विषय - सूची[छिपाना][प्रदर्शन]
फर्जी फोटो और वीडियो का होना कोई नई बात नहीं है। इंटरनेट के व्यापक उपयोग के बाद से, जब से चित्र और फिल्में बनी हैं, तब से लोग मूर्ख बनाने या मनोरंजन करने के लिए जालसाजी बना रहे हैं।
हालाँकि, एक नए प्रकार के मशीन-निर्मित नकली हैं जो किसी दिन हमारे लिए कल्पना से वास्तविकता को अलग करना कठिन बना सकते हैं।
ये फेक फोटोशॉप जैसे एडिटिंग सॉफ्टवेयर या अतीत की चतुराई से हेरफेर की गई फिल्मों द्वारा उत्पन्न साधारण चित्र जोड़तोड़ से भिन्न होते हैं।
डीपफेक "सिंथेटिक मीडिया" का सबसे प्रसिद्ध उदाहरण है - चित्र, ध्वनियाँ और वीडियो जो पारंपरिक तरीकों का उपयोग करके निर्मित किए गए लगते हैं लेकिन वास्तव में परिष्कृत सॉफ़्टवेयर का उपयोग करके बनाए गए थे।
डीपफेक कुछ समय के लिए आसपास रहे हैं, और जबकि उनका सबसे लोकप्रिय अनुप्रयोग अभी तक पोर्नोग्राफिक फिल्मों में अभिनेताओं के शरीर पर प्रसिद्ध लोगों के सिर लगाने के लिए है, वे कहीं भी, कुछ भी करने वाले किसी के भी ठोस फुटेज का उत्पादन करने की क्षमता रखते हैं।
इस पोस्ट में, हम डीपफेक को देखेंगे कि यह कैसे काम करता है, आप उन्हें अपने दम पर कैसे उत्पन्न कर सकते हैं, और भी बहुत कुछ।
तो, डीपफेक क्या है?
डीपफेक—डीप लर्निंग और फेक वाक्यांशों का संयोजन—का एक टुकड़ा है सिंथेटिक मीडिया जिसमें पहले से मौजूद तस्वीर या वीडियो में किसी व्यक्ति की समानता को बदलने के लिए किसी अन्य व्यक्ति की समानता का उपयोग किया जाता है।
डीपफेक दृश्य और श्रव्य जानकारी को संशोधित करने और बनाने के लिए परिष्कृत मशीन लर्निंग और कृत्रिम बुद्धिमत्ता तकनीकों को नियोजित करता है जिसमें धोखे की उच्च क्षमता होती है।
डीप लर्निंग मेथड्स जैसे ऑटोएन्कोडर और जनरेटिव एडवरसैरियल नेटवर्क डीपफेक प्रोडक्शन (जीएएन) के लिए प्राथमिक तंत्र हैं।
इन मॉडलों का उपयोग किसी व्यक्ति की चेहरे की भावनाओं और आंदोलनों का विश्लेषण करने के लिए किया जाता है और तुलनीय भाव और आंदोलनों को प्रदर्शित करने वाले अन्य लोगों के चेहरे के चित्रों को संश्लेषित करता है।
सेलिब्रिटी अश्लील वीडियो, नकली समाचार, धोखाधड़ी और वित्तीय धोखाधड़ी में डीपफेक के उपयोग ने काफी ध्यान आकर्षित किया है। उद्योग और सरकार दोनों ने उन्हें खोजने और उनके उपयोग को सीमित करने का प्रयास करके प्रतिक्रिया दी है।
पहला ऑर्डर मोशन मॉडल
अतीत में गहरे नकली विकसित करने की कोशिश करते समय, मुद्दा यह था कि काम करने के इन तरीकों के लिए हमें किसी प्रकार के अतिरिक्त ज्ञान, या पुजारियों की आवश्यकता होती है।
एक उदाहरण के रूप में, यदि हम सिर की गति का पता लगाना चाहते हैं तो चेहरे के निशान की आवश्यकता होती है। यदि हम पूरे शरीर की गति को मैप करना चाहते हैं तो मुद्रा का अनुमान आवश्यक था।
यह पिछले साल न्यूरआईपीएस सम्मेलन में बदल गया जब टोरंटो विश्वविद्यालय की शोध टीम ने अपना काम प्रस्तुत किया, "इमेज एनिमेशन के लिए फर्स्ट ऑर्डर मोशन मॉडल".
इस दृष्टिकोण के लिए एनीमेशन का कोई और ज्ञान आवश्यक नहीं है। इसके अलावा, इस मॉडल के प्रशिक्षित होने के बाद, इसका उपयोग ट्रांसफर लर्निंग के लिए किया जा सकता है और उसी श्रेणी के अंतर्गत आने वाली किसी भी वस्तु पर लागू किया जा सकता है।
आइए इस विधि के संचालन को थोड़ा आगे देखें। मोशन एक्सट्रैक्शन और जेनरेशन पूरी प्रक्रिया का पहला भाग बनाते हैं। ड्राइविंग वीडियो और स्रोत चित्रों को इनपुट के रूप में उपयोग किया जाता है।
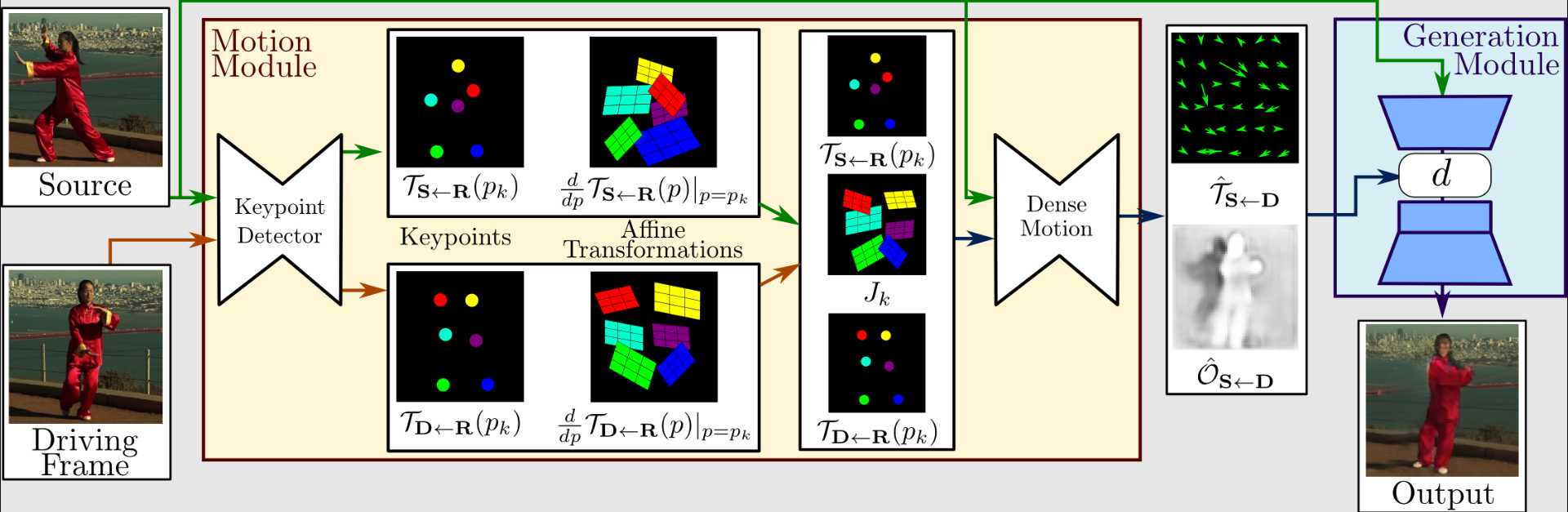
पहले क्रम के गति प्रतिनिधित्व को निकालने के लिए, जिसमें विरल प्रमुख बिंदु और स्थानीय एफ़िन परिवर्तन होते हैं, एक गति चिमटा प्रमुख बिंदुओं की पहचान करने के लिए एक ऑटोएन्कोडर का उपयोग करता है।
घने गति नेटवर्क के साथ घने ऑप्टिकल प्रवाह और रोड़ा मानचित्र बनाने के लिए, उन्हें ड्राइविंग वीडियो के साथ नियोजित किया जाता है। जनरेटर तब डेंस मोशन नेटवर्क और सोर्स इमेज से आउटपुट का उपयोग करके लक्ष्य चित्र प्रस्तुत करता है।
पूरे मंडल में, यह कार्य अत्याधुनिक से बेहतर प्रदर्शन करता है। इसमें ऐसी विशेषताएं भी हैं जो अन्य मॉडलों में नहीं हैं। यह कई प्रकार के चित्र पर काम करता है, इसलिए आप इसे चेहरे, शरीर, कार्टून आदि की छवियों पर लागू कर सकते हैं, जो कि बहुत बढ़िया है।
इससे कई नए अवसर पैदा होते हैं। हमारी रणनीति का एक और महत्वपूर्ण पहलू यह है कि अब यह आपको लक्ष्य वस्तु की सिर्फ एक छवि का उपयोग करके उच्च गुणवत्ता वाले डीपफेक का उत्पादन करने की अनुमति देता है, जैसा कि हम कैसे करते हैं वस्तु के लिए योलो मान्यता।
डीपफेक मॉडल बनाने की प्रक्रिया
डीपफेक जनरेशन के लिए तीन प्रक्रियाएँ आवश्यक हैं: निष्कर्षण, प्रशिक्षण और निर्माण। इन चरणों में से प्रत्येक के मुख्य बिंदु और वे समग्र प्रक्रिया से कैसे संबंधित हैं, इस खंड में शामिल किए जाएंगे।
निष्कर्षण
डीपफेक चेहरे बदलने के लिए गहरे तंत्रिका नेटवर्क का उपयोग करते हैं और सही ढंग से और दृढ़ता से संचालित करने के लिए बहुत सारे डेटा (चित्र) की आवश्यकता होती है। निष्कर्षण प्रक्रिया वह चरण है जिसमें वीडियो क्लिप से सभी फ़्रेम निकाले जाते हैं, चेहरों को पहचाना जाता है, और फिर प्रदर्शन को अधिकतम करने के लिए चेहरों को संरेखित किया जाता है।
प्रशिक्षण
प्रशिक्षण चरण में, तंत्रिका नेटवर्क एक चेहरे को दूसरे चेहरे में बदल सकते हैं। अभ्यास सेट और प्रशिक्षण गैजेट के आकार के आधार पर, प्रशिक्षण में कई घंटे या दिन भी लग सकते हैं।
अधिकांश अन्य तंत्रिका नेटवर्क प्रशिक्षण की तरह, प्रशिक्षण को केवल एक बार समाप्त करना होगा। प्रशिक्षण के बाद, मॉडल व्यक्ति ए से व्यक्ति बी में चेहरा बदलने में सक्षम होगा।
निर्माण
मॉडल को प्रशिक्षित करने के बाद, एक डीपफेक का उत्पादन किया जा सकता है। फ़्रेम एक वीडियो से लिए जाते हैं और फिर सभी चेहरों के साथ संरेखित होते हैं। प्रशिक्षित तंत्रिका नेटवर्क का उपयोग तब प्रत्येक फ्रेम को बदलने के लिए किया जाता है।
रूपांतरित चेहरे को अंतिम चरण के रूप में मूल फ़्रेम के साथ मर्ज किया जाना चाहिए।
डीपफेक डिटेक्शन मॉडल का निर्माण
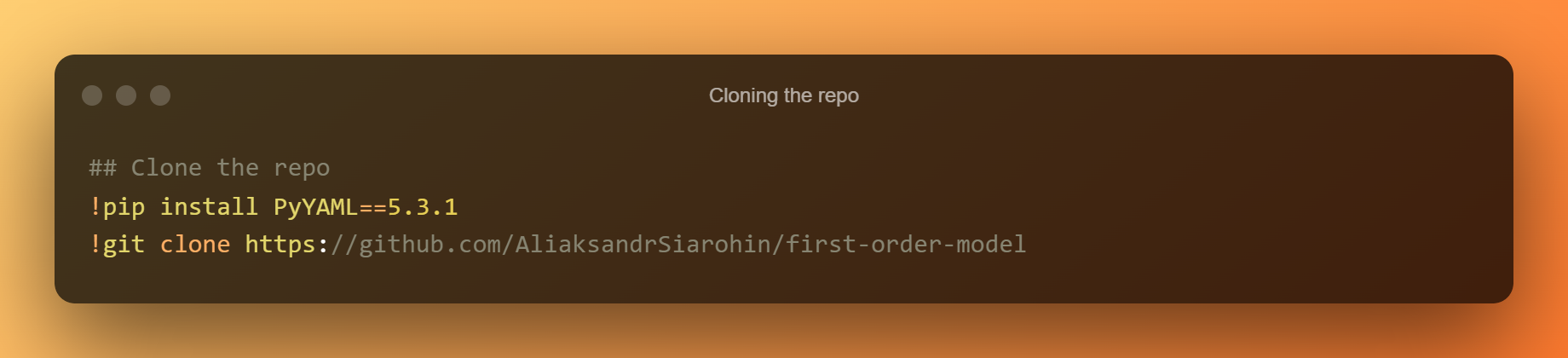
बढ़ते और क्लोनिंग GitHub रेपो
Colab में काम करते हुए Google के GPU का मुफ़्त में इस्तेमाल करना इनके लिए फायदेमंद है ध्यान लगा के पढ़ना या सीखना. एक अतिरिक्त लाभ क्लाउड वर्चुअल मशीन (VM) पर Google ड्राइव को माउंट करने की क्षमता है।
अपने सभी सामानों तक आसान पहुंच के साथ, उपयोगकर्ता सक्षम है। क्लाउड में वर्चुअल मशीन पर Google ड्राइव को माउंट करने के लिए आवश्यक प्रोग्राम इस खंड में मिलेगा।


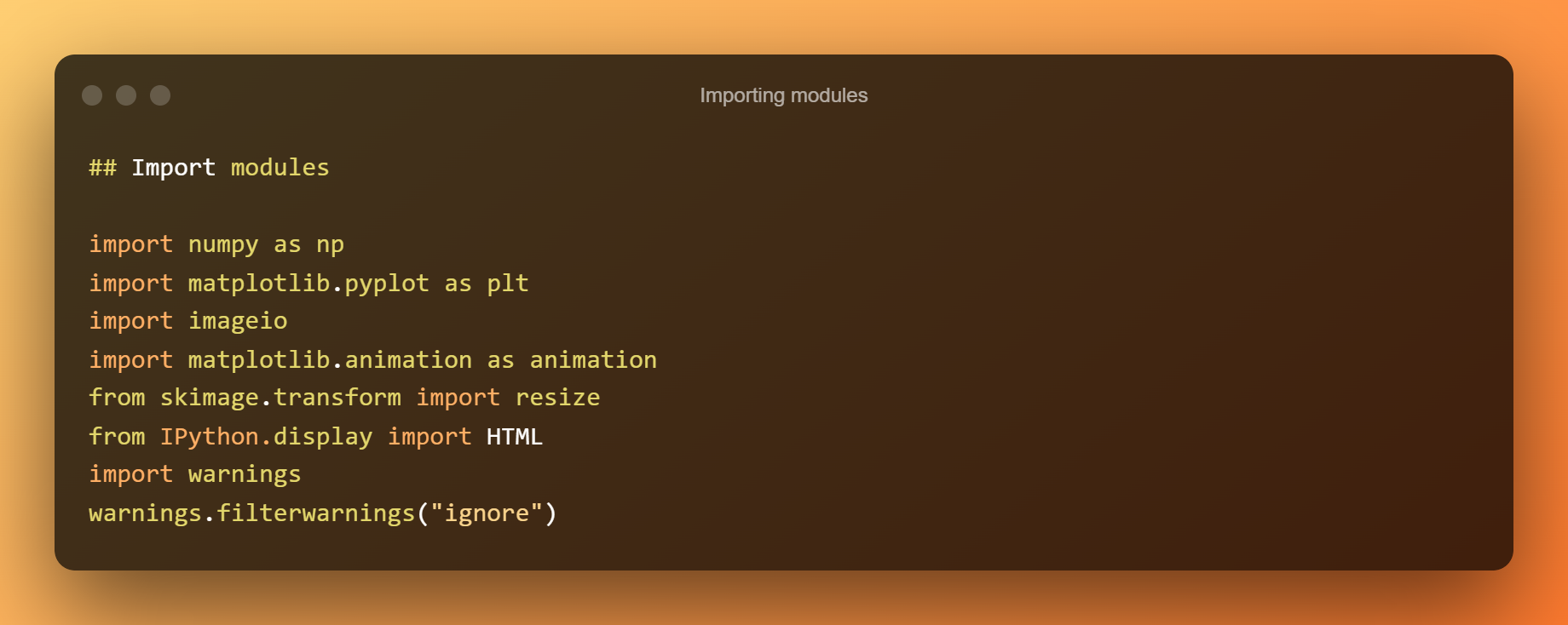
मॉड्यूल आयात करना
अब, हम सभी आवश्यक मॉड्यूल आयात करेंगे।
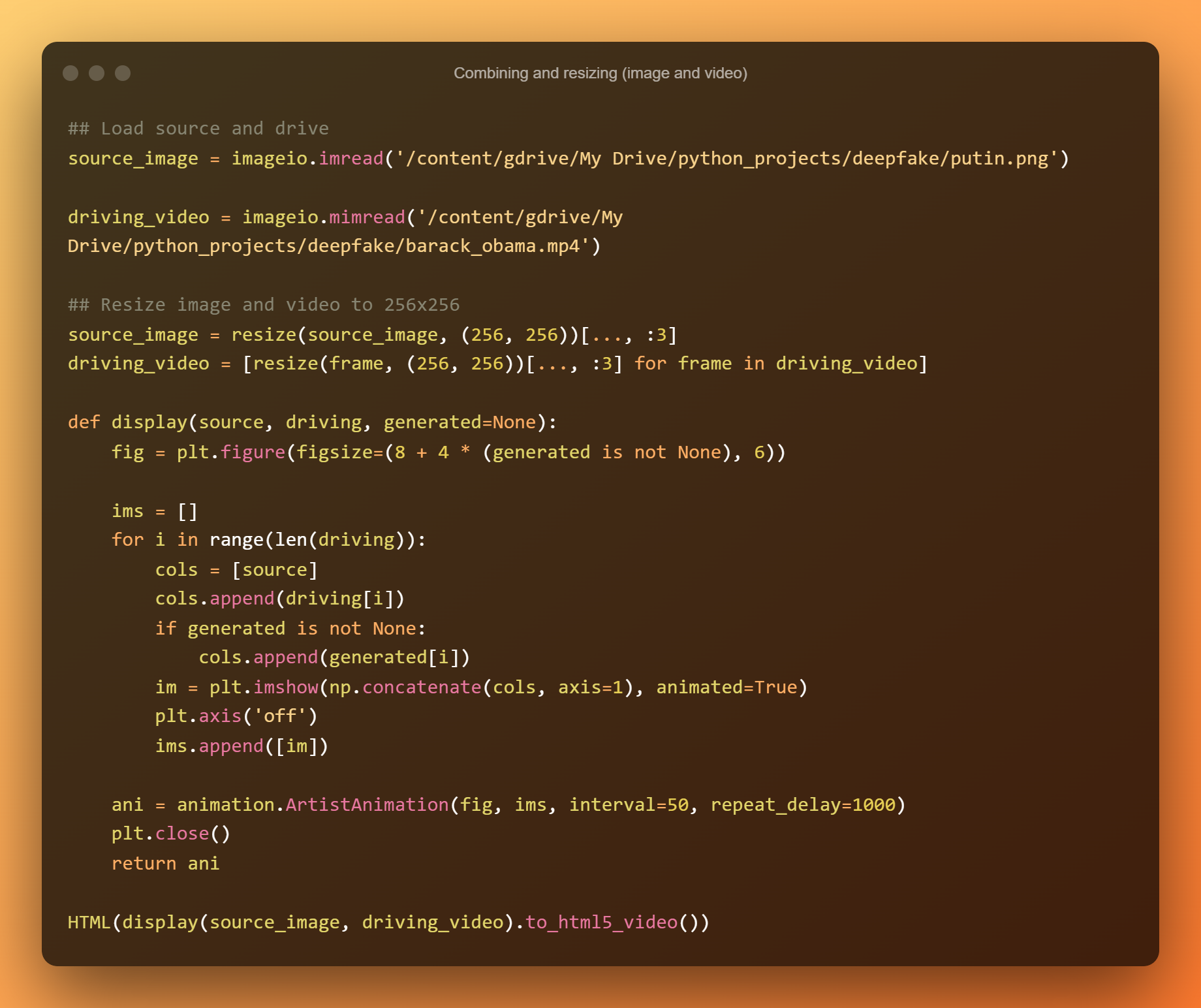
मॉडल का निष्पादन
हम एक उदाहरण का उपयोग करेंगे जो ओबामा के वीडियो के साथ पुतिन की एक स्थिर तस्वीर (स्रोत चित्र) को जोड़ती है। नतीजा यह है कि पुतिन ठीक उसी चेहरे के भावों के साथ बोलते और हावभाव करते हैं जो ओबामा गाड़ी चलाते समय इस्तेमाल करते थे।
मॉडल का परिणाम प्रदर्शित करने से पहले, मीडिया को लोड किया जाएगा और कार्यों की घोषणा की जाएगी। फिर चौकियों को लोड किया जाएगा और मॉडल का निर्माण किया जाएगा। डीप फेक बनाने के बाद, एनीमेशन की दो अलग-अलग शैलियों को प्रदर्शित किया जाएगा।
सापेक्ष कीपॉइंट विस्थापन का उपयोग करते हुए ओबामा के आंदोलनों से पुतिन अनुप्राणित हैं। ओबामा के चेहरे की भावनाओं और बॉडी लैंग्वेज को जिस तरह से पुतिन के लिए उनके वीडियो के दौरान खूबसूरती और स्पष्ट रूप से चित्रित किया गया है, वह आश्चर्यजनक है।
कुछ सूक्ष्म गलतियाँ हैं, खासकर जब ओबामा अपनी भौंहें उठाते हैं और अपनी आँखें झपकाते हैं। इन भावों को पुतिन के फ्रेम में बिल्कुल दोहराया नहीं गया है।
गहरी नकली पृष्ठभूमि के बिना, पुतिन की फिल्म काफी विश्वसनीय और प्रामाणिक प्रतीत होगी यदि इसे टीवी पर देखा जाए या सोशल मीडिया.
मॉडल निर्माण
अब, हम एक पूर्ण मॉडल बनाने के लिए पूर्व-प्रशिक्षित चौकियों का उपयोग करेंगे।
डीपफेक डिटेक्शन
नीचे के सेल में आइटम्स को एनिमेट करने के लिए रिलेटिव कीपॉइंट विस्थापन का उपयोग किया जाता है। अगला सेल इसके बजाय निरपेक्ष निर्देशांक का उपयोग करता है, लेकिन सभी आइटम अनुपात इस तरह से ड्राइविंग वीडियो से लिए जाएंगे।
निरपेक्ष निर्देशांक का उपयोग करके आउटपुट बढ़ाना

आप इस तरह से डीपफेक डिटेक्शन विकसित करने में सक्षम होंगे।
डीपफेक टेक्नोलॉजी के जोखिम क्या हैं?
डीपफेक वीडियो अब अपनी नवीनता के कारण देखने में आकर्षक और मनोरंजक हैं। हालांकि, एक जोखिम है जो इस प्रतीत होने वाली अजीब तकनीक की सतह के नीचे नियंत्रण से बाहर हो सकता है।
नकली और असली वीडियो के बीच अंतर करना निश्चित रूप से चुनौतीपूर्ण होगा गहरी तकनीक आगे बढ़ना जारी है। प्रमुख हस्तियों और मशहूर हस्तियों के लिए, विशेष रूप से, इसके गंभीर प्रभाव हो सकते हैं। जानबूझकर दुर्भावनापूर्ण डीपफेक में करियर और जीवन को पूरी तरह से नुकसान पहुंचाने की क्षमता होती है।
इनका उपयोग किसी के द्वारा दूसरों के लिए पारित करने और अपने दोस्तों, रिश्तेदारों और सहकर्मियों का लाभ उठाने के लिए किया जा सकता है। वे विदेशी नेताओं की नकली फिल्मों का उपयोग करके दुनिया भर में विवादों और यहां तक कि युद्धों को भड़काने में भी सक्षम हैं।
निष्कर्ष
संक्षेप में, हम एक अजीब अवधि और असामान्य वातावरण में हैं। पहले से कहीं अधिक, झूठी खबरें और फिल्में बनाना और उन्हें फैलाना आसान है। क्या सच है और क्या नहीं यह समझना लगातार चुनौतीपूर्ण होता जा रहा है।
आज, ऐसा प्रतीत होता है, हम अब अपनी इंद्रियों पर भरोसा नहीं कर सकते।
इस तथ्य के बावजूद कि झूठे वीडियो डिटेक्टर विकसित किए गए हैं, यह केवल कुछ समय पहले की बात है जब सूचना का अंतर इतना कम हो जाता है कि बेहतरीन नकली डिटेक्टर भी यह निर्धारित करने में असमर्थ होंगे कि वीडियो वास्तविक है या नहीं।





एक जवाब लिखें