មាតិកា[លាក់][បង្ហាញ]
ឥឡូវនេះយើងអាចគណនាការពង្រីកនៃលំហ និងភាពស្និទ្ធស្នាលនាទីនៃភាគល្អិតអាតូមិក ដោយសារកុំព្យូទ័រ។
កុំព្យូទ័រវាយមនុស្សនៅពេលនិយាយអំពីការរាប់ និងការគណនា ក៏ដូចជាការធ្វើតាមឡូជីខល បាទ/ចាស ដំណើរការ អរគុណចំពោះអេឡិចត្រុងដែលធ្វើដំណើរក្នុងល្បឿនពន្លឺតាមរយៈសៀគ្វីរបស់វា។
ទោះជាយ៉ាងណាក៏ដោយ យើងមិនសូវឃើញពួកគេថាជា "ឆ្លាតវៃ" ទេ ព្រោះកាលពីអតីតកាល កុំព្យូទ័រមិនអាចដំណើរការអ្វីបានឡើយ បើគ្មានការបង្រៀន (កម្មវិធី) ដោយមនុស្ស។
ការរៀនម៉ាស៊ីន រួមទាំងការរៀនស៊ីជម្រៅ និង ក្លែងបន្លំបានក្លាយជាពាក្យចចាមអារ៉ាមនៅក្នុងចំណងជើងវិទ្យាសាស្ត្រ និងបច្ចេកវិទ្យា។
ការរៀនតាមម៉ាស៊ីនហាក់ដូចជាមានគ្រប់សព្វ ប៉ុន្តែមនុស្សជាច្រើនដែលប្រើពាក្យនេះ នឹងពិបាកក្នុងការកំណត់ឱ្យបានគ្រប់គ្រាន់ថាវាជាអ្វី វាធ្វើអ្វី និងអ្វីដែលវាត្រូវបានប្រើប្រាស់ល្អបំផុត។
អត្ថបទនេះស្វែងរកការបញ្ជាក់ពីការរៀនម៉ាស៊ីន ខណៈពេលដែលផ្តល់នូវឧទាហរណ៍ជាក់ស្តែង និងជាក់ស្តែងនៃរបៀបដែលបច្ចេកវិទ្យាដំណើរការ ដើម្បីបង្ហាញពីមូលហេតុដែលវាមានប្រយោជន៍។
បន្ទាប់មក យើងនឹងពិនិត្យមើលវិធីសាស្រ្តរៀនម៉ាស៊ីនផ្សេងៗ និងមើលពីរបៀបដែលពួកវាត្រូវបានប្រើដើម្បីដោះស្រាយបញ្ហាប្រឈមមុខជំនួញ។
ជាចុងក្រោយ យើងនឹងពិគ្រោះជាមួយបាល់គ្រីស្តាល់របស់យើងសម្រាប់ការទស្សន៍ទាយរហ័សមួយចំនួនអំពីអនាគតនៃការរៀនម៉ាស៊ីន។
តើការរៀនម៉ាស៊ីនគឺជាអ្វី?
ការរៀនម៉ាស៊ីនគឺជាវិន័យនៃវិទ្យាសាស្ត្រកុំព្យូទ័រដែលអាចឱ្យកុំព្យូទ័រអាចសន្និដ្ឋានបាននូវគំរូពីទិន្នន័យដោយមិនត្រូវបានបង្រៀនយ៉ាងច្បាស់ថាគំរូទាំងនោះជាអ្វី។
ការសន្និដ្ឋានទាំងនេះជារឿយៗផ្អែកលើការប្រើក្បួនដោះស្រាយដើម្បីវាយតម្លៃដោយស្វ័យប្រវត្តិនូវលក្ខណៈស្ថិតិនៃទិន្នន័យ និងការបង្កើតគំរូគណិតវិទ្យាដើម្បីពណ៌នាអំពីទំនាក់ទំនងរវាងតម្លៃផ្សេងៗ។
ប្រៀបធៀបវាជាមួយនឹងការគណនាបុរាណ ដែលផ្អែកលើប្រព័ន្ធកំណត់ ដែលយើងផ្តល់ឱ្យកុំព្យូទ័រនូវច្បាប់ជាក់លាក់មួយដើម្បីអនុវត្តតាមសម្រាប់វាដើម្បីធ្វើកិច្ចការជាក់លាក់មួយ។
វិធីនៃការសរសេរកម្មវិធីកុំព្យូទ័រត្រូវបានគេស្គាល់ថាជាកម្មវិធីដែលផ្អែកលើច្បាប់។ ការរៀនម៉ាស៊ីនខុសពី និងដំណើរការកម្មវិធីដែលផ្អែកលើច្បាប់ ដែលវាអាចកាត់យកច្បាប់ទាំងនេះដោយខ្លួនឯងបាន។
សន្មតថាអ្នកជាអ្នកគ្រប់គ្រងធនាគារដែលចង់កំណត់ថាតើកម្មវិធីប្រាក់កម្ចីនឹងបរាជ័យលើប្រាក់កម្ចីរបស់ពួកគេ។
នៅក្នុងវិធីសាស្រ្តផ្អែកលើច្បាប់ អ្នកគ្រប់គ្រងធនាគារ (ឬអ្នកឯកទេសផ្សេងទៀត) នឹងជូនដំណឹងដល់កុំព្យូទ័រយ៉ាងច្បាស់ថា ប្រសិនបើពិន្ទុឥណទានរបស់អ្នកដាក់ពាក្យសុំទាបជាងកម្រិតជាក់លាក់មួយ កម្មវិធីគួរតែត្រូវបានបដិសេធ។
ទោះយ៉ាងណាក៏ដោយ កម្មវិធីសិក្សាតាមម៉ាស៊ីននឹងវិភាគទិន្នន័យមុនលើការផ្តល់ចំណាត់ថ្នាក់ឥណទានរបស់អតិថិជន និងលទ្ធផលប្រាក់កម្ចី ហើយកំណត់ថាតើកម្រិតនេះគួរជាអ្វីដោយខ្លួនឯង។
ម៉ាស៊ីនរៀនពីទិន្នន័យពីមុន ហើយបង្កើតច្បាប់ដោយខ្លួនឯងតាមវិធីនេះ។ ជាការពិតណាស់, នេះគឺគ្រាន់តែជា primer នៅលើការរៀនម៉ាស៊ីនមួយ; ម៉ូដែលរៀនម៉ាស៊ីនពិភពពិតមានភាពស្មុគស្មាញជាងកម្រិតមូលដ្ឋាន។
យ៉ាងណាក៏ដោយ វាជាការបង្ហាញដ៏ល្អមួយនៃសក្ដានុពលនៃការរៀនម៉ាស៊ីន។
តើក ម៉ាស៊ីន រៀន?
ដើម្បីរក្សាអ្វីៗឱ្យសាមញ្ញ ម៉ាស៊ីន "រៀន" ដោយស្វែងរកគំរូក្នុងទិន្នន័យដែលអាចប្រៀបធៀបបាន។ ចាត់ទុកទិន្នន័យជាព័ត៌មានដែលអ្នកប្រមូលពីពិភពខាងក្រៅ។ ទិន្នន័យកាន់តែច្រើនដែលម៉ាស៊ីនត្រូវបានចុក វាកាន់តែ "ឆ្លាតជាងមុន" ។
ទោះយ៉ាងណាក៏ដោយ មិនមែនទិន្នន័យទាំងអស់ដូចគ្នាទេ។ សន្មតថាអ្នកជាចោរសមុទ្រដែលមានគោលបំណងជីវិតដើម្បីស្វែងរកទ្រព្យសម្បត្តិដែលកប់នៅលើកោះ។ អ្នកនឹងចង់បានចំណេះដឹងច្រើនក្នុងការកំណត់ទីតាំងរង្វាន់។
ចំណេះដឹងនេះ ដូចជាទិន្នន័យ អាចនាំអ្នកទៅផ្លូវត្រូវ ឬខុស។
ព័ត៌មាន/ទិន្នន័យដែលទទួលបានកាន់តែច្រើន ភាពមិនច្បាស់លាស់កាន់តែតិច ហើយផ្ទុយទៅវិញ។ ជាលទ្ធផល វាមានសារៈសំខាន់ណាស់ក្នុងការពិចារណាលើប្រភេទទិន្នន័យដែលអ្នកកំពុងផ្តល់អាហារដល់ម៉ាស៊ីនរបស់អ្នកដើម្បីរៀន។
ទោះជាយ៉ាងណាក៏ដោយ នៅពេលដែលបរិមាណទិន្នន័យច្រើនត្រូវបានផ្តល់ឱ្យ កុំព្យូទ័រអាចធ្វើការទស្សន៍ទាយបាន។ ម៉ាស៊ីនអាចទស្សទាយអនាគតបាន ដរាបណាវាមិនងាកចេញច្រើនពីអតីតកាល។
ម៉ាស៊ីន "រៀន" ដោយការវិភាគទិន្នន័យប្រវត្តិសាស្រ្តដើម្បីកំណត់នូវអ្វីដែលទំនងជានឹងកើតឡើង។
ប្រសិនបើទិន្នន័យចាស់ស្រដៀងនឹងទិន្នន័យថ្មី នោះរឿងដែលអ្នកអាចនិយាយអំពីទិន្នន័យមុនទំនងជានឹងអនុវត្តចំពោះទិន្នន័យថ្មី។ វាដូចជាអ្នកកំពុងមើលទៅក្រោយដើម្បីមើលទៅមុខ។
តើម៉ាស៊ីនរៀនប្រភេទអ្វីខ្លះ?
ក្បួនដោះស្រាយសម្រាប់ការរៀនម៉ាស៊ីនត្រូវបានចាត់ថ្នាក់ជាញឹកញាប់ជាបីប្រភេទធំ (ទោះបីជាគ្រោងការណ៍ចំណាត់ថ្នាក់ផ្សេងទៀតក៏ត្រូវបានគេប្រើផងដែរ):
- ការរៀនសូត្រត្រួតពិនិត្យ
- ការរៀនសូត្រដែលមិនមានការត្រួតពិនិត្យ
- ការរៀនសូត្រពង្រឹង
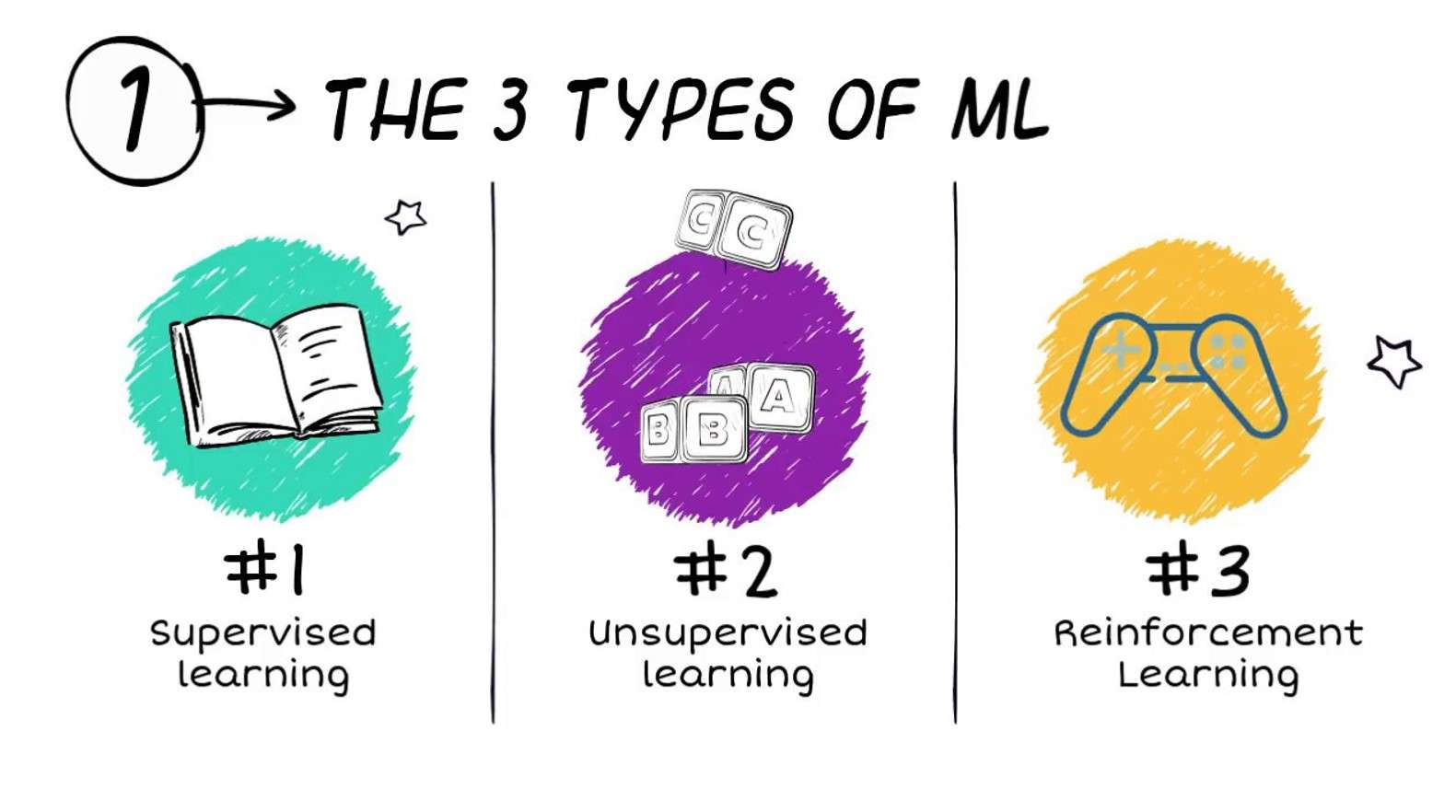
ការរៀនសូត្រត្រួតពិនិត្យ
ការរៀនម៉ាស៊ីនដែលមានការត្រួតពិនិត្យ សំដៅលើបច្ចេកទេសដែលគំរូរៀនម៉ាស៊ីនត្រូវបានផ្តល់ការប្រមូលទិន្នន័យដែលមានស្លាកច្បាស់លាស់សម្រាប់បរិមាណនៃការចាប់អារម្មណ៍ (បរិមាណនេះច្រើនតែហៅថាជាការឆ្លើយតប ឬគោលដៅ)។
ដើម្បីបណ្តុះបណ្តាលគំរូ AI ការរៀនពាក់កណ្តាលត្រួតពិនិត្យប្រើការលាយបញ្ចូលគ្នានៃទិន្នន័យដែលមានស្លាក និងមិនមានស្លាក។
ប្រសិនបើអ្នកកំពុងធ្វើការជាមួយទិន្នន័យដែលមិនមានស្លាក អ្នកនឹងត្រូវអនុវត្តការដាក់ស្លាកទិន្នន័យមួយចំនួន។
ការដាក់ស្លាកសញ្ញាគឺជាដំណើរការនៃការដាក់ស្លាកគំរូដើម្បីជួយក្នុង ការបណ្តុះបណ្តាលម៉ាស៊ីនរៀន គំរូ។ ការដាក់ស្លាកត្រូវបានធ្វើជាចម្បងដោយមនុស្ស ដែលអាចត្រូវចំណាយប្រាក់ និងចំណាយពេលវេលា។ ទោះយ៉ាងណាក៏ដោយមានបច្ចេកទេសដើម្បីធ្វើឱ្យដំណើរការដាក់ស្លាកដោយស្វ័យប្រវត្តិ។
ស្ថានភាពនៃការស្នើសុំប្រាក់កម្ចីដែលយើងបានពិភាក្សាពីមុនគឺជារូបភាពដ៏ល្អមួយនៃការរៀនសូត្រដែលមានការត្រួតពិនិត្យ។ យើងមានទិន្នន័យប្រវត្តិសាស្ត្រទាក់ទងនឹងការផ្តល់ចំណាត់ថ្នាក់ឥណទានរបស់អ្នកខ្ចីពីមុន (ហើយប្រហែលជាកម្រិតប្រាក់ចំណូល អាយុ និងផ្សេងៗទៀត) ក៏ដូចជាស្លាកជាក់លាក់ដែលប្រាប់យើងថាតើបុគ្គលដែលស្ថិតក្នុងសំណួរបានខកខានក្នុងការផ្តល់ប្រាក់កម្ចីរបស់ពួកគេ។
ការតំរែតំរង់ និងការចាត់ថ្នាក់គឺជាសំណុំរងពីរនៃបច្ចេកទេសសិក្សាដែលត្រូវបានត្រួតពិនិត្យ។
- ចំណាត់ថា្នាក់ - វាប្រើ algorithm ដើម្បីចាត់ថ្នាក់ទិន្នន័យឱ្យបានត្រឹមត្រូវ។ តម្រងសារឥតបានការគឺជាឧទាហរណ៍មួយ។ "សារឥតបានការ" អាចជាប្រភេទប្រធានបទ - បន្ទាត់រវាងការប្រាស្រ័យទាក់ទងឥតបានការ និងមិនមែនសារឥតបានការគឺមានភាពមិនច្បាស់លាស់ ហើយក្បួនដោះស្រាយតម្រងសារឥតបានការកំពុងកែលម្អខ្លួនវាជានិច្ច អាស្រ័យលើមតិកែលម្អរបស់អ្នក (មានន័យថាអ៊ីមែលដែលមនុស្សសម្គាល់ថាជាសារឥតបានការ)។
- តំរែតំរង់ - វាមានប្រយោជន៍ក្នុងការយល់អំពីការតភ្ជាប់រវាងអថេរអាស្រ័យ និងអថេរ។ គំរូតំរែតំរង់អាចព្យាករណ៍តម្លៃជាលេខដោយផ្អែកលើប្រភពទិន្នន័យជាច្រើន ដូចជាការប៉ាន់ប្រមាណប្រាក់ចំណូលពីការលក់សម្រាប់ក្រុមហ៊ុនជាក់លាក់មួយ។ តំរែតំរង់លីនេអ៊ែរ តំរែតំរង់តំរែតំរង់តំរែតំរង់តំរែតំរង់តំរែតំរង់ពហុនាមគឺជាបច្ចេកទេសតំរែតំរង់ដ៏លេចធ្លោមួយចំនួន។
ការរៀនសូត្រដែលមិនមានការត្រួតពិនិត្យ
នៅក្នុងការរៀនដែលគ្មានការត្រួតពិនិត្យ យើងត្រូវបានផ្តល់ទិន្នន័យដែលគ្មានស្លាកសញ្ញា ហើយគ្រាន់តែស្វែងរកគំរូប៉ុណ្ណោះ។ ចូរធ្វើពុតថាអ្នកជា Amazon ។ តើយើងអាចស្វែងរកចង្កោមណាមួយ (ក្រុមអ្នកប្រើប្រាស់ស្រដៀងគ្នា) ដោយផ្អែកលើប្រវត្តិការទិញរបស់អតិថិជនបានទេ?
ទោះបីជាយើងមិនមានទិន្នន័យច្បាស់លាស់ និងច្បាស់លាស់អំពីចំណូលចិត្តរបស់មនុស្សក៏ដោយ ក្នុងករណីនេះគ្រាន់តែដឹងថាក្រុមអ្នកប្រើប្រាស់ជាក់លាក់មួយទិញទំនិញដែលអាចប្រៀបធៀបបានអនុញ្ញាតឱ្យយើងបង្កើតសំណើទិញដោយផ្អែកលើអ្វីដែលបុគ្គលផ្សេងទៀតនៅក្នុងចង្កោមបានទិញផងដែរ។
"អ្នកក៏ប្រហែលជាចាប់អារម្មណ៍ផងដែរ" របស់ Amazon ត្រូវបានបំពាក់ដោយបច្ចេកវិទ្យាស្រដៀងគ្នា។
ការសិក្សាដែលមិនមានការត្រួតពិនិត្យអាចដាក់ទិន្នន័យជាក្រុមតាមរយៈការធ្វើចង្កោមឬការភ្ជាប់គ្នាអាស្រ័យលើអ្វីដែលអ្នកចង់ដាក់ជាក្រុមជាមួយគ្នា។
- ចង្កោម - ការរៀនសូត្រដែលមិនមានការត្រួតពិនិត្យ ព្យាយាមយកឈ្នះលើបញ្ហាប្រឈមនេះដោយស្វែងរកគំរូនៅក្នុងទិន្នន័យ។ ប្រសិនបើមានចង្កោម ឬក្រុមស្រដៀងគ្នា នោះក្បួនដោះស្រាយនឹងចាត់ថ្នាក់ពួកវាតាមលក្ខណៈជាក់លាក់មួយ។ ការព្យាយាមចាត់ថ្នាក់អតិថិជនដោយផ្អែកលើប្រវត្តិនៃការទិញពីមុនគឺជាឧទាហរណ៍នៃរឿងនេះ។
- សមាគម - ការរៀនសូត្រដែលមិនមានការត្រួតពិនិត្យ ព្យាយាមដោះស្រាយបញ្ហាប្រឈមនេះ ដោយព្យាយាមស្វែងយល់ពីច្បាប់ និងអត្ថន័យនៃក្រុមផ្សេងៗ។ ឧទាហរណ៍ជាញឹកញាប់នៃបញ្ហាសមាគមគឺកំណត់ទំនាក់ទំនងរវាងការទិញរបស់អតិថិជន។ ហាងនានាអាចចាប់អារម្មណ៍ក្នុងការដឹងថាតើទំនិញអ្វីខ្លះត្រូវបានទិញរួមគ្នា ហើយអាចប្រើប្រាស់ព័ត៌មាននេះដើម្បីរៀបចំទីតាំងនៃផលិតផលទាំងនេះសម្រាប់ភាពងាយស្រួល។
ការរៀនសូត្រពង្រឹង
ការរៀនពង្រឹងគឺជាបច្ចេកទេសសម្រាប់ការបង្រៀនគំរូនៃការរៀនម៉ាស៊ីនដើម្បីធ្វើការសម្រេចចិត្តតម្រង់ទិសជាបន្តបន្ទាប់នៅក្នុងការកំណត់អន្តរកម្ម។ ករណីប្រើប្រាស់ហ្គេមដែលបានរៀបរាប់ខាងលើគឺជារូបភាពដ៏ល្អនៃរឿងនេះ។
អ្នកមិនចាំបាច់បញ្ចូលហ្គេមអុកពីមុនរាប់ពាន់ AlphaZero នោះទេ នីមួយៗមានស្លាកសញ្ញា "ល្អ" ឬ "អន់" ។ គ្រាន់តែបង្រៀនវាអំពីច្បាប់ និងគោលដៅរបស់ហ្គេម ហើយបន្ទាប់មកអនុញ្ញាតឱ្យវាសាកល្បងសកម្មភាពចៃដន្យ។
ការពង្រឹងជាវិជ្ជមានត្រូវបានផ្តល់ទៅឱ្យសកម្មភាពដែលនាំកម្មវិធីខិតទៅជិតគោលដៅ (ដូចជាការអភិវឌ្ឍទីតាំងបញ្ចាំដ៏រឹងមាំ)។ នៅពេលដែលសកម្មភាពមានឥទ្ធិពលផ្ទុយ (ដូចជាការផ្លាស់ប្តូរស្តេចមុនអាយុ) ពួកគេនឹងទទួលបានការពង្រឹងអវិជ្ជមាន។
ទីបំផុតកម្មវិធីអាចគ្រប់គ្រងហ្គេមដោយប្រើវិធីសាស្ត្រនេះ។
ការរៀនសូត្រពង្រឹង ត្រូវបានគេប្រើយ៉ាងទូលំទូលាយក្នុងផ្នែកមនុស្សយន្តដើម្បីបង្រៀនមនុស្សយន្តសម្រាប់សកម្មភាពស្មុគស្មាញ និងពិបាកក្នុងការធ្វើវិស្វករ។ ពេលខ្លះវាត្រូវបានប្រើប្រាស់ដោយភ្ជាប់ជាមួយហេដ្ឋារចនាសម្ព័ន្ធផ្លូវថ្នល់ ដូចជាសញ្ញាចរាចរណ៍ ដើម្បីកែលម្អលំហូរចរាចរណ៍។
តើអាចធ្វើអ្វីបានជាមួយការរៀនម៉ាស៊ីន?
ការប្រើប្រាស់ម៉ាសុីនរៀននៅក្នុងសង្គម និងឧស្សាហកម្ម នាំឱ្យមានការជឿនលឿនក្នុងជួរដ៏ធំទូលាយនៃការខិតខំប្រឹងប្រែងរបស់មនុស្ស។
នៅក្នុងជីវិតប្រចាំថ្ងៃរបស់យើង ការរៀនម៉ាស៊ីនឥឡូវនេះគ្រប់គ្រងការស្វែងរក និងរូបភាពរបស់ Google ដែលអនុញ្ញាតឱ្យយើងផ្គូផ្គងកាន់តែត្រឹមត្រូវជាមួយនឹងព័ត៌មានដែលយើងត្រូវការនៅពេលយើងត្រូវការវា។
ជាឧទាហរណ៍ នៅក្នុងវេជ្ជសាស្ត្រ ការរៀនម៉ាស៊ីនកំពុងត្រូវបានអនុវត្តចំពោះទិន្នន័យហ្សែន ដើម្បីជួយឱ្យវេជ្ជបណ្ឌិតយល់ និងទស្សន៍ទាយពីរបៀបដែលជំងឺមហារីករីករាលដាល ដែលអនុញ្ញាតឱ្យបង្កើតការព្យាបាលដែលមានប្រសិទ្ធភាពជាងមុន។
ទិន្នន័យពីលំហដ៏ជ្រៅកំពុងត្រូវបានប្រមូលនៅទីនេះនៅលើផែនដីតាមរយៈតេឡេស្កុបវិទ្យុដ៏ធំ ហើយបន្ទាប់ពីត្រូវបានវិភាគដោយប្រើម៉ាស៊ីនរៀន វាកំពុងជួយយើងស្រាយអាថ៌កំបាំងនៃប្រហោងខ្មៅ។
ការរៀនម៉ាស៊ីននៅក្នុងការលក់រាយភ្ជាប់អ្នកទិញជាមួយនឹងអ្វីដែលពួកគេចង់ទិញតាមអ៊ីនធឺណិត ហើយថែមទាំងជួយបុគ្គលិកហាងក្នុងការកែសម្រួលសេវាកម្មដែលពួកគេផ្តល់ជូនអតិថិជនរបស់ពួកគេនៅក្នុងពិភពឥដ្ឋនិងបាយអ។
ការរៀនម៉ាស៊ីនត្រូវបានប្រើប្រាស់នៅក្នុងការប្រយុទ្ធប្រឆាំងនឹងភេរវកម្ម និងភាពជ្រុលនិយម ដើម្បីប្រមើលមើលអាកប្បកិរិយារបស់អ្នកដែលមានបំណងចង់ធ្វើបាបជនស្លូតត្រង់។
ដំណើរការភាសាធម្មជាតិ (NLP) សំដៅលើដំណើរការនៃការអនុញ្ញាតឱ្យកុំព្យូទ័រយល់ និងប្រាស្រ័យទាក់ទងជាមួយយើងជាភាសាមនុស្សតាមរយៈការរៀនម៉ាស៊ីន ហើយវាបណ្តាលឱ្យមានការទម្លាយនូវបច្ចេកវិទ្យាបកប្រែ ក៏ដូចជាឧបករណ៍ដែលគ្រប់គ្រងដោយសំឡេងដែលយើងប្រើប្រាស់កាន់តែច្រើនឡើងជារៀងរាល់ថ្ងៃ ដូចជា Alexa, Google dot, Siri, និងជំនួយការ Google ។
ដោយគ្មានសំណួរទេ ការរៀនម៉ាស៊ីនកំពុងបង្ហាញថាវាជាបច្ចេកវិទ្យាបំប្លែង។
មនុស្សយន្តដែលមានសមត្ថភាពធ្វើការជាមួយយើង និងបង្កើនភាពដើម និងការស្រមើលស្រមៃរបស់យើងជាមួយនឹងតក្កវិជ្ជាគ្មានកំហុស និងល្បឿនដ៏អស្ចារ្យរបស់ពួកគេ មិនមែនជារឿងប្រឌិតបែបវិទ្យាសាស្ត្រទៀតទេ ពួកវាកំពុងក្លាយជាការពិតនៅក្នុងវិស័យជាច្រើន។
ករណីប្រើប្រាស់ Machine Learning
1. សុវត្ថភាពអ៊ិនធឺណែត
ដោយសារបណ្តាញកាន់តែមានភាពស្មុគស្មាញ អ្នកឯកទេសសុវត្ថិភាពតាមអ៊ីនធឺណិតបានធ្វើការដោយមិននឿយហត់ដើម្បីសម្របខ្លួនទៅនឹងជួរនៃការគំរាមកំហែងផ្នែកសុវត្ថិភាពដែលចេះតែកើនឡើង។
ការប្រឆាំងនឹងការវិវឌ្ឍន៍យ៉ាងឆាប់រហ័សនៃមេរោគ និងយុទ្ធសាស្ត្រការលួចចូលគឺមានការពិបាកគ្រប់គ្រាន់ ប៉ុន្តែការរីកសាយភាយនៃឧបករណ៍ Internet of Things (IoT) បានផ្លាស់ប្តូរជាមូលដ្ឋាននៃបរិយាកាសសុវត្ថិភាពតាមអ៊ីនធឺណិត។
ការវាយប្រហារអាចកើតឡើងគ្រប់ពេល និងនៅកន្លែងណាមួយ។
អរគុណណាស់ ក្បួនដោះស្រាយការរៀនម៉ាស៊ីនបានបើកប្រតិបត្តិការសុវត្ថិភាពតាមអ៊ីនធឺណិត ដើម្បីបន្តការវិវត្តន៍ដ៏លឿនទាំងនេះ។
ការវិភាគព្យាករណ៍ បើកការរកឃើញ និងកាត់បន្ថយការវាយប្រហារបានលឿនជាងមុន ខណៈពេលដែលការរៀនម៉ាស៊ីនអាចវិភាគសកម្មភាពរបស់អ្នកនៅក្នុងបណ្តាញ ដើម្បីរកមើលភាពមិនប្រក្រតី និងភាពទន់ខ្សោយនៅក្នុងយន្តការសុវត្ថិភាពដែលមានស្រាប់។
2. ស្វ័យប្រវត្តិកម្មនៃសេវាកម្មអតិថិជន
ការគ្រប់គ្រងការកើនឡើងនៃចំនួនទំនាក់ទំនងអតិថិជនតាមអ៊ីនធឺណិតបានធ្វើឱ្យស្ថាប័នមានភាពតានតឹងច្រើន។
ពួកគេគ្រាន់តែមិនមានបុគ្គលិកសេវាអតិថិជនគ្រប់គ្រាន់ដើម្បីដោះស្រាយបរិមាណនៃការសាកសួរដែលពួកគេកំពុងទទួលបាន ហើយវិធីសាស្រ្តបែបប្រពៃណីនៃបញ្ហាប្រភពខាងក្រៅទៅកាន់ មជ្ឈមណ្ឌលទំនាក់ទំនង គឺមិនអាចទទួលយកបានសម្រាប់អតិថិជនជាច្រើននាពេលបច្ចុប្បន្ននេះ។
Chatbots និងប្រព័ន្ធស្វ័យប្រវត្តិផ្សេងទៀតឥឡូវនេះអាចដោះស្រាយតម្រូវការទាំងនេះបាន ដោយសារភាពជឿនលឿននៃបច្ចេកទេសរៀនម៉ាស៊ីន។ ក្រុមហ៊ុននានាអាចបង្កើនបុគ្គលិកឱ្យទទួលការគាំទ្រអតិថិជនកម្រិតខ្ពស់បន្ថែមទៀត ដោយធ្វើស្វ័យប្រវត្តិកម្មសកម្មភាពមនុស្ស និងអាទិភាពទាប។
នៅពេលប្រើបានត្រឹមត្រូវ ការរៀនម៉ាស៊ីននៅក្នុងអាជីវកម្មអាចជួយសម្រួលដល់ការដោះស្រាយបញ្ហា និងផ្តល់ឱ្យអ្នកប្រើប្រាស់នូវប្រភេទនៃការគាំទ្រដ៏មានប្រយោជន៍ដែលបំប្លែងពួកគេឱ្យក្លាយជាម្ចាស់ជើងឯកម៉ាកយីហោដែលមានការប្តេជ្ញាចិត្ត។
3 ។ ការទំនាក់ទំនង
ការជៀសវាងកំហុសឆ្គង និងការយល់ខុសគឺមានសារៈសំខាន់ក្នុងការទំនាក់ទំនងគ្រប់ប្រភេទ ប៉ុន្តែមានច្រើនជាងនេះទៅទៀតនៅក្នុងការទំនាក់ទំនងអាជីវកម្មនាពេលបច្ចុប្បន្ននេះ។
កំហុសវេយ្យាករណ៍សាមញ្ញ សម្លេងមិនត្រឹមត្រូវ ឬការបកប្រែខុសអាចបណ្តាលឱ្យមានការលំបាកជាច្រើនក្នុងទំនាក់ទំនងអ៊ីមែល ការវាយតម្លៃអតិថិជន។ ការធ្វើសន្និសីទវីដេអូឬឯកសារផ្អែកលើអត្ថបទក្នុងទម្រង់ជាច្រើន។
ប្រព័ន្ធរៀនម៉ាស៊ីនមានទំនាក់ទំនងកម្រិតខ្ពស់លើសពីថ្ងៃដ៏មមាញឹករបស់ Clippy របស់ Microsoft ។
ឧទាហរណ៍នៃការរៀនតាមម៉ាស៊ីនទាំងនេះបានជួយបុគ្គលម្នាក់ៗក្នុងការប្រាស្រ័យទាក់ទងគ្នាយ៉ាងសាមញ្ញ និងច្បាស់លាស់ដោយប្រើដំណើរការភាសាធម្មជាតិ ការបកប្រែភាសាតាមពេលវេលាជាក់ស្តែង និងការទទួលស្គាល់ការនិយាយ។
ខណៈពេលដែលបុគ្គលជាច្រើនមិនចូលចិត្តសមត្ថភាពកែដោយស្វ័យប្រវត្តិ ពួកគេក៏ផ្តល់តម្លៃផងដែរក្នុងការការពារពីកំហុសដែលគួរឱ្យអាម៉ាស់ និងសម្លេងមិនត្រឹមត្រូវ។
4. ការទទួលស្គាល់វត្ថុ
ខណៈពេលដែលបច្ចេកវិទ្យាក្នុងការប្រមូល និងបកស្រាយទិន្នន័យបានកើតមានមួយរយៈមកហើយ ការបង្រៀនប្រព័ន្ធកុំព្យូទ័រឱ្យយល់ពីអ្វីដែលពួកគេកំពុងសម្លឹងមើល បានបង្ហាញថាជាកិច្ចការពិបាកបោកបញ្ឆោត។
សមត្ថភាពសម្គាល់វត្ថុកំពុងត្រូវបានបន្ថែមទៅក្នុងការកើនឡើងនៃឧបករណ៍ដោយសារតែកម្មវិធីរៀនម៉ាស៊ីន។
ជាឧទាហរណ៍ ឡានដែលបើកបរដោយខ្លួនឯង ស្គាល់ឡានមួយទៀត នៅពេលវាឃើញឡានមួយ ទោះបីជាអ្នកសរសេរកម្មវិធីមិនបានផ្តល់ឧទាហរណ៍ពិតប្រាកដនៃឡាននោះដើម្បីប្រើជាឯកសារយោងក៏ដោយ។
ឥឡូវនេះបច្ចេកវិទ្យានេះកំពុងត្រូវបានប្រើប្រាស់នៅក្នុងអាជីវកម្មលក់រាយដើម្បីជួយបង្កើនល្បឿនដំណើរការទូទាត់ប្រាក់។ កាមេរ៉ាកំណត់អត្តសញ្ញាណផលិតផលនៅក្នុងរទេះរបស់អ្នកប្រើប្រាស់ ហើយអាចចេញវិក្កយបត្រគណនីរបស់ពួកគេដោយស្វ័យប្រវត្តិនៅពេលពួកគេចាកចេញពីហាង។
5. ទីផ្សារឌីជីថល
ទីផ្សារសព្វថ្ងៃនេះភាគច្រើនត្រូវបានធ្វើតាមអ៊ីនធឺណិត ដោយប្រើវេទិកាឌីជីថល និងកម្មវិធីកម្មវិធីជាច្រើន។
នៅពេលដែលអាជីវកម្មប្រមូលព័ត៌មានអំពីអ្នកប្រើប្រាស់របស់ពួកគេ និងអាកប្បកិរិយានៃការទិញរបស់ពួកគេ ក្រុមទីផ្សារអាចប្រើប្រាស់ព័ត៌មាននោះដើម្បីបង្កើតរូបភាពលម្អិតនៃទស្សនិកជនគោលដៅរបស់ពួកគេ និងស្វែងរកថាតើមនុស្សណាដែលមានទំនោរក្នុងការស្វែងរកផលិតផល និងសេវាកម្មរបស់ពួកគេ។
ក្បួនដោះស្រាយការរៀនម៉ាស៊ីនជួយអ្នកទីផ្សារក្នុងការយល់អំពីទិន្នន័យទាំងអស់នោះ ដោយស្វែងរកគំរូ និងគុណលក្ខណៈសំខាន់ៗដែលអនុញ្ញាតឱ្យពួកគេចាត់ថ្នាក់លទ្ធភាពយ៉ាងតឹងរ៉ឹង។
បច្ចេកវិទ្យាដូចគ្នានេះអនុញ្ញាតឱ្យមានស្វ័យប្រវត្តិកម្មទីផ្សារឌីជីថលដ៏ធំ។ ប្រព័ន្ធផ្សាយពាណិជ្ជកម្មអាចត្រូវបានបង្កើតឡើងដើម្បីស្វែងរកអតិថិជនអនាគតថ្មីប្រកបដោយថាមពល និងផ្តល់នូវមាតិកាទីផ្សារដែលពាក់ព័ន្ធដល់ពួកគេតាមពេលវេលា និងទីកន្លែងត្រឹមត្រូវ។
អនាគតនៃការរៀនម៉ាស៊ីន
ការរៀនម៉ាស៊ីនពិតជាកំពុងទទួលបានប្រជាប្រិយភាព ដោយសារតែអាជីវកម្មកាន់តែច្រើន និងស្ថាប័នធំៗប្រើប្រាស់បច្ចេកវិទ្យាដើម្បីដោះស្រាយបញ្ហាប្រឈមជាក់លាក់ ឬការបង្កើតថ្មីប្រកបដោយថាមពល។
ការវិនិយោគបន្តនេះបង្ហាញពីការយល់ដឹងថាការរៀនម៉ាស៊ីនកំពុងផលិត ROI ជាពិសេសតាមរយៈករណីប្រើប្រាស់ដែលបានបង្កើតឡើង និងផលិតឡើងវិញដែលបានរៀបរាប់ខាងលើមួយចំនួន។
យ៉ាងណាមិញ ប្រសិនបើបច្ចេកវិទ្យាល្អគ្រប់គ្រាន់សម្រាប់ Netflix, Facebook, Amazon, Google Maps ជាដើមនោះ ឱកាសដែលវាអាចជួយក្រុមហ៊ុនរបស់អ្នកប្រើប្រាស់ទិន្នន័យបានច្រើនបំផុតផងដែរ។
ដូចថ្មី ការរៀនម៉ាស៊ីន ម៉ូដែលត្រូវបានបង្កើត និងដាក់ឱ្យដំណើរការ យើងនឹងឃើញការកើនឡើងនៃចំនួនកម្មវិធីដែលនឹងត្រូវបានប្រើនៅទូទាំងឧស្សាហកម្ម។
រឿងនេះកំពុងកើតឡើងរួចហើយជាមួយ ការទទួលស្គាល់មុខដែលពីមុនជាមុខងារថ្មីនៅលើ iPhone របស់អ្នក ប៉ុន្តែឥឡូវនេះកំពុងត្រូវបានអនុវត្តនៅក្នុងកម្មវិធី និងកម្មវិធីជាច្រើន ជាពិសេសកម្មវិធីដែលទាក់ទងនឹងសន្តិសុខសាធារណៈ។
គន្លឹះសម្រាប់ស្ថាប័នភាគច្រើនដែលព្យាយាមចាប់ផ្តើមជាមួយការរៀនម៉ាស៊ីនគឺដើម្បីមើលរំលងចក្ខុវិស័យអនាគតដ៏ភ្លឺស្វាង និងស្វែងរកបញ្ហាប្រឈមមុខជំនួញពិតប្រាកដដែលបច្ចេកវិទ្យាអាចជួយអ្នកបាន។
សន្និដ្ឋាន
នៅក្នុងយុគសម័យក្រោយឧស្សាហ៍កម្ម អ្នកវិទ្យាសាស្ត្រ និងអ្នកជំនាញបាននឹងកំពុងព្យាយាមបង្កើតកុំព្យូទ័រដែលមានឥរិយាបទដូចមនុស្ស។
ម៉ាស៊ីនគិតគឺជាការរួមចំណែកដ៏សំខាន់បំផុតរបស់ AI ចំពោះមនុស្សជាតិ។ ការមកដល់ដ៏អស្ចារ្យនៃម៉ាស៊ីនផលិតដោយខ្លួនឯងនេះបានផ្លាស់ប្តូរយ៉ាងឆាប់រហ័សនូវបទប្បញ្ញត្តិប្រតិបត្តិការសាជីវកម្ម។
យានជំនិះដែលបើកបរដោយខ្លួនឯង ជំនួយការស្វ័យប្រវត្តិ បុគ្គលិកផលិតកម្មស្វយ័ត និងទីក្រុងឆ្លាតវៃបានបង្ហាញឱ្យឃើញនាពេលថ្មីៗនេះអំពីលទ្ធភាពជោគជ័យនៃម៉ាស៊ីនឆ្លាតវៃ។ បដិវត្តនៃការរៀនម៉ាស៊ីន និងអនាគតនៃការរៀនម៉ាស៊ីននឹងនៅជាមួយយើងរយៈពេលយូរ។





សូមផ្ដល់យោបល់