Índice analítico[Ocultar][Mostrar]
A forma en que nos comunicamos coas máquinas e outros aparellos transformouse por completo co desenvolvemento do software de recoñecemento de voz AI.
Converte as palabras faladas en texto impreso cunha precisión e eficiencia sorprendentes mediante algoritmos de intelixencia artificial. Esta tecnoloxía ten aplicacións en moitos sectores, desde a asistencia sanitaria e o servizo ao cliente ata a educación e o entretemento.
Nos últimos anos, houbo un enorme aumento da demanda de conversión de voz a texto precisa e efectiva.
Tanto as empresas como as persoas están vendo a enorme utilidade do software de recoñecemento de voz da intelixencia artificial dado o rápido crecemento da tecnoloxía e a crecente dependencia da comunicación dixital.
Esta necesidade deriva do desexo de mellorar a produtividade, axilizar os trámites e aumentar a accesibilidade das persoas con discapacidade.
Para manter os rexistros dos pacientes e permitir unha prestación sanitaria eficaz, a transcrición precisa e rápida dos ditados médicos é esencial en sectores como a saúde.
Ao automatizar o proceso de transcrición, eliminando a necesidade da entrada manual de datos e proporcionando unha precisión e velocidade melloradas, xurdiu o software de recoñecemento de voz AI.
Ademais, as divisións de atención ao cliente están utilizando esta tecnoloxía para acelerar os tempos de resposta e ofrecer experiencias individualizadas.
As empresas poden detectar patróns, mellorar os seus servizos e tomar opcións baseadas en datos transcribindo as chamadas dos clientes e recollendo información perspicaz destas interaccións.
Outra industria que se beneficia do software de recoñecemento de voz con IA é a educación, xa que permite crear ferramentas de ensino de vangarda.
Pódese promover un ambiente de aprendizaxe máis dinámico e inmersivo permitindo aos estudantes ditar as súas tarefas ou interactuar con instrutores virtuais a través da voz.
O sector do entretemento tamén adoptou a tecnoloxía de recoñecemento de voz da intelixencia artificial, abrindo o camiño para produtos intelixentes activados por voz e asistentes virtuais que melloran a experiencia do usuario.
Con comandos de voz para reprodución multimedia e motores de busca activados por voz, esta tecnoloxía fai que sexa fácil e cómodo gozar do entretemento.
Nesta peza, veremos o principal software de recoñecemento de voz AI.
1. rotación
Rev é un programa de recoñecemento de voz baseado na nube que se fixo máis popular entre as empresas e as persoas que buscan servizos de transcrición precisos e eficaces para datos de audio e vídeo. O uso de Rev de algoritmos de IA de vangarda para a conversión de voz a texto faino único.
Para converter correctamente as palabras faladas en texto escrito, estes algoritmos complexos fan uso dos puntos fortes de aprendizaxe de máquina e procesamento da linguaxe natural.
Os algoritmos de intelixencia artificial de Rev poden recoñecer e interpretar unha gran variedade de acentos, dialectos e linguas, xa que foron adestrados en enormes volumes de datos.
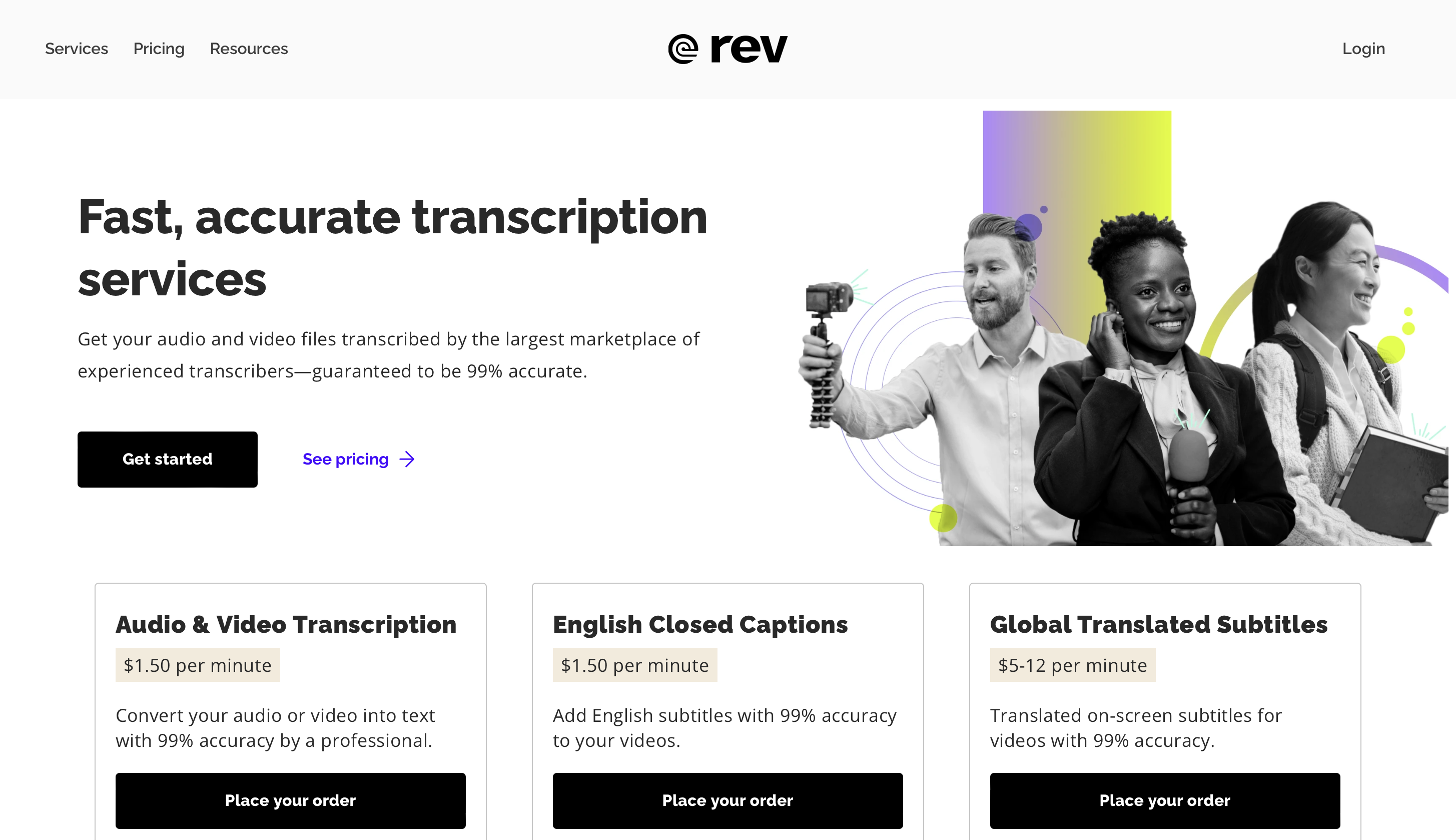
Como resultado, Rev pode ofrecer servizos de transcrición moi precisos que tamén se poden personalizar para satisfacer necesidades lingüísticas específicas. O programa pode xestionar unha variedade de tipos de ficheiros de audio, incluíndo podcasts, conferencias, entrevistas e vídeos.
Rev prioriza a eficiencia antes que a precisión, proporcionando tempos de resposta rápidos sen sacrificar a calidade. O programa pode procesar grandes cantidades de datos de audio e vídeo rápido debido ao seu fluxo de traballo optimizado e á súa infraestrutura escalable.
A gama de servizos de transcrición de Rev vai máis aló da simple tradución de voz a texto.
Ademais, o programa ofrece opcións para o formato, a identificación do orador e a marca de tempo.
A marca de tempo dá ao texto transcrito unha referencia cronolóxica e a identificación do falante fai máis doado distinguir entre distintos participantes da conversa.
As opcións de formato ofrecen aos clientes a posibilidade de axustar a presentación e o deseño da transcrición para adaptarse aos seus propios requisitos.
prezos
Pode proba Rev Max gratis durante 2 semanas, e os prezos premium comezan a partir de 29.99 dólares ao mes.
2. Nuance Dragon Professional
Nuance Dragon Professional é un software de recoñecemento de voz líder no mercado que ofrece un conxunto completo de funcións e capacidades para permitir aos profesionais dunha gran variedade de sectores.
Coas súas sofisticadas funcións de comandos de voz, podes manexar o teu ordenador sen mans mentres navegas polas aplicacións e ditas papeis, aumentando a eficiencia e a produtividade. O programa ten un nivel excepcional de precisión de transcrición, polo que as palabras faladas convértense de forma fiable en forma escrita.
Ao ofrecer vocabularios especializados e modelos lingüísticos, Nuance Dragon Professional satisface as demandas de industrias particulares. Co uso de dicionarios especializados e opcións de vocabulario, os profesionais de industrias como a saúde, o dereito e as finanzas poden aumentar a produtividade e producir transcricións máis precisas.
Ademais, o programa pode recoñecer diferentes patróns de fala e dialectos grazas aos perfís de voz personalizables polo usuario.
Os profesionais sanitarios poden rexistrar as notas dos pacientes, os datos médicos e as receitas cunha precisión notable usando Nuance Dragon Professional no sector da saúde, o que alivia a tensión administrativa e mellora a atención ao paciente.
As súas funcións de recoñecemento de voz poden ser utilizadas polos profesionais xurídicos para preparar documentos xudiciais de forma rápida e eficaz e crear notas de casos.
O programa tamén simplifica os procedementos de documentación nas industrias bancarias e de seguros, permitindo aos expertos redactar comunicacións, reclamacións e informes de forma rápida e precisa.
Ademais do simple ditado, as capacidades avanzadas de comandos de voz do software permítenche utilizar as indicacións de voz para operar instrucións sofisticadas, xestionar programas e realizar tarefas informáticas. As persoas con problemas de mobilidade ou as que prefiren o funcionamento de mans libres considerarán que esta función é especialmente útil.
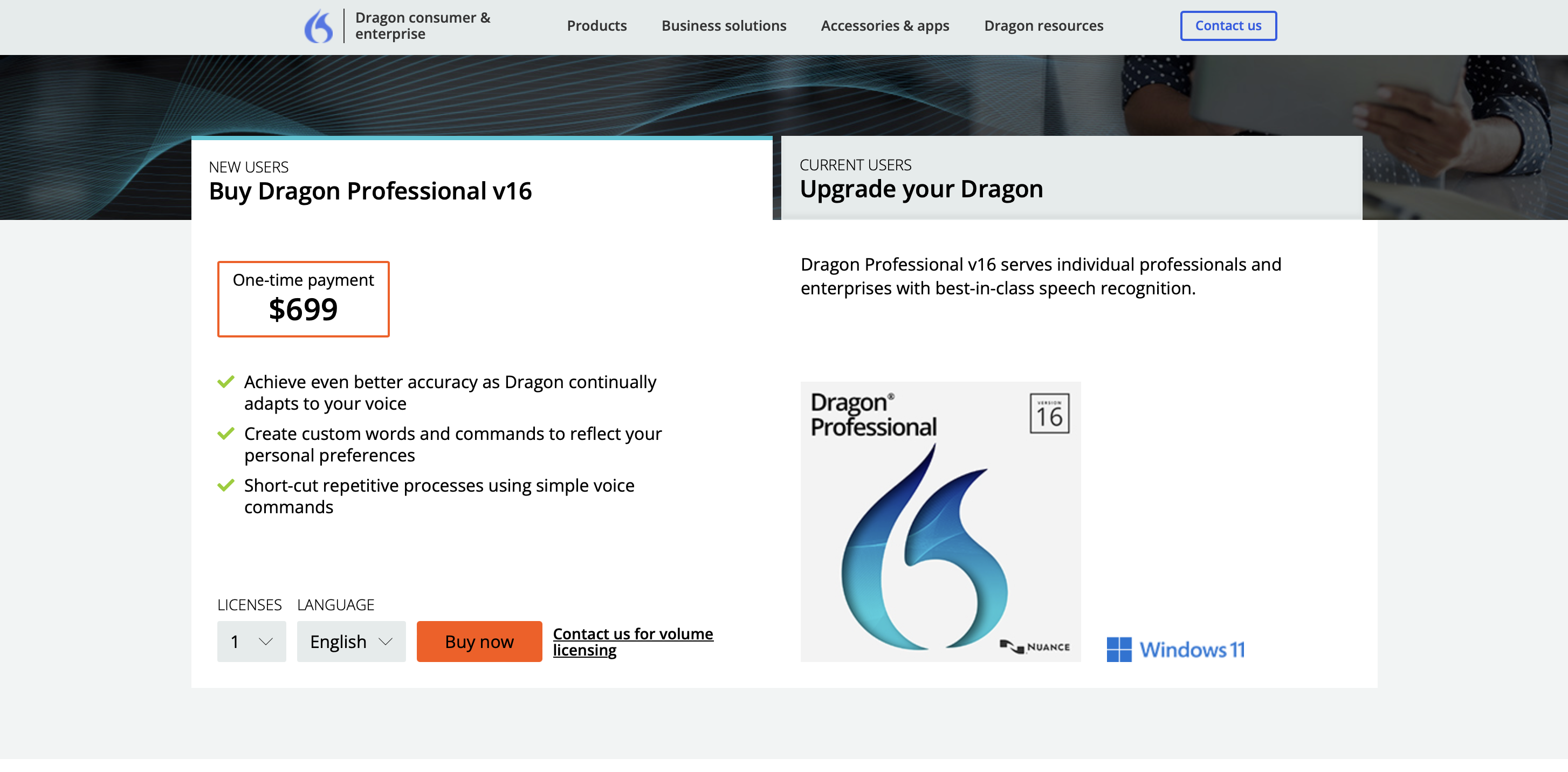
prezos
O prezo premium do software para mercar é de 699 dólares.
3. Google Cloud Speech-to-Text
Google Cloud Speech-to-Text é un coñecido programa de recoñecemento de voz con intelixencia artificial con excelentes poderes e competencia tecnolóxica.
É unha opción ideal para empresas e desenvolvedores que buscan unha conversión precisa de voz a texto porque é un compoñente da plataforma Google Cloud e ofrece unha gama completa de funcionalidades.
Unha calidade única do programa é a súa gran precisión, que utiliza sofisticados algoritmos de aprendizaxe automática para converter as palabras faladas en texto escrito cunha precisión sorprendente.
Ademais, Google Cloud Speech-to-Text ofrece unha ampla gama de compatibilidade lingüística, o que lle permite traducir audio nunha variedade de linguas, dialectos e acentos. É unha ferramenta útil para as corporacións multinacionais e as aplicacións que utilizan varios idiomas debido á súa ampla cobertura lingüística.
O programa é apropiado para aplicacións con alta demanda de transcrición, xa que pode xestionar enormes cantidades de datos de audio rapidamente utilizando o poder da nube.
Debido á arquitectura baseada na nube de Google Cloud Speech-to-Text, os desenvolvedores poden integrala sen esforzo con outros servizos e API de Google Cloud para crear aplicacións de voz completas.
O programa tamén ofrece outras capacidades que melloran a precisión e a utilidade da transcrición, como o rexistro do orador, a puntuación automatizada e a comprensión contextual.
Aínda que o rexistro dun falante permite recoñecer e distinguir entre varios falantes nunha discusión, a puntuación automática proporciona claridade e estrutura á saída.
A comprensión contextual axuda na interpretación e transcrición do audio dependendo de determinados dominios ou da xerga empresarial.
prezos
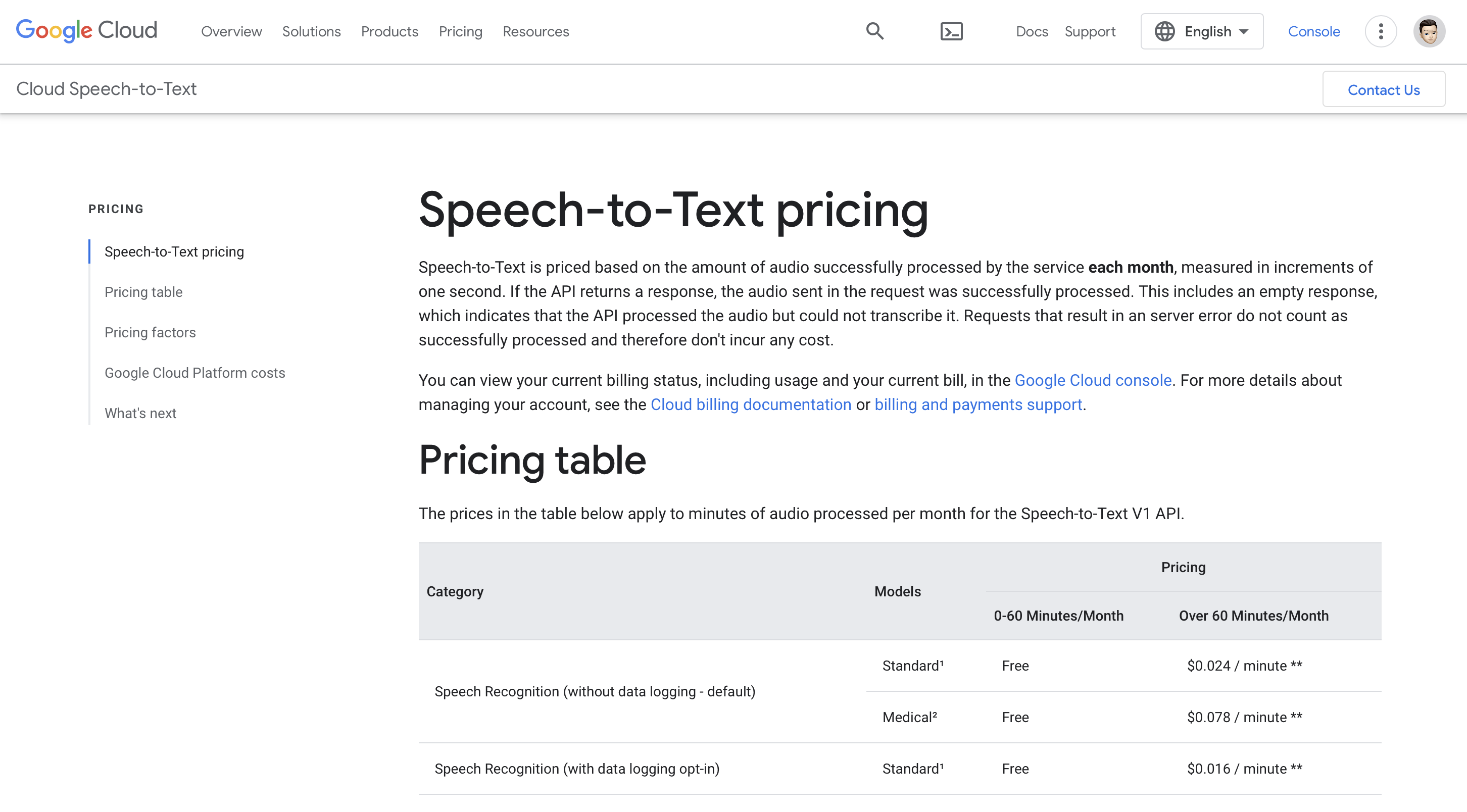
O seu uso é gratuíto durante 0-60 minutos ao mes e o prezo premium comeza a partir de 60 minutos ao mes, que é de 0.024 $/minuto.
4. Servizos de voz de Microsoft Azure
Microsoft Azure Speech Services é unha tecnoloxía de recoñecemento de voz que cambiou o xogo que transformou as nosas interaccións con máquinas e gadgets. As súas sofisticadas habilidades de transcrición permiten converter as palabras faladas en texto escrito con precisión e eficacia.
En consecuencia, pódense simplificar as operacións e mellorar a accesibilidade ao tempo que permite ás organizacións e ás persoas obter información detallada dos datos de audio. Vai máis alá do simple recoñecemento de voz ao incluír funcións de comprensión da linguaxe natural (NLU).
Pode comprender as intencións dos usuarios e dar respostas máis adecuadas ao contexto examinando o contexto e o significado das palabras faladas. Ao facilitarche a comunicación con aplicacións e asistentes virtuais, esta capacidade de comprensión da linguaxe natural mellora a experiencia do usuario.
Ademais, os desenvolvedores poden desenvolver aplicacións de voz completas coas posibilidades de integración fluida de Microsoft Azure Speech Services con outros servizos e API de Azure.
Ofrece kits de desenvolvemento de software (SDK) e API que permiten unha integración sinxela con aplicacións e sistemas xa existentes, e admite unha serie de linguaxes de programación.
Microsoft Azure Speech Services ofrece capacidades que inclúen síntese de voz, recoñecemento de falantes, tradución de idiomas e comprensión da linguaxe natural, ademais da transcrición e NLU.
Ofrécese un maior nivel de seguridade e personalización a través do recoñecemento de altofalantes, que permite identificar e validar determinados falantes.
A comunicación multilingüe vese facilitada polas tecnoloxías de tradución lingüística que permiten a tradución da fala en tempo real a moitos idiomas.
Ademais, a síntese de voz mellora a calidade das aplicacións e servizos baseados na voz ao producir unha voz que soa como a fala humana.
prezos
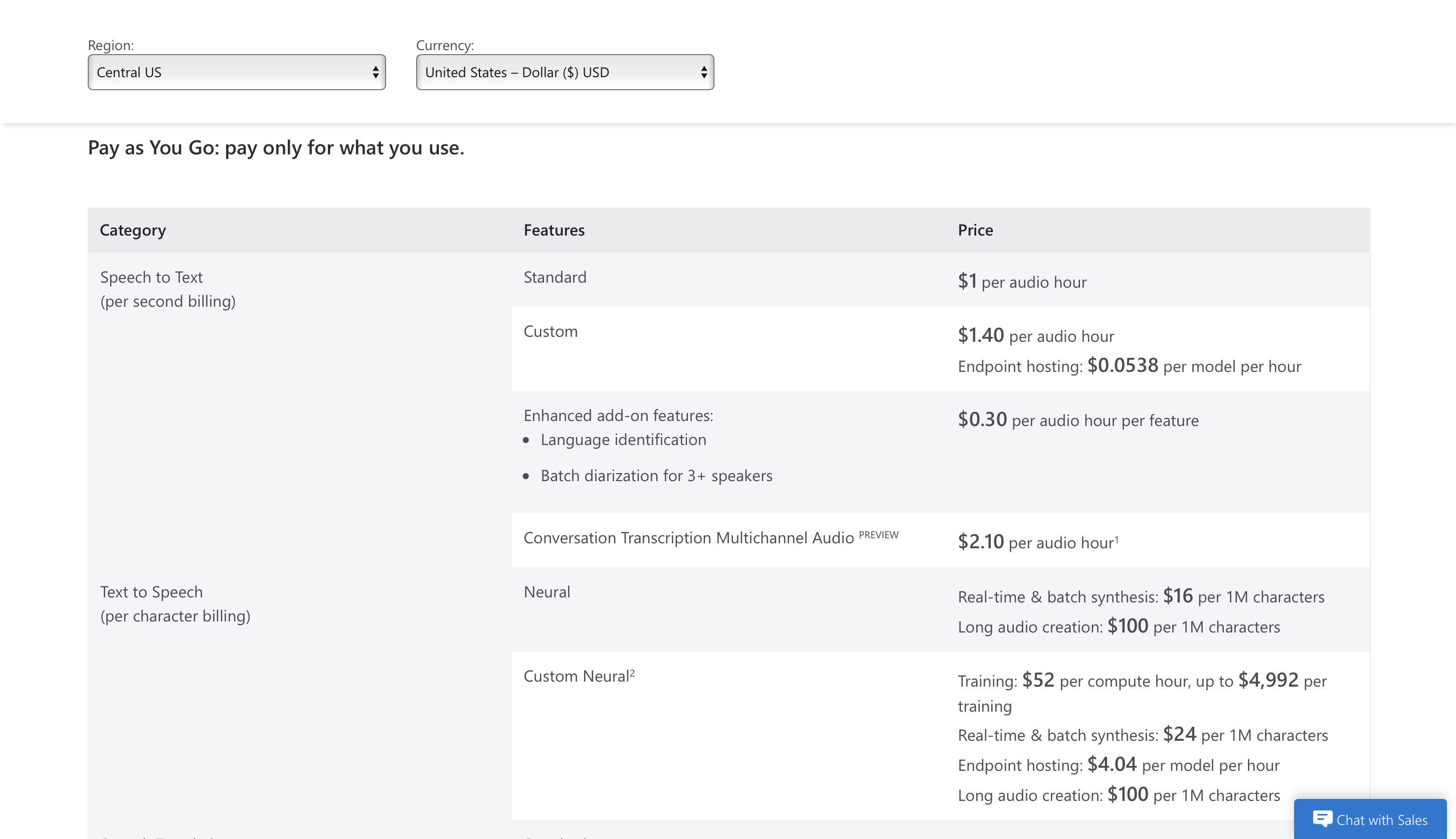
Podes comezar a usalo de balde durante 5 horas de audio gratuítas ao mes e os prezos premium comezan a partir de 1 USD por hora de audio.
5. Transcribe Amazon
Amazon Transcribe é unha aplicación moi útil que ofrece varias vantaxes á hora de converter eficazmente a voz en texto e o recoñecemento de voz.
Coa excepcional escalabilidade desta solución baseada na nube de Amazon Web Services (AWS), as empresas poden xestionar de forma eficaz grandes cantidades de datos de audio.
Amazon Transcribe é capaz de adaptarse aos requisitos de transcrición cambiantes con facilidade, xa sexan para reunións, entrevistas ou chamadas de atención ao cliente. As empresas poden recibir información valiosa da información de audio mediante transcricións precisas que se entregan habitualmente mediante a tecnoloxía de recoñecemento automático de voz.
A utilización de sofisticados algoritmos de aprendizaxe automática, que aprenden continuamente e melloran co paso do tempo, mellora significativamente a precisión de Amazon Transcribe.
Intégrase con outros servizos web de Amazon sen ningún problema. Coa axuda desta conexión, as organizacións poden engadir rapidamente capacidades de recoñecemento de voz á súa actual infraestrutura de AWS, reducindo os procesos e aumentando a eficacia xeral.
Ademais, Amazon Transcribe ofrece metadatos adicionais, como selos de tempo, que che permiten navegar e buscar máis facilmente a través do texto transcrito.
Pode analizar e transcribir de forma eficaz calquera tamaño do ficheiro de audio. As empresas poden usar Amazon Transcribe para xestionar a carga, asegurando transcricións rápidas e precisas tanto se teñen uns minutos como varias horas de audio para transcribir.
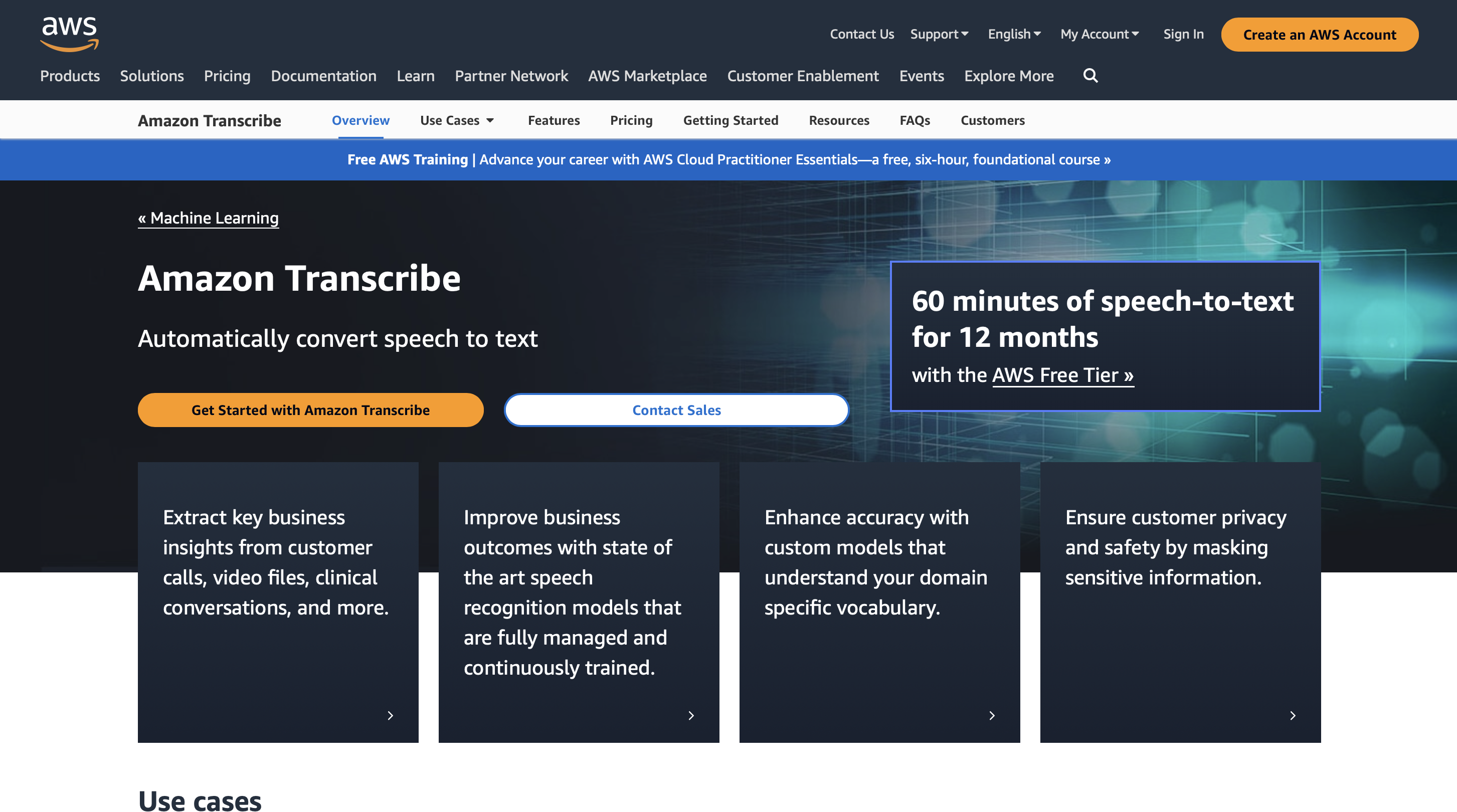
prezos
Podes usar Amazon Transcribe durante 60 minutos ao mes durante 12 meses e o prezo premium comeza a partir de 0.02400 USD/minuto
6. IBM Watson Speech to Text
IBM Watson Speech to Text é unha ferramenta robusta para o recoñecemento de voz e a transcrición que inclúe unha variedade de capacidades avanzadas e opcións de personalización. A lingua falada tradúcese con precisión a texto escrito mediante este servizo baseado na nube, que fai uso de tecnoloxía de punta como aprendizaxe profunda e procesamento da linguaxe natural.
Como resultado do seu amplo soporte lingüístico, os usuarios poden transcribir audio nunha variedade de linguas e dialectos. Para as empresas que fan negocios a nivel internacional ou necesitan servizos de transcrición multilingüe, esta adaptabilidade convérteo nunha ferramenta inestimable.
Ademais, IBM Watson Speech to Text ofrece modelos e vocabularios especializados para un sector determinado para adaptalos ás súas demandas.
IBM Watson Speech to Text pódese axustar ás necesidades específicas de moitas empresas, xa sexan dos sectores xurídico, financeiro ou sanitario.
A capacidade de IBM Watson Speech to Text para xestionar o audio en modo por lotes ou en tempo real ofrécelle flexibilidade en función das súas propias necesidades. Aínda que a transcrición por lotes funciona ben para ficheiros de audio gravados previamente, a transcrición en tempo real é mellor para aplicacións como a análise de voz e os subtítulos en directo.
Ademais, IBM Watson Speech to Text ten poderosas funcións de diarización de altofalantes que permiten o recoñecemento e a separación de varios altofalantes dentro dunha fonte de audio.
Cando hai numerosos oradores presentes, como durante as gravacións de conferencias ou entrevistas, esta función é moi útil. Debido á súa conexión perfecta con outros servizos e API de IBM Watson, os desenvolvedores poden crear de xeito rápido e sinxelo aplicacións sólidas dirixidas por voz.
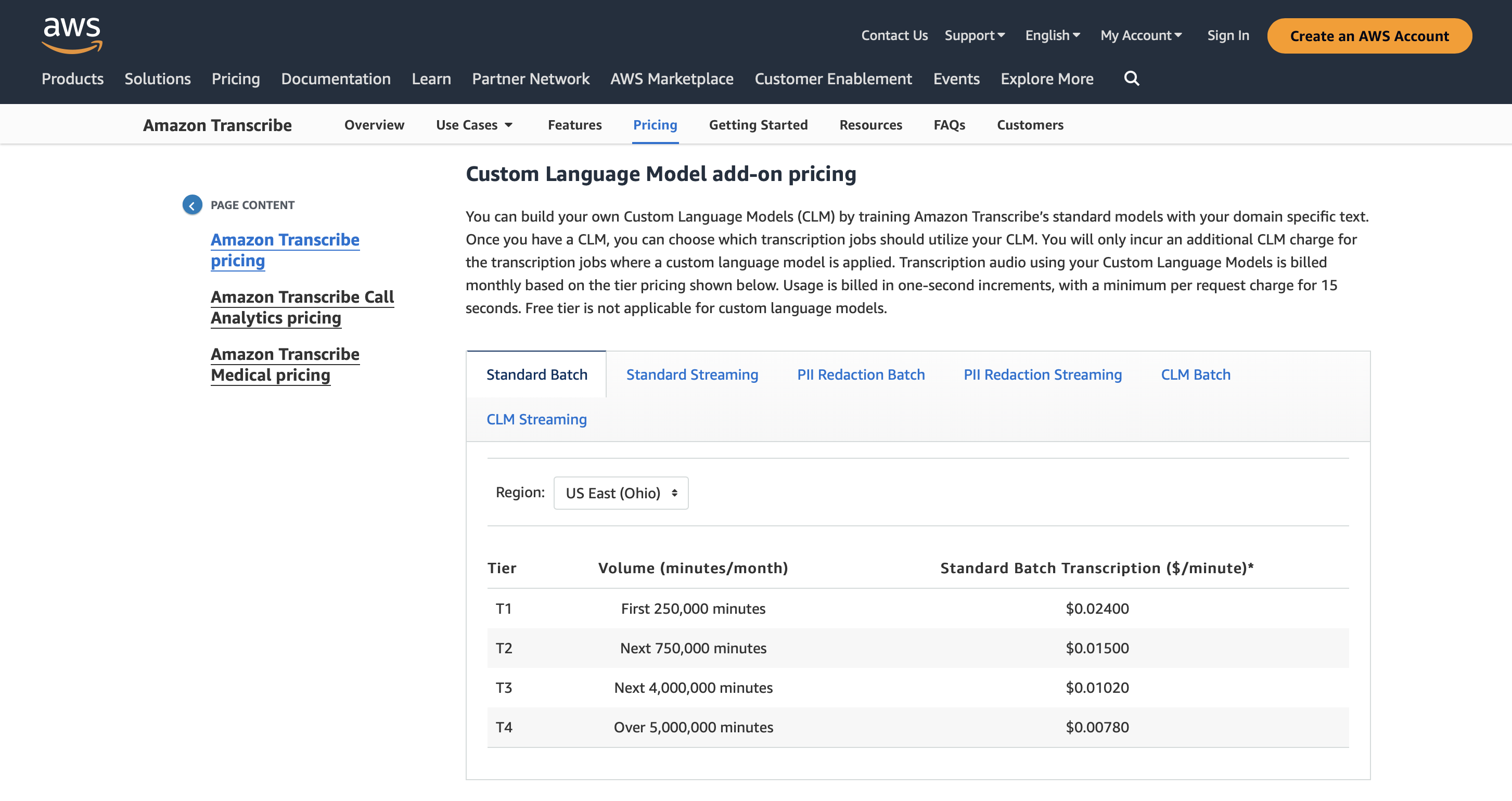
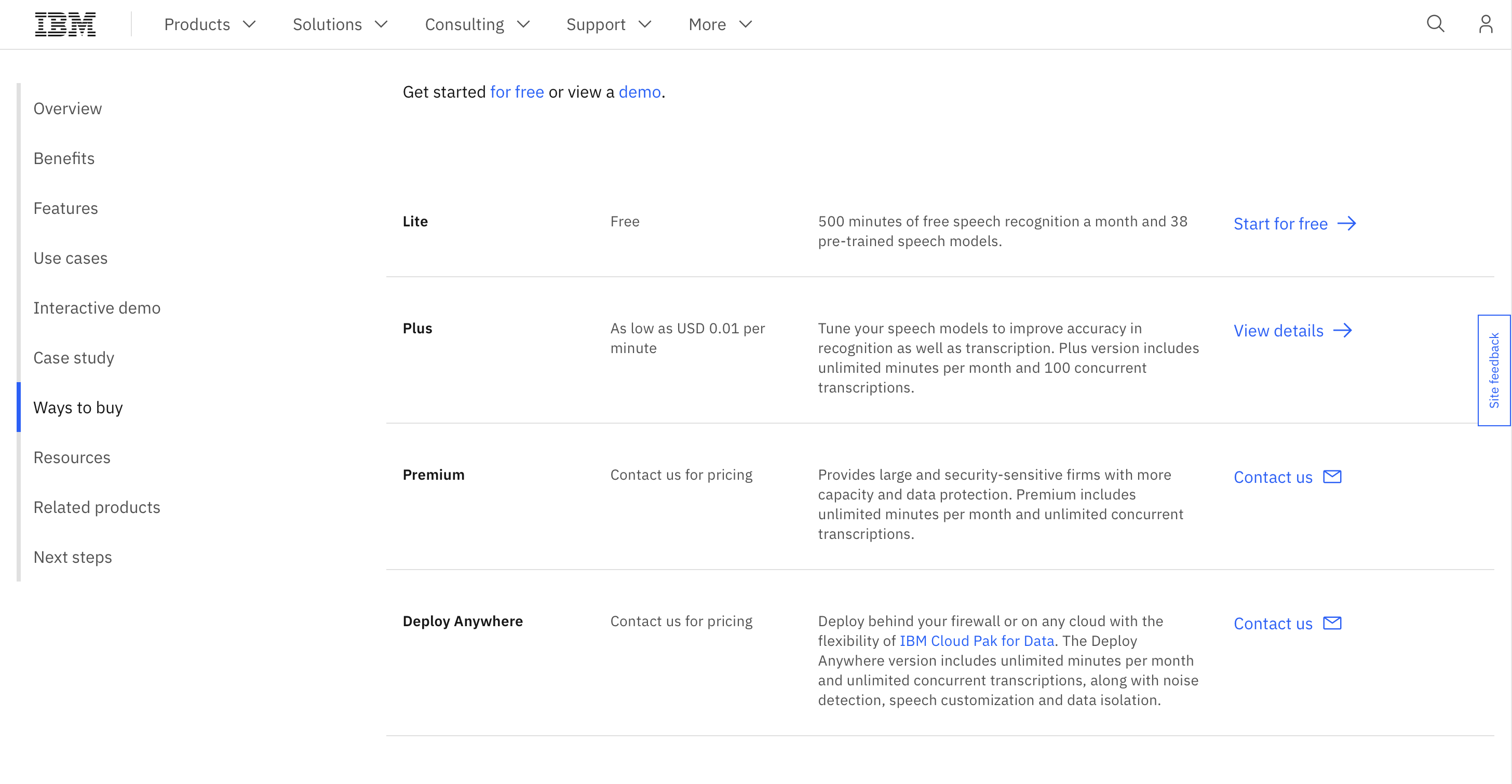
prezos
Podes usar o servizo durante 500 minutos de recoñecemento de voz gratuíto ao mes e os prezos premium comezan a partir de 0.01 USD/minuto.
7. OpenAI Whisper
OpenAI Whisper é unha API de recoñecemento de voz de vangarda que utiliza tecnoloxías de punta para acadar un rendemento excepcional. Whisper é unha solución de confianza para organizacións e desenvolvedores xa que converte con precisión a linguaxe falada en texto escrito grazas aos seus sólidos modelos de aprendizaxe automática.
Esta API destaca polas súas capacidades multilingües, que lle permiten traducir contido de audio a outros idiomas, dialectos e acentos, atendendo a unha base de usuarios diversa.
O sistema OpenAI Whisper pode recoñecer e comprender unha variedade de patróns e variacións de fala xa que está construído sobre un gran conxunto de datos de adestramento.
O murmurio redes neuronais profundas foron adestrados sobre enormes volumes de datos de audio grazas aos cales agora é capaz de recoñecer e transcribir frases faladas cunha precisión asombrosa.
Ofrece servizos de transcrición precisos e eficaces e atopa uso en sectores como a saúde, a atención ao cliente e os medios. Whisper pode axudar co ditado médico no sector da saúde, axudando aos expertos a manter os datos correctos dos pacientes.
Permite a transcrición das interaccións dos consumidores na atención ao cliente, mellorando a análise e o control de calidade. Para mellorar a accesibilidade e o descubrimento de contido, as organizacións de medios tamén poden empregar Whisper para transcribir entrevistas, podcasts e material de vídeo.
A gran precisión de OpenAI Whisper é o produto da súa aprendizaxe e desenvolvemento continuos. As capacidades de transcrición de Whisper mellóranse como resultado dos modelos que usa, que cambian a medida que se procesan máis datos e se reciben entradas.
Esta mellora constante garante que a API permanece á vangarda da tecnoloxía de recoñecemento de voz, proporcionando aos consumidores os mellores resultados.
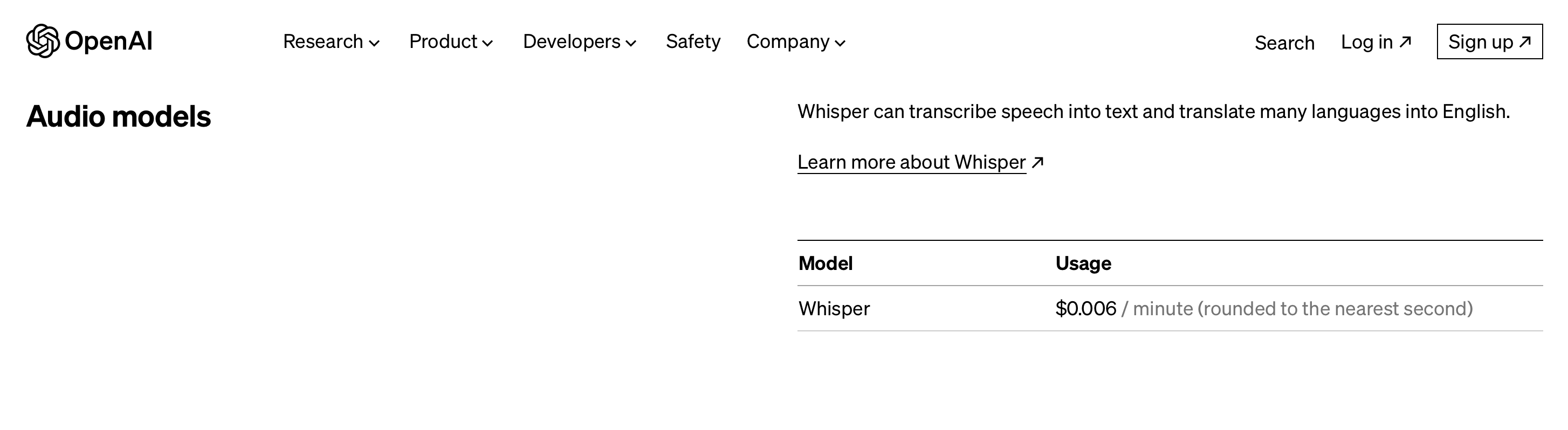
prezos
O prezo premium do modelo comeza a partir de 0.006 USD/minuto.
8. Speechmatics
Speechmatics é líder do mercado en tecnoloxía de recoñecemento de voz e ofrece unha API de voz a texto forte e precisa. Speechmatics destaca por converter con precisión a linguaxe falada en texto escrito mediante o uso de algoritmos de vangarda e métodos de aprendizaxe profunda.
É unha ferramenta útil para unha variedade de aplicacións, incluíndo subtítulos multimedia, centro de contacto analítica e indexación de contidos debido ás súas capacidades de transcrición precisas.
Speechmatics pode transcribir de forma fiable información de audio de diversas orixes lingüísticas grazas ao seu amplo soporte lingüístico, que inclúe dialectos e acentos rexionais.
Non importa a lingua que se pronuncie, poderás copiar e comprender con precisión o texto falado debido a esta capacidade multilingüe. Speechmatics ofrece resultados fiables e precisos, xa sexa para inglés, español, mandarín ou outros idiomas.
A tecnoloxía subxacente de Speechmatics mellórase e apréndese continuamente, o que lle permite axustarse a varios patróns de fala, acentos e factores ambientais.
A dedicación de Speechmatics á innovación continua garante que seguirá liderando o campo da tecnoloxía de recoñecemento de voz e ofrecerá aos seus clientes a conversión de voz a texto máis precisa.
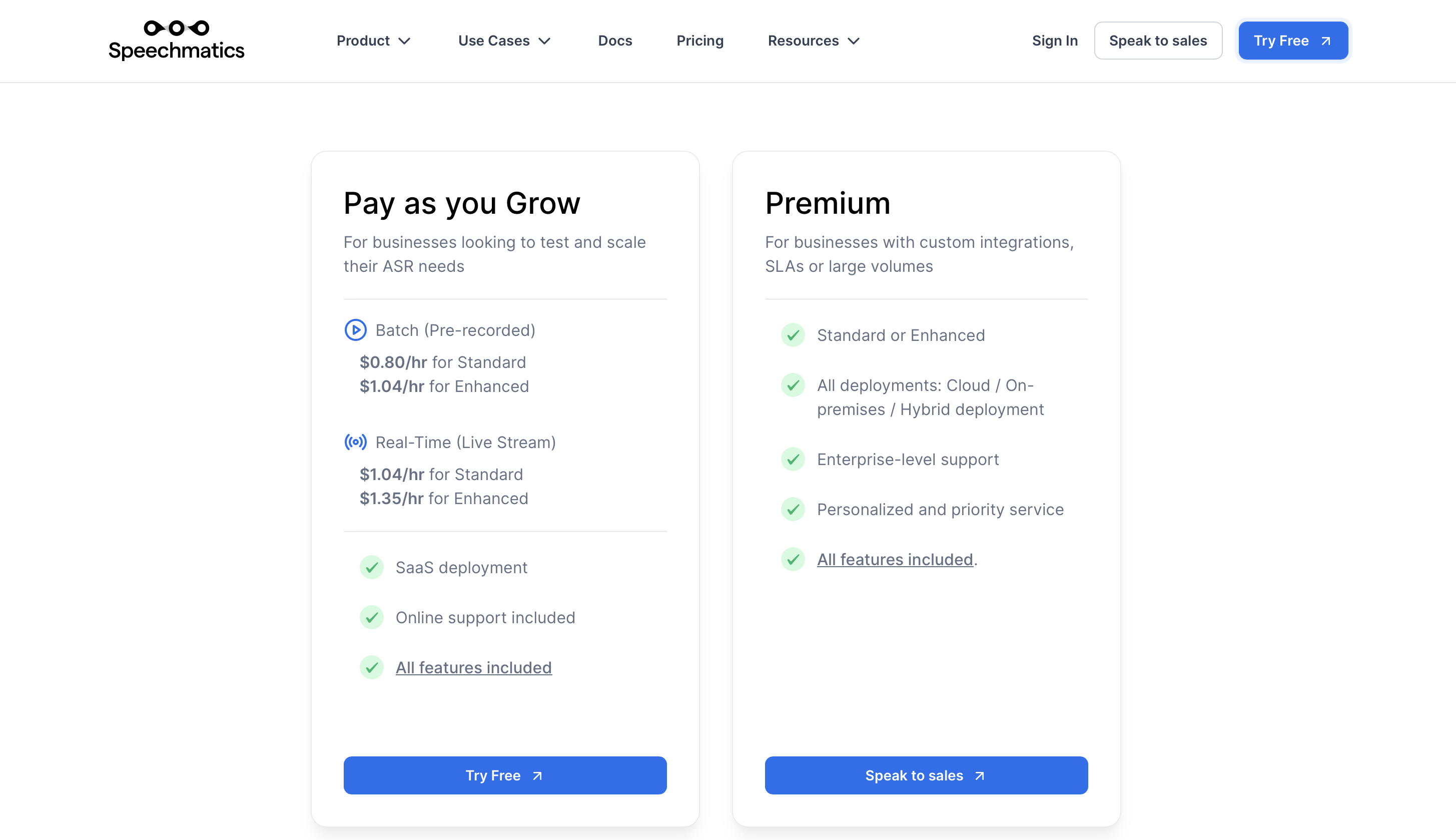
prezos
O prezo premium comeza a partir de 0.80 $/hora en lote (pregravado) e 1.04 $/hora para o tempo real (transmisión en directo).
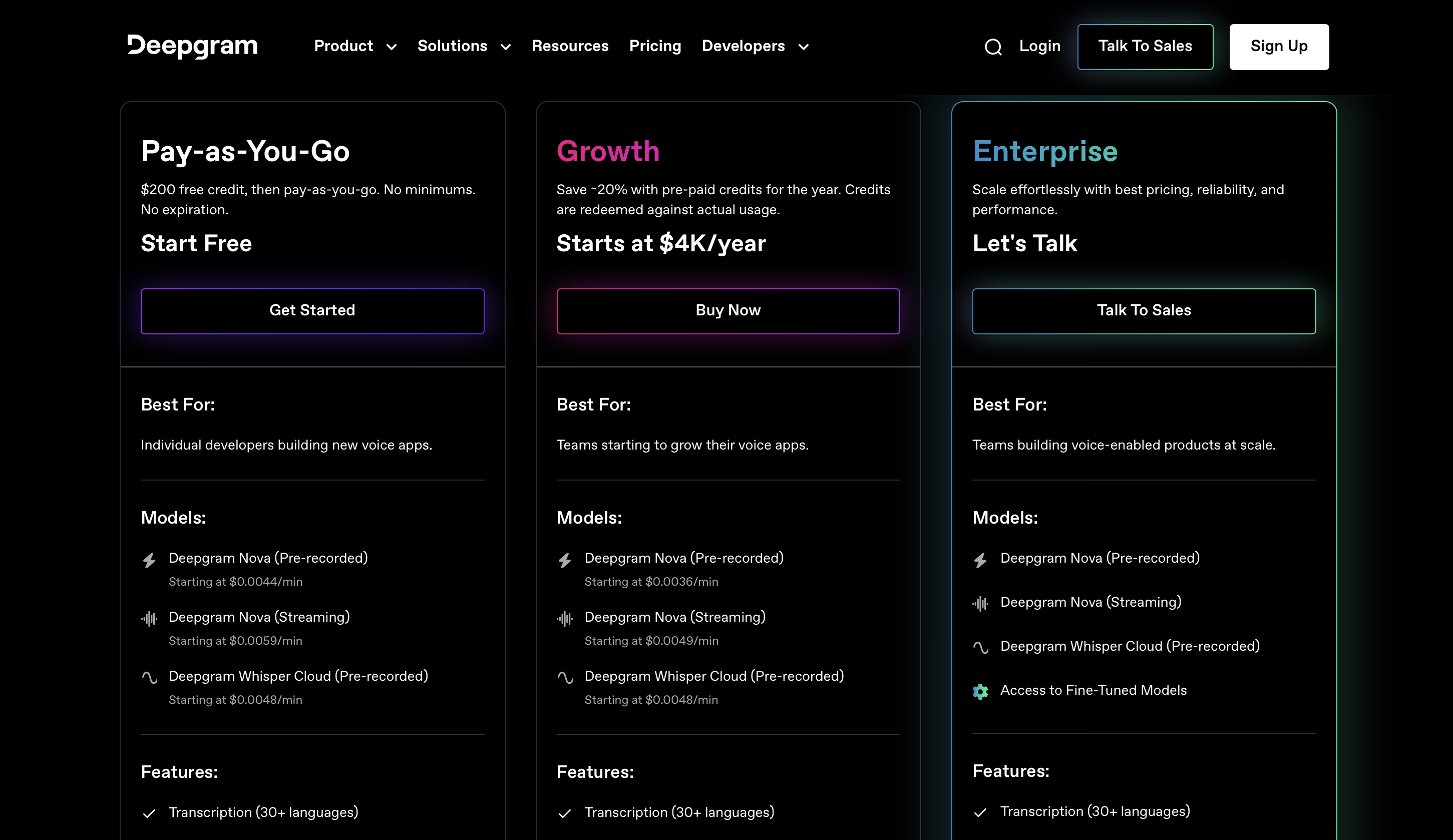
9. Deepgram
Deepgram, pioneiro na tecnoloxía de recoñecemento de voz e transcrición, proporciona unha base sólida para unha conversión de audio a texto extremadamente precisa usando modelos de aprendizaxe profunda.
Os modelos de aprendizaxe profunda construídos dentro da plataforma poden comprender e tipear unha gran variedade de patróns de fala e variacións xa que foron adestrados en enormes cantidades de datos.
A gran precisión e capacidade de Deepgram para captar sutilezas no contido falado son resultado do seu adestramento intensivo. Debido á versatilidade da plataforma, as transcricións son máis precisas xa que poden xestionar unha variedade de acentos, idiomas e termos específicos do sector.
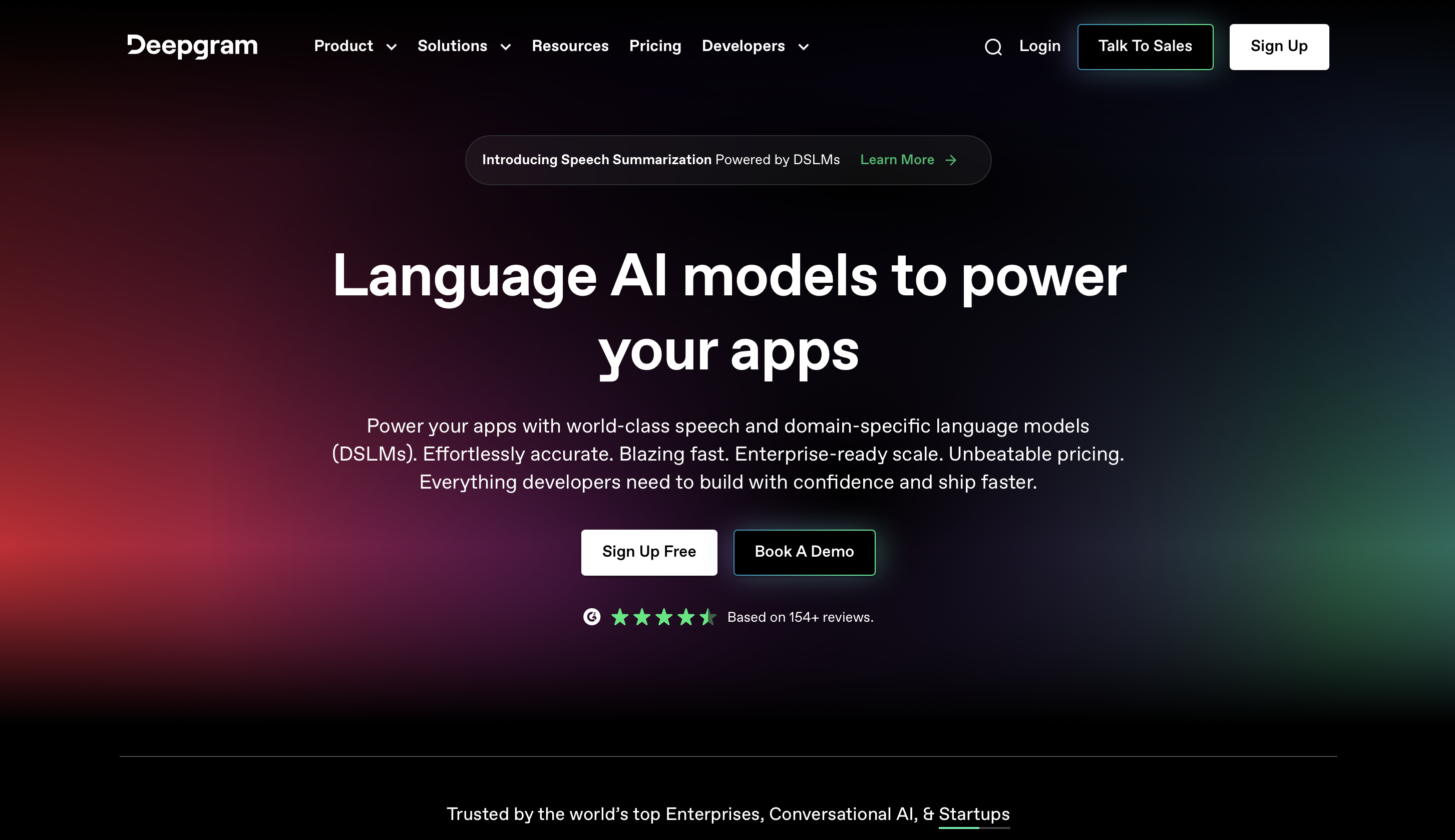
Pode producir achados precisos incluso en circunstancias menos que ideais grazas aos seus modelos de aprendizaxe profunda, que tamén lle permiten xestionar situacións auditivas difíciles e ruído de fondo.
Ademais, unha serie de capacidades tecnolóxicas están dispoñibles na plataforma de recoñecemento de voz e transcrición de Deepgram para mellorar a experiencia do usuario..
Podes recibir transcricións inmediatas de conversas ou eventos en directo debido ás súas capacidades de procesamento en tempo real. Deepgram tamén permite o procesamento por lotes, o que permite transcribir de forma eficiente grandes conxuntos de datos de audio.
prezos
Podes comezar a usalo de balde e os prezos premium comezan a partir de 4 dólares ao ano.
10. Siri
Siri creceu en popularidade como unha das aplicacións de software de recoñecemento de voz máis recoñecibles e de uso habitual accesibles na actualidade. Un asistente virtual favorito de millóns de propietarios de dispositivos Apple en todo o mundo, Siri é coñecido polo seu deseño sinxelo e as interaccións activadas por voz.
Siri é un asistente activado por voz que pode realizar unha variedade de operacións cun só comando falado, incluíndo crear recordatorios, enviar mensaxes, facer chamadas telefónicas e mesmo responder preguntas sobre coñecementos xerais.
A perfecta integración de Siri con produtos de Apple, como iPhones, iPads, Macs e HomePods, é o que o distingue doutros asistentes dixitais.

Podes acceder a Siri usando diferentes dispositivos grazas a esta integración, que garante unha experiencia de usuario cómoda e consistente. Siri está dispoñible en todo momento, tanto se estás traballando no teu Mac ou nun iPhone cando estás de viaxe.
Non se pode negar a utilidade e adaptabilidade de Siri na vida diaria. Só coa súa voz, podes usar Siri para xestionar os seus horarios, enviar correos electrónicos, navegar a través de mapas e manexar aparellos domésticos intelixentes. Podes seguir estando conectado e produtivo mentres estás en movemento grazas a este método mans libres, que tamén aforra tempo.
Ademais, Siri sempre está a desenvolver e mellorar. Apple cambia a miúdo as capacidades de Siri, aumentando a súa capacidade de interpretación e procesamento da linguaxe natural, aumentando a súa base de coñecemento e engadindo novas funcións.
Ao manter o seu liderado na tecnoloxía de recoñecemento de voz a través do desenvolvemento continuo, Siri pode continuar proporcionándoche unha experiencia fluida e personalizada.
prezos
É de uso gratuíto para todos.
Conclusión
En conclusión, o software de recoñecemento de voz impulsado pola intelixencia artificial cambiou completamente a forma en que interactuamos coa tecnoloxía e converteuse nunha ferramenta crucial para moitos sectores diferentes.
A variedade de posibilidades, desde Microsoft Azure Speech Services e OpenAI Whisper ata Google Cloud Speech-to-Text e Nuance Dragon Professional, demostra o desenvolvemento e adaptabilidade destes sistemas.
Insto aos lectores a investigar e analizar a fondo os seus desexos e requisitos individuais antes de seleccionar o software de recoñecemento de voz AI que mellor satisfaga os seus obxectivos porque cada software ten unha variedade de funcións e capacidades especiais.
Podes acadar novos niveis de produtividade, eficiencia e experiencia de usuario nos teus esforzos persoais e profesionais adoptando esta potente tecnoloxía.





Estiven facendo comparacións de traballo, hai algunhas cousas que pode querer corrixir.
1. Siri non é comparable cos outros. Siri non é unha ferramenta de desenvolvemento.
2. Os prezos de Rev que compartiches son para a transcrición humana, mentres que outros están baseados exclusivamente na transcrición automática. Se miras a transcrición da máquina de Rev, o seu prezo tamén é competitivo. https://www.rev.ai/pricing
3. Falta Picovoice, que ofrece o único modelo no dispositivo que funciona como unha oferta de servizos. Normalmente, as solucións no dispositivo como Whisper non inclúen soporte técnico e a personalización é moi difícil. Ofrecen un gran soporte e a personalización é moi sinxela. https://picovoice.ai/platform/cat/