Índice analítico[Ocultar][Mostrar]
Non é novo ter fotos e vídeos falsos. Desde o uso xeneralizado de internet, os individuos foron creando falsificacións destinadas a enganar ou divertir desde que houbo imaxes e películas.
Non obstante, hai un novo tipo de falsificacións producidas por máquinas que algún día nos poden dificultar distinguir a realidade da ficción.
Estas falsificacións difiren das simples manipulacións de imaxes xeradas por programas de edición como Photoshop ou as películas habilmente manipuladas do pasado.
Os deepfakes son o exemplo máis coñecido de "medios sintéticos": imaxes, sons e vídeos que parecen producirse mediante métodos convencionais pero que realmente se fixeron mediante software sofisticado.
Os deepfakes existen dende hai tempo e, aínda que a súa aplicación máis popular ata agora foi poñer as cabezas de personaxes famosos no corpo dos actores de películas pornográficas, teñen a capacidade de producir imaxes convincentes de calquera que fai calquera cousa, en calquera lugar.
Nesta publicación, imos ver os Deepfakes, como funciona, como pode xeralos por conta propia e moito máis.
Entón, que é DeepFake?
Un deepfake (unha combinación das frases deep learning e fake) é unha peza medios sintéticos na que se utiliza a semellanza doutra persoa para substituír a dunha persoa nunha fotografía ou vídeo xa existente.
Os deepfakes empregan técnicas sofisticadas de aprendizaxe automática e intelixencia artificial para modificar e crear información visual e sonora que ten un alto potencial de engano.
Os métodos de aprendizaxe profunda como os codificadores automáticos e as redes xerativas de confrontación son o mecanismo principal para a produción de deepfake (GAN).
Estes modelos utilízanse para analizar as emocións e movementos faciais dunha persoa e sintetizar imaxes faciais doutras persoas que presentan expresións e movementos comparables.
O uso de deepfakes en vídeos pornográficos de famosos, noticias falsas, enganos e fraude financeiro chamou considerablemente a atención. Tanto a industria como o goberno responderon intentando atopalos e limitar o seu uso.
Modelo de movemento de primeira orde
Ao tentar desenvolver falsos profundos no pasado, o problema era que necesitamos algún tipo de coñecemento adicional, ou previos, para que estes enfoques funcionen.
Como ilustración, os marcadores faciais son necesarios se queremos rastrexar o movemento da cabeza. A estimación da pose era necesaria se queriamos mapear o movemento de todo o corpo.
Iso cambiou na conferencia NeurIPS o ano pasado cando o equipo de investigación da Universidade de Toronto presentou o seu traballo, "Modelo de movemento de primeira orde para animación de imaxes. "
Non é necesario ningún coñecemento adicional de animación para este enfoque. Ademais, despois de adestrar este modelo, pódese utilizar para a aprendizaxe de transferencia e aplicarse a calquera elemento da mesma categoría.
Vexamos un pouco máis o funcionamento deste método. A extracción e xeración de movementos constitúen a primeira metade de todo o proceso. O vídeo de condución e as imaxes de orixe utilízanse como entradas.
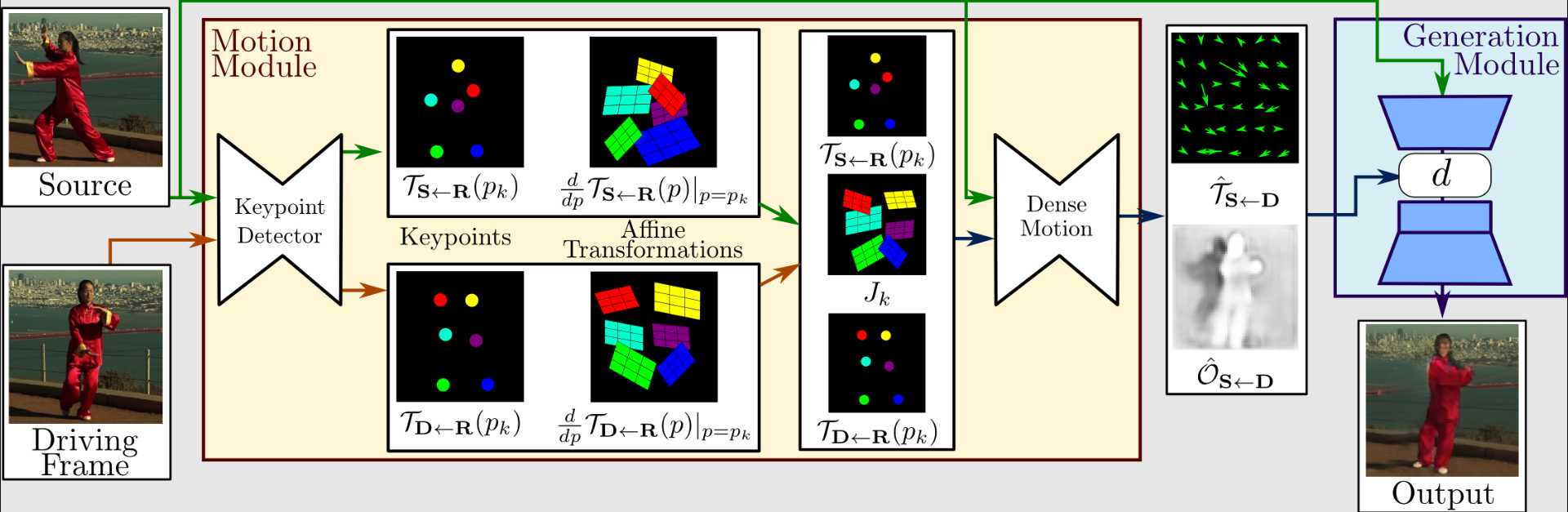
Para extraer a representación de movemento de primeira orde, que consiste en puntos clave escasos e transformacións afines locais, un extractor de movemento usa un codificador automático para identificar puntos clave.
Para crear un fluxo óptico denso e un mapa de oclusión coa rede de movemento denso, empréganse xunto co vídeo de condución. A continuación, o xerador renderiza a imaxe de destino usando as saídas da rede de movemento densa e a imaxe de orixe.
En xeral, este traballo funciona mellor que o estado da arte. Tamén contén características que outros modelos simplemente non teñen. Funciona en varios tipos de imaxes, polo que podes aplicala a imaxes da cara, corpo, debuxos animados, etc., o que é moi xenial.
Con isto créanse moitas oportunidades novas. Outro aspecto innovador da nosa estratexia é que agora che permite producir Deepfakes de alta calidade usando só unha imaxe do obxecto obxectivo, de xeito similar ao que facemos con YOLO para obxecto recoñecemento.
Proceso de creación de modelo Deepfake
Son necesarios tres procesos para a xeración de deepfake: extracción, formación e creación. Neste apartado trataranse os puntos principais de cada unha destas etapas e como se relacionan co proceso global.
Extracción
Os deepfakes usan redes neuronais profundas para cambiar de cara e necesitan moitos datos (imaxes) para funcionar de forma correcta e convincente. O proceso de extracción é a etapa na que se extraen todos os fotogramas dos videoclips, recoñécense as caras e, a continuación, aliñan as caras para maximizar o rendemento.
formación
Na fase de formación, o rede neural pode cambiar unha cara por outra. Dependendo do tamaño do conxunto de prácticas e do gadget de adestramento, o adestramento pode levar varias horas ou incluso días.
O adestramento só ten que rematar unha vez, como a maioría dos outros adestramentos de redes neuronais. Despois do adestramento, o modelo podería cambiar un rostro da persoa A á persoa B.
Creación
Despois de que o modelo fose adestrado, pódese producir un deepfake. Os fotogramas son tomados dun vídeo e despois aliñados a todas as caras. A rede neuronal adestrada emprégase entón para transformar cada cadro.
A cara transformada debe combinarse co marco orixinal como último paso.
Construír un modelo de detección de Deepfake
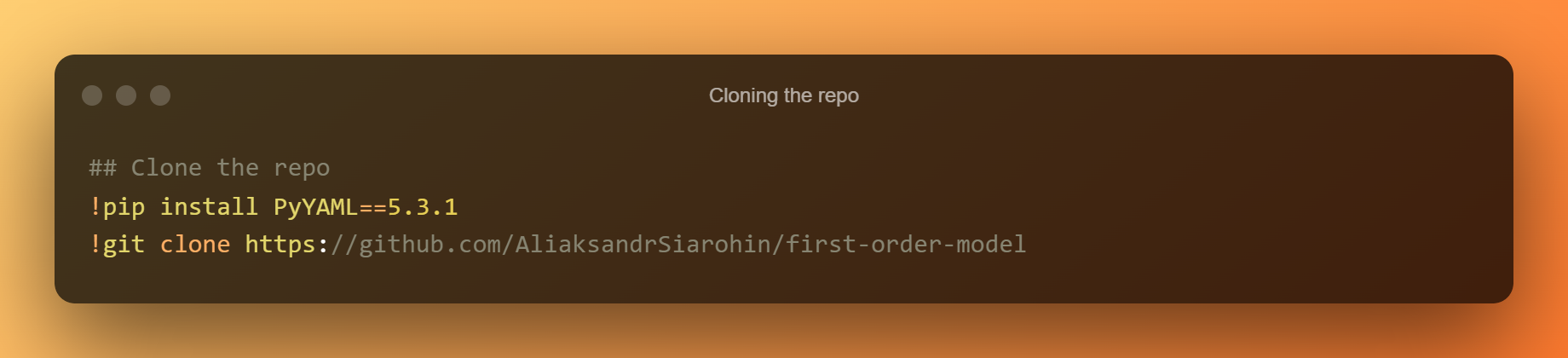
Montaxe e clonación de GitHub Repo
Poder usar as GPU de Google de balde mentres traballas en Colab é vantaxoso aprendizaxe profunda. Unha vantaxe adicional é a posibilidade de montar un Google Drive nunha máquina virtual (VM) na nube.
Con fácil acceso a todas as súas cousas, o usuario está habilitado. Neste apartado atoparase o programa necesario para montar Google Drive na máquina virtual na nube.


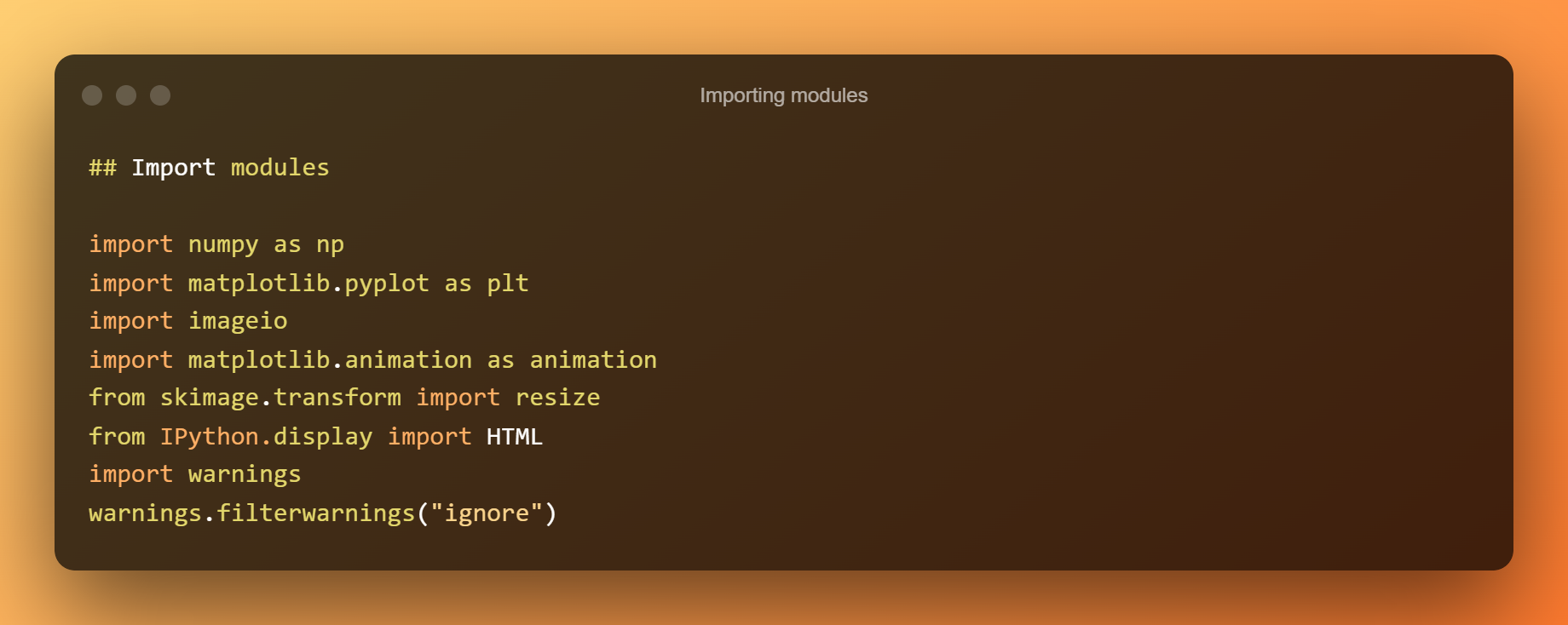
Importación de módulos
Agora importaremos todos os módulos necesarios.
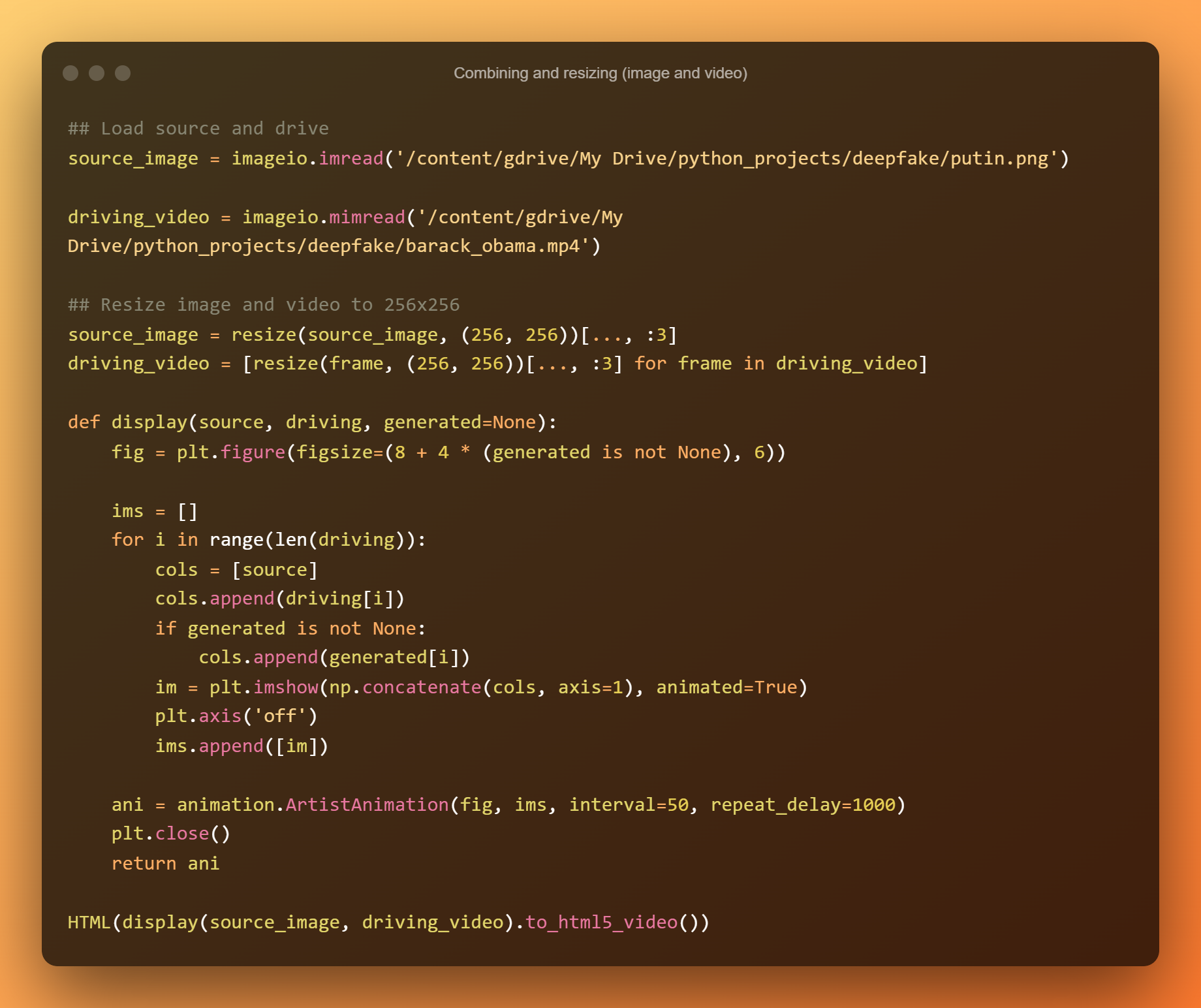
Execución do modelo
Usaremos un exemplo que combina unha foto fixa de Putin (foto fonte) cun vídeo de Obama. O resultado é un vídeo de Putin falando e xesticulando coas mesmas expresións faciais que usaba Obama mentres conducía.
Antes de mostrar o resultado do modelo, cargaranse os medios e declararanse as funcións. Despois cargaranse os puntos de control e construirase o modelo. Despois de crear o deep fake, mostraranse dous estilos diferentes de animación.
Putin está animado polos movementos de Obama que utilizan o desprazamento relativo de puntos clave. A forma en que as emocións faciais e a linguaxe corporal de Obama son representadas de xeito fermoso e claro para Putin durante os seus vídeos é sorprendente.
Hai algúns erros microscópicos, especialmente cando Obama levanta as cellas e pestanexa os ollos. Estas expresións non se replican exactamente nos marcos de Putin.
Sen o fondo falso, a película de Putin parecería ser bastante crible e auténtica se fose vista na televisión ou medios sociais.
Creación de modelos
Agora, usaremos os puntos de control previamente adestrados para crear un modelo completo.
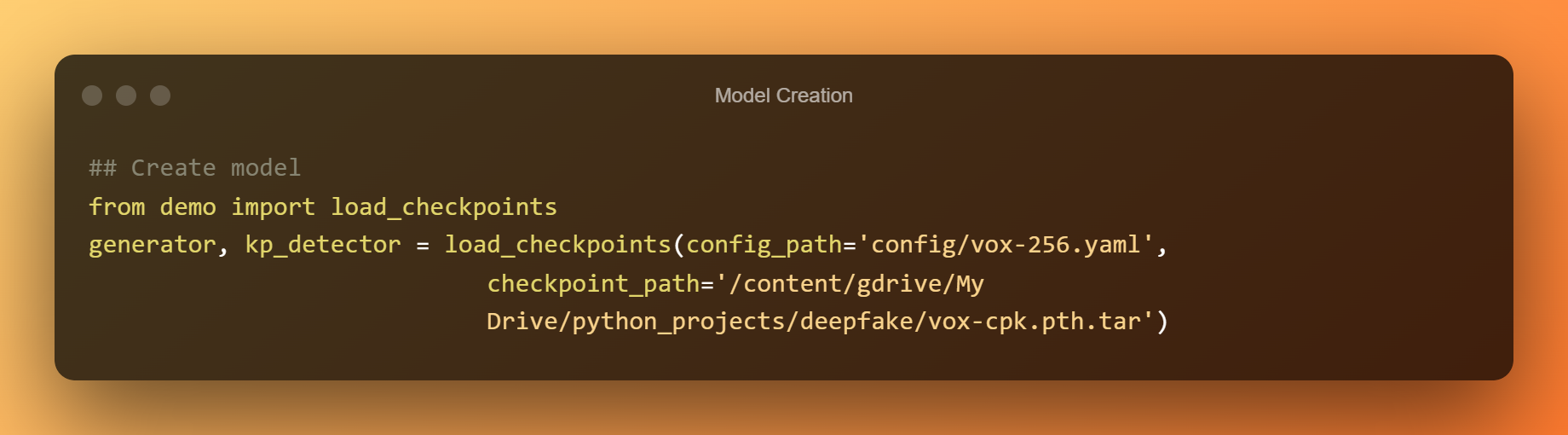
Detección de deepfake
O desprazamento relativo do punto clave úsase para animar os elementos da cela de abaixo. A seguinte cela utiliza coordenadas absolutas, pero todas as proporcións dos elementos serán tomadas do vídeo de condución deste xeito.
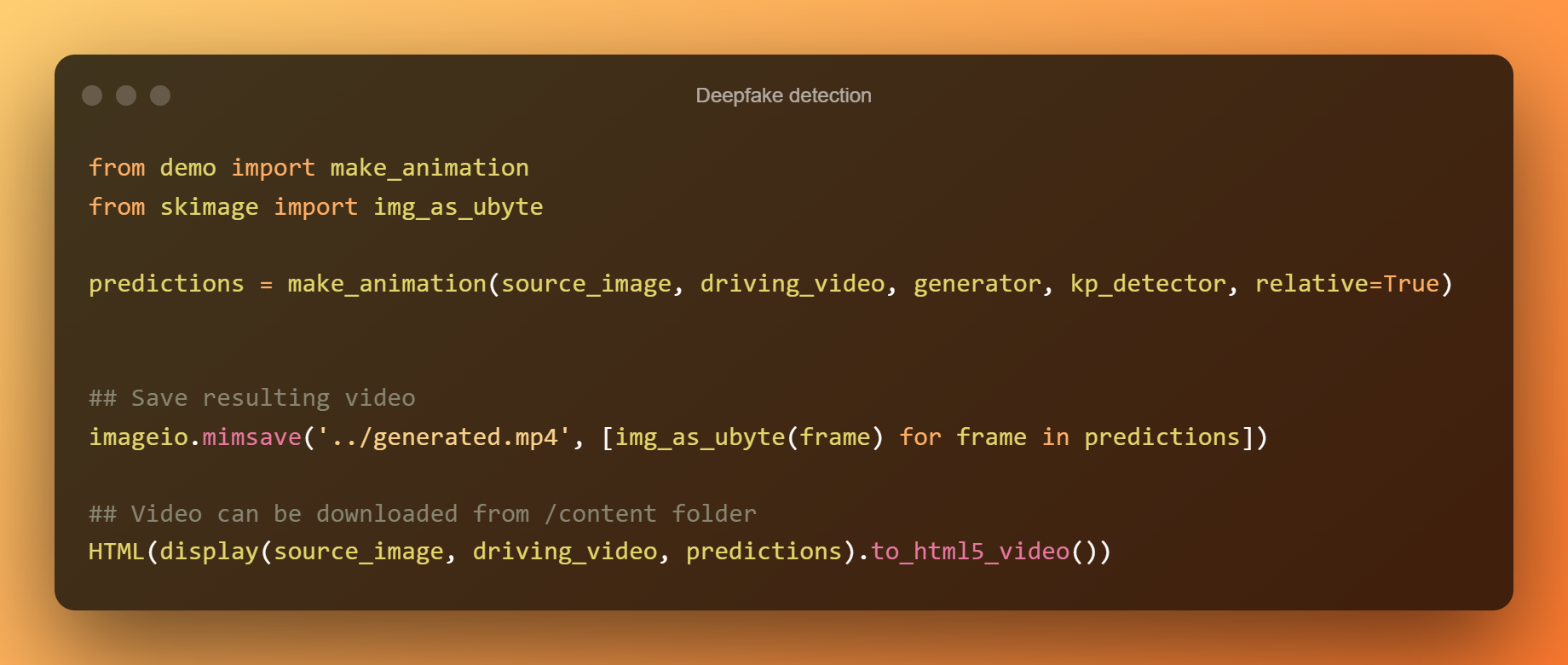
Mellorar a saída utilizando coordenadas absolutas

Deste xeito, poderás desenvolver unha detección de deepfake.
Cales son os riscos da tecnoloxía Deepfake?
Os vídeos deepfake agora son atractivos e divertidos de ver debido á súa novidade. Non obstante, existe o risco de que se descontrole baixo a superficie desta tecnoloxía aparentemente divertida.
Sen dúbida será un reto distinguir entre vídeos falsos e reais tecnoloxía deepfake segue avanzando. Para personalidades e celebridades destacadas, en particular, isto pode ter efectos graves. Os deepfakes que son intencionadamente malévolos teñen o potencial de danar completamente as carreiras e as vidas.
Estes poden ser usados por alguén con intención maligna para pasar por outros e aproveitar os seus amigos, familiares e compañeiros de traballo. Tamén son capaces de provocar controversias en todo o mundo e mesmo guerras usando películas falsas de líderes estranxeiros.
Conclusión
En resumo, estamos nun período estraño e ambiente inusual. Máis que nunca, é sinxelo producir noticias e películas falsas e difundilos. Comprender o que é verdade e o que non é cada vez máis difícil.
Hoxe, ao parecer, xa non podemos confiar nos nosos propios sentidos.
A pesar do feito de que se desenvolveron detectores de vídeo falso, é só cuestión de tempo que a brecha de información sexa tan estreita que nin os mellores detectores falsos non poderán determinar se o vídeo é real ou non.





Deixe unha resposta