L'intelligenza artificiale è ovunque, ma a volte può essere difficile comprenderne la terminologia e il gergo. In questo post del blog, spieghiamo oltre 50 termini e definizioni di intelligenza artificiale in modo che tu possa dare più senso a questa tecnologia in rapida crescita.
Che tu sia un principiante o un esperto, scommettiamo che qui ci sono alcuni termini che non conosci!
1. Intelligenza artificiale
Intelligenza Artificiale (AI) si riferisce allo sviluppo di sistemi informatici che hanno la capacità di apprendere e funzionare in modo indipendente, spesso emulando l'intelligenza umana.
Questi sistemi analizzano i dati, riconoscono modelli, prendono decisioni e adattano il loro comportamento in base all'esperienza. Sfruttando algoritmi e modelli, l'IA mira a creare macchine intelligenti in grado di percepire e comprendere l'ambiente circostante.
L'obiettivo finale è consentire alle macchine di eseguire attività in modo efficiente, imparare dai dati e mostrare capacità cognitive simili a quelle umane.
2. Algoritmo
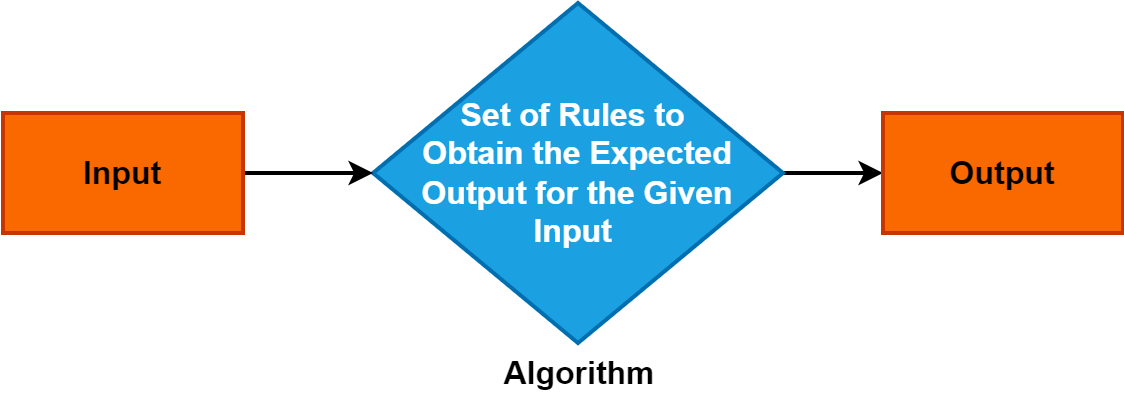
Un algoritmo è un insieme preciso e sistematico di istruzioni o regole che guidano il processo di risoluzione di un problema o l'esecuzione di un compito specifico.
Serve come concetto fondamentale in vari domini e svolge un ruolo fondamentale nelle discipline dell'informatica, della matematica e della risoluzione dei problemi. Comprendere gli algoritmi è fondamentale in quanto consentono approcci di risoluzione dei problemi efficienti e strutturati, guidando i progressi nella tecnologia e nei processi decisionali.
3. Grandi dati
I big data si riferiscono a set di dati estremamente grandi e complessi che superano le capacità dei metodi di analisi tradizionali. Questi set di dati sono tipicamente caratterizzati dal loro volume, velocità e varietà.
Il volume si riferisce alla grande quantità di dati generati da varie fonti come Social Media, sensori e transazioni.
La velocità si riferisce all'elevata velocità con cui i dati vengono generati e devono essere elaborati in tempo reale o quasi in tempo reale. Varietà indica i diversi tipi e formati di dati, inclusi dati strutturati, non strutturati e semi-strutturati.
4. Estrazione dei dati
Il data mining è un processo completo volto a estrarre informazioni preziose da vasti set di dati.
Comprende quattro fasi chiave: raccolta dei dati, che comporta la raccolta di dati rilevanti; preparazione dei dati, garantendo la qualità e la compatibilità dei dati; estrarre i dati, impiegando algoritmi per scoprire modelli e relazioni; e analisi e interpretazione dei dati, in cui la conoscenza estratta viene esaminata e compresa.
5. Rete neurale
Un sistema informatico è progettato per funzionare come il cervello umano, composto da nodi o neuroni interconnessi. Comprendiamo questo un po 'di più poiché la maggior parte dell'IA si basa su reti neurali.
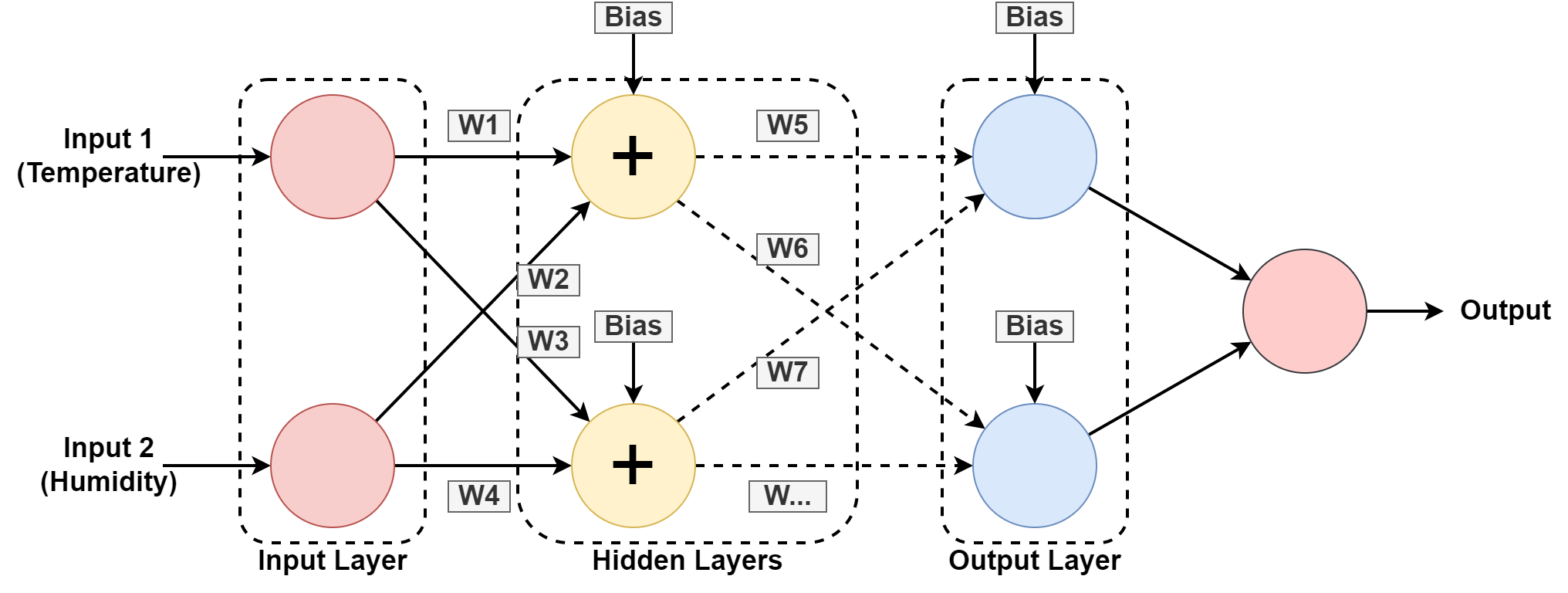
Nei grafici sopra, stiamo prevedendo l'umidità e la temperatura di una posizione geografica imparando dal modello passato. Gli input sono il set di dati per il record passato.
Il la rete neurale impara il pattern giocando con i pesi e applicando valori di bias negli strati nascosti. W1, W2….W7 sono i rispettivi pesi. Si allena sul set di dati fornito e fornisce un output come previsione.
Potresti essere sopraffatto da queste informazioni complesse. Se questo è il caso, puoi iniziare con la nostra semplice guida qui.
6. Apprendimento automatico
L'apprendimento automatico si concentra sullo sviluppo di algoritmi e modelli in grado di apprendere automaticamente dai dati e migliorare le loro prestazioni nel tempo.
Implica l'uso di tecniche statistiche per consentire ai computer di identificare modelli, fare previsioni e prendere decisioni basate sui dati senza essere esplicitamente programmati.
Algoritmi di apprendimento automatico analizzare e apprendere da grandi set di dati, consentendo ai sistemi di adattare e migliorare il proprio comportamento in base alle informazioni che elaborano.
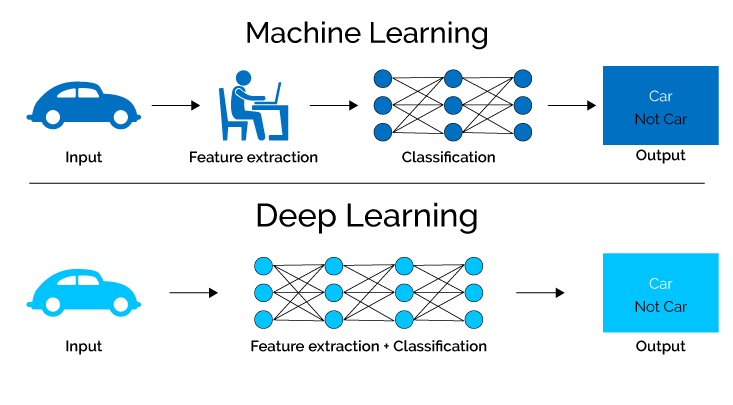
7. Apprendimento profondo
Apprendimento approfondito, un sottocampo dell'apprendimento automatico e delle reti neurali, sfrutta sofisticati algoritmi per acquisire conoscenza dai dati simulando i complessi processi del cervello umano.
Utilizzando reti neurali con numerosi livelli nascosti, i modelli di deep learning possono estrarre autonomamente caratteristiche e modelli complessi, consentendo loro di affrontare attività complesse con precisione ed efficienza eccezionali.
8. Riconoscimento del modello
Il riconoscimento dei modelli, una tecnica di analisi dei dati, sfrutta la potenza degli algoritmi di apprendimento automatico per rilevare e discernere autonomamente modelli e regolarità all'interno dei set di dati.
Sfruttando modelli computazionali e metodi statistici, gli algoritmi di riconoscimento dei modelli possono identificare strutture significative, correlazioni e tendenze in dati complessi e diversi.
Questo processo consente l'estrazione di informazioni preziose, la classificazione dei dati in categorie distinte e la previsione dei risultati futuri sulla base di modelli riconosciuti. Il riconoscimento dei modelli è uno strumento vitale in vari domini, che consente il processo decisionale, il rilevamento delle anomalie e la modellazione predittiva.
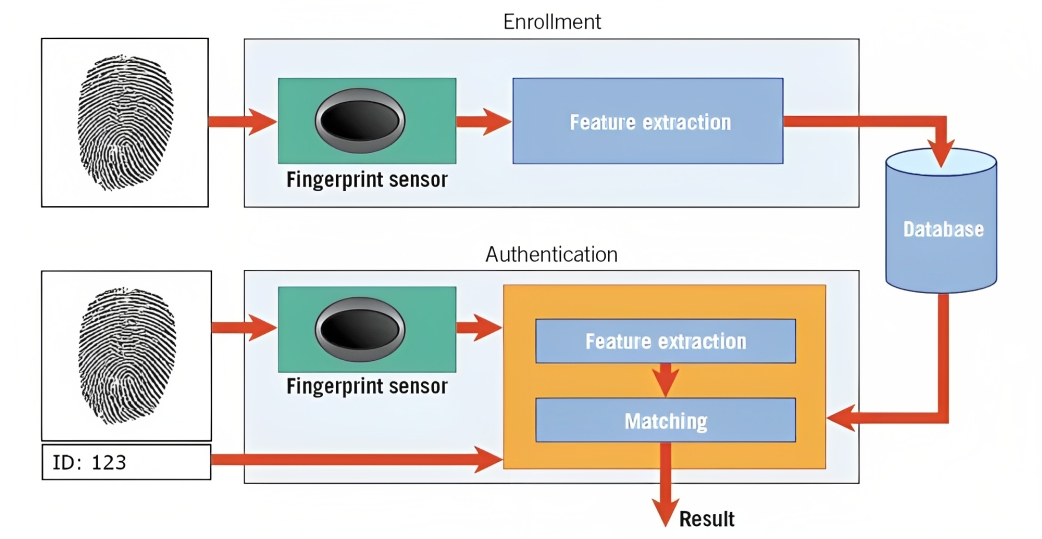
La biometria ne è un esempio. Ad esempio, nel riconoscimento delle impronte digitali, l'algoritmo analizza le creste, le curve e le caratteristiche uniche dell'impronta digitale di una persona per creare una rappresentazione digitale chiamata modello.
Quando si tenta di sbloccare lo smartphone o di accedere a una struttura protetta, il sistema di riconoscimento del modello confronta i dati biometrici acquisiti (ad esempio, l'impronta digitale) con i modelli memorizzati nel suo database.
Abbinando i modelli e valutando il livello di somiglianza, il sistema può determinare se i dati biometrici forniti corrispondono al modello memorizzato e concedere l'accesso di conseguenza.
9. Apprendimento supervisionato
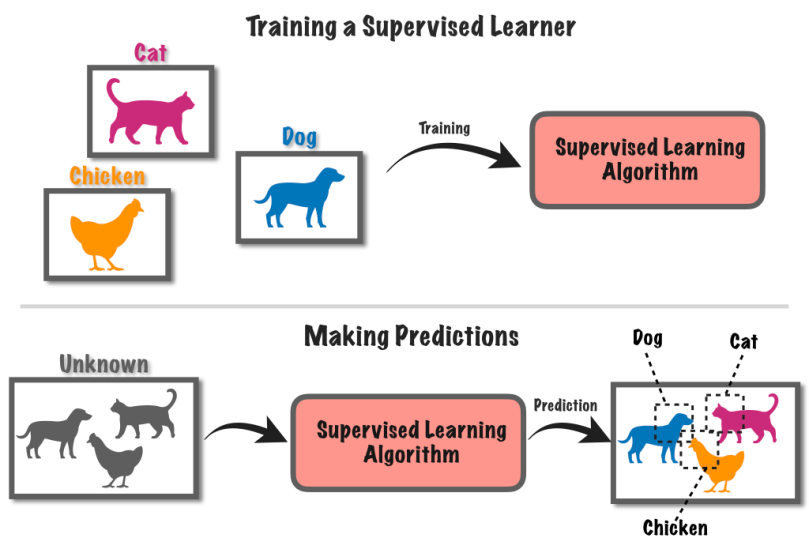
L'apprendimento supervisionato è un approccio di apprendimento automatico che prevede l'addestramento di un sistema informatico utilizzando dati etichettati. In questo metodo, al computer viene fornito un insieme di dati di input insieme a corrispondenti etichette o risultati noti.
Diciamo che hai un sacco di foto, alcune con cani e altre con gatti.
Dici al computer quali immagini hanno cani e quali hanno gatti. Il computer impara quindi a riconoscere le differenze tra cani e gatti trovando modelli nelle immagini.
Dopo aver appreso, puoi dare al computer nuove immagini e cercherà di capire se hanno cani o gatti in base a ciò che ha appreso dagli esempi etichettati. È come addestrare un computer a fare previsioni utilizzando informazioni note.
10. Apprendimento senza supervisione
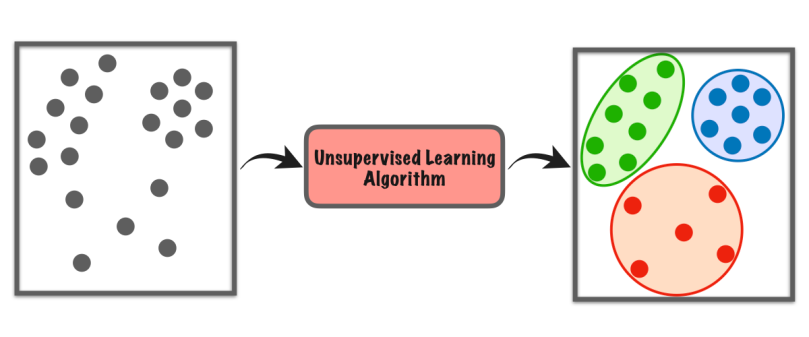
L'apprendimento non supervisionato è un tipo di apprendimento automatico in cui il computer esplora da solo un set di dati per trovare modelli o somiglianze senza istruzioni specifiche.
Non si basa su esempi etichettati come nell'apprendimento supervisionato. Cerca invece strutture o gruppi nascosti nei dati. È come se il computer stesse scoprendo le cose da solo, senza che un insegnante gli dica cosa cercare.
Questo tipo di apprendimento ci aiuta a trovare nuove intuizioni, organizzare dati o identificare cose insolite senza bisogno di conoscenze precedenti o di una guida esplicita.
11. Elaborazione del linguaggio naturale (PNL)
L'elaborazione del linguaggio naturale si concentra su come i computer comprendono e interagiscono con il linguaggio umano. Aiuta i computer ad analizzare, interpretare e rispondere al linguaggio umano in un modo che ci sembra più naturale.
La PNL è ciò che ci consente di comunicare con assistenti vocali e chatbot e persino di ordinare automaticamente le nostre e-mail in cartelle.
Implica insegnare ai computer a comprendere il significato dietro parole, frasi e persino interi testi, in modo che possano assisterci in vari compiti e rendere le nostre interazioni con la tecnologia più fluide.
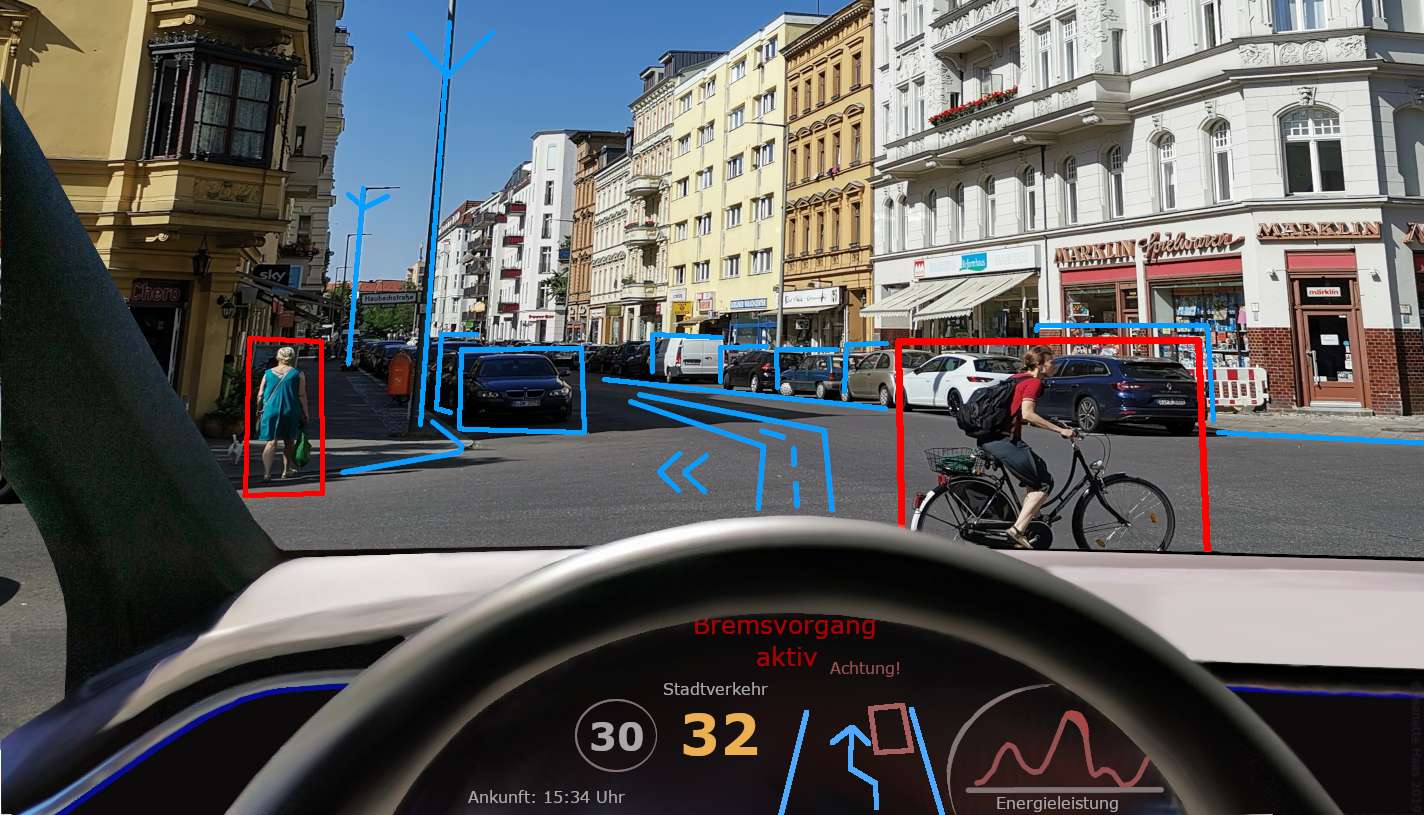
12. Visione artificiale
Visione computerizzata è un'affascinante tecnologia che consente ai computer di vedere e comprendere immagini e video, proprio come noi umani facciamo con i nostri occhi. Si tratta di insegnare ai computer ad analizzare le informazioni visive e dare un senso a ciò che vedono.
In termini più semplici, la visione artificiale aiuta i computer a riconoscere e interpretare il mondo visivo. Implica compiti come insegnare loro a identificare oggetti specifici nelle immagini, classificare le immagini in diverse categorie o persino dividere le immagini in parti significative.
Immagina un'auto a guida autonoma che utilizza la visione artificiale per "vedere" la strada e tutto ciò che la circonda.
Può rilevare e tracciare pedoni, segnali stradali e altri veicoli, aiutandoli a navigare in sicurezza. Oppure pensa a come la tecnologia di riconoscimento facciale utilizza la visione artificiale per sbloccare i nostri smartphone o verificare le nostre identità riconoscendo le nostre caratteristiche facciali uniche.
Viene anche utilizzato nei sistemi di sorveglianza per monitorare luoghi affollati e individuare eventuali attività sospette.
La visione artificiale è una potente tecnologia che apre un mondo di possibilità. Consentendo ai computer di vedere e comprendere le informazioni visive, possiamo sviluppare applicazioni e sistemi in grado di percepire e interpretare il mondo che ci circonda, rendendo le nostre vite più facili, più sicure e più efficienti.
13. chatbot
Un chatbot è come un programma per computer in grado di parlare alle persone in un modo che sembra una vera conversazione umana.
Viene spesso utilizzato nel servizio clienti online per aiutare i clienti e farli sentire come se stessero parlando con una persona, anche se in realtà è un programma in esecuzione su un computer.
Il chatbot può comprendere e rispondere a messaggi o domande dei clienti, fornendo informazioni utili e assistenza proprio come farebbe un rappresentante umano del servizio clienti.
14. Riconoscimento vocale
Il riconoscimento vocale si riferisce alla capacità di un sistema informatico di comprendere e interpretare il linguaggio umano. Coinvolge la tecnologia che consente a un computer o dispositivo di "ascoltare" le parole pronunciate e convertirle in testo o comandi comprensibili.
Con riconoscimento vocale, puoi interagire con dispositivi o applicazioni semplicemente parlando con loro invece di digitare o utilizzare altri metodi di input.
Il sistema analizza le parole pronunciate, riconosce i modelli e i suoni e quindi li traduce in testo o azioni comprensibili. Consente una comunicazione a mani libere e naturale con la tecnologia, rendendo possibili attività come comandi vocali, dettatura o interazioni a comando vocale. Gli esempi più comuni sono gli assistenti AI come Siri e Google Assistant.
15. Analisi del sentimento
Analisi del sentimento è una tecnica utilizzata per comprendere e interpretare le emozioni, le opinioni e gli atteggiamenti espressi nel testo o nel discorso. Implica l'analisi del linguaggio scritto o parlato per determinare se il sentimento espresso è positivo, negativo o neutro.
Utilizzando algoritmi di apprendimento automatico, gli algoritmi di analisi del sentimento possono scansionare e analizzare grandi quantità di dati di testo, come recensioni dei clienti, post sui social media o feedback dei clienti, per identificare il sentimento sottostante dietro le parole.
Gli algoritmi cercano parole, frasi o modelli specifici che indicano emozioni o opinioni.
Questa analisi aiuta le aziende o gli individui a capire come si sentono le persone riguardo a un prodotto, servizio o argomento e può essere utilizzata per prendere decisioni basate sui dati o ottenere informazioni sulle preferenze dei clienti.
Ad esempio, un'azienda può utilizzare l'analisi del sentiment per monitorare la soddisfazione del cliente, identificare le aree di miglioramento o monitorare l'opinione pubblica sul proprio marchio.
16. Traduzione automatica
La traduzione automatica, nel contesto dell'intelligenza artificiale, si riferisce all'uso di algoritmi informatici e intelligenza artificiale per tradurre automaticamente testo o parlato da una lingua all'altra.
Si tratta di insegnare ai computer a comprendere ed elaborare le lingue umane al fine di fornire traduzioni accurate. L'esempio più comune è Google Traduttore.
Con la traduzione automatica, puoi inserire testo o voce in una lingua e il sistema analizzerà l'input e genererà una traduzione corrispondente in un'altra lingua. Ciò è particolarmente utile quando si comunica o si accede a informazioni in diverse lingue.
I sistemi di traduzione automatica si basano su una combinazione di regole linguistiche, modelli statistici e algoritmi di apprendimento automatico. Imparano da grandi quantità di dati linguistici per migliorare l'accuratezza della traduzione nel tempo. Alcuni approcci di traduzione automatica incorporano anche reti neurali per migliorare la qualità delle traduzioni.
17. Robotica
La robotica è la combinazione di intelligenza artificiale e ingegneria meccanica per creare macchine intelligenti chiamate robot. Questi robot sono progettati per eseguire compiti in modo autonomo o con un intervento umano minimo.
I robot sono entità fisiche che possono percepire il loro ambiente, prendere decisioni basate su quell'input sensoriale ed eseguire azioni o compiti specifici.
Sono dotati di vari sensori, come fotocamere, microfoni o sensori tattili, che consentono loro di raccogliere informazioni dal mondo che li circonda. Con l'aiuto degli algoritmi e della programmazione dell'intelligenza artificiale, i robot possono analizzare questi dati, interpretarli e prendere decisioni intelligenti per eseguire i compiti designati.
L'intelligenza artificiale svolge un ruolo cruciale nella robotica consentendo ai robot di imparare dalle loro esperienze e adattarsi a situazioni diverse.
Gli algoritmi di apprendimento automatico possono essere utilizzati per addestrare i robot a riconoscere oggetti, navigare in ambienti o persino interagire con gli esseri umani. Ciò consente ai robot di diventare più versatili, flessibili e in grado di gestire compiti complessi.
18. droni
I droni sono un tipo di robot che può volare o librarsi in aria senza un pilota umano a bordo. Sono anche conosciuti come veicoli aerei senza pilota (UAV). I droni sono dotati di vari sensori, come fotocamere, GPS e giroscopi, che consentono loro di raccogliere dati e navigare nell'ambiente circostante.
Sono controllati a distanza da un operatore umano o possono funzionare autonomamente utilizzando istruzioni pre-programmate.
I droni servono a una vasta gamma di scopi, tra cui la fotografia aerea e la videografia, il rilevamento e la mappatura, i servizi di consegna, le missioni di ricerca e soccorso, il monitoraggio dell'agricoltura e persino l'uso ricreativo. Possono accedere ad aree remote o pericolose che sono difficili o pericolose per l'uomo.
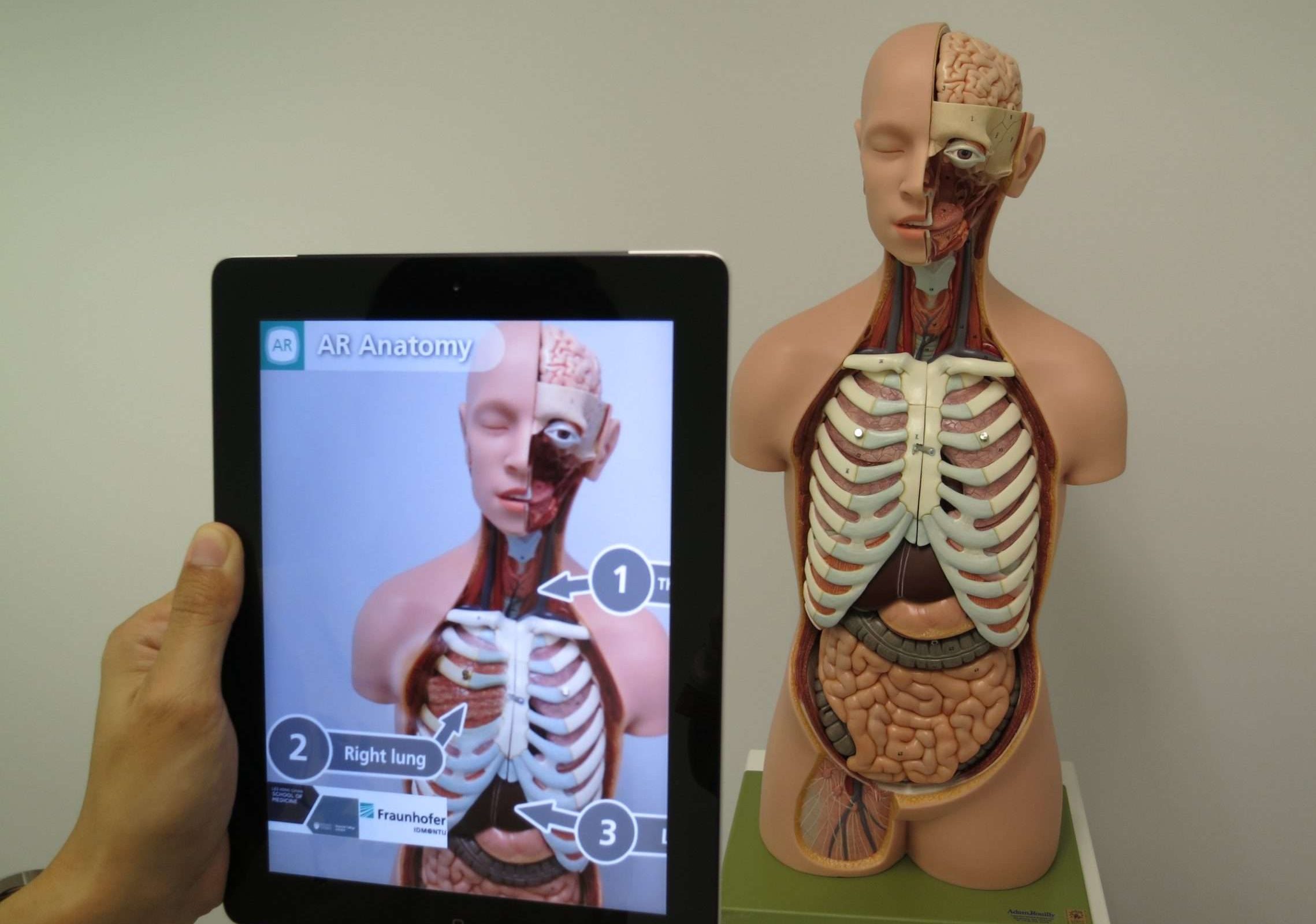
19. Realtà aumentata (AR)
La realtà aumentata (AR) è una tecnologia che combina il mondo reale con oggetti o informazioni virtuali per migliorare la nostra percezione e interazione con l'ambiente. Sovrappone immagini, suoni o altri input sensoriali generati dal computer al mondo reale, creando un'esperienza coinvolgente e interattiva.
In poche parole, immagina di indossare occhiali speciali o utilizzare il tuo smartphone per vedere il mondo intorno a te, ma con ulteriori elementi virtuali aggiunti.
Ad esempio, puoi puntare il tuo smartphone su una strada cittadina e vedere cartelli virtuali che mostrano indicazioni, valutazioni e recensioni per ristoranti nelle vicinanze o persino personaggi virtuali che interagiscono con l'ambiente reale.
Questi elementi virtuali si fondono perfettamente con il mondo reale, migliorando la comprensione e l'esperienza dell'ambiente circostante. La realtà aumentata può essere utilizzata in vari campi come i giochi, l'istruzione, l'architettura e persino per attività quotidiane come la navigazione o provare nuovi mobili in casa prima di acquistarli.
20. Realtà virtuale (VR)
La realtà virtuale (VR) è una tecnologia che utilizza simulazioni generate al computer per creare un ambiente artificiale che una persona può esplorare e con cui interagire. Immerge l'utente in un mondo virtuale, bloccando il mondo reale e sostituendolo con un regno digitale.
In poche parole, immagina di indossare un auricolare speciale che ti copra gli occhi e le orecchie e ti trasporti in un posto completamente diverso. In questo mondo virtuale, tutto ciò che vedi e senti sembra incredibilmente reale, anche se è tutto generato da un computer.
Puoi muoverti, guardare in qualsiasi direzione e interagire con oggetti o personaggi come se fossero fisicamente presenti.
Ad esempio, in un gioco di realtà virtuale, potresti trovarti all'interno di un castello medievale, dove puoi camminare attraverso i suoi corridoi, raccogliere armi e impegnarti in duelli con la spada con avversari virtuali. L'ambiente della realtà virtuale risponde ai tuoi movimenti e alle tue azioni, facendoti sentire completamente immerso e coinvolto nell'esperienza.
La realtà virtuale non viene utilizzata solo per i giochi, ma anche per varie altre applicazioni come simulazioni di addestramento per piloti, chirurghi o personale militare, procedure dettagliate architettoniche, turismo virtuale e persino terapia per determinate condizioni psicologiche. Crea un senso di presenza e trasporta gli utenti in mondi virtuali nuovi ed entusiasmanti, rendendo l'esperienza il più vicino possibile alla realtà.
21. Scienza dei dati
Scienza dei dati è un campo che prevede l'utilizzo di metodi, strumenti e algoritmi scientifici per estrarre preziose conoscenze e approfondimenti dai dati. Combina elementi di matematica, statistica, programmazione e competenze di dominio per analizzare set di dati grandi e complessi.
In termini più semplici, la scienza dei dati riguarda la ricerca di informazioni e schemi significativi nascosti all'interno di un mucchio di dati. Implica la raccolta, la pulizia e l'organizzazione dei dati, quindi l'utilizzo di varie tecniche per esplorarli e analizzarli. Data scientist utilizzare modelli statistici e algoritmi per scoprire tendenze, fare previsioni e risolvere problemi.
Ad esempio, nel campo dell'assistenza sanitaria, la scienza dei dati può essere utilizzata per analizzare le cartelle cliniche dei pazienti e i dati medici per identificare i fattori di rischio per le malattie, prevedere gli esiti dei pazienti o ottimizzare i piani di trattamento. Nel mondo degli affari, la scienza dei dati può essere applicata ai dati dei clienti per comprendere le loro preferenze, consigliare prodotti o migliorare le strategie di marketing.
22. Conflitto di dati
Il data wrangling, noto anche come data munging, è il processo di raccolta, pulizia e trasformazione dei dati grezzi in un formato più utile e adatto all'analisi. Implica la gestione e la preparazione dei dati per garantirne la qualità, la coerenza e la compatibilità con strumenti o modelli di analisi.
In termini più semplici, il data wrangling è come preparare gli ingredienti per cucinare. Implica la raccolta di dati da diverse fonti, l'ordinamento e la pulizia per rimuovere eventuali errori, incoerenze o informazioni irrilevanti.
Inoltre, potrebbe essere necessario trasformare, ristrutturare o aggregare i dati per semplificare l'utilizzo e l'estrazione di informazioni dettagliate.
Ad esempio, il data wrangling può comportare la rimozione di voci duplicate, la correzione di errori di ortografia o problemi di formattazione, la gestione di valori mancanti e la conversione di tipi di dati. Può anche comportare l'unione o l'unione di set di dati diversi, la suddivisione dei dati in sottoinsiemi o la creazione di nuove variabili basate su dati esistenti.
23. Storytelling dei dati
Narrazione dei dati è l'arte di presentare i dati in modo convincente e coinvolgente per comunicare in modo efficace una narrazione o un messaggio. Implica l'utilizzo visualizzazioni dei dati, narrazioni e contesto per trasmettere intuizioni e scoperte in modo comprensibile e memorabile per il pubblico.
In termini più semplici, il data storytelling consiste nell'utilizzare i dati per raccontare una storia. Va oltre la semplice presentazione di numeri e grafici. Implica la creazione di una narrazione attorno ai dati, utilizzando elementi visivi e tecniche di narrazione per dare vita ai dati e renderli riconoscibili per il pubblico.
Ad esempio, invece di presentare semplicemente una tabella dei dati di vendita, il data storytelling potrebbe comportare la creazione di un dashboard interattivo che consenta agli utenti di esplorare visivamente le tendenze di vendita.
Potrebbe includere una narrazione che evidenzi i risultati chiave, spieghi le ragioni alla base delle tendenze e suggerisca raccomandazioni attuabili basate sui dati.
24. Processo decisionale basato sui dati
Il processo decisionale basato sui dati è un processo di scelte o azioni basate sull'analisi e l'interpretazione di dati rilevanti. Implica l'utilizzo dei dati come base per guidare e supportare i processi decisionali piuttosto che affidarsi esclusivamente all'intuizione o al giudizio personale.
In termini più semplici, il processo decisionale basato sui dati significa utilizzare fatti e prove dai dati per informare e guidare le scelte che facciamo. Implica la raccolta e l'analisi dei dati per comprendere modelli, tendenze e relazioni e l'utilizzo di tale conoscenza per prendere decisioni informate e risolvere problemi.
Ad esempio, in un contesto aziendale, il processo decisionale basato sui dati può comportare l'analisi dei dati di vendita, il feedback dei clienti e le tendenze del mercato per determinare la strategia di prezzo più efficace o identificare le aree di miglioramento nello sviluppo del prodotto.
Nel settore sanitario, può comportare l'analisi dei dati dei pazienti per ottimizzare i piani di trattamento o prevedere gli esiti della malattia.
25. Lago di dati
Un data lake è un repository di dati centralizzato e scalabile che memorizza grandi quantità di dati nella loro forma grezza e non elaborata. È progettato per contenere un'ampia varietà di tipi, formati e strutture di dati, come dati strutturati, semi-strutturati e non strutturati, senza la necessità di schemi predefiniti o trasformazioni di dati.
Ad esempio, un'azienda può raccogliere e archiviare dati da varie fonti, come registri di siti Web, transazioni dei clienti, feed di social media e dispositivi IoT, in un data lake.
Questi dati possono quindi essere utilizzati per vari scopi, come condurre analisi avanzate, eseguire algoritmi di apprendimento automatico o esplorare modelli e tendenze nel comportamento dei clienti.
26. Magazzino dati
Un data warehouse è un sistema di database specializzato progettato specificamente per l'archiviazione, l'organizzazione e l'analisi di grandi quantità di dati provenienti da varie fonti. È strutturato in modo da supportare un efficiente recupero dei dati e query analitiche complesse.
Funge da repository centrale che integra i dati provenienti da diversi sistemi operativi, come database transazionali, sistemi CRM e altre fonti di dati all'interno di un'organizzazione.
I dati vengono trasformati, ripuliti e caricati nel data warehouse in un formato strutturato ottimizzato per scopi analitici.
27. Intelligenza aziendale (BI)
La business intelligence si riferisce al processo di raccolta, analisi e presentazione dei dati in un modo che aiuta le aziende a prendere decisioni informate e ottenere informazioni preziose. Implica l'utilizzo di vari strumenti, tecnologie e tecniche per trasformare i dati grezzi in informazioni significative e fruibili.
Ad esempio, un sistema di business intelligence potrebbe analizzare i dati di vendita per identificare i prodotti più redditizi, monitorare i livelli di inventario e tenere traccia delle preferenze dei clienti.
Può fornire approfondimenti in tempo reale su indicatori chiave di prestazione (KPI) come entrate, acquisizione di clienti o prestazioni del prodotto, consentendo alle aziende di prendere decisioni basate sui dati e intraprendere azioni appropriate per migliorare le proprie operazioni.
Gli strumenti di business intelligence spesso includono funzionalità come visualizzazione dei dati, query ad hoc e capacità di esplorazione dei dati. Questi strumenti consentono agli utenti, ad esempio analisti di business o manager, per interagire con i dati, suddividerli in sezioni e generare report o rappresentazioni visive che evidenziano intuizioni e tendenze importanti.
28. Analisi predittiva
L'analisi predittiva è la pratica di utilizzare dati e tecniche statistiche per fare previsioni o previsioni informate su eventi o risultati futuri. Implica l'analisi dei dati storici, l'identificazione di modelli e la costruzione di modelli per estrapolare e stimare tendenze, comportamenti o eventi futuri.
Ha lo scopo di scoprire le relazioni tra le variabili e utilizzare tali informazioni per fare previsioni. Va oltre la semplice descrizione di eventi passati; invece, sfrutta i dati storici per comprendere e anticipare ciò che è probabile che accada in futuro.
Ad esempio, nel campo della finanza, l'analisi predittiva può essere utilizzata per prevedere azione prezzi basati su dati storici di mercato, indicatori economici e altri fattori rilevanti.
Nel marketing, può essere impiegato per prevedere il comportamento e le preferenze dei clienti, consentendo pubblicità mirate e campagne di marketing personalizzate.
Nel settore sanitario, l'analisi predittiva può aiutare a identificare i pazienti ad alto rischio per determinate malattie o prevedere la probabilità di riammissione in base all'anamnesi e ad altri fattori.
29. Analisi prescrittiva
L'analisi prescrittiva è l'applicazione di dati e analisi per determinare le migliori azioni possibili da intraprendere in una particolare situazione o scenario decisionale.
Va oltre il descrittivo e analisi predittiva non solo fornendo approfondimenti su ciò che potrebbe accadere in futuro, ma anche raccomandando la linea d'azione più ottimale per ottenere il risultato desiderato.
Combina dati storici, modelli predittivi e tecniche di ottimizzazione per simulare diversi scenari e valutare i potenziali risultati di varie decisioni. Considera molteplici vincoli, obiettivi e fattori per generare raccomandazioni attuabili che massimizzino i risultati desiderati o riducano al minimo i rischi.
Ad esempio, in supply chain gestione, l'analisi prescrittiva può analizzare i dati sui livelli di inventario, le capacità di produzione, i costi di trasporto e la domanda dei clienti per determinare il piano di distribuzione più efficiente.
Può consigliare l'allocazione ideale delle risorse, come i luoghi di stoccaggio dell'inventario o le rotte di trasporto, per ridurre al minimo i costi e garantire consegne puntuali.
30. Marketing basato sui dati
Il marketing basato sui dati si riferisce alla pratica di utilizzare dati e analisi per guidare strategie di marketing, campagne e processi decisionali.
Implica lo sfruttamento di varie fonti di dati per ottenere informazioni dettagliate sul comportamento, le preferenze e le tendenze dei clienti e l'utilizzo di tali informazioni per ottimizzare gli sforzi di marketing.
Si concentra sulla raccolta e l'analisi dei dati da più punti di contatto, come le interazioni del sito Web, l'impegno sui social media, i dati demografici dei clienti, la cronologia degli acquisti e altro ancora. Questi dati vengono quindi utilizzati per creare una comprensione completa del pubblico di destinazione, delle sue preferenze e delle sue esigenze.
Sfruttando i dati, i professionisti del marketing possono prendere decisioni informate in merito alla segmentazione, al targeting e alla personalizzazione dei clienti.
Possono identificare segmenti di clienti specifici che hanno maggiori probabilità di rispondere positivamente alle campagne di marketing e adattare di conseguenza i loro messaggi e le loro offerte.
Inoltre, il marketing basato sui dati aiuta a ottimizzare i canali di marketing, determinare il marketing mix più efficace e misurare il successo delle iniziative di marketing.
Ad esempio, un approccio di marketing basato sui dati potrebbe comportare l'analisi dei dati dei clienti per identificare il comportamento di acquisto e i modelli di preferenze. Sulla base di queste informazioni, i professionisti del marketing possono creare campagne mirate con contenuti personalizzati e offerte che risuonano con specifici segmenti di clientela.
Attraverso l'analisi e l'ottimizzazione continue, possono misurare l'efficacia dei loro sforzi di marketing e perfezionare le strategie nel tempo.
31. Governance dei dati
La governance dei dati è il framework e l'insieme di pratiche che le organizzazioni adottano per garantire la corretta gestione, protezione e integrità dei dati durante tutto il loro ciclo di vita. Comprende i processi, le politiche e le procedure che regolano il modo in cui i dati vengono raccolti, archiviati, consultati, utilizzati e condivisi all'interno di un'organizzazione.
Mira a stabilire responsabilità, responsabilità e controllo sulle risorse di dati. Garantisce che i dati siano accurati, completi, coerenti e affidabili, consentendo alle organizzazioni di prendere decisioni informate, mantenere la qualità dei dati e soddisfare i requisiti normativi.
La governance dei dati implica la definizione di ruoli e responsabilità per la gestione dei dati, la definizione di standard e criteri per i dati e l'implementazione di processi per monitorare e applicare la conformità. Affronta vari aspetti della gestione dei dati, tra cui la privacy dei dati, la sicurezza dei dati, la qualità dei dati, la classificazione dei dati e la gestione del ciclo di vita dei dati.
Ad esempio, la governance dei dati può comportare l'implementazione di procedure per garantire che i dati personali o sensibili siano gestiti in conformità con le normative sulla privacy applicabili, come il Regolamento generale sulla protezione dei dati (GDPR).
Può anche includere la definizione di standard di qualità dei dati e l'implementazione di processi di convalida dei dati per garantire che i dati siano accurati e affidabili.
32. La sicurezza dei dati
La sicurezza dei dati riguarda la protezione delle nostre preziose informazioni da accessi non autorizzati o furti. Implica l'adozione di misure per proteggere la riservatezza, l'integrità e la disponibilità dei dati.
In sostanza, significa garantire che solo le persone giuste possano accedere ai nostri dati, che rimangano accurati e inalterati e che siano disponibili quando necessario.
Per raggiungere la sicurezza dei dati, vengono utilizzate varie strategie e tecnologie. Ad esempio, i controlli di accesso e i metodi di crittografia aiutano a limitare l'accesso a persone o sistemi autorizzati, rendendo più difficile per gli estranei l'accesso ai nostri dati.
I sistemi di monitoraggio, i firewall e i sistemi di rilevamento delle intrusioni fungono da guardiani, avvisandoci di attività sospette e impedendo l'accesso non autorizzato.
33. Internet delle cose
L'Internet of Things (IoT) si riferisce a una rete di oggetti fisici o "cose" che sono connessi a Internet e possono comunicare tra loro. È come una grande rete di oggetti, dispositivi e macchine di uso quotidiano in grado di condividere informazioni ed eseguire attività interagendo tramite Internet.
In termini semplici, l'IoT implica l'assegnazione di funzionalità "intelligenti" a vari oggetti o dispositivi che tradizionalmente non erano connessi a Internet. Questi oggetti possono includere elettrodomestici, dispositivi indossabili, termostati, automobili e persino macchinari industriali.
Collegando questi oggetti a Internet, possono raccogliere e condividere dati, ricevere istruzioni ed eseguire attività in modo autonomo o in risposta ai comandi dell'utente.
Ad esempio, un termostato intelligente può monitorare la temperatura, regolare le impostazioni e inviare rapporti sull'utilizzo dell'energia a un'app per smartphone. Un fitness tracker indossabile può raccogliere dati sulle tue attività fisiche e sincronizzarli con una piattaforma basata su cloud per l'analisi.
34. Albero decisionale
Un albero decisionale è una rappresentazione visiva o un diagramma che ci aiuta a prendere decisioni o determinare una linea di condotta basata su una serie di scelte o condizioni.
È come un diagramma di flusso che ci guida attraverso un processo decisionale prendendo in considerazione diverse opzioni e i loro potenziali risultati.
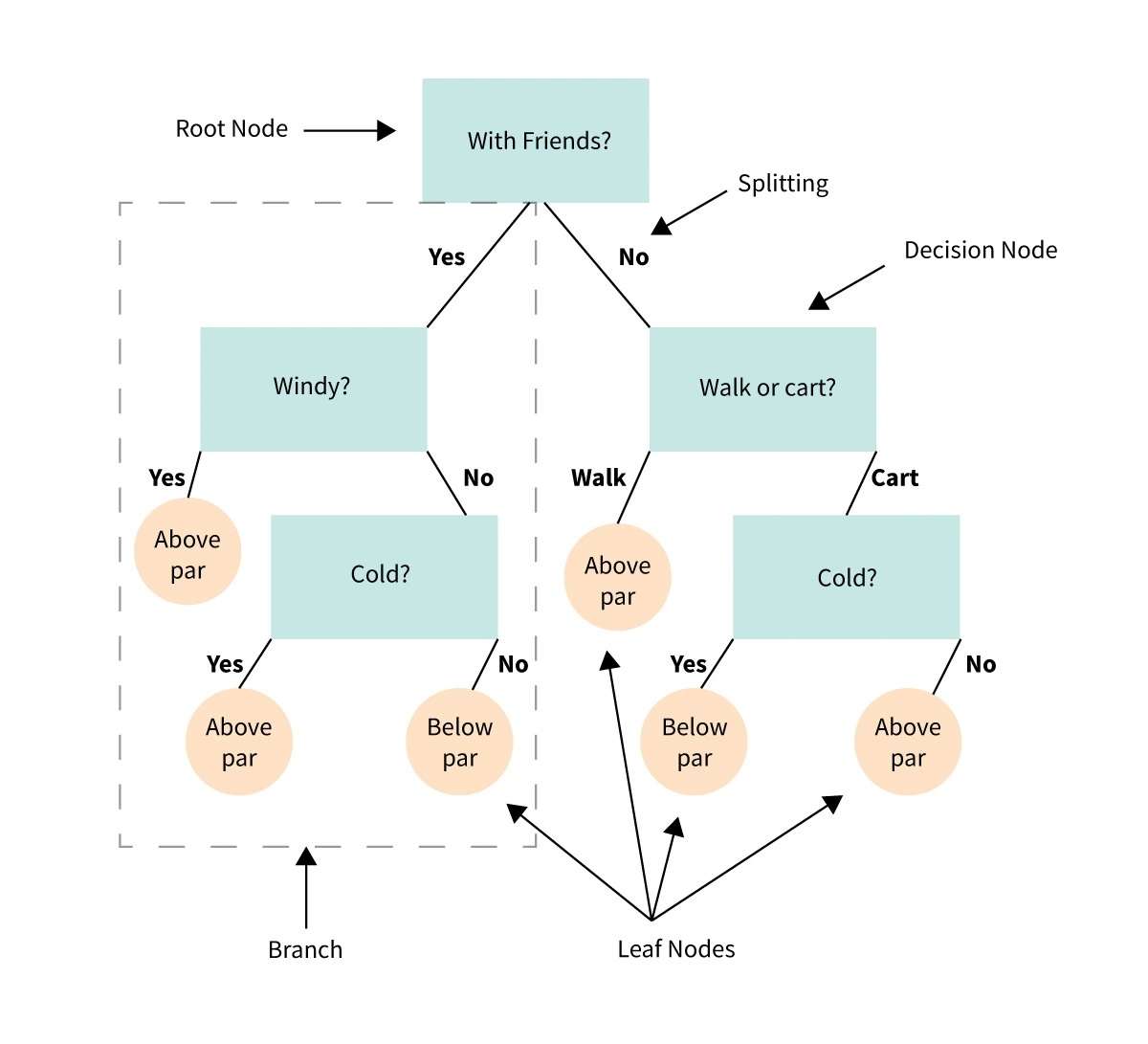
Immagina di avere un problema o una domanda e devi fare una scelta.
Un albero decisionale suddivide la decisione in passaggi più piccoli, a partire da una domanda iniziale e ramificandosi in diverse possibili risposte o azioni in base alle condizioni o ai criteri di ogni passaggio.
35. Informatica cognitiva
Il calcolo cognitivo, in termini semplici, si riferisce a sistemi o tecnologie informatiche che imitano le capacità cognitive umane, come l'apprendimento, il ragionamento, la comprensione e la risoluzione dei problemi.
Implica la creazione di sistemi informatici in grado di elaborare e interpretare le informazioni in un modo che assomiglia al pensiero umano.
Il calcolo cognitivo mira a sviluppare macchine in grado di comprendere e interagire con gli esseri umani in modo più naturale e intelligente. Questi sistemi sono progettati per analizzare grandi quantità di dati, riconoscere modelli, fare previsioni e fornire approfondimenti significativi.
Pensa al cognitive computing come a un tentativo di far pensare e agire i computer più come gli umani.
Implica lo sfruttamento di tecnologie come l'intelligenza artificiale, l'apprendimento automatico, l'elaborazione del linguaggio naturale e la visione artificiale per consentire ai computer di eseguire attività tradizionalmente associate all'intelligenza umana.
36. Teoria dell'apprendimento computazionale
La teoria dell'apprendimento computazionale è una branca specializzata nel regno dell'intelligenza artificiale che ruota attorno allo sviluppo e all'esame di algoritmi specificamente progettati per apprendere dai dati.
Questo campo esplora varie tecniche e metodologie per la costruzione di algoritmi in grado di migliorare autonomamente le proprie prestazioni analizzando ed elaborando grandi quantità di informazioni.
Sfruttando la potenza dei dati, la Teoria dell'apprendimento computazionale mira a scoprire modelli, relazioni e intuizioni che consentono alle macchine di migliorare le proprie capacità decisionali e di eseguire le attività in modo più efficiente.
L'obiettivo finale è creare algoritmi in grado di adattarsi, generalizzare e fare previsioni accurate sulla base dei dati a cui sono stati esposti, contribuendo al progresso dell'intelligenza artificiale e delle sue applicazioni pratiche.
37. Prova di Turing
Il test di Turing, originariamente proposto dal brillante matematico e scienziato informatico Alan Turing, è un concetto accattivante utilizzato per valutare se una macchina può esibire un comportamento intelligente paragonabile o praticamente indistinguibile da quello di un essere umano.
Nel test di Turing, un valutatore umano si impegna in una conversazione in linguaggio naturale sia con una macchina che con un altro partecipante umano senza sapere quale sia la macchina.
Il ruolo del valutatore è discernere quale entità è la macchina esclusivamente in base alle sue risposte. Se la macchina è in grado di convincere il valutatore che è la controparte umana, allora si dice che abbia superato il test di Turing, dimostrando così un livello di intelligenza che rispecchia le capacità umane.
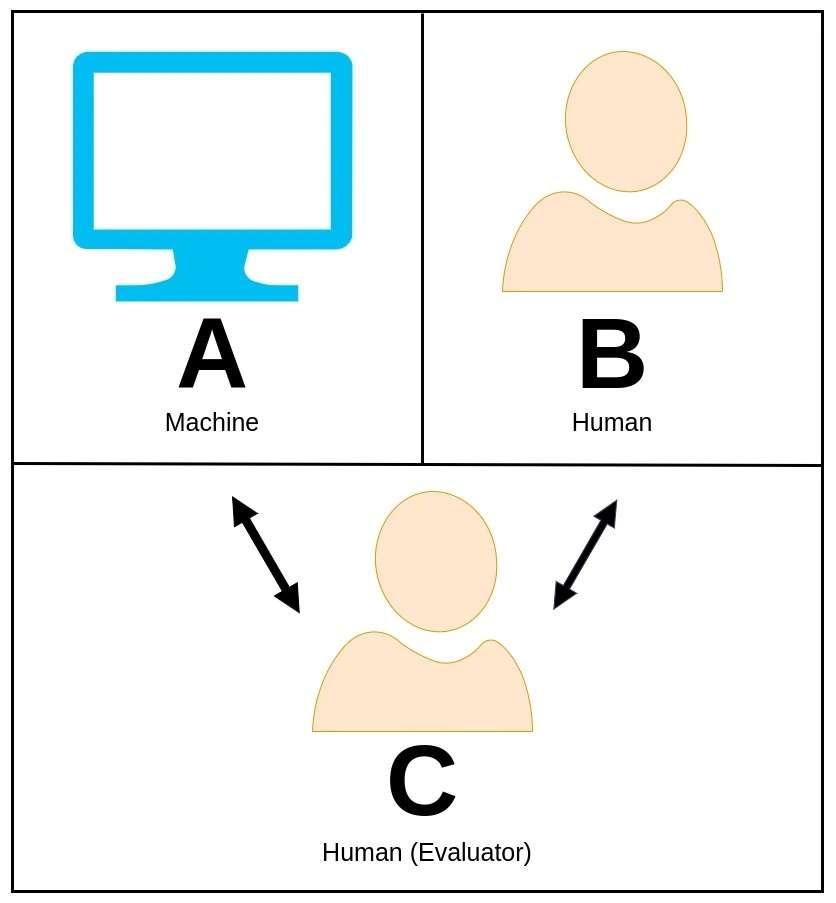
Alan Turing ha proposto questo test come mezzo per esplorare il concetto di intelligenza delle macchine e per porre la questione se le macchine possano raggiungere una cognizione a livello umano.
Inquadrando il test in termini di indistinguibilità umana, Turing ha evidenziato il potenziale per le macchine di esibire un comportamento così convincentemente intelligente che diventa difficile differenziarle dagli umani.
Il test di Turing ha suscitato ampie discussioni e ricerche nei campi dell'intelligenza artificiale e delle scienze cognitive. Sebbene il superamento del test di Turing rimanga una pietra miliare significativa, non è l'unica misura dell'intelligenza.
Tuttavia, il test funge da punto di riferimento stimolante, stimolando gli sforzi in corso per sviluppare macchine in grado di emulare intelligenza e comportamento simili a quelli umani e contribuendo alla più ampia esplorazione di cosa significhi essere intelligenti.
38. Apprendimento per rinforzo
Insegnamento rafforzativo è un tipo di apprendimento che avviene attraverso tentativi ed errori, in cui un "agente" (che può essere un programma per computer o un robot) impara a svolgere compiti ricevendo ricompense per un buon comportamento e affrontando le conseguenze o le punizioni per un cattivo comportamento.
Immagina uno scenario in cui l'agente sta tentando di completare un'attività specifica, come navigare in un labirinto. All'inizio, l'agente non conosce il percorso corretto da intraprendere, quindi prova diverse azioni ed esplora vari percorsi.
Quando sceglie una buona azione che lo avvicina all'obiettivo, riceve una ricompensa, come una "pacca sulla spalla" virtuale. Tuttavia, se prende una decisione sbagliata che porta a un vicolo cieco o lo allontana dall'obiettivo, riceve una punizione o un feedback negativo.
Attraverso questo processo di tentativi ed errori, l'agente impara ad associare determinate azioni a risultati positivi o negativi. Capisce gradualmente la migliore sequenza di azioni per massimizzare le sue ricompense e ridurre al minimo le punizioni, diventando infine più abile nel compito.
L'apprendimento per rinforzo trae ispirazione dal modo in cui gli esseri umani e gli animali apprendono ricevendo feedback dall'ambiente.
Applicando questo concetto alle macchine, i ricercatori mirano a sviluppare sistemi intelligenti in grado di apprendere e adattarsi a diverse situazioni scoprendo autonomamente i comportamenti più efficaci attraverso un processo di rinforzo positivo e conseguenze negative.
39. Estrazione di entità
L'estrazione di entità si riferisce a un processo in cui identifichiamo ed estraiamo informazioni importanti, note come entità, da un blocco di testo. Queste entità possono essere varie cose come i nomi delle persone, i nomi dei luoghi, i nomi delle organizzazioni e così via.
Immaginiamo di avere un paragrafo che descrive un articolo di notizie.
L'estrazione di entità comporterebbe l'analisi del testo e la selezione di bit specifici che rappresentano entità distinte. Ad esempio, se il testo menziona il nome di una persona come "John Smith", il luogo "New York City" o l'organizzazione "OpenAI", queste sarebbero le entità che miriamo a identificare ed estrarre.
Eseguendo l'estrazione di entità, stiamo essenzialmente insegnando a un programma per computer a riconoscere e isolare elementi significativi dal testo. Questo processo ci consente di organizzare e classificare le informazioni in modo più efficiente, semplificando la ricerca, l'analisi e la derivazione di approfondimenti da grandi volumi di dati testuali.
Nel complesso, l'estrazione di entità ci aiuta ad automatizzare il compito di individuare entità importanti, come persone, luoghi e organizzazioni, all'interno del testo, semplificando l'estrazione di informazioni preziose e migliorando la nostra capacità di elaborare e comprendere i dati testuali.
40. Annotazione linguistica
L'annotazione linguistica comporta l'arricchimento del testo con informazioni linguistiche aggiuntive per migliorare la nostra comprensione e analisi della lingua utilizzata. È come aggiungere utili etichette o tag a diverse parti di un testo.
Quando eseguiamo l'annotazione linguistica, andiamo oltre le parole e le frasi di base in un testo e iniziamo a etichettare o etichettare elementi specifici. Ad esempio, potremmo aggiungere tag di parte del discorso, che indicano la categoria grammaticale di ogni parola (come sostantivo, verbo, aggettivo, ecc.). Questo ci aiuta a capire il ruolo che ogni parola gioca in una frase.
Un'altra forma di annotazione linguistica è il riconoscimento di entità denominate, in cui identifichiamo ed etichettiamo entità denominate specifiche, come nomi di persone, luoghi, organizzazioni o date. Questo ci consente di individuare ed estrarre rapidamente informazioni importanti dal testo.
Annotando il testo in questi modi, creiamo una rappresentazione più strutturata e organizzata della lingua. Questo può essere immensamente utile in una varietà di applicazioni. Ad esempio, aiuta a migliorare l'accuratezza dei motori di ricerca comprendendo l'intento dietro le query degli utenti. Assiste anche nella traduzione automatica, nell'analisi dei sentimenti, nell'estrazione di informazioni e in molte altre attività di elaborazione del linguaggio naturale.
L'annotazione linguistica funge da strumento vitale per ricercatori, linguisti e sviluppatori, consentendo loro di studiare modelli linguistici, costruire modelli linguistici e sviluppare algoritmi sofisticati in grado di analizzare e comprendere meglio il testo.
41. Iperparametro
In machine learning, un iperparametro è come un'impostazione o configurazione speciale che dobbiamo decidere prima di eseguire il training di un modello. Non è qualcosa che il modello può apprendere da solo dai dati; invece, dobbiamo determinarlo in anticipo.
Pensalo come una manopola o un interruttore che possiamo regolare per mettere a punto il modo in cui il modello apprende e fa previsioni. Questi iperparametri governano vari aspetti del processo di apprendimento, come la complessità del modello, la velocità di addestramento e il compromesso tra accuratezza e generalizzazione.
Ad esempio, consideriamo una rete neurale. Un importante iperparametro è il numero di livelli nella rete. Dobbiamo scegliere quanto profonda vogliamo che sia la rete, e questa decisione influisce sulla sua capacità di catturare schemi complessi nei dati.
Altri iperparametri comuni includono il tasso di apprendimento, che determina la velocità con cui il modello regola i propri parametri interni in base ai dati di addestramento, e la forza di regolarizzazione, che controlla quanto il modello penalizza i modelli complessi per evitare l'overfitting.
L'impostazione corretta di questi iperparametri è fondamentale perché possono influire in modo significativo sulle prestazioni e sul comportamento del modello. Spesso comporta un po' di prove ed errori, sperimentando valori diversi e osservando come influenzano le prestazioni del modello su un set di dati di convalida.
42. Metadati
I metadati si riferiscono a informazioni aggiuntive che forniscono dettagli su altri dati. È come un insieme di tag o etichette che ci danno più contesto o descrivono le caratteristiche dei dati principali.
Quando disponiamo di dati, che si tratti di un documento, una fotografia, un video o qualsiasi altro tipo di informazione, i metadati ci aiutano a comprendere aspetti importanti di tali dati.
Ad esempio, in un documento, i metadati possono includere dettagli come il nome dell'autore, la data di creazione o il formato del file. Nel caso di una fotografia, i metadati potrebbero dirci il luogo in cui è stata scattata, le impostazioni della fotocamera utilizzate o anche la data e l'ora in cui è stata scattata.
I metadati ci aiutano a organizzare, cercare e interpretare i dati in modo più efficace. Aggiungendo queste informazioni descrittive, possiamo trovare rapidamente file specifici o comprenderne l'origine, lo scopo o il contesto senza dover scavare nell'intero contenuto.
43. Riduzione della dimensionalità
La riduzione della dimensionalità è una tecnica utilizzata per semplificare un set di dati riducendo il numero di caratteristiche o variabili che contiene. È come condensare o riassumere le informazioni in un set di dati per renderlo più gestibile e più facile da utilizzare.
Immagina di avere un set di dati con numerose colonne o attributi che rappresentano diverse caratteristiche dei punti dati. Ogni colonna aumenta la complessità e i requisiti computazionali degli algoritmi di machine learning.
In alcuni casi, avere un numero elevato di dimensioni può rendere difficile trovare modelli o relazioni significativi nei dati.
La riduzione della dimensionalità aiuta a risolvere questo problema trasformando il set di dati in una rappresentazione di dimensioni inferiori conservando quante più informazioni pertinenti possibili. Mira a catturare gli aspetti o le variazioni più importanti nei dati scartando dimensioni ridondanti o meno informative.
44. Classificazione del testo
La classificazione del testo è un processo che comporta l'assegnazione di etichette o categorie specifiche a blocchi di testo in base al loro contenuto o significato. È come ordinare o organizzare le informazioni testuali in diversi gruppi o classi per facilitare ulteriori analisi o decisioni.
Consideriamo un esempio di classificazione della posta elettronica. In questo scenario, vogliamo determinare se un'e-mail in arrivo è spam o non spam (nota anche come ham). Classificazione del testo gli algoritmi analizzano il contenuto dell'e-mail e gli assegnano un'etichetta di conseguenza.
Se l'algoritmo determina che l'e-mail presenta caratteristiche comunemente associate allo spam, assegna l'etichetta "spam". Al contrario, se l'email appare legittima e non spam, assegna l'etichetta "non spam" o "ham".
La classificazione del testo trova applicazioni in vari domini oltre al filtraggio della posta elettronica. Viene utilizzato nell'analisi del sentiment per determinare il sentimento espresso nelle recensioni dei clienti (positivo, negativo o neutro).
Gli articoli di notizie possono essere classificati in diversi argomenti o categorie come sport, politica, intrattenimento e altro. I registri delle chat dell'assistenza clienti possono essere classificati in base all'intento o al problema da risolvere.
45. IA debole
L'intelligenza artificiale debole, nota anche come intelligenza artificiale ristretta, si riferisce a sistemi di intelligenza artificiale progettati e programmati per eseguire compiti o funzioni specifici. A differenza dell'intelligenza umana, che comprende un'ampia gamma di capacità cognitive, l'IA debole è limitata a un particolare dominio o compito.
Pensa all'intelligenza artificiale debole come software o macchine specializzati che eccellono nell'esecuzione di lavori specifici. Ad esempio, è possibile creare un programma di intelligenza artificiale per giocare a scacchi per analizzare le situazioni di gioco, elaborare strategie e competere contro giocatori umani.
Un altro esempio è un sistema di riconoscimento delle immagini in grado di identificare oggetti in fotografie o video.
Questi sistemi di intelligenza artificiale sono addestrati e ottimizzati per eccellere nelle loro specifiche aree di competenza. Si basano su algoritmi, dati e regole predefinite per svolgere i propri compiti in modo efficace.
Tuttavia, non possiedono un'intelligenza generale che consenta loro di comprendere o eseguire compiti al di fuori del loro dominio designato.
46. IA forte
L'intelligenza artificiale forte, nota anche come intelligenza artificiale generale o intelligenza artificiale generale (AGI), si riferisce a una forma di intelligenza artificiale che possiede la capacità di comprendere, apprendere ed eseguire qualsiasi attività intellettuale che un essere umano può fare.
A differenza dell'IA debole, progettata per compiti specifici, l'IA forte mira a replicare l'intelligenza e le capacità cognitive simili a quelle umane. Si sforza di creare macchine o software che non solo eccellono in compiti specializzati, ma possiedano anche una più ampia comprensione e adattabilità per affrontare una vasta gamma di sfide intellettuali.
L'obiettivo dell'IA forte è sviluppare sistemi in grado di ragionare, comprendere informazioni complesse, imparare dall'esperienza, impegnarsi in conversazioni in linguaggio naturale, mostrare creatività ed esibire altre qualità associate all'intelligenza umana.
In sostanza, aspira a creare sistemi di intelligenza artificiale in grado di simulare o replicare il pensiero e la risoluzione dei problemi a livello umano in più domini.
47. Concatenamento in avanti
Il forward chaining è un metodo di ragionamento o logica che inizia con i dati disponibili e li utilizza per fare inferenze e trarre nuove conclusioni. È come collegare i punti utilizzando le informazioni a portata di mano per andare avanti e raggiungere ulteriori approfondimenti.
Immagina di avere una serie di regole o fatti e di voler ricavare nuove informazioni o raggiungere conclusioni specifiche basate su di esse. Il concatenamento in avanti funziona esaminando i dati iniziali e applicando regole logiche per generare ulteriori fatti o conclusioni.
Per semplificare, consideriamo un semplice scenario per determinare cosa indossare in base alle condizioni meteorologiche. Hai una regola che dice: "Se piove, porta un ombrello" e un'altra regola che dice: "Se fa freddo, indossa una giacca". Ora, se osservi che sta davvero piovendo, puoi usare il concatenamento in avanti per dedurre che dovresti portare un ombrello.
48. Concatenamento all'indietro
Il concatenamento all'indietro è un metodo di ragionamento che inizia con una conclusione o un obiettivo desiderati e lavora all'indietro per determinare i dati o i fatti necessari per supportare tale conclusione. È come seguire i tuoi passi dal risultato desiderato alle informazioni iniziali necessarie per raggiungerlo.
Per comprendere il concatenamento all'indietro, consideriamo un semplice esempio. Supponiamo che tu voglia determinare se è adatto per fare una nuotata. La conclusione desiderata è se il nuoto sia appropriato o meno in base a determinate condizioni.
Invece di iniziare con le condizioni, il concatenamento all'indietro inizia con la conclusione e lavora all'indietro per trovare i dati di supporto.
In questo caso, il concatenamento all'indietro comporterebbe porre domande come "Fa caldo?" Se la risposta è sì, allora chiederesti: "C'è una piscina disponibile?" Se la risposta è di nuovo sì, faresti ulteriori domande come "C'è abbastanza tempo per andare a nuotare?"
Rispondendo in modo iterativo a queste domande e lavorando a ritroso, è possibile determinare le condizioni necessarie che devono essere soddisfatte per supportare la conclusione di fare una nuotata.
49. Euristica
Un'euristica, in termini semplici, è una regola pratica o una strategia che ci aiuta a prendere decisioni o risolvere problemi, di solito sulla base delle nostre esperienze o intuizioni passate. È come una scorciatoia mentale che ci consente di trovare rapidamente una soluzione ragionevole senza passare attraverso un processo lungo o esaustivo.
Di fronte a situazioni o compiti complessi, le euristiche fungono da principi guida o "regole empiriche" che semplificano il processo decisionale. Ci forniscono linee guida generali o strategie che sono spesso efficaci in determinate situazioni, anche se potrebbero non garantire la soluzione ottimale.
Ad esempio, consideriamo un'euristica per trovare un parcheggio in un'area affollata. Invece di analizzare meticolosamente ogni posto disponibile, potresti fare affidamento sull'euristica della ricerca di auto parcheggiate con i motori accesi.
Questa euristica presuppone che queste auto stiano per partire, aumentando le possibilità di trovare un posto disponibile.
50. Modellazione del linguaggio naturale
La modellazione del linguaggio naturale, in termini semplici, è il processo di addestramento dei modelli di computer per comprendere e generare il linguaggio umano in un modo simile a come comunicano gli esseri umani. Implica insegnare ai computer a elaborare, interpretare e generare testo in modo naturale e significativo.
L'obiettivo della modellazione del linguaggio naturale è consentire ai computer di comprendere e generare il linguaggio umano in modo fluido, coerente e contestualmente rilevante.
Implica l'addestramento di modelli su grandi quantità di dati testuali, come libri, articoli o conversazioni, per apprendere i modelli, le strutture e la semantica del linguaggio.
Una volta addestrati, questi modelli possono eseguire varie attività relative alla lingua, come la traduzione in lingua, il riepilogo del testo, la risposta alle domande, le interazioni con i chatbot e altro ancora.
Possono comprendere il significato e il contesto delle frasi, estrarre informazioni rilevanti e generare testi grammaticalmente corretti e coerenti.





Lascia un Commento