映画を観たり、ビデオ ゲームをプレイしたり、仮想現実を使用したりしたときに、人間のキャラクターの動きや表示方法について何か違和感を感じたことはありますか?
コンピュータで生成されたリアルで詳細な人間を作成することは、コンピュータ グラフィックスとコンピュータ ビジョンの研究の長年の目標でした。
ヒューマンRF プロジェクトはその目標に向けたエキサイティングな第一歩です
HumanRF は、マルチビュー ビデオ入力を使用して、動いている人間の全身の外観をキャプチャする動的なニューラル シーン表現です。 このテクノロジーの概要と、このテクノロジーの潜在的な利点を見てみましょう。

人間のパフォーマンスのキャプチャ
仮想設定の写真のようにリアルな表現を作成することは、長い間問題となってきました。 コンピューターグラフィックス.
従来、アーティストは 3D オブジェクトを手作業で生成していました。 しかし、最近の研究は、実世界のデータから 3D 表現を再作成することに重点を置いています。
特に、人間のリアルなパフォーマンスをキャプチャして合成することは、映画制作、コンピューター ゲーム、テレプレゼンスなどのアプリケーションの研究の焦点となっています。
ダイナミックニューラルラディアンスフィールドの進歩
近年、動的神経放射フィールド (NeRF) の使用を通じてこれらの課題に対処する上で大きな進歩が見られました。 NeRF は、多層パーセプトロン (MLP) でエンコードされた 3D フィールドを再構築することができ、新しいビューの合成を可能にします。
NeRF は当初静的なシーンに焦点を当てていましたが、最近の研究では時間調整フィールドや変形フィールドを使用して動的なシーンに取り組んでいます。 ただし、これらの方法は、複雑な動きを伴う長いシーケンス、特に動く人間をキャプチャする場合に引き続き苦労します。
ActorsHQのデータセ
これらの欠陥に対処するために、専門家は、フォトリアリスティックな新しいビュー合成用に最適化された、動いている服を着た人間の新しい高忠実度データセットである ActorsHQ を提案しています。 データセットには、160 台の同期カメラからのマルチビュー録画が含まれており、各カメラは 12 メガピクセルのビデオ ストリームをキャプチャしています。
このデータセットを使用すると、フィーチャ グリッドの低ランク時空間テンソル分解とともに時間次元を組み込むことで、Instant-NGP ハッシュ エンコーディングを時間領域に拡張する新しいシーン表現の作成が可能になります。

HumanRF の紹介
HumanRF は、マルチビュー ビデオ入力から全身の動きをキャプチャし、これまで見たことのない視点からの再生を可能にする 4D ダイナミック ニューラル シーン表現です。 これは、非常に少ないスペースで大量のデータをキャプチャするビデオ録画技術です。
これは、レゴ セットを分解して再組み立てする方法と同様に、空間と時間をより小さな部分に分割することでこれを実現します。
HumanRF テクノロジーは、たとえ難しい動きや複雑な動きをしている人であっても、ビデオ内の人の動きを非常にうまくキャプチャできます。 このテクノロジーの作成者は、新しく導入された ActorsHQ データセットに対する HumanRF の有効性を実証し、既存の最先端の手法に比べて大幅な改善が見られることを実証しました。

では、HumanRF はどのようにして作成できたのでしょうか?また、その内部の仕組みはどうなっているのでしょうか?
HumanRF メソッドの概要
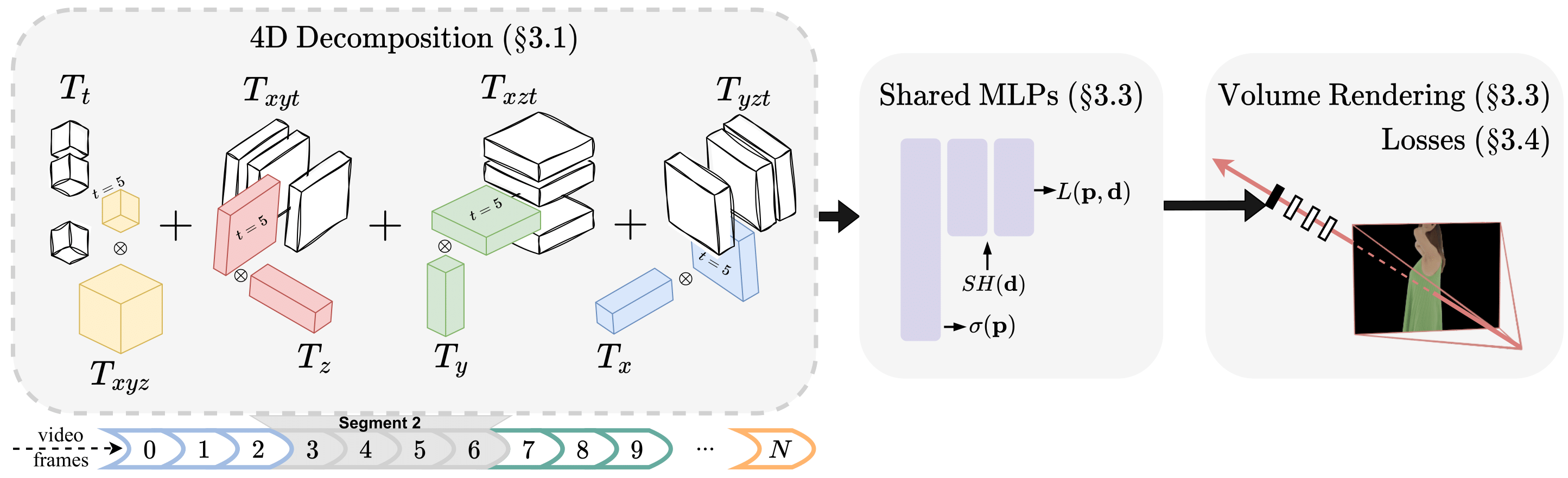
4D フィーチャ グリッドの分解
4D フィーチャ グリッド分解は、HumanRF の重要なコンポーネントです。 この方法では、最適に分割された 4D セグメントを組み合わせることで、動的な 3D シーンをモデル化します。 各セグメントには、一連のフレームをエンコードする独自のトレーニング可能な 4D 特徴グリッドがあります。
時空間データをよりコンパクトに表現するために、4D フィーチャ グリッドは 3 つの 1D フィーチャ グリッドと 4 つの XNUMXD フィーチャ グリッドの分解として定義されます。 XNUMXD フィーチャ グリッド分解は、この方法がより少ないスペースで、高レベルの詳細を備えた高品質の画像を生成するのに役立ちます。
適応型時間分割
HumanRF は、疎な特徴ハッシュ グリッドを備えた浅い多層パーセプトロンを使用して、任意の長さのマルチビュー データを効果的にレンダリングします。 コンパクトな 4D 特徴グリッドを使用して、時間領域を構成する最適に分散された時間セグメントを表現します。
時間的コンテキストに関係なく、この方法では、適応型時間分割を使用して各セグメントがカバーする 3D 空間の総体積が同様のサイズになるようにすることで、優れた表現力を実現します。 ビデオがどれだけ長くても、適応型時間分割は一貫した表現を生成するのに役立ちます。

2D のみの損失による監視
レンダリングおよび入力 RGB イメージと前景マスクの間の誤差は、監視された 2D のみの損失を使用して HumanRF によって測定されます。
この手法は、共有 MLP と 4D 分解を使用して時間的一貫性を実現し、その結果は最適なセグメント サイズの結果と非常に似ています。
この方法は 3D 損失のみを使用するため、2D 損失を使用する方法よりも効果的かつ簡単にトレーニングできます。
この方法は、実験的にテストされた他の方法よりも優れた結果をもたらし、高品質で動いている人間の俳優の画像を生成するための有望な戦略となっています。
使用可能な領域
ビデオゲームと仮想現実の強化
リアルタイムの仮想キャラクター作成 ビデオゲーム HumanRF を使用すると VR アプリケーションが可能になります。 人間の俳優の動きはさまざまな角度から記録でき、そのデータは HumanRF を通じて処理できます。
これにより、 ゲーム開発者 より現実的に動き、環境と対話できるキャラクターを作成し、プレイヤーにより魅力的な体験を提供します。
映画制作におけるモーション キャプチャ
HumanRF は、俳優の動きの鮮明な画像を生成することで、映画制作プロセスにおけるモーション キャプチャを強化できます。
映画制作者は、複数のカメラを使用して俳優の演技を記録し、HumanRF を使用して 4D 表現を生成することで、さまざまな角度から編集できるリアルでダイナミックなパフォーマンスを作成できます。
これにより、再撮影の必要性が減り、制作コストが削減されます。
仮想会議と電話会議の強化
HumanRF は、遠隔地の参加者の 3D モデルをリアルタイムで生成することにより、仮想会議での没入感とリアリズムの作成を可能にします。
仮想会議の参加者は、遠隔地の参加者の動きをさまざまな角度からキャプチャし、HumanRF を通じてデータを処理することで、より興味深いインタラクティブな体験をすることができます。
さらに、HumanRF を使用すると、遠隔参加者の高品質なビューを作成できます。 ビデオ会議、より良いコラボレーションとコミュニケーションにつながります。
教育と訓練の促進
HumanRF を使用すると、トレーニングおよび教育環境で動的で現実的なシミュレーションを構築できます。
特定のタスクを実行するインストラクターや俳優の動きを記録し、HumanRF を通じてデータを処理することで、受講者がより現実的で興味深い環境で練習および学習できるトレーニング シミュレーションを作成できます。
たとえば、HumanRF は、運転、飛行、または医療訓練のためのシミュレーションを開発するために使用できます。
セキュリティと監視の強化
監視およびセキュリティ アプリケーションでは、HumanRF を使用して、動的でリアルな人物またはグループの 3D モデルを作成できます。 セキュリティ担当者は、さまざまな視点から個人の動きを捕捉し、HumanRF を通じてデータを処理することで、人の動きや行動をより正確に表現することができます。
これにより、潜在的な脅威の特定と追跡が向上します。 セキュリティ担当者は、HumanRF を使用して緊急シナリオのシミュレーションを作成することで、さまざまな状況を練習し、準備することができます。
まとめ、将来はどうなるでしょうか?
HumanRF は、動く人間のアクターの高品質でユニークなビューを生成するための効果的なアプローチです。 モーション キャプチャ、仮想現実、テレプレゼンスなど、さまざまなアプリケーションで有望な結果が実証されています。 HumanRF の可能性はこれらのアプリケーションに限定されません。 このテクノロジーにはさらにいくつかの応用例が考えられます。
この分野の研究が発展するにつれて改善され、より効率的かつ正確になることが期待されます。
新しいアルゴリズムとアーキテクチャは、ほぼ確実に、動いている人間の俳優をモデリングして描写する、より高度な方法につながり、映画、ゲーム、コミュニケーションの業界に数多くの興味深い進歩をもたらす可能性があります。
さらに、 深層学習モデル HumanRF との併用は、将来の研究の方向性となる可能性があります。 これは、より効果的かつ効率的な人間の動作分析およびモデリング技術につながる可能性があります。
さらに、HumanRF を触覚フィードバック システムや拡張現実などの他のテクノロジーと組み合わせることで、医療トレーニング、教育、治療における新しい応用が生まれる可能性があります。





コメントを残す