

Let’s imagine you’re trying to teach a robot how to walk. Unlike teaching a computer how to predict stock prices or categorize images, we don’t really have a large dataset that we can use to train our robot.
While it may come naturally to you, walking is actually a very complex action. Walking a step typically involves dozens of different muscles working together. The effort and techniques used to walk from one place to another also depend on a variety of factors, including whether you are carrying something or whether there is an incline or other forms of obstacles.
In scenarios like these, we can use a method known as reinforcement learning or RL. With RL, you can define a specific goal you want your model to solve and gradually let the model learn on its own how to accomplish it.
In this article, we’ll explore the basics of reinforcement learning and how we can apply the RL framework to a variety of different problems in the real world.
What is reinforcement learning?
Reinforcement learning refers to a particular subset of machine learning that focuses on finding solutions by rewarding desired behaviors and punishing undesired behaviors.

Unlike supervised learning, the reinforcement learning method typically does not have a training dataset that provides the right output for a given input. In the absence of training data, the algorithm must find the solution through trial and error. The algorithm, which we typically refer to as an agent, must find the solution by itself by interacting with the environment.
Researchers decide on what particular outcomes to reward and what the algorithm is capable of doing. Every action the algorithm takes will receive some form of feedback that scores how well the algorithm is doing. During the training process, the algorithm will eventually find the optimal solution to solve a certain problem.
A Simple Example: 4×4 Grid
Let’s take a look at a simple example of a problem we can solve with reinforcement learning.
Suppose we have a 4×4 grid as our environment. Our agent is placed randomly in one of the squares along with a few obstacles. The grid shall contain three “pit” obstacles that must be avoided and a single “diamond” reward which the agent must find. The complete description of our environment is known as the environment’s state.

In our RL model, our agent can move to any adjacent square as long as there are no obstacles blocking them. The set of all valid actions in a given environment is known as the action space. The goal of our agent is to find the shortest path to the reward.

Our agent will use the reinforcement learning method to find the path to the diamond that requires the least amount of steps. Each right step will give the robot a reward and each wrong step will subtract the reward of the robot. The model calculates the total reward once the agent reaches the diamond.
Now that we’ve defined the agent and environment, we must also define the rules to use for determining the next action the agent will take given its current state and the environment.
Policies and Rewards
In a reinforcement learning model, a policy refers to the strategy used by an agent to accomplish their goals. The agent’s policy is what decides what the agent should do next given the current state of the agent and its environment.
The agent must evaluate all possible policies to see which policy is optimal.

In our simple example, landing on an empty space will return a value of -1. When the agent lands on a space with the diamond reward, they will receive a value of 10. Using these values, we can compare the different policies using a utility function U.
Let’s now compare the utility of the two policies seen above:
U(A) = -1 – 1 -1 + 10 = 7
U(B) = -1 – 1 – 1 – 1 – 1 + 10 = 5
The results show that Policy A is the better path to finding the reward. Thus, the agent will use Path A over Policy B.
Exploration vs. Exploitation
The exploration vs. exploitation trade-off problem in reinforcement learning is a dilemma an agent must face during the decision process.
Should agents focus on exploring new paths or options or should they continue exploiting the options they already know?
If the agent chooses to explore, there is a possibility for the agent to find a better option, but it may also risk wasting time and resources. On the other hand, if the agent chooses to exploit the solution it already knows, it may miss out on a better option.
Practical Applications
Here are some ways AI researchers have applied reinforcement learning models to solve real-world problems:
Reinforcement Learning in Self-Driving Cars
Reinforcement learning has been applied to self-driving cars in order to improve their ability to drive safely and efficiently. The technology enables autonomous cars to learn from their mistakes and continually adjust their behavior in order to optimize their performance.

For example, the London-based AI company Wayve has successfully applied a deep reinforcement learning model for autonomous driving. In their experiment, they used a reward function that maximizes the amount of time the vehicle runs without the driver onboard providing input.
RL models also help cars make decisions based on the environment, such as avoiding obstacles or merging into traffic. These models must find a way to convert the complex environment surrounding a car into a representative state space that the model can understand.
Reinforcement Learning in Robotics
Researchers have also been using reinforcement learning to develop robots that can learn complex tasks. Through these RL models, robots are able to observe their environment and make decisions based on their observations.
For example, research has been made on using reinforcement learning models to allow bipedal robots to learn how to walk on their own.
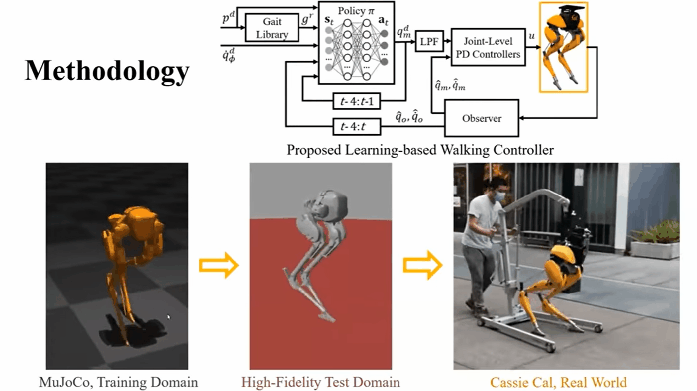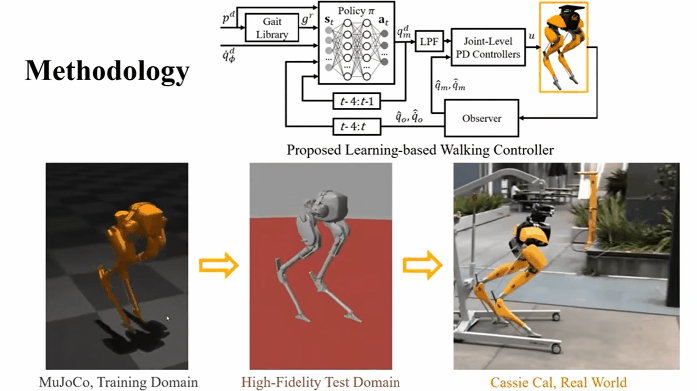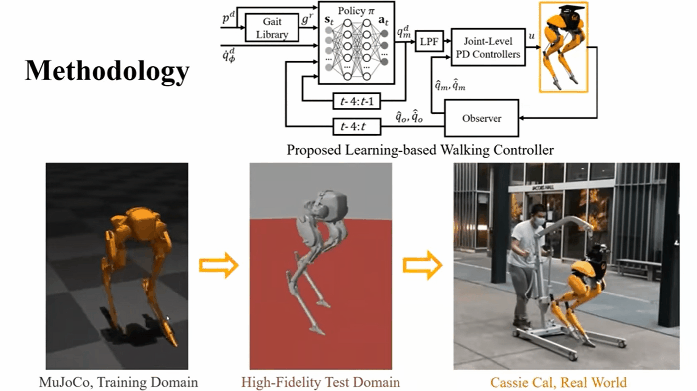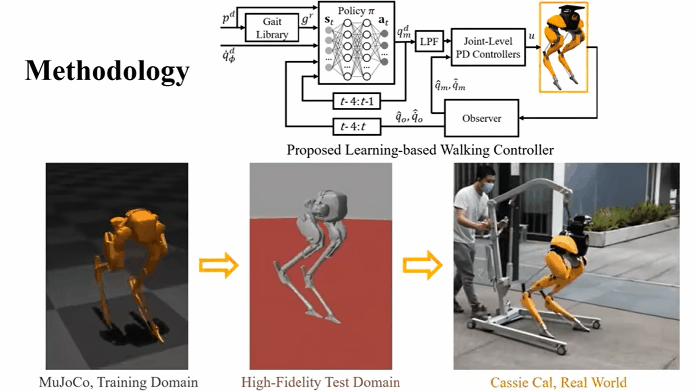
Researchers consider RL to be a key method in the field of robotics. Reinforcement learning gives robotic agents a framework to learn sophisticated actions that may be otherwise difficult to engineer.
Reinforcement Learning in Gaming
RL models have also been used to learn how to play video games. Agents can be set up to learn from their mistakes and continually improve their performance in the game.
Researchers have already developed agents that can play games such as chess, Go, and poker. In 2013, DeepMind used Deep Reinforcement Learning to allow a model to learn how to play Atari games from scratch.
Many board games and video games have a limited action space and a well-defined concrete goal. These traits work to the RL model’s advantage. RL methods can quickly iterate over millions of simulated games to learn the optimal strategies to achieve victory.
Conclusion
Whether it is learning how to walk or learning how to play video games, RL models have been proven to be useful AI frameworks for solving problems that require complex decision-making.
As the technology continues to evolve, both researchers and developers will continue to find new applications that take advantage of the model’s self-teaching ability.
What practical applications do you think reinforcement learning can help with?




Leave a Reply