È un compito cruciale e desiderabile nella visione artificiale e nella grafica produrre film di ritratti creativi di altissimo livello.
Sebbene siano stati proposti diversi modelli efficaci per l'onificazione delle immagini dei ritratti basati sul potente StyleGAN, queste tecniche orientate all'immagine presentano evidenti svantaggi se utilizzate con i video, come la dimensione fissa del fotogramma, il requisito per l'allineamento del viso, l'assenza di dettagli non facciali , e incoerenza temporale.
Un rivoluzionario framework VToonify viene utilizzato per affrontare il difficile trasferimento controllato in stile video verticale ad alta risoluzione.
Esamineremo lo studio più recente su VToonify in questo articolo, comprese le sue funzionalità, svantaggi e altri fattori.
Cos'è Vtoonify?
Il framework VToonify consente la trasmissione personalizzabile in stile video verticale ad alta risoluzione.
VToonify utilizza i livelli a media e alta risoluzione di StyleGAN per creare ritratti artistici di alta qualità basati su caratteristiche del contenuto multiscala recuperate da un codificatore per conservare i dettagli del fotogramma.
L'architettura risultante completamente convolutiva prende come input i volti non allineati nei filmati di dimensioni variabili, risultando in regioni del viso intero con movimenti realistici nell'output.

Questo framework è compatibile con gli attuali modelli di toonificazione delle immagini basati su StyleGAN, consentendone l'estensione alla toonificazione video, ed eredita caratteristiche interessanti come la personalizzazione del colore e dell'intensità regolabili.
La sezione studio introduce due istanze di VToonify basate su Toonify e DualStyleGAN rispettivamente per il trasferimento di stili video verticale basato su raccolta e basato su esemplare.
Numerosi risultati sperimentali mostrano che il framework VToonify proposto supera gli approcci esistenti nella realizzazione di film di ritratti artistici di alta qualità e temporalmente coerenti con parametri di stile variabili.
I ricercatori forniscono il Quaderno Google Colab, così puoi sporcarti le mani.
Come funziona?
Per realizzare il trasferimento regolabile in stile video verticale ad alta risoluzione, VToonify combina i vantaggi del framework di traduzione delle immagini con il framework basato su StyleGAN.
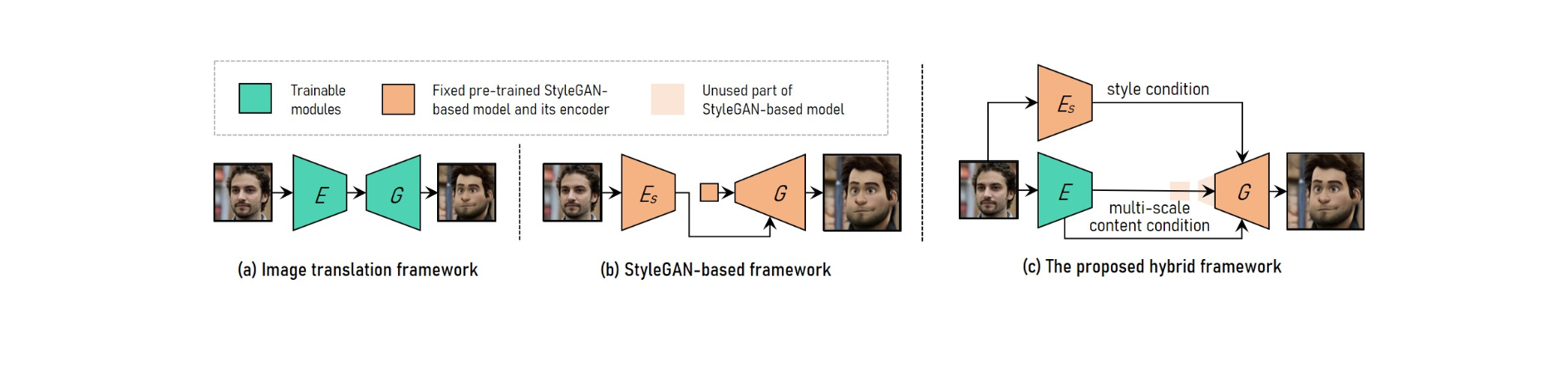
Per adattarsi a dimensioni di input variabili, il sistema di traduzione delle immagini utilizza reti completamente convoluzionali. L'allenamento da zero, d'altra parte, rende impossibile la trasmissione ad alta risoluzione e stile controllato.
Il modello StyleGAN pre-addestrato viene utilizzato nel framework basato su StyleGAN per un trasferimento di stile controllato e ad alta risoluzione, sebbene sia limitato a dimensioni fisse dell'immagine e perdite di dettagli.
StyleGAN viene modificato nel framework ibrido eliminando la sua funzione di input di dimensioni fisse e livelli a bassa risoluzione, risultando in un'architettura generatore di codificatore completamente convoluzionale simile a quella del framework di traduzione delle immagini.
Per mantenere i dettagli del frame, addestrare un codificatore per estrarre le caratteristiche del contenuto multiscala del frame di input come requisito di contenuto aggiuntivo per il generatore. Vtoonify eredita la flessibilità del controllo dello stile del modello StyleGAN inserendolo nel generatore per distillare sia i dati che il modello.
Limitazioni di StyleGAN e Proposta di Vtoonify
I ritratti artistici sono comuni nella nostra vita quotidiana così come nelle attività creative come l'arte, Social Media avatar, film, pubblicità di intrattenimento e così via.
Con lo sviluppo di apprendimento profondo tecnologia, ora è possibile creare ritratti artistici di alta qualità da foto di volti reali utilizzando il trasferimento automatico dello stile del ritratto.
Esistono diversi modi di successo creati per il trasferimento di stili basati su immagini, molti dei quali sono facilmente accessibili agli utenti principianti sotto forma di applicazioni mobili. Il materiale video è diventato rapidamente un pilastro dei nostri feed sui social media negli ultimi anni.
L'ascesa dei social media e dei film effimeri ha aumentato la domanda di editing video innovativo, come il trasferimento in stile video di ritratti, per generare video interessanti e di successo.
Le tecniche esistenti orientate all'immagine presentano svantaggi significativi se applicate ai film, limitando la loro utilità nella stilizzazione video automatizzata dei ritratti.
StyleGAN è una spina dorsale comune per lo sviluppo di un modello di trasferimento dello stile di foto ritratto grazie alla sua capacità di creare volti di alta qualità con gestione dello stile regolabile.
Un sistema basato su StyleGAN (noto anche come immagine toonification) codifica un volto reale nello spazio latente StyleGAN e quindi applica il codice di stile risultante a un altro StyleGAN ottimizzato sul set di dati del ritratto artistico per creare una versione stilizzata.
StyleGAN crea immagini con volti allineati e con una dimensione fissa, che non favorisce i volti dinamici nelle riprese del mondo reale. Il ritaglio e l'allineamento del viso nel video a volte si traducono in un viso parziale e gesti imbarazzanti. I ricercatori chiamano questo problema "restrizione del raccolto fisso" di StyleGAN.
Per le facce non allineate è stato proposto StyleGAN3; tuttavia, supporta solo una dimensione dell'immagine impostata.
Inoltre, uno studio recente ha scoperto che la codifica dei volti non allineati è più impegnativa rispetto ai volti allineati. La codifica errata dei volti è dannosa per il trasferimento dello stile del ritratto, causando problemi come l'alterazione dell'identità e componenti mancanti nelle cornici ricostruite e con lo stile.
Come discusso, una tecnica efficiente per il trasferimento in stile video verticale deve gestire i seguenti problemi:
- Per preservare i movimenti realistici, l'approccio deve essere in grado di gestire volti non allineati e dimensioni video diverse. Un video di grandi dimensioni o un ampio angolo di visione possono acquisire più informazioni evitando che il viso si muova fuori dall'inquadratura.
- Per competere con i gadget HD comunemente utilizzati oggi, è necessario video ad alta risoluzione.
- Il controllo dello stile flessibile dovrebbe essere offerto agli utenti per modificare e scegliere la loro scelta durante lo sviluppo di un sistema realistico di interazione con l'utente.
A tal fine, i ricercatori suggeriscono VToonify, un nuovo framework ibrido per la toonificazione video. Per superare il vincolo del raccolto fisso, i ricercatori studiano prima l'equivarianza della traduzione in StyleGAN.
VToonify combina i vantaggi dell'architettura basata su StyleGAN e il framework di traduzione delle immagini per ottenere un trasferimento in stile video verticale ad alta risoluzione regolabile.
Di seguito i contributi principali:
- I ricercatori studiano il vincolo del raccolto fisso di StyleGAN e propongono una soluzione basata sull'equivarianza traslativa.
- I ricercatori presentano un framework VToonify completamente convoluzionale unico per il trasferimento controllato in stile video verticale ad alta risoluzione che supporta volti non allineati e dimensioni video diverse.
- I ricercatori costruiscono VToonify sulle dorsali di Toonify e DualStyleGAN e condensano le dorsali in termini sia di dati che di modello per consentire il trasferimento di stili video di ritratti basati su raccolte e su esempi.
Confronto di Vtoonify con altri modelli all'avanguardia
toonificare
Serve come base per il trasferimento dello stile basato sulla raccolta su facce allineate utilizzando StyleGAN. Per recuperare i codici di stile, i ricercatori devono allineare i volti e ritagliare 256256 foto per PSP. Toonify viene utilizzato per generare un risultato stilizzato con codici di stile 1024*1024.
Infine, riallineano il risultato nel video alla sua posizione originale. L'area non stilizzata è stata impostata su nero.

DualStyleGAN
È una spina dorsale per il trasferimento di stile basato su esemplari basato su StyleGAN. Usano le stesse tecniche di pre e post elaborazione dei dati di Toonify.
Pix2pix HD
È un modello di traduzione da immagine a immagine comunemente utilizzato per condensare modelli pre-addestrati per l'editing ad alta risoluzione. Viene addestrato utilizzando dati accoppiati.
I ricercatori utilizzano pix2pixHD come input della mappa di istanza aggiuntiva poiché utilizza la mappa di analisi estratta.
Mozione del Primo Ordine
FOM è un tipico modello di animazione dell'immagine. È stato addestrato su 256256 immagini e funziona male con altre dimensioni dell'immagine. Di conseguenza, i ricercatori prima ridimensionano i fotogrammi video a 256*256 per FOM all'animazione e quindi ridimensionano i risultati alla loro dimensione originale.
Per un confronto equo, FOM utilizza la prima cornice stilizzata del suo approccio come immagine dello stile di riferimento.
DaGAN
È un modello di animazione facciale 3D. Usano gli stessi metodi di preparazione e post-elaborazione dei dati di FOM.

Vantaggi
- Può essere impiegato nelle arti, avatar di social media, film, pubblicità di intrattenimento e così via.
- Vtoonify può essere utilizzato anche nel metaverso.
Limiti
- Questa metodologia estrae sia i dati che il modello dai backbone basati su StyleGAN, con conseguente distorsione dei dati e del modello.
- Gli artefatti sono causati principalmente da differenze di dimensioni tra la regione del viso stilizzato e le altre sezioni.
- Questa strategia ha meno successo quando si tratta di cose nella regione del viso.
Conclusione
Infine, VToonify è un framework per la toonificazione video ad alta risoluzione controllata dallo stile.
Questo framework offre grandi prestazioni nella gestione dei video e consente un ampio controllo sullo stile strutturale, sullo stile del colore e sul grado di stile condensando i modelli di toonificazione delle immagini basati su StyleGAN in termini sia di dati sintetici e strutture di rete.





Lascia un Commento