기업은 데이터 기반 의사 결정을 촉진하기 위해 도구와 인재에 투자하고 있습니다. 기계 학습 모델과 데이터 과학 기술은 조직이 수집한 방대한 양의 데이터를 이해할 수 있는 기회를 제공할 수 있습니다.
그러나 많은 소규모 회사는 제한된 리소스와 팀 내 지식 수출 부족으로 인해 이러한 추세에 적응하는 데 어려움을 겪고 있습니다.
다행스럽게도 우리는 지금의 시대에 살고 있습니다. 코드 없는 플랫폼 및 서비스. 고용하지 않고도 데이터 과학자 또는 엔지니어, 비즈니스 분석가 및 도메인 전문가는 이제 데이터에서 추세를 찾기 시작할 수 있습니다.
이 기사에서는 조직이 성장을 주도할 예측 모델을 구축하는 데 도움이 되는 흥미롭고 새로운 AI 노코드 도구인 Clearly AI를 살펴보겠습니다.
분명히 AI가 제공하는 몇 가지 주요 기능을 다루고 이 도구를 사용하여 몇 분 안에 모델을 생성하는 방법을 안내합니다.
분명히 AI 란 무엇입니까?
분명히 AI 사용자가 자신의 데이터를 사용하여 예측 모델을 만들 수 있는 코드 없는 데이터 과학 플랫폼입니다. 이 플랫폼은 직관적인 사용자 친화적인 인터페이스를 사용하여 데이터 소스를 업로드하거나 연결하고 빌드 모델 몇 분 안에
데이터가 분명히 AI의 서버에 업로드되면 데이터 세트를 탐색하여 알고 있는 것과 예측하려는 것을 보다 포괄적으로 볼 수 있습니다.
분명히 AI는 데이터 세트를 사용하여 즉시 사용할 수 있는 기계 학습 모델을 생성합니다. 이러한 모델은 Zapier와 같은 타사 도구 또는 자체 도구를 통해 통합할 수 있습니다. REST API 서비스.
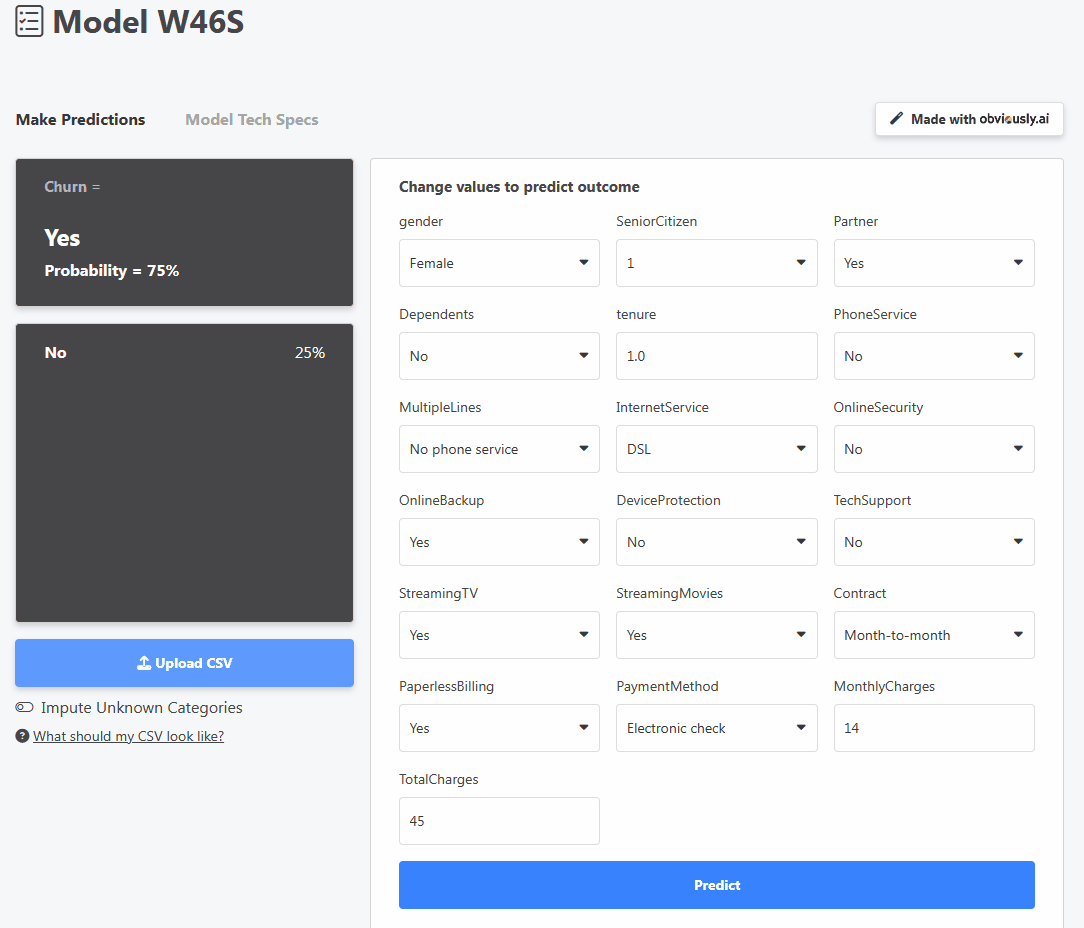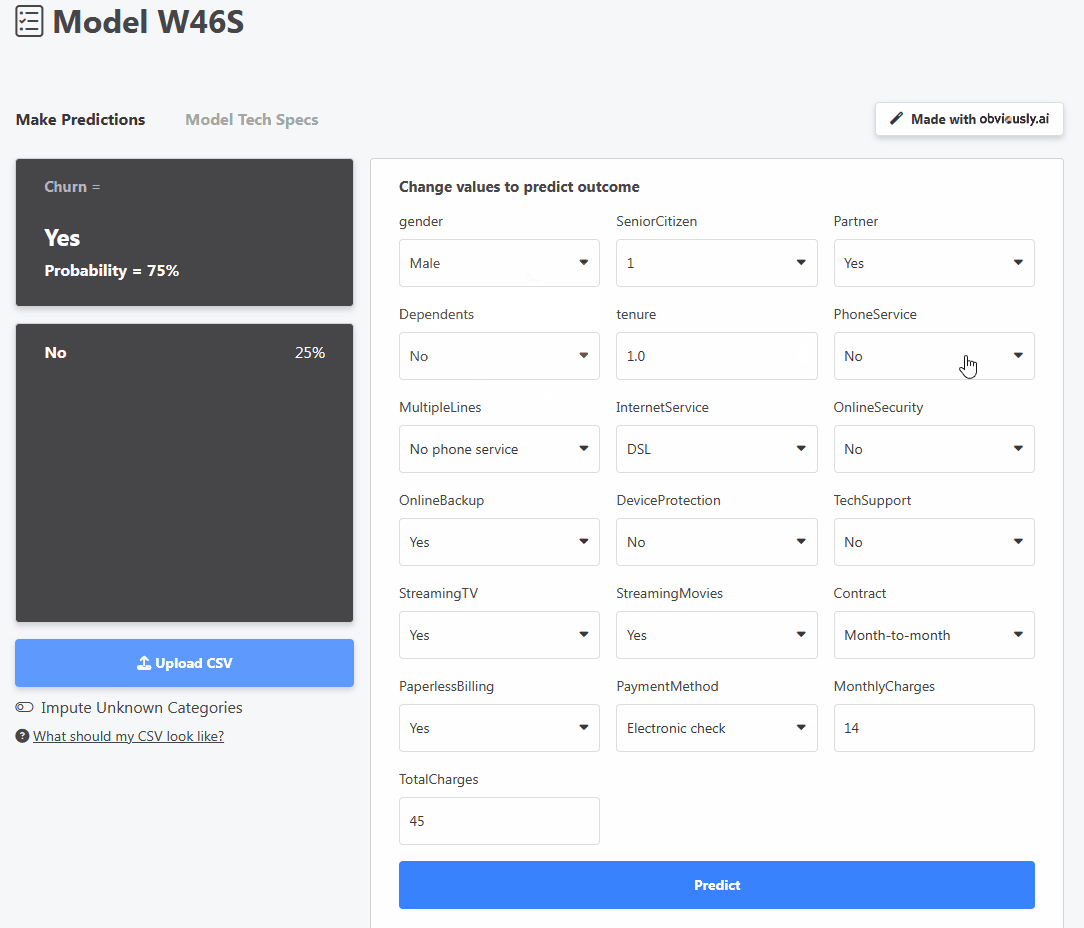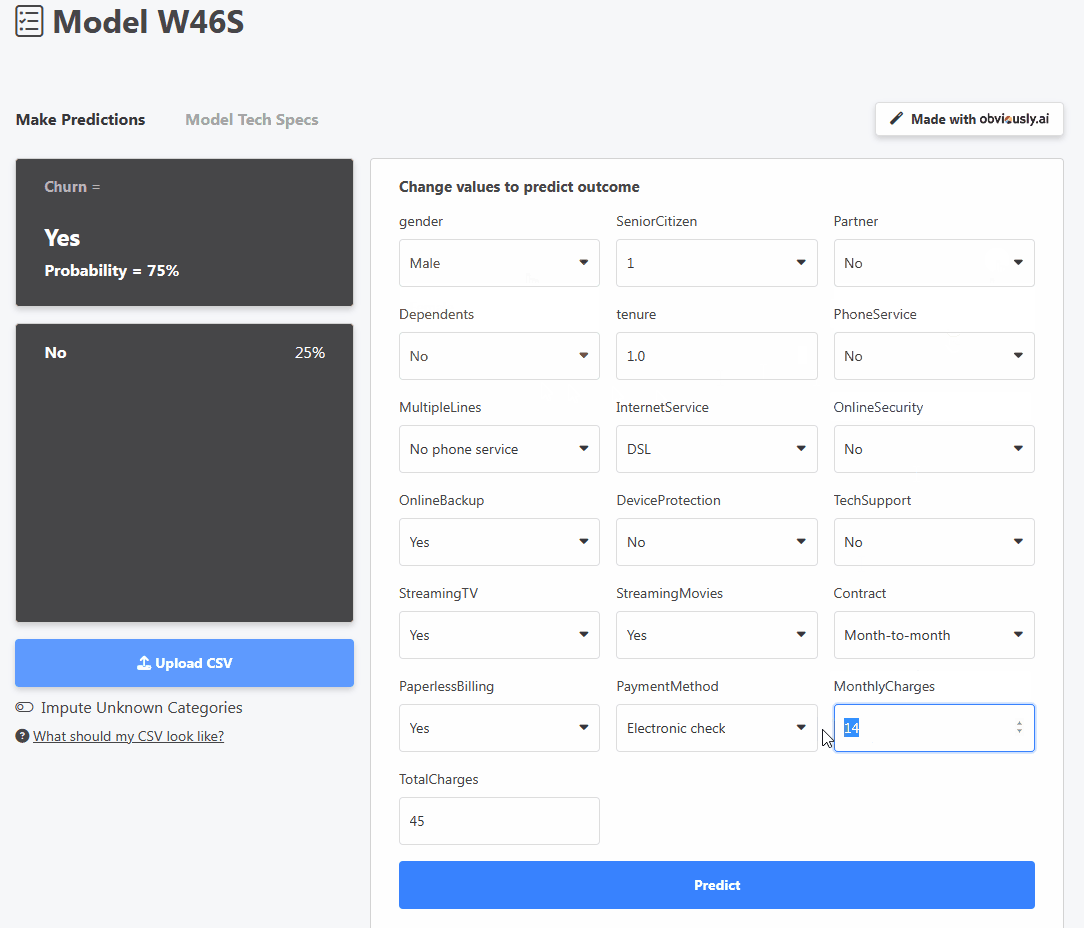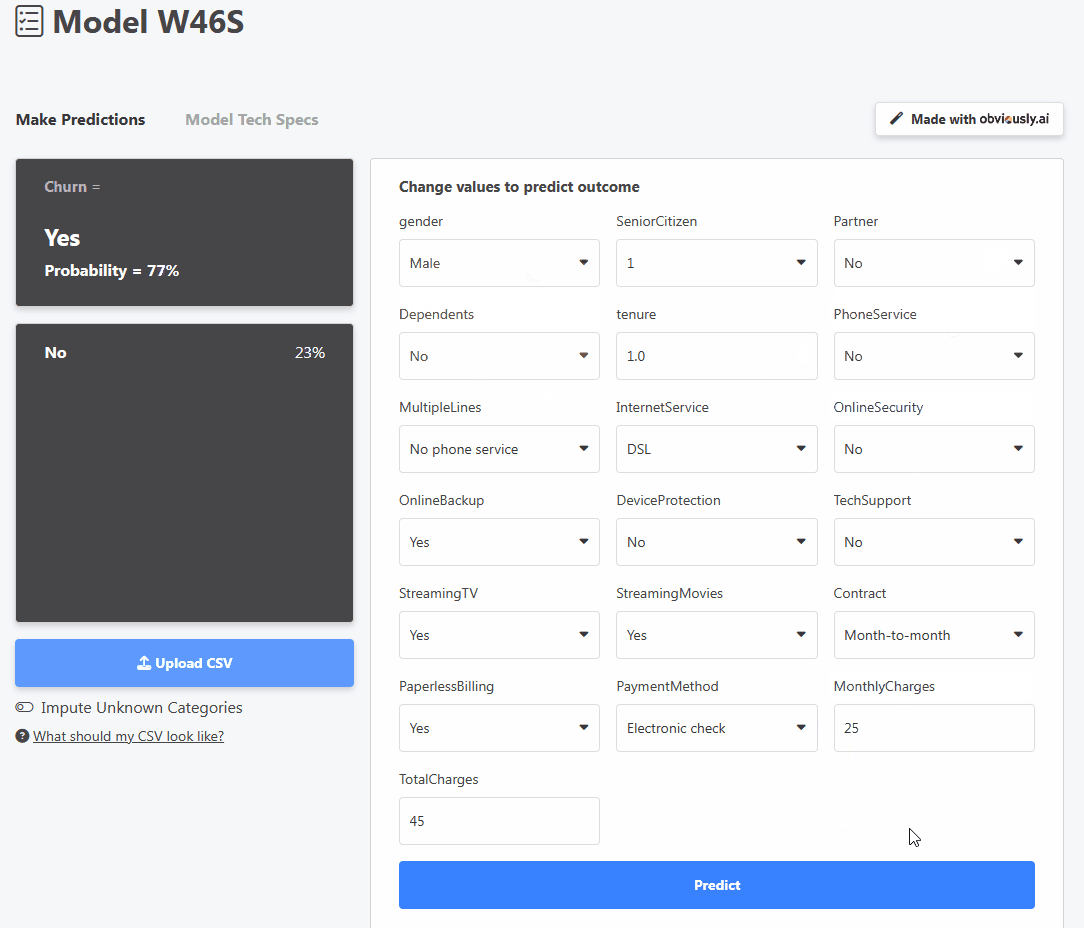
분명히 AI는 모델을 위한 사용자 친화적인 대시보드 인터페이스를 제공하므로 누구나 브라우저에서 바로 모델을 사용할 수 있습니다. 예를 들어 위의 이미지는 고객의 세부 정보를 조정하여 이탈률이나 서비스 구독을 취소할 확률을 예측하는 사용자를 보여줍니다.
이러한 모든 도구는 사용자가 데이터를 가장 잘 사용하는 방법을 이해할 수 있도록 데이터 과학자와 상담하는 기능으로 더욱 강력해집니다.
분명히 AI의 주요 기능
다음은 분명히 AI에서 사용할 수 있는 몇 가지 주요 기능입니다.
데이터세트 탐색기
분명히 AI는 업로드된 데이터 세트를 이해하는 데 도움이 되는 읽기 쉬운 데이터 탐색기와 함께 제공됩니다. 사용자는 데이터 세트의 전체 크기와 각 열의 값 분포를 볼 수 있습니다.
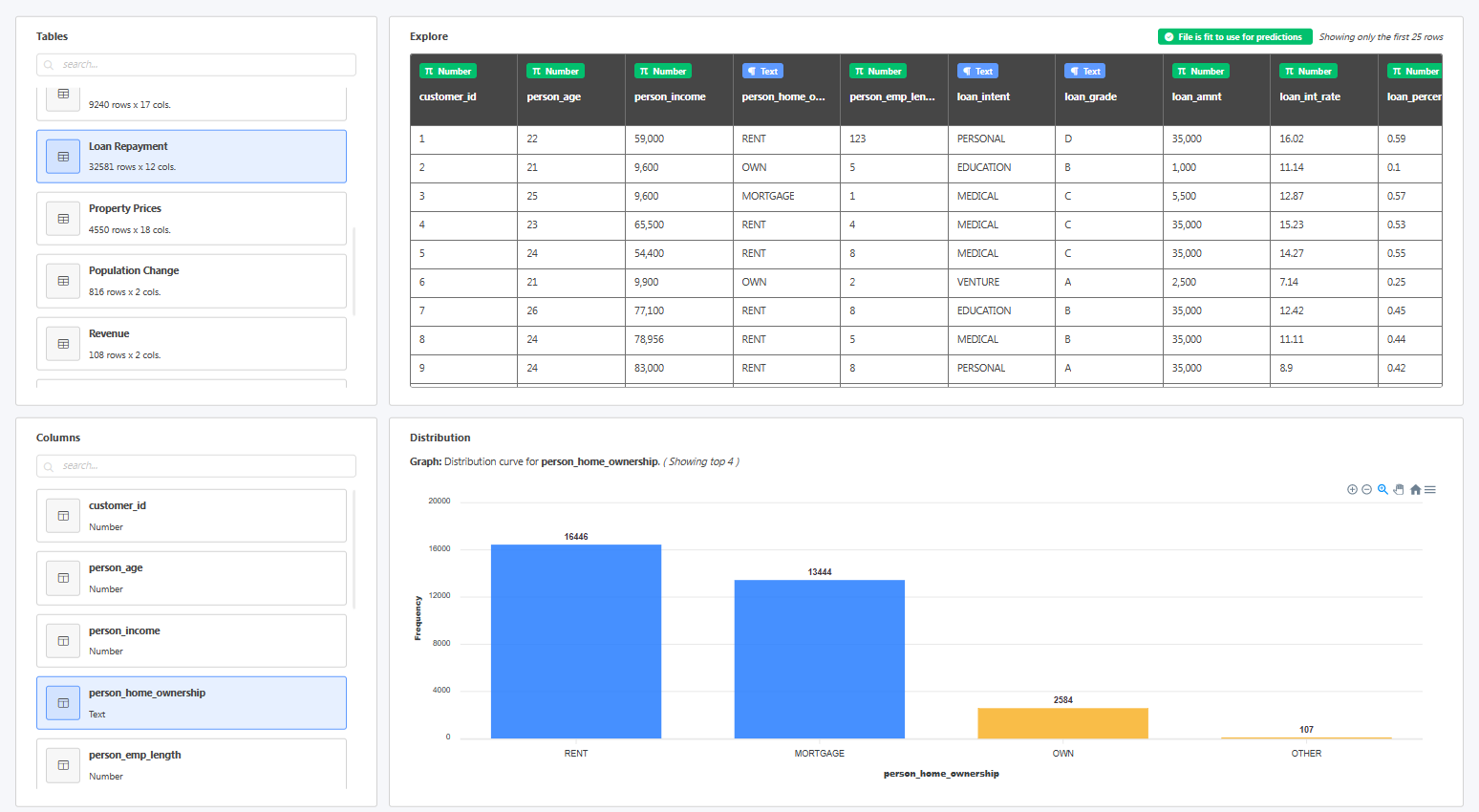
분명히 AI는 데이터 세트를 분석하고 데이터가 누락된 필드와 모델 구축에 사용할 준비가 된 필드를 알려줍니다.
여러 모델 지원
분명히 AI는 클러스터링, 분류, 시계열 분석 및 회귀를 처리하는 모델을 지원합니다.
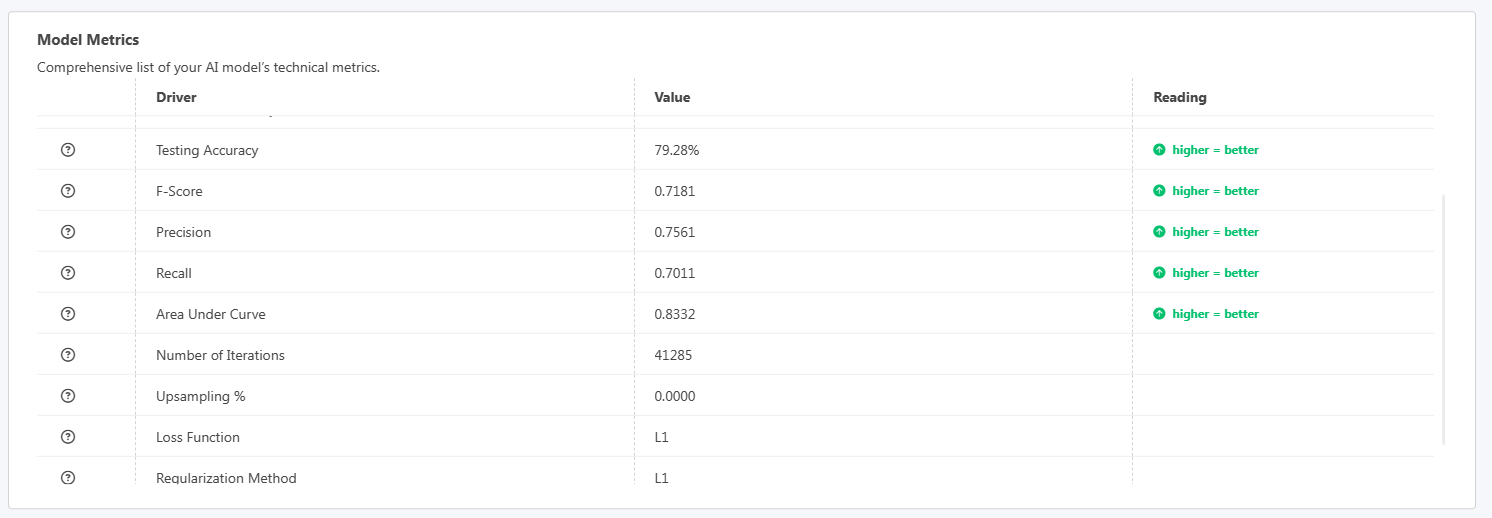
XNUMXD덴탈의 플랫폼은 테스트할 것입니다 여러 다른 모델을 선택하고 전체 결과가 가장 좋은 모델을 반환합니다.
모델 API
분명히 AI가 모델을 구축하면 사용자는 맞춤형 요청을 보낼 수 있습니다. REST API.
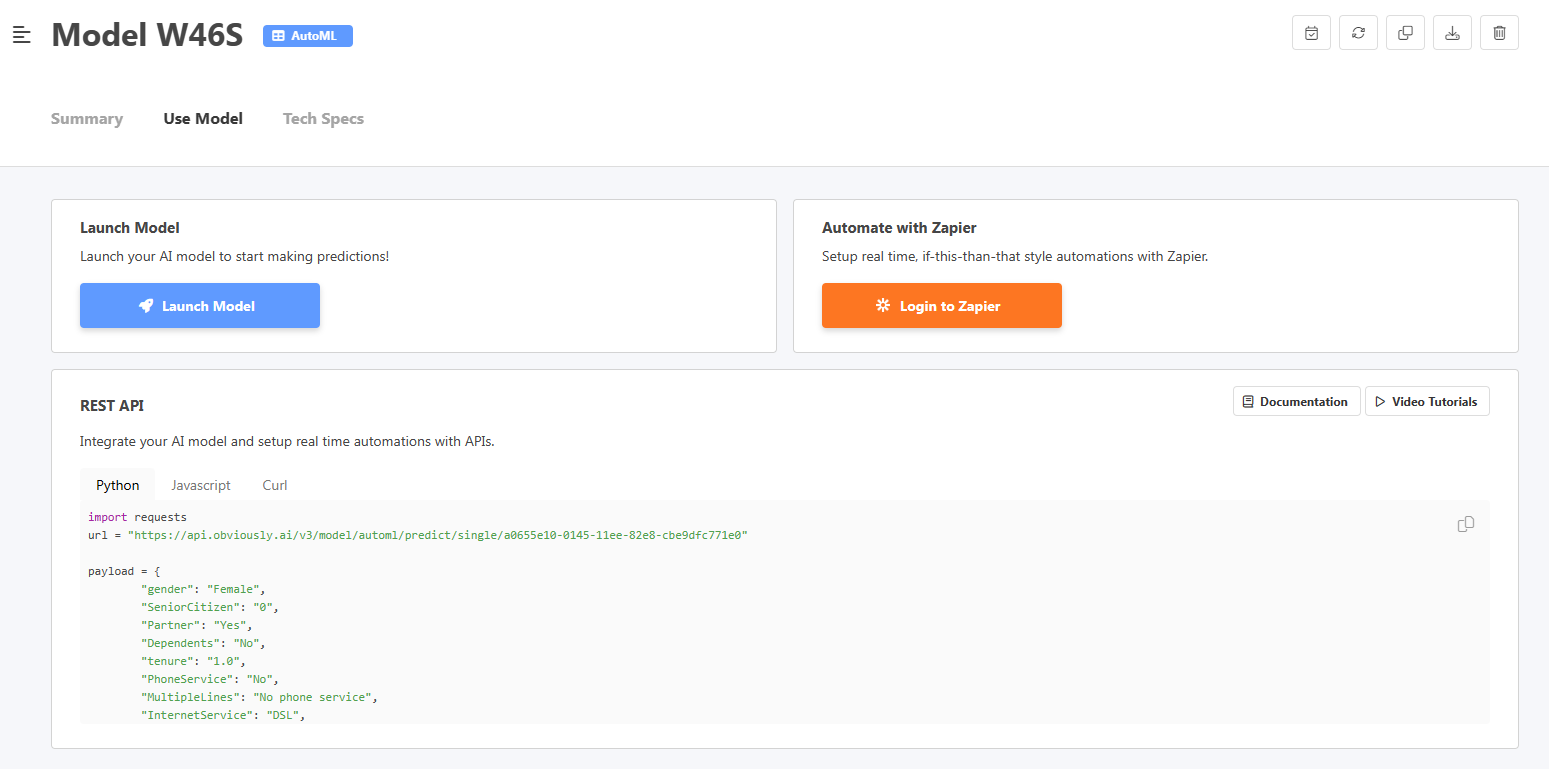
이를 통해 조직은 분명히 AI를 그들이 접하는 모든 유형의 산업 데이터를 분류하거나 예측할 수 있는 백엔드 클라우드 서비스로 사용할 수 있습니다.
이 플랫폼에는 Zapier에 대한 지원도 포함되어 있어 사용자가 분명히 AI의 모델을 워크플로 자동화에 통합할 수 있습니다.
서비스로서의 데이터 과학자
대부분의 조직은 필터링되지 않은 원시 데이터로 시작하므로 전문 데이터 과학자에게 도움을 요청해야 할 수 있습니다.
분명히 AI는 이러한 필요성을 이해하고 추가했습니다. 여러 기능 이를 수용하기 위해 플랫폼에.
Software + Data Scientist 플랜에 가입한 사용자는 데이터 과학자와 협력하여 보다 정확한 모델을 만들 수 있습니다.
데이터 과학자는 원시 데이터 세트를 조사하고 새 열을 만들고 누락된 데이터를 처리하고 사용 사례에 가장 적합한 모델을 식별할 수 있습니다.
분명히 AI에서 모델을 구축하는 방법
이제 Obiously AI 플랫폼이 무엇을 제공해야 하는지 더 잘 이해했으므로 분명히 AI 모델을 구축하는 방법을 살펴보겠습니다.
이 간단한 예에서는 분명히 AI를 사용하여 Titanic Survivors 데이터 세트를 사용하여 분류 모델을 생성합니다.
먼저 Clear AI로 로그인하거나 계정을 만드십시오. 웹사이트 app.obviously.ai에 액세스하여 분명히 AI 대시보드를 봅니다.
왼쪽 패널에서 "+" 버튼을 클릭하여 계정에 새 데이터 세트를 추가합니다.
빌드하려는 모델 유형을 선택하십시오. 이 데모에서는 분류.
다음으로 데이터 세트를 업로드하는 방법을 선택합니다. 지금은 로컬 CSV 파일을 업로드하여 데이터를 업로드하겠습니다.
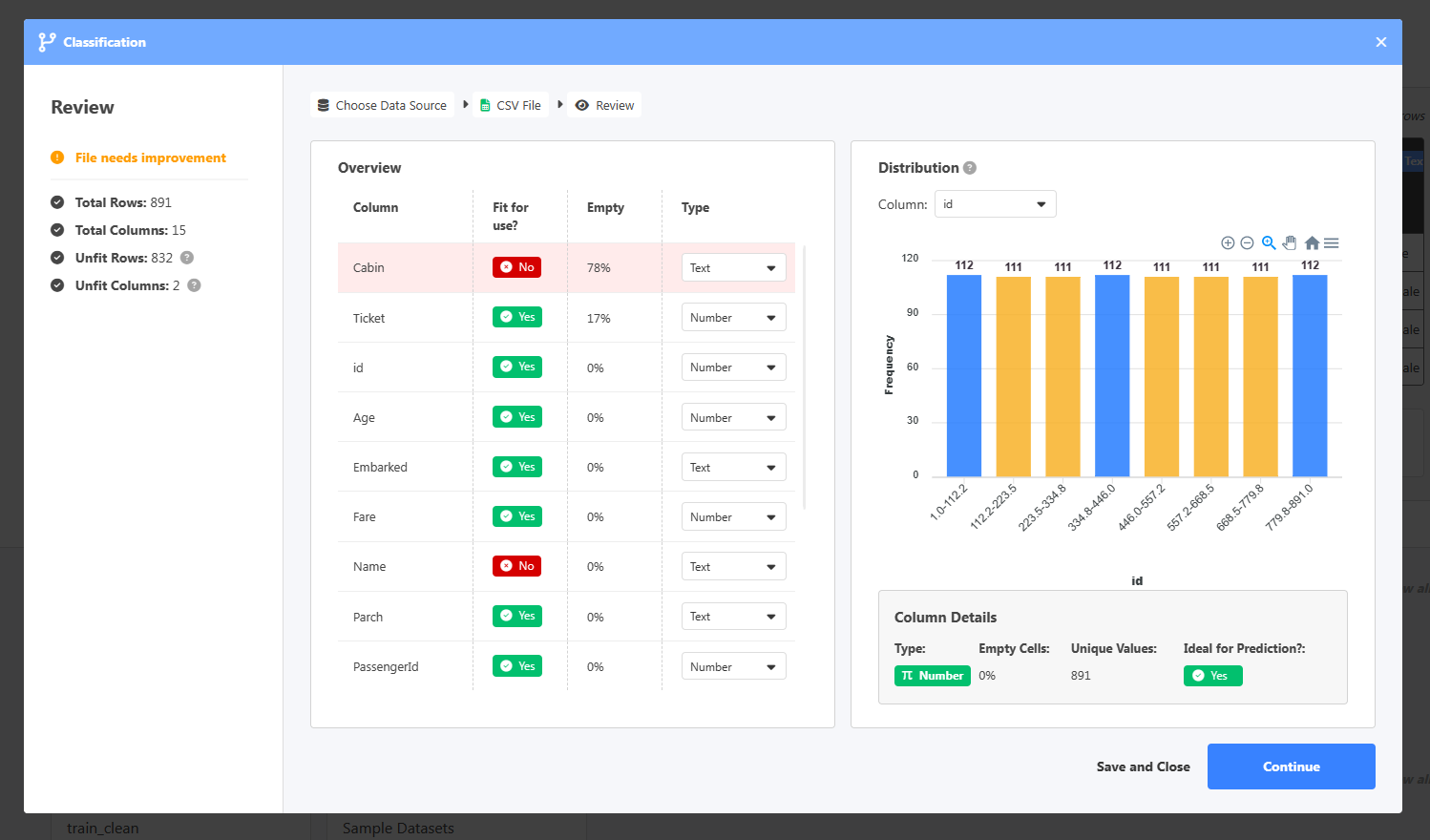
검토 페이지는 데이터에 대한 예비 개요를 제공합니다. 또한 비어 있고 사용할 준비가 된 각 열의 비율을 확인할 수 있습니다.

다음 페이지에서 예측할 열을 결정해야 합니다. 이 경우 다음을 선택합니다. 생존 열입니다.
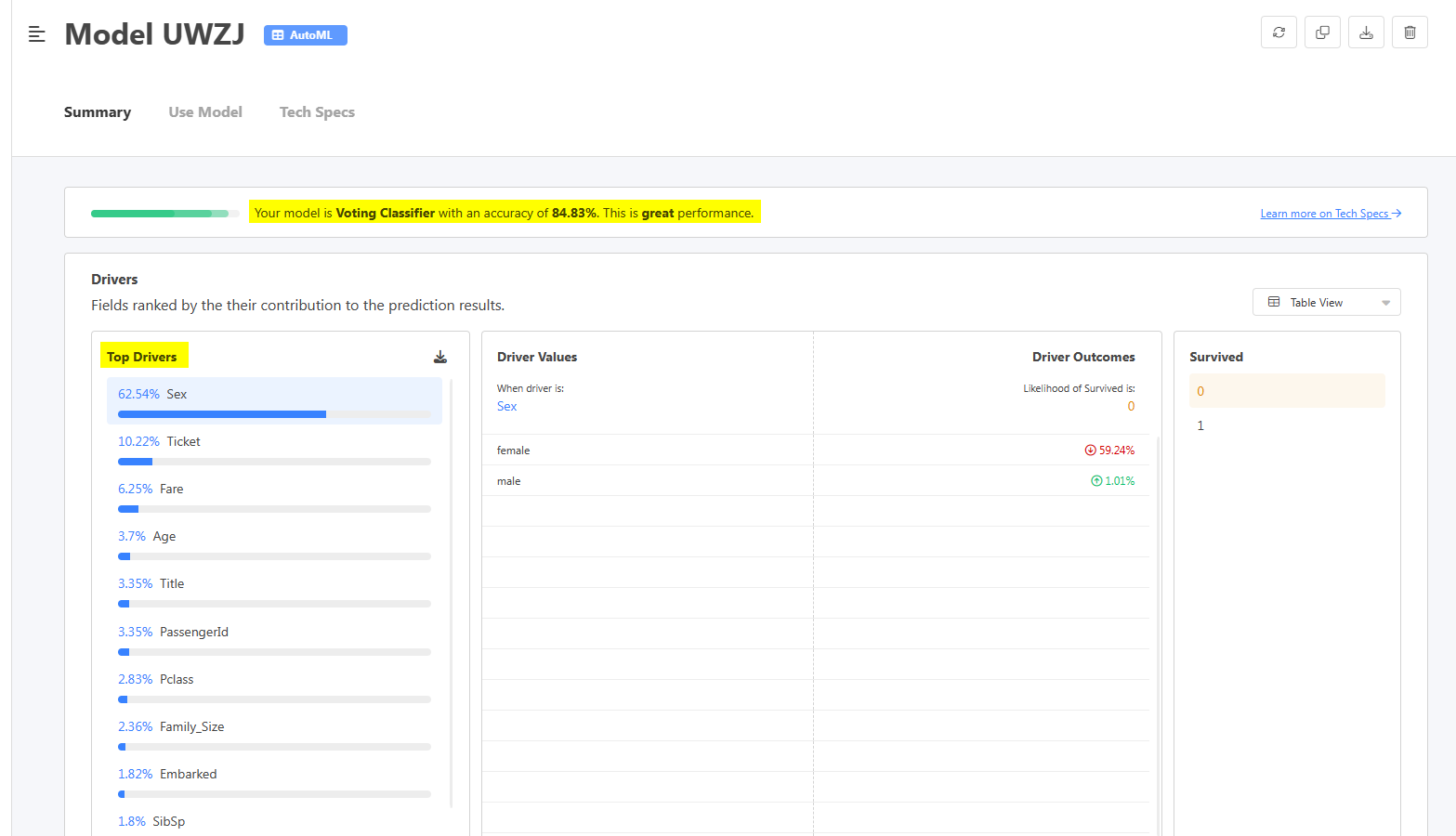
모델이 구축되면 모델 요약이 포함된 새 보기로 리디렉션됩니다.
분명히 AI는 모델의 정확도뿐만 아니라 어떤 유형의 모델이 사용되었는지 알려줄 것입니다. 이 페이지에는 결과를 예측하는 데 가장 중요한 동인인 데이터 세트의 기능도 나열됩니다.
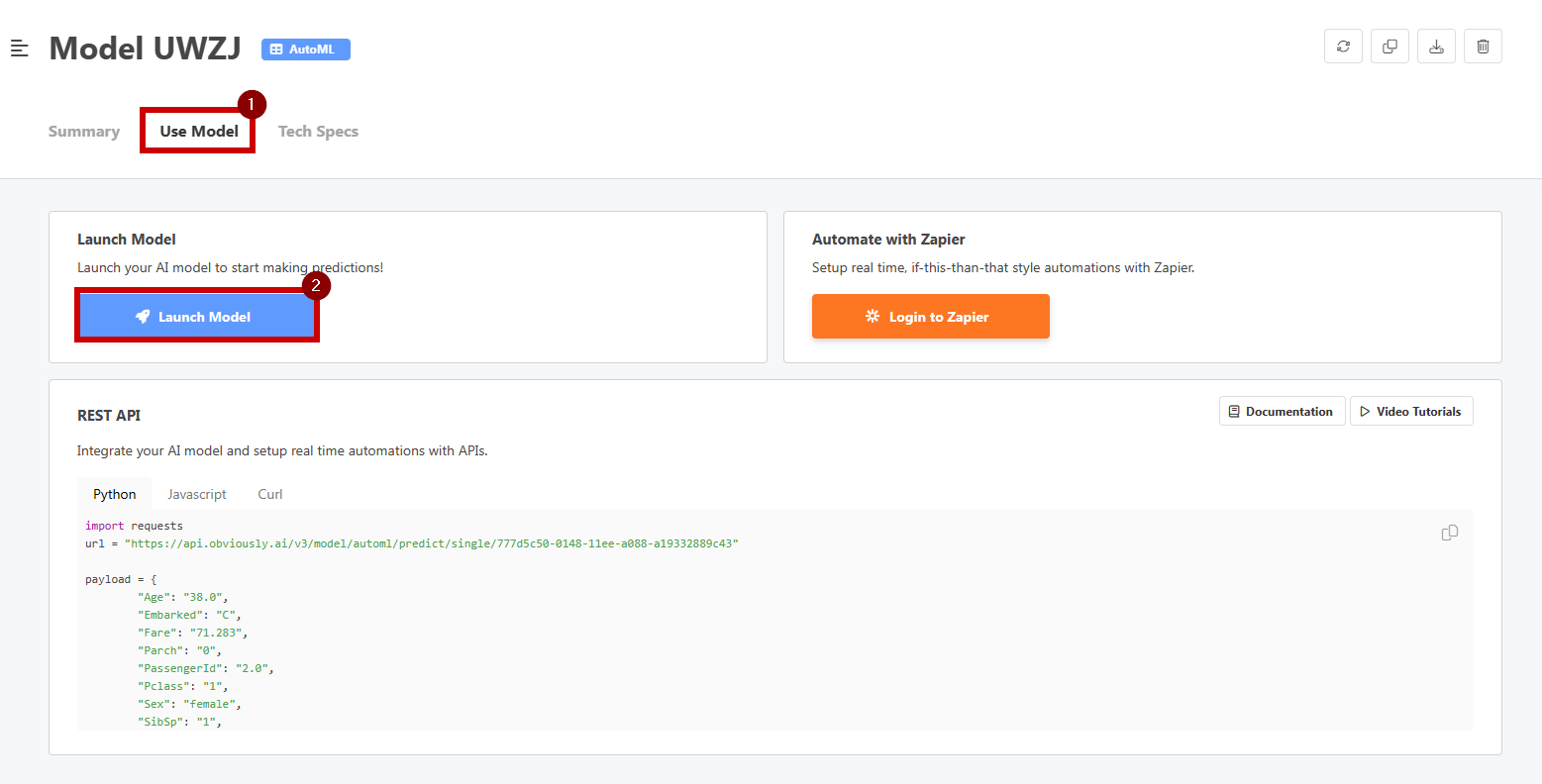
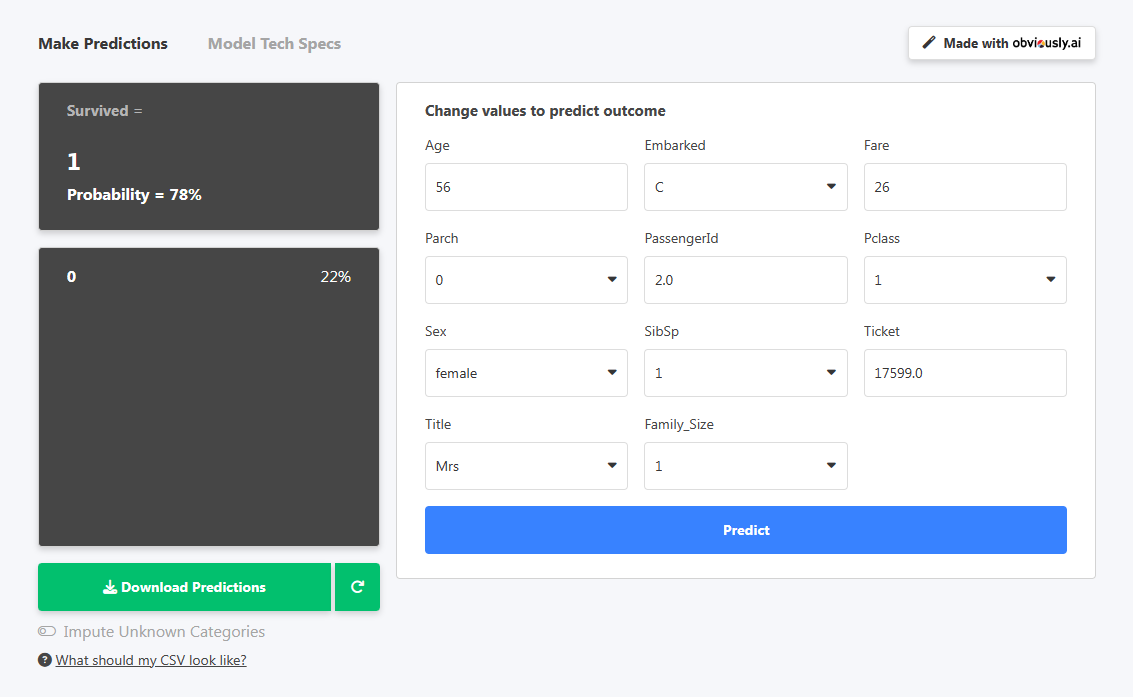
모델 사용 탭을 클릭하고 모델 시작을 선택하여 브라우저에서 직접 모델을 사용해 보십시오.
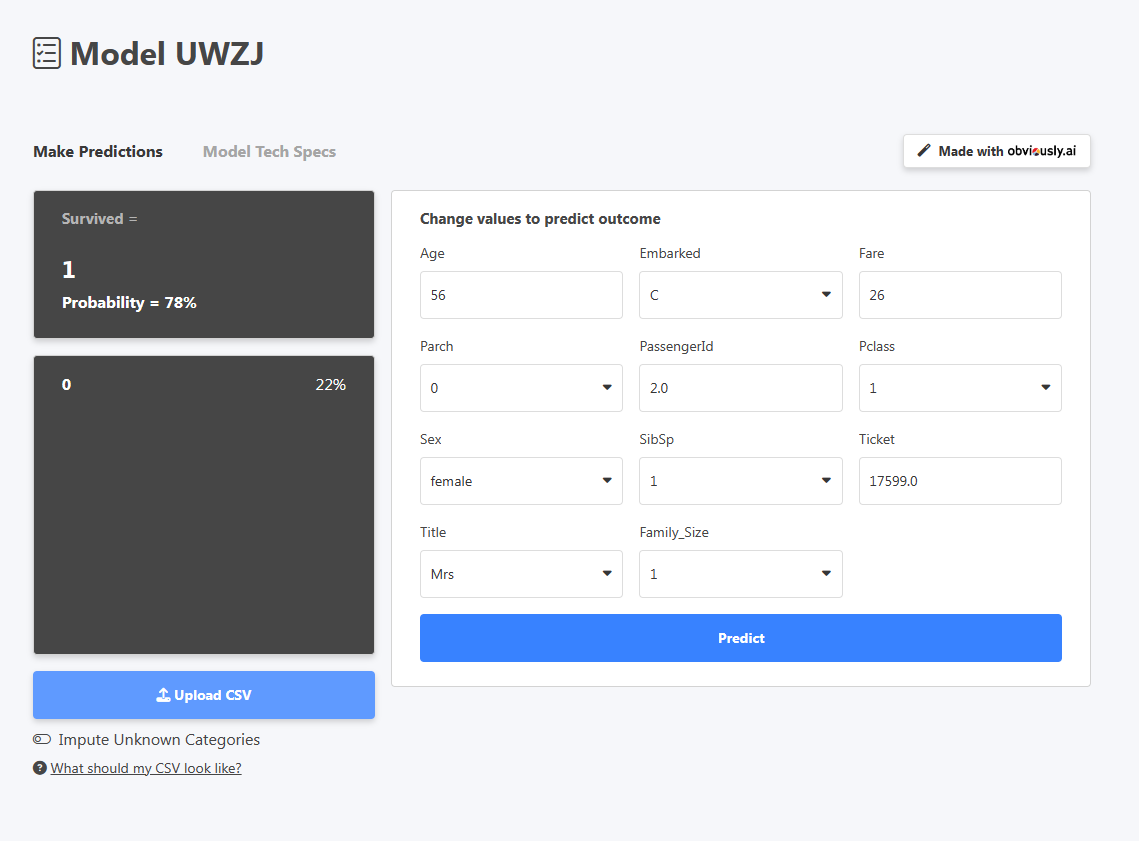
분명히 AI는 예측을 위해 데이터를 입력할 수 있는 대시보드로 리디렉션합니다. 위의 예에서는 새 승객의 데이터를 입력했습니다. 클릭 예측, 새로운 승객이 생존할 확률이 78%임을 확인했습니다(Survived=1).
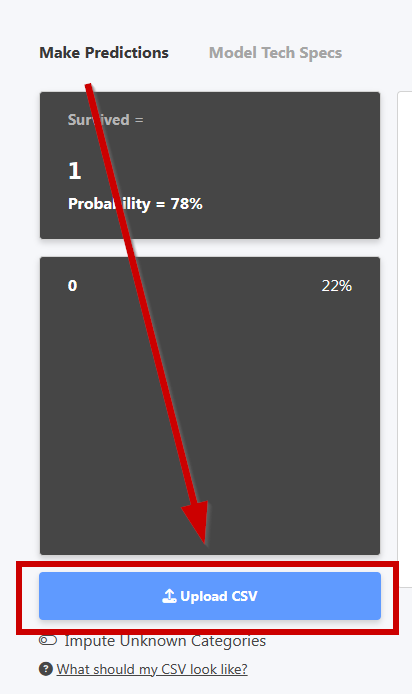
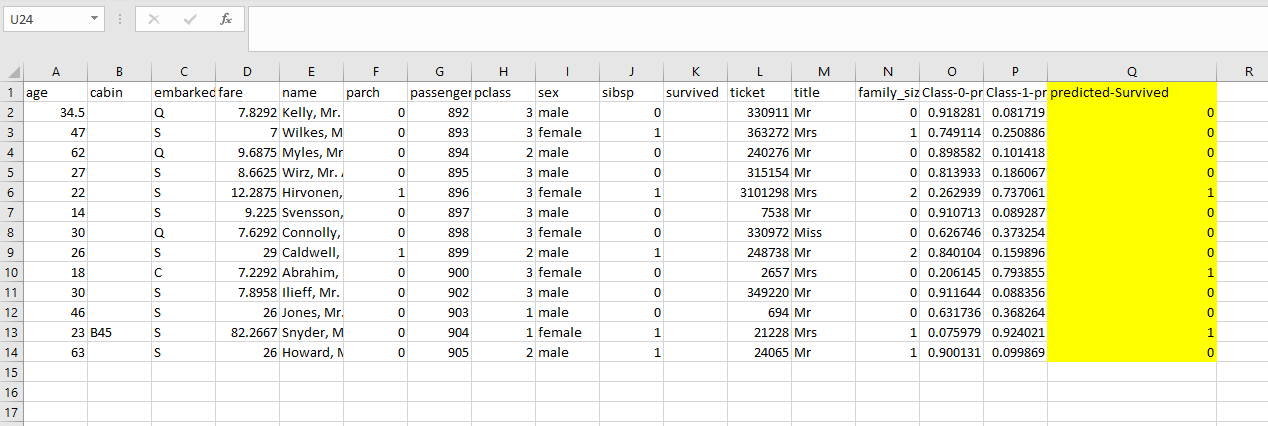
테스트 데이터의 CSV를 업로드하여 일괄 예측을 할 수도 있습니다.
를 클릭하십시오 예측 다운로드 업로드된 데이터에 대해 모델이 만든 예측의 CSV를 다운로드합니다.
가격 정책
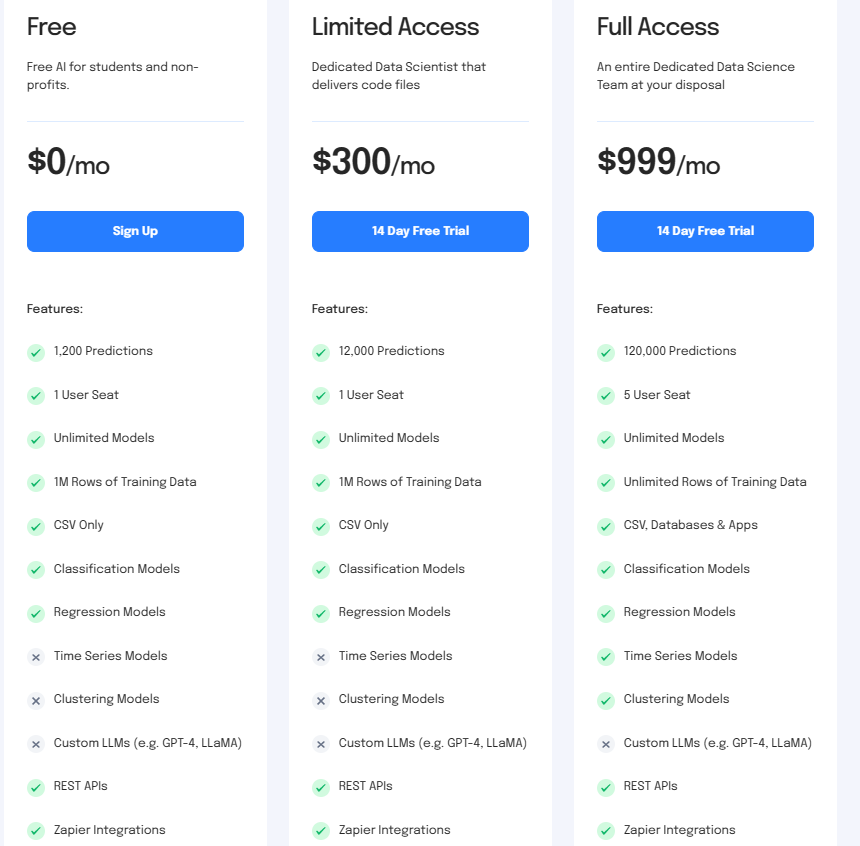
분명히 AI는 무료 계획 1200개 예측으로 제한되며 분류 및 회귀 모델에 액세스할 수 있습니다.
제한된 액세스 계획은 예측의 양을 12,000개로 늘리고 사용자에게 프로젝트를 도와줄 전담 데이터 과학자에 대한 액세스를 제공합니다.
전체 액세스 계획은 한도를 120,000개의 예측 및 무제한 교육 데이터 행으로 늘립니다. 또한 사용자는 데이터 준비 및 기타 요청을 처리하기 위해 시계열 및 클러스터링 모델과 전담 데이터 과학 팀에 액세스할 수 있습니다.
결론
분명히 AI를 사용하여 첫 번째 모델을 만든 후 원시 데이터 세트를 작업 중인 클라우드 기반 데이터 과학 애플리케이션으로 변환하는 것이 얼마나 간단하고 빠른지 감명받았습니다. 처음부터 모델을 설정하는 데 몇 분밖에 걸리지 않습니다.
가격 계획은 애호가나 비영리 조직에게는 다소 가파를 수 있지만, 아직 팀에 전담 데이터 과학자나 데이터 엔지니어가 없는 소규모 회사에는 이 계획이 충분히 합리적입니다.
분명히 AI에 대해 어떻게 생각하세요?





댓글을 남겨주세요.