O rascado web converteuse nun método crucial para obter datos perspicaces das plataformas de internet na sociedade actual de datos.
Como un sitio de redes sociais moi popular, Instagram ofrece moito material xerado polos usuarios. E, estes datos xerados pódense usar para mercadotecnia, investigación e outros motivos.
Os usuarios poden extraer datos de Instagram con facilidade e eficacia grazas aos scrapers de Instagram ricos en funcións de Bright Data, un líder rascado web ferramenta. Nesta publicación, daremos un paso a paso detallado do proceso de raspado de Instagram.
Entón, vexamos os pasos sobre como podemos extraer datos de Instagram.
Comprensión de Instagram Scrapers a partir de Bright Data
Coa axuda de dous raspadores web multiusos e un conxunto de datos precompilados, Bright Data ofrece unha variedade de servizos de raspado de Instagram. Estas tecnoloxías ofrecen versatilidade na extracción de datos e adáptanse a diversas demandas.
Examinemos cada unha destas opcións con máis detalle:
a. Explorador de raspado
A tecnoloxía innovadora coñecida como Scraping Browser creouse para satisfacer as demandas dos proxectos de rascado de datos. Ofrece todo o necesario para raspar a escala dentro dun único navegador. Destaca grazas á súa automatización integrada de desbloqueo de sitios web, o que o converte no único navegador deste tipo en todo o mundo.
Scraping Browser ofrece aos usuarios acceso a funcións robustas que van máis alá dos navegadores automatizados e sen cabeza, o que lles permite superar incluso os scripts máis difíciles e as barreiras do sitio web para a detección de bots.
O rascado de datos é máis eficaz e sen problemas debido ás súas funcións de axuste automatizado, que xestionan facilmente bloques novos, solucións CAPTCHA, impresións dixitais e reintentos, e aparece como un usuario xenuíno.
Usando AI para superar os sistemas de detección de bots
Ao utilizar tecnoloxía de IA de vangarda, Scraping Browser pode burlar os sistemas de detección de bots e axustarse continuamente ás súas estratexias de cambio. Para desbloquear mellor as páxinas web, Scraping Browser aprende dos intentos destes sistemas de detectar e bloquear os intentos de raspado e modifica o seu comportamento de forma adecuada.
Supera a eficiencia dos proxies convencionais ao imitar o comportamento dun navegador usado por un usuario real. Como resultado, os clientes poden concentrarse nos seus obxectivos para o rascado de datos sen ter que xestionar a dificultade e o gasto dos procedementos de detección de bots en curso.
b. Web Scraper IDE
Unha robusta ferramenta de rascado web creada para desenvolvedores, Web Scraper IDE pode xestionar tarefas de rascado complexas. Reduce considerablemente o tempo de desenvolvemento ao tempo que ofrece unha escalabilidade infinita grazas á súa solución completamente aloxada e ás funcións de raspado predefinidas. A aplicación permite a creación rápida e escalable de raspadores en liña proporcionando modelos de código e funcións JavaScript preparadas de sitios web populares.
Todo o necesario para un rascado web exitoso é proporcionado polo Web Scraper IDE. É unha solución completa para a extracción de datos en liña xa que as opcións de integración permiten aos clientes planificar os rastrexos ou inicialos a través da API e enlazar cos principais sistemas de almacenamento.
Como usalo? – Titoría
Primeiro, navegue ata o panel de control do usuario no sitio web.

Comecemos cos nosos pasos para raspar Instagram.
1- Navega ata o panel de control e fai clic na sección Datasets & Web Scraper IDE.
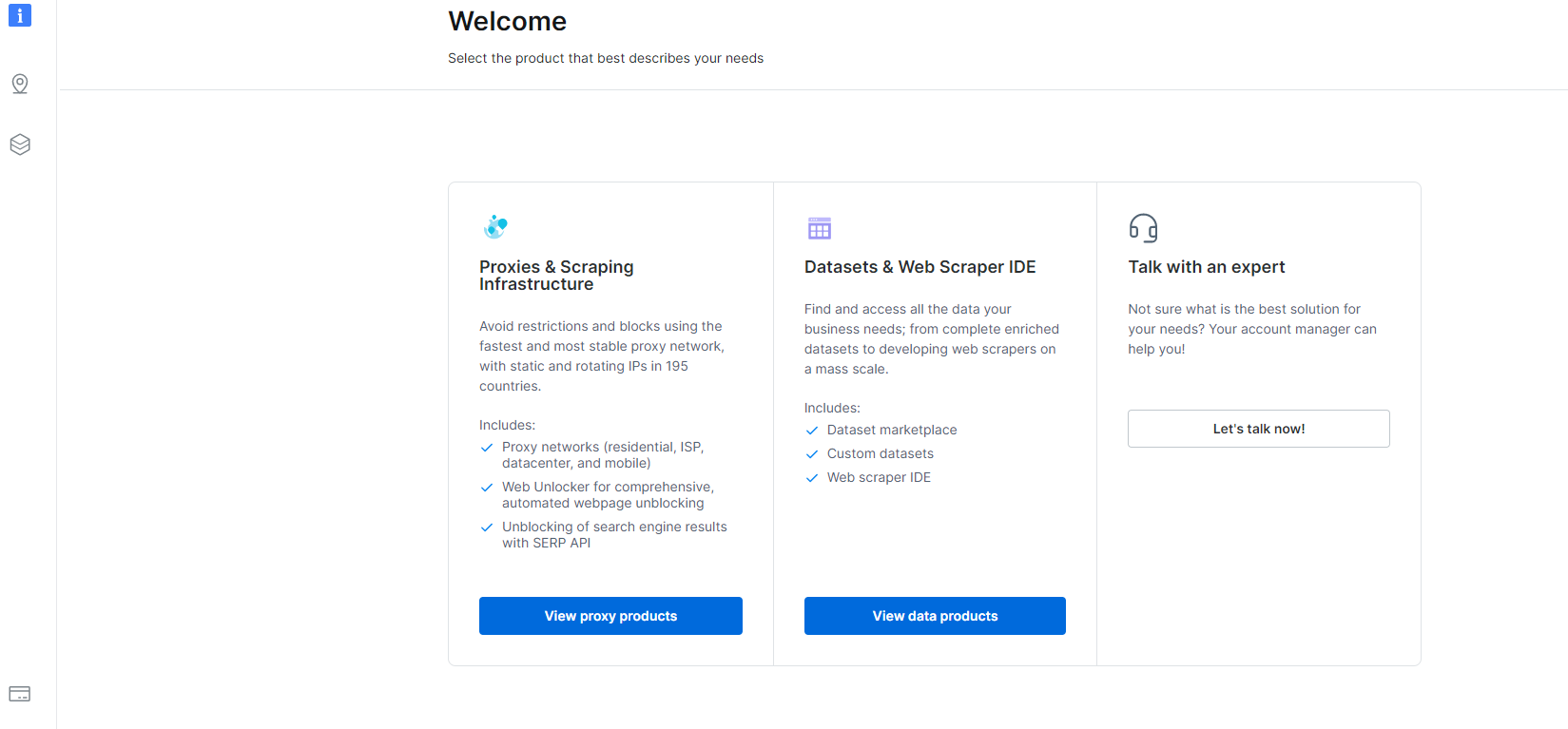
2- Unha vez que esteas alí, fai clic en My Scrapers.
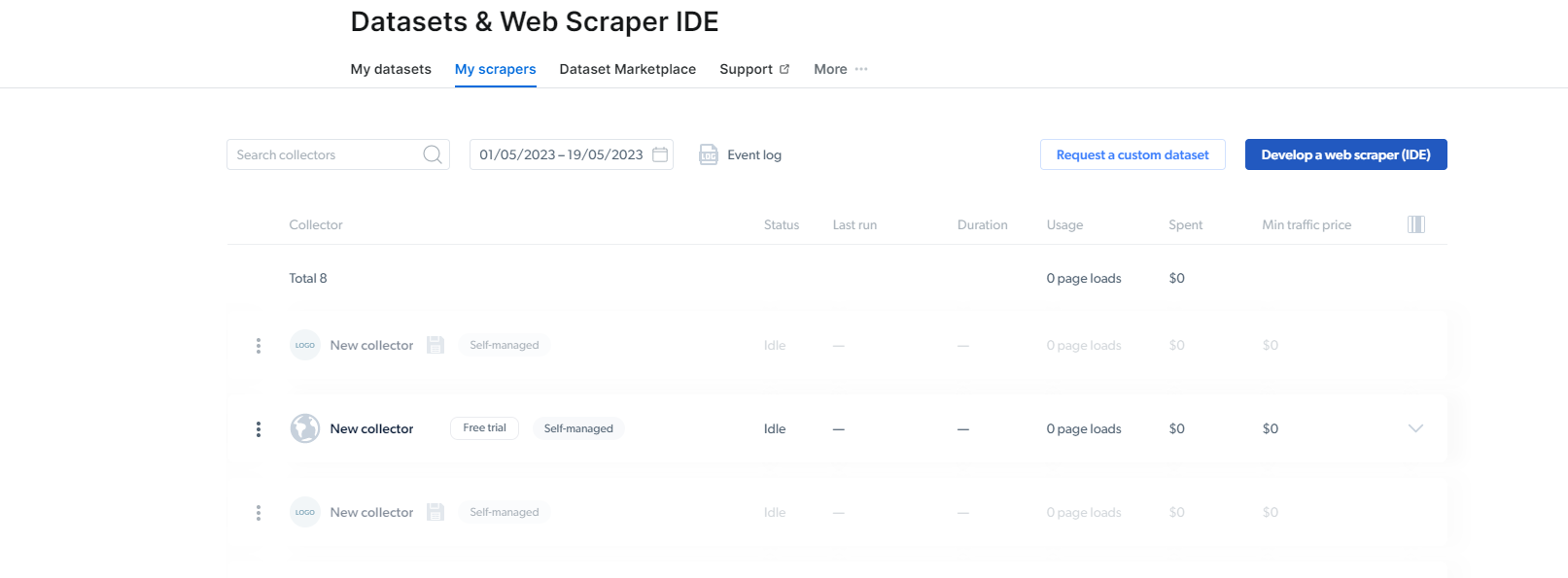
Aquí, cómpre facer clic en "Desenvolver un raspador web (IDE)". Aquí imos crear o noso raspador para Instagram.
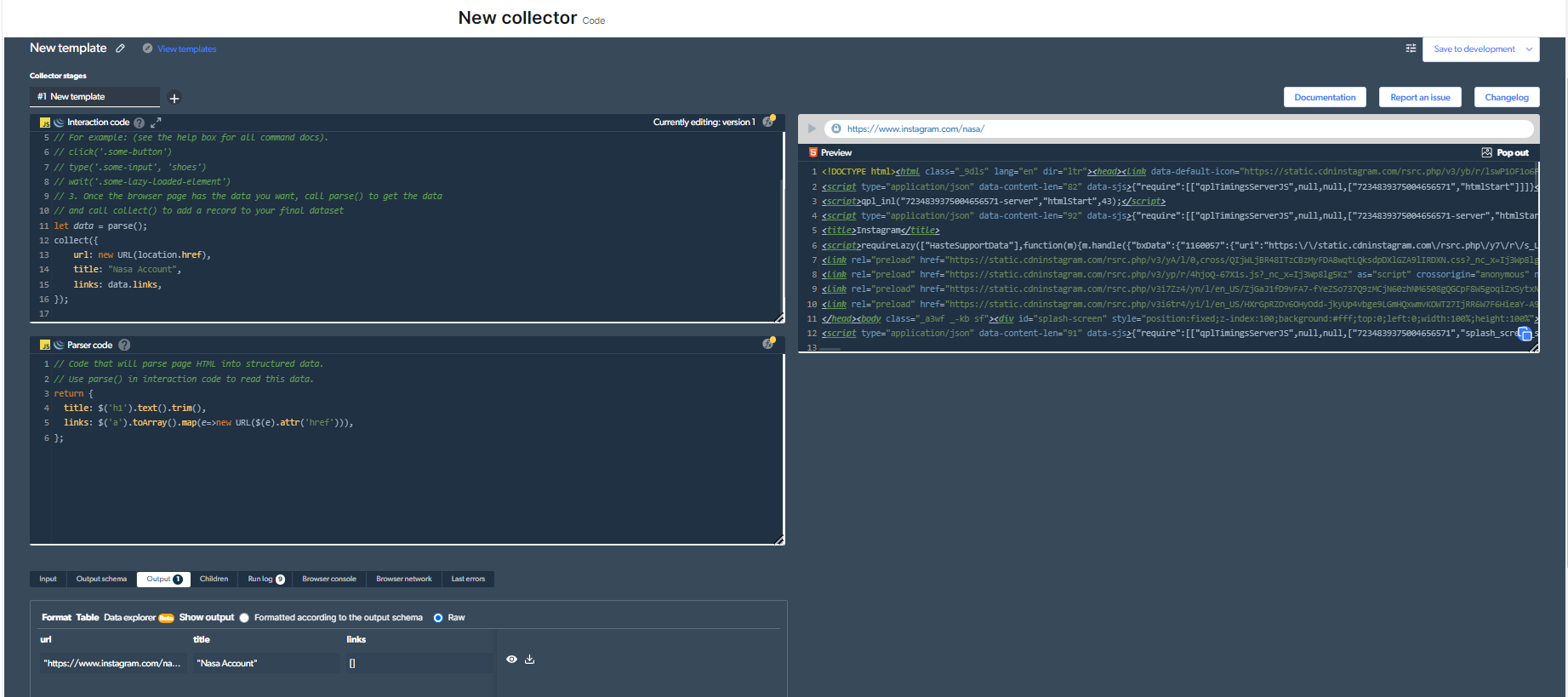
3-Agora, necesitamos desenvolver un novo raspador web. Só por este exemplo, escollo raspar a conta "NASA". Isto é só polo ben deste exemplo.
Entón, o meu código quedará así:
/ Click the 'play' button in the top right to run this code:
// 1. Go to the page where you want to start
navigate('https://www.instagram.com/nasa/');
// 2. Add anything else you need to do on the page.
// For example: (see the help box for all command docs).
// click('.some-button')
// type('.some-input', 'shoes')
// wait('.some-lazy-loaded-element')
// 3. Once the browser page has the data you want, call parse() to get the data
// and call collect() to add a record to your final dataset
let data = parse();
collect({
url: new URL(location.href),
title: "Nasa Account",
links: data.links,
});
Debes facer clic no botón "Xogar" na parte superior dereita para executar este código.
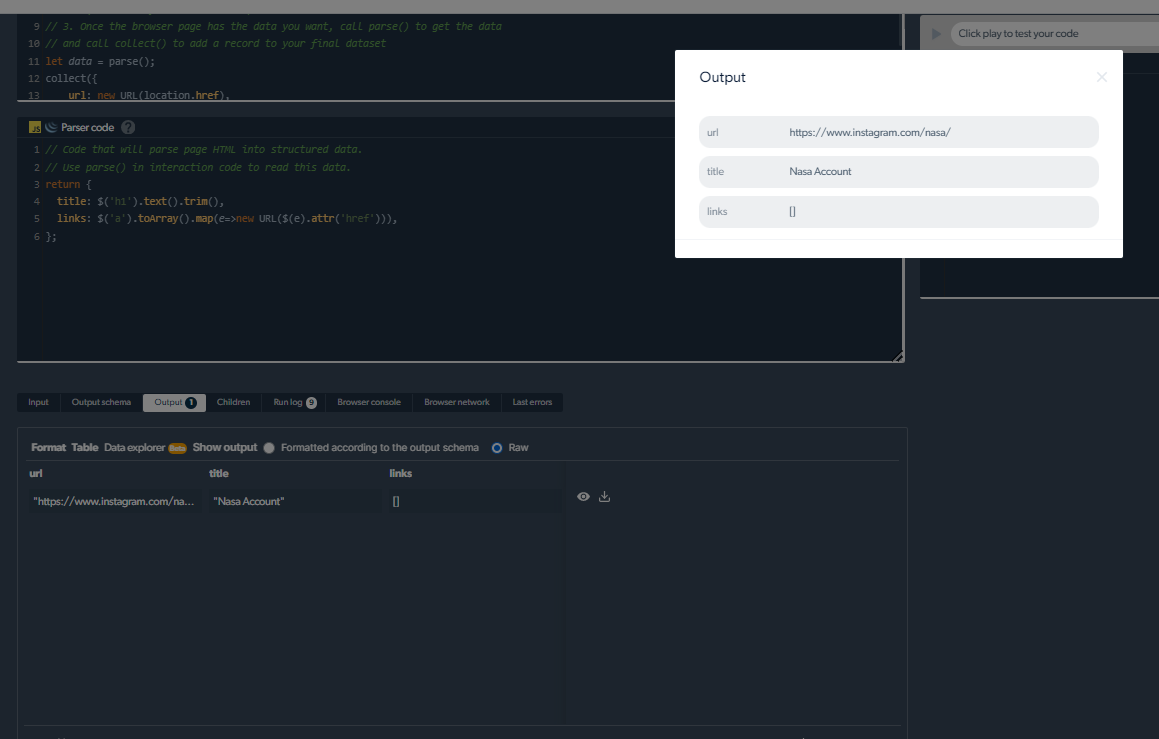
4- Agora, teremos unha saída.
Xestión de problemas de raspado
As publicacións de Instagram co botón "Mostrar máis" poden ser difíciles de capturar para os scrapers. Non obstante, os raspadores de Instagram de Bright Data están feitos para xestionar esa complexidade con éxito. Estes raspadores teñen habilidades de vangarda para atravesar a paxinación e carga de botóns adicionais.
Os scrapers de Instagram de Bright Data xestionan estas dificultades de forma eficaz para permitir unha extracción completa de datos, o que lle permite recoller toda a colección de información necesaria para a súa análise ou estudo.
Podes sortear os retos que presenta a natureza dinámica das publicacións de Instagram utilizando estas ferramentas de rascado.
c. Conjunto de datos pre-recollidos
Bright Data entende que non todos queren facer funcionar o seu rascador. Fornecen un conxunto de datos pre-recollidos para Instagram para atraer a estes consumidores.
Este conxunto de datos ofrece unha gran cantidade de información útil, como seguidores, perfís, publicacións e moito máis.
Bright Data ofrece opcións de personalización para personalizar o conxunto de datos ás súas necesidades, tanto se quere un conxunto de datos completo como un subconxunto de datos especializados. Este enfoque evita construír e xestionar un raspador, ofrecéndoche datos listos para usar para análise e información.
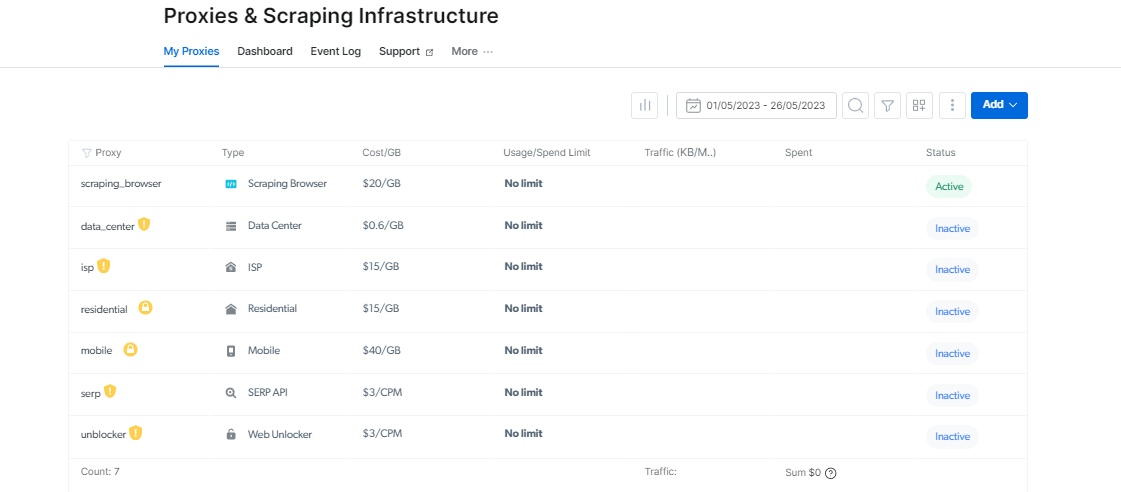
Agora, imos comprobar a infraestrutura que fai que estas ferramentas sexan tan eficaces: a infraestrutura proxy e Web Unlocker.
Libera o poder dos proxies
Uso proxies é fundamental durante o rascado web para garantir que as súas accións pasen desapercibidas.
Bright Data ofrece unha ampla selección de servizos de proxy que se adaptan ás súas necesidades. Podes escoller entre Proxectos residenciais, que ofrecen máis de 72 millóns de IP rotadas desde dispositivos de pares reais en 195 países.
Podes escoller Proxies ISP, que ofrecen máis de 700,000 IPs de casas reais en todo o mundo para uso a longo prazo; Proxies de centros de datos, que teñen máis de 770,000 IPs compartidas desde calquera xeolocalización; e Mobile Proxies, que forman a maior rede móbil 3G/4G de pares reais con máis de 7,000,000 de IPs.
Co uso destes proxies, pódese recoller facilmente datos mentres se fai pasar por un usuario autorizado en numerosos lugares.

Xestor de proxy: facilita a xestión de proxy
Xestionar varios proxies pode ser difícil, pero o Xestor de proxy faino doado.
Esta interface de código aberto permítelle xestionar todos os seus proxies desde unha única plataforma. Despídese da configuración e cambio manual de proxies. Proxy Manager simplifica o procedemento e aforra tempo e esforzo.
Extensión do navegador proxy: cambia a túa localización facilmente
Necesitas recompilar datos web de varias rexións? Estás cuberto pola nosa extensión do navegador proxy. Podes cambiar a túa localización de navegación cun só clic para obter información específica da rexión.
Aproveita a flexibilidade e a sinxeleza de recoller datos de varias rexións sen complicacións tecnolóxicas.
Como funciona? – Titoría
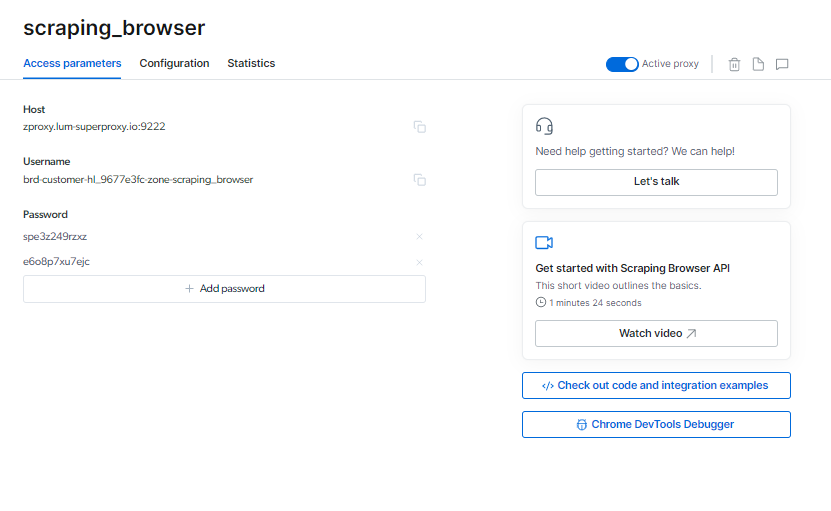
Podes localizar o teu Explorador de raspado información de inicio de sesión na páxina de parámetros de acceso, que se utilizará cando inicie unha nova sesión do navegador.
Consulta a documentación e as mostras de código, incluíndo un script de exemplo totalmente funcional que está listo para usar, ou mira un breve vídeo de instrucións de inicio. Por exemplo; aquí hai un Código Python exemplo de integración:
Queres axuda? Para conversar cun dos especialistas, podes facer clic na icona do chat.
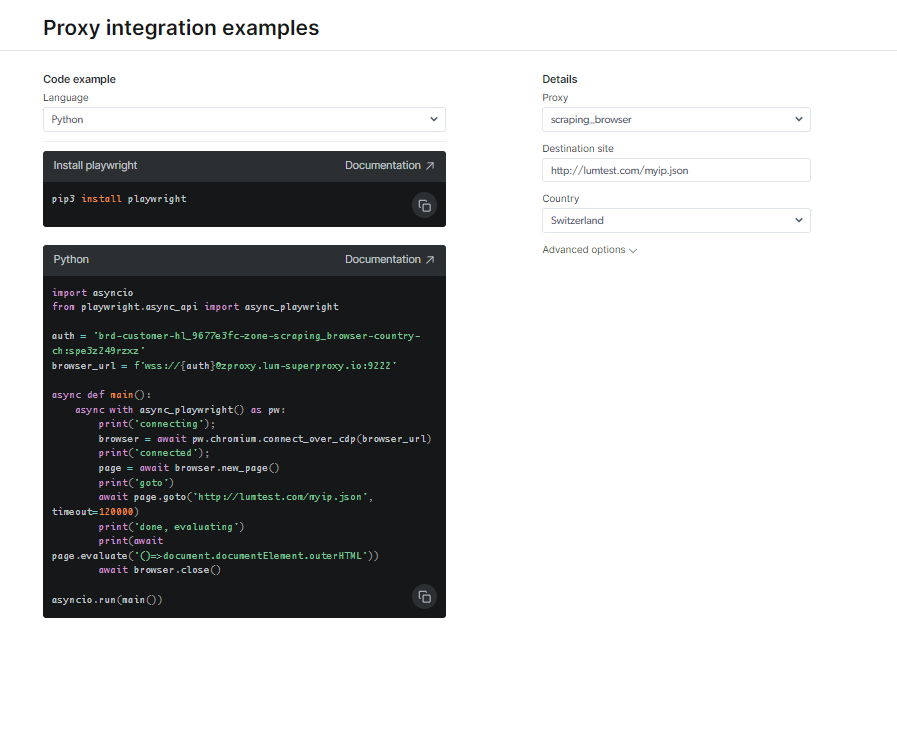
Ten en conta que tes control total sobre as sesións do navegador mentres usas Scraping Browser e que podes realizar calquera operación que admita Puppeteer, Playwright ou o uso directo do protocolo Chrome DevTools.
Desbloqueo de sitios web sen bloqueos
Scraping Browser está feito para funcionar a escala e segundo sexa necesario. Non te preocupes por ser prohibido; pode iniciar tantas sesións de navegador como necesite.
Esta capacidade, cando se combina coa forza dos proxies, garante a recollida continua de datos, o que lle permite obter de forma eficaz os datos que desexa.
As habilidades de desbloqueo integradas de Scraping Browser e a robusta rede proxy axúdanche a aforrar tempo, mellorar a produtividade e descubrir novas oportunidades.
Tamén podes consultar as estatísticas directamente desde a mesma páxina.
Prezos do navegador Scraping
Bright Data ofrece opcións de prezos personalizables para satisfacer unha variedade de propósitos. Podes escoller un período de facturación mensual ou anual.
A opción Pay as You Go permítelle pagar só polo que usas, sen ningún compromiso, a partir de 20.00 $/GB e 0.1 $/hora.
O plan de crecemento de 500 dólares é axeitado para empresas en crecemento, cunha tarifa con desconto de 15.30 dólares por GB e 0.1 dólares por hora.
o paquete comercial, que custa $ 1000, é a opción máis popular, coa API Scraping Browser custa $ 13.50 / GB e $ 0.1 / hora.
Ao contactar directamente co equipo de Bright Data, os usuarios empresariais poden gozar dunha escala infinita e de prezos personalizados. Comeza hoxe unha proba gratuíta para descubrir o potencial do navegador de rascado de Bright Data e cambiar os teus esforzos de raspado en liña.
Desbloqueador de sitios web
Web Unlocker é unha potente ferramenta creada para superar as restricións do sitio web e facilitar a recollida de datos. Supera varios desafíos, incluíndo cookies, axentes de usuario de navegador específicos do sitio e solucións de captcha, mediante o uso de procedementos automatizados.
Ao usar a rotación automática de enderezos IP, os usuarios de Web Unlocker poden raspar continuamente os sitios web de destino, asegurando o acceso constante a datos importantes.
Mellorar as viaxes de solicitudes dos programadores
Varias funcións fan que Web Unlocker sexa popular entre os desenvolvedores. O programa simplifica o proceso de recollida de datos identificando automaticamente os axentes de usuario necesarios para cada sitio web, aforrando tempo e recursos valiosos.
Web Unlocker adáptase en tempo real para evitar a detección en resposta ás estratexias en constante cambio empregadas polos bots de bloqueo, garantindo o acceso continuo aos sitios web de interese. Os algoritmos de aprendizaxe automática da plataforma poden resolver rapidamente os captchas, un obstáculo frecuente para as iniciativas de recollida de datos.

Prezos de Web Unlocker
A partir duns 2.03 dólares por mil solicitudes (CPM), Web Unlocker ofrece varias opcións de prezos para satisfacer varias demandas. Hai unha proba gratuíta de 7 días dispoñible para os usuarios para que poidan comezar e permitirlles probar as funcións de Web Unlocker antes de comprometerse.
Web Unlocker ten a capacidade de adaptación para admitir varios patróns de uso, independentemente de se os consumidores queren un enfoque de pago por uso ou necesitan un plan personalizado adaptado aos seus requisitos particulares. Ademais, aqueles que elixen plans de prezos a longo prazo poderían aforrar un 32%.
Comparación entre Web Unlocker con proxies autoxestionados
Web Unlocker ofrece numerosos beneficios instantáneos sobre os proxies autoxestionados. Para unha implementación sen problemas, ofrece unha técnica de integración extensa que combina funcións de superproxy e de xestor de proxy. Os usuarios poden escalar eficazmente as súas operacións de recollida de datos cun número infinito de conexións simultáneas.
Web Unlocker ofrece un desbloqueo automático, resolve os CAPTCHA e xestiona con éxito as modificacións de marcas nos sitios web de destino.
A plataforma garante a extracción de datos continua e fiable implementando un sistema de reintento automático e facendo chamadas asíncronas a determinados dominios. Ademais, a crecente colección de solicitudes de cabeceira HTTP de Unlocker en liña, cookies de navegador específicas do sitio e gadgets simulados permite aos usuarios permanecer sen ser detectados ao tempo que lles permite adquirir datos en liña en tempo real.
Pensamentos finais e cousas importantes para lembrar
Finalmente, ao usar Bright Data para o raspado de Instagram, é fundamental ter en conta algúns puntos vitais.
Teña en conta que as súas capacidades de raspado están limitadas a datos dispoñibles publicamente, por prácticas éticas.
Sempre debes seguir os termos de servizo e as políticas de privacidade de Instagram. O raspado debe facerse de forma ética e responsable, sen entrometerse nos dereitos dos usuarios nin infrinxir ningunha lei.
En segundo lugar, actualice e axuste regularmente os seus parámetros de raspado para garantir a precisión e a relevancia dos datos recuperados. A plataforma e os algoritmos de Instagram están suxeitos a cambios, polo que debes modificar as túas estratexias de raspado en consecuencia.
Finalmente, utiliza a axuda e os recursos da plataforma Bright Data para optimizar o éxito dos teus esforzos de raspado de Instagram. Participa coa súa documentación, titoriais e servizo ao cliente para mellorar o teu coñecemento das súas ferramentas de rascado.
Podes obter información útil, influír na toma de decisións sabias e ter éxito nas túas iniciativas baseadas en datos na plataforma de Instagram seguindo estas mellores prácticas e utilizando a forza das capacidades de raspado de Instagram de Bright Data.





Deixe unha resposta