Sommario[Nascondere][Spettacolo]
Non è nuovo avere foto e video falsi. Dall'uso diffuso di Internet, le persone hanno creato falsi intesi per ingannare o divertire sin da quando ci sono state immagini e film.
Tuttavia, esiste un nuovo tipo di falsi prodotti da macchine che un giorno potrebbero renderci difficile distinguere la realtà dalla finzione.
Questi falsi differiscono dalle semplici manipolazioni delle immagini generate da software di editing come Photoshop o dai film abilmente manipolati del passato.
I deepfake sono l'esempio più noto di "media sintetici": immagini, suoni e video che sembrano essere stati prodotti utilizzando metodi convenzionali, ma in realtà sono stati realizzati utilizzando software sofisticati.
I deepfake sono in circolazione da un po' di tempo e, sebbene la loro applicazione più popolare sia stata quella di mettere le teste di personaggi famosi sui corpi degli attori nei film pornografici, hanno la capacità di produrre filmati convincenti di chiunque faccia qualsiasi cosa, ovunque.
In questo post, esamineremo Deepfake, come funziona, come puoi generarli da solo e molto altro.
Allora, cos'è DeepFake?
Un deepfake, una combinazione delle frasi deep learning e fake, è un pezzo di supporti sintetici in cui la somiglianza di un'altra persona viene utilizzata per sostituire quella di una persona in una fotografia o in un video già esistente.
I deepfake utilizzano sofisticate tecniche di apprendimento automatico e intelligenza artificiale per modificare e creare informazioni visive e audio che hanno un alto potenziale di inganno.
I metodi di deep learning come autoencoder e reti generative contraddittorio sono il meccanismo principale per la produzione di deepfake (GAN).
Questi modelli vengono utilizzati per analizzare le emozioni e i movimenti facciali di una persona e sintetizzare le immagini del viso di altre persone che esibiscono espressioni e movimenti comparabili.
L'uso di deepfake in video pornografici di celebrità, notizie false, bufale e frodi finanziarie ha attirato notevole attenzione. Sia l'industria che il governo hanno risposto cercando di trovarli e limitarne l'utilizzo.
Modello di movimento del primo ordine
Quando si cercava di sviluppare falsi profondi in passato, il problema era che avevamo bisogno di una sorta di conoscenza extra, o di precedenti, affinché questi approcci funzionassero.
A titolo illustrativo, i marcatori facciali sono necessari se desideriamo tracciare il movimento della testa. La stima della posa era necessaria se volevamo mappare il movimento di tutto il corpo.
Ciò è cambiato alla conferenza NeurIPS dell'anno scorso, quando il team di ricerca dell'Università di Toronto ha presentato il proprio lavoro, "Modello di movimento del primo ordine per l'animazione di immagini. "
Non sono necessarie ulteriori conoscenze di animazione per questo approccio. Inoltre, dopo che questo modello è stato addestrato, può essere utilizzato per trasferire l'apprendimento e applicato a qualsiasi elemento che rientra nella stessa categoria.
Diamo un'occhiata al funzionamento di questo metodo un po' più avanti. L'estrazione e la generazione del movimento costituiscono la prima metà dell'intero processo. Il video di guida e le immagini sorgente vengono utilizzati come input.
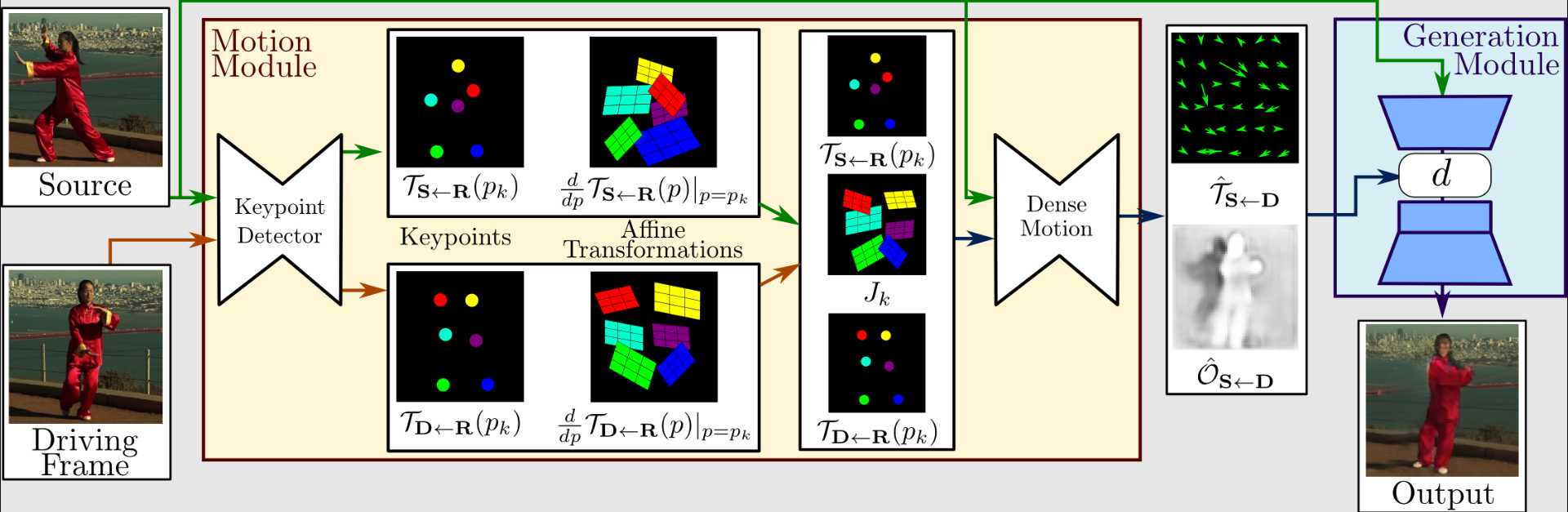
Per estrarre la rappresentazione del movimento del primo ordine, che consiste in punti chiave sparsi e trasformazioni affini locali, un estrattore di movimento utilizza un codificatore automatico per identificare i punti chiave.
Per creare un flusso ottico denso e una mappa di occlusione con la fitta rete di movimento, vengono utilizzati insieme al video di guida. Il generatore esegue quindi il rendering dell'immagine target utilizzando gli output della fitta rete di movimento e l'immagine sorgente.
In generale, questo lavoro ha prestazioni migliori rispetto allo stato dell'arte. Contiene anche caratteristiche che altri modelli semplicemente non hanno. Funziona su diversi tipi di immagini, quindi puoi applicarlo alle immagini del viso, del corpo, dei cartoni animati, ecc., Il che è estremamente fantastico.
Molte nuove opportunità sono create da questo. Un altro aspetto rivoluzionario della nostra strategia è che ora ti consente di produrre Deepfake di alta qualità utilizzando solo un'immagine dell'oggetto target, in modo simile a come facciamo con YOLO per oggetto riconoscimento.
Processo di creazione del modello Deepfake
Sono necessari tre processi per la generazione di deepfake: estrazione, formazione e creazione. In questa sezione verranno trattati i punti principali di ciascuna di queste fasi e il modo in cui si riferiscono al processo complessivo.
Estrazione
I deepfake utilizzano reti neurali profonde per cambiare volto e necessitano di molti dati (immagini) per funzionare in modo corretto e convincente. Il processo di estrazione è la fase in cui tutti i fotogrammi dai video clip vengono estratti, i volti vengono riconosciuti e i volti vengono quindi allineati per massimizzare le prestazioni.
Training
Nella fase formativa, il rete neurale può cambiare una faccia in un'altra. A seconda delle dimensioni del set di esercitazione e del gadget di allenamento, l'allenamento può richiedere diverse ore o addirittura giorni.
L'addestramento deve essere terminato una volta, proprio come la maggior parte degli altri corsi di formazione sulle reti neurali. Dopo l'allenamento, il modello sarebbe in grado di cambiare un volto da persona A a persona B.
coerenti
Dopo che il modello è stato addestrato, potrebbe essere prodotto un deepfake. I fotogrammi vengono presi da un video e quindi allineati a tutti i volti. La rete neurale addestrata viene quindi utilizzata per trasformare ogni frame.
La faccia trasformata deve essere unita alla cornice originale come ultimo passaggio.
Costruire un modello di rilevamento dei deepfake
Montaggio e clonazione del repository GitHub
Essere in grado di utilizzare gratuitamente le GPU di Google mentre si lavora in Colab è vantaggioso apprendimento profondo. Un ulteriore vantaggio è la possibilità di montare un Google Drive su una macchina virtuale (VM) cloud.
Con un facile accesso a tutte le sue cose, l'utente è abilitato. Il programma necessario per montare Google Drive sulla macchina virtuale nel cloud si trova in questa sezione.


Importazione di moduli
Ora importeremo tutti i moduli necessari.
Esecuzione del modello
Useremo un esempio che combina una foto di Putin (foto di origine) con un video di Obama. Il risultato è un video di Putin che parla e gesticola con le stesse identiche espressioni facciali che Obama usava durante la guida.
Prima di visualizzare il risultato del modello, il supporto verrà caricato e le funzioni verranno dichiarate. Verranno quindi caricati i checkpoint e costruito il modello. Dopo aver creato il deep fake, verranno visualizzati due diversi stili di animazione.
Putin è animato dai movimenti di Obama che utilizzano il relativo spostamento dei punti chiave. Il modo in cui le emozioni facciali e il linguaggio del corpo di Obama sono rappresentati in modo bello e chiaro per Putin durante i suoi video è sbalorditivo.
Ci sono alcuni errori microscopici, in particolare quando Obama alza le sopracciglia e sbatte le palpebre. Queste espressioni non sono esattamente replicate nelle cornici di Putin.
Senza lo sfondo del deepfake, il film di Putin sembrerebbe abbastanza credibile e autentico se dovesse essere visto in TV o Social Media.
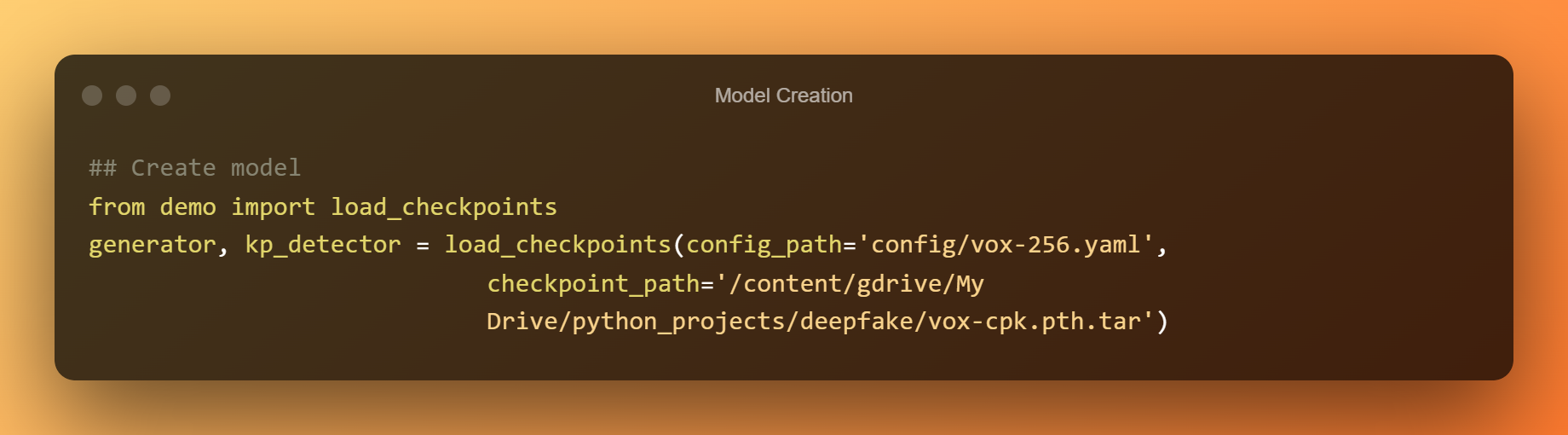
Creazione del modello
Ora utilizzeremo i checkpoint pre-addestrati per creare un modello completo.
Rilevamento deepfake
Lo spostamento relativo del punto chiave viene utilizzato per animare gli elementi nella cella sottostante. La cella successiva utilizza invece coordinate assolute, ma tutte le proporzioni dell'oggetto verranno prese dal video di guida in questo modo.
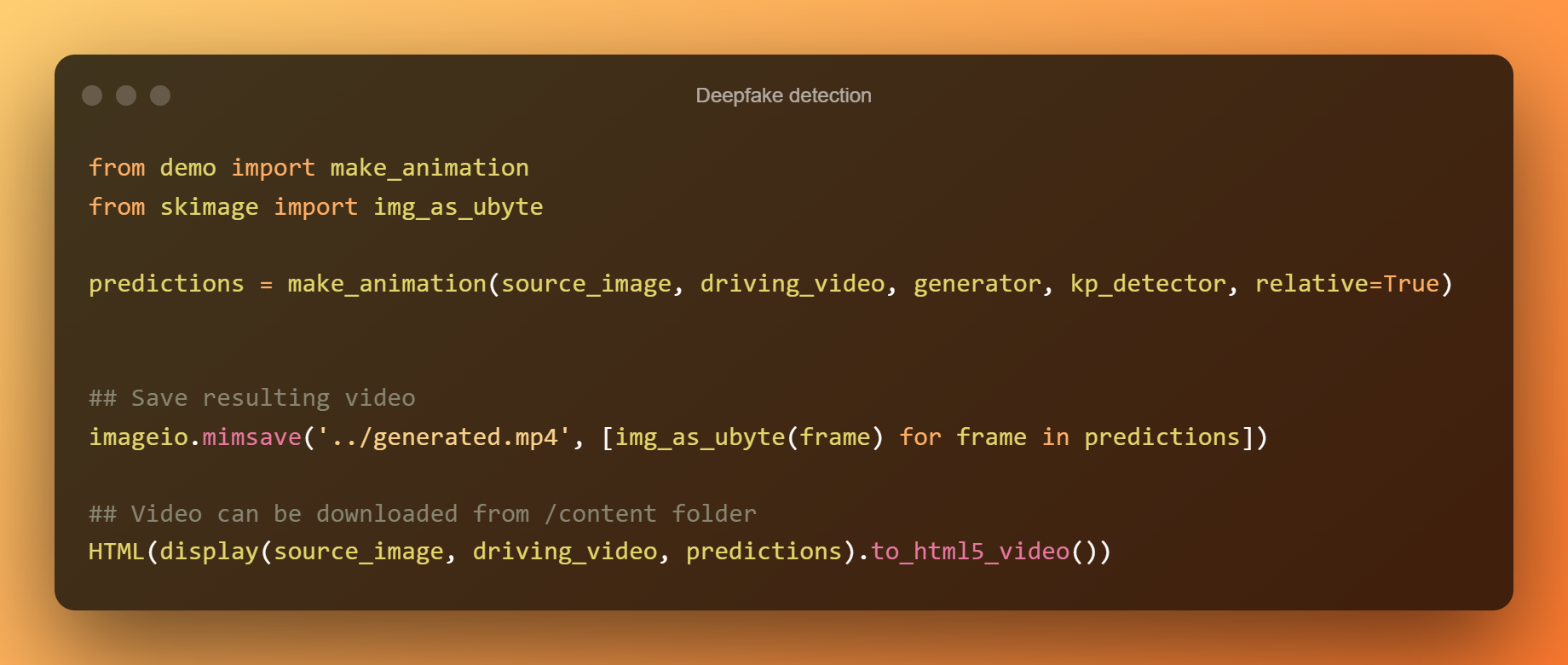
Miglioramento dell'output utilizzando le coordinate assolute

Sarai in grado di sviluppare un rilevamento di deepfake in questo modo.
Quali sono i rischi della tecnologia Deepfake?
I video deepfake ora sono coinvolgenti e divertenti da guardare grazie alla loro novità. Tuttavia, c'è un rischio che potrebbe andare fuori controllo sotto la superficie di questa tecnologia apparentemente divertente.
Sarà sicuramente difficile distinguere tra video falsi e reali come tecnologia deepfake continua ad avanzare. Per personalità di spicco e celebrità, in particolare, ciò potrebbe avere gravi effetti. I deepfake intenzionalmente malevoli hanno il potenziale per danneggiare completamente carriere e vite.
Questi potrebbero essere usati da qualcuno con intenzioni maligne per passare per altri e approfittare dei propri amici, parenti e colleghi. Sono anche in grado di suscitare controversie in tutto il mondo e persino guerre usando film fasulli di leader stranieri.
Conclusione
In sintesi, siamo in un periodo strano e in un ambiente insolito. Più che mai, è semplice produrre notizie e film falsi e diffonderli. Capire cosa è vero e cosa non lo è sta diventando sempre più difficile.
Oggi, a quanto pare, non possiamo più fare affidamento sui nostri sensi.
Nonostante il fatto che siano stati sviluppati rilevatori di falsi video, è solo questione di tempo prima che il divario di informazioni sia così ridotto che anche i migliori rilevatori di falsi non saranno in grado di determinare se il video è reale o meno.





Lascia un Commento