 시각화 및 그래픽 표현 기능.
- 비주얼 프로그래밍이 포함됩니다.
- 캔버스 기반 그래픽 시간을 아껴주는 인터페이스 (GUI) 초보자도 쉽게 사용할 수 있습니다.
- 간단하고 복잡한 데이터 분석을 실행할 수 있습니다.
2. 아나콘다
오픈 소스 데이터 과학 Python 및 R 배포 플랫폼으로 250개 이상의 인기 있는 패키지를 사용하여 관리 및 배포를 간편하게 패키지화할 수 있습니다. 이 배포는 데이터 과학을 사용합니다. 기계 학습 애플리케이션 및 대규모 데이터 처리를 통해 예측 분석을 수행합니다.
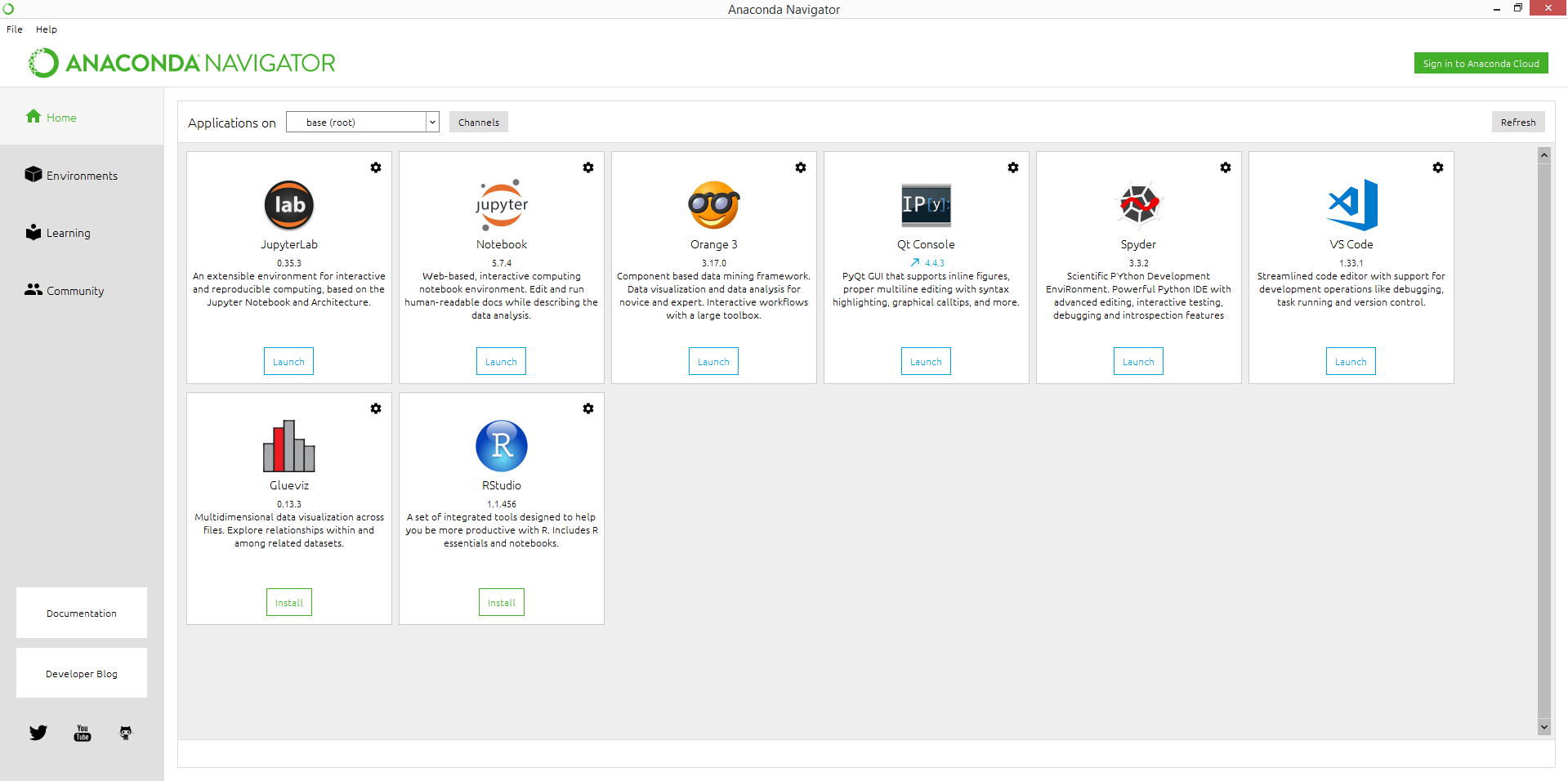
주요 기능
- 고급 분석, 워크플로 사용 및 데이터 상호 작용.
- 모든 데이터 소스를 연결하여 데이터에서 최대한의 가치를 추출합니다.
- Python, R 및 주피터 수첩.
- 예측 분석 모델을 지능형 웹 앱 및 대화형 시각화에 통합합니다.
- Anaconda를 사용하여 전체 데이터 과학 팀에서 협업합니다.
3. R 소프트웨어 환경
R 환경은 통계 컴퓨팅 및 그래픽에 사용됩니다. UNIX, Windows 및 MAC OS를 포함한 다양한 운영 체제에서 컴파일 및 실행됩니다. 이 환경에는 데이터 분석 및 데이터 분석의 그래픽 표시를 위한 다양한 중간 도구 모음이 있습니다.
주요 기능
- 예측 분석을 위한 다양한 통계 모델 및 그래픽 기술을 포함합니다.
- 효과적인 데이터 처리 및 저장 시설.
- 복잡한 데이터 배열 계산 및 통계 분석을 위한 연산자 모음입니다.
- R 커뮤니티에서 온라인으로 지원이 가능합니다.
4. 사이킷런
이것은 Python 프로그래밍 언어를 위한 기계 학습 라이브러리입니다. 여기에는 예측 모델링에 매우 유용한 SVM(Support Vector Machine), 랜덤 포레스트 및 k-means 클러스터링을 비롯한 다양한 분류, 회귀 및 클러스터링 알고리즘이 포함됩니다. 그러나 Scikit-Learn을 사용하여 예측 분석을 수행하려면 고급 프로그래밍 지식이 필요합니다.
주요 기능
- 고급 데이터 처리에는 데이터를 시각적 및 표 형식으로 표시하고 데이터를 기능 매트릭스 또는 대상 벡터로 정렬하는 작업이 포함됩니다.
- 예측 분석에 사용할 수 있는 다양한 분류, 회귀 및 클러스터링 모델.
- 예측 모델 성능을 테스트하기 위한 여러 정확도 메트릭.
5. 웨카 데이터 마이닝
Weka는 Java로 작성된 예측 모델링 작업을 위한 기계 학습 알고리즘 모음입니다. 이러한 알고리즘은 데이터에 직접 적용하거나 Javascript를 사용하여 호출할 수 있습니다. Weka에서 제공하는 데이터 분석 방법에는 데이터 마이닝, 전처리 및 시각화 기술이 포함됩니다. Weka는 또한 예측 분석을 위해 분류, 회귀 및 클러스터링 모델을 사용합니다.
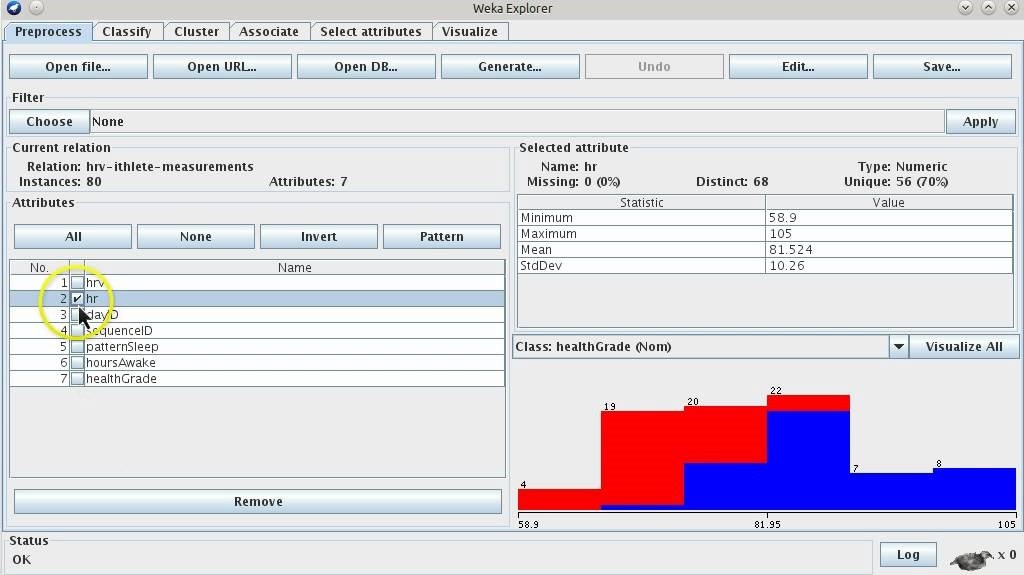
주요 기능
- 데이터 전처리 및 시각화 기술.
- 데이터 분류, 회귀 및 클러스터링 알고리즘.
- 데이터의 추세를 예측하기 위한 광범위한 연관 규칙.
- 휴대용 및 메모리 공간 친화적 소프트웨어.
6. 아파치 마하우트
확장 가능하고 성능이 뛰어난 기계 학습 알고리즘을 구축하기 위한 간단하고 확장 가능한 프로그래밍 환경 및 프레임워크입니다. 이 환경에는 미리 만들어진 여러 Scala, Apache Spark 및 Apache Flint 알고리즘이 포함되어 있습니다. 이 환경은 대규모로 작동하는 R 언어와 유사한 벡터 수학 실험인 Samsara를 사용합니다.
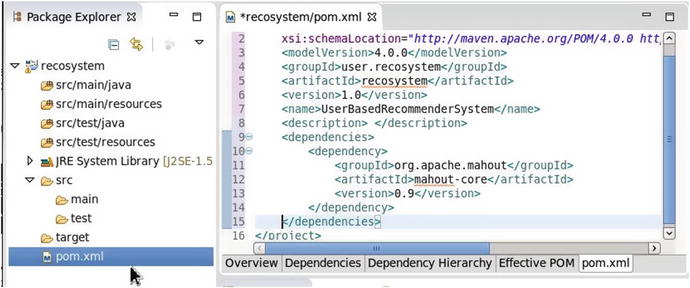
주요 기능
- 추천 시스템을 구축하기 위한 협업 필터링.
- 예측 모델링을 위한 클러스터링 및 분류 알고리즘.
- 고급 데이터 추출을 위해 빈번한 항목 집합 타이밍을 지원합니다.
- 고급 통계 분석을 위한 선형 대수 연산자 및 분산 대수 최적화 프로그램입니다.
- 예측 분석을 위한 확장 가능한 알고리즘을 구축합니다.
7. GNU 옥타브
이 소프트웨어는 수치 계산을 위한 고급 언어를 나타냅니다. 이 소프트웨어에는 고급 데이터 분석을 위한 플로팅 및 시각화 도구가 내장된 강력한 수학 중심 구문이 있습니다. GNU Octave는 MATLAB 스크립트 및 GNU/Linux, MAC OS 및 Windows를 포함한 운영 체제와 호환됩니다.
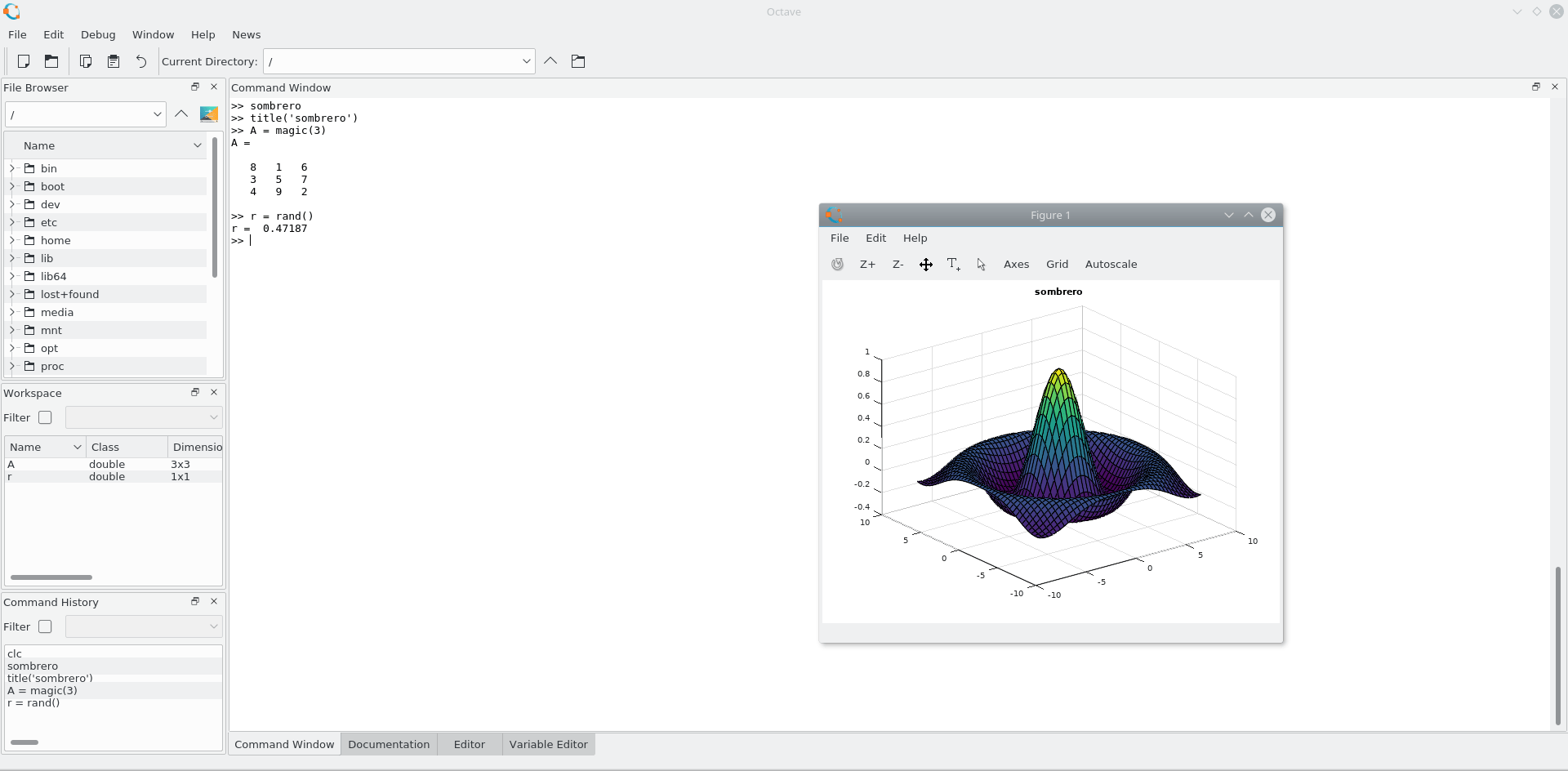
주요 기능
- 내장된 2D/3D 데이터 플로팅 및 시각화 도구.
- 데이터 분석을 위한 여러 GNU 통계 패키지를 지원합니다.
- 수학 지향 예측 모델링을 사용합니다.
- MATLAB 예측 모델 및 기계 학습 알고리즘을 실행할 수 있는 능력.
8. SciPy
기술 및 과학 컴퓨팅에 사용되는 오픈 소스 Python 기반 소프트웨어 모음입니다. SciPy는 Python용 컴퓨팅 도구를 제공하는 핵심 패키지를 제공합니다. k개의 최근접 이웃, 랜덤 포레스트, 신경망.
SciPy는 파이썬 라이브러리 많은 Python 배포판에 있으며 Anaconda의 패키지입니다.
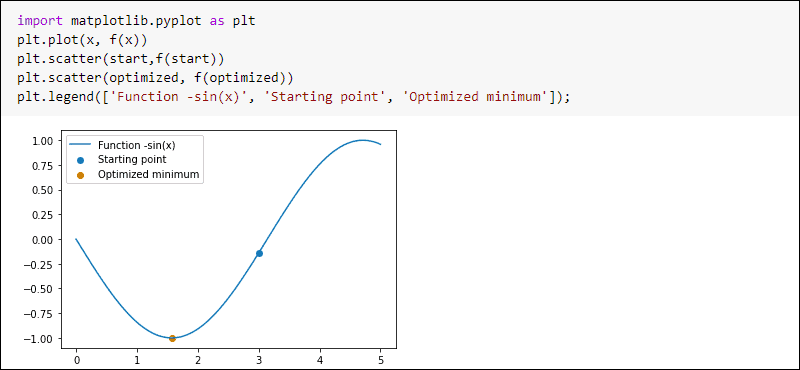
주요 기능
- 최적화, 선형 대수학, 적분, 보간, 특수 함수, FFT 및 ODE 솔버용 모듈.
- 신호, 영상, 데이터 처리를 위한 다양한 기능을 제공합니다.
- NumPy 및 Matplot을 지원합니다.
결론
이제 오픈 소스 예측 분석 도구, 해당 응용 프로그램 및 고급 기술을 사용하여 데이터를 통해 예측하는 방법에 대해 잘 알고 있어야 합니다.
언급된 모든 도구는 완전히 무료이며 모든 사람이 사용할 수 있습니다. 이전에 이러한 도구를 사용한 적이 있다면 의견에 귀하의 경험에 대해 알려주십시오.





댓글을 남겨주세요.