זוהי משימה מכרעת ורצויה בראייה ממוחשבת ובגרפיקה לייצר סרטי דיוקן יצירתיים ברמה הגבוהה ביותר.
למרות שהוצעו כמה מודלים יעילים להצגת תמונות דיוקן המבוססות על StyleGAN החזק, לטכניקות מוכוונות תמונה אלה יש חסרונות ברורים בשימוש עם סרטונים, כגון גודל המסגרת הקבועה, הדרישה ליישור הפנים, היעדר פרטים שאינם פנים. , וחוסר עקביות זמני.
מסגרת מהפכנית של VToonify משמשת להתמודדות עם העברת סגנון וידאו דיוקן מבוקרת קשה ברזולוציה גבוהה.
נבחן את המחקר האחרון על VToonify במאמר זה, כולל הפונקציונליות שלו, החסרונות וגורמים אחרים.
מה זה Vtoonify?
מסגרת VToonify מאפשרת שידור בסגנון וידאו דיוקן ברזולוציה גבוהה להתאמה אישית.
VToonify משתמשת בשכבות ברזולוציה בינונית וגבוהה של StyleGAN כדי ליצור דיוקנאות אמנותיים באיכות גבוהה המבוססים על מאפייני תוכן מרובים שאוחזרו על ידי מקודד כדי לשמור על פרטי מסגרת.
הארכיטקטורה הקונבולוציונית המלאה הנובעת לוקחת פרצופים לא מיושרים בסרטים בגודל משתנה כקלט, וכתוצאה מכך אזורים שלמים עם תנועות ריאליסטיות בפלט.

מסגרת זו תואמת לדגמי הצגת תמונות הנוכחיים מבוססי StyleGAN, ומאפשרת להרחיב אותם להצגת וידאו, ותורשת מאפיינים אטרקטיביים כגון התאמה אישית של צבע ועוצמה.
זֶה ללמוד מציגה שני מופעים של VToonify המבוססים על Toonify ו- DualStyleGAN להעברת סגנון וידאו דיוקן מבוסס אוסף ומבוסס דוגמה, בהתאמה.
ממצאים ניסיוניים נרחבים מראים כי המסגרת המוצעת של VToonify עולה על הגישות הקיימות ביצירת סרטי דיוקן אמנותיים באיכות גבוהה, קוהרנטית בזמנית עם פרמטרי סגנון משתנים.
חוקרים מספקים את מחברת Google Colab, כדי שתוכל ללכלך עליו את הידיים.
איך זה עובד?
כדי לבצע העברת סגנון וידאו דיוקן ברזולוציה גבוהה מתכווננת, VToonify משלב את היתרונות של מסגרת תרגום התמונה עם המסגרת מבוססת StyleGAN.
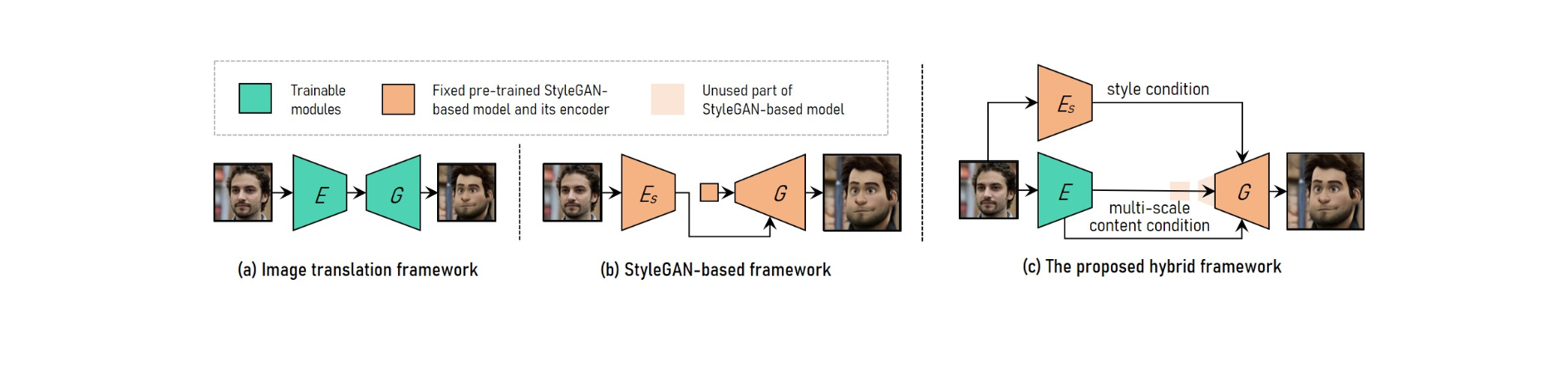
כדי להכיל גדלי קלט משתנים, מערכת תרגום התמונות משתמשת ברשתות קונבולוציוניות לחלוטין. אימון מאפס, לעומת זאת, הופך שידור בסגנון מבוקר ברזולוציה גבוהה לבלתי אפשרית.
מודל StyleGAN שהוכשר מראש משמש במסגרת המבוססת על StyleGAN להעברת סגנון ברזולוציה גבוהה ומבוקרת, אם כי הוא מוגבל לגודל תמונה קבוע ואובדן פרטים.
StyleGAN שונה במסגרת ההיברידית על ידי מחיקת תכונת הקלט בגודל קבוע ושכבות ברזולוציה נמוכה, וכתוצאה מכך ארכיטקטורת מחולל-קודד קונבולוציונית דומה לזו של מסגרת תרגום התמונה.
כדי לשמור על פרטי מסגרת, אמנו מקודד לחלץ מאפייני תוכן מרובים של מסגרת הקלט כדרישת תוכן נוספת למחולל. Vtoonify יורשת את גמישות בקרת הסגנון של מודל StyleGAN על ידי הכנסתו לתוך המחולל כדי לזקק את הנתונים והמודל שלו.
מגבלות של StyleGAN & Vtoonify המוצע
דיוקנאות אמנותיים נפוצים בחיי היומיום שלנו כמו גם בעסקים יצירתיים כמו אמנות, מדיה חברתית אווטרים, סרטים, פרסום בידור וכדומה.
עם ההתפתחות של למידה עמוקה טכנולוגיה, כעת ניתן ליצור פורטרטים אמנותיים באיכות גבוהה מתמונות פנים אמיתיות באמצעות העברה אוטומטית של סגנון דיוקן.
ישנן מגוון דרכים מוצלחות שנוצרו להעברת סגנונות מבוססת תמונה, שרבות מהן נגישות בקלות למשתמשים מתחילים בצורה של יישומים ניידים. חומרי וידאו הפכו במהירות לעמוד התווך של עדכוני המדיה החברתית שלנו במהלך השנים האחרונות.
עלייתם של מדיה חברתית וסרטים ארעיים הגבירה את הביקוש לעריכת וידאו חדשנית, כגון העברת סגנון וידאו פורטרטים, כדי ליצור סרטונים מוצלחים ומעניינים.
לטכניקות קיימות מוכוונות תמונה יש חסרונות משמעותיים כשהן מיושמות על סרטים, מה שמגביל את התועלת שלהן בסטייליזציה אוטומטית של וידאו דיוקן.
StyleGAN הוא עמוד שדרה נפוץ לפיתוח מודל העברת סגנון תמונת דיוקן בשל יכולתו ליצור פרצופים באיכות גבוהה עם ניהול סגנון מתכוונן.
מערכת מבוססת StyleGAN (הידועה גם בשם הצגת תמונה) מקודדת פנים אמיתיות לתוך המרחב הסמוי של StyleGAN ולאחר מכן מיישמת את קוד הסגנון המתקבל על StyleGAN אחר המכוונן עדין במערך הנתונים של דיוקן אמנותי כדי ליצור גרסה מסוגננת.
StyleGAN יוצר תמונות עם פנים מיושרות ובגודל קבוע, שאינו מעדיף פנים דינמיות בצילומים מהעולם האמיתי. חיתוך ויישור פנים בסרטון גורמים לפעמים לפרצוף חלקי ולתנועות מביכות. חוקרים מכנים את הנושא הזה 'הגבלת יבול קבוע' של StyleGAN.
עבור פנים לא מיושרות, StyleGAN3 הוצע; עם זאת, הוא תומך רק בגודל תמונה מוגדר.
יתר על כן, מחקר שנערך לאחרונה גילה שקידוד פנים לא מיושרות הוא מאתגר יותר מפרצופים מיושרים. קידוד פנים שגוי מזיק להעברת סגנון דיוקן, וכתוצאה מכך בעיות כמו שינוי זהות ורכיבים חסרים במסגרות המשוחזרות והמסוגננות.
כפי שצוין, טכניקה יעילה להעברת סגנון וידאו דיוקן חייבת לטפל בבעיות הבאות:
- כדי לשמר תנועות ריאליסטיות, הגישה חייבת להיות מסוגלת להתמודד עם פנים לא מיושרות וגדלים מגוונים של וידאו. גודל וידאו גדול, או זווית ראייה רחבה, יכולים ללכוד מידע נוסף תוך שמירה על הפנים מלצאת מהמסגרת.
- כדי להתחרות בגאדג'טים HD הנפוצים כיום, יש צורך בווידאו ברזולוציה גבוהה.
- יש להציע למשתמשים בקרת סגנון גמישה כדי לשנות ולבחור את בחירתם בעת פיתוח מערכת אינטראקציה מציאותית עם משתמשים.
לשם כך, החוקרים מציעים את VToonify, מסגרת היברידית חדשה להצגת וידאו. כדי להתגבר על מגבלת היבול הקבועה, חוקרים חוקרים תחילה שוויון תרגום ב- StyleGAN.
VToonify משלב את היתרונות של הארכיטקטורה המבוססת על StyleGAN ומסגרת תרגום התמונה כדי להשיג העברת סגנון וידאו דיוקן ברזולוציה גבוהה מתכווננת.
להלן התרומות העיקריות:
- חוקרים חוקרים את אילוץ היבול הקבוע של StyleGAN ומציעים פתרון המבוסס על שוויוניות תרגום.
- החוקרים מציגים מסגרת ייחודית של VToonify המהווה פיתול מלא להעברת סגנון וידאו דיוקן ברזולוציה גבוהה, התומכת בפנים לא מיושרות ובגדלים שונים של וידאו.
- חוקרים בונים את VToonify על עמודי השדרה של Toonify ו- DualStyleGAN ומצמצמים את עמודי השדרה הן במונחים של נתונים והן במונחים של מודל כדי לאפשר העברת סגנון וידאו דיוקן מבוסס אוסף ומבוסס דוגמה.
השוואת Vtoonify עם דגמים חדישים אחרים
טוניפי
הוא משמש כבסיס להעברת סגנון מבוסס אוסף על פנים מיושרות באמצעות StyleGAN. כדי לאחזר את קודי הסגנון, על החוקרים ליישר פרצופים ולחתוך 256256 תמונות עבור PSP. Toonify משמש ליצירת תוצאה מסוגננת עם קודי סגנון 1024*1024.
לבסוף, הם מיישרים מחדש את התוצאה בסרטון למיקומה המקורי. האזור הלא מעוצב הוגדר לשחור.

DualStyleGAN
זהו עמוד שדרה להעברת סגנון מבוססת דוגמה המבוססת על StyleGAN. הם משתמשים באותן טכניקות עיבוד נתונים לפני ואחרי כמו Toonify.
Pix2pixHD
זהו מודל תרגום תמונה לתמונה המשמש בדרך כלל לעיבוי מודלים מאומנים מראש לעריכה ברזולוציה גבוהה. הוא מאומן באמצעות נתונים מזווגים.
החוקרים משתמשים ב-pix2pixHD ככניסות מפת המופעים הנוספות שלו מכיוון שהוא משתמש במפת ניתוח שחולצה.
תנועה מסדר ראשון
FOM הוא מודל אנימציית תמונה טיפוסית. הוא הוכשר על 256256 תמונות וביצועים גרועים עם גדלי תמונה אחרים. כתוצאה מכך, החוקרים משנים תחילה את מסגרות הווידאו ל-256*256 עבור FOM להנפשה ולאחר מכן משנים את גודל התוצאות לגודלן המקורי.
לשם השוואה הוגנת, FOM משתמשת בפריים המסוגנן הראשון של הגישה שלה כתמונת סגנון ההתייחסות שלה.
DaGAN
זהו מודל הנפשת פנים תלת מימד. הם משתמשים באותן שיטות הכנה ועיבוד של נתונים כמו FOM.

יתרונות
- זה יכול להיות מועסק באמנויות, אווטרים במדיה חברתית, סרטים, פרסום בידור וכו'.
- ניתן להשתמש ב-Vtoonify גם ב-metaverse.
מגבלות
- מתודולוגיה זו מחלצת הן את הנתונים והן את המודל מעמודי השדרה המבוססים על StyleGAN, וכתוצאה מכך יש הטיית נתונים ומודל.
- החפצים נגרמים בעיקר מהבדלי גודל בין אזור הפנים המסוגנן לבין החלקים האחרים.
- האסטרטגיה הזו פחות מוצלחת כשעוסקים בדברים באזור הפנים.
סיכום
לבסוף, VToonify היא מסגרת להצגת וידאו ברזולוציה גבוהה בשליטה בסגנון.
מסגרת זו משיגה ביצועים מעולים בטיפול בסרטונים ומאפשרת שליטה רחבה על הסגנון המבני, סגנון הצבע ודרגת הסגנון על ידי עיבוי מודלים של הצגת תמונות מבוססי StyleGAN במונחים של שניהם. נתונים סינתטיים ומבני רשת.





השאירו תגובה