Le déplacement et le stockage des données ont gagné en importance en raison de l'expansion constante de l'industrie informatique et des millions de points de données produits chaque seconde.
De plus, ces données doivent être claires et simples à comprendre afin de soutenir une prise de décision précise.
Pour maintenir sa compétitivité et atteindre un succès à long terme, votre entreprise doit stocker et déplacer des données en utilisant les solutions les plus efficaces disponibles.
Pour cette raison, de plus en plus d'entreprises utilisent des data fabrics. L'un des meilleurs moyens d'économiser votre temps, votre argent et vos ressources consiste à utiliser une structure de données pour traiter les données et permettre l'apprentissage automatique de l'IA.
Dans cet article, nous examinerons en profondeur Data Fabric, y compris ses utilisations, ses principaux composants, ses avantages et d'autres détails essentiels.
Alors, qu'est-ce que Data Fabric ?
Quel que soit leur emplacement, gérez et surveillez vos données et applications. À la base, une structure de données est une architecture de données intégrée qui est sûre, polyvalente et adaptable.
Une structure de données, qui combine le meilleur du cloud, du cœur et de la périphérie, constitue à bien des égards une nouvelle approche stratégique pour les opérations de stockage de votre entreprise.
Tout en étant contrôlé de manière centralisée, il peut atteindre n'importe où, y compris les clouds sur site, publics et privés, ainsi que les périphériques de périphérie et IoT.
Les silos de données de la taille d'un gratte-ciel et les infrastructures diverses et non connectées appartiennent au passé. Une Data Fabric est basée sur une collection complète d'outils de gestion de données qui garantissent la cohérence dans tous vos environnements liés.
Grâce à l'automatisation, rationalise la gestion fastidieuse, accélère le développement, les tests et le déploiement, et protège vos actifs XNUMX heures sur XNUMX.
Peu importe où se trouvent vos données et applications, vous pouvez suivre les dépenses de stockage, les performances et l'efficacité à partir d'une plateforme unique.
Vous pouvez rapidement (et, dans certains cas, automatiquement) apporter des modifications à votre infrastructure de cloud hybride une fois que vous avez des connaissances exploitables à son sujet, telles que la correction des erreurs, la résolution des problèmes de sécurité et de conformité et l'augmentation et la réduction de l'informatique.
En bref, Data Fabric améliore l'efficacité du déploiement et de la maintenance de l'infrastructure, réduit les coûts et augmente les performances.
Pourquoi utiliser une Data Fabric ?
Toute entreprise centrée sur les données a besoin d'une stratégie globale qui surmonte les obstacles tels que le temps, l'espace, divers types de logiciels et l'emplacement des données. Les données ne doivent pas être cachées derrière des pare-feu ou dispersées à plusieurs endroits, mais doivent être accessibles aux personnes qui en ont besoin.
Pour réussir, les entreprises ont besoin d'une solution de données évolutive et d'un environnement sûr, efficace et unifié. Cela peut être fait avec une structure de données.
Les besoins des entreprises modernes en matière de connexion en temps réel, de libre-service, d'automatisation et de changements universels ne peuvent être satisfaits par l'intégration de données traditionnelle.
Bien que la collecte de données provenant de nombreuses sources ne soit souvent pas un problème, de nombreuses entreprises ont du mal à intégrer, traiter, conserver et transformer des données avec des données provenant d'autres sources.
Pour donner une compréhension approfondie des consommateurs, des partenaires et des biens, cette étape critique du processus de gestion des données doit avoir lieu. En raison de leur capacité à mettre à niveau leurs systèmes, à mieux servir les clients et à utiliser le cloud computing, les entreprises gagnent ainsi un avantage concurrentiel.
Où que se trouvent les utilisateurs de l'organisation, la data fabric peut être imaginée comme un tissu qui s'étale à l'échelle mondiale. Sur ce réseau, l'utilisateur peut se trouver à n'importe quel endroit et avoir toujours un accès illimité et en temps réel aux données de n'importe quel autre endroit.
Composants principaux de Data Fabric
Les composants de base qui composent une structure de données peuvent être choisis et rassemblés de différentes manières. La structure de données peut ainsi être mise en œuvre de différentes manières. Examinons les principaux éléments d'une structure de données.
- Catalogue de données augmenté
- Couche de persistance
- Graphique connaissances
- Moteur d'analyse et de recommandations
- Préparation des données et couche de livraison des données
- Orchestration et opérations de données
Vous pouvez consulter les piliers clés de l'architecture Data Fabric selon Gartner.
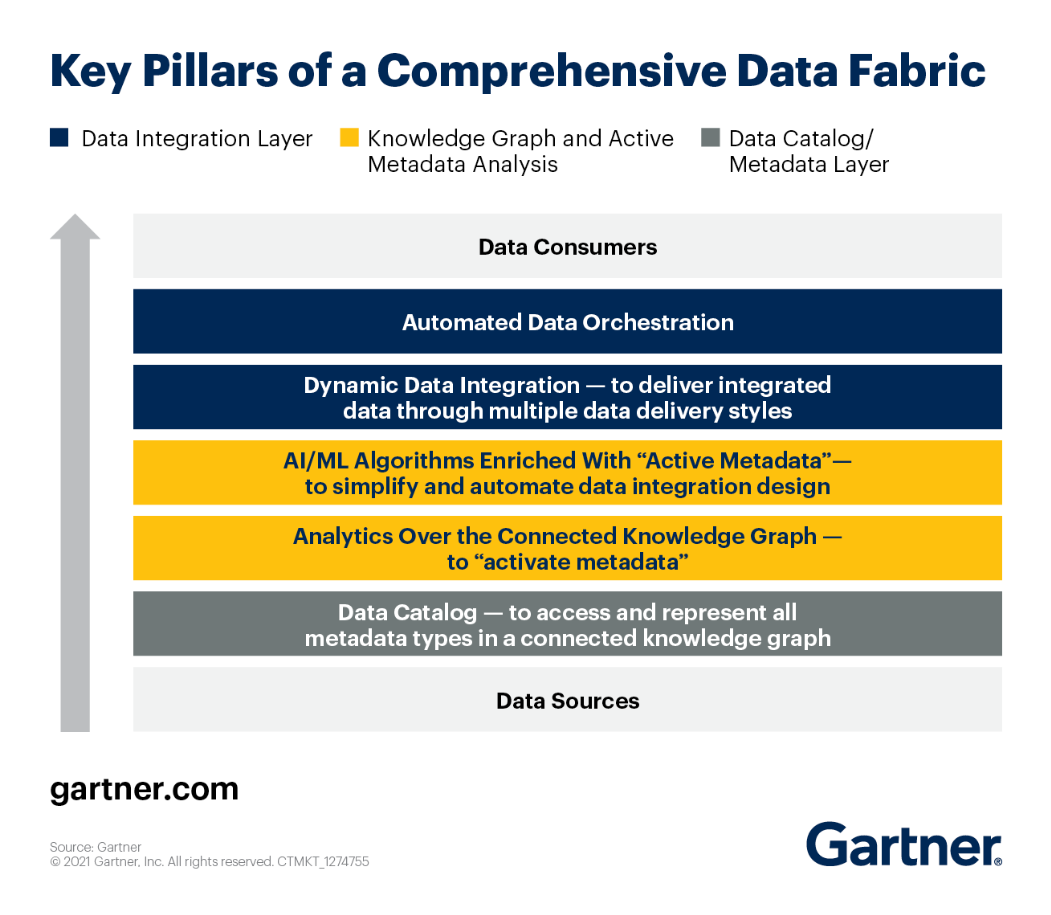
Regardons chacun d'eux de près.
- Catalogue de données augmenté – donne aux utilisateurs l'accès à toutes sortes de métadonnées via un graphe de connaissances puissant. De plus, il développe des associations distinctives entre les informations existantes et les montre visuellement de manière compréhensible. En utilisant machine learning Pour lier les ressources de données à la terminologie organisationnelle, les catalogues de données améliorés créent la couche sémantique métier pour la structure de données.
- Couche de persistance – Selon le cas d'utilisation, divers modèles relationnels et non relationnels peuvent être utilisés pour stocker dynamiquement les données.
- Métadonnées actives – un élément distinctif d'une structure de données. donne à la structure de données la capacité de collecter, partager et analyser de nombreux types de métadonnées. Contrairement aux métadonnées passives, les métadonnées actives suivent l'utilisation continue des données par les systèmes et les personnes (métadonnées basées sur la conception et d'exécution).
- Graphique connaissances – Une autre unité fondamentale pour les data fabrics. Ils utilisent des ID standard, des schémas adaptables, etc. pour afficher un environnement de données liées. Les graphes de connaissances rendent la structure de données consultable et facilitent sa compréhension.
- Moteur d'analyse et de recommandation – construit des pipelines de données fiables et solides pour les cas d'utilisation opérationnels et analytiques.
- Préparation des données et couche de livraison des données – Les données peuvent être extraites de n'importe quelle source et envoyées à n'importe quelle cible à l'aide de n'importe quel mécanisme, y compris ETL (en masse), messagerie, CDC, virtualisation et API.
- Orchestration et opérations de données – Ce composant utilise des données pour coordonner toutes les tâches à chaque étape du flux de travail de bout en bout. Il vous permet de choisir quand et à quelle fréquence exécuter les pipelines ainsi que la manière de gérer les données produites par ces pipelines.
Avantages
Les données saines dans un contexte distribué sont accessibles, chargées, intégrées et partagées sur une structure de données. Ce faisant, les entreprises peuvent accélérer la transition numérique et maximiser la valeur de leurs données.
Vous trouverez ci-dessous les principaux avantages du modèle Data Fabric.
Rendement :
Une structure de données peut compiler les résultats de requêtes antérieures, permettant au système d'analyser la table agrégée plutôt que les données brutes dans le backend.
En raison des temps de réponse plus rapides des demandes individuelles, laisser les demandes accéder à des ensembles de données plus petits plutôt que d'avoir à analyser les données brutes du magasin complet résout également le problème de plusieurs demandes simultanées.
Les entreprises peuvent répondre rapidement aux demandes urgentes grâce à la capacité de la structure de données à réduire considérablement les temps de réponse aux requêtes.
Intégration intelligente
Pour intégrer des données sur divers types de données et points de terminaison, les structures de données utilisent des graphes de connaissances sémantiques, la gestion des métadonnées et l'apprentissage automatique.
Cela aide les équipes de gestion des données à regrouper les ensembles de données pertinents et à intégrer de toutes nouvelles sources de données dans l'écosystème de données d'une entreprise.
Cette fonctionnalité automatise certaines parties de la gestion des tâches de données, ce qui entraîne les économies de productivité indiquées ci-dessus, mais elle aide également à éliminer les silos du système de données, à centraliser les procédures de gouvernance des données et à améliorer la qualité globale des données.
Une sécurité des données plus efficace
Cela n'implique pas non plus de sacrifier la sécurité des données et la protection de la vie privée pour étendre l'accès aux données.
En effet, cela nécessite le renforcement des garde-corps de contrôle d'accès et la mise en place de davantage de mesures de gouvernance des données pour garantir que certains rôles sont les seuls à avoir accès à un ensemble de données donné.
De plus, les architectures de tissu de données permettent des équipes de sécurité pour mettre en œuvre le masquage des données et le cryptage des informations confidentielles et sensibles, réduisant la probabilité de partage de données et de piratage du système.
Démocratisation des données
Les applications en libre-service sont facilitées par les conceptions de Data Fabric, étendant la portée de l'accès aux données au-delà du personnel plus technique comme les ingénieurs de données, les développeurs et les équipes d'analyse de données.
En permettant aux utilisateurs professionnels de faire des choix commerciaux plus rapides et en permettant aux utilisateurs techniques de hiérarchiser les activités qui utilisent au mieux leurs compétences, l'élimination des goulots d'étranglement des données entraîne une augmentation de la productivité.
Les cas d'utilisation
Une architecture de structure de données est destinée à offrir une structure globale pour gérer toutes les formes d'informations stockées afin qu'elles puissent être rendues utilisables en cas de besoin.
Ces types de données peuvent être utilisés pour n'importe quoi, d'une prévision des ventes à un rapport sur l'état de l'infrastructure informatique d'une organisation ou des points de terminaison des utilisateurs.
Les cas d'utilisation de l'architecture Data Fabric sont identiques aux cas d'utilisation pour tout autre type de données dans une entreprise, y compris les ventes, le marketing, l'informatique, la cybersécurité, etc.
Cependant, les données d'une organisation sont souvent organisées, semi-structurées ou non structurées dans presque tous les cas d'utilisation. Une base de données relationnelle peut stocker des données structurées et être rapidement utilisée, comme des enregistrements de base de données.
Les données qui n'ont pas été nettoyées ou catégorisées sont appelées données non structurées et doivent être préparées pour être utilisées en cas de besoin.
Plusieurs formes de données non structurées que de nombreuses entreprises peuvent acquérir et stocker pour une utilisation future comprennent machine learning, d'analyse, de données de capteurs, de cloud computing et d'applications de productivité.
Dans les données semi-structurées, qui incluent des données d'un type reconnu enregistrées avec des données non structurées (telles que des fichiers zip, des pages Web et des e-mails), les deux aspects sont présents.
De nombreux cas d'utilisation possibles basés sur la capacité de la data fabric à aider les entreprises à accéder et à utiliser leurs données plus rapidement et efficacement peuvent être trouvés en recherchant son utilisation.
Les exemples typiques incluent :
- Détection de fraude
- Analyse IoT
- Logistique de la chaîne d'approvisionnement
- Analyse de données en temps réel
- Intelligence client
- Augmentation de l'efficacité opérationnelle
- Analyse de la maintenance préventive
- De plus, les modèles de risque de retour au travail
- Sécuriser les transactions avec les cartes de crédit
- Prédiction du taux de désabonnement, détection des fraudes et évaluation du crédit
Conclusion
En conclusion, les silos de données doivent progressivement se désintégrer à mesure que nos niveaux d'utilisation des données augmentent pour faire place aux entreprises connectées.
Le déploiement des data fabrics représente une avancée significative sur cette voie, se classant parmi les découvertes les plus révolutionnaires depuis le développement des bases de données relationnelles dans les années 1970.
Il en est ainsi parce que la structure de données est plus qu'une technologie ou un élément unique.
Les données et les opérations commerciales sont intimement liées par la conception de l'architecture, une procédure systématique et un changement de mentalité.
Data Fabric réduit les coûts, améliore les performances et facilite un déploiement et une maintenance plus efficaces de l'infrastructure. Cela pourrait être le composant clé pour s'assurer que chaque processus, application et décision commerciale est basé sur les données.





Soyez sympa! Laissez un commentaire