Ini adalah tugas penting dan diinginkan dalam visi komputer dan grafis untuk menghasilkan film potret kreatif kaliber tertinggi.
Meskipun beberapa model efektif untuk toonifikasi gambar potret berdasarkan StyleGAN yang kuat telah diusulkan, teknik berorientasi gambar ini memiliki kelemahan yang jelas saat digunakan dengan video, seperti ukuran bingkai tetap, persyaratan untuk perataan wajah, tidak adanya detail non-wajah. , dan inkonsistensi temporal.
Kerangka kerja VToonify revolusioner digunakan untuk menangani transfer gaya video potret resolusi tinggi yang sulit dikontrol.
Kami akan memeriksa studi terbaru tentang VToonify dalam artikel ini, termasuk fungsionalitasnya, kekurangannya, dan faktor lainnya.
Apa itu Vtoonify?
Kerangka kerja VToonify memungkinkan transmisi gaya video potret resolusi tinggi yang dapat disesuaikan.
VToonify menggunakan lapisan resolusi menengah dan tinggi StyleGAN untuk membuat potret artistik berkualitas tinggi berdasarkan karakteristik konten multi-skala yang diambil oleh encoder untuk mempertahankan detail bingkai.
Arsitektur konvolusi penuh yang dihasilkan mengambil wajah yang tidak sejajar dalam film ukuran variabel sebagai input, menghasilkan wilayah seluruh wajah dengan gerakan realistis dalam output.

Kerangka kerja ini kompatibel dengan model toonifikasi gambar berbasis StyleGAN saat ini, memungkinkannya diperluas ke toonifikasi video, dan mewarisi karakteristik menarik seperti penyesuaian warna dan intensitas yang dapat disesuaikan.
Kredensial mikro belajar memperkenalkan dua instantiasi VToonify berdasarkan Toonify dan DualStyleGAN masing-masing untuk transfer gaya video potret berbasis koleksi dan berbasis contoh.
Temuan eksperimental yang luas menunjukkan bahwa kerangka kerja VToonify yang diusulkan mengungguli pendekatan yang ada dalam membuat film potret artistik yang koheren dan berkualitas tinggi dengan parameter gaya variabel.
Peneliti memberikan Buku catatan Google Colab, sehingga Anda bisa mengotori tangan Anda.
Bagaimana cara kerjanya?
Untuk mencapai transfer gaya video potret resolusi tinggi yang dapat disesuaikan, VToonify menggabungkan keunggulan kerangka terjemahan gambar dengan kerangka kerja berbasis StyleGAN.
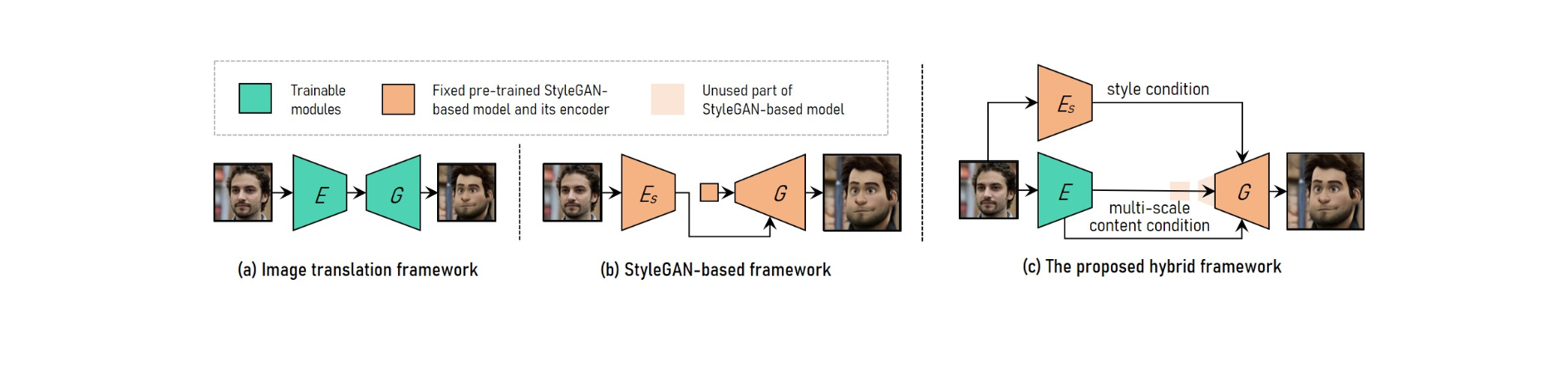
Untuk mengakomodasi berbagai ukuran input, sistem terjemahan gambar menggunakan jaringan konvolusi penuh. Pelatihan dari awal, di sisi lain, membuat transmisi gaya resolusi tinggi dan terkontrol menjadi tidak mungkin.
Model StyleGAN pra-terlatih digunakan dalam kerangka berbasis StyleGAN untuk resolusi tinggi dan transfer gaya terkontrol, meskipun terbatas pada ukuran gambar tetap dan kehilangan detail.
StyleGAN dimodifikasi dalam kerangka kerja hibrid dengan menghapus fitur masukan berukuran tetap dan lapisan beresolusi rendah, menghasilkan arsitektur encoder-generator yang sepenuhnya konvolusi serupa dengan kerangka kerja terjemahan gambar.
Untuk mempertahankan detail bingkai, latih encoder untuk mengekstrak karakteristik konten multi-skala dari bingkai input sebagai persyaratan konten tambahan ke generator. Vtoonify mewarisi fleksibilitas kontrol gaya model StyleGAN dengan memasukkannya ke dalam generator untuk menyaring data dan modelnya.
Batasan StyleGAN & Usulan Vtoonify
Potret artistik umum dalam kehidupan kita sehari-hari serta dalam bisnis kreatif seperti seni, media sosial avatar, film, iklan hiburan, dan sebagainya.
Dengan perkembangan belajar mendalam teknologi, sekarang dimungkinkan untuk membuat potret artistik berkualitas tinggi dari foto wajah kehidupan nyata menggunakan transfer gaya potret otomatis.
Ada berbagai cara sukses yang dibuat untuk transfer gaya berbasis gambar, banyak di antaranya mudah diakses oleh pengguna pemula dalam bentuk aplikasi seluler. Materi video dengan cepat menjadi andalan feed media sosial kami selama beberapa tahun terakhir.
Maraknya media sosial dan film fana telah meningkatkan permintaan untuk pengeditan video yang inovatif, seperti transfer gaya video potret, untuk menghasilkan video yang sukses dan menarik.
Teknik berorientasi gambar yang ada memiliki kelemahan yang signifikan ketika diterapkan pada film, membatasi kegunaannya dalam stilisasi video potret otomatis.
StyleGAN adalah tulang punggung umum untuk mengembangkan model transfer gaya gambar potret karena kapasitasnya untuk membuat wajah berkualitas tinggi dengan manajemen gaya yang dapat disesuaikan.
Sistem berbasis StyleGAN (juga dikenal sebagai toonifikasi gambar) mengkodekan wajah asli ke dalam ruang laten StyleGAN dan kemudian menerapkan kode gaya yang dihasilkan ke StyleGAN lain yang disempurnakan pada kumpulan data potret artistik untuk membuat versi bergaya.
StyleGAN membuat gambar dengan wajah sejajar dan pada ukuran tetap, yang tidak mendukung wajah dinamis dalam rekaman dunia nyata. Pemotongan wajah dan penyelarasan dalam video terkadang menghasilkan wajah sebagian dan gerakan canggung. Para peneliti menyebut masalah ini sebagai 'pembatasan tanaman tetap' StyleGAN.
Untuk wajah yang tidak sejajar, StyleGAN3 telah diusulkan; namun, ini hanya mendukung ukuran gambar yang ditetapkan.
Lebih jauh, sebuah penelitian baru-baru ini menemukan bahwa pengkodean wajah yang tidak sejajar lebih menantang daripada wajah yang disejajarkan. Encoding wajah yang salah berbahaya bagi transfer gaya potret, yang mengakibatkan masalah seperti perubahan identitas dan komponen yang hilang dalam bingkai yang direkonstruksi dan ditata.
Seperti yang telah dibahas, teknik yang efisien untuk transfer gaya video potret harus menangani masalah berikut:
- Untuk mempertahankan gerakan realistis, pendekatan harus mampu menangani wajah yang tidak sejajar dan ukuran video yang bervariasi. Ukuran video besar, atau sudut pandang lebar, dapat menangkap lebih banyak informasi sekaligus menjaga wajah agar tidak keluar dari bingkai.
- Untuk bersaing dengan gadget HD yang umum digunakan saat ini, video resolusi tinggi diperlukan.
- Kontrol gaya yang fleksibel harus ditawarkan kepada pengguna untuk mengubah dan memilih pilihan mereka saat mengembangkan sistem interaksi pengguna yang realistis.
Untuk tujuan itu, para peneliti menyarankan VToonify, kerangka kerja hibrida baru untuk toonifikasi video. Untuk mengatasi kendala tanaman tetap, peneliti pertama mempelajari kesetaraan terjemahan di StyleGAN.
VToonify menggabungkan manfaat arsitektur berbasis StyleGAN dan kerangka terjemahan gambar untuk mencapai transfer gaya video potret resolusi tinggi yang dapat disesuaikan.
Berikut ini adalah kontribusi utama:
- Para peneliti menyelidiki kendala tanaman tetap StyleGAN dan mengusulkan solusi berdasarkan kesetaraan terjemahan.
- Para peneliti menghadirkan kerangka kerja VToonify yang sepenuhnya konvolusional unik untuk transfer gaya video potret resolusi tinggi yang terkontrol yang mendukung wajah yang tidak sejajar dan ukuran video yang berbeda.
- Para peneliti membangun VToonify pada tulang punggung Toonify dan DualStyleGAN dan menyingkat tulang punggung dalam hal data dan model untuk memungkinkan transfer gaya video potret berbasis koleksi dan contoh.
Membandingkan Vtoonify dengan model canggih lainnya
Toonifikasi
Ini berfungsi sebagai dasar untuk transfer gaya berbasis koleksi pada wajah yang disejajarkan menggunakan StyleGAN. Untuk mengambil kode gaya, peneliti harus menyelaraskan wajah dan memotong 256256 foto untuk PSP. Toonify digunakan untuk menghasilkan hasil bergaya dengan kode gaya 1024*1024.
Akhirnya, mereka menyelaraskan kembali hasil dalam video ke lokasi aslinya. Area yang tidak bergaya telah disetel ke hitam.

Gaya GandaGAN
Ini adalah tulang punggung untuk transfer gaya berbasis teladan berdasarkan StyleGAN. Mereka menggunakan teknik pra dan pasca pemrosesan data yang sama dengan Toonify.
Pix2pixHD
Ini adalah model terjemahan gambar-ke-gambar yang biasanya digunakan untuk menyingkat model yang sudah terlatih untuk pengeditan resolusi tinggi. Itu dilatih menggunakan data berpasangan.
Peneliti menggunakan pix2pixHD sebagai input peta instance tambahan karena menggunakan peta parsing yang diekstraksi.
Gerak Orde Pertama
FOM adalah model animasi gambar yang khas. Itu dilatih pada 256256 gambar dan berkinerja buruk dengan ukuran gambar lainnya. Akibatnya, peneliti pertama-tama menskalakan bingkai video ke 256*256 untuk FOM ke animasi dan kemudian mengubah ukuran hasilnya ke ukuran aslinya.
Untuk perbandingan yang adil, FOM menggunakan bingkai bergaya pertama dari pendekatannya sebagai gambar gaya referensi.
daGAN
Ini adalah model animasi wajah 3D. Mereka menggunakan persiapan data dan metode pascapemrosesan yang sama seperti FOM.

Kelebihan
- Ini dapat digunakan dalam seni, avatar media sosial, film, iklan hiburan, dan sebagainya.
- Vtoonify juga dapat digunakan di metaverse.
keterbatasan
- Metodologi ini mengekstrak data dan model dari tulang punggung berbasis StyleGAN, menghasilkan bias data dan model.
- Artefak sebagian besar disebabkan oleh perbedaan ukuran antara bagian wajah yang distilasi dan bagian lainnya.
- Strategi ini kurang berhasil ketika berhadapan dengan hal-hal di wilayah wajah.
Kesimpulan
Terakhir, VToonify adalah kerangka kerja untuk toonifikasi video resolusi tinggi yang dikontrol gaya.
Kerangka kerja ini mencapai kinerja luar biasa dalam menangani video dan memungkinkan kontrol luas atas gaya struktural, gaya warna, dan tingkat gaya dengan memadatkan model toonifikasi gambar berbasis StyleGAN baik dari segi data sintetis dan struktur jaringan.





Tinggalkan Balasan