Tartalomjegyzék[Elrejt][Előadás]
A nagyméretű szöveg-kép modellek jelentős előrelépést tettek az AI fejlesztésében azáltal, hogy egy adott szöveges promptból jó minőségű és változatos képszintézist állítottak elő.
Ezek a modellek nem képesek az alanyok egyedi reprezentációinak szintetizálására különböző beállításokban, vagy nem képesek megismételni az alanyok megjelenését egy adott referenciakészletben.
Az olyan újonnan kiadott technológiák, mint az OpenAI DALL.E2 vagy a StabilityAI Stabil diffúzió és a Midjourney máris viharba veszi az internetet. Itt az ideje testreszabni az eredményeket. Mégis hogyan?
Megérkezett a Google DreamBooth AI.
A DreamBooth képes felismerni egy kép témáját, dekonstruálni azt eredeti kontextusából, majd pontosan szintetizálni egy új kívánt kontextusba. Ezenkívül használható a jelenlegi AI képgenerátorokkal.
Ebben a cikkben alaposan áttekintjük a DreamBooth-ot, annak használatát, oktatóanyagát, korlátait és még sok mást.
Mi az a Dreambooth?
álombódé, egy vadonatúj szöveg-kép diffúziós modellt mutatott be a Google. A Google DreamBooth AI egy írásos felszólítást használhat útmutatásként a felhasználó által kiválasztott témáról készült fényképek széles skálájának létrehozásához, különböző beállításokkal.
A Boston Egyetem és a Google kutatócsoportja kifejlesztette a DreamBooth-ot, a legmodernebb technikát a kiterjedt előképzésen átesett szöveges képké modellek átalakítására.
Az általános koncepció meglehetősen egyszerű: bővíteni akarják a nyelvi látásszótárat, hogy a szokatlan token-azonosítók egyéni témákhoz legyenek társítva, amelyeket a felhasználók meghatározhatnak.
A modell fő célja, hogy összekapcsolja a felhasználókat a szöveg-kép diffúziós modell azáltal, hogy megadjuk nekik azokat az erőforrásokat, amelyekre szükségük van a kiválasztott témájuk eseteinek fotorealisztikus ábrázolásához.
Következésképpen úgy tűnik, hogy ez a technika számos helyzetben jól működik a kihívások összegzésében.
A Google DreamBooth-ja eltér a korábbi szöveg-kép eszközeitől, mint pl DALL-E2, Stabil diffúzióés középút, mivel a felhasználóknak nagyobb irányítást biztosítanak a téma kép felett, mielőtt szövegalapú bemenetekkel manipulálják a diffúziós modellt.
Jellemzők
- A DreamBooth AI 3-5 képpel javíthat egy szöveg-kép modellt.
- A DreamBooth AI segítségével eredeti fotorealisztikus fényképek készíthetők.
- Ezenkívül a DreamBooth AI több szögből is képes fotókat készíteni egy témáról.
Alkalmazás
Művészeti átadások
Ez a feladat kifejezetten különbözik a stílusátviteltől, amely megtartja a forrásjelenet szemantikáját, miközben egy másik kép stílusát beépíti az eredeti jelenetbe.

A kreatív megközelítés alapján az AI jelentős jelenetmódosításokat tud végrehajtani, miközben megtartja az azonosítási és témapéldány-specifikációkat.
Tulajdonmódosítás
Az alanypéldány jellemzőit a DreamBooth AI módosíthatja.

Kiegészítők
A generációs modellt megelőző erős kompozíció az, ami annyira érdekessé teszi a DreamBooth AI azon képességét, hogy tárgyakat díszítsen.

Rekontextualizálás
A DreamBooth AI megkülönböztető képeket tud előállítani egy bizonyos tárgypéldányhoz, ha a képzett modellnek egy mondatot ad, amely tartalmazza az egyedi azonosítót és az osztály főnevet.

A környezet megváltoztatása helyett egyedi, korábban nem hallott testhelyzetekben, artikulációkban és jelenetstruktúrákban generálhatja a témát. Valósághű tükröződések és árnyékok, valamint az alany és a környező tárgyak közötti interakciók.
Dreambooth oktatóanyag
Ebben az oktatóanyagban követni fogjuk a Google Collab jegyzetfüzet, és végigvezetem rajta, amivel megértheted és egyedül is használhatod.
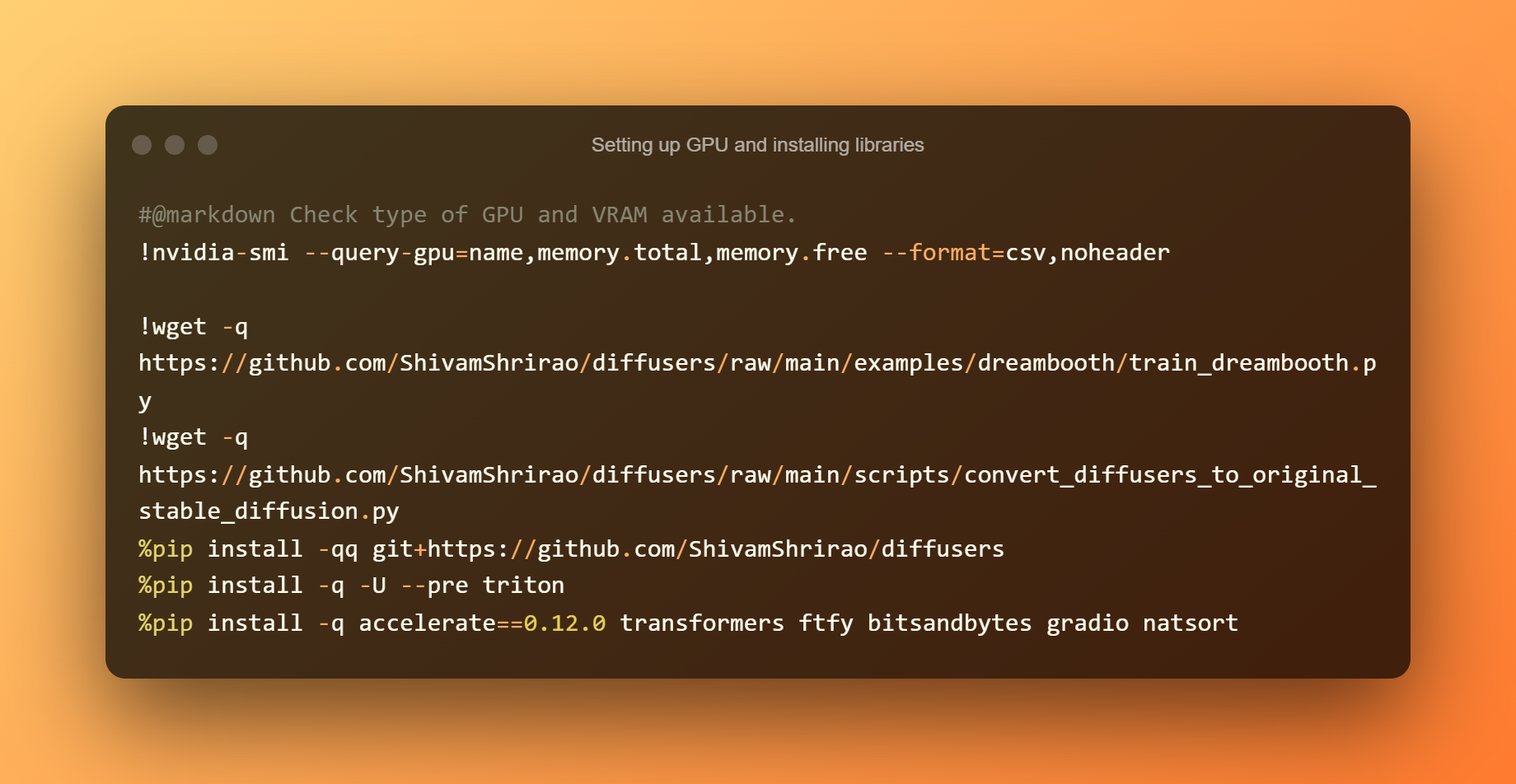
GPU beállítása és könyvtárak telepítése
Az első lépés annak kiderítése, hogy milyen GPU és VRAM típusok állnak rendelkezésre. Néhány követelmény és függőség telepítése is szükséges. Egyszerűen nyomja meg a lejátszás gombot, majd várja meg, amíg befejeződik.
Hozzon létre egy fiókot a Huggingface-en, és hozzon létre egy tokent
A következő lépés a Huggingface-fiók regisztrálása. Ha végzett, kattintson a beállításokra a jobb felső sarokban. A következő oldalon fogsz megérkezni.
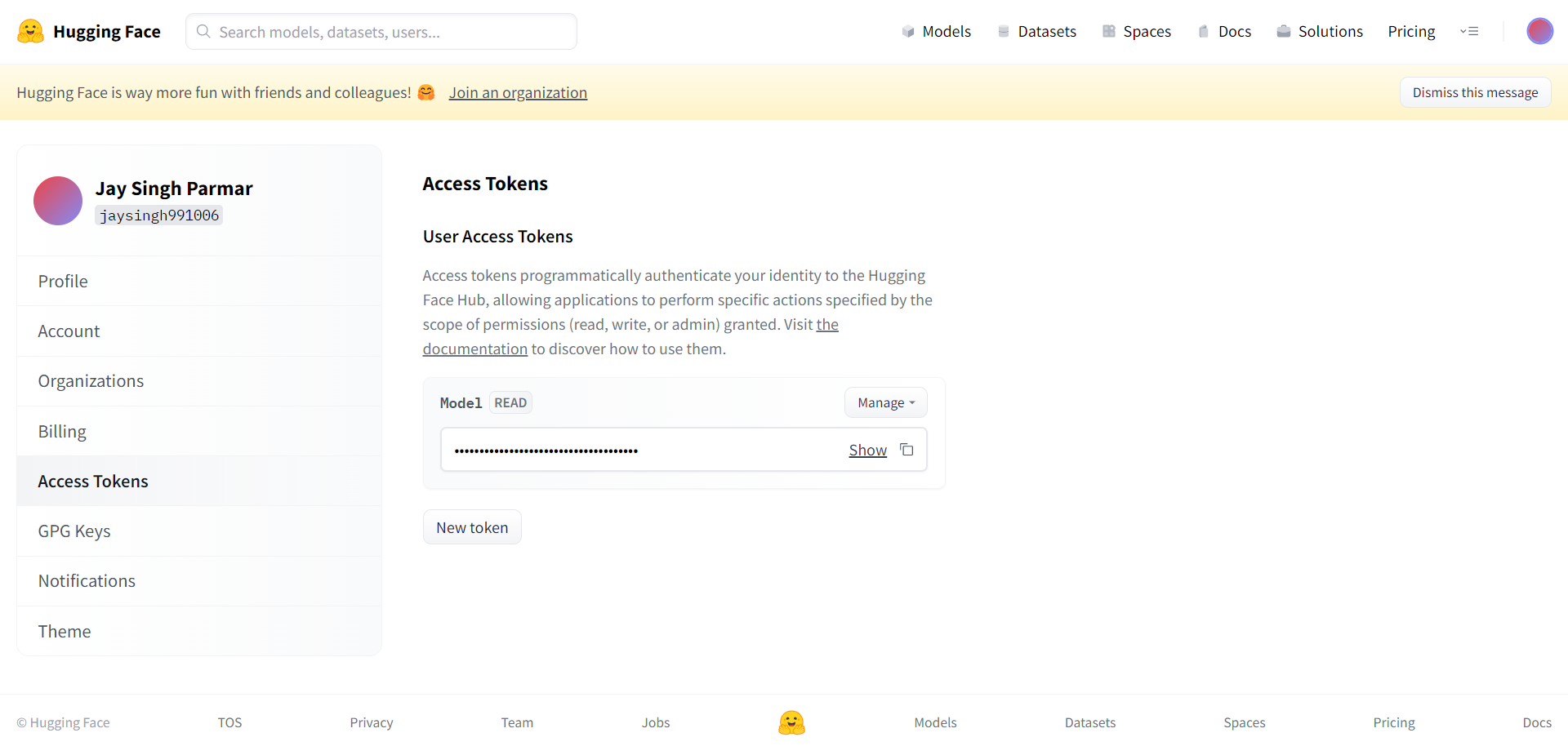
Hozza létre a tokent és a nevet az innen kért módon. A tokent ki kell másolni, és be kell illeszteni az alábbi cellában lévő Google együttműködésbe.

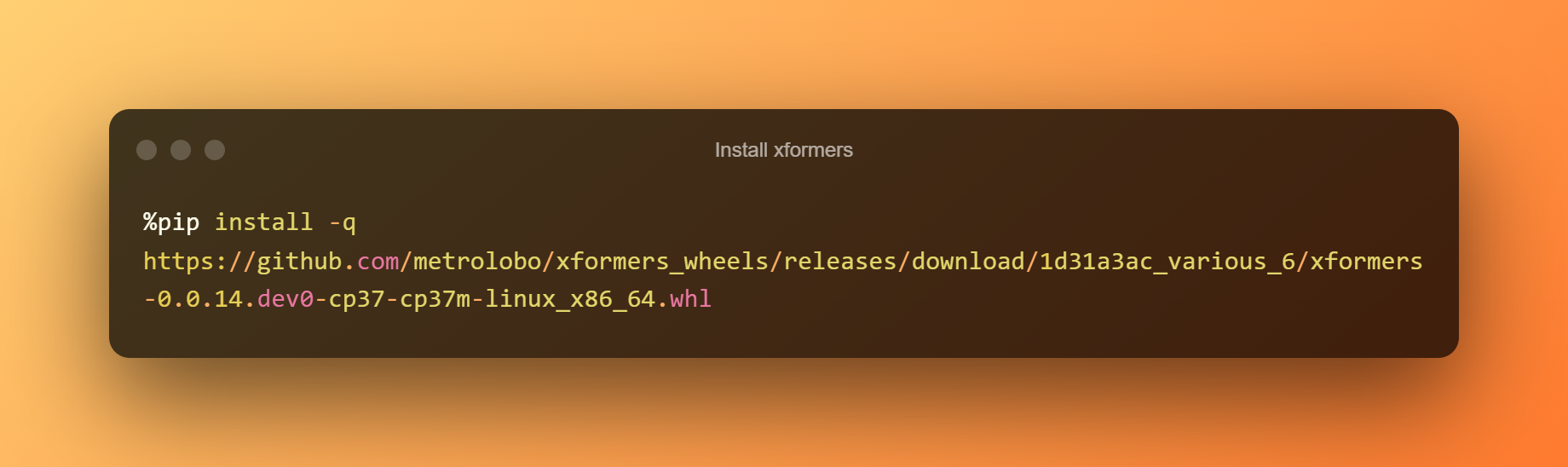
Telepítse az xformers programot
Ebben a szakaszban egyszerűen megnyomhatja a lejátszás gombot az xformers telepítéséhez a futtatókörnyezetre kattintva.
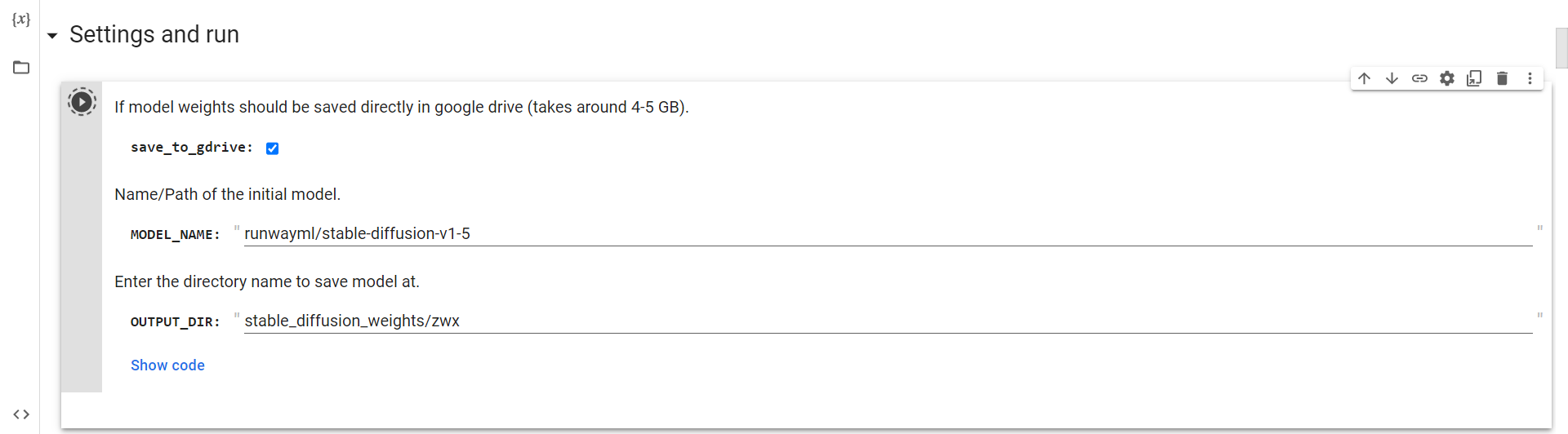
Csatlakozás a Drive-hoz
Most már csak le kell futtatnia ezt a cellát, hogy csatlakozzon a Google meghajtóhoz.
Írja be a promptot
A következő cellában csak be kell írnia a promptot.
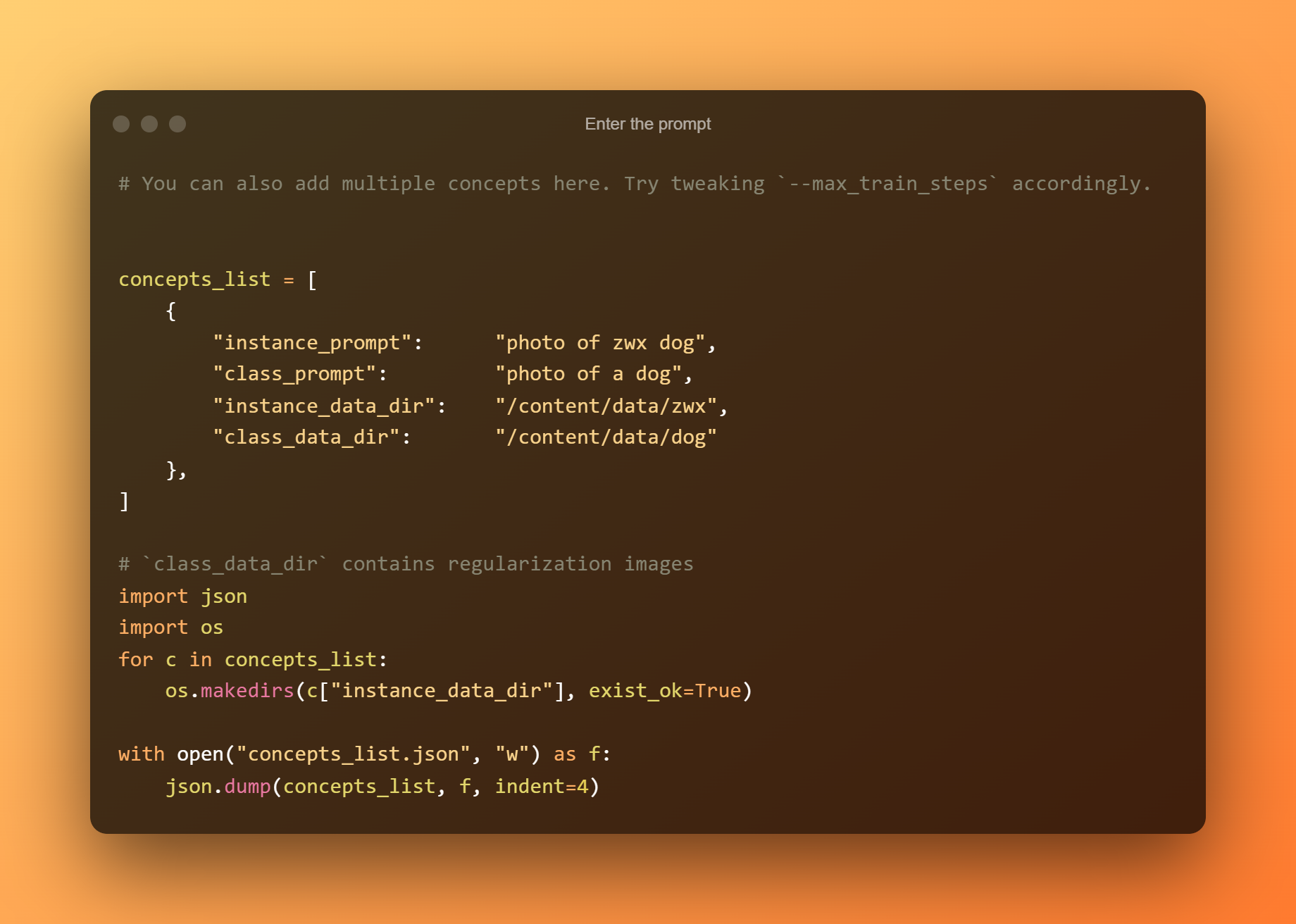
Képek feltöltése
Ebben a lépésben csak fel kell töltenie azokat a képeket, amelyeket edzeni akart.

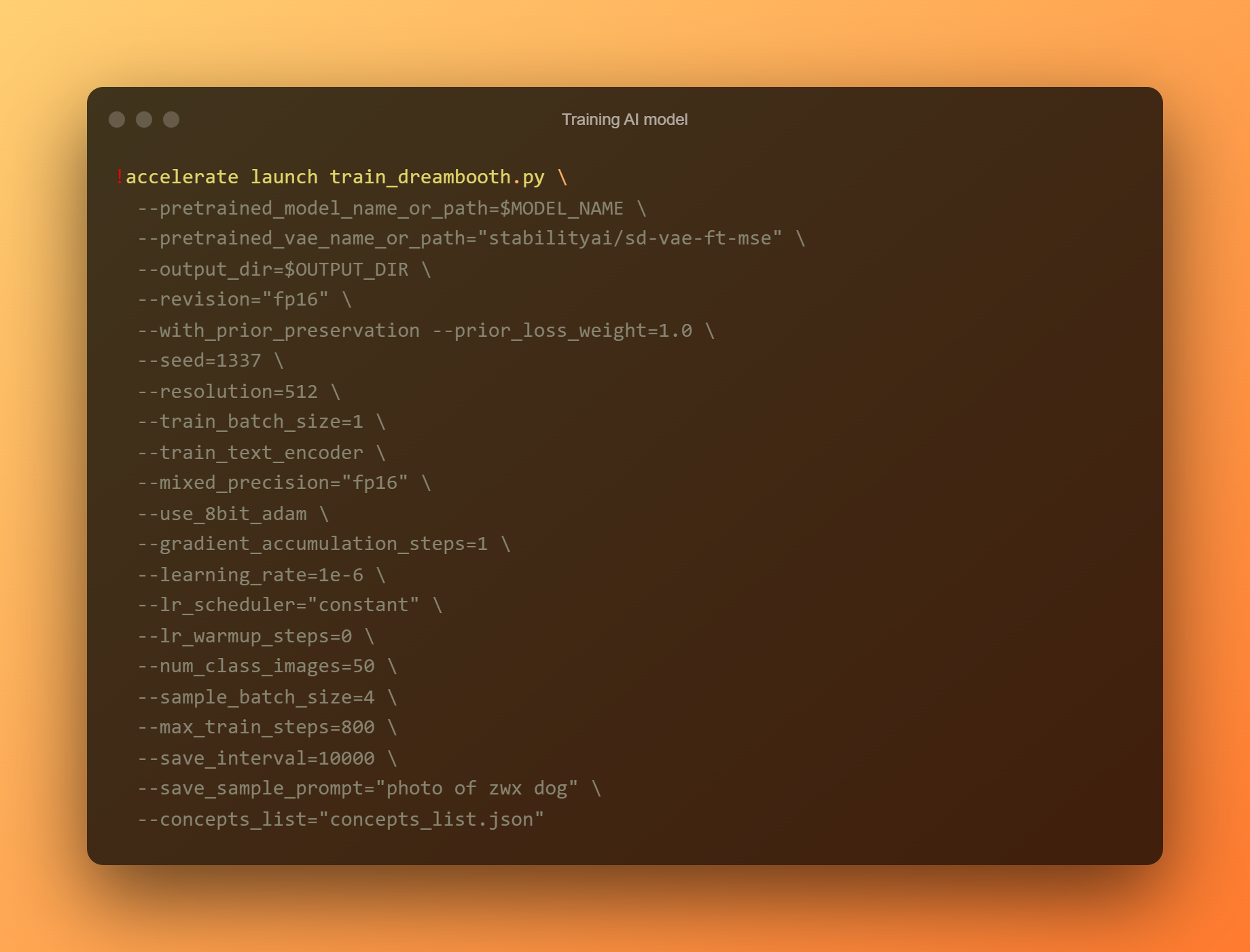
Vonat AI modell
Ez a legfontosabb fázis, mivel a DreamBooth segítségével új AI-modellt képezhet ki az összes beküldött referenciafotója alapján. Két beviteli mezőre kell korlátoznia a figyelmét. A „-példány prompt” az első paraméter. Itt nagyon jól megkülönböztethető nevet kell megadnia.
A „–fogalomlista” argumentum a második kritikus beviteli mező. Át kell nevezni, hogy megfeleljen a „Megjelenítés módosítása” részben használtnak.
AI képeket generál
A mesterséges intelligencia képek ebben a szakaszban jönnek létre, ahol megadhatja a szöveges utasításokat.

Dreambooth korlátozások
- A parancssor akadályozza a témakörben a nagyfokú részletezésű iterációkat. A DreamBooth megváltoztathatja az alany kontextusát, de ha a modell magát a témát akarja megváltoztatni, akkor problémák vannak a kerettel.
- Egy másik probléma a kimeneti kép túlillesztése a bemeneti képhez. Ha nincs elég kép, előfordulhat, hogy a téma nem kerül figyelembevételre, vagy keveredik a beküldött képek kontextusával. Amikor egy páratlan generáció kontextusát kérdezik, ugyanez történik.
Következtetés
Az egyetlen szövegbevitelből származó kimenetek előállításához a szöveg-kép modellek többsége paraméterek és könyvtárak millióit igényli.
A DreamBooth leegyszerűsíti a tartalomszerzést és -használatot a fogyasztók számára azáltal, hogy mindössze három-öt témájú fényképet és szöveges hátteret kell megadnia.





Hagy egy Válaszol