ಪ್ರಪಂಚದಾದ್ಯಂತದ ಶತಕೋಟಿ ಆಟಗಾರರಿಗೆ ವೀಡಿಯೊ ಗೇಮ್ಗಳು ಸವಾಲನ್ನು ನೀಡುತ್ತಲೇ ಇರುತ್ತವೆ. ನಿಮಗೆ ಇದು ಇನ್ನೂ ತಿಳಿದಿಲ್ಲದಿರಬಹುದು, ಆದರೆ ಮಷಿನ್ ಲರ್ನಿಂಗ್ ಅಲ್ಗಾರಿದಮ್ಗಳು ಸಹ ಸವಾಲಿಗೆ ಏರಲು ಪ್ರಾರಂಭಿಸಿವೆ.
ವೀಡಿಯೊ ಆಟಗಳಿಗೆ ಯಂತ್ರ ಕಲಿಕೆಯ ವಿಧಾನಗಳನ್ನು ಅನ್ವಯಿಸಬಹುದೇ ಎಂದು ನೋಡಲು ಪ್ರಸ್ತುತ AI ಕ್ಷೇತ್ರದಲ್ಲಿ ಗಮನಾರ್ಹ ಪ್ರಮಾಣದ ಸಂಶೋಧನೆ ಇದೆ. ಈ ಕ್ಷೇತ್ರದಲ್ಲಿ ಗಣನೀಯ ಪ್ರಗತಿಯು ಅದನ್ನು ತೋರಿಸುತ್ತದೆ ಯಂತ್ರ ಕಲಿಕೆ ಮಾನವ ಆಟಗಾರನನ್ನು ಅನುಕರಿಸಲು ಅಥವಾ ಬದಲಿಸಲು ಏಜೆಂಟ್ಗಳನ್ನು ಬಳಸಬಹುದು.
ಭವಿಷ್ಯಕ್ಕಾಗಿ ಇದರ ಅರ್ಥವೇನು ವಿಡಿಯೋ ಆಟಗಳು?
ಈ ಯೋಜನೆಗಳು ಕೇವಲ ವಿನೋದಕ್ಕಾಗಿಯೇ ಅಥವಾ ಅನೇಕ ಸಂಶೋಧಕರು ಆಟಗಳ ಮೇಲೆ ಕೇಂದ್ರೀಕರಿಸಲು ಆಳವಾದ ಕಾರಣಗಳಿವೆಯೇ?
ಈ ಲೇಖನವು ವೀಡಿಯೊ ಆಟಗಳಲ್ಲಿ AI ಇತಿಹಾಸವನ್ನು ಸಂಕ್ಷಿಪ್ತವಾಗಿ ಅನ್ವೇಷಿಸುತ್ತದೆ. ನಂತರ, ಆಟಗಳನ್ನು ಸೋಲಿಸುವುದು ಹೇಗೆಂದು ತಿಳಿಯಲು ನಾವು ಬಳಸಬಹುದಾದ ಕೆಲವು ಯಂತ್ರ ಕಲಿಕೆಯ ತಂತ್ರಗಳ ತ್ವರಿತ ಅವಲೋಕನವನ್ನು ನಾವು ನಿಮಗೆ ನೀಡುತ್ತೇವೆ. ನಂತರ ನಾವು ಕೆಲವು ಯಶಸ್ವಿ ಅಪ್ಲಿಕೇಶನ್ಗಳನ್ನು ನೋಡುತ್ತೇವೆ ನರ ಜಾಲಗಳು ನಿರ್ದಿಷ್ಟ ವೀಡಿಯೊ ಆಟಗಳನ್ನು ಕಲಿಯಲು ಮತ್ತು ಕರಗತ ಮಾಡಿಕೊಳ್ಳಲು.
ಗೇಮಿಂಗ್ನಲ್ಲಿ AI ನ ಸಂಕ್ಷಿಪ್ತ ಇತಿಹಾಸ
ವೀಡಿಯೊ ಗೇಮ್ಗಳನ್ನು ಪರಿಹರಿಸಲು ನ್ಯೂರಲ್ ನೆಟ್ಗಳು ಏಕೆ ಆದರ್ಶ ಅಲ್ಗಾರಿದಮ್ ಆಗಿವೆ ಎಂಬುದನ್ನು ನಾವು ತಿಳಿದುಕೊಳ್ಳುವ ಮೊದಲು, ಕಂಪ್ಯೂಟರ್ ವಿಜ್ಞಾನಿಗಳು AI ನಲ್ಲಿ ತಮ್ಮ ಸಂಶೋಧನೆಯನ್ನು ಮುನ್ನಡೆಸಲು ವೀಡಿಯೊ ಗೇಮ್ಗಳನ್ನು ಹೇಗೆ ಬಳಸಿದ್ದಾರೆ ಎಂಬುದನ್ನು ಸಂಕ್ಷಿಪ್ತವಾಗಿ ನೋಡೋಣ.
ಅದರ ಪ್ರಾರಂಭದಿಂದಲೂ, AI ನಲ್ಲಿ ಆಸಕ್ತಿ ಹೊಂದಿರುವ ಸಂಶೋಧಕರಿಗೆ ವೀಡಿಯೊ ಗೇಮ್ಗಳು ಸಂಶೋಧನೆಯ ಬಿಸಿ ಪ್ರದೇಶವಾಗಿದೆ ಎಂದು ನೀವು ವಾದಿಸಬಹುದು.
ಮೂಲದಲ್ಲಿ ಕಟ್ಟುನಿಟ್ಟಾಗಿ ವೀಡಿಯೊ ಗೇಮ್ ಅಲ್ಲದಿದ್ದರೂ, AI ಯ ಆರಂಭಿಕ ದಿನಗಳಲ್ಲಿ ಚೆಸ್ ಹೆಚ್ಚಿನ ಗಮನವನ್ನು ಹೊಂದಿದೆ. 1951 ರಲ್ಲಿ, ಡಾ. ಡೈಟ್ರಿಚ್ ಪ್ರಿಂಜ್ ಅವರು ಫೆರಾಂಟಿ ಮಾರ್ಕ್ 1 ಡಿಜಿಟಲ್ ಕಂಪ್ಯೂಟರ್ ಅನ್ನು ಬಳಸಿಕೊಂಡು ಚೆಸ್-ಪ್ಲೇಯಿಂಗ್ ಪ್ರೋಗ್ರಾಂ ಅನ್ನು ಬರೆದರು. ಈ ಬೃಹತ್ ಕಂಪ್ಯೂಟರ್ಗಳು ಪೇಪರ್ ಟೇಪ್ನಿಂದ ಕಾರ್ಯಕ್ರಮಗಳನ್ನು ಓದಬೇಕಾದ ಯುಗದಲ್ಲಿ ಇದು ಹಿಂದಿನದು.

ಕಾರ್ಯಕ್ರಮವು ಸಂಪೂರ್ಣ ಚೆಸ್ AI ಆಗಿರಲಿಲ್ಲ. ಕಂಪ್ಯೂಟರ್ನ ಮಿತಿಗಳ ಕಾರಣದಿಂದ, ಪ್ರಿನ್ಜ್ ಮೇಟ್-ಇನ್-ಟೂ ಚೆಸ್ ಸಮಸ್ಯೆಗಳನ್ನು ಪರಿಹರಿಸುವ ಪ್ರೋಗ್ರಾಂ ಅನ್ನು ಮಾತ್ರ ರಚಿಸಬಹುದು. ಸರಾಸರಿ, ಪ್ರೋಗ್ರಾಂ ಬಿಳಿ ಮತ್ತು ಕಪ್ಪು ಆಟಗಾರರಿಗೆ ಪ್ರತಿ ಸಂಭವನೀಯ ನಡೆಯನ್ನು ಲೆಕ್ಕಾಚಾರ ಮಾಡಲು 15-20 ನಿಮಿಷಗಳನ್ನು ತೆಗೆದುಕೊಂಡಿತು.
ಚೆಸ್ ಮತ್ತು ಚೆಕರ್ಸ್ AI ಅನ್ನು ಸುಧಾರಿಸುವ ಕೆಲಸವು ದಶಕಗಳಲ್ಲಿ ಸ್ಥಿರವಾಗಿ ಸುಧಾರಿಸಿದೆ. 1997 ರಲ್ಲಿ IBM ನ ಡೀಪ್ ಬ್ಲೂ ರಷ್ಯಾದ ಚೆಸ್ ಗ್ರ್ಯಾಂಡ್ ಮಾಸ್ಟರ್ ಗ್ಯಾರಿ ಕಾಸ್ಪರೋವ್ ಅವರನ್ನು ಆರು-ಗೇಮ್ ಪಂದ್ಯಗಳಲ್ಲಿ ಸೋಲಿಸಿದಾಗ ಪ್ರಗತಿಯು ಅದರ ಪರಾಕಾಷ್ಠೆಯನ್ನು ತಲುಪಿತು. ಇತ್ತೀಚಿನ ದಿನಗಳಲ್ಲಿ, ನಿಮ್ಮ ಮೊಬೈಲ್ ಫೋನ್ನಲ್ಲಿ ನೀವು ಕಾಣುವ ಚೆಸ್ ಎಂಜಿನ್ಗಳು ಡೀಪ್ ಬ್ಲೂ ಅನ್ನು ಸೋಲಿಸಬಹುದು.
ವಿಡಿಯೋ ಆರ್ಕೇಡ್ ಆಟಗಳ ಸುವರ್ಣ ಯುಗದಲ್ಲಿ AI ವಿರೋಧಿಗಳು ಜನಪ್ರಿಯತೆಯನ್ನು ಗಳಿಸಲು ಪ್ರಾರಂಭಿಸಿದರು. 1978 ರ ಸ್ಪೇಸ್ ಇನ್ವೇಡರ್ಸ್ ಮತ್ತು 1980 ರ ಪ್ಯಾಕ್-ಮ್ಯಾನ್ AI ಅನ್ನು ರಚಿಸುವಲ್ಲಿ ಉದ್ಯಮದ ಕೆಲವು ಪ್ರವರ್ತಕರು, ಇದು ಆರ್ಕೇಡ್ ಗೇಮರ್ಗಳ ಅತ್ಯಂತ ಅನುಭವಿಗಳಿಗೂ ಸಾಕಷ್ಟು ಸವಾಲು ಹಾಕುತ್ತದೆ.
Pac-Man, ನಿರ್ದಿಷ್ಟವಾಗಿ, AI ಸಂಶೋಧಕರು ಪ್ರಯೋಗಿಸಲು ಜನಪ್ರಿಯ ಆಟವಾಗಿತ್ತು. ವಿವಿಧ ಸ್ಪರ್ಧೆಗಳು Ms. Pac-Man ಗಾಗಿ ಆಟವನ್ನು ಸೋಲಿಸಲು ಯಾವ ತಂಡವು ಅತ್ಯುತ್ತಮ AI ಯೊಂದಿಗೆ ಬರಬಹುದು ಎಂಬುದನ್ನು ನಿರ್ಧರಿಸಲು ಆಯೋಜಿಸಲಾಗಿದೆ.
ಆಟದ AI ಮತ್ತು ಹ್ಯೂರಿಸ್ಟಿಕ್ ಅಲ್ಗಾರಿದಮ್ಗಳು ಚುರುಕಾದ ಎದುರಾಳಿಗಳ ಅಗತ್ಯತೆಯಿಂದಾಗಿ ವಿಕಸನಗೊಳ್ಳುವುದನ್ನು ಮುಂದುವರೆಸಿದವು. ಉದಾಹರಣೆಗೆ, ಫಸ್ಟ್-ಪರ್ಸನ್ ಶೂಟರ್ಗಳಂತಹ ಪ್ರಕಾರಗಳು ಹೆಚ್ಚು ಮುಖ್ಯವಾಹಿನಿಯಾಗಿದ್ದರಿಂದ ಯುದ್ಧ AI ಜನಪ್ರಿಯತೆ ಗಳಿಸಿತು.
ವಿಡಿಯೋ ಗೇಮ್ಗಳಲ್ಲಿ ಯಂತ್ರ ಕಲಿಕೆ
ಯಂತ್ರ ಕಲಿಕೆಯ ತಂತ್ರಗಳು ಶೀಘ್ರವಾಗಿ ಜನಪ್ರಿಯತೆ ಗಳಿಸಿದಂತೆ, ವಿವಿಧ ಸಂಶೋಧನಾ ಯೋಜನೆಗಳು ವೀಡಿಯೊ ಆಟಗಳನ್ನು ಆಡಲು ಈ ಹೊಸ ತಂತ್ರಗಳನ್ನು ಬಳಸಲು ಪ್ರಯತ್ನಿಸಿದವು.
ಡೋಟಾ 2, ಸ್ಟಾರ್ಕ್ರಾಫ್ಟ್ ಮತ್ತು ಡೂಮ್ನಂತಹ ಆಟಗಳು ಇವುಗಳಿಗೆ ಸಮಸ್ಯೆಗಳಾಗಿ ಕಾರ್ಯನಿರ್ವಹಿಸಬಹುದು ಯಂತ್ರ ಕಲಿಕೆ ಕ್ರಮಾವಳಿಗಳು ಪರಿಹರಿಸಲು. ಆಳವಾದ ಕಲಿಕೆಯ ಕ್ರಮಾವಳಿಗಳು, ನಿರ್ದಿಷ್ಟವಾಗಿ, ಮಾನವ ಮಟ್ಟದ ಕಾರ್ಯಕ್ಷಮತೆಯನ್ನು ಸಾಧಿಸಲು ಮತ್ತು ಮೀರಿಸಲು ಸಾಧ್ಯವಾಯಿತು.
ನಮ್ಮ ಆರ್ಕೇಡ್ ಕಲಿಕೆಯ ಪರಿಸರ ಅಥವಾ ALE ಸಂಶೋಧಕರಿಗೆ ನೂರಕ್ಕೂ ಹೆಚ್ಚು ಅಟಾರಿ 2600 ಆಟಗಳಿಗೆ ಇಂಟರ್ಫೇಸ್ ಅನ್ನು ನೀಡಿದೆ. ಓಪನ್ ಸೋರ್ಸ್ ಪ್ಲಾಟ್ಫಾರ್ಮ್ ಸಂಶೋಧಕರಿಗೆ ಕ್ಲಾಸಿಕ್ ಅಟಾರಿ ವೀಡಿಯೋ ಗೇಮ್ಗಳಲ್ಲಿ ಯಂತ್ರ ಕಲಿಕೆ ತಂತ್ರಗಳ ಕಾರ್ಯಕ್ಷಮತೆಯನ್ನು ಬೆಂಚ್ಮಾರ್ಕ್ ಮಾಡಲು ಅವಕಾಶ ಮಾಡಿಕೊಟ್ಟಿತು. ಗೂಗಲ್ ತಮ್ಮದೇ ಆದದನ್ನು ಸಹ ಪ್ರಕಟಿಸಿದೆ ಕಾಗದದ ALE ನಿಂದ ಏಳು ಆಟಗಳನ್ನು ಬಳಸಲಾಗುತ್ತಿದೆ

ಏತನ್ಮಧ್ಯೆ, ಅಂತಹ ಯೋಜನೆಗಳು ವಿಜ್ಡೂಮ್ 3D ಮೊದಲ-ವ್ಯಕ್ತಿ ಶೂಟರ್ಗಳನ್ನು ಆಡಲು ಯಂತ್ರ ಕಲಿಕೆ ಅಲ್ಗಾರಿದಮ್ಗಳನ್ನು ತರಬೇತಿ ಮಾಡಲು AI ಸಂಶೋಧಕರಿಗೆ ಅವಕಾಶವನ್ನು ನೀಡಿತು.

ಇದು ಹೇಗೆ ಕೆಲಸ ಮಾಡುತ್ತದೆ: ಕೆಲವು ಪ್ರಮುಖ ಪರಿಕಲ್ಪನೆಗಳು
ನ್ಯೂರಾಲ್ ನೆಟ್ವರ್ಕ್ಸ್
ಯಂತ್ರ ಕಲಿಕೆಯೊಂದಿಗೆ ವಿಡಿಯೋ ಗೇಮ್ಗಳನ್ನು ಪರಿಹರಿಸುವ ಹೆಚ್ಚಿನ ವಿಧಾನಗಳು ನ್ಯೂರಲ್ ನೆಟ್ವರ್ಕ್ ಎಂದು ಕರೆಯಲ್ಪಡುವ ಒಂದು ರೀತಿಯ ಅಲ್ಗಾರಿದಮ್ ಅನ್ನು ಒಳಗೊಂಡಿರುತ್ತದೆ.
ಮೆದುಳು ಹೇಗೆ ಕಾರ್ಯನಿರ್ವಹಿಸುತ್ತದೆ ಎಂಬುದನ್ನು ಅನುಕರಿಸಲು ಪ್ರಯತ್ನಿಸುವ ಪ್ರೋಗ್ರಾಂ ಎಂದು ನೀವು ನರ ನಿವ್ವಳವನ್ನು ಯೋಚಿಸಬಹುದು. ನಮ್ಮ ಮೆದುಳು ಹೇಗೆ ಸಿಗ್ನಲ್ ಅನ್ನು ರವಾನಿಸುವ ನ್ಯೂರಾನ್ಗಳಿಂದ ಕೂಡಿದೆ ಎಂಬುದರಂತೆಯೇ, ನರಮಂಡಲವು ಕೃತಕ ನ್ಯೂರಾನ್ಗಳನ್ನು ಹೊಂದಿರುತ್ತದೆ.
ಈ ಕೃತಕ ನರಕೋಶಗಳು ಸಹ ಸಂಕೇತಗಳನ್ನು ಪರಸ್ಪರ ವರ್ಗಾಯಿಸುತ್ತವೆ, ಪ್ರತಿ ಸಂಕೇತವು ನಿಜವಾದ ಸಂಖ್ಯೆಯಾಗಿರುತ್ತದೆ. ನ್ಯೂರಲ್ ನೆಟ್ ಇನ್ಪುಟ್ ಮತ್ತು ಔಟ್ಪುಟ್ ಲೇಯರ್ಗಳ ನಡುವೆ ಬಹು ಪದರಗಳನ್ನು ಹೊಂದಿರುತ್ತದೆ, ಇದನ್ನು ಆಳವಾದ ನರಮಂಡಲ ಎಂದು ಕರೆಯಲಾಗುತ್ತದೆ.
ಬಲವರ್ಧನೆಯ ಕಲಿಕೆ
ವೀಡಿಯೊ ಆಟಗಳನ್ನು ಕಲಿಯುವುದಕ್ಕೆ ಸಂಬಂಧಿಸಿದ ಮತ್ತೊಂದು ಸಾಮಾನ್ಯ ಯಂತ್ರ ಕಲಿಕೆಯ ತಂತ್ರವೆಂದರೆ ಬಲವರ್ಧನೆಯ ಕಲಿಕೆಯ ಕಲ್ಪನೆ.
ಈ ತಂತ್ರವು ಪ್ರತಿಫಲಗಳು ಅಥವಾ ಶಿಕ್ಷೆಗಳನ್ನು ಬಳಸಿಕೊಂಡು ಏಜೆಂಟ್ಗೆ ತರಬೇತಿ ನೀಡುವ ಪ್ರಕ್ರಿಯೆಯಾಗಿದೆ. ಈ ವಿಧಾನದೊಂದಿಗೆ, ಏಜೆಂಟ್ ಪ್ರಯೋಗ ಮತ್ತು ದೋಷದ ಮೂಲಕ ಸಮಸ್ಯೆಗೆ ಪರಿಹಾರದೊಂದಿಗೆ ಬರಲು ಸಾಧ್ಯವಾಗುತ್ತದೆ.
ಹಾವು ಆಟವನ್ನು ಹೇಗೆ ಆಡಬೇಕೆಂದು ಕಂಡುಹಿಡಿಯಲು ನಮಗೆ AI ಬೇಕು ಎಂದು ಹೇಳೋಣ. ಆಟದ ಉದ್ದೇಶವು ಸರಳವಾಗಿದೆ: ವಸ್ತುಗಳನ್ನು ಸೇವಿಸುವ ಮೂಲಕ ಮತ್ತು ನಿಮ್ಮ ಬೆಳೆಯುತ್ತಿರುವ ಬಾಲವನ್ನು ತಪ್ಪಿಸುವ ಮೂಲಕ ಸಾಧ್ಯವಾದಷ್ಟು ಅಂಕಗಳನ್ನು ಪಡೆಯಿರಿ.
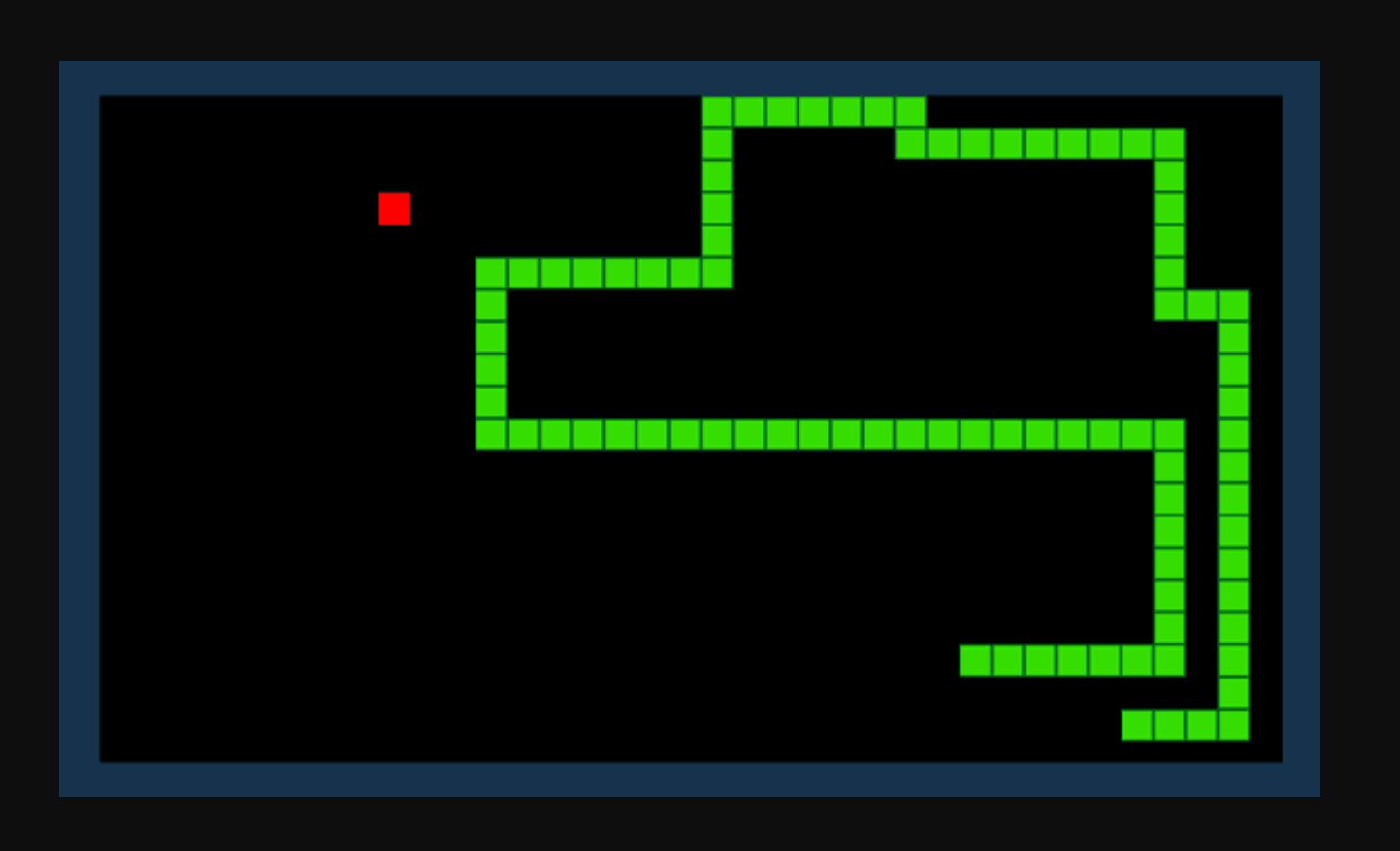
ಬಲವರ್ಧನೆಯ ಕಲಿಕೆಯೊಂದಿಗೆ, ನಾವು ರಿವಾರ್ಡ್ ಫಂಕ್ಷನ್ R ಅನ್ನು ವ್ಯಾಖ್ಯಾನಿಸಬಹುದು. ಹಾವು ಒಂದು ವಸ್ತುವನ್ನು ಸೇವಿಸಿದಾಗ ಕಾರ್ಯವು ಅಂಕಗಳನ್ನು ಸೇರಿಸುತ್ತದೆ ಮತ್ತು ಹಾವು ಒಂದು ಅಡಚಣೆಯನ್ನು ಹೊಡೆದಾಗ ಅಂಕಗಳನ್ನು ಕಡಿತಗೊಳಿಸುತ್ತದೆ. ಪ್ರಸ್ತುತ ಪರಿಸರ ಮತ್ತು ಸಂಭವನೀಯ ಕ್ರಿಯೆಗಳ ಗುಂಪನ್ನು ನೀಡಿದರೆ, ನಮ್ಮ ಬಲವರ್ಧನೆಯ ಕಲಿಕೆಯ ಮಾದರಿಯು ನಮ್ಮ ಪ್ರತಿಫಲ ಕಾರ್ಯವನ್ನು ಗರಿಷ್ಠಗೊಳಿಸುವ ಅತ್ಯುತ್ತಮವಾದ 'ನೀತಿಯನ್ನು' ಲೆಕ್ಕಾಚಾರ ಮಾಡಲು ಪ್ರಯತ್ನಿಸುತ್ತದೆ.
ನರವಿಕಸನ
ನಿಸರ್ಗದಿಂದ ಪ್ರೇರಿತವಾದ ವಿಷಯವನ್ನು ಇಟ್ಟುಕೊಂಡು, ಸಂಶೋಧಕರು ನ್ಯೂರೋ ಎವಲ್ಯೂಷನ್ ಎಂದು ಕರೆಯಲ್ಪಡುವ ತಂತ್ರದ ಮೂಲಕ ವೀಡಿಯೊ ಗೇಮ್ಗಳಿಗೆ ML ಅನ್ನು ಅನ್ವಯಿಸುವಲ್ಲಿ ಯಶಸ್ಸನ್ನು ಕಂಡುಕೊಂಡಿದ್ದಾರೆ.
ಬಳಸುವ ಬದಲು ಗ್ರೇಡಿಯಂಟ್ ಅವರೋಹಣ ನೆಟ್ವರ್ಕ್ನಲ್ಲಿ ನ್ಯೂರಾನ್ಗಳನ್ನು ನವೀಕರಿಸಲು, ಉತ್ತಮ ಫಲಿತಾಂಶಗಳನ್ನು ಸಾಧಿಸಲು ನಾವು ವಿಕಸನೀಯ ಅಲ್ಗಾರಿದಮ್ಗಳನ್ನು ಬಳಸಬಹುದು.
ಯಾದೃಚ್ಛಿಕ ವ್ಯಕ್ತಿಗಳ ಆರಂಭಿಕ ಜನಸಂಖ್ಯೆಯನ್ನು ಉತ್ಪಾದಿಸುವ ಮೂಲಕ ವಿಕಸನೀಯ ಕ್ರಮಾವಳಿಗಳು ಸಾಮಾನ್ಯವಾಗಿ ಪ್ರಾರಂಭವಾಗುತ್ತವೆ. ನಂತರ ನಾವು ಕೆಲವು ಮಾನದಂಡಗಳನ್ನು ಬಳಸಿಕೊಂಡು ಈ ವ್ಯಕ್ತಿಗಳನ್ನು ಮೌಲ್ಯಮಾಪನ ಮಾಡುತ್ತೇವೆ. ಉತ್ತಮ ವ್ಯಕ್ತಿಗಳನ್ನು "ಪೋಷಕರು" ಎಂದು ಆಯ್ಕೆ ಮಾಡಲಾಗುತ್ತದೆ ಮತ್ತು ಹೊಸ ಪೀಳಿಗೆಯ ವ್ಯಕ್ತಿಗಳನ್ನು ರೂಪಿಸಲು ಒಟ್ಟಿಗೆ ಬೆಳೆಸಲಾಗುತ್ತದೆ. ಈ ವ್ಯಕ್ತಿಗಳು ನಂತರ ಜನಸಂಖ್ಯೆಯಲ್ಲಿ ಕಡಿಮೆ ಫಿಟ್ ವ್ಯಕ್ತಿಗಳನ್ನು ಬದಲಾಯಿಸುತ್ತಾರೆ.
ಆನುವಂಶಿಕ ವೈವಿಧ್ಯತೆಯನ್ನು ಕಾಪಾಡಿಕೊಳ್ಳಲು ಕ್ರಾಸ್ಒವರ್ ಅಥವಾ "ಬ್ರೀಡಿಂಗ್" ಹಂತದ ಸಮಯದಲ್ಲಿ ಈ ಕ್ರಮಾವಳಿಗಳು ವಿಶಿಷ್ಟವಾಗಿ ಕೆಲವು ರೀತಿಯ ರೂಪಾಂತರ ಕಾರ್ಯಾಚರಣೆಯನ್ನು ಪರಿಚಯಿಸುತ್ತವೆ.
ವೀಡಿಯೊ ಗೇಮ್ಗಳಲ್ಲಿ ಯಂತ್ರ ಕಲಿಕೆಯ ಮಾದರಿ ಸಂಶೋಧನೆ
OpenAI ಐದು

OpenAI ಐದು ಜನಪ್ರಿಯ ಮಲ್ಟಿಪ್ಲೇಯರ್ ಮೊಬೈಲ್ ಬ್ಯಾಟಲ್ ಅರೇನಾ (MOBA) ಆಟವಾದ DOTA 2 ಅನ್ನು ಆಡಲು ಗುರಿಯನ್ನು ಹೊಂದಿರುವ OpenAI ಯ ಕಂಪ್ಯೂಟರ್ ಪ್ರೋಗ್ರಾಂ ಆಗಿದೆ.
ಪ್ರೋಗ್ರಾಂ ಅಸ್ತಿತ್ವದಲ್ಲಿರುವ ಬಲವರ್ಧನೆಯ ಕಲಿಕೆಯ ತಂತ್ರಗಳನ್ನು ಹತೋಟಿಗೆ ತಂದಿತು, ಪ್ರತಿ ಸೆಕೆಂಡಿಗೆ ಲಕ್ಷಾಂತರ ಫ್ರೇಮ್ಗಳಿಂದ ಕಲಿಯಲು ಅಳೆಯಲಾಗುತ್ತದೆ. ವಿತರಿಸಿದ ತರಬೇತಿ ವ್ಯವಸ್ಥೆಗೆ ಧನ್ಯವಾದಗಳು, OpenAI ಪ್ರತಿದಿನ 180 ವರ್ಷಗಳ ಮೌಲ್ಯದ ಆಟಗಳನ್ನು ಆಡಲು ಸಾಧ್ಯವಾಯಿತು.
ತರಬೇತಿ ಅವಧಿಯ ನಂತರ, OpenAI ಫೈವ್ ಪರಿಣಿತ ಮಟ್ಟದ ಕಾರ್ಯಕ್ಷಮತೆಯನ್ನು ಸಾಧಿಸಲು ಮತ್ತು ಮಾನವ ಆಟಗಾರರೊಂದಿಗೆ ಸಹಕಾರವನ್ನು ಪ್ರದರ್ಶಿಸಲು ಸಾಧ್ಯವಾಯಿತು. 2019 ರಲ್ಲಿ, OpenAI ಐದು ಸಾಧ್ಯವಾಯಿತು ಸೋಲು ಸಾರ್ವಜನಿಕ ಪಂದ್ಯಗಳಲ್ಲಿ 99.4% ಆಟಗಾರರು.
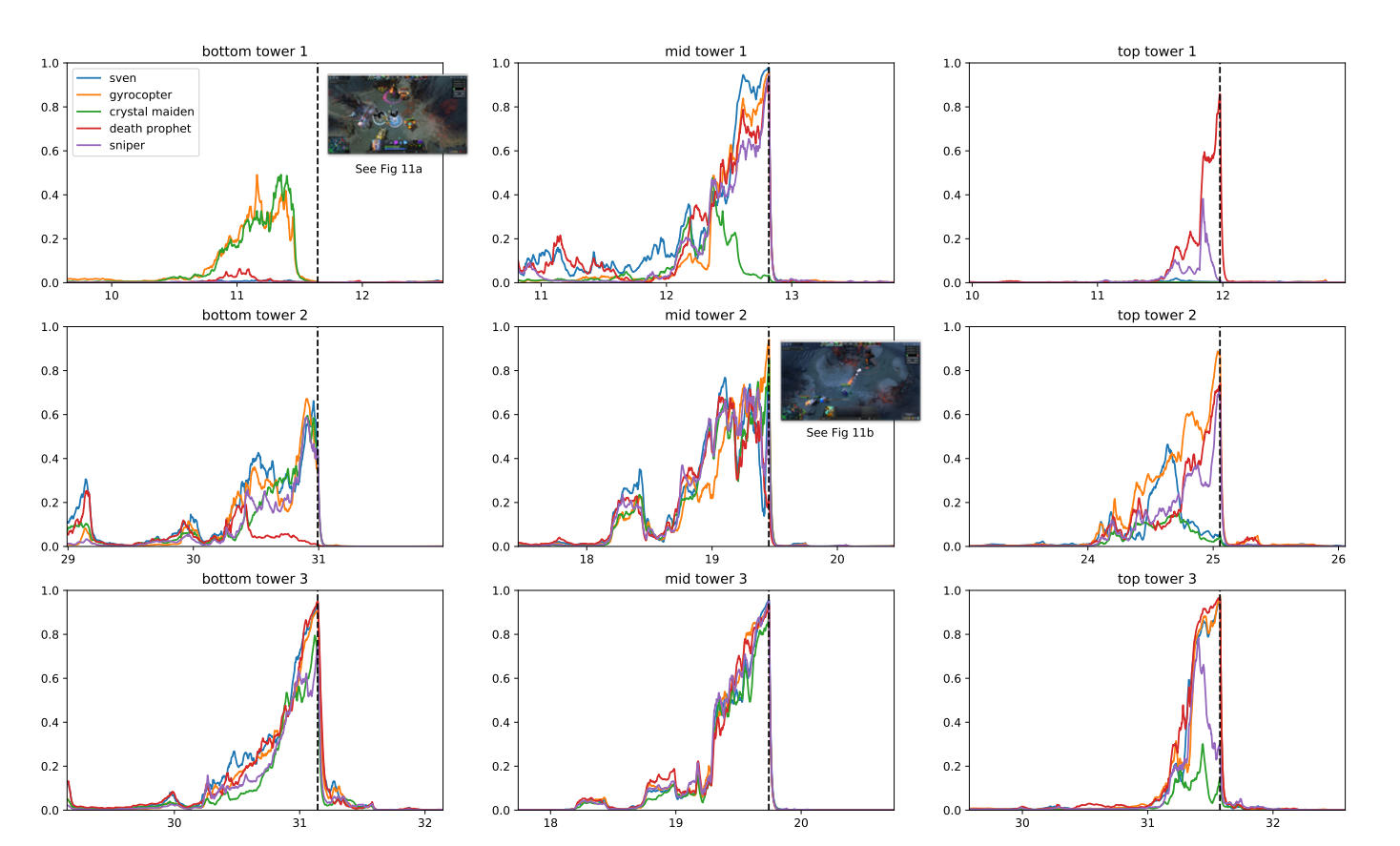
OpenAI ಈ ಆಟವನ್ನು ಏಕೆ ನಿರ್ಧರಿಸಿತು? ಸಂಶೋಧಕರ ಪ್ರಕಾರ, DOTA 2 ಸಂಕೀರ್ಣ ಯಂತ್ರಶಾಸ್ತ್ರವನ್ನು ಹೊಂದಿದ್ದು ಅದು ಅಸ್ತಿತ್ವದಲ್ಲಿರುವ ಆಳದ ವ್ಯಾಪ್ತಿಯಿಂದ ಹೊರಗಿದೆ ಬಲವರ್ಧನೆಯ ಕಲಿಕೆ ಕ್ರಮಾವಳಿಗಳು.
ಸೂಪರ್ ಮಾರಿಯೋ ಬ್ರದರ್ಸ್
ಸೂಪರ್ ಮಾರಿಯೋ ಬ್ರದರ್ಸ್ ನಂತಹ ಪ್ಲ್ಯಾಟ್ಫಾರ್ಮ್ಗಳನ್ನು ಆಡಲು ನ್ಯೂರೋ ವಿಕಸನದ ಬಳಕೆ ವಿಡಿಯೋ ಗೇಮ್ಗಳಲ್ಲಿ ನ್ಯೂರಲ್ ನೆಟ್ಗಳ ಮತ್ತೊಂದು ಆಸಕ್ತಿದಾಯಕ ಅಪ್ಲಿಕೇಶನ್ ಆಗಿದೆ.
ಉದಾಹರಣೆಗೆ, ಇದು ಹ್ಯಾಕಥಾನ್ ಪ್ರವೇಶ ಆಟದ ಬಗ್ಗೆ ಯಾವುದೇ ಜ್ಞಾನವಿಲ್ಲದೆ ಪ್ರಾರಂಭವಾಗುತ್ತದೆ ಮತ್ತು ನಿಧಾನವಾಗಿ ಒಂದು ಹಂತದ ಮೂಲಕ ಪ್ರಗತಿಗೆ ಅಗತ್ಯವಿರುವ ಅಡಿಪಾಯವನ್ನು ನಿರ್ಮಿಸುತ್ತದೆ.
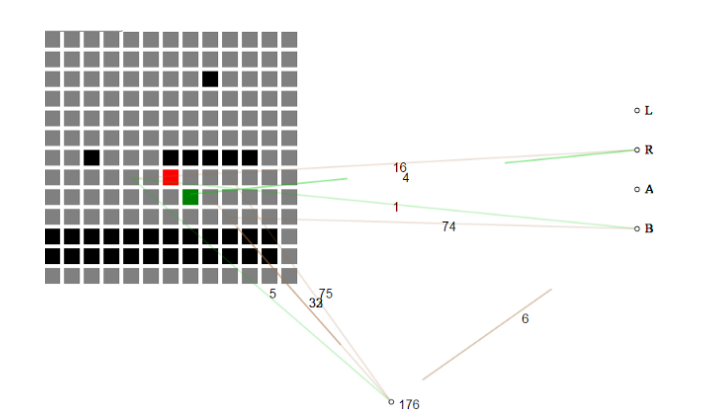
ಸ್ವಯಂ-ವಿಕಸನಗೊಳ್ಳುವ ನರಮಂಡಲವು ಆಟದ ಪ್ರಸ್ತುತ ಸ್ಥಿತಿಯನ್ನು ಟೈಲ್ಸ್ ಗ್ರಿಡ್ ಆಗಿ ತೆಗೆದುಕೊಳ್ಳುತ್ತದೆ. ಮೊದಲಿಗೆ, ನ್ಯೂರಲ್ ನಿವ್ವಳವು ಪ್ರತಿ ಟೈಲ್ ಎಂದರೆ ಏನು ಎಂಬುದರ ಬಗ್ಗೆ ಯಾವುದೇ ತಿಳುವಳಿಕೆಯನ್ನು ಹೊಂದಿಲ್ಲ, "ಗಾಳಿ" ಅಂಚುಗಳು "ನೆಲದ ಅಂಚುಗಳು" ಮತ್ತು "ಶತ್ರು ಅಂಚುಗಳು" ಗಿಂತ ಭಿನ್ನವಾಗಿರುತ್ತವೆ.
ಹ್ಯಾಕಥಾನ್ ಪ್ರಾಜೆಕ್ಟ್ನ ನರವಿಕಸನದ ಅನುಷ್ಠಾನವು NEAT ಜೆನೆಟಿಕ್ ಅಲ್ಗಾರಿದಮ್ ಅನ್ನು ವಿವಿಧ ನರ ಜಾಲಗಳನ್ನು ಆಯ್ದವಾಗಿ ತಳಿ ಮಾಡಲು ಬಳಸಿದೆ.
ಪ್ರಾಮುಖ್ಯತೆ
ಈಗ ನೀವು ನ್ಯೂರಲ್ ನೆಟ್ಗಳು ವಿಡಿಯೋ ಗೇಮ್ಗಳನ್ನು ಆಡುವ ಕೆಲವು ಉದಾಹರಣೆಗಳನ್ನು ನೋಡಿದ್ದೀರಿ, ಇದೆಲ್ಲದರ ಅರ್ಥವೇನು ಎಂದು ನೀವು ಆಶ್ಚರ್ಯ ಪಡಬಹುದು.
ವೀಡಿಯೊ ಗೇಮ್ಗಳು ಏಜೆಂಟ್ಗಳು ಮತ್ತು ಅವರ ಪರಿಸರಗಳ ನಡುವಿನ ಸಂಕೀರ್ಣ ಸಂವಹನಗಳನ್ನು ಒಳಗೊಂಡಿರುವುದರಿಂದ, ಇದು AI ಅನ್ನು ತಯಾರಿಸಲು ಪರಿಪೂರ್ಣ ಪರೀಕ್ಷಾ ಮೈದಾನವಾಗಿದೆ. ವರ್ಚುವಲ್ ಪರಿಸರಗಳು ಸುರಕ್ಷಿತ ಮತ್ತು ನಿಯಂತ್ರಿಸಬಲ್ಲವು ಮತ್ತು ಡೇಟಾದ ಅನಂತ ಪೂರೈಕೆಯನ್ನು ಒದಗಿಸುತ್ತವೆ.
ಈ ಕ್ಷೇತ್ರದಲ್ಲಿ ಮಾಡಿದ ಸಂಶೋಧನೆಯು ನೈಜ ಜಗತ್ತಿನಲ್ಲಿ ಸಮಸ್ಯೆಗಳನ್ನು ಹೇಗೆ ಪರಿಹರಿಸಬೇಕೆಂದು ತಿಳಿಯಲು ನರ ಜಾಲಗಳನ್ನು ಹೇಗೆ ಆಪ್ಟಿಮೈಸ್ ಮಾಡಬಹುದು ಎಂಬುದರ ಕುರಿತು ಸಂಶೋಧಕರಿಗೆ ಒಳನೋಟವನ್ನು ನೀಡಿದೆ.
ನರ ಜಾಲಗಳು ನೈಸರ್ಗಿಕ ಜಗತ್ತಿನಲ್ಲಿ ಮಿದುಳುಗಳು ಹೇಗೆ ಕೆಲಸ ಮಾಡುತ್ತವೆ ಎಂಬುದಕ್ಕೆ ಸ್ಫೂರ್ತಿ. ವೀಡಿಯೊ ಗೇಮ್ ಅನ್ನು ಹೇಗೆ ಆಡಬೇಕೆಂದು ಕಲಿಯುವಾಗ ಕೃತಕ ನ್ಯೂರಾನ್ಗಳು ಹೇಗೆ ವರ್ತಿಸುತ್ತವೆ ಎಂಬುದನ್ನು ಅಧ್ಯಯನ ಮಾಡುವ ಮೂಲಕ, ನಾವು ಹೇಗೆ ಒಳನೋಟವನ್ನು ಪಡೆಯಬಹುದು ಮಾನವ ಮೆದುಳು ಕೆಲಸ.
ತೀರ್ಮಾನ
ನರಮಂಡಲಗಳು ಮತ್ತು ಮೆದುಳಿನ ನಡುವಿನ ಸಾಮ್ಯತೆಗಳು ಎರಡೂ ಕ್ಷೇತ್ರಗಳಲ್ಲಿ ಒಳನೋಟಗಳಿಗೆ ಕಾರಣವಾಗಿವೆ. ನರ ಜಾಲಗಳು ಸಮಸ್ಯೆಗಳನ್ನು ಹೇಗೆ ಪರಿಹರಿಸಬಹುದು ಎಂಬುದರ ಕುರಿತು ನಿರಂತರ ಸಂಶೋಧನೆಯು ಒಂದು ದಿನ ಹೆಚ್ಚು ಸುಧಾರಿತ ರೂಪಗಳಿಗೆ ಕಾರಣವಾಗಬಹುದು ಕೃತಕ ಬುದ್ಧಿವಂತಿಕೆ.
ನಿಮ್ಮ ಸಮಯಕ್ಕೆ ಯೋಗ್ಯವಾಗಿದೆಯೇ ಎಂದು ನಿಮಗೆ ತಿಳಿಸಲು ನೀವು ಅದನ್ನು ಖರೀದಿಸುವ ಮೊದಲು ಸಂಪೂರ್ಣ ವೀಡಿಯೊ ಗೇಮ್ ಅನ್ನು ಆಡಬಹುದಾದ ನಿಮ್ಮ ವಿಶೇಷಣಗಳಿಗೆ ಅನುಗುಣವಾಗಿ AI ಅನ್ನು ಬಳಸುವುದನ್ನು ಕಲ್ಪಿಸಿಕೊಳ್ಳಿ. ಆಟದ ವಿನ್ಯಾಸ, ಟ್ವೀಕ್ ಮಟ್ಟ ಮತ್ತು ಎದುರಾಳಿಯ ತೊಂದರೆಯನ್ನು ಸುಧಾರಿಸಲು ವೀಡಿಯೊ ಗೇಮ್ ಕಂಪನಿಗಳು ನ್ಯೂರಲ್ ನೆಟ್ಗಳನ್ನು ಬಳಸುತ್ತವೆಯೇ?
ನ್ಯೂರಲ್ ನೆಟ್ಗಳು ಅಂತಿಮ ಗೇಮರ್ಗಳಾದಾಗ ಏನಾಗುತ್ತದೆ ಎಂದು ನೀವು ಯೋಚಿಸುತ್ತೀರಿ?





ಪ್ರತ್ಯುತ್ತರ ನೀಡಿ