Az adatmozgatás és -tárolás jelentősége megnőtt az IT-ipar folyamatos bővülésének és a másodpercenként keletkező több millió adatpontnak köszönhetően.
Ezen túlmenően, ezeknek az adatoknak világosnak és könnyen érthetőnek kell lenniük, hogy támogassák a pontos döntéshozatalt.
A versenyképesség megőrzése és a hosszú távú siker elérése érdekében vállalatának a rendelkezésre álló leghatékonyabb megoldásokkal kell adatokat tárolnia és mozgatnia.
Emiatt egyre több vállalkozás használ adatszöveteket. Az egyik legjobb módja az idő, a pénz és az erőforrások megtakarításának, ha adatszövetet használunk az adatok feldolgozására és az AI gépi tanulásra.
Ebben a cikkben alaposan áttekintjük a Data Fabricot, beleértve a felhasználási területeit, a fő összetevőit, előnyeit és egyéb fontos részleteket.
Szóval, mi az a Data Fabric?
Függetlenül attól, hogy hol vannak, kezelje és figyelje adatait és alkalmazásait. Az adatszövet lényegében egy olyan integrált adatarchitektúra, amely biztonságos, sokoldalú és adaptálható.
Az adatszövet, amely egyesíti a felhő, a mag és az él legjavát, sok szempontból új stratégiai megközelítést jelent az üzleti tárolási műveletekhez.
Bár központilag vezérelhető, mindenhová elérhet, beleértve a helyszíni, a nyilvános és privát felhőket, valamint az éles és IoT-eszközöket is.
A felhőkarcolók méretű adatsilók és a változatos, egymással nem összekapcsolt infrastruktúrák a múlté. Az adatszövet olyan adatkezelési eszközök átfogó gyűjteményén alapul, amelyek garantálják a konzisztenciát a kapcsolt környezetekben.
Az automatizálás révén leegyszerűsíti az időigényes kezelést, felgyorsítja a fejlesztést, a tesztelést és a telepítést, valamint éjjel-nappal óvja eszközeit.
Nem számít, hol találhatók adatai és alkalmazásai, egyetlen platformról nyomon követheti a tárolási költségeket, a teljesítményt és a hatékonyságot.
Gyorsan (és bizonyos esetekben automatikusan) módosíthatja hibrid felhő-infrastruktúráját, amint gyakorlati ismeretei vannak róla, például kijavíthatja a hibákat, megoldhatja a biztonsági és megfelelőségi problémákat, valamint fel- és lefelé méretezheti a számítástechnikát.
Röviden, a Data Fabric javítja az infrastruktúra telepítésének és karbantartásának hatékonyságát, csökkenti a költségeket és növeli a teljesítményt.
Miért érdemes Data Fabric-ot használni?
Minden adatközpontú cégnek átfogó stratégiára van szüksége, amely áthidalja az olyan akadályokat, mint az idő, a tér, a különféle szoftvertípusok és az adatok helye. Az adatokat nem szabad tűzfalak mögé rejteni vagy több helyen szétszórni, hanem elérhetővé kell tenni azokat, akiknek szükségük van rá.
A sikerhez a vállalkozásoknak jövőbiztos adatmegoldásra, valamint biztonságos, hatékony, egységes környezetre van szükségük. Ezt adatszövettel lehet megtenni.
A modern vállalkozások valós idejű kapcsolódási, önkiszolgálási, automatizálási és univerzális változtatási igényeit a hagyományos adatintegráció nem tudja kielégíteni.
Míg a sok forrásból származó adatok gyűjtése gyakran nem probléma, sok vállalkozásnak nehézséget okoz az adatok integrálása, feldolgozása, gondozása és átalakítása más forrásokból származó adatokkal.
A fogyasztók, partnerek és áruk alapos megértéséhez az adatkezelési folyamat ezen kritikus lépésének meg kell történnie. Mivel képesek frissíteni rendszereiket, jobban kiszolgálni az ügyfeleket és kihasználni cloud computing, a cégek ezáltal versenyelőnyhöz jutnak.
Bárhol tartózkodjanak is a szervezet felhasználói, az adatszövetet úgy lehet elképzelni, mint egy globálisan elterjedt szövetet. Ezen a hálózaton a felhasználó bárhol tartózkodhat, és továbbra is korlátlan, valós idejű hozzáféréssel rendelkezik bármely más helyen lévő adatokhoz.
A Data Fabric alapvető összetevői
Az adatszövetet alkotó alapvető összetevők többféleképpen választhatók és gyűjthetők össze. Az adatszövet így sokféleképpen megvalósítható. Nézzük meg az adatszövet elsődleges elemeit.
- Kiterjesztett adatkatalógus
- Perzisztencia réteg
- Tudás Graph
- Insights and Recommendations Engine
- Adat-előkészítési és adattovábbítási réteg
- Hangszerelés és adatkezelés
Ennek megfelelően megtekintheti a Data Fabric architektúra kulcsfontosságú pilléreit Gartner.
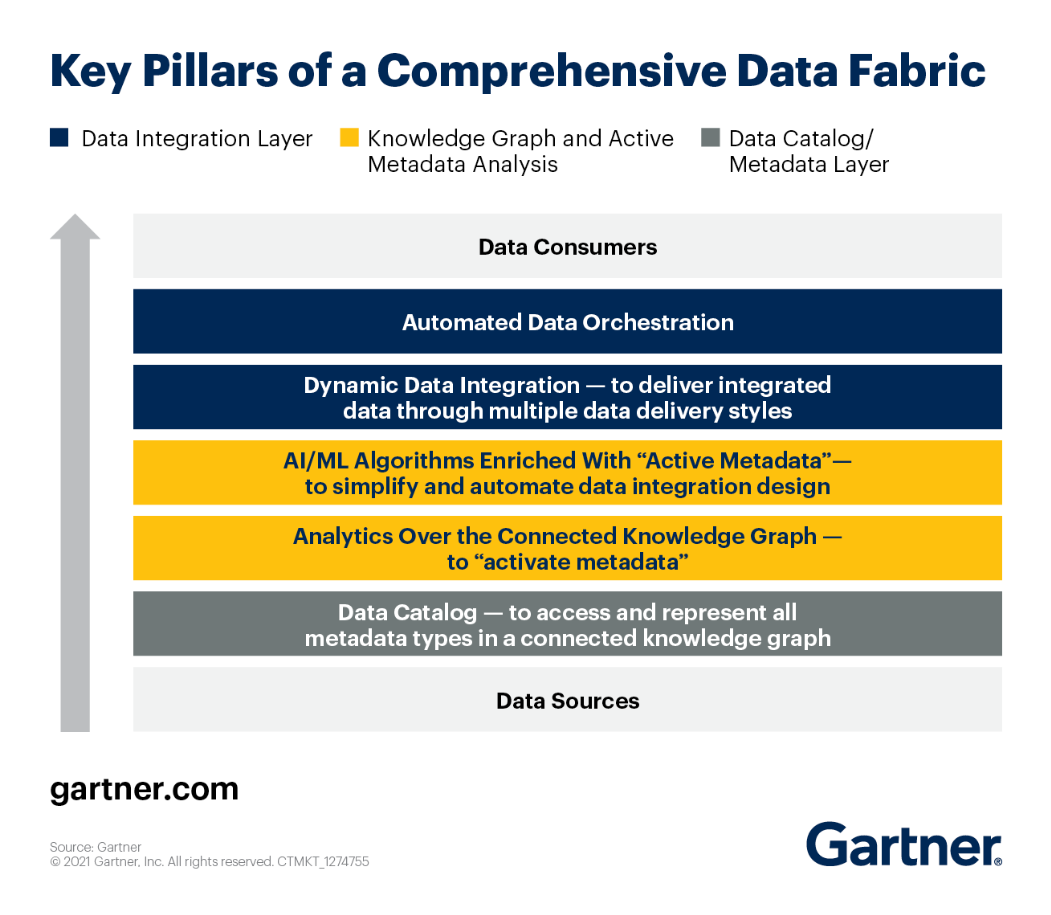
Nézzük meg mindegyiket alaposan.
- Kiterjesztett adatkatalógus – erős tudásdiagramon keresztül mindenféle metaadathoz hozzáférést biztosít a felhasználóknak. Ezenkívül megkülönböztető asszociációkat alakít ki a meglévő információk között, és érthető módon vizuálisan mutatja meg azokat. Használva gépi tanulás Az adatvagyon és a szervezeti terminológia összekapcsolása érdekében a továbbfejlesztett adatkatalógusok hozzák létre az adatszövet üzleti szemantikai rétegét.
- Perzisztencia réteg – A felhasználási esettől függően számos relációs és nem relációs modell használható az adatok dinamikus tárolására.
- Aktív metaadatok – az adatszövet jellegzetes része. Lehetőséget ad az adatszövetnek sokféle metaadat összegyűjtésére, megosztására és elemzésére. A passzív metaadatokkal ellentétben az aktív metaadatok nyomon követik a rendszerek és az emberek folyamatos adathasználatát (tervezésalapú és futásidejű metaadatok).
- Tudás Graph – Az adatszövetek másik alapvető egysége. Szabványos azonosítókat, adaptálható sémákat stb. használnak a kapcsolt adatkörnyezet megjelenítéséhez. A tudásgrafikonok kereshetővé teszik az adatszövetet, és segítik annak megértését.
- Insights and Recommendation Engine – Megbízható, erős adatfolyamokat épít ki mind az operatív, mind az analitikai felhasználási esetekre.
- Adat-előkészítési és adattovábbítási réteg – Az adatok bármilyen forrásból lekérhetők, és bármely célpontra elküldhetők bármilyen mechanizmus segítségével, beleértve az ETL-t (tömeges), üzenetkezelést, CDC-t, virtualizációt és API-t.
- Hangszerelés és adatkezelés – Ez az összetevő adatok segítségével koordinálja az összes feladatot a végpontok közötti munkafolyamat minden szakaszában. Lehetővé teszi, hogy kiválassza, mikor és milyen gyakran futtassa a folyamatokat, valamint hogyan kezelje az általa előállított adatfolyamokat.
Előnyök
Az elosztott környezetben lévő egészséges adatok hozzáférhetőek, betölthetők, integrálhatók és megoszthatók egy adathálón. Ezzel a vállalkozások felgyorsíthatják a digitális átállást, és maximalizálhatják adataik értékét.
Az alábbiakban felvázoljuk az adatszövet-modell legfontosabb előnyeit.
Hatékonyság:
Az adatszövet összeállíthatja a korábbi lekérdezések eredményeit, lehetővé téve a rendszer számára, hogy a háttérben lévő nyers adatok helyett az összesített táblát vizsgálja meg.
Az egyedi kérések gyorsabb válaszideje miatt több egyidejű kérés problémáját is megoldja, ha a kérések kisebb adatkészletekhez férhetnek hozzá ahelyett, hogy a teljes tárhely nyers adatait kellene átvizsgálniuk.
A vállalatok gyorsan válaszolhatnak a sürgető megkeresésekre, mivel az adatszövet jelentősen lerövidíti a lekérdezések válaszidejét.
Intelligens integráció
A különféle adattípusok és végpontok közötti adatok integrálásához az adatszövetek szemantikai tudásgráfokat, metaadatkezelést és gépi tanulást használnak.
Ez segít az adatkezelő csapatoknak a releváns adatkészletek csoportosításában, és vadonatúj adatforrások beépítésében a vállalati adatökoszisztémába.
Ez a funkció automatizálja az adatfeladat-kezelés egyes részeit, ami a fent jelzett termelékenység-megtakarítást eredményez, de segít az adatrendszer-silók lebontásában, az adatkezelési eljárások központosításában és az általános adatminőség javításában.
Hatékonyabb adatbiztonság
Ez nem jelenti azt sem, hogy fel kell áldozni az adatbiztonságot és a magánélet védelmét az adatokhoz való hozzáférés kiterjesztése érdekében.
Valójában a hozzáférés-ellenőrzési korlátok szigorítására és több adatkezelési intézkedés bevezetésére van szükség annak biztosítására, hogy bizonyos szerepkörök egyedüliként férhessenek hozzá egy adott adathalmazhoz.
Ezenkívül az adatháló-architektúrák lehetővé teszik a műszaki és biztonsági csapatok az adatmaszkolás megvalósításához és titkosítás a bizalmas és érzékeny információk körül, csökkentve az adatmegosztás és a rendszerfeltörések valószínűségét.
Az adatok demokratizálása
Az önkiszolgáló alkalmazásokat az adatszövet-tervek könnyítik meg, és kiterjesztik az adathozzáférés hatókörét a műszaki személyzet, például adatmérnökök, fejlesztők és adatelemző csapatok körén túl.
Azáltal, hogy lehetővé teszi az üzleti felhasználók számára, hogy gyorsabban hozzanak üzleti döntéseket, és felengedik a technikai felhasználókat, hogy olyan tevékenységeket helyezzenek előtérbe, amelyek a legjobban hasznosítják képességeiket, az adatszűk keresztmetszetek kiküszöbölése a termelékenység növekedéséhez vezet.
Használati esetek
Az adatszövet-architektúra célja, hogy átfogó struktúrát kínáljon a tárolt információk minden formájának kezelésére, hogy szükség esetén használhatóvá váljon.
Az ilyen típusú adatok az értékesítési előrejelzésektől a szervezet IT-infrastruktúrájának vagy felhasználói végpontjainak állapotáról szóló jelentésig bármihez felhasználhatók.
Az adatszövet-architektúra használati esetei megegyeznek az üzleti élet bármely más típusú adathasználati eseteivel, beleértve az értékesítést, a marketinget, az IT-t, a kiberbiztonságot és még sok mást.
A szervezetben lévő adatok azonban gyakran szinte minden felhasználási esetben szervezettek, félig strukturáltak vagy strukturálatlanok. A relációs adatbázis strukturált adatokat tárolhat, és azonnal felhasználható, például adatbázisrekordokat.
A ki nem tisztított vagy kategorizálatlan adatokat strukturálatlan adatoknak nevezzük, és szükség esetén fel kell készíteni a felhasználásra.
A strukturálatlan adatok számos formája, amelyeket sok cég megszerezhet és tárolhat jövőbeli felhasználás céljából gépi tanulás, analitika, érzékelőadatok, számítási felhő és termelékenységi alkalmazások.
A félig strukturált adatokban, amelyek felismert típusú, strukturálatlan adatokkal mentett adatokat tartalmaznak (például zip-fájlok, weboldalak és e-mailek), mindkét szempont jelen van.
Az adatszövet azon képessége alapján, hogy segíti a vállalatokat adataik gyorsabb és hatékonyabb elérésében és felhasználásában, számos lehetséges felhasználási esetet találhatunk a felhasználás kutatásával.
Tipikus példák a következők:
- Csalások felderítése
- IoT elemzés
- Ellátási lánc logisztika
- Valós idejű adatelemzés
- Ügyfél intelligencia
- A működési hatékonyság növelése
- A megelőző karbantartás elemzése
- Ezenkívül a munkába való visszatérés kockázati modelljei
- Tranzakciók biztosítása hitelkártyákkal
- Lemorzsolódás előrejelzése, csalás felderítése és hitelpontozás
Következtetés
Összefoglalva, az adatsilóknak fokozatosan fel kell oszlaniuk az adatfelhasználási szintünk növekedésével, hogy helyet adjunk a kapcsolódó vállalatoknak.
Az adatszövetek telepítése jelentős előrelépést jelent ezen az úton, amely a relációs adatbázisok 1970-es évekbeli fejlesztése óta a legáttörőbb felfedezések közé tartozik.
Ez azért van így, mert az adatszövet több, mint egy technológia vagy egyetlen elem.
Az adatok és az üzleti műveletek bonyolultan összefonódnak az architektúra tervezésén, a szisztematikus eljárásokon és a mentalitásváltáson keresztül.
A Data Fabric csökkenti a költségeket, növeli a teljesítményt, és megkönnyíti az infrastruktúra hatékonyabb telepítését és karbantartását. Kulcsfontosságú eleme lehet annak biztosításában, hogy minden folyamat, alkalmazás és üzleti döntés adatvezérelt legyen.





Hagy egy Válaszol