საწარმოებისთვის მონაცემთა ანალიტიკისა და მონაცემთა მართვის მზარდი მნიშვნელობის გამო, მონაცემთა პლატფორმების Snowflake და Databricks შედარება აუცილებელია დღევანდელი ბაზრისთვის.
ორგანიზაციებს სჭირდებათ მექანიზმი, რათა შეაგროვონ ყველა ის მონაცემი, რომელიც მათ უნდა შეაფასონ ერთ ადგილას, სადაც ის მზად იქნება მონაცემთა მოპოვებისთვის, რადგან შესასწავლი მონაცემების რაოდენობა თანდათან იზრდება.
ეჭვგარეშეა, ცნობილი ღრუბელზე დაფუძნებული მონაცემთა სისტემები Snowflake და Databricks ორივე ინდუსტრიის ლიდერები არიან. თუმცა, რომელი მონაცემთა პლატფორმაა იდეალური თქვენი კომპანიისთვის?
რაოდენობა, სიჩქარე და ხარისხი, რასაც ბიზნეს დაზვერვის აპლიკაციები მოითხოვს, ყველა მოწოდებულია Snowflake-ისა და Databricks-ის მიერ.
მიუხედავად იმისა, რომ არსებობს განსხვავებები, ასევე არის უამრავი პარალელი. მათ აქვთ მკაფიო ორიენტაცია, რაც აშკარაა ყურადღებით შემოწმებისას.
Apache Spark-ის დამფუძნებლებმა დააარსეს საწარმოს პროგრამული ბიზნესი Databricks.
იგი ცნობილია მონაცემთა ტბების უდიდესი ასპექტების შერწყმით და მონაცემთა საწყობები ტბის არქიტექტურაში.
მონაცემთა შენახვის ბიზნესი Snowflake გთავაზობთ ღრუბელზე დაფუძნებულ შენახვას და წვდომის სერვისებს მინიმალური სირთულეებით. ის ადგენს თავის პოზიციას, როგორც გადაწყვეტას, რომელიც გთავაზობთ უსაფრთხო წვდომას თქვენს მონაცემებზე, ხოლო თითქმის მცირე მოვლას მოითხოვს.
ეს სტატია გთავაზობთ დეტალურ შედარებას ფიფქის წინააღმდეგ. აკრიფებს და განმარტავს თითოეული პროდუქტის სარგებელს, ასე რომ თქვენ შეგიძლიათ გადაწყვიტოთ რომელია საუკეთესო თქვენი ბიზნესისთვის. დავიწყოთ მათი გაცნობით.
რა არის ფიფქია?
Snowflake არის სრულად მართული სერვისი, რომელიც მომხმარებელს სთავაზობს თანმხლები დატვირთვების თითქმის უსაზღვრო მასშტაბურობას მონაცემთა მარტივი ინტეგრაციის, ჩატვირთვის, ანალიზისა და გაზიარებისთვის.
მონაცემთა ტბები, მონაცემთა ინჟინერია, მონაცემთა აპლიკაციების განვითარება, მონაცემთა მეცნიერება და გაზიარებული მონაცემების უსაფრთხო მოხმარება მისი ტიპიური გამოყენებაა.

გამოთვლა და შენახვა ბუნებრივად გამოყოფილია ფიფქის გამორჩეული დიზაინით.
ამ არქიტექტურის დახმარებით თქვენ შეგიძლიათ პრაქტიკულად უზრუნველყოთ თქვენი ყველა მომხმარებლის და მონაცემთა დატვირთვის წვდომა თქვენი მონაცემების ერთ ასლზე, ყოველგვარი უარყოფითი ეფექტის გარეშე.
მომხმარებლის თანმიმდევრული გამოცდილებისთვის, ფიფქია საშუალებას გაძლევთ შეასრულოთ თქვენი მონაცემთა გადაწყვეტა უხილავად სხვადასხვა ლოკაციებსა და ღრუბლებში.
ღრუბლოვანი ინფრასტრუქტურის სირთულის მოხსნით, ფიფქია მას შესაძლებელს ხდის.
Snowflake Data Marketplace, რომელიც გთავაზობთ მრავალ ვარიანტს Snowflake-ის ათასობით მომხმარებელთან ურთიერთობისთვის, ასევე გაძლევთ საშუალებას მიიღოთ წვდომა გაზიარებულ მონაცემთა ნაკრებებსა და მონაცემთა სერვისებზე.
მისი მახასიათებლებია;
- უფრო ეფექტური მონაცემების საფუძველზე გადაწყვეტილების მიღება: Snowflake-ით შეგიძლიათ ამოშალოთ მონაცემთა სილოსები და უზრუნველყოთ ყველა ბიზნესში წვდომა სასარგებლო ინფორმაციაზე. ეს არის გადამწყვეტი საწყისი ნაბიჯი პარტნიორული ურთიერთობების გასაძლიერებლად, ფასების ოპტიმიზაციისთვის, ოპერაციებთან დაკავშირებული ხარჯების შემცირებაში, გაყიდვების ეფექტურობის გაზრდისა და მრავალი სხვა რამისთვის.
- გააუმჯობესეთ ანალიტიკის სიჩქარე და ხარისხი: შეგიძლიათ გააძლიეროთ თქვენი ანალიტიკური მილსადენი Snowflake-ით, ღამის სერიული დატვირთვებიდან რეალურ დროში მონაცემთა ნაკადებზე გადასვლით. თქვენს ბიზნესში ყველას უსაფრთხო, თანმხლები და კონტროლირებადი წვდომით თქვენს მონაცემთა საწყობში, შეგიძლიათ გააუმჯობესოთ ანალიტიკის ხარისხი სამსახურში. ეს ამცირებს ხარჯებს და ხელით შრომას, რაც ფირმებს საშუალებას აძლევს ოპტიმალურად გაანაწილონ რესურსები შემოსავლის მაქსიმალურად გაზრდის მიზნით.
- მონაცემთა გაცვლა პერსონალიზაციასთან ერთად: თქვენ შეგიძლიათ შექმნათ თქვენი საკუთარი მონაცემთა გაცვლა Snowflake-თან, რაც საშუალებას მოგცემთ გადაიტანოთ ცოცხალი, რეგულირებული მონაცემები უსაფრთხო გზით. გარდა ამისა, ის ემსახურება როგორც მოტივაციას უფრო ძლიერი მონაცემთა კავშირების განსავითარებლად პარტნიორებთან, კლიენტებთან და სხვა ბიზნეს ერთეულებთან. ის ამას აღწევს თქვენი მომხმარებლის 360 გრადუსიანი პერსპექტივის მიღებით, რომელიც გთავაზობთ ინფორმაციას მომხმარებლის მნიშვნელოვანი მახასიათებლების შესახებ, მათ შორის ინტერესები, პროფესია და მრავალი სხვა.
- უფრო დიდი პროდუქტი და მომხმარებლის გამოცდილება: თქვენ შეგიძლიათ უკეთ გაიგოთ მომხმარებლის ქცევა და პროდუქტის გამოყენება ფიფქის ადგილზე. გარდა ამისა, თქვენ შეგიძლიათ გამოიყენოთ მთელი მონაცემთა ნაკრები მომხმარებლების დასაკმაყოფილებლად, მნიშვნელოვნად გაზარდოთ თქვენი პროდუქტის ხაზი და ხელი შეუწყოთ მონაცემთა მეცნიერების ინოვაციას.
- ძლიერი უსაფრთხოება: შესაბამისობისა და კიბერუსაფრთხოების ყველა მონაცემი შეიძლება იყოს ცენტრალიზებული უსაფრთხო მონაცემთა ტბაში. ინციდენტის სწრაფი რეაქცია გარანტირებულია ფიფქის მონაცემების ტბებით. დიდი რაოდენობით ჟურნალის მონაცემების ერთ ადგილას გაერთიანება და წლების ჟურნალის მონაცემების სწრაფი შეფასება, საშუალებას გაძლევთ მიიღოთ სრული სურათი მოვლენის შესახებ. ნახევრად სტრუქტურირებული ჟურნალები და სტრუქტურირებული საწარმოს მონაცემები ახლა შეიძლება გაერთიანდეს ერთ მონაცემთა ტბაში. ყოველგვარი ინდექსირების გარეშე, Snowflake საშუალებას გაძლევთ შეაღწიოთ კარში და ამავდროულად გაადვილოთ მონაცემების რედაქტირება და შეცვლა მისი იმპორტის შემდეგ.
რა არის მონაცემთა ბაზები?
Databricks არის ღრუბელზე დაფუძნებული მონაცემთა პლატფორმა, რომელსაც მართავს Apache Spark. ის ძირითადად ყურადღებას ამახვილებს დიდი მონაცემების ანალიტიკაზე და თანამშრომლობაზე.
თქვენ შეგიძლიათ უზრუნველყოთ მონაცემთა მეცნიერების სრული სამუშაო ადგილი ბიზნესის ანალიტიკოსები, მონაცემთა მეცნიერები და მონაცემთა ინჟინრები ურთიერთქმედებენ Databricks' Machine Learning Runtime-ის, კონტროლირებადი ML Flow-ისა და ერთობლივი ნოუთბუქების გამოყენებით.

Dataframes და Spark SQL ბიბლიოთეკები, რომლებიც საშუალებას გაძლევთ გაუმკლავდეთ სტრუქტურირებულ მონაცემებს, განთავსებულია Databricks-ში.
გარდა იმისა, რომ დაგეხმარებათ შექმნათ ხელოვნური ინტელექტი გადაწყვეტილებები, Databricks აადვილებს დასკვნების გამოტანას თქვენი ამჟამინდელი მონაცემებიდან.
გარდა ამისა, Databricks გთავაზობთ მრავალფეროვან ბიბლიოთეკებს მანქანა სწავლის, მათ შორის Tensorflow, Pytorch და სხვები, მანქანური სწავლების მოდელების მშენებლობისა და ტრენინგისთვის.
ბიზნეს კლიენტების ფართო სპექტრი იყენებს Databricks-ს, რათა განახორციელოს მასიური წარმოების პროცესები გამოყენების უზარმაზარ საქმეებსა და სექტორებში, მათ შორის ჯანდაცვა, მედია და გართობა, ფინანსური მომსახურება, საცალო ვაჭრობა და მრავალი სხვა.
მისი მახასიათებლებია;
- დელტას ტბა: Databricks-ს აქვს ტრანზაქციული შენახვის ფენა, რომელიც ღია წყაროა და შექმნილია მონაცემთა მთელი სასიცოცხლო ციკლის განმავლობაში გამოსაყენებლად. ეს ფენა შეიძლება გამოყენებულ იქნას მონაცემთა მასშტაბურობისა და სანდოობის უზრუნველსაყოფად თქვენი ამჟამინდელი მონაცემთა ტბისთვის.
- ინტერაქტიული ნოუთბუქები: თქვენ შეგიძლიათ სწრაფად შეხვიდეთ თქვენს მონაცემებზე, გააანალიზოთ ისინი, ააწყოთ მოდელები სხვებთან და გაუზიაროთ ახალი, სასარგებლო შეხედულებები, როდესაც გაქვთ სწორი ინსტრუმენტები და ენა. Scala, R, SQL და Python მხოლოდ რამდენიმე ენაა, რომლებსაც მხარს უჭერს Databricks.
- მანქანა სწავლის: უახლესი ჩარჩოების დახმარებით, როგორიცაა Tensorflow, Scikit-Learn და Pytorch, Databricks გაძლევთ ერთი დაწკაპუნებით წვდომას წინასწარ კონფიგურირებულ მანქანათმცოდნეობის გარემოზე. თქვენ შეგიძლიათ გააზიაროთ და დააკვირდეთ ექსპერიმენტებს, მართოთ მოდელები ერთად და გაიმეოროთ გაშვებები ერთი ცენტრალური საცავიდან.
- გაძლიერებული ნაპერწკლის ძრავა: შეგიძლიათ მიიღოთ Apache Spark-ის უახლესი ვერსიები Databricks-ის გამოყენებით. სხვადასხვა ღია წყაროს ბიბლიოთეკები ასევე შეიძლება შეუფერხებლად იყოს ინტეგრირებული Databricks-თან. თქვენ შეგიძლიათ სწრაფად დააყენოთ კლასტერები და შექმნათ სრულად მართული Apache Spark გარემო, თუ გაქვთ წვდომა Cloud სერვისის რამდენიმე პროვაიდერის ხელმისაწვდომობაზე და მასშტაბურობაზე. კლასტერების კონფიგურაცია, დაყენება და დაზუსტება Databricks-ით შესაძლებელია მუდმივი მონიტორინგის გარეშე ოპტიმალური მუშაობისა და საიმედოობის შესანარჩუნებლად.
ძირითადი განსხვავებები Snowflake-სა და Databricks-ს შორის
არქიტექტურა
Snowflake არის ANSI SQL-ზე დაფუძნებული სერვერის სისტემა, სრულიად განსხვავებული შენახვისა და დამუშავების ფენების გამოთვლით.
თითოეული ვირტუალური საწყობი (ანუ გამოთვლითი კლასტერი) Snowflake-ში ინახავს მონაცემთა მთლიანი ნაკრების ქვეჯგუფს ლოკალურად, ხოლო მასიურად პარალელური დამუშავების (MPP) გამოყენებით შეკითხვის შესასრულებლად.
მონაცემთა შიდა ორგანიზებისა და ოპტიმიზაციისთვის შეკუმშულ სვეტურ ფორმატში, რომელიც შეიძლება შეინახოს ღრუბელში, Snowflake იყენებს მიკრო დანაყოფებს.
ის ფაქტი, რომ Snowflake ინარჩუნებს მონაცემთა მართვის ყველა ასპექტს, მათ შორის ფაილის ზომას, შეკუმშვას, სტრუქტურას, მეტამონაცემებს, სტატისტიკას და სხვა მონაცემთა ერთეულებს, რომლებიც არ არის დაუყოვნებლივ ხილული მომხმარებლებისთვის და მათი წვდომა მხოლოდ SQL მოთხოვნების საშუალებით არის შესაძლებელი. ავტომატურად.
ვირტუალური საწყობები, რომლებიც წარმოადგენს გამოთვლილ კლასტერებს, რომლებიც შედგება მრავალი MPP კვანძისგან, გამოიყენება Snowflake-ში ყველა დამუშავების შესასრულებლად.
Snowflake და Databricks ორივე SaaS გადაწყვეტაა, თუმცა Databricks-ის არქიტექტურა ძალიან განსხვავებულია, რადგან ის აგებულია Spark-ზე.
მრავალენოვანი ძრავა სახელწოდებით Spark შეიძლება დამონტაჟდეს ღრუბელში და დაფუძნებულია ცალკეულ კვანძებზე ან კლასტერებზე. Databricks ამჟამად იყენებს AWS, GCP და Azure, ისევე როგორც ფიფქია.
საკონტროლო სიბრტყე და მონაცემთა სიბრტყე ქმნიან მის სტრუქტურას. ყველა დამუშავებული მონაცემი შეიცავს მონაცემთა სიბრტყეში, ხოლო ყველა backend სერვისი, რომელსაც მართავს Databricks Serverless Computing, გვხვდება საკონტროლო სიბრტყეში.
სერვერის გარეშე გამოთვლა საშუალებას აძლევს ადმინისტრატორებს შექმნან სერვერის გარეშე SQL ბოლო წერტილები, რომლებიც სრულად იმართება Databricks-ის მიერ და გთავაზობთ მყისიერ გამოთვლას.
მიუხედავად იმისა, რომ სხვა Databricks-ის გამოთვლების უმეტესობის გამოთვლითი რესურსები გაზიარებულია ღრუბლოვან ანგარიშში ან ტრადიციულ მონაცემთა სიბრტყეში, ეს რესურსები გაზიარებულია სერვერის მონაცემთა სიბრტყეში.
Databricks-ის არქიტექტურა შედგება რამდენიმე მნიშვნელოვანი ნაწილისგან:
- დათაბრიქსი დელტა ტბა
- Databricks Delta Engine
- MLFlow
Მონაცემთა სტრუქტურა
ორივე ნახევრად სტრუქტურირებული და სტრუქტურირებული ფაილების შენახვა და ატვირთვა შესაძლებელია Snowflake-ის გამოყენებით ETL ხელსაწყოს საჭიროების გარეშე, რათა პირველად მოაწყოს მონაცემები EDW-ში იმპორტამდე.
Snowflake მყისიერად გარდაქმნის მონაცემებს საკუთარ შიდა, ორგანიზებულ ფორმატში, როდესაც მონაცემები წარდგენილია. მონაცემთა ტბისგან განსხვავებით, ფიფქიას არ სჭირდება თქვენი არასტრუქტურირებული მონაცემების სტრუქტურის მიწოდება, სანამ შეძლებთ მათ ჩატვირთვას და ურთიერთქმედებას.
მონაცემთა ტიპები შეიძლება გამოყენებულ იქნას Databricks-თან თავდაპირველ ფორმატში. თქვენი არასტრუქტურირებული მონაცემთა სტრუქტურის მისაცემად ისე, რომ მისი გამოყენება შესაძლებელი იყოს სხვა ინსტრუმენტებით, როგორიცაა Snowflake, შეგიძლიათ გამოიყენოთ Databricks, როგორც ETL ინსტრუმენტი..
Databricks-სა და Snowflake-ს შორის დებატებში Databricks ჭარბობს ფიფქზე მონაცემთა სტრუქტურის თვალსაზრისით.
მონაცემთა საკუთრება
გადამამუშავებელი და შესანახი ფენები გამოყოფილია Snowflake-ში, რაც მათ ღრუბელზე დამოუკიდებლად ზრდის საშუალებას აძლევს. ეს მიუთითებს იმაზე, რომ მათ შეუძლიათ დამოუკიდებლად მასშტაბირება Cloud-ში თქვენი მოთხოვნებიდან გამომდინარე.
ამით თქვენი ფინანსები ისარგებლებს. გარდა ამისა, ორივე ფენის საკუთრება შენარჩუნებულია. Snowflake უზრუნველყოფს წვდომას მონაცემებსა და მანქანის რესურსებზე როლებზე დაფუძნებული წვდომის კონტროლის (RBAC) ტექნიკის გამოყენებით.
Databricks-ის მონაცემთა დამუშავებისა და შენახვის ფენები მთლიანად განცალკევებულია, განსხვავებით Snowflake-ის გამოყოფილი ფენებისგან.
მომხმარებლებს შეუძლიათ თავიანთი მონაცემების განთავსება ნებისმიერ ფორმატში, და Databricks ეფექტურად გაუმკლავდება მას, რადგან მისი მთავარი მიზანი მონაცემთა გამოყენებაა.
Databricks აშკარად გამარჯვებულია Databricks-სა და Snowflake-ს შორის დებატებში, რადგან თქვენ შეგიძლიათ უბრალოდ გამოიყენოთ იგი მონაცემთა დასამუშავებლად.
მონაცემთა დაცვა
დროში მოგზაურობა და წარუმატებელი უსაფრთხოება ფიფქის ორი განსაკუთრებული მახასიათებელია. დროში მოგზაურობის ფუნქცია ფიფქია ინახავს მონაცემებს მდგომარეობამდე განახლებამდე.
მიუხედავად იმისა, რომ Enterprise კლიენტებს შეუძლიათ აირჩიონ დროის დიაპაზონი 90 დღემდე, დროში მოგზაურობა ხშირად შემოიფარგლება ერთი დღით. მონაცემთა ბაზებს, სქემებსა და ცხრილებს შეუძლიათ გამოიყენონ ეს შესაძლებლობა.
როდესაც დროში მოგზაურობის შენახვის ვადა ამოიწურება, იწყება 7-დღიანი წარუმატებლობისთვის უსაფრთხო პერიოდი, რომელიც შექმნილია წინა მონაცემების დასაცავად და აღდგენისთვის.
Databricks Snowflake-ის დროში მოგზაურობის ფუნქციის მსგავსად, Delta Lake-ის ფუნქციაც მუშაობს. დელტა ტბაში შენახული მონაცემები ავტომატურად ვერსიდება, რაც მომხმარებლებს საშუალებას აძლევს მოიძიონ ადრინდელი მონაცემების ვერსიები მომავალი გამოყენებისთვის.
Databricks მუშაობს Spark-ზე და ვინაიდან Spark აგებულია ობიექტის დონის საცავზე, Databricks ნამდვილად არასოდეს ინახავს რაიმე მონაცემს.
ეს არის მისი ერთ-ერთი მთავარი უპირატესობა. ეს ასევე გულისხმობს, რომ Databricks შეიძლება გაუმკლავდეს გამოყენების შემთხვევებს შიდა სისტემებისთვის.
უსაფრთხოება
ყველა მონაცემი ავტომატურად დაშიფრულია Snowflake-ში დასვენების დროს.
ყველა კომუნიკაცია საკონტროლო სიბრტყესა და მონაცემთა სიბრტყეს შორის ხდება ღრუბლოვანი პროვაიდერის კერძო ქსელში და Databricks-ში შენახული ყველა მონაცემი დაცულია.
ორივე ვარიანტი გთავაზობთ RBAC (როლზე დაფუძნებული წვდომის კონტროლი). Snowflake და Databricks იცავენ რამდენიმე კანონსა და სერთიფიკატს, მათ შორის SOC 2 Type II, ISO 27001, HIPAA და GDPR.
თუმცა, რადგან Databricks მუშაობს ობიექტის დონის საცავზე, როგორიცაა AWS S3, Azure Blob Storage, Google Cloud შენახვა და ა.შ., მას აკლია შესანახი ფენა ფიფქისგან განსხვავებით.
Performance
შესრულების თვალსაზრისით, Snowflake და Databricks ისეთი რადიკალურად განსხვავებული გადაწყვეტილებებია, რომ მათი შედარება საკმაოდ რთულია.
შესაძლებელია თითოეული ნიშნულის შეცვლა ოდნავ განსხვავებული ზღაპრის წარმოსადგენად. ამის შესანიშნავი მაგალითია ბოლო კვლევების ჩატარებული Databricks-ის მიერ TPC-DS ბენჩმარკის შესახებ.
თავდაპირველი შედარების თვალსაზრისით, Snowflake და Databricks მხარს უჭერენ ოდნავ განსხვავებულ გამოყენებას და არც ერთი არ არის არსებითად აღმატებული მეორეზე.
თუმცა, ფიფქია შეიძლება იყოს სასურველი ვარიანტი ინტერაქტიული მოთხოვნებისთვის, რადგან ის ოპტიმიზირებს ყველა მეხსიერებას მონაცემების წვდომისთვის გადაყლაპვის მომენტში.
გამოყენების შემთხვევაში
BI და SQL გამოყენების შემთხვევები კარგად არის მხარდაჭერილი Databricks და Snowflake მიერ.
Snowflake გთავაზობთ JDBC და ODBC დრაივერებს, რომელთა ინტეგრირება მარტივია სხვა პროგრამულ უზრუნველყოფასთან.
იმის გათვალისწინებით, რომ კლიენტებს არ უწევთ პროგრამის ადმინისტრირება, ის ძირითადად ცნობილია BI-ში გამოყენების შემთხვევებით და იმ ბიზნესებისთვის, რომლებიც ირჩევენ პირდაპირ ანალიტიკურ პლატფორმას.
Databricks-მა გამოუშვა ღია კოდის დელტა ტბა, ამასობაში სტაბილურობის დამატებით ფენას მატებს მათ მონაცემთა ტბას. მომხმარებელს შეუძლია გაგზავნოს SQL მოთხოვნები დელტა ტბაზე შესანიშნავი შესრულებით.
მათი მრავალფეროვნებისა და უმაღლესი ტექნოლოგიის გათვალისწინებით, Databricks კარგად არის ცნობილი მათი გამოყენების შემთხვევებით, რომლებიც ამცირებს გამყიდველის ჩაკეტვას, უკეთესად შეეფერება ML სამუშაო დატვირთვას და ეხმარება ტექნიკურ გიგანტებს.
ფასები
მომხმარებელს აქვს წვდომა საწარმოს დონის ოთხ ხედზე Snowflake-ით. Standard, Enterprise, Business Critical და Virtual Private Snowflake არის ოთხი ხელმისაწვდომი ვერსია. ფასის სრული ინფორმაცია ხელმისაწვდომია აქ დაწკაპუნებით.
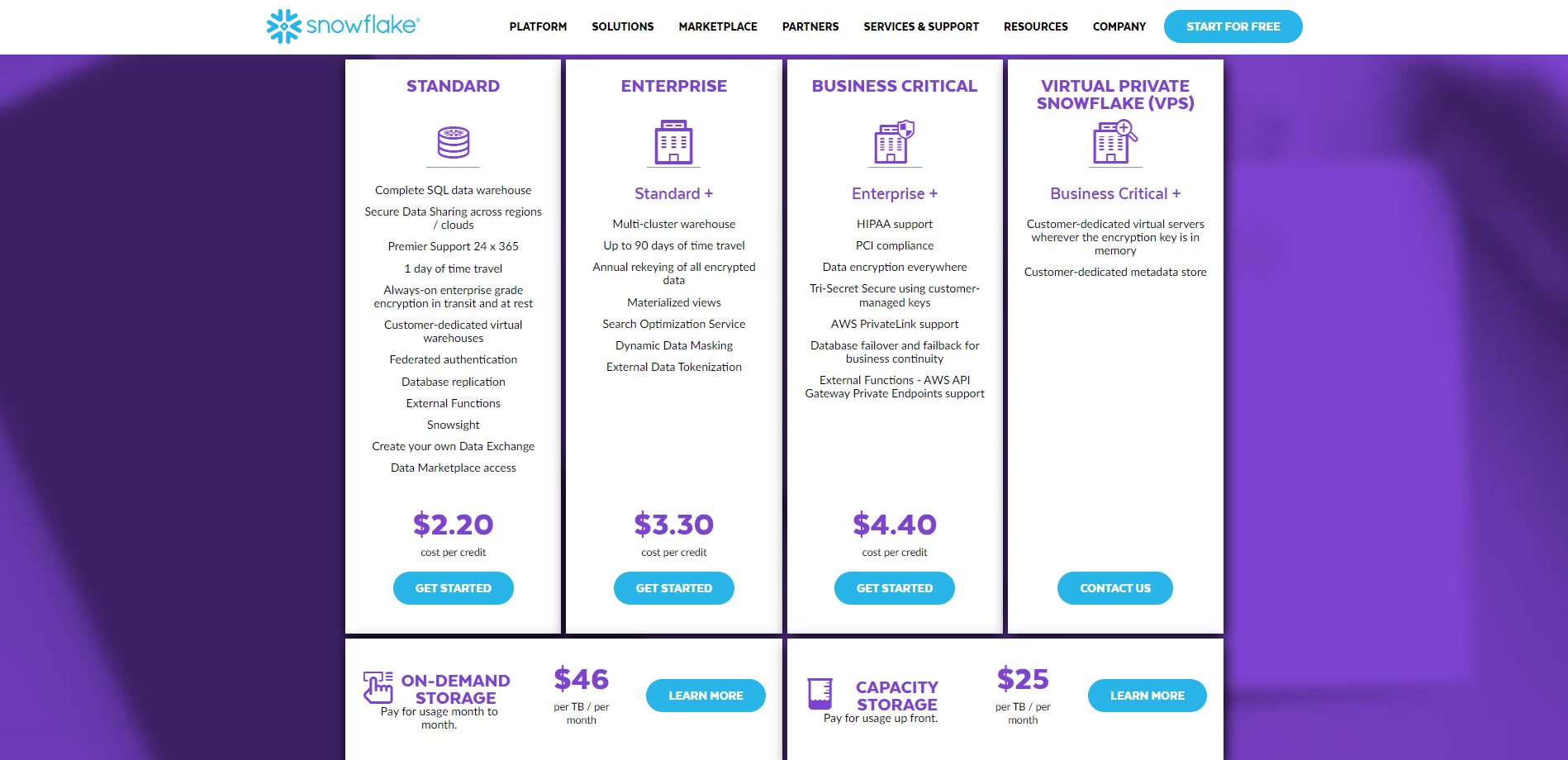
მეორეს მხრივ, Databricks-ის მიერ შემოთავაზებული სამი კომერციული ფასების დონე არის ძირითადი, პრემიუმი და საწარმო. თქვენ შეგიძლიათ ნახოთ მთელი ფასების სია აქ დაწკაპუნებით.

დასკვნა
მონაცემთა ანალიზის შესანიშნავი ინსტრუმენტებია Snowflake და Databricks.
თითოეულს აქვს დადებითი და უარყოფითი მხარეები. გამოყენების შაბლონები, მონაცემთა მოცულობა, სამუშაო დატვირთვა და მონაცემთა სტრატეგია მოქმედებს, როდესაც გადაწყვეტთ, რომელი პლატფორმაა იდეალური თქვენი ბიზნესისთვის.
ფიფქია უფრო შესაფერისია მათთვის, ვინც გამოცდილია SQL-ით და ტიპიური მონაცემთა ტრანსფორმაციისა და ანალიზისთვის.
Streaming, ML, AI და მონაცემთა მეცნიერების დატვირთვა უფრო შეეფერება Databricks-ს მისი Spark ძრავის გამო, რომელიც მხარს უჭერს მრავალი ენების გამოყენებას.
სხვა ენების დასაჭერად, ფიფქიამ შემოიღო მხარდაჭერა Python-ის, Java-სა და Scala-სთვის.
ზოგიერთი ამტკიცებს, რომ ფიფქია ამცირებს შენახვას შეყვანის დროს, ამიტომ ის უკეთესია ინტერაქტიული მოთხოვნებისთვის.
გარდა ამისა, ის შესანიშნავად აწარმოებს ანგარიშებს და დაფებს და მართავს BI სამუშაო დატვირთვას. მონაცემთა საწყობის თვალსაზრისით, ის კარგად მუშაობს.
თუმცა, ზოგიერთმა მომხმარებელმა აღნიშნა, რომ ის განიცდის მონაცემთა დიდი რაოდენობით, როგორიცაა ნაკადი აპლიკაციებში. ფიფქია იმარჯვებს პირდაპირ კონკურსში, რომელიც დაფუძნებულია მონაცემთა შენახვის უნარებზე.
თუმცა, Databricks რეალურად არ არის მონაცემთა საწყობი. მისი მონაცემთა პლატფორმა უფრო ყოვლისმომცველია და აქვს უმაღლესი ELT, მონაცემთა მეცნიერების და მანქანათმცოდნეობის შესაძლებლობები, ვიდრე Snowflake.
მომხმარებლები არ აკონტროლებენ მართული ობიექტების შენახვის ღირებულებას, სადაც ისინი ინახავენ თავიანთ მონაცემებს. მონაცემთა ტბა და მონაცემთა დამუშავება მთავარი თემაა.
თუმცა, ის სპეციალურად გამიზნულია მონაცემთა მეცნიერებისა და ძალიან გამოცდილი ანალიტიკოსებისთვის.
დასასრულს, Databricks იმარჯვებს ტექნიკური აუდიტორიისთვის. როგორც ტექნიკურად მცოდნე, ისე არატექნიკურად მცოდნე მომხმარებლებს შეუძლიათ მარტივად გამოიყენონ ფიფქია.
მონაცემთა მართვის თითქმის ყველა ფუნქცია, რომელსაც Snowflake გვთავაზობს, ხელმისაწვდომია Databricks-ის და მრავალი სხვა საშუალებით. მაგრამ მისი მუშაობა უფრო რთულია, მოიცავს სწავლის მაღალ მრუდს და საჭიროებს მეტ მოვლას.
თუმცა, მას შეუძლია გაუმკლავდეს მონაცემთა დატვირთვისა და ენების ბევრად უფრო დიდ დიაპაზონს. და ვინც იცნობს Apache Spark-ს, გადაიხრება Databricks-ისკენ.
Snowflake უფრო შეეფერება კლიენტებს, რომლებსაც სურთ სწრაფად დააინსტალირონ კარგი მონაცემთა საწყობი და ანალიტიკური პლატფორმა დაყენების, მონაცემთა მეცნიერების დეტალების ან ხელით დაყენების გარეშე.
ეს ასევე არ ნიშნავს იმას, რომ ფიფქია არის მარტივი ინსტრუმენტი ან ახალი მომხმარებლებისთვის. არ ვიცი.
ეს არ არის ისეთი მაღალი დონის, როგორც Databricks; ეს პლატფორმა უფრო შესაფერისია რთული მონაცემთა ინჟინერიისთვის, ETL, მონაცემთა მეცნიერებისა და ნაკადის აპლიკაციებისთვის.
Snowflake არის მონაცემთა საწყობი ანალიტიკისთვის, რომელიც ინახავს წარმოების მონაცემებს. გარდა ამისა, ეს მომგებიანია იმ პირებისთვის, რომლებსაც სურთ დაიწყონ მცირე და ეტაპობრივად აწევა, ასევე დამწყებთათვის.





დატოვე პასუხი