Համակարգչային տեսողության և գրաֆիկայի մեջ վճռորոշ և ցանկալի խնդիր է ամենաբարձր տրամաչափի ստեղծագործական դիմանկարային ֆիլմեր արտադրելը:
Թեև առաջարկվել են մի քանի արդյունավետ մոդելներ՝ հիմնված հզոր StyleGAN-ի վրա, պատկերի վրա հիմնված այս տեխնիկան ունի հստակ թերություններ, երբ օգտագործվում է տեսանյութերի հետ, ինչպիսիք են ֆիքսված շրջանակի չափը, դեմքի հավասարեցման պահանջը, ոչ դեմքի մանրամասների բացակայությունը: , և ժամանակային անհամապատասխանություն։
Հեղափոխական VToonify շրջանակն օգտագործվում է դժվար վերահսկվող բարձր լուծաչափով դիմանկարային վիդեո ոճի փոխանցումը լուծելու համար:
Մենք կուսումնասիրենք VToonify-ի ամենավերջին ուսումնասիրությունը այս հոդվածում, ներառյալ դրա ֆունկցիոնալությունը, թերությունները և այլ գործոններ:
Ինչ է Vtoonify-ը:
VToonify շրջանակը թույլ է տալիս կարգավորելի բարձր լուծաչափով դիմանկարային տեսանյութերի փոխանցում:
VToonify-ն օգտագործում է StyleGAN-ի միջին և բարձր լուծաչափի շերտերը՝ ստեղծելու բարձրորակ գեղարվեստական դիմանկարներ՝ հիմնված բազմամասշտաբ բովանդակության բնութագրերի վրա, որոնք վերցված են կոդավորիչի կողմից՝ շրջանակի մանրամասները պահպանելու համար:
Արդյունքում ստացված ամբողջովին կոնվոլյուցիոն ճարտարապետությունը որպես մուտքագրում է ընդունում փոփոխական չափի ֆիլմերում չհավասարեցված դեմքերը, ինչը հանգեցնում է ամբողջ դեմքի շրջանների՝ ելքի իրատեսական շարժումներով:

Այս շրջանակը համատեղելի է StyleGAN-ի վրա հիմնված պատկերների տոնայնացման ներկայիս մոդելների հետ, ինչը թույլ է տալիս դրանք ընդլայնել տեսանյութերի տոնայնացման համար և ժառանգել գրավիչ բնութագրեր, ինչպիսիք են գույնի և ինտենսիվության կարգավորելի հարմարեցումը:
այս սովորել ներկայացնում է VToonify-ի երկու օրինակ՝ հիմնված Toonify-ի և DualStyleGAN-ի վրա՝ համապատասխանաբար հավաքածուի վրա հիմնված և օրինակների վրա հիմնված դիմանկարային վիդեո ոճերի փոխանցման համար:
Լայնածավալ փորձարարական արդյունքները ցույց են տալիս, որ առաջարկվող VToonify շրջանակը գերազանցում է գոյություն ունեցող մոտեցումներին՝ փոփոխական ոճի պարամետրերով բարձրորակ, ժամանակավորապես համահունչ գեղարվեստական դիմանկարային ֆիլմեր ստեղծելու հարցում:
Հետազոտողները տրամադրում են Google Colab նոթատետր, այնպես որ դուք կարող եք կեղտոտել ձեր ձեռքերը դրա վրա:
Ինչպես է դա աշխատում?
Բարձր լուծաչափով դիմանկարային վիդեո ոճի կարգավորելի փոխանցում իրականացնելու համար VToonify-ը համատեղում է պատկերների թարգմանության շրջանակի առավելությունները StyleGAN-ի վրա հիմնված շրջանակի հետ:
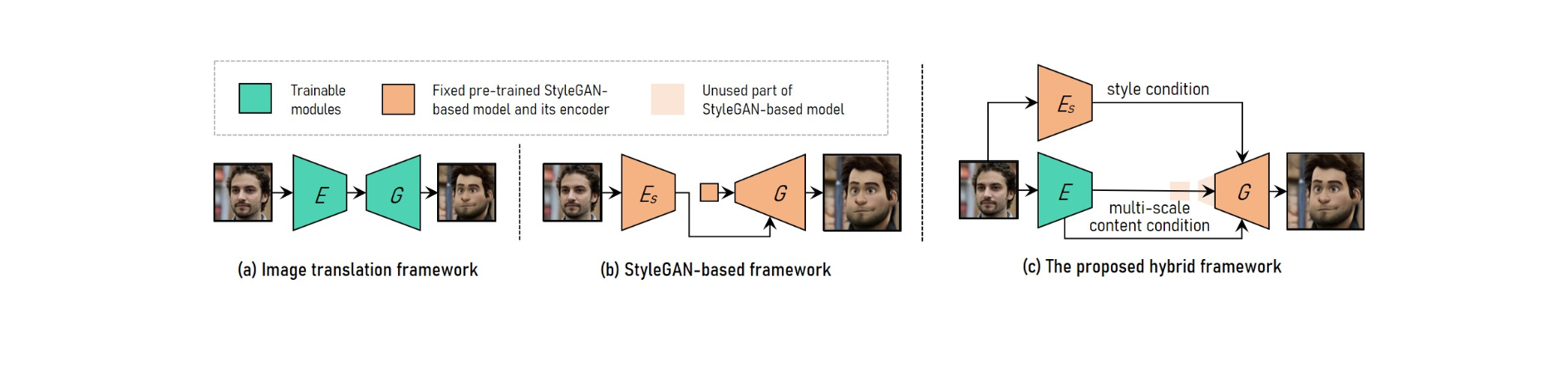
Մուտքագրման տարբեր չափերը տեղավորելու համար պատկերների թարգմանության համակարգը օգտագործում է ամբողջովին կոնվոլյուցիոն ցանցեր: Մյուս կողմից, զրոյից մարզվելը անհնարին է դարձնում բարձր լուծաչափով և վերահսկվող ոճի փոխանցումը:
Նախապես վերապատրաստված StyleGAN մոդելը օգտագործվում է StyleGAN-ի վրա հիմնված շրջանակում՝ բարձր լուծաչափով և վերահսկվող ոճի փոխանցման համար, թեև այն սահմանափակվում է նկարի ֆիքսված չափերով և մանրամասների կորուստներով:
StyleGAN-ը փոփոխվել է հիբրիդային շրջանակում՝ ջնջելով իր ֆիքսված չափի մուտքագրման առանձնահատկությունը և ցածր լուծաչափի շերտերը, ինչի արդյունքում ձևավորվում է ամբողջովին կոնվոլյուցիոն կոդավորող-գեներատոր ճարտարապետություն, որը նման է պատկերների թարգմանության շրջանակին:
Շրջանակի մանրամասները պահպանելու համար վարժեցրեք կոդավորիչը՝ հանելու մուտքային շրջանակի բազմամասշտաբ բովանդակության բնութագրերը՝ որպես գեներատորի բովանդակության լրացուցիչ պահանջ: Vtoonify-ը ժառանգում է StyleGAN մոդելի ոճի կառավարման ճկունությունը՝ այն դնելով գեներատորի մեջ՝ ինչպես իր տվյալները, այնպես էլ մոդելը թորելու համար:
StyleGAN-ի և առաջարկվող Vtoonify-ի սահմանափակումները
Գեղարվեստական դիմանկարները սովորական են մեր առօրյա կյանքում, ինչպես նաև ստեղծագործական բիզնեսներում, ինչպիսիք են արվեստը, սոցիալական լրատվամիջոցների ավատարներ, ֆիլմեր, զվարճանքի գովազդ և այլն:
Զարգացումով խորը ուսուցում տեխնոլոգիայով, այժմ հնարավոր է ստեղծել բարձրորակ գեղարվեստական դիմանկարներ իրական դեմքի լուսանկարներից՝ օգտագործելով դիմանկարի ոճի ավտոմատ փոխանցում:
Պատկերի վրա հիմնված ոճի փոխանցման համար ստեղծված հաջողակ եղանակներ կան, որոնցից շատերը հեշտությամբ հասանելի են սկսնակ օգտատերերին բջջային հավելվածների տեսքով: Վերջին մի քանի տարիների ընթացքում վիդեո նյութերն արագորեն դարձել են մեր սոցիալական մեդիայի հոսքերի հիմքը:
Սոցիալական մեդիայի և ժամանակավոր ֆիլմերի աճը մեծացրել է նորարարական վիդեո խմբագրման պահանջարկը, ինչպիսին է դիմանկարային վիդեո ոճի փոխանցումը՝ հաջող և հետաքրքիր տեսանյութեր ստեղծելու համար:
Պատկերի վրա հիմնված գոյություն ունեցող տեխնիկան զգալի թերություններ ունի, երբ կիրառվում է ֆիլմերի վրա՝ սահմանափակելով դրանց օգտակարությունը ավտոմատացված դիմանկարային տեսանյութերի ոճավորման մեջ:
StyleGAN-ը սովորական ողնաշար է դիմանկարային նկարների ոճի փոխանցման մոդելի մշակման համար, քանի որ այն կարող է ստեղծել բարձրորակ դեմքեր՝ կարգավորելի ոճերի կառավարման միջոցով:
StyleGAN-ի վրա հիմնված համակարգը (նաև հայտնի է որպես նկարների տոնայնացում) կոդավորում է իրական դեմքը StyleGAN թաքնված տարածության մեջ և այնուհետև կիրառում է ստացված ոճի կոդը մեկ այլ StyleGAN-ի վրա, որը ճշգրտված է գեղարվեստական դիմանկարների տվյալների բազայի վրա՝ ոճավորված տարբերակ ստեղծելու համար:
StyleGAN-ը նկարներ է ստեղծում հավասարեցված դեմքերով և ֆիքսված չափերով, ինչը չի նպաստում դինամիկ դեմքերին իրական աշխարհի կադրերում: Տեսանյութում դեմքի կտրումը և հավասարեցումը երբեմն հանգեցնում են դեմքի մասնակի և անհարմար ժեստերի: Հետազոտողները այս խնդիրը անվանում են StyleGAN-ի «ֆիքսված բերքի սահմանափակում»:
Չհավասարեցված դեմքերի համար առաջարկվել է StyleGAN3; սակայն, այն աջակցում է միայն սահմանված նկարի չափը:
Ավելին, վերջերս կատարած ուսումնասիրությունը պարզել է, որ չհավասարեցված դեմքերի կոդավորումն ավելի դժվար է, քան հավասարեցված դեմքերը: Դեմքի սխալ կոդավորումը վնասակար է դիմանկարի ոճի փոխանցման համար, ինչը հանգեցնում է այնպիսի խնդիրների, ինչպիսիք են ինքնության փոփոխությունը և բաղադրիչների բացակայությունը վերակառուցված և ոճավորված կադրերում:
Ինչպես քննարկվեց, դիմանկարային վիդեո ոճի փոխանցման արդյունավետ տեխնիկան պետք է կարգավորի հետևյալ խնդիրները.
- Իրատեսական շարժումները պահպանելու համար մոտեցումը պետք է կարողանա հաղթահարել չհավասարեցված դեմքերը և տարբեր չափերի տեսանյութերը: Տեսանյութի մեծ չափը կամ տեսադաշտի լայն անկյունը կարող է ավելի շատ տեղեկություններ ստանալ՝ դեմքը կադրից դուրս չթողնելով:
- Այսօրվա սովորաբար օգտագործվող HD գաջեթների հետ մրցելու համար անհրաժեշտ է բարձր լուծաչափով տեսանյութ:
- Օգտագործողների համար պետք է առաջարկվի ճկուն ոճի կառավարում, որպեսզի փոխեն և ընտրեն իրենց ընտրությունը օգտատերերի հետ իրատեսական փոխազդեցության համակարգ մշակելիս:
Այդ նպատակով հետազոտողները առաջարկում են VToonify՝ նոր հիբրիդային շրջանակ՝ վիդեո տոնայնացման համար: Մշակաբույսերի ֆիքսված սահմանափակումը հաղթահարելու համար հետազոտողները նախ ուսումնասիրում են թարգմանության համարժեքությունը StyleGAN-ում:
VToonify-ը համատեղում է StyleGAN-ի վրա հիմնված ճարտարապետության և պատկերների թարգմանության շրջանակի առավելությունները՝ բարձր լուծաչափով դիմանկարային տեսանյութերի կարգավորելի փոխանցման համար:
Հետևյալը հիմնական ներդրումներն են.
- Հետազոտողները ուսումնասիրում են StyleGAN-ի ֆիքսված բերքի սահմանափակումը և առաջարկում լուծում՝ հիմնված թարգմանության համարժեքության վրա:
- Հետազոտողները ներկայացնում են եզակի VToonify-ի ամբողջական կոնվուլցիոն շրջանակ՝ վերահսկվող բարձր լուծաչափով դիմանկարային վիդեո ոճի փոխանցման համար, որն աջակցում է չհավասարեցված դեմքերին և տեսանյութերի տարբեր չափերին:
- Հետազոտողները կառուցում են VToonify-ը Toonify-ի և DualStyleGAN-ի ողնաշարի վրա և խտացնում են ողնաշարը և՛ տվյալների, և՛ մոդելի առումով՝ հնարավորություն տալու հավաքածուի վրա հիմնված և օրինակների վրա հիմնված դիմանկարային վիդեո ոճերի փոխանցում:
Vtoonify-ի համեմատություն այլ ժամանակակից մոդելների հետ
Toonify
Այն ծառայում է որպես հավաքածուի վրա հիմնված ոճերի փոխանցման հիմք՝ հարթեցված դեմքերի վրա՝ օգտագործելով StyleGAN-ը: Ոճի կոդերն առբերելու համար հետազոտողները պետք է հավասարեցնեն դեմքերը և կտրեն 256256 լուսանկար PSP-ի համար: Toonify-ն օգտագործվում է 1024*1024 ոճի կոդերով ոճավորված արդյունք ստեղծելու համար:
Ի վերջո, նրանք կրկին հավասարեցնում են տեսանյութի արդյունքը իր սկզբնական վայրին: Չոճավորված տարածքը դրվել է սևի:

DualStyleGAN
Այն հիմք է հանդիսանում StyleGAN-ի վրա հիմնված օրինակների վրա հիմնված ոճերի փոխանցման համար: Նրանք օգտագործում են տվյալների նախնական և հետմշակման նույն մեթոդները, ինչ Toonify-ը:
Pix2pixHD
Սա պատկերից պատկեր թարգմանության մոդել է, որը սովորաբար օգտագործվում է բարձր լուծաչափով խմբագրման համար նախապես պատրաստված մոդելները խտացնելու համար: Այն մարզվում է զուգակցված տվյալների միջոցով:
Հետազոտողները օգտագործում են pix2pixHD որպես քարտեզի լրացուցիչ օրինակներ, քանի որ այն օգտագործում է արդյունահանված վերլուծական քարտեզ:
Առաջին կարգի շարժում
FOM-ը պատկերի անիմացիոն տիպիկ մոդել է: Այն վերապատրաստվել է 256256 նկարների վրա և վատ է կատարում այլ պատկերների չափսերի հետ: Որպես հետևանք, հետազոտողները նախ չափում են տեսանյութի շրջանակները մինչև 256*256, FOM-ի համար մինչև անիմացիա, այնուհետև չափափոխում են արդյունքները իրենց սկզբնական չափի:
Արդար համեմատության համար FOM-ն օգտագործում է իր մոտեցման առաջին ոճավորված շրջանակը՝ որպես հղման ոճի պատկեր:
ԴաԳԱՆ
Դա դեմքի 3D անիմացիայի մոդել է։ Նրանք օգտագործում են նույն տվյալների պատրաստման և հետմշակման մեթոդները, ինչ FOM-ը:

Առավելությունները
- Այն կարող է օգտագործվել արվեստում, սոցիալական լրատվամիջոցների ավատարներում, ֆիլմերում, զվարճանքի գովազդում և այլն:
- Vtoonify-ը կարող է օգտագործվել նաև մետավերսում:
Սահմանափակումները
- Այս մեթոդաբանությունը քաղում է ինչպես տվյալները, այնպես էլ մոդելը StyleGAN-ի վրա հիմնված ողնաշարից, ինչը հանգեցնում է տվյալների և մոդելի կողմնակալության:
- Արտեֆակտները հիմնականում առաջանում են ոճավորված դեմքի շրջանի և մյուս հատվածների չափերի տարբերություններով:
- Այս ռազմավարությունը ավելի քիչ հաջողակ է, երբ առնչվում է դեմքի տարածաշրջանում առկա բաներին:
Եզրափակում
Վերջապես, VToonify-ը ոճով կառավարվող բարձր լուծաչափով տեսահոլովակների տոնայնացման շրջանակ է:
Այս շրջանակը մեծ արդյունավետություն է ձեռք բերում տեսանյութերի մշակման մեջ և հնարավորություն է տալիս լայն վերահսկողություն կառուցվածքային ոճի, գույնի ոճի և ոճի աստիճանի նկատմամբ՝ խտացնելով StyleGAN-ի վրա հիմնված պատկերի տոնայնացման մոդելները՝ թե՛ դրանց առումով։ սինթետիկ տվյալներ և ցանցային կառույցներ։





Թողնել գրառում