Índice analítico[Ocultar][Mostrar]
O futuro está aquí. E, neste futuro, as máquinas comprenden o mundo que as rodea do mesmo xeito que as persoas. Os ordenadores poden conducir automóbiles, diagnosticar enfermidades e prever con precisión o futuro.
Isto pode parecer ciencia ficción, pero os modelos de aprendizaxe profunda fano realidade.
Estes algoritmos sofisticados están revelando os segredos de intelixencia artificial, permitindo que os ordenadores se autoaprendan e se desenvolvan. Nesta publicación, afondaremos no ámbito dos modelos de aprendizaxe profunda.
E, investigaremos o enorme potencial que teñen para revolucionar as nosas vidas. Prepárate para aprender sobre a tecnoloxía de punta que está a cambiar o futuro da humanidade.

Que son exactamente os modelos de aprendizaxe profunda?
Xogaches algunha vez a un xogo no que teñas que identificar as diferenzas entre dúas imaxes?
Non obstante, é divertido, tamén pode ser difícil, non? Imaxina poder ensinarlle a un ordenador a xogar a ese xogo e gañar cada vez. Os modelos de aprendizaxe profunda logran precisamente iso!
Os modelos de aprendizaxe profunda son similares ás máquinas superintelixentes que poden examinar un gran número de imaxes e determinar o que teñen en común. Conségueno desmontando as imaxes e estudando cada unha individualmente.
Despois aplican o que aprenderon para identificar patróns e facer predicións sobre imaxes novas que nunca antes viron.

Os modelos de aprendizaxe profunda son redes neuronais artificiais que poden aprender e extraer patróns e características complicadas de conxuntos de datos masivos. Estes modelos están formados por varias capas de nodos ligados, ou neuronas, que analizan e cambian os datos entrantes para xerar unha saída.
Os modelos de aprendizaxe profunda son especialmente axeitados para traballos que requiren gran precisión e precisión, como a identificación de imaxes, o recoñecemento de voz, o procesamento da linguaxe natural e a robótica.
Utilizáronse en todo, desde coches autónomos ata diagnósticos médicos, sistemas de recomendación e análise preditiva.
Aquí tes unha versión simplificada da visualización para ilustrar o fluxo de datos nun modelo de aprendizaxe profunda.
Os datos de entrada flúen á capa de entrada do modelo, que despois pasa os datos a través dunha serie de capas ocultas antes de proporcionar unha predición de saída.
Cada capa oculta realiza unha serie de operacións matemáticas sobre os datos de entrada antes de pasalos á seguinte capa, que proporciona a predición final.
Agora, vexamos cales son os modelos de aprendizaxe profunda e como podemos utilizalos na nosa vida.
1. Redes neuronais convolucionais (CNN)
As CNN son un modelo de aprendizaxe profunda que transformou a área da visión por ordenador. As CNN úsanse para clasificar imaxes, recoñecer obxectos e segmentar imaxes. A estrutura e función do córtex visual humano informou o deseño das CNN.
Como funcionan?
Unha CNN está formada por varias capas convolucionais, capas de agrupación e capas totalmente ligadas. A entrada é unha imaxe e a saída é unha predición da etiqueta de clase da imaxe.
As capas convolucionais dunha CNN constrúen un mapa de características realizando un produto puntual entre a imaxe de entrada e un conxunto de filtros. As capas de agrupación reducen o tamaño do mapa de características reducindo a mostra.
Finalmente, o mapa de características é usado polas capas totalmente conectadas para predicir a etiqueta de clase da imaxe.

Por que son importantes as CNN?
As CNN son esenciais porque poden aprender a detectar patróns e características en imaxes que ás persoas lles resulta difícil notar. Pódese ensinar ás CNN a recoñecer características como bordos, esquinas e texturas usando grandes conxuntos de datos. Despois de aprender estas propiedades, unha CNN pode usalas para identificar obxectos en fotos novas. As CNN demostraron un rendemento de vangarda nunha variedade de aplicacións de identificación de imaxes.
Onde usamos as CNN
A saúde, a industria do automóbil e o comercio polo miúdo son só algúns dos sectores que empregan CNN. Na industria da saúde, poden ser beneficiosos para o diagnóstico de enfermidades, o desenvolvemento de medicamentos e a análise de imaxes médicas.
No sector do automóbil, axudan á detección de carril, detección de obxectos, e condución autónoma. Tamén son moi utilizados na venda polo miúdo para a busca visual, a recomendación de produtos baseados en imaxes e o control de inventario.
Por exemplo; Google emprega CNN nunha variedade de aplicacións, incluíndo Lente de Google, unha ferramenta de identificación de imaxes moi apreciada. O programa usa CNN para avaliar fotografías e dar información aos usuarios.
Google Lens, por exemplo, pode recoñecer cousas nunha imaxe e ofrecer detalles sobre elas, como o tipo de flor.

Tamén pode traducir o texto que se extrae dunha imaxe a varios idiomas. Google Lens é capaz de ofrecer aos consumidores información útil grazas á asistencia das CNN para identificar con precisión elementos e extraer características das fotos.
2. Redes de memoria a longo prazo (LSTM).
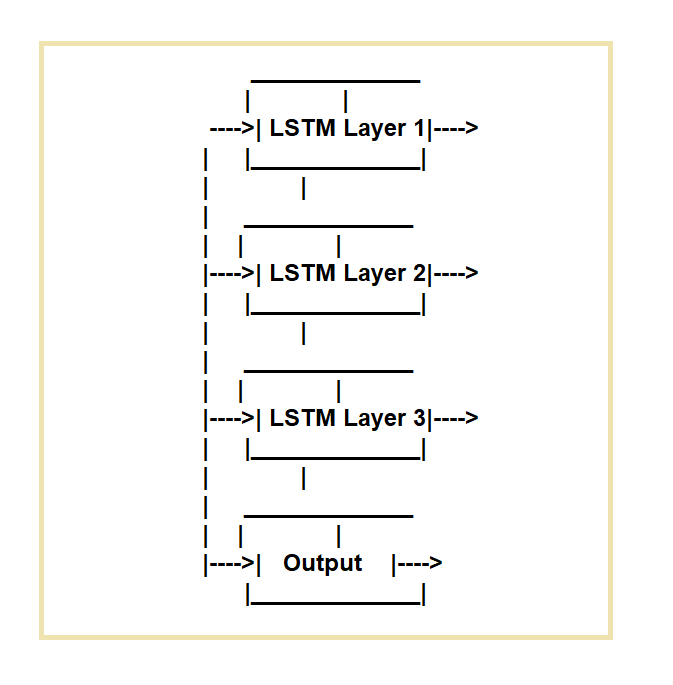
As redes de memoria a curto prazo (LSTM) créanse para solucionar as deficiencias das redes neuronais recorrentes regulares (RNN). As redes LSTM son ideais para tarefas que requiren o procesamento de secuencias de datos ao longo do tempo.
Funcionan empregando unha célula de memoria específica e tres mecanismos de activación.
Regulan o fluxo de información dentro e fóra da célula. A porta de entrada, a porta de esquecemento e a porta de saída son as tres portas.
A porta de entrada regula o fluxo de datos na cela de memoria, a porta de esquecemento regula a eliminación de datos da cela e a porta de saída regula o fluxo de datos fóra da cela.
Cal é o seu significado?
As redes LSTM son útiles porque poden representar e prever con éxito secuencias de datos con relacións a longo prazo. Poden rexistrar e conservar información sobre entradas anteriores, o que lles permite facer predicións máis precisas sobre entradas futuras.
O recoñecemento de voz, o recoñecemento de escritura a man, o procesamento da linguaxe natural e os subtítulos de imaxes son só algunhas das aplicacións que fixeron uso das redes LSTM.
Onde usamos as redes LSTM?
Moitas aplicacións de software e tecnoloxía empregan redes LSTM, incluíndo sistemas de recoñecemento de voz, ferramentas de procesamento de linguaxes naturais como análise de sentimentos, sistemas de tradución automática e sistemas de xeración de textos e imaxes.
Tamén se utilizaron na creación de coches e robots autónomos, así como na industria financeira para detectar fraudes e anticipar mercado de accións movementos.
3. Redes xerativas adversarias (GAN)
Os GAN son a aprendizaxe profunda técnica que se utiliza para xerar novas mostras de datos que sexan similares a un conxunto de datos determinado. Os GAN están formados por dous redes neuronais: un que aprende a producir novas mostras e outro que aprende a distinguir entre mostras xenuínas e xeradas.
Nun enfoque similar, estas dúas redes adestran xuntas ata que o xerador pode xerar mostras que non se poden distinguir das reais.
Por que usamos GAN
Os GAN son importantes pola súa capacidade de producir de alta calidade datos sintéticos que se poden utilizar para unha variedade de aplicacións, incluíndo produción de imaxes e vídeos, xeración de texto e incluso xeración de música.
Os GAN tamén se utilizaron para o aumento de datos, que é a xeración de datos sintéticos para complementar datos do mundo real e mellorar o rendemento dos modelos de aprendizaxe automática.
Ademais, ao crear datos sintéticos que se poden usar para adestrar modelos e imitar ensaios, as GAN teñen o potencial de transformar sectores como o da medicina e o desenvolvemento de fármacos.

Aplicacións dos GAN
Os GAN poden complementar conxuntos de datos, crear novas imaxes ou películas e mesmo xerar datos sintéticos para simulacións científicas. Ademais, os GAN teñen o potencial de ser empregados nunha variedade de aplicacións que van desde o entretemento ata a medicina.
idades e vídeos. StyleGAN2 de NVIDIA, por exemplo, utilizouse para crear fotografías de alta calidade de famosos e obras de arte.
4. Redes de crenza profunda (DBN)
As redes de crenza profunda (DBN) son intelixencia artificial sistemas que poden aprender a detectar patróns nos datos. Eles conseguen isto segmentando os datos en anacos cada vez máis pequenos, gañando unha comprensión máis completa dos mesmos en cada nivel.
Os DBN poden aprender a partir dos datos sen que se lles informe de que se trata (denomínase "aprendizaxe non supervisada"). Isto fai que sexan moi valiosos para detectar patróns en datos que a unha persoa lle resultaría difícil ou imposible discernir.
Que fai que os DBN sexan significativos?
Os DBN son significativos pola súa capacidade para aprender representacións de datos xerárquicos. Estas representacións pódense utilizar para unha variedade de aplicacións como clasificación, detección de anomalías e redución da dimensionalidade.
A capacidade dos DBN para realizar adestramento previo sen supervisión, que pode aumentar o rendemento dos modelos de aprendizaxe profunda cun mínimo de datos etiquetados, é un beneficio significativo.

Cales son as aplicacións dos DBN?
Unha das aplicacións máis significativas é detección de obxectos, no que os DBN úsanse para recoñecer certos tipos de cousas como avións, aves e humanos. Tamén se utilizan para a xeración e clasificación de imaxes, a detección de movemento en películas e a comprensión da linguaxe natural para o procesamento da voz.
Ademais, os DBN úsanse habitualmente en conxuntos de datos para avaliar as posturas humanas. Os DBN son unha excelente ferramenta para unha variedade de industrias, incluíndo a asistencia sanitaria, a banca e a tecnoloxía.
5. Redes de aprendizaxe de reforzo profundo (DRL)
profundo Aprendizaxe de reforzo As redes (DRL) integran redes neuronais profundas con técnicas de aprendizaxe de reforzo para permitir que os axentes aprendan nun ambiente complicado mediante proba e erro.
Os DRL úsanse para ensinar aos axentes a optimizar un sinal de recompensa interactuando co seu entorno e aprendendo dos seus erros.
Que os fai notables?
Utilizáronse de forma eficaz nunha variedade de aplicacións, incluíndo xogos, robótica e condución autónoma. Os DRL son importantes porque poden aprender directamente da entrada sensorial bruta, o que permite aos axentes tomar decisións en función das súas interaccións co medio.
Aplicacións importantes
Os DRL úsanse en circunstancias reais porque poden xestionar problemas difíciles.
Os DRL foron incluídos en varias plataformas tecnolóxicas e de software destacadas, incluíndo OpenAI's Gym, Os axentes ML de Unity, e DeepMind Lab de Google. AlphaGo, construído por Google Deepmind, por exemplo, emprega DRL para xogar ao xogo de mesa Go a nivel de campión do mundo.

Outro uso do DRL é na robótica, onde se usa para controlar os movementos dos brazos robóticos para executar tarefas como agarrar cousas ou apilar bloques. Os DRL teñen moitos usos e son unha ferramenta útil para formación de axentes para aprender e tomar decisións en contextos complicados.
6. Autocodificadores
Os codificadores automáticos son un tipo interesante de rede neural que captou o interese tanto de estudosos como de científicos de datos. Están deseñados fundamentalmente para aprender a comprimir e restaurar datos.
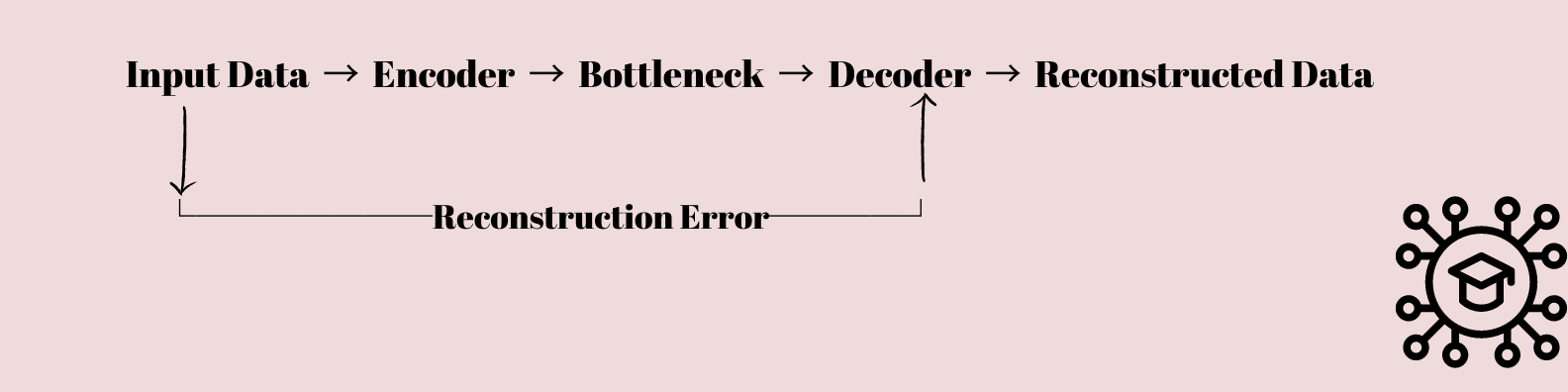
Os datos de entrada aliméntanse a través dunha sucesión de capas que reducen gradualmente a dimensionalidade dos datos ata que se comprimen nunha capa de pescozo de botella con menos nodos que as capas de entrada e saída.
Esta representación comprimida emprégase entón para recrear os datos orixinais de entrada usando unha secuencia de capas que aumentan gradualmente a dimensionalidade dos datos de novo á súa forma orixinal.
Por que é importante?
Os codificadores automáticos son un compoñente crucial aprendizaxe profunda porque posibilitan a extracción de características e a redución de datos.
Son capaces de identificar os elementos clave dos datos entrantes e traducilos nunha forma comprimida que despois pode aplicarse a outras tarefas como clasificación, agrupación ou creación de novos datos.
Onde usamos os codificadores automáticos?
Detección de anomalías, procesamento da linguaxe natural e visión por computador son só algunhas das disciplinas onde se usan os codificadores automáticos. Os codificadores automáticos, por exemplo, pódense usar para a compresión de imaxes, a eliminación de ruído e a síntese de imaxes en visión por ordenador.
Podemos usar os codificadores automáticos en tarefas como a creación de texto, a categorización de texto e o resumo de texto no procesamento da linguaxe natural. Pode identificar actividade anómala en datos que se desvían da norma na identificación de anomalías.
7. Redes de cápsulas
Capsule Networks é unha nova arquitectura de aprendizaxe profunda que se desenvolveu como substitución das redes neuronais convolucionais (CNN).
As Redes de Cápsulas baséanse na noción de agrupar unidades cerebrais chamadas cápsulas que se encargan de recoñecer a existencia dun determinado elemento nunha imaxe e de codificar os seus atributos, como a orientación e a posición, nos seus vectores de saída. As Redes Cápsulas poden xestionar as interaccións espaciais e as flutuacións de perspectiva mellor que as CNN.
Por que escollemos as redes de cápsula en lugar das de CNN?
As redes de cápsulas son útiles porque superan as dificultades de CNN para capturar relacións xerárquicas entre os elementos dunha imaxe. As CNN poden recoñecer cousas de varios tamaños, pero loitan por comprender como se conectan estes elementos entre si.
Capsule Networks, pola súa banda, pode aprender a recoñecer as cousas e as súas pezas, así como a como se sitúan espacialmente nunha imaxe, o que as converte nun competidor viable para aplicacións de visión artificial.
Áreas de Aplicación
Capsule Networks xa demostrou resultados prometedores nunha variedade de aplicacións, incluíndo clasificación de imaxes, identificación de obxectos e segmentación de imaxes.
Utilizáronse para distinguir cousas en fotos médicas, recoñecer persoas en películas e incluso crear modelos 3D a partir de imaxes 2D.
Para aumentar o seu rendemento, as redes cápsulas combináronse con outras arquitecturas de aprendizaxe profunda como as redes xerativas adversarias (GAN) e os codificadores automáticos variacionais (VAE). Prevese que as redes de cápsulas desempeñarán un papel cada vez máis vital na mellora das tecnoloxías de visión por ordenador a medida que evoluciona a ciencia da aprendizaxe profunda.
Por exemplo; Nibabel é unha coñecida ferramenta de Python para ler e escribir tipos de ficheiros de neuroimaxes. Para a segmentación de imaxes, emprega Capsule Networks.
8. Modelos baseados na atención
Os modelos de aprendizaxe profunda coñecidos como modelos baseados na atención, tamén coñecidos como mecanismos de atención, esfórzanse por aumentar a precisión da modelos de aprendizaxe automática. Estes modelos funcionan concentrándose en determinadas características dos datos entrantes, o que resulta nun procesamento máis eficiente e eficaz.
En tarefas de procesamento da linguaxe natural, como a tradución automática e a análise de sentimentos, os métodos de atención demostraron ser bastante exitosos.
Cal é a súa importancia?
Os modelos baseados na atención son útiles porque permiten un procesamento máis eficaz e eficiente de datos complicados.
Redes neuronais tradicionais avaliar todos os datos de entrada como igualmente importantes, o que resulta nun procesamento máis lento e unha precisión diminuída. Os procesos de atención céntranse en aspectos cruciais dos datos de entrada, o que permite realizar predicións máis rápidas e precisas.

Áreas de uso
No campo da intelixencia artificial, os mecanismos de atención teñen unha ampla gama de aplicacións, incluíndo o procesamento da linguaxe natural, o recoñecemento de imaxes e audio, e mesmo os vehículos sen condutor.
Os métodos de atención, por exemplo, pódense utilizar para mellorar a tradución automática no procesamento da linguaxe natural ao permitir que o sistema se centre en determinadas palabras ou frases que son esenciais para o contexto.
Pódense empregar métodos de atención nos coches autónomos para axudar ao sistema a centrarse en determinados elementos ou desafíos da súa contorna.
9. Redes de transformadores
As redes transformadoras son modelos de aprendizaxe profunda que examinan e producen secuencias de datos. Funcionan procesando a secuencia de entrada un elemento á vez e producindo unha secuencia de saída de lonxitudes igual ou diferentes.
As redes transformadoras, a diferenza dos modelos estándar de secuencia a secuencia, non procesan secuencias usando redes neuronais recorrentes (RNN). En cambio, empregan procesos de autoatención para aprender os vínculos entre as pezas da secuencia.
Cal é a importancia das redes de transformadores?
As redes transformadoras creceron en popularidade nos últimos anos como resultado do seu mellor rendemento nos traballos de procesamento da linguaxe natural.
Son especialmente axeitados para tarefas de creación de texto, como tradución de idiomas, resumo de textos e produción de conversas.
As redes de transformadores son significativamente máis eficientes computacionalmente que os modelos baseados en RNN, polo que son unha opción preferida para aplicacións a gran escala.

Onde podes atopar redes de transformadores?
As redes transformadoras empréganse amplamente nunha ampla gama de aplicacións, sobre todo no procesamento da linguaxe natural.
A serie GPT (Generative Pre-Trained Transformer) é un modelo destacado baseado en transformadores que se utilizou para tarefas como a tradución de idiomas, o resumo de textos e a xeración de chatbots.
BERT (Bidirectional Encoder Representations from Transformers) é outro modelo común baseado en transformadores que se utilizou para aplicacións de comprensión da linguaxe natural, como respostas de preguntas e análise de sentimentos.
Tanto GPT e BERT foron creados con PyTorch, un marco de aprendizaxe profundo de código aberto que foi popular para desenvolver modelos baseados en transformadores.
10. Máquinas Boltzmann restrinxidas (RBM)
As máquinas de Boltzmann restrinxidas (RBM) son unha especie de rede neuronal non supervisada que aprende de forma xerativa. Debido á súa capacidade para aprender e extraer características esenciais de datos de alta dimensión, foron amplamente empregados nos campos da aprendizaxe automática e da aprendizaxe profunda.
Os RBM están formados por dúas capas, visibles e ocultas, e cada capa está formada por un grupo de neuronas conectadas por bordos ponderados. Os RBM están deseñados para aprender unha distribución de probabilidade que describe os datos de entrada.
Que son as máquinas Boltzmann restrinxidas?
Os RBM empregan unha estratexia de aprendizaxe xerativa. Nos RBM, a capa visible reflicte os datos de entrada, mentres que a capa soterrada codifica as características dos datos de entrada. Os pesos das capas visibles e ocultas mostran a forza da súa ligazón.
Os RBM axustan os pesos e os prexuízos entre as capas durante o adestramento mediante unha técnica coñecida como diverxencia contrastiva. A diverxencia contrastiva é unha estratexia de aprendizaxe non supervisada que maximiza a probabilidade de predición do modelo.
Cal é a importancia das máquinas Boltzmann restrinxidas?
Os RBM son importantes aprendizaxe de máquina e aprendizaxe profunda porque poden aprender e extraer características relevantes de grandes cantidades de datos.
Son moi eficaces para o recoñecemento de imaxes e de voz, e empregáronse nunha variedade de aplicacións como sistemas de recomendación, detección de anomalías e redución de dimensións. Os RBM poden atopar patróns en amplos conxuntos de datos, o que resulta en predicións e coñecementos superiores.

Onde se poden usar as máquinas Boltzmann restrinxidas?
As aplicacións para RBM inclúen a redución da dimensionalidade, a detección de anomalías e os sistemas de recomendación. Os RBM son especialmente útiles para a análise de sentimentos e modelado de temas no contexto do procesamento da linguaxe natural.
As redes de crenzas profundas, unha especie de rede neuronal utilizada para o recoñecemento de voz e imaxe, tamén empregan RBM. A caixa de ferramentas da rede Deep Belief, TensorFlowe Teano son algúns exemplos particulares de software ou tecnoloxía que usa RBM.
Envolver
Os modelos de aprendizaxe profunda son cada vez máis cruciais nunha variedade de industrias, incluíndo o recoñecemento de voz, o procesamento da linguaxe natural e a visión por ordenador.
As redes neuronais convolucionais (CNN) e as redes neuronais recorrentes (RNN) mostraron as máis prometedoras e utilízanse amplamente en moitas aplicacións, con todo, todos os modelos de aprendizaxe profunda teñen as súas vantaxes e desvantaxes.
Non obstante, os investigadores seguen investigando as máquinas de Boltzmann restrinxidas (RBM) e outras variedades de modelos de aprendizaxe profunda porque tamén teñen vantaxes especiais.
Prevese que se creen modelos novos e creativos a medida que a área de aprendizaxe profunda continúa avanzando para xestionar problemas máis difíciles.





Deixe unha resposta